TL;DR#
Current multi-modal document retrieval benchmarks suffer from issues like poor question quality, incomplete documents, and limited retrieval granularity. These shortcomings hinder accurate evaluation and progress in this important area.
To address this, the researchers introduce MMDocIR, a new benchmark dataset with two key tasks: page-level and layout-level retrieval. MMDocIR features 313 long documents across 10 diverse domains, along with 1685 expertly-annotated questions. The results show that visual-based methods generally outperform text-based methods. This benchmark significantly improves multi-modal document retrieval evaluation and guides future research directions.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for robust benchmarks in multi-modal document retrieval. Existing benchmarks are insufficient, hindering effective evaluation of systems. MMDocIR provides a comprehensive, expertly annotated dataset, advancing the field and enabling more accurate comparisons of retrieval methods. This opens avenues for future research in multi-modal understanding and retrieval techniques, impacting various applications.
Visual Insights#

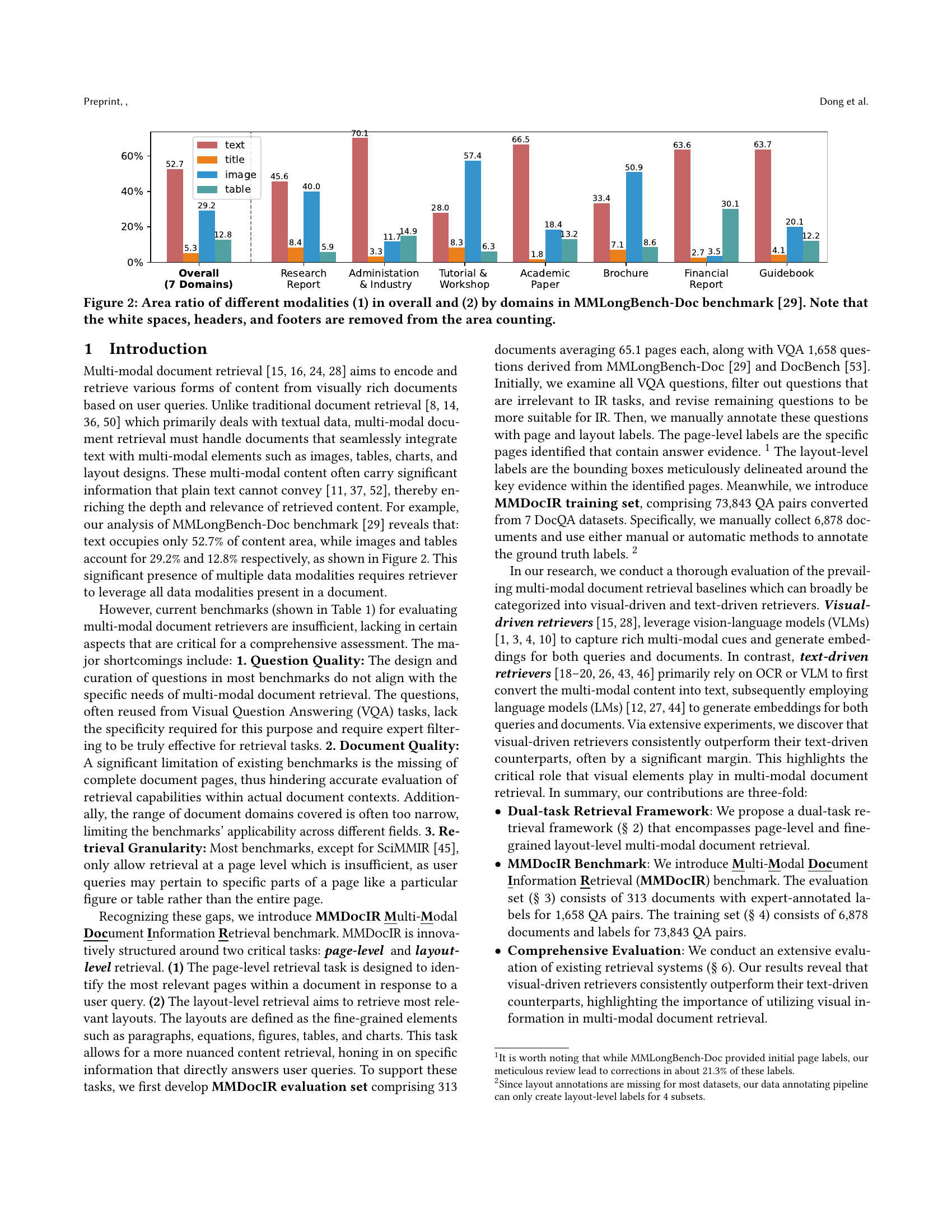
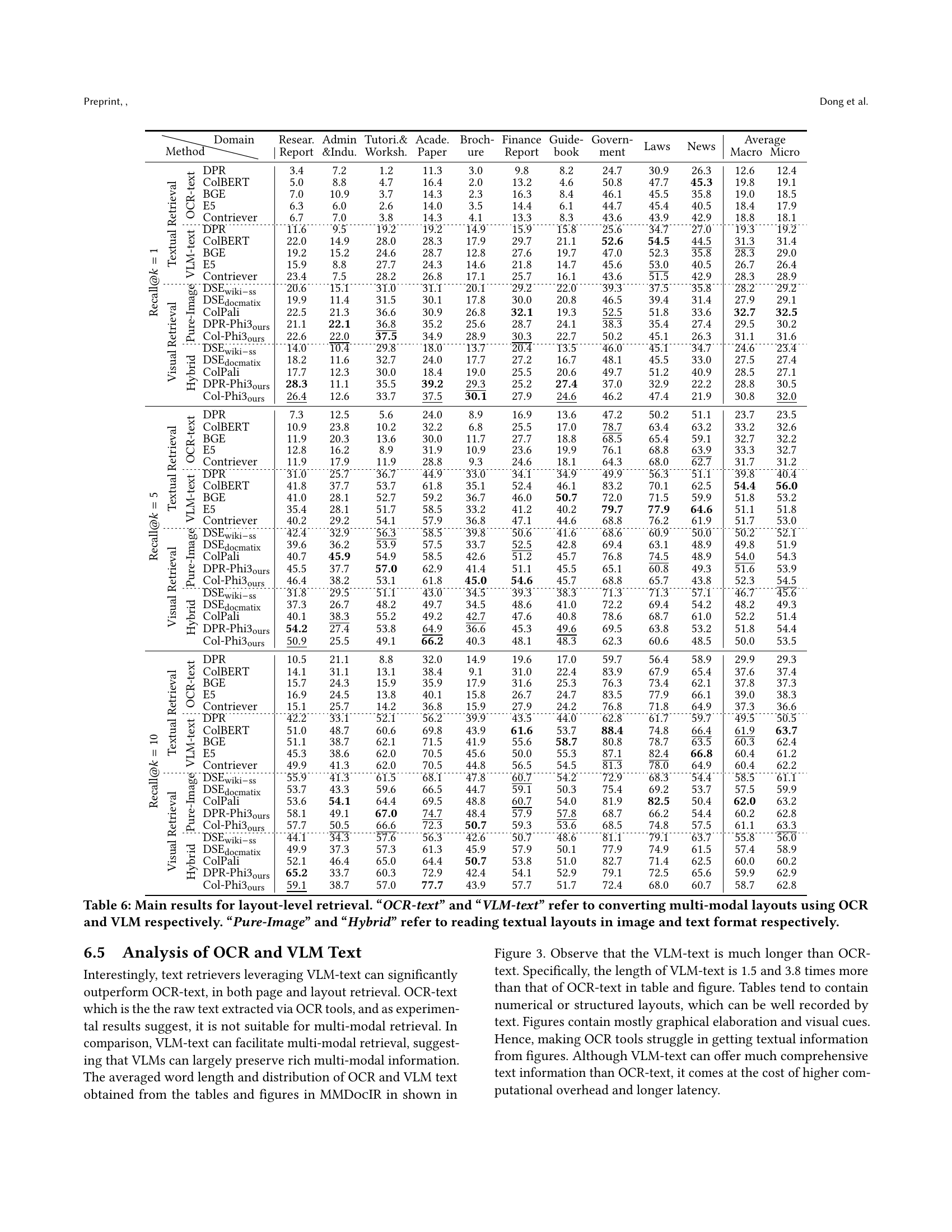
🔼 This figure illustrates the MMDocIR dataset, which includes 313 long documents spanning 10 diverse domains and a total of 1,685 associated questions. Each question is meticulously annotated at the page level, using selected screenshots to indicate the relevant page. Furthermore, the figure highlights layout-level annotations, represented by red boundary boxes, signifying more precise pinpointings of information within each page compared to simple page-level annotations. This detailed annotation makes MMDocIR a robust benchmark for evaluating multi-modal document retrieval systems.
read the caption
Figure 1. MMDocIR comprises 313 lengthy documents across 10 different domains, along with 1,685 questions. For each question, page-level annotations are provided via selected screenshots. Red boundary boxes represent layout-level annotations.
| Benchmarks | Question | Document | Label | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Type | By Expert? | For IR? | #Num | Evidence Type | Domain | #Pages | Source | Page | Layout | |
| DocCVQA (Tito et al., 2021) | VQA question | ✓ | ✓ | 20 | TXT/L | Finance | 1.0 | ✓ | ✓ | ✗ |
| SciMMIR (Wu et al., 2024) | Image caption | ✗ | ✗ | 530K | TAB/I | Science | 1.0 | ✗ | ✗ | ✗ |
| ViDoRe (Faysse et al., 2024) | VQA question | ✗ | 3,810 | TXT/C/TAB/I | Multi-domain | 1.0 | ✗ | ✓ | ✗ | |
| PDF-MVQA (Ding et al., 2024) | Search query | ✗ | ✓ | 260k | TXT/TAB/I | Biomedical | 9.6 | ✓ | ✓ | ✓ |
| MMLongBench-Doc (Ma et al., 2024b) | VQA question | ✓ | ✗ | 1,082 | TXT/L/C/TAB/I | Multi-domain | 47.5 | ✓ | ✓ | ✗ |
| Wiki-SS (Ma et al., 2024a) | Natural question | ✗ | ✓ | 3,610 | TXT | Wikipedia | 1.0 | ✗ | ✓ | ✗ |
| DocMatix-IR (Ma et al., 2024a) | VQA question | ✗ | ✗ | 5.61M | TXT/L/C/TAB/I | Multi-domain | 4.2 | ✓ | ✓ | ✗ |
| MMDocIR | VQA question | ✓ | ✓ | 1,658 | TXT/C/TAB/I | Multi-domain | 65.1 | ✓ | ✓ | ✓ |
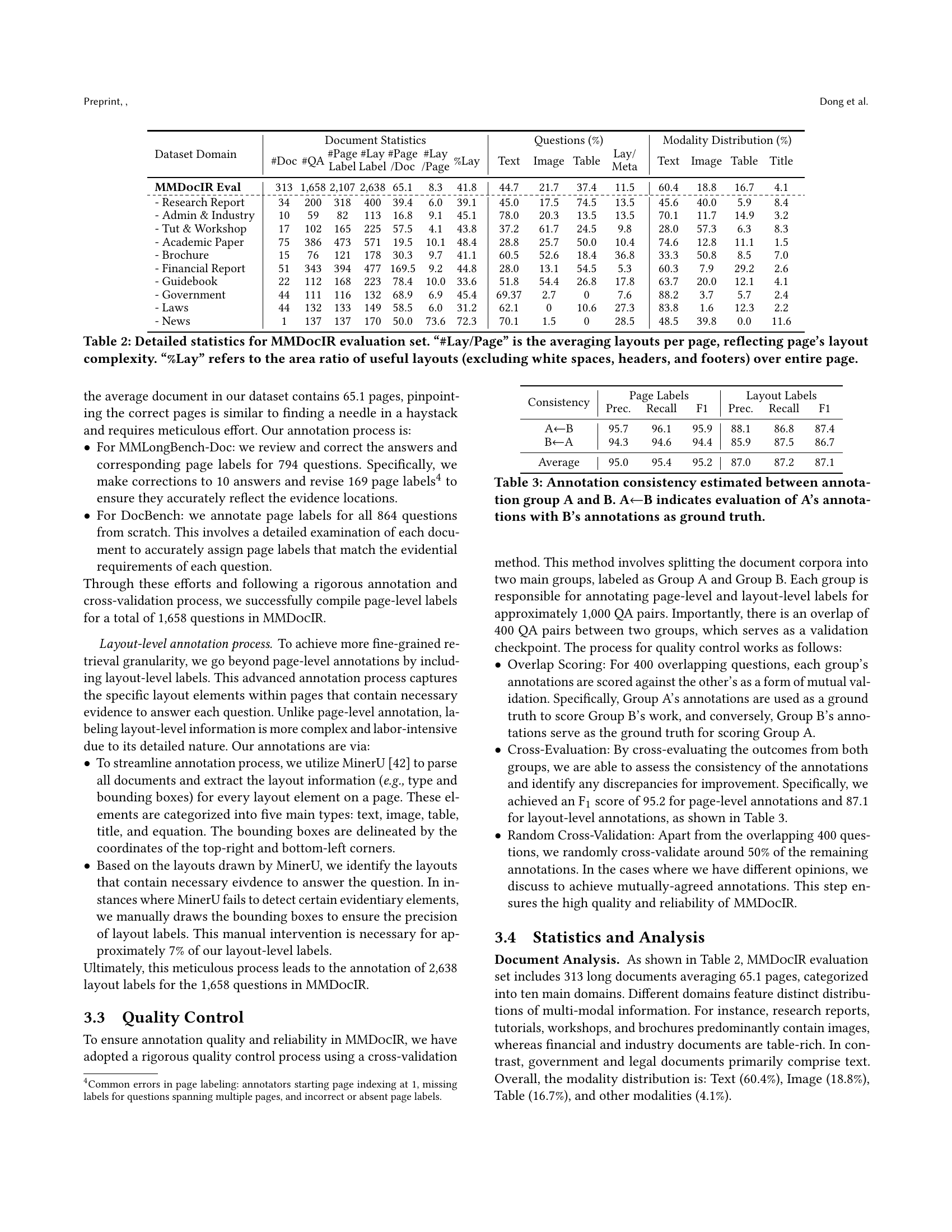
🔼 This table compares the MMDocIR benchmark with other existing document information retrieval datasets. For each dataset, it lists the type of questions used, whether those questions were created by experts or automatically generated, whether the questions were specifically designed for IR tasks, the number of questions in each dataset, the types of evidence included (pure text, generalized layout, chart, table, image), the document domains covered, the average number of pages per document, and whether the datasets contain annotations for page-level and layout-level retrieval. The abbreviations TXT/L/C/TAB/I represent pure text, generalized layout, chart, table, and image, respectively.
read the caption
Table 1. Comparison between our benchmark and previous Document IR datasets. TXT/L/C/TAB/I: pure text/generalized layout/chart/table/image.
In-depth insights#
MMDocIR Benchmark#
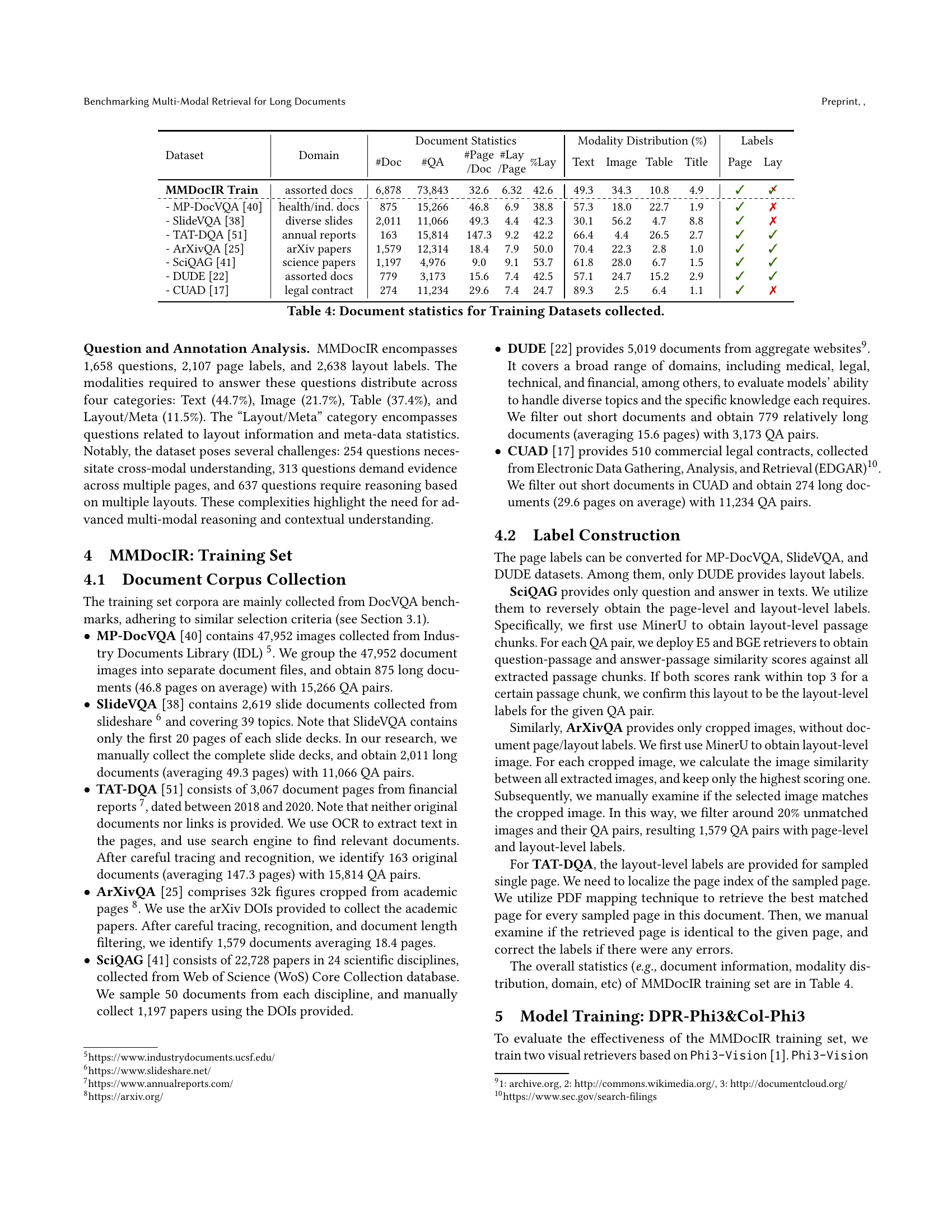
The MMDocIR benchmark represents a significant contribution to the field of multi-modal document retrieval by addressing the critical need for a robust evaluation framework. Its innovative dual-task design, encompassing both page-level and layout-level retrieval, allows for a more comprehensive assessment of system performance than previously possible. The benchmark’s rich dataset, including expertly annotated labels for over 1,600 questions and bootstrapped labels for many more, provides a substantial resource for training and evaluating retrieval models. The inclusion of diverse document types and domains strengthens its generalizability and practical relevance. However, the relatively small size of the expertly annotated portion may limit its effectiveness in capturing the full range of challenges in multi-modal retrieval tasks. Future work could explore expanding the dataset to include more documents and diverse query types to further enhance its robustness and utility in advancing the state-of-the-art in multi-modal information retrieval.
Dual-Task Retrieval#
The concept of ‘Dual-Task Retrieval’ in the context of multi-modal document retrieval presents a significant advancement. It cleverly addresses the limitations of existing benchmarks by introducing two distinct yet interconnected retrieval tasks: page-level and layout-level retrieval. This dual approach offers a more granular and nuanced evaluation compared to traditional page-level-only methods. Page-level retrieval focuses on identifying the most relevant pages within a lengthy document, while layout-level retrieval further refines this by targeting specific layouts (paragraphs, figures, tables, etc.) within those pages. This two-pronged approach is crucial because users often seek specific information within a document, not just the overall most relevant page. The integration of these tasks within a single benchmark allows for a more comprehensive assessment of multi-modal retrieval systems, revealing their strengths and weaknesses in both broad and fine-grained retrieval scenarios. The dual-task methodology provides a more realistic and user-centric evaluation framework, advancing the field significantly beyond simpler, less sophisticated approaches.
Visual Retrieval Wins#
The assertion that “Visual Retrieval Wins” in multi-modal document retrieval is supported by the research paper’s findings. Visual-driven methods consistently outperformed text-driven approaches, indicating the significant advantage of leveraging visual information. This superiority holds across various domains and evaluation metrics, highlighting the importance of visual cues in understanding document content. The study reveals that even when text-based methods utilize powerful vision-language models (VLMs) for text generation, they still fail to match the performance of visual-driven models that directly process images. This suggests that directly incorporating visual data is crucial and that simply transforming visual elements into text loses valuable contextual information. The effectiveness of visual methods underscores the limitations of relying solely on OCR or text-based representations of multi-modal documents. The paper’s comprehensive evaluation strengthens the conclusion that visual information plays a pivotal role in effectively retrieving relevant content from complex documents.
VLM-Text Advantage#
The concept of ‘VLM-Text Advantage’ highlights the superior performance of models using Vision-Language Models (VLMs) to process text extracted from visual elements within documents, compared to traditional Optical Character Recognition (OCR) methods. VLMs offer a richer, more nuanced understanding of textual data embedded within images and layouts, going beyond simple character recognition. This advantage is crucial in multi-modal document retrieval because it allows for capturing contextual information that’s often lost during OCR. This is especially true for complex documents with a high degree of visual integration, as VLMs can interpret the layout, formatting and visual cues alongside text, leading to more accurate retrieval results. The improvement suggests that combining visual and textual analysis offers a more robust method of extracting meaningful information from documents, and directly benefits applications requiring comprehension of visually-rich content. Future research should investigate VLM’s capability to handle diverse visual elements, including tables and charts, more efficiently. Optimizations to VLM processes, addressing computational costs and latency, will further enhance the practical benefits of this approach.
Future Directions#
Future research in multi-modal document retrieval should focus on several key areas. Improving the robustness and efficiency of visual-based retrieval methods is crucial, especially for handling high-resolution images and complex layouts. This could involve exploring more efficient visual embedding techniques, such as those that leverage sparse representations or attention mechanisms. Addressing the challenges of cross-modal information fusion remains essential; developing sophisticated models capable of seamlessly integrating textual and visual cues, and handling the inherent heterogeneity of information formats is vital. Developing more sophisticated evaluation metrics that account for the nuances of long documents and multi-modal data are also needed. Current benchmarks are often limited, and improvements would facilitate more accurate assessment of retrieval performance. Finally, expanding existing benchmarks and datasets to include a wider range of document types and domains would be highly beneficial, as would the incorporation of more diverse and complex question types in evaluating system performance. The development of effective and reliable techniques for handling noisy or incomplete multi-modal data will also be crucial for improving the scalability and practicality of multi-modal document retrieval.
More visual insights#
More on figures

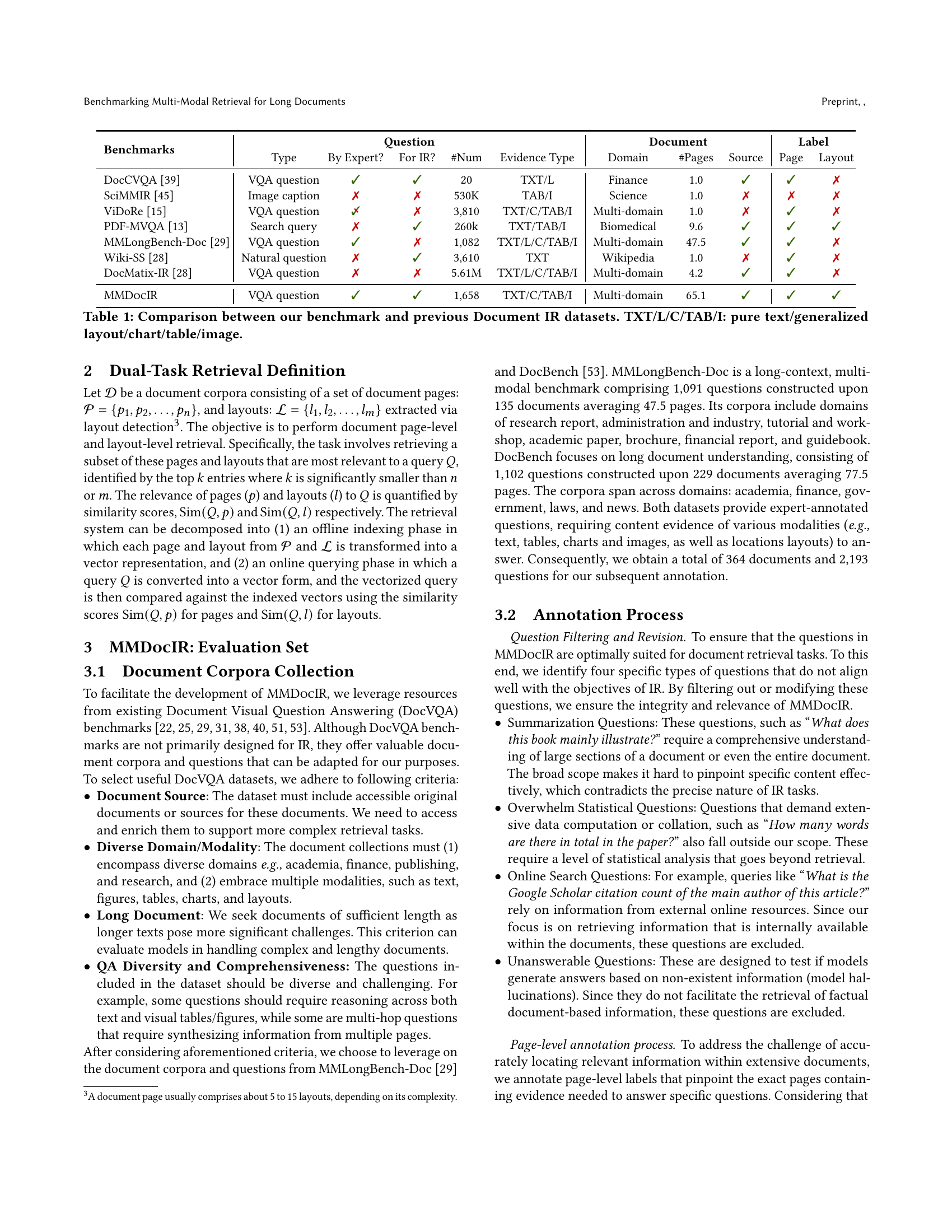
🔼 This figure shows a comparison of the area occupied by different modalities (text, images, tables) within documents from the MMLongBench-Doc benchmark. The first bar chart presents the overall distribution across all document types in the benchmark. The subsequent bar charts break down this area distribution for each individual document domain (Research Report, Administration & Industry, etc.) included in the MMLongBench-Doc dataset. This visualization highlights the prevalence of non-textual content (images and tables) in many document types and the variability across different domains. Note that the calculations exclude white spaces, headers, and footers to focus on the actual content area.
read the caption
Figure 2. Area ratio of different modalities (1) in overall and (2) by domains in MMLongBench-Doc benchmark (Ma et al., 2024b). Note that the white spaces, headers, and footers are removed from the area counting.
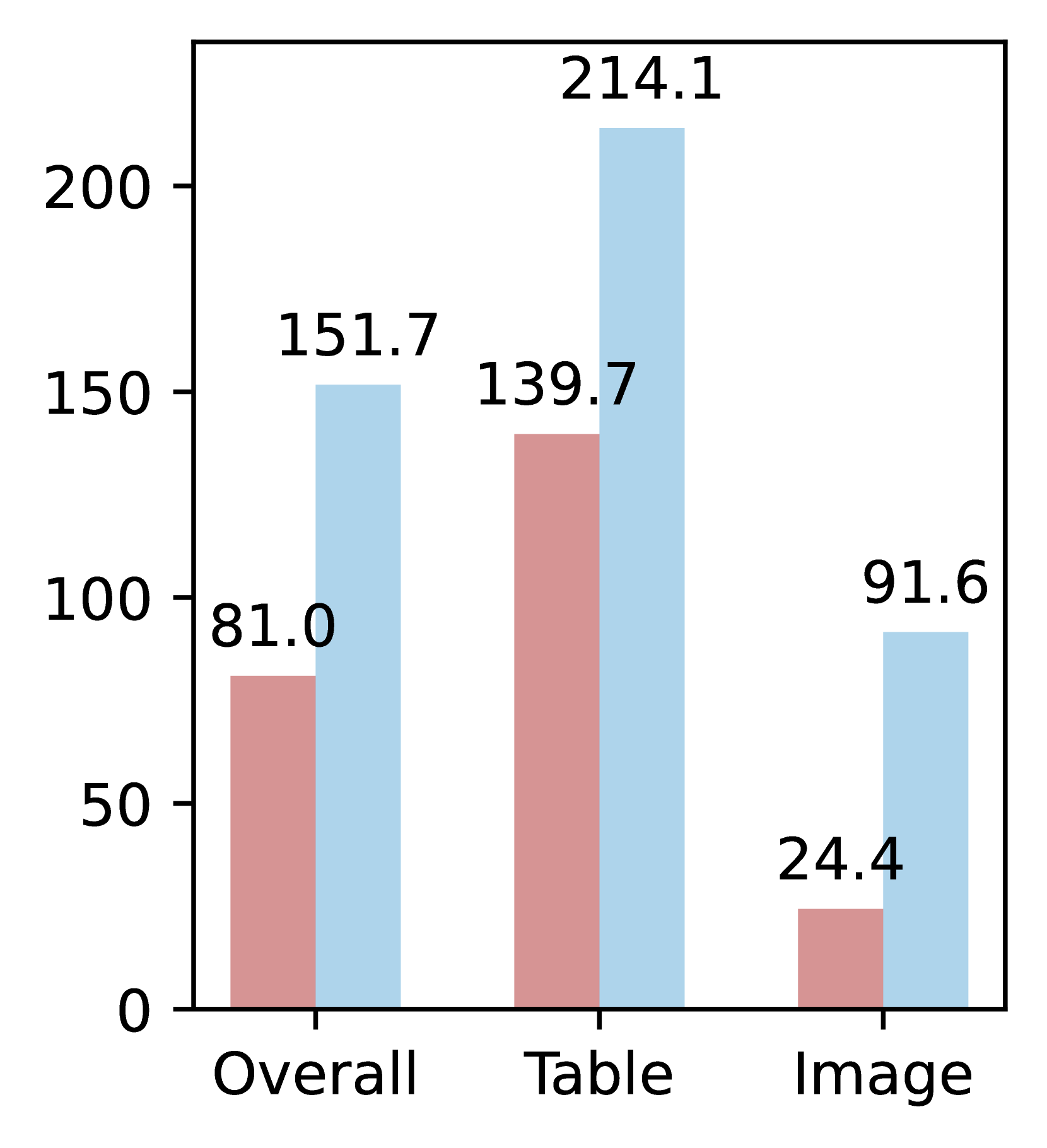
🔼 This figure presents a comparative analysis of the average word length and word length distribution for OCR-extracted text and VLM-generated text from tables and figures within the MMDocIR dataset. The subfigure (a) shows a bar chart comparing the average word length for OCR text versus VLM text in tables and images separately. Subfigure (b) displays the distribution of word lengths as histograms for both OCR and VLM text in tables and images.
read the caption
(a) Avg word length

🔼 The figure shows the distribution density of word lengths for OCR and VLM texts extracted from tables and images within the MMDocIR dataset. It illustrates the difference in word length characteristics between the raw text from OCR and the more descriptive text generated by a Vision Language Model (VLM). The VLM text is considerably longer than the OCR text, especially for images.
read the caption
(b) Distribution density of word length
Full paper#