16 Cleaning up mislabeled dev and test set examples
에러 분석 도중, 개발 데이터셋에 있는 몇 예제 데이터들이 잘못 레이블링된 것을 발견하는 경우가 있다. “잘못 레이블링되었다”라는 말은 알고리즘이 이 문제에 직면하기도 전에, 이미 사람이 잘못된 레이블 기입한 경우를 말한다. 예를 들어서 (x, y)라는 데이터에서 y 값이 잘못 기입된 것이다. 또 다른 예로는 몇 고양이가 아닌 사진들에 대하여 고양이라고 잘못 레이블링한 경우나, 그 반대의 경우도 생각해 볼 수 있다. 잘못 레이블링된 이미지들의 부분집합이 문제의 원인제공에 매우 큰 영향을 행사한다고 의심이 되면, 다음과 같이 그 잘못 레이블링된 예제 데이터를 지속적으로 추적하기 위한 에러 종류를 추가해 보자 :
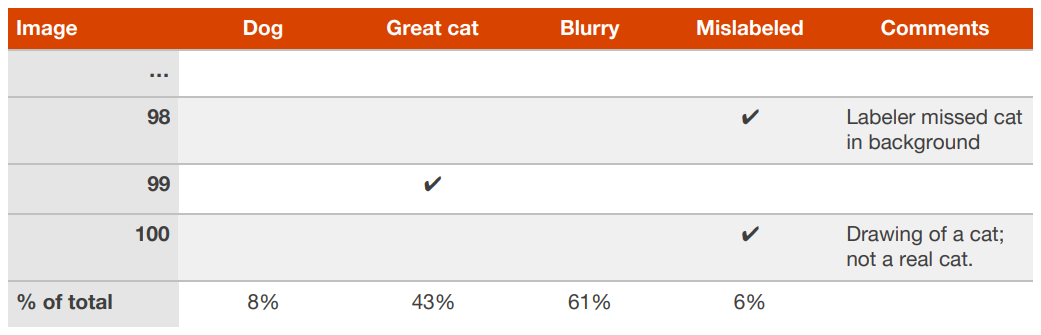
개발 데이터셋에 있는 레이블들을 올바르게 수정해야만 할까? 개발 데이터셋의 목표점은 알고리즘 A가 B보다 더 낫다고 빠르게 판단을 내릴 수 있는데 도움을 주는 것임을 상기하자. 잘못 레이블링된 개발 데이터셋의 일부분 때문에, 이런 판단이 지연된다면, 이 잘못 레이블링된 값을 올바르게 수정하는데 드는 시간이 의미 있는 것이다.
예를 들어서, 당신이 만든 알고리즘의 성능이 다음과 같을때:
- 개발 데이터셋에 대한 종합적인 정확도 …….. 90% (10%의 종합적인 에러율)
- 잘못 레이블링된 데이터로 야기된 에러율 …… 0.6% (개발 데이터셋에서의 6%의 에러율)
- 그 외의 원인으로 야기된 에러율 …………. 9.4% (개발 데이터셋에서의 94%의 에러율)
잘못 레이블링된 데이터로 야기되는 0.6% 라는 수치의 에러율은 비교적 별로 중요하지 않을 수 있다. 상대적으로 그 외의 원인을 조사하여 9.4%라는 더 큰 비중을 차지하는 에러율을 개선 할 수 있을지도 모르기 때문이다. 개발 데이터셋에서 잘못 레이블링된 데이터를 수작업으로 올바르게 수정하는 것이 해롭지는 않지만, 크게 중요하지도 않다. 전체 시스템의 에러율이 10%인 것과 9.4%인 것에는 큰 차이가 없기 때문이다.
고양이 분류 알고리즘을 계속 개선하여, 다음과 같은 성능을 얻었을때:
- 개발 데이터셋에 대한 종합적인 정확도 …….. 98.0% (2.0%의 종합적인 에러율)
- 잘못 레이블링된 데이터로 야기된 에러율 …… 0.6% (개발 데이터셋에서의 30%의 에러율)
- 그 외의 원인으로 야기된 에러율 …………. 1.4% (개발 데이터셋에서의 70%의 에러율)
전체 에러 중, 30%에 해당하는 에러율이 개발 데이터셋에 있는 잘못 레이블링된 이미지로 부터 야기되었다. 이정도의 에러율은 정확도 측면에서 중대한 에러율이라고 볼 수 있다. 이 경우에는 개발 데이터셋에 있는 레이블들의 퀄리티를 향상시키는 것이 의미가 있다. 잘못 레이블링된 예제 데이터를 건드리는 것은 분류 알고리즘의 에러율이 1.4%와 2.0% 둘 중 어느쪽에 더 가까운지 알아내는데 도움을 줄 것이다. 이 경우에 1.4%인 것과 2.0%인 것은 상대적으로 중요한 차이라고 볼 수 있겠다.
프로젝트 시작 단계에서, 잘못 레이블링된 개발/테스트 데이터셋을 용인하는 것은 일반적이다. 하지만, 시스템의 성능이 향상됨에 따라 잘못 레이블링된 데이터로 야기되는 에러율이 차지하는 비율이 커질 수 있다. 그러므로 시스템이 성장함에 따라 이를 염두해 두는 것이 좋다.
이전 챕터에서는 “강아지”, “큰 고양잇과의 동물”, “흐릿한” 이미지등으로 부터 야기되는 에러율을 어떻게 알고리즘적으로 개선할 수 있는지를 설명 할 것이다. 이번 챕터에서는 잘못 레이블링된 데이터의 레이블을 개선을 통한 작업을 어떻게 진행 해야하는지 또한 배웠다.
개발 데이터셋의 레이블을 고치기 위한 과정이 무엇이든지 간에, 이를 테스트 데이터셋에도 동일하게 적용해야 함을 기억해 두자. 그래야 개발/테스트 데이터셋이 동일한 데이터 분포를 가지게 된다. 개발/테스트 데이터셋을 함께 수정하는 것이 챕터6에서 논의된 문제를 방지할 수 있을 것이다.
레이블의 퀄리티를 향상 하고자 마음 먹었다면, 시스템이 잘못 분류한 예제 데이터와 잘 분류한 예제 데이터의 레이블을 함께 체크해 보기를 권장한다. 수정 전의 레이블이 잘못 되었을 수도 있고, 알고리즘이 그 특정 예제 데이터 모두에 대해서 잘못 동작하고 있을 가능성이 있기 때문이다. 만약 시스템에 의해 잘못 분류된 데이터의 레이블만을 수정한다면, 나중의 평가 단계에서 편향된 결과를 얻을 수도 있다. 1,000개로 이뤄진 개발 데이터셋을 가지고 있고, 알고리즘의 정확도가 98.0%일때, 20개의 잘못 분류된 데이터의 분석이 올바르게 분류된 나머지 980개의 데이터의 분석보다 쉬울 것이다. 잘못 분류된 데이터만을 확인 해 보는 것이 현실적으로 더 쉽기 때문에, 개발 데이터셋에 대해서 편향된 결과가 발생하게 된다. 이 편향된 결과는 상품/어플리케이션을 개발하는 것에만 관심이 있는 경우 괜찮을 수 있다. 하지만, 아카데믹한 연구 논문에 사용되거나 테스트 데이터셋의 정확도에서, 완전히 편파적이지 않은 측정을 하고 싶을때는 문제가 될 수 있다.