TL;DR#
Current AI music generation struggles with controlling musical emotions and ensuring high-quality output. This research tackles these challenges by introducing XMusic, a novel framework for symbolic music generation. Existing methods often lack flexibility in input types and struggle with consistent output quality.
XMusic uses a two-part system. The first, XProjector, translates diverse input prompts (images, video, text, etc.) into symbolic musical elements such as genre, emotion, rhythm, and notes. The second part, XComposer, generates music based on these elements using a transformer network, and a selector identifies the highest-quality results via multi-task learning. The framework also includes XMIDI, a large, high-quality dataset to train the system, demonstrating significant improvements over current state-of-the-art methods in both objective and subjective evaluations.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical gap in AI-generated music: controllability and quality. It introduces a novel framework and dataset that will likely advance research in symbolic music generation, enabling the creation of more sophisticated and emotionally expressive music. The multi-modal approach and the large-scale dataset also provide valuable resources for researchers in related areas. This work could spur innovations in interactive music systems, virtual reality, and game design.
Visual Insights#
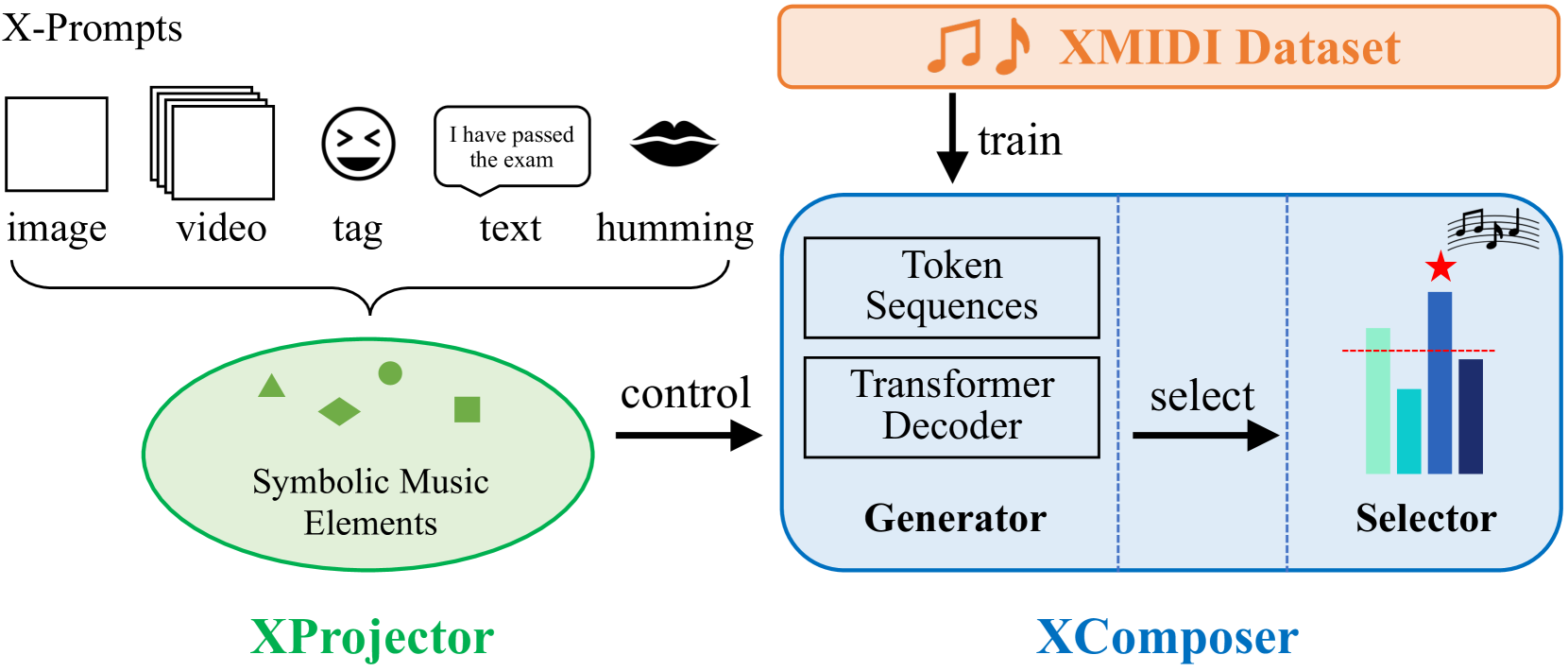
🔼 XMusic is a symbolic music generation framework with two main components: XProjector and XComposer. XProjector takes multi-modal inputs (images, videos, text, tags, humming) and translates them into symbolic musical elements like emotion, genre, rhythm, and notes. These elements act as control signals for XComposer. XComposer consists of a Generator, which produces music based on these control signals, and a Selector, which uses a multi-task learning approach (quality, emotion, and genre assessment) to select the highest-quality output. The Generator is trained on a large dataset, XMIDI, that includes emotion and genre labels.
read the caption
Figure 1: The architectural overview of our XMusic framework. It contains two essential components: XProjector and XComposer. XProjector parses various input prompts into specific symbolic music elements. These elements then serve as control signals, guiding the music generation process within the Generator of XComposer. Additionally, XComposer includes a Selector that evaluates and identifies high-quality generated music. The Generator is trained on our large-scale dataset, XMIDI, which includes precise emotion and genre labels.
| Input Prompt | Analyzed Content | Activated Elements |
|---|---|---|
| video | emotion, rhythm | |
| image | emotion | |
| text | emotion | |
| tag | emotion / genre | |
| humming | notes, rhythm |
🔼 This table shows the correlation between different types of input prompts (video, image, text, tag, humming) and the corresponding symbolic music elements that are activated in the XProjector module. For each prompt type, the table specifies which symbolic music elements (emotions, rhythms, notes) are primarily influenced and subsequently used to guide the music generation process. This illustrates how XMusic handles the multi-modal input and translates it into a unified representation suitable for music generation.
read the caption
TABLE I: Mapping table of the input prompts and the activated elements.
In-depth insights#
XMusic Framework#
The XMusic framework presents a novel approach to symbolic music generation, emphasizing generalization and controllability. It cleverly integrates a multi-modal prompt parser (XProjector) to handle diverse inputs (images, text, humming, etc.), transforming them into a unified symbolic music representation. This representation, enhanced from previous work, allows for fine-grained control over various musical elements (emotion, genre, rhythm). The framework’s XComposer further refines the generation process, employing a generator and selector for high-quality output and efficient filtering. The inclusion of a large-scale, annotated dataset (XMIDI) significantly contributes to its success. The multi-task learning approach in the Selector ensures high-quality results, showcasing a significant leap forward in AI-generated music.
Multimodal Prompt Parsing#
The concept of “Multimodal Prompt Parsing” in the context of AI music generation is crucial. It tackles the challenge of translating diverse input types—images, text, audio, etc.—into a unified representation understandable by the music generation model. The core innovation lies in creating a “projection space” that maps heterogeneous data onto common musical elements like emotion, genre, rhythm, and notes. This approach elegantly solves the problem of incompatible data formats. For example, temporal information from a video is projected onto rhythm elements, while emotional cues from images are mapped to emotional attributes. This unified representation allows the model to generate music that coherently integrates all aspects of the user prompt. A significant aspect is the method’s versatility, enabling flexible and nuanced control over the generated music. The system’s ability to understand and combine disparate inputs reflects an advanced understanding of multimodal fusion, going beyond simplistic concatenation.
Symbolic Music Representation#
The choice of symbolic music representation significantly impacts the model’s ability to generate high-quality and controllable music. MIDI-like representations, encoding music as a sequence of events, are popular but struggle with rhythm modeling. Image-like representations, using matrices like piano rolls, offer advantages for capturing harmonic information but lack the temporal expressiveness of MIDI. The paper’s proposed representation improves upon existing methods by incorporating enhanced Compound Words, adding crucial tokens for instrument specification, emotional control (genre and emotion tags), and finer rhythmic details (beat density and strength). This hybrid approach aims to combine the benefits of both MIDI-like and image-like approaches while addressing their respective limitations, ultimately enabling more nuanced and precise control over music generation.
XMIDI Dataset#
The creation of the XMIDI dataset is a significant contribution to the field of AI-generated music. Its size (108,023 MIDI files) is unprecedented, dwarfing previous datasets and providing a much-needed resource for training robust music generation models. The precise emotion and genre annotations are crucial, enabling researchers to train models capable of generating music with specific emotional and stylistic characteristics. The dataset’s public availability is commendable, fostering broader collaboration and advancement in the field. However, further investigation into the dataset’s potential biases and the annotation methodology’s reliability would enhance its value and provide a deeper understanding of its strengths and limitations.
Future Directions#
Future research should prioritize expanding the XMusic framework to encompass a wider array of input modalities, such as human motion capture data, depth information, and more nuanced textual descriptions. This would enhance the system’s versatility and allow for a more fine-grained control over the generated music’s emotional and stylistic characteristics. Additionally, improving the XMIDI dataset by incorporating more diverse musical genres, instruments, and emotional expressions is crucial. A larger and more representative dataset would significantly enhance the model’s ability to generalize to unseen musical styles and prompts. Furthermore, investigating methods to improve the interpretability and explainability of the model’s decisions is essential. Understanding how the model processes different types of inputs and generates specific musical features would contribute significantly to its wider acceptance and application. Lastly, exploring techniques for real-time generation and interactive music composition would greatly extend the potential applications of XMusic, from composing adaptive soundtracks for videos to enabling collaborative music creation in real-time.
More visual insights#
More on figures

🔼 Figure 2 illustrates the XMusic framework, a system for generating high-quality symbolic music from various prompts. Panel (a) shows the diverse input types: images, videos, text, tags, and humming. The XProjector component (b) processes these prompts, translating them into symbolic music elements (emotions, genres, rhythms, and notes) within a common ‘Projection Space’. Next, the XComposer component’s Generator (c) uses these elements to generate the actual music, employing a Transformer Decoder to create sequential musical representations. Finally, the Selector (d) assesses the generated music’s quality via a multi-task learning process incorporating emotion recognition, genre recognition, and overall quality evaluation.
read the caption
Figure 2: Illustration of the proposed XMusic, which supports flexible (a) X-Prompts to guide the generation of high-quality symbolic music. The XProjector analyzes these prompts, mapping them to symbolic music elements within the (b) Projection Space. Subsequently, the (c) Generator of XComposer transforms these symbolic music elements into token sequences based on our enhanced representation. It employs a Transformer Decoder as the generative model to predict successive events iteratively, thereby creating complete musical compositions. Finally, the (d) Selector of XComposer utilizes a Transformer Encoder to encode the complete token sequences and employs a multi-task learning scheme to evaluate the quality of the generated music.

🔼 Figure 3 illustrates the differences between our proposed symbolic music representation and the Compound Word (CP) representation introduced in a previous work [10]. The core enhancement in our representation is the inclusion of new token types (shown in dotted boxes) which provide explicit control over musical elements, namely: genre, emotion, and instrument type. These additional tokens improve the model’s ability to generate diverse and controlled symbolic music. The addition of the ‘Tag’ token, encapsulating ‘Emotion’ and ‘Genre’, allows for high-level semantic control over style and emotional expression. The ‘Instrument’ token, further divided into ‘Program’, facilitates the creation of multi-track compositions. The improvements to the ‘Rhythm’ token allows more precise control over rhythmic elements, namely ‘density’ and ‘strength’.
read the caption
Figure 3: Comparison between our representation and Compound Word (CP) [10] representation. The dotted boxes represent our new tokens in comparison with those of the CP representation.

🔼 Figure 4 presents a visual summary of the XMIDI dataset’s key statistical properties. It consists of three subfigures: (a) illustrates the distribution of the 11 emotion classes, showing the relative frequency of each emotion in the dataset. (b) shows the distribution of the 6 genre classes, similarly displaying their proportions. (c) illustrates the distribution of music lengths across the dataset, indicating the frequency of different song durations. This figure provides a concise overview of the dataset’s characteristics in terms of emotional variety, musical genres and song lengths.
read the caption
Figure 4: Data statistics of our XMIDI dataset.
More on tables
| Token Type | Vocabulary Size | Embedding Size | ||
|---|---|---|---|---|
| CP [10] | Ours | CP [10] | Ours | |
| instrument | - | 17 (+1) | - | 64 |
| \hdashlinetempo | 58 (+2) | 65 (+2) | 128 | 256 |
| position/bar | 17 (+1) | 33 (+1) | 64 | 256 |
| chord | 133 (+2) | 133 (+2) | 256 | 256 |
| \hdashlinepitch | 86 (+1) | 256 (+1) | 512 | 1024 |
| duration | 17 (+1) | 32 (+1) | 128 | 512 |
| velocity | 24 (+1) | 44 (+1) | 128 | 512 |
| \hdashlinefamily | 3 | 5 | 32 | 64 |
| \hdashlinedensity | - | 33 (+1) | - | 128 |
| strength | - | 37 (+1) | - | 128 |
| \hdashlineemotion | - | 11 (+1) | - | 64 |
| genre | - | 6 (+1) | - | 64 |
| \hdashlinetotal | 338 (+8) | 672 (+13) | - | - |
🔼 This table details the specific implementation choices made in the design of the symbolic music representation used in the XMusic model. It compares the vocabulary size, embedding size, and token types in the proposed representation with those used in the Compound Word (CP) model from a previous work. This allows the reader to better understand the differences in the approach and scale of these two models.
read the caption
TABLE II: Comparison of the implementation details between the CP and our proposed representation.
| Dataset | Emotion Type | Genre Type | Size (Songs) |
|---|---|---|---|
| MIREX-like [55] | 5 classes | multiple | 193 |
| VGMIDI [56] | valence | video game | 95 |
| EMOPIA [11] | Russell’s 4Q | pop | 387 |
| ELMG [12] | 2 classes | multiple | 11,528 |
| XMIDI (Ours) | 11 classes | 6 classes | 108,023 |
🔼 This table compares the characteristics of several existing datasets of emotion-labeled MIDI files with the new XMIDI dataset introduced in this paper. It shows the number of emotion classes, genre types (or whether genre information is included at all), and the total number of MIDI files included in each dataset. This comparison highlights the scale and comprehensiveness of the XMIDI dataset relative to prior work, particularly its significantly larger size and more detailed annotation (e.g., 11 emotion classes vs. fewer in others).
read the caption
TABLE III: Comparison between existing emotion-labeled MIDI datasets and the proposed XMIDI dataset.
| Method | PCE | GS | EBR | |
|---|---|---|---|---|
| (a) Unconditioned | CP [10] | 2.6025 | 0.9990 | 0.0273 |
| EMOPIA [11] | 2.6756 | 0.9989 | 0.1197 | |
| XMusic (Ours) | 2.5174 | 0.9992 | 0.0045 | |
| (b) Video-conditioned | CMT [19] | 2.7290 | 0.6698 | 0.0321 |
| XMusic (Ours) | 2.6161 | 0.9983 | 0.0078 |
🔼 This table presents an objective comparison of XMusic with state-of-the-art symbolic music generation methods across three key metrics: Pitch Class Histogram Entropy (PCE), Grooving Pattern Similarity (GS), and Empty Beat Rate (EBR). Lower PCE and EBR scores indicate better tonality and rhythm, while a higher GS score suggests stronger rhythmic structure. The table is divided into two sections: unconditioned and video-conditioned methods, showcasing XMusic’s superior performance in both scenarios.
read the caption
TABLE IV: Objective comparison with state-of-the-art symbolic music generation methods.
| Method | Richness | Correctness | Structuredness | Emotion-Matching | Rhythm-Matching | Overall Rank | |
|---|---|---|---|---|---|---|---|
| (a) Unconditioned | CP [10] | 2.2323 | 2.1161 | 2.0871 | - | - | 2.1452 |
| EMOPIA [11] | 2.2387 | 2.4807 | 2.3452 | - | - | 2.3549 | |
| XMusic (Ours) | 1.5290 | 1.4032 | 1.5677 | - | - | 1.5000 | |
| (b) Video-conditioned | CMT [19] | 1.7129 | 1.7484 | 1.6742 | 1.6452 | 1.6807 | 1.6923 |
| XMusic (Ours) | 1.2871 | 1.2516 | 1.3258 | 1.3548 | 1.3194 | 1.3077 | |
| (c) Text-conditioned | BART-base [62] | 2.3871 | 2.4806 | 2.2226 | 2.6258 | - | 2.4290 |
| GPT-4 [22] | 2.1355 | 2.0065 | 2.1903 | 1.8613 | - | 2.0484 | |
| XMusic (Ours) | 1.4774 | 1.5129 | 1.5871 | 1.5129 | - | 1.5226 | |
| (d) Image-conditioned | Synesthesia [63] | 1.5548 | 1.8065 | 1.7484 | 1.7936 | - | 1.7258 |
| XMusic (Ours) | 1.4452 | 1.1935 | 1.2516 | 1.2064 | - | 1.2742 |
🔼 This table presents a subjective evaluation comparing the performance of different symbolic music generation methods. Three state-of-the-art methods and the proposed XMusic framework are compared across four categories of music generation (unconditioned, video-conditioned, text-conditioned, and image-conditioned), with human participants rating the generated music samples based on metrics such as richness, correctness, structuredness, emotion matching, and rhythm matching. The average ranking for each method within each category provides a comprehensive comparison of their overall quality and strengths across different generation paradigms.
read the caption
TABLE V: Subjective comparison with state-of-the-art symbolic music generation methods.
| Classes | EMOPIA [11] | XMusic (Ours) |
|---|---|---|
| Positive Valence (PV) | 38% | 76% |
| Negative Valence (NV) | 38% | 70% |
| Positive Arousal (PA) | 39% | 66% |
| Negative Arousal (NA) | 51% | 84% |
🔼 This table presents a subjective comparison of XMusic with the state-of-the-art emotion-conditioned symbolic music generation method, EMOPIA. It shows the percentage of correctly classified music pieces based on four emotion categories: Positive Valence (PV), Negative Valence (NV), Positive Arousal (PA), and Negative Arousal (NA). These categories are derived from a combination of EMOPIA’s emotion quadrants and XMusic’s more granular emotion labels, allowing for a more meaningful comparison despite the difference in granularity.
read the caption
TABLE VI: Subjective comparison with state-of-the-art emotion-conditioned symbolic music generation method.
| Setting | Richness | Correctness | Structuredness | Emotion-Matching | Rhythm-Matching | Overall Rank | |
|---|---|---|---|---|---|---|---|
| (a) Selector | without (✗) Selector | 1.5957 | 1.5878 | 1.5484 | 1.5348 | - | 1.5667 |
| with (✓) Selector | 1.4043 | 1.4122 | 1.4516 | 1.4652 | - | 1.4333 | |
| (b) Emotion Control | No control | 2.2097 | 2.2903 | 2.2000 | 2.3548 | 2.3000 | 2.2710 |
| Music-level | 2.0839 | 2.0065 | 2.2000 | 2.1129 | 2.1484 | 2.1103 | |
| Bar-level | 1.7064 | 1.7032 | 1.6000 | 1.5323 | 1.5516 | 1.6187 | |
| (c) Music Representation | CP [10] | 3.2323 | 3.2942 | 3.7844 | - | - | 3.4370 |
| CP+Tag | 2.8179 | 2.9640 | 2.5991 | - | - | 2.7937 | |
| CP+Tag+Instr | 2.4308 | 2.1195 | 2.1022 | - | - | 2.2175 | |
| CP+Tag+Instr+Rhythm (Ours) | 1.5190 | 1.6223 | 1.5143 | - | - | 1.5519 | |
| (d) Data Sampling | Undersampling | 2.3813 | 2.4746 | 2.1271 | - | - | 2.3277 |
| Oversampling | 2.2069 | 2.0604 | 2.3667 | - | - | 2.2113 | |
| Original XMIDI | 1.4118 | 1.4650 | 1.5062 | - | - | 1.4610 |
🔼 This table presents the results of an ablation study on the XMusic model. It systematically removes or modifies different components of the model to assess their individual contributions to overall performance. Specifically, it examines the impact of the Selector, emotion control level (music-level vs. bar-level), music representation (comparing different token schemes), and data sampling strategies (undersampling and oversampling) on the subjective and objective evaluation metrics. The subjective metrics used include Richness, Correctness, Structuredness, Emotion-Matching, Rhythm-Matching, and Overall Rank, all based on human evaluations. The table provides a detailed quantitative analysis of how each modification affects the performance, allowing for a better understanding of the key components within the XMusic framework.
read the caption
TABLE VII: Ablation analysis.
| Dataset | Method | Richness | Correctness | Structuredness | Overall Rank |
|---|---|---|---|---|---|
| AILabs1k7 [10] | CP [10] | 2.1521 | 2.1053 | 2.0276 | 2.0950 |
| EMOPIA [11] | 2.2567 | 2.2318 | 2.2382 | 2.2422 | |
| XMusic (Ours) | 1.5912 | 1.6629 | 1.7342 | 1.6628 | |
| AILabs1k7 [10] | CP [10] | 2.1016 | 2.0651 | 2.0177 | 2.0615 |
| +EMOPIA [11] | EMOPIA [11] | 2.2607 | 2.1889 | 2.2956 | 2.2484 |
| XMusic (Ours) | 1.6377 | 1.7460 | 1.6867 | 1.6901 |
🔼 Table VIII presents a comparison of the performance of XMusic against state-of-the-art symbolic music generation methods on publicly available datasets. Specifically, it shows a subjective evaluation of the quality of music generated by XMusic compared to CP [10] and EMOPIA [11] across different metrics such as Richness, Correctness, and Structuredness. The evaluation was conducted on two datasets: AILabs1k7 and EMOPIA.
read the caption
TABLE VIII: Comparison with state-of-the-art symbolic music generation methods on public datasets.
| Setting | PCE | GS | EBR |
|---|---|---|---|
| w/o (✗) Selector | 2.5806 | 0.9991 | 0.0097 |
| with (✓) Selector | 2.5083 | 0.9994 | 0.0042 |
🔼 This table presents the results of an ablation study evaluating the impact of the proposed Selector on the overall performance of the XMusic model. It compares the objective metrics (PCE, GS, EBR) achieved by the XMusic model with and without the Selector. This demonstrates the effectiveness of the Selector in enhancing the quality of generated symbolic music.
read the caption
TABLE IX: Objective ablation study on the proposed Selector.
| Classification Head | Accuracy | ||
| Quality | Emotion | Genre | |
| ✓ | ✗ | ✗ | 83.2% |
| ✓ | ✓ | ✗ | 90.1% |
| ✓ | ✓ | ✓ | 94.8% |
🔼 This table presents an ablation study evaluating the impact of the multi-task learning scheme on the Selector component of the XMusic model. It shows how the accuracy of the quality assessment task changes when different combinations of sub-tasks (quality, emotion, and genre recognition) are included in the training process. This demonstrates the contribution of each sub-task to the overall performance of the Selector in identifying high-quality music.
read the caption
TABLE X: Ablation study on the multi-task learning scheme of the Selector.
| (0,1) | (1,0) | (1,1) | (1,2) | (1,3) | (2,1) | (3,1) | |
|---|---|---|---|---|---|---|---|
| Accuracy (%) | 80.2 | 77.9 | 83.7 | 85.2 | 84.8 | 82.5 | 81.7 |
🔼 This table presents the results of an ablation study investigating the impact of different weighting factors (λ1 and λ2) on the accuracy of image emotion recognition. The study varied the weights assigned to two different models used for emotion classification (ResNet and CLIP) in the XProjector component of the XMusic system. The table shows how changes in these weights affect the overall accuracy of image emotion recognition, providing insights into the relative contributions of each model.
read the caption
TABLE XI: Ablation analysis on the weighting factors λ1subscript𝜆1\lambda_{1}italic_λ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and λ2subscript𝜆2\lambda_{2}italic_λ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT of image emotion recognition task.
Full paper#














