TL;DR#
Current image pyramids use the same large model for all image resolutions, resulting in high computational costs. This is a major bottleneck for high-resolution image processing, especially with large vision models and emerging multimodal large language models. Existing methods like feature pyramids attempt to mitigate this, but top-performing models still rely on inefficient image pyramids due to their performance advantages. The paper also explores the issue in multimodal understanding, as scaling up the resolution helps but incurs a high computational cost.
The paper proposes a novel architecture called Parameter-Inverted Image Pyramid Networks (PIIP) to address this issue. PIIP employs pretrained models of varying sizes for different image resolutions, with smaller models processing higher-resolution images and larger models handling lower-resolution ones. This parameter-inverted approach significantly reduces computation while maintaining accuracy. The paper also introduces a novel cross-branch feature interaction mechanism to better integrate information from different scales. Experiments show PIIP outperforms existing methods on object detection, semantic segmentation, image classification, and multimodal understanding with significantly lower computation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient approach to building image pyramids for visual perception and multimodal understanding. This significantly reduces computational costs without sacrificing performance, a critical advancement in the field of large-scale vision models. The parameter-inverted design and cross-branch feature interaction mechanism offer new avenues for optimizing model architectures and improving efficiency. Researchers can use this work as a foundation for developing more cost-effective and high-performing vision systems for various applications.
Visual Insights#

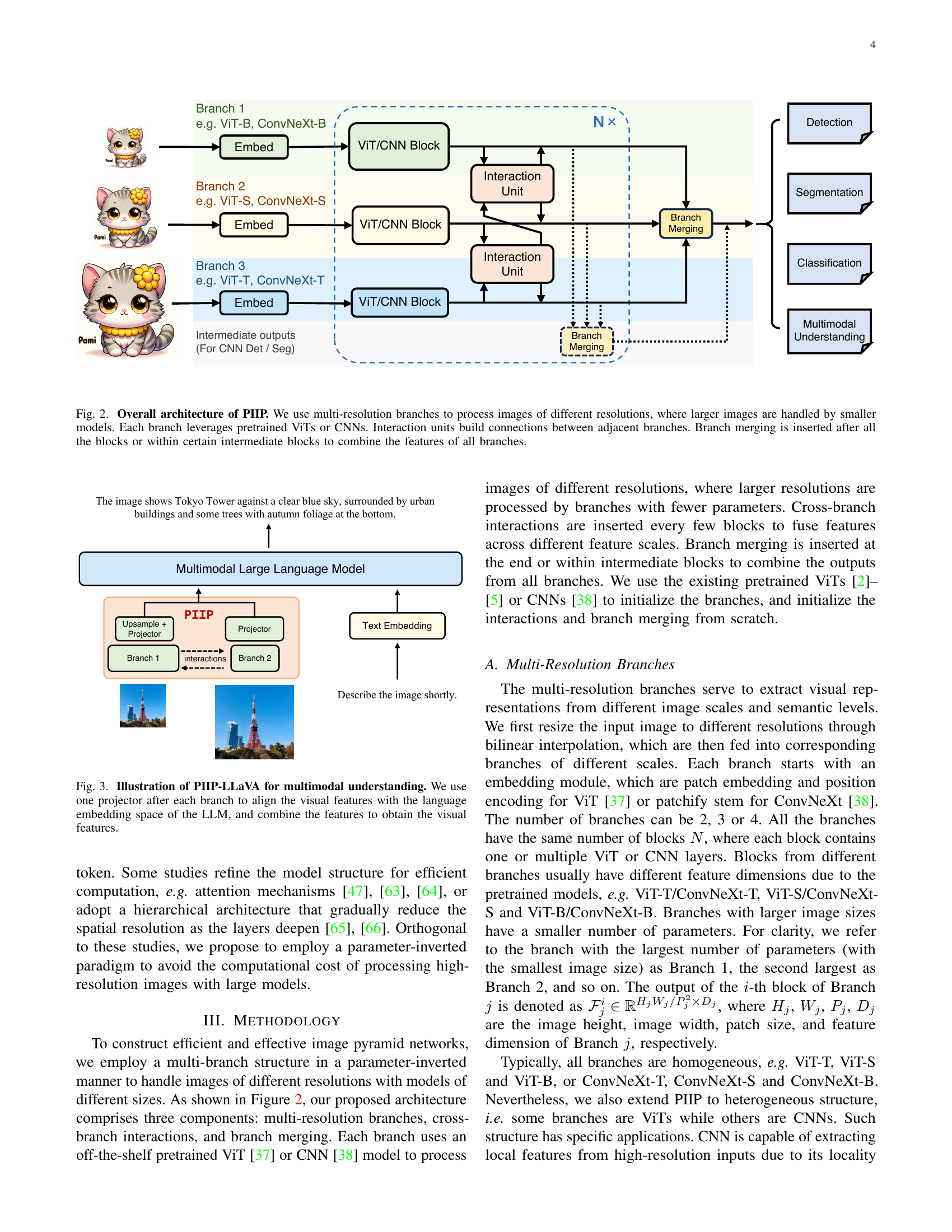
🔼 Figure 1 illustrates various multi-resolution approaches used in visual perception and multimodal understanding tasks. (a) and (e) show basic network architectures lacking multi-scale feature processing. (b), (c), and (f) depict traditional image pyramid methods, which use the same large model across all image resolutions, leading to high computational costs. This is done either through weight sharing or with separate weights for each resolution, with some sort of feature interaction. (d) demonstrates a parameter-direct approach using large models for high-resolution images, again causing high computational costs. (g) presents multi-resolution strategies applied to multimodal understanding, often involving image partitioning. Finally, (h) introduces the authors’ proposed Parameter-Inverted Image Pyramid Network (PIIP), which uses smaller models for higher-resolution images and larger models for lower-resolution images, leading to improved efficiency and performance.
read the caption
Figure 1: Different multi-resolution designs in visual perception and multimodal understanding. (a)(e) Plain network without multi-scale features. (b)(c)(f) Inefficient image pyramid networks using equivalently large models for all scales, either with shared weights or with separate weights and interactions. (d) Parameter-direct image pyramid network which processes high-resolution images with large models, leading to high computational cost. (g) Multi-resolution approaches on multimodal tasks based on grid partition. (h) Our efficient and effective parameter-inverted image pyramid network (PIIP), which pairs models of increasing parameter sizes inversely with images of decreasing resolution. It achieves better performance with much lower computational cost.
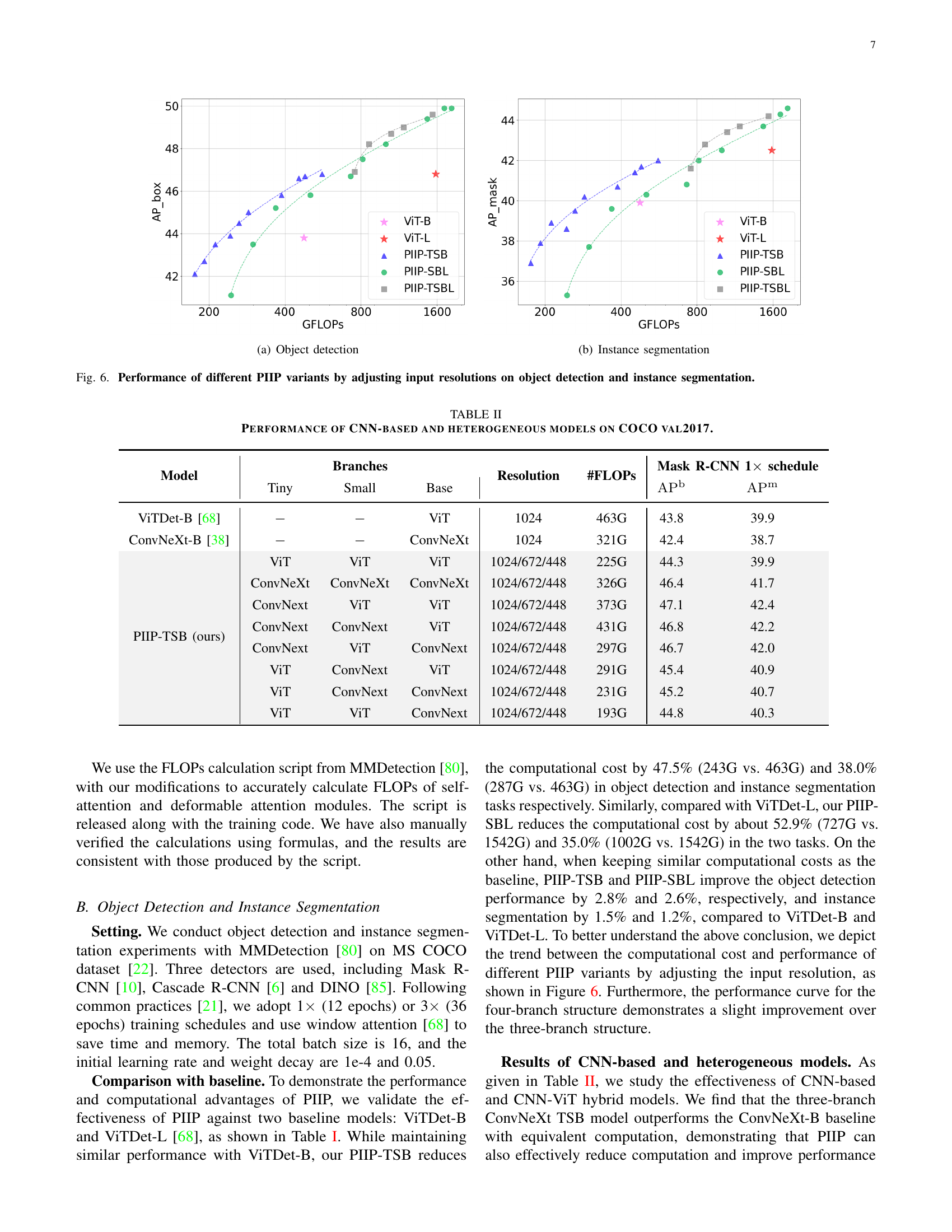
| Model | Resolution | #Param | #FLOPs | Mask R-CNN 1 schedule | |||||
| ViTDet-B [68] | 1024 | 90M | 463G | 43.8 | 67.6 | 47.7 | 39.9 | 63.6 | 42.2 |
| 1120/896/448 | 146M | 243G | 43.9 | 65.7 | 47.5 | 38.6 | 61.8 | 40.6 | |
| PIIP-TSB (ours) | 1568/896/448 | 147M | 287G | 45.0 | 67.0 | 48.7 | 40.2 | 63.8 | 42.6 |
| 1568/1120/672 | 149M | 453G | 46.6 | 68.4 | 51.1 | 41.4 | 65.2 | 44.3 | |
| ViTDet-L [68] | 1024 | 308M | 1542G | 46.8 | 70.8 | 51.4 | 42.5 | 67.3 | 45.3 |
| 1120/672/448 | 493M | 727G | 46.7 | 69.0 | 50.6 | 40.8 | 65.2 | 42.8 | |
| PIIP-SBL (ours) | 1344/896/448 | 495M | 1002G | 48.2 | 71.0 | 52.8 | 42.5 | 67.3 | 45.4 |
| 1568/896/672 | 497M | 1464G | 49.4 | 71.9 | 53.9 | 43.7 | 68.4 | 46.6 | |
| 1344/896/672/448 | 506M | 755G | 46.9 | 69.9 | 50.6 | 41.6 | 65.9 | 44.1 | |
| PIIP-TSBL (ours) | 1568/1120/672/448 | 507M | 861G | 48.2 | 70.5 | 52.7 | 42.8 | 66.9 | 45.6 |
| 1792/1568/1120/448 | 512M | 1535G | 49.6 | 72.4 | 54.2 | 44.2 | 69.2 | 47.5 | |
🔼 Table I presents a comparison of the proposed Parameter-Inverted Image Pyramid Networks (PIIP) model with baseline models on the COCO val2017 dataset for object detection. It shows the number of parameters and FLOPs (floating point operations) for each backbone network architecture. Key performance metrics, including box Average Precision (APb) and mask Average Precision (APm), are reported for both 50 and 75 IoU thresholds. Underlined values indicate performance metrics or FLOPs comparable to the baseline.
read the caption
TABLE I: Comparison with baseline on COCO val2017. We report the number of parameters and FLOPs of the backbone. Underline indicates FLOPs or metrics on par with the baseline. APbsuperscriptAPb\rm AP^{b}roman_AP start_POSTSUPERSCRIPT roman_b end_POSTSUPERSCRIPT and APmsuperscriptAPm\rm AP^{m}roman_AP start_POSTSUPERSCRIPT roman_m end_POSTSUPERSCRIPT represent box AP and mask AP, respectively.
In-depth insights#
Inverted Image Pyramids#
The concept of “Inverted Image Pyramids” presents a compelling alternative to traditional approaches in image processing and multimodal understanding. Instead of using large models to process all image resolutions, which is computationally expensive, an inverted pyramid architecture utilizes smaller models for high-resolution images and progressively larger models for lower resolutions. This approach leverages the observation that high-resolution images benefit from detailed local feature extraction, which can be efficiently accomplished by smaller models. In contrast, lower resolution images allow for capturing richer semantic context that may be better modeled using larger parameter sets. The key advantages of this strategy are enhanced efficiency and computational savings without necessarily sacrificing accuracy. Effective feature fusion strategies are crucial to integrate features from different resolutions, enabling the network to learn robust multi-scale representations. While promising, further exploration is needed to fully understand the limitations and optimal architectural design principles for inverted image pyramids across diverse visual perception tasks.
Cross-Branch Fusion#
Cross-branch fusion, in the context of a multi-scale image processing network like the one described, is crucial for effective visual perception and understanding. It’s a method to integrate features from different spatial scales and semantic levels extracted by multiple branches of the network, each processing a different resolution of the same image. Effective fusion is key to achieving accurate multi-scale feature representations that are both computationally efficient and highly performative. The fusion mechanism employed (e.g., attention, concatenation) should be designed carefully to minimize redundancy and maximize information exchange between branches. The choice of fusion method directly impacts overall accuracy, efficiency, and the model’s ability to leverage the strengths of both high and low-resolution feature maps. Strategies for balancing computational cost against accuracy are vital since it directly affects both the number of branches used and the complexity of the fusion operations. A parameter-inverted pyramid, where larger models process lower-resolution images and vice-versa, would necessitate careful design of the fusion to ensure that low-level details aren’t lost. Optimal fusion strategies likely require considering feature dimensionality and semantic relevance across scales for effective integration.
Multimodal LLM gains#
Multimodal LLMs, integrating vision and language, offer significant advantages. Improved accuracy in tasks like visual question answering and image captioning results from the fusion of visual and textual data, surpassing the capabilities of unimodal models. The integration also unlocks enhanced contextual understanding, allowing the model to generate more relevant and accurate responses by considering both image content and the accompanying textual context. High-resolution image processing capabilities represent another area of substantial gain, leading to improved detail capture and finer-grained analyses within multimodal tasks. However, challenges remain, including efficient computation and model scaling, especially with large high-resolution images. Successfully addressing these challenges will unlock even more impressive advancements in multimodal AI applications. Further research focusing on data efficiency and robustness will be crucial to the future development of this technology.
Computational Efficiency#
The research paper emphasizes computational efficiency as a critical design goal. Traditional image pyramid networks are computationally expensive because they process images at multiple scales using the same large model, leading to a quadratic increase in computational cost. The proposed Parameter-Inverted Image Pyramid Network (PIIP) directly addresses this by employing smaller models for higher-resolution images and larger models for lower-resolution images. This approach effectively balances computational cost and performance, achieving superior performance with significantly reduced computational overhead. The paper also validates the effectiveness of PIIP in various visual perception tasks and multimodal understanding. The core idea is to leverage the complementary nature of features at different scales to avoid redundancy, enhancing efficiency without sacrificing accuracy.
Future Research#
Future research directions stemming from this Parameter-Inverted Image Pyramid Network (PIIP) research could explore several promising avenues. Extending PIIP to even larger vision foundation models is crucial to assess scalability and performance gains on more demanding tasks. Investigating alternative cross-branch interaction mechanisms beyond the current deformable attention could potentially unlock further performance improvements or enable more computationally efficient designs. A particularly interesting avenue would be to explore the application of PIIP in other computer vision modalities, such as video understanding or 3D vision, adapting the multi-resolution strategy to temporal or volumetric data. Finally, a deeper investigation into the optimal design choices for the number of branches and the specific model choices for each branch could lead to even more efficient and effective PIIP architectures, tailored to specific computational budgets and task requirements. The successful extension of PIIP to multimodal large language models (MLLMs) opens doors for research on combining PIIP with other novel MLLM architectures for enhanced multimodal understanding.
More visual insights#
More on figures

🔼 The figure illustrates the architecture of Parameter-Inverted Image Pyramid Networks (PIIP). PIIP uses multiple branches to process images at different resolutions, a key innovation being that higher resolution images are processed by smaller models to optimize computational efficiency. Each branch employs a pre-trained Vision Transformer (ViT) or Convolutional Neural Network (CNN). Interaction units connect adjacent branches to facilitate information exchange across different scales. A branch merging mechanism combines the features from all branches, either at the end of all processing blocks or at intermediate stages, depending on the specific task. This design balances computational cost and performance by using smaller, less computationally expensive models on the high-resolution inputs where a smaller receptive field is sufficient to extract important details and larger, richer models for lower resolution data which provides more contextual information.
read the caption
Figure 2: Overall architecture of PIIP. We use multi-resolution branches to process images of different resolutions, where larger images are handled by smaller models. Each branch leverages pretrained ViTs or CNNs. Interaction units build connections between adjacent branches. Branch merging is inserted after all the blocks or within certain intermediate blocks to combine the features of all branches.

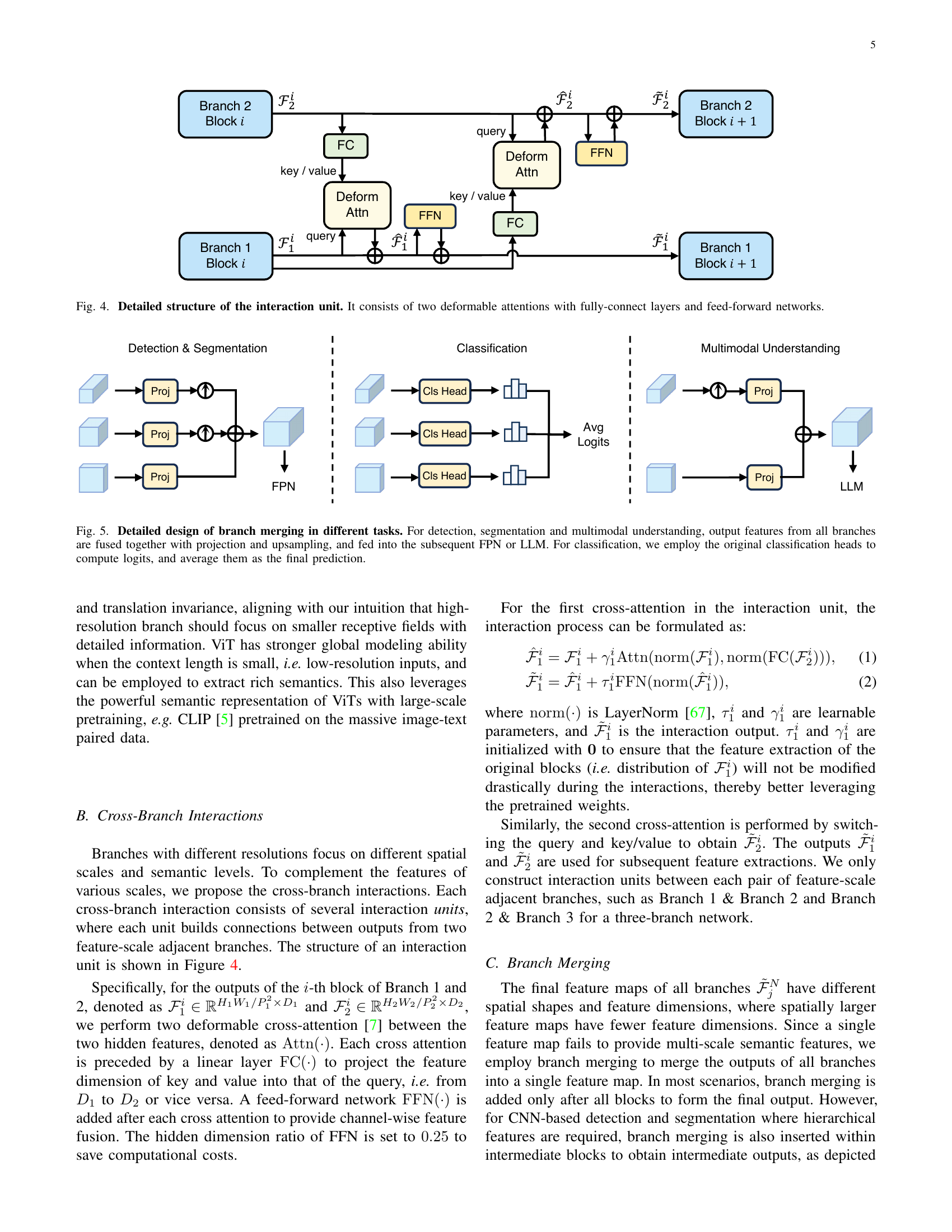
🔼 PIIP-LLaVA is a multimodal large language model that uses a parameter-inverted image pyramid network for efficient and effective high-resolution understanding. The figure illustrates the architecture. Visual input is passed through multiple branches of the network, each handling a different resolution of the image. Lower resolution images are processed by higher capacity branches, while higher resolution images are processed by smaller capacity branches. This parameter-inverted design balances computational cost and performance. Each branch uses a projector to align the resulting features with the language embedding space of a large language model (LLM). The aligned features from all branches are then combined to produce a comprehensive visual representation for the LLM to use in multimodal understanding tasks.
read the caption
Figure 3: Illustration of PIIP-LLaVA for multimodal understanding. We use one projector after each branch to align the visual features with the language embedding space of the LLM, and combine the features to obtain the visual features.

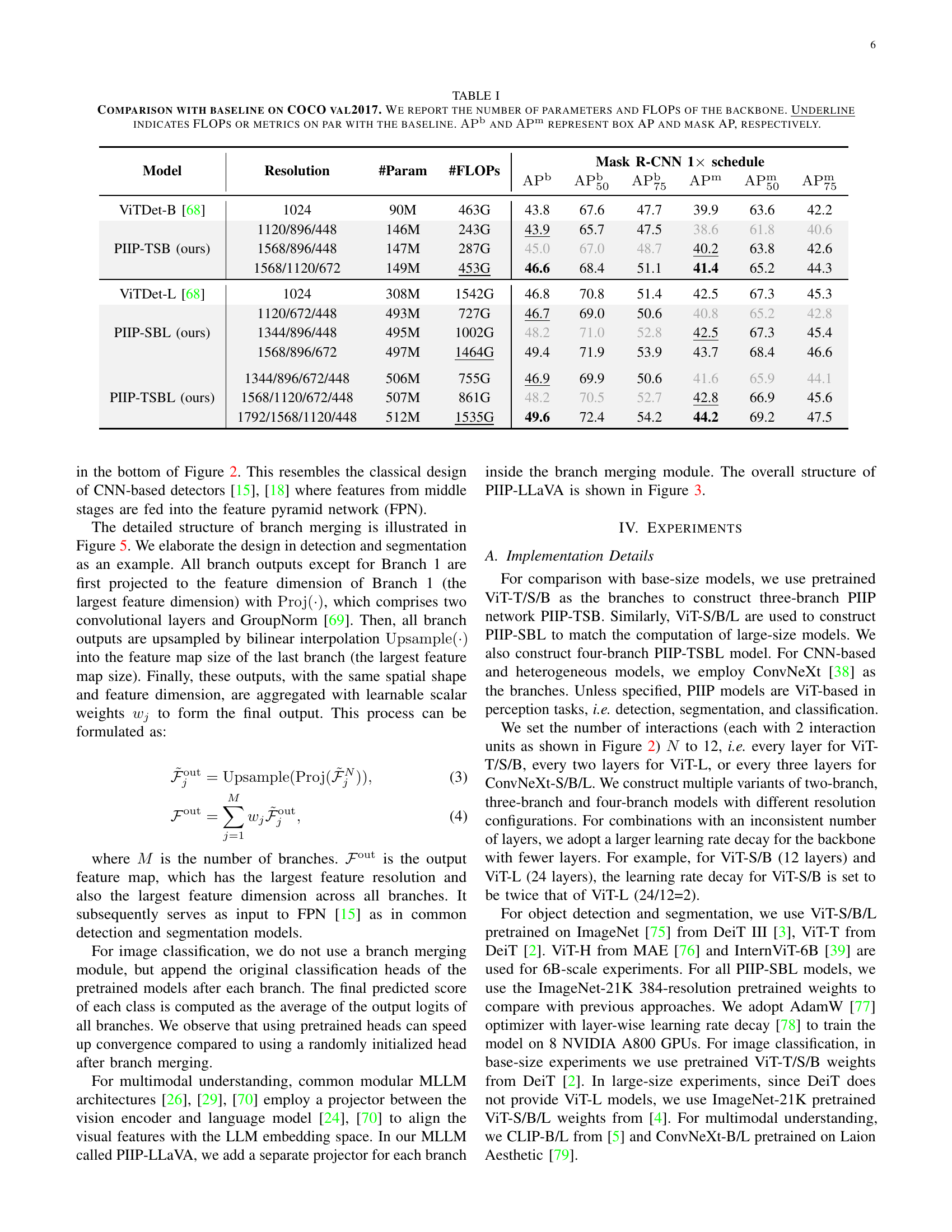
🔼 This figure details the architecture of the interaction unit, a crucial component within the Parameter-Inverted Image Pyramid Network (PIIP). The interaction unit facilitates communication and feature integration between adjacent branches of the PIIP, which process images at different resolutions. As shown, the unit employs two deformable attention mechanisms. Each deformable attention mechanism consists of a fully-connected layer (FC) for feature projection, the deformable attention operation itself, and a feed-forward network (FFN) for channel-wise feature fusion. This multi-step process ensures that features from different scales are effectively combined, improving the overall representational power of the network.
read the caption
Figure 4: Detailed structure of the interaction unit. It consists of two deformable attentions with fully-connect layers and feed-forward networks.

🔼 Figure 5 illustrates how feature maps from multiple branches of the Parameter-Inverted Image Pyramid Network (PIIP) are integrated for different downstream tasks. In object detection, segmentation, and multimodal understanding, features from each branch undergo projection and upsampling to match dimensions before being combined and fed into a Feature Pyramid Network (FPN) or a Large Language Model (LLM). This fusion step leverages the complementary information extracted from various resolutions. For image classification, however, the original classification heads of each branch are used independently, and their predictions are averaged to produce the final result.
read the caption
Figure 5: Detailed design of branch merging in different tasks. For detection, segmentation and multimodal understanding, output features from all branches are fused together with projection and upsampling, and fed into the subsequent FPN or LLM. For classification, we employ the original classification heads to compute logits, and average them as the final prediction.

🔼 This figure displays qualitative results of object detection using the proposed Parameter-Inverted Image Pyramid Networks (PIIP). The images showcase the model’s ability to accurately detect objects at various scales, even small ones, as demonstrated by the bounding boxes around objects in several images.
read the caption
(a) Object detection

🔼 This figure displays instance segmentation results from the PIIP-SBL model. The images showcase the model’s ability to accurately identify and delineate the boundaries of multiple objects within complex scenes. High-resolution processing allows the model to detect even small objects, which are clearly identified and outlined with masks. The results demonstrate a high degree of accuracy and detail in segmenting different objects, highlighting the model’s effectiveness in instance segmentation tasks.
read the caption
(b) Instance segmentation

🔼 This figure shows the performance of different Parameter-Inverted Image Pyramid Network (PIIP) variants on object detection and instance segmentation tasks. The x-axis represents the computational cost (GFLOPS), and the y-axis shows the performance in terms of Average Precision (AP) for both box AP (APb) and mask AP (APm). Different colors represent different PIIP network configurations (with varying model sizes and input image resolutions). The figure demonstrates the impact of adjusting input image resolutions on the overall performance and computational cost for different PIIP models, showcasing a tradeoff between computational efficiency and accuracy.
read the caption
Figure 6: Performance of different PIIP variants by adjusting input resolutions on object detection and instance segmentation.

🔼 Table V presents the results of experiments conducted to assess the impact of using different pre-trained weights on the performance of the Parameter-Inverted Image Pyramid Networks (PIIP) model. Specifically, the table focuses on the PIIP-SBL model configuration with a resolution of 1568/1120/672. This configuration is one of the multiple variations of the PIIP model. The table shows how using different pre-trained ViT weights (from various sources like AugReg, DeiT III, MAE, Uni-Perceiver, DINOv2, and BEiTv2) as initial weights affected the model’s performance on the COCO val2017 dataset for object detection. The performance is measured in terms of Average Precision (AP) for both bounding boxes (APb) and masks (APm). By comparing the APb and APm scores across different pre-trained weights, the study aimed to determine the influence of the initial weight choice on the final model’s accuracy and efficiency.
read the caption
TABLE V: Experiments of initializing with different pre-trained weights on COCO val2017 with PIIP-SBL 1568/1120/672.
More on tables
| Model | Branches | Resolution | #FLOPs | Mask R-CNN 1 schedule | |||
| Tiny | Small | Base | |||||
| ViTDet-B [68] | ViT | 1024 | 463G | 43.8 | 39.9 | ||
| ConvNeXt-B [38] | ConvNeXt | 1024 | 321G | 42.4 | 38.7 | ||
| ViT | ViT | ViT | 1024/672/448 | 225G | 44.3 | 39.9 | |
| ConvNeXt | ConvNeXt | ConvNeXt | 1024/672/448 | 326G | 46.4 | 41.7 | |
| ConvNext | ViT | ViT | 1024/672/448 | 373G | 47.1 | 42.4 | |
| ConvNext | ConvNext | ViT | 1024/672/448 | 431G | 46.8 | 42.2 | |
| ConvNext | ViT | ConvNext | 1024/672/448 | 297G | 46.7 | 42.0 | |
| ViT | ConvNext | ViT | 1024/672/448 | 291G | 45.4 | 40.9 | |
| ViT | ConvNext | ConvNext | 1024/672/448 | 231G | 45.2 | 40.7 | |
| PIIP-TSB (ours) | ViT | ViT | ConvNext | 1024/672/448 | 193G | 44.8 | 40.3 |
🔼 This table presents a comparison of object detection and instance segmentation performance on the COCO val2017 dataset using different model architectures. It shows the results for several models, including the baseline ViTDet-B, and variations of the PIIP model using different combinations of CNNs and Vision Transformers (ViTs), along with various numbers of branches in the multi-resolution architecture. The table highlights the impact of architectural choices and the trade-off between computational cost (#FLOPS) and performance (APb, APm).
read the caption
TABLE II: Performance of CNN-based and heterogeneous models on COCO val2017.
| Method | ||||||
| Mask R-CNN 1 schedule | ||||||
| PVTv2-B5 [66] | 47.4 | 68.6 | 51.9 | 42.5 | 65.7 | 46.0 |
| ViT-B [72] | 42.9 | 65.7 | 46.8 | 39.4 | 62.6 | 42.0 |
| ViTDet-B [68] | 43.2 | 65.8 | 46.9 | 39.2 | 62.7 | 41.4 |
| Swin-B [65] | 46.9 | - | - | 42.3 | - | - |
| ViT-Adapter-B [21] | 47.0 | 68.2 | 51.4 | 41.8 | 65.1 | 44.9 |
| PIIP-TSB (ours) | 47.9 | 70.2 | 52.5 | 42.6 | 67.2 | 45.5 |
| ViT-L [72] | 45.7 | 68.9 | 49.4 | 41.5 | 65.6 | 44.6 |
| ViTDet-L [68] | 46.2 | 69.2 | 50.3 | 41.4 | 65.8 | 44.1 |
| ViT-Adapter-L [21] | 48.7 | 70.1 | 53.2 | 43.3 | 67.0 | 46.9 |
| PIIP-SBL (ours) | 49.9 | 72.8 | 54.7 | 44.6 | 69.3 | 47.9 |
| DINO + MS schedule | ||||||
| PIIP-SBL-3 (ours) | 57.9 | 76.9 | 63.3 | - | - | - |
| PIIP-H6B-1 (ours) | 60.0 | 79.0 | 65.4 | - | - | - |
🔼 Table III presents a comparison of different models’ performance on object detection and instance segmentation tasks using the COCO val2017 dataset. The table shows the Average Precision (AP) scores at different intersection over union (IoU) thresholds (AP50, AP75, AP, APm) for various models. The ‘MS’ column indicates whether AutoAugment [71] was used for multi-scale training, enhancing the model’s ability to handle objects of various sizes. Large-size models in this table utilize ViT weights pretrained on the larger ImageNet-21K dataset, improving their overall performance compared to models trained on the standard ImageNet dataset. Note that some results included in this table are taken from a previous study [21].
read the caption
TABLE III: Object detection and instance segmentation performance on COCO val2017. ‘MS’ means using AutoAugment [71] for multi-scale training. Large-size models use ViT weights trained on ImageNet-21K. Some results are from [21].
| Method | ||||||
| Cascade R-CNN 1 schedule | ||||||
| Swin-L [65] | 51.8 | 71.0 | 56.2 | 44.9 | 68.4 | 48.9 |
| ConvNeXt-L [38] | 53.5 | 72.8 | 58.3 | 46.4 | 70.2 | 50.2 |
| PIIP-SBL (ours) | 53.6 | 73.3 | 57.9 | 46.3 | 70.3 | 50.0 |
| Cascade R-CNN 3 + MS schedule | ||||||
| Swin-B [65] | 51.9 | 70.9 | 57.0 | - | - | - |
| Shuffle-B [73] | 52.2 | 71.3 | 57.0 | - | - | - |
| ViT-B [72] | 50.1 | 69.3 | 54.3 | - | - | - |
| ViT-Adapter-B [21] | 52.1 | 70.6 | 56.5 | - | - | - |
| PIIP-TSB (ours) | 53.1 | 72.3 | 57.4 | 46.5 | 70.1 | 51.1 |
| Swin-L [65] | 53.9 | 72.4 | 58.8 | 46.7 | 70.1 | 50.8 |
| RepLKNet-31L [74] | 53.9 | 72.5 | 58.6 | 46.5 | 70.0 | 50.6 |
| ConvNeXt-L [38] | 54.8 | 73.8 | 59.8 | 47.6 | 71.3 | 51.7 |
| PIIP-SBL (ours) | 54.5 | 73.8 | 59.1 | 47.7 | 71.6 | 52.1 |
🔼 This table presents the results of experiments conducted using the InternViT-6B, a large-scale vision foundation model. It compares the performance of the InternViT-6B model with and without the proposed Parameter-Inverted Image Pyramid Networks (PIIP) on object detection and semantic segmentation tasks. The table shows the model’s parameters, FLOPs (floating point operations), resolution, and performance metrics (APb for bounding box average precision and APm for mask average precision). This allows for a direct comparison of the computational cost and performance gains achieved by incorporating PIIP into the InternViT-6B architecture.
read the caption
TABLE IV: Experiments on the large-scale vision foundation model InternViT-6B.
| Model | #Param | Mask R-CNN 1 schedule | UperNet 160k | |||||
| #FLOPs | Resolution | Crop Size | #FLOPs | mIoU | ||||
| InternViT-6B [39] | 5919M | 24418G | 1024 | 53.8 | 48.1 | 512 | 6105G | 58.36 |
| 7269M | 5643G | 1280/1024/256 | 53.5 | 47.5 | 640/512/192 | 1903G | 57.82 | |
| PIIP-LH6B (ours) | 7271M | 10368G | 1280/1024/512 | 54.4 | 47.8 | 640/512/256 | 2592G | 58.42 |
| 7273M | 13911G | 1280/1024/640 | 55.7 | 49.0 | 640/512/384 | 4560G | 59.65 | |
🔼 Table X details the configurations and performance of a model trained from scratch using a parameter-inverted image pyramid design. It breaks down the model architecture into three branches, specifying the number of layers, dimensions, heads, and resolution for each. The table contrasts these architectural settings against the total number of parameters and floating-point operations (FLOPs) required. Finally, it presents the resulting top-1 accuracy achieved on the ImageNet-1K benchmark, offering a quantitative evaluation of the proposed parameter-inverted approach in a from-scratch pretraining context.
read the caption
TABLE X: From-scratch pre-training settings and results on ImageNet-1K.
| ViT-S | ViT-B / ViT-L | ||
| AugReg [4] | AugReg [4] | 48.3 | 42.6 |
| DeiT III [3] | Uni-Perceiver [81] | 48.8 | 42.9 |
| DeiT III [3] | MAE [76] | 49.1 | 43.0 |
| DeiT III [3] | DeiT III [3] | 50.0 | 44.4 |
| DeiT III [3] | DINOv2 [82] | 51.0 | 44.7 |
| DeiT III [3] | BEiTv2 [83] | 51.8 | 45.4 |
🔼 This table compares the performance of several multimodal large language models (MLLMs) on various benchmark datasets. The models use different multi-resolution approaches for processing images, and the comparison highlights the impact of different strategies on the overall performance and efficiency. The key metrics include several benchmark scores (MMBEN, MMVet, TextVQA, SQA, GQA, VQAv2, SEED, POPE) reflecting various aspects of multimodal understanding. The table also shows the number of FLOPs (floating-point operations) used by the vision encoders of each model, indicating computational cost. All models were trained using the same LLaVA-1.5 training data for consistency.
read the caption
TABLE XI: Comparison with multi-resolution baselines on multimodal benchmarks. All models are trained with LLaVA-1.5 [24] training data. We report #FLOPs of the vision encoder.
| Method | Crop Size | #FLOPS | mIoU |
| ViT-B | 640 | 159G | 51.0 |
| PIIP-TSB (ours) | 896/448/336 | 118G | 51.6 |
| ViT-L | 640 | 545G | 53.6 |
| PIIP-SBL (ours) | 1120/448/336 | 456G | 54.3 |
🔼 Table XII presents a comparison of the PIIP-LLaVA model’s performance against other existing large multimodal language models (MLLMs) across various benchmark datasets. The benchmarks evaluate different aspects of multimodal understanding, including visual perception, question answering, and visual reasoning. The table includes the vision encoder used by each model, its input image resolution, the language model employed, the amount of training data used, and the performance scores achieved on each benchmark. Note that the SQA-IMG test set contains images also present in the training data, thus affecting the result and average score for this specific benchmark; these are indicated in gray.
read the caption
TABLE XII: Comparison with existing MLLMs on multimodal benchmarks. “Data” denotes the data size of all training stages. *Images from SQA-IMG test set are observed in training, so we mark its result and Avg in gray.
| Method | Crop Size | mIoU |
| Swin-B [65] | 512 | 48.1 |
| ConvNeXt-B [38] | 512 | 49.1 |
| RepLKNet-31B [74] | 512 | 49.9 |
| SLaK-B [84] | 512 | 50.2 |
| InternImage-B [18] | 512 | 50.2 |
| PIIP-TSB (ours) | 896/448/336 | 51.6 |
| Swin-L [65] | 640 | 52.1 |
| RepLKNet-31L [74] | 640 | 52.4 |
| ConvNeXt-L [38] | 640 | 53.2 |
| ConvNeXt-XL [38] | 640 | 53.6 |
| InternImage-L [18] | 640 | 53.9 |
| PIIP-SBL (ours) | 1120/448/336 | 54.3 |
🔼 This ablation study analyzes the impact of different design choices in the PIIP-LLaVA model on its performance in multimodal understanding tasks. Specifically, it investigates the effects of varying the number of interactions between vision branches and the number of unfrozen modules during pretraining, while controlling computational costs by adjusting input resolution. The results demonstrate the optimal configurations for maximizing performance in different multimodal tasks.
read the caption
TABLE XIII: Ablation on multimodal understanding with CLIP-B, CLIP-L and Vicuna-7B.
| Model | Resolution | #FLOPs | Top-1 Acc |
| DeiT-B [2] | 224 | 17.2G | 81.8 |
| PIIP-TSB (ours) | 368/192/128 | 17.4G | 82.1 |
| ViT-L [4] | 224 | 61.6G | 84.0 |
| ViT-L [4] (our impl.) | 224 | 61.6G | 85.2 |
| PIIP-SBL (ours) | 320/160/96 | 39.0G | 85.2 |
| PIIP-SBL (ours) | 384/192/128 | 61.2G | 85.9 |
🔼 This table presents an ablation study comparing different design choices within the image pyramid network architecture. It investigates the impact of three key components: the parameter-inverted design (PI), the traditional image pyramid approach (IP), and the cross-branch interaction mechanism (Inter.). The table shows how variations in these components affect performance (measured by APb, APm, etc.) on the MS COCO dataset. The multi-scale training strategy from reference [71] is also considered. Different model configurations (e.g., using the same sized model for all branches or different sized models) and input resolutions are compared. The baseline (Fig. 1(a)) is a standard network without any multi-scale features, while others introduce image pyramids and/or parameter inversion and compare performance under similar computational budgets. This provides insights into which design choices are most effective for improving both accuracy and efficiency.
read the caption
TABLE XIV: Ablation on image pyramid and parameter-inverted design. ‘PI’, ‘IP’ and ‘Inter.’ represent parameter-inverted, image pyramid and interactions. ‘MS’ means multi-scale training, following [71].
| Out Branch | ||
| B | 43.1 | 37.0 |
| S | 44.7 | 39.1 |
| T | 45.6 | 40.6 |
| B+S | 45.4 | 39.8 |
| B+T | 46.3 | 41.1 |
| S+T | 46.2 | 40.9 |
| B+S+T | 46.6 | 41.4 |
🔼 This table presents a comparison of the performance of a baseline model (ViTDet-L) with higher input resolution (1792) against the same model with lower resolution (1024) and the PIIP-TSBL model also with 1792 resolution. It demonstrates the impact of increased resolution on performance and computational cost, highlighting the efficiency of the PIIP approach.
read the caption
TABLE XV: Baseline with higher resolution.
| Module | #Layers | Dim | #Heads | Resolution | #Param | #FLOPs |
| Branch 1 | 12 | 640 | 8 | 128 | 59.6M | 3.8G |
| Branch 2 | 12 | 320 | 4 | 256 | 15.1M | 4.3G |
| Branch 3 | 12 | 160 | 2 | 512 | 4.0M | 4.9G |
| Interactions | 12 | - | - | - | 21.2M | 5.1G |
| Branch Merging | - | - | - | - | 0.3M | 0.2G |
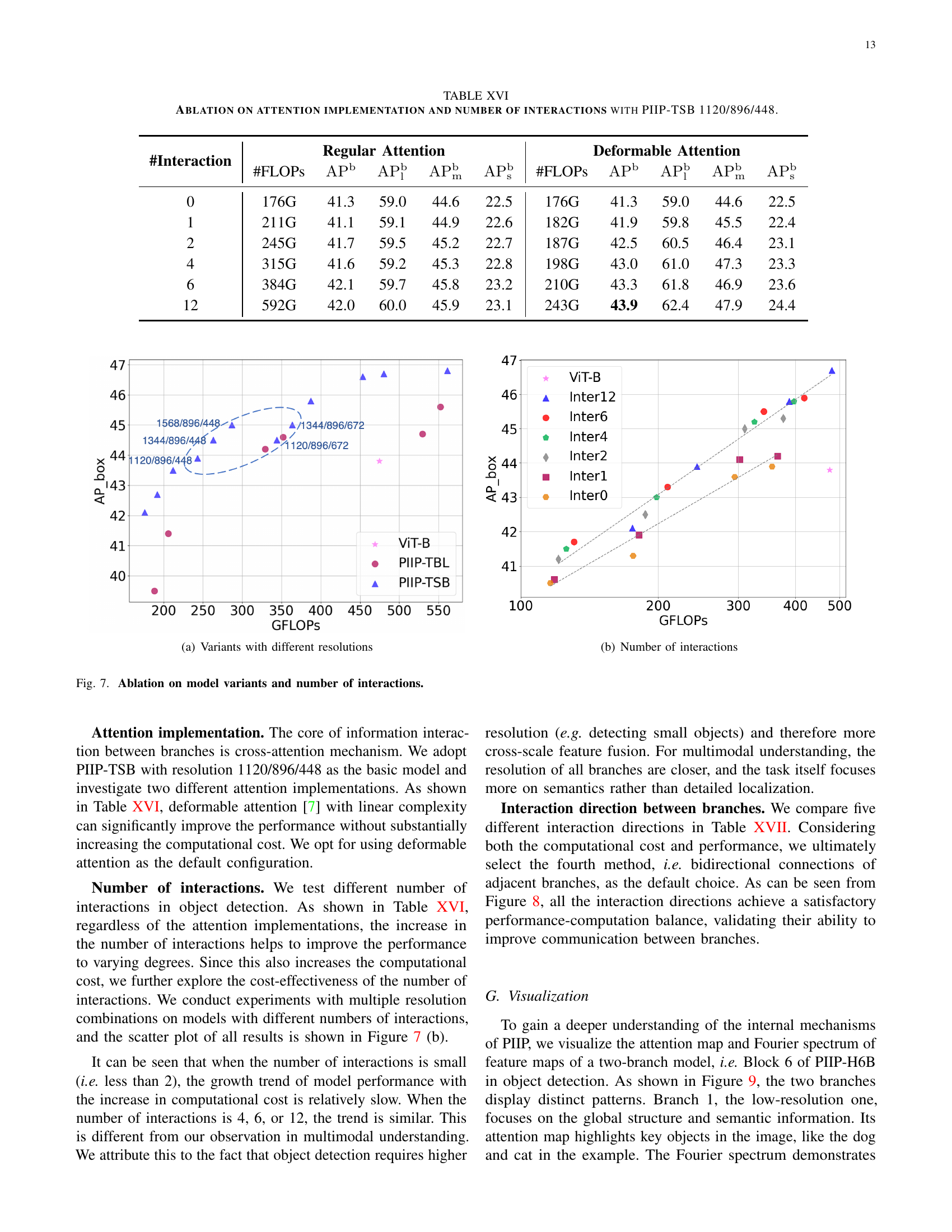
🔼 This table presents the results of ablation studies conducted on the PIIP-TSB model (with resolution 1120/896/448) to analyze the impact of different attention mechanisms and varying numbers of cross-branch interactions on object detection performance. It compares the performance using regular attention versus deformable attention, and shows how performance changes as the number of interactions increases from zero to twelve. The metrics evaluated are AP (average precision) for various object sizes (box AP, small object AP, medium object AP, and large object AP), and FLOPs (floating-point operations), which reflects computational cost.
read the caption
TABLE XVI: Ablation on attention implementation and number of interactions with PIIP-TSB 1120/896/448.
| Model | Resolution | #Param | #FLOPs | Top-1 Acc |
| ViT-B (our impl.) | 224 | 86M | 17.5G | 82.0 |
| PIIP-B (ours) | 512/256/128 | 100M | 18.4G | 82.7 |
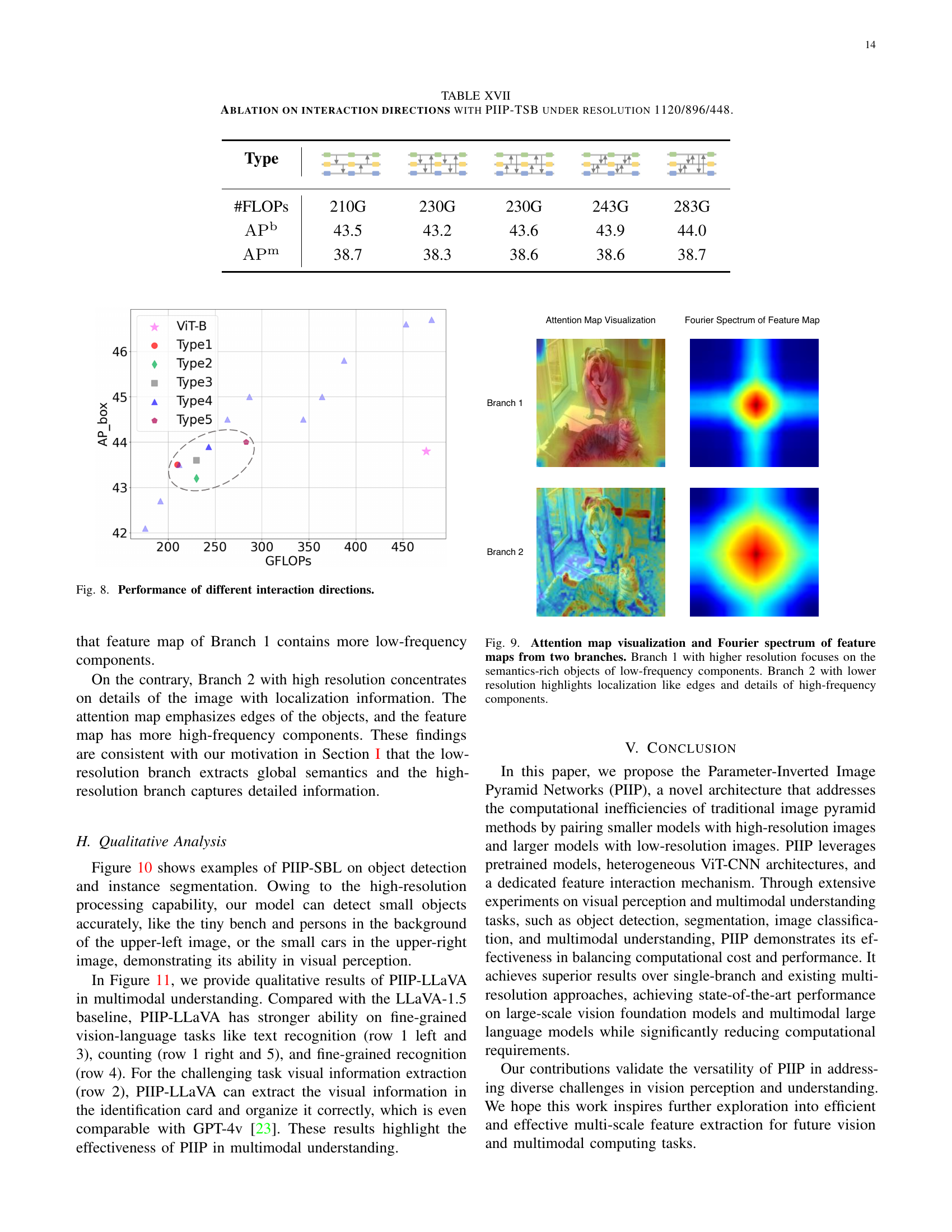
🔼 This table presents an ablation study on different cross-branch interaction strategies within the PIIP-TSB model. It shows the impact of various interaction designs on the model’s performance in terms of APb and APm metrics, while maintaining a consistent resolution of 1120/896/448. The different types represent different patterns of information flow between branches, such as unidirectional from higher to lower resolution, and bidirectional exchange. The FLOPS (floating point operations) are also provided to assess computational cost.
read the caption
TABLE XVII: Ablation on interaction directions with PIIP-TSB under resolution 1120/896/448.
Full paper#