TL;DR#
Generating realistic 4D city models is challenging due to the complexity of urban environments, requiring the handling of diverse objects and their interactions. Existing methods often struggle with temporal consistency, scalability, or the ability to model dynamic elements such as traffic. They also lack the availability of high-quality, large-scale datasets for training and evaluation.
CityDreamer4D tackles these challenges by employing a compositional approach, separating dynamic and static elements. It utilizes a compact Bird’s-Eye-View (BEV) representation for city layouts and traffic simulations. Multiple neural fields are used to represent different object types, improving realism and ensuring temporal consistency. The model supports unbounded scenes and offers various downstream applications. Moreover, the research introduces a suite of comprehensive datasets, including OSM data, Google Earth imagery, and CityTopia, a high-quality synthetic dataset that facilitates training and evaluation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents CityDreamer4D, a novel approach to generating realistic and unbounded 4D city models. This addresses a significant challenge in computer graphics and related fields, paving the way for advancements in urban planning, game development, and metaverse applications. The introduction of comprehensive datasets and the ability to handle dynamic elements such as traffic further enhance the practical value and broad applicability of this research. The compositional nature of the model enables flexible manipulation and editing, opening exciting new avenues for future research in generative models and urban simulation.
Visual Insights#

🔼 CityDreamer4D is a framework for generating unbounded 4D cities by separating static and dynamic elements. Static elements (city layout) are generated using the Unbounded Layout Generator, while dynamic elements (traffic) are created using the Traffic Scenario Generator. The City Background Generator renders background elements like sky, roads, and vegetation. Building Instance Generators produce building images, and Vehicle Instance Generators create vehicle images. These are then combined by the Compositor to form a final 4D city image. The caption also lists abbreviations used in the figure.
read the caption
Figure 1: Overview of CityDreamer4D. 4D city generation is divided into static and dynamic scene generation, conditioned on 𝐋𝐋\mathbf{L}bold_L and 𝐓tsubscript𝐓𝑡\mathbf{T}_{t}bold_T start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT, produced by Unbounded Layout Generator and Traffic Scenario Generator, respectively. City Background Generator uses 𝐋𝐋\mathbf{L}bold_L to create background images 𝐈^Gsubscript^𝐈𝐺\mathbf{\hat{I}}_{G}over^ start_ARG bold_I end_ARG start_POSTSUBSCRIPT italic_G end_POSTSUBSCRIPT for stuff like roads, vegetation, and the sky, while Building Instance Generator renders the buildings {𝐈^Bi}subscript^𝐈subscript𝐵𝑖\{\mathbf{\hat{I}}_{B_{i}}\}{ over^ start_ARG bold_I end_ARG start_POSTSUBSCRIPT italic_B start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT } within the city. Using 𝐓tsubscript𝐓𝑡\mathbf{T}_{t}bold_T start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT, Vehicle Instance Generator generates vehicles {𝐈^Vit}superscriptsubscript^𝐈subscript𝑉𝑖𝑡\{\mathbf{\hat{I}}_{V_{i}}^{t}\}{ over^ start_ARG bold_I end_ARG start_POSTSUBSCRIPT italic_V start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT } at time step t𝑡titalic_t. Finally, Compositor combines the rendered background, buildings, and vehicles into a unified and coherent image 𝐈^Ctsuperscriptsubscript^𝐈𝐶𝑡\mathbf{\hat{I}}_{C}^{t}over^ start_ARG bold_I end_ARG start_POSTSUBSCRIPT italic_C end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT. “Gen.”, “Mod.“, “Cond.”, “BG.”, “BLDG.”, and “VEH.” denote “Generation”, “Modulation”, “Condition”, “Background”, “Building”, and “Vehicle”, respectively.
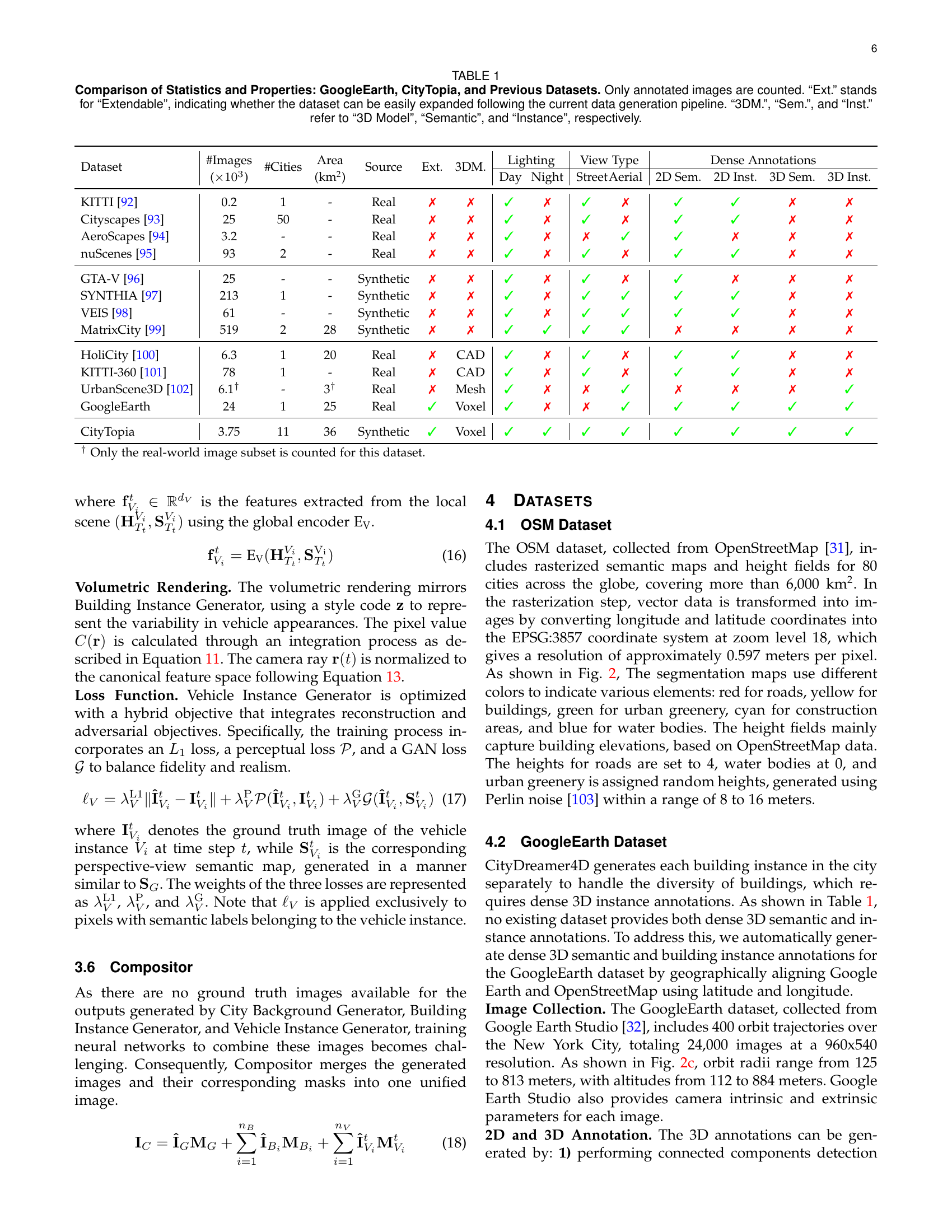
| Dataset | #Images | #Cities | Area | Source | Ext. | 3DM. | Lighting | View Type | Dense Annotations | |||||
| () | (km2) | Day | Night | Street | Aerial | 2D Sem. | 2D Inst. | 3D Sem. | 3D Inst. | |||||
| KITTI [92] | 0.2 | 1 | - | Real | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ |
| Cityscapes [93] | 25 | 50 | - | Real | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ |
| AeroScapes [94] | 3.2 | - | - | Real | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| nuScenes [95] | 93 | 2 | - | Real | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ |
| GTA-V [96] | 25 | - | - | Synthetic | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| SYNTHIA [97] | 213 | 1 | - | Synthetic | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| VEIS [98] | 61 | - | - | Synthetic | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| MatrixCity [99] | 519 | 2 | 28 | Synthetic | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| HoliCity [100] | 6.3 | 1 | 20 | Real | ✗ | CAD | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ |
| KITTI-360 [101] | 78 | 1 | - | Real | ✗ | CAD | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ |
| UrbanScene3D [102] | 6.1† | - | 3† | Real | ✗ | Mesh | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ |
| GoogleEarth | 24 | 1 | 25 | Real | ✓ | Voxel | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CityTopia | 3.75 | 11 | 36 | Synthetic | ✓ | Voxel | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| † Only the real-world image subset is counted for this dataset. | ||||||||||||||
🔼 This table compares the GoogleEarth and CityTopia datasets with several other publicly available datasets used for urban scene understanding. It details the number of images, cities, and the total area covered by each dataset. It also indicates whether the dataset is from real-world sources or synthetically generated. Further, it notes the type of lighting conditions present (daytime and/or nighttime), the viewpoints available (street and/or aerial), and the types of annotations included (2D and 3D semantic, and 2D and 3D instance). Finally, it specifies whether the dataset can be easily expanded upon using the current data generation method and what type of 3D model representations (if any) are included.
read the caption
TABLE I: Comparison of Statistics and Properties: GoogleEarth, CityTopia, and Previous Datasets. Only annotated images are counted. “Ext.” stands for “Extendable”, indicating whether the dataset can be easily expanded following the current data generation pipeline. “3DM.”, “Sem.”, and “Inst.” refer to “3D Model”, “Semantic”, and “Instance”, respectively.
In-depth insights#
Unbounded 4D CityGen#
Unbounded 4D CityGen presents a significant advance in virtual world creation. The focus on unboundedness directly addresses limitations of existing methods, which often generate small, finite environments. Generating 4D (spatiotemporal) data instead of just static 3D scenes is a key innovation, enabling more realistic and dynamic simulations of urban life. The compositional approach, separating static elements (buildings, roads) from dynamic ones (vehicles, traffic), is crucial for efficient generation and manipulation of complex city models. Utilizing neural fields for diverse object types ensures detailed and varied rendering. The integration of real-world data, such as OpenStreetMap and Google Earth imagery, is essential for creating believable and realistic results. Datasets created are significant contributions, providing valuable resources for future research in urban simulation and generative AI. Challenges remain in achieving perfect temporal consistency and handling global illumination, particularly for nighttime scenes, but this research provides a strong foundation for future development in this field.
Neural Field Fusion#
A hypothetical “Neural Field Fusion” section in a 4D city generation paper would likely explore methods for combining multiple neural fields to create a cohesive and realistic scene. Different neural fields could specialize in representing various aspects of the city, such as buildings, vehicles, and background elements. The fusion process would need to address challenges like consistent rendering across different field types, handling occlusions and interactions between objects from separate fields, and ensuring temporal coherence in 4D sequences. Techniques such as weighted averaging, concatenation, or more sophisticated attention mechanisms might be employed to achieve seamless integration. The success of this approach hinges on carefully designing the scene representation and parameterization to facilitate efficient and effective fusion, while balancing realism with computational efficiency. Furthermore, the choice of neural field architecture (e.g., MLP, convolutional) would have a significant impact on the quality of the fusion results. Evaluation would focus on metrics like visual fidelity, temporal consistency, and the ability to generate diverse and unbounded urban scenes.
Traffic Scenario Gen#
The heading ‘Traffic Scenario Gen’ suggests a system designed to generate realistic and dynamic traffic scenarios within a simulated environment, likely for urban settings. This is crucial for creating believable and engaging 4D city models, as static scenes lack the liveliness of real-world urban environments. The generation process likely involves several key steps: defining road networks (potentially from existing map data like OpenStreetMap), determining vehicle types and numbers, and simulating their movement according to realistic rules (e.g., respecting traffic laws, reacting to other vehicles and traffic signals). Sophisticated algorithms are needed to model vehicle behavior, potentially employing techniques from traffic flow simulations or reinforcement learning. The system would also need to consider factors like time of day, weather conditions, and special events that could affect traffic patterns. The output would be a representation of traffic flow, providing data such as vehicle positions and trajectories over time. The quality of this ‘Traffic Scenario Gen’ would directly impact the realism and user experience of the resulting 4D city, making it a pivotal component of the overall system.
Dataset Contributions#
The research paper’s contribution in creating diverse and high-quality datasets is a significant aspect. The authors emphasize the importance of comprehensive datasets for training robust 4D city generation models. They highlight three main datasets: OSM, Google Earth, and CityTopia. OSM provides realistic city layouts, useful for generating the structural foundations of a city. Google Earth offers real-world, high-resolution city imagery, but lacks the dense 3D instance annotations crucial for training instance-level generative models. Therefore, CityTopia, a synthetic dataset, is created to address this need, providing high-quality images with detailed 3D semantic and instance annotations, allowing for more precise training of the generative models. This multi-faceted approach addresses limitations in existing datasets and facilitates a more effective training process, ultimately improving the realism and diversity of generated 4D cities. The effort invested in data curation, especially 3D annotation, is a key strength of the work.
CityDreamer4D Limits#
CityDreamer4D, while groundbreaking, has limitations. Computational cost is a concern, stemming from generating buildings and vehicles individually. Global illumination and reflections are not fully addressed, impacting realism, especially in night scenes. The model’s reliance on pre-trained models for specific object types limits flexibility. Data limitations in the training datasets, particularly regarding varied lighting conditions and diverse urban scenarios, might also restrict generalization. Further research could explore more efficient architectures, improved scene parameterization, and enhanced datasets to overcome these limitations and enhance the model’s capabilities in generating realistic and unbounded 4D cities. Addressing these shortcomings would significantly improve the model’s overall performance and usability.
More visual insights#
More on figures

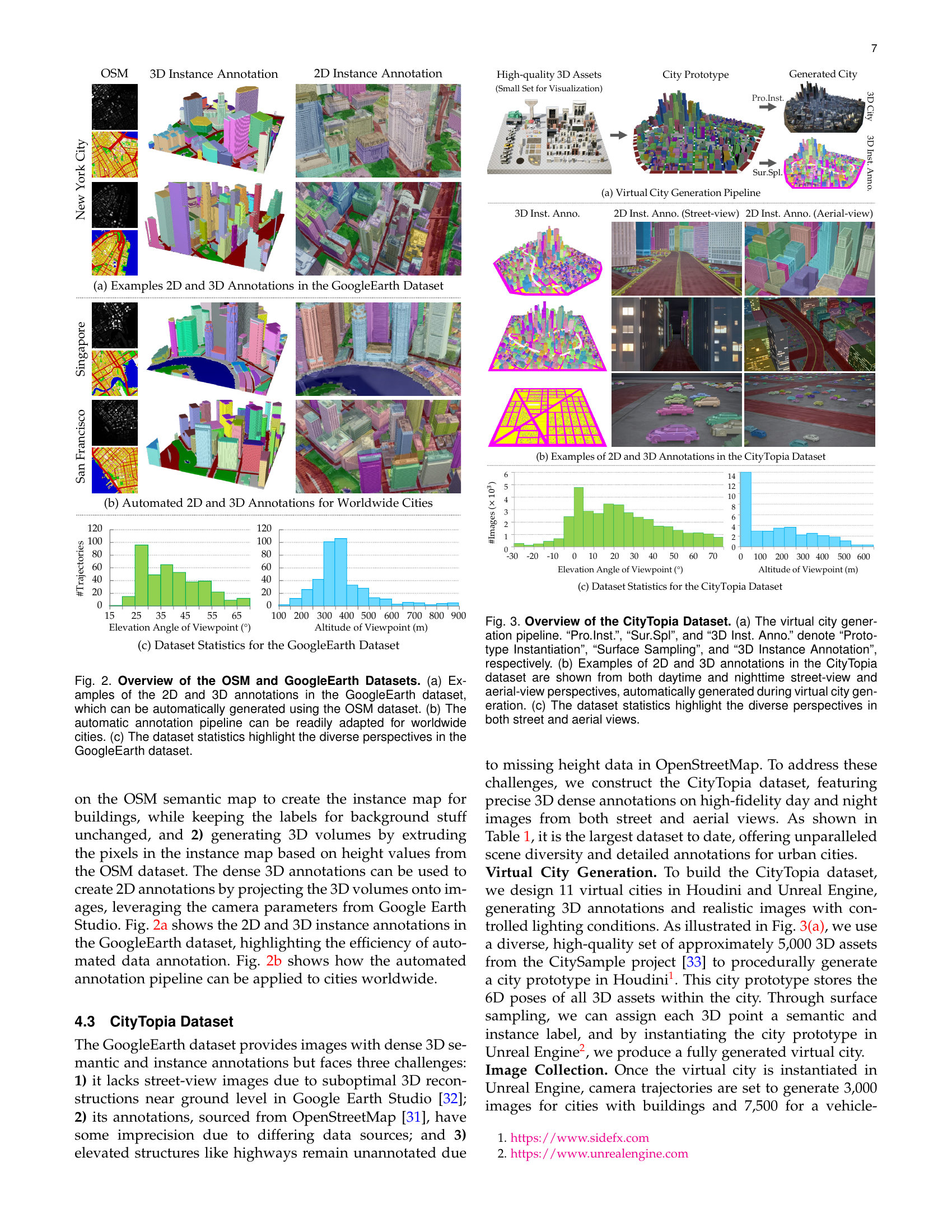
🔼 Figure 2 provides a detailed look into the OSM and Google Earth datasets used in the CityDreamer4D project. Part (a) showcases examples of 2D and 3D annotations within the Google Earth dataset, demonstrating how these annotations can be automatically derived from the OSM data. Part (b) illustrates the adaptability of the automated annotation pipeline for global city application. Finally, part (c) presents statistical analyses of the Google Earth dataset, highlighting the diversity of viewpoints (drone altitudes and angles) it offers.
read the caption
Figure 2: Overview of the OSM and GoogleEarth Datasets. (a) Examples of the 2D and 3D annotations in the GoogleEarth dataset, which can be automatically generated using the OSM dataset. (b) The automatic annotation pipeline can be readily adapted for worldwide cities. (c) The dataset statistics highlight the diverse perspectives in the GoogleEarth dataset.

🔼 Figure 3 provides a comprehensive overview of the CityTopia dataset, a key contribution of the paper. Part (a) details the virtual city generation pipeline, outlining the stages of Prototype Instantiation, Surface Sampling, and 3D Instance Annotation. Part (b) showcases examples of the high-quality 2D and 3D annotations within the dataset, highlighting the diversity of viewpoints (daytime/nighttime, street-view/aerial-view) and the automated generation process. Finally, part (c) presents statistical analysis of the dataset, emphasizing the variation in viewpoints obtained through elevation and altitude parameters, showcasing the rich diversity of perspectives included in CityTopia.
read the caption
Figure 3: Overview of the CityTopia Dataset. (a) The virtual city generation pipeline. “Pro.Inst.”, “Sur.Spl”, and “3D Inst. Anno.” denote “Prototype Instantiation”, “Surface Sampling”, and “3D Instance Annotation”, respectively. (b) Examples of 2D and 3D annotations in the CityTopia dataset are shown from both daytime and nighttime street-view and aerial-view perspectives, automatically generated during virtual city generation. (c) The dataset statistics highlight the diverse perspectives in both street and aerial views.

🔼 This figure provides a qualitative comparison of different 3D and 4D city generation models on the Google Earth dataset. The models compared are SceneDreamer, CityDreamer4D, DimensionX, InfiniCity, and PersistentNature. Because the Google Earth dataset lacks semantic annotations for vehicles, CityDreamer4D and SceneDreamer use models trained on the CityTopia dataset for vehicle generation. DimensionX uses an initial frame provided by CityDreamer4D. The InfiniCity results, provided by the paper’s authors, are zoomed in for better visualization. The comparison demonstrates CityDreamer4D’s superior ability to generate realistic and detailed 4D cities.
read the caption
Figure 4: Qualitative Comparison on Google Earth. For SceneDreamer [7] and CityDreamer4D, vehicles are generated using models trained on CityTopia due to the lack of semantic annotations for vehicles in Google Earth. For DimensionX [107], the initial frame is provided by CityDreamer4D. The visual results of InfiniCity [26], provided by the authors, have been zoomed in for better viewing. “Pers.Nature” stands for “PersistentNature” [105].

🔼 Figure 5 presents a qualitative comparison of CityDreamer4D’s 4D city generation capabilities against several state-of-the-art methods on the CityTopia dataset. The comparison includes SGAM, PersistentNature, SceneDreamer, DreamScene4D, and DimensionX. For methods requiring initial frames or video inputs, these were selected from the CityTopia dataset. The figure visually showcases the generated city sequences from each method, allowing for a direct comparison of their visual realism, scene consistency, and overall quality in generating 4D urban scenes.
read the caption
Figure 5: Qualitative Comparison on CityTopia. The initial frame for DimensionX and the input frames for DreamScene4D are chosen from the dataset. “Pers.Nature” refers to “PersistentNature” [105].

🔼 This figure presents the results of a user study comparing the performance of different methods for generating 4D city models, including CityDreamer4D, SceneDreamer, PersistentNature, InfiniCity, DimensionX, and SGAM. Users rated each method on a scale of 1 to 5 across three key dimensions: perceptual quality, 4D realism, and view consistency. Higher scores indicate better performance. The figure clearly shows that CityDreamer4D outperforms all other methods across all three evaluation criteria.
read the caption
Figure 6: User Study on 4D City Generation. All scores are in the range of 5, with 5 indicating the best. “Pers.Nature” refers to “PersistentNature” [105].

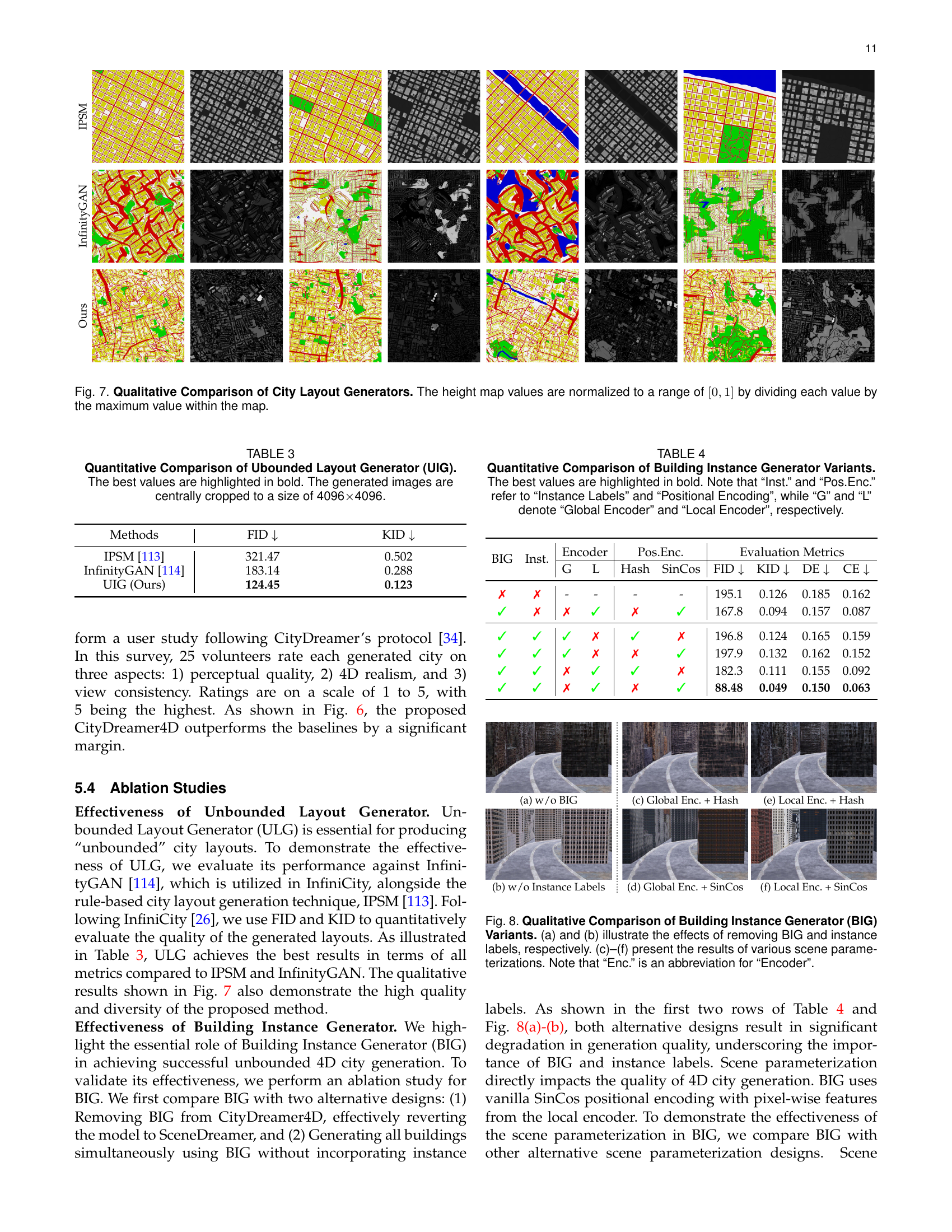
🔼 Figure 7 presents a qualitative comparison of three different city layout generators: the proposed method, InfinityGAN, and IPSM. The figure visually compares the generated height maps produced by each method. Height map values are normalized to a range of 0 to 1 for consistent comparison across methods. This allows for easier visual assessment of the similarities and differences in generated city layouts by the three approaches, including texture and shape.
read the caption
Figure 7: Qualitative Comparison of City Layout Generators. The height map values are normalized to a range of [0,1]01[0,1][ 0 , 1 ] by dividing each value by the maximum value within the map.

🔼 This figure compares different variations of the Building Instance Generator (BIG) within the CityDreamer4D model. The top row shows the impact of removing the BIG module entirely (a) and the impact of removing instance labels while retaining the BIG module (b). The significant drop in image quality highlights the importance of both the BIG module and the use of instance labels. The bottom row (c-f) explores the effects of different scene parameterizations within the BIG. Specifically, it compares different encoder types (global vs. local) and different positional encoding methods (hash grids vs. sinusoidal). These experiments demonstrate how the chosen parameterization strategy impacts the realism and fidelity of the generated building images.
read the caption
Figure 8: Qualitative Comparison of Building Instance Generator (BIG) Variants. (a) and (b) illustrate the effects of removing BIG and instance labels, respectively. (c)–(f) present the results of various scene parameterizations. Note that “Enc.” is an abbreviation for “Encoder”.

🔼 This figure compares different configurations of the Vehicle Instance Generator (VIG) within the CityDreamer4D model. (a) and (b) show the impact of removing VIG entirely and removing the canonicalization process, respectively. The remaining subfigures (c) through (f) explore the effects of different scene parameterization strategies. These variations involve using different encoders (global vs. local) combined with different positional encoding techniques (hash grids vs. sinusoidal functions). The goal is to demonstrate the impact of each component on the quality of generated vehicle instances within the simulated city scenes.
read the caption
Figure 9: Qualitative Comparison of Vehicle Instance Generator (VIG) Variants. (a) and (b) illustrate the effects of removing VIG and canonicalization, respectively. (c)–(f) present the results of various scene parameterizations. Note that “Enc.” is an abbreviation for “Encoder”.

🔼 This figure showcases the localized editing capabilities of the CityDreamer4D model. Panels (a) and (c) demonstrate modifications to vehicles within the generated city scenes, illustrating changes such as vehicle type and placement. Panels (b) and (d) exhibit similar localized editing applied to buildings, showing adjustments to building height and style. These examples highlight the model’s ability to make precise, localized alterations without affecting the overall scene coherence.
read the caption
Figure 10: Localized Editing on the Generated Cities. (a) and (c) show vehicle editing results, while (b) and (d) present building editing results.

🔼 This figure showcases the results of applying ControlNet to stylize generated cityscapes. ControlNet allows for directing the style of the generated image while preserving multi-view consistency; even when changing the style significantly, the structural integrity of the scene remains consistent across different viewpoints. The example shown demonstrates successful stylization of generated cities to resemble the visual styles of Minecraft and Cyberpunk.
read the caption
Figure 11: Text-driven City Stylization with ControlNet. The multi-view consistency is preserved in stylized Minecraft and Cyberpunk cities.

🔼 This figure displays the results of a 3D reconstruction performed using COLMAP on a sequence of 600 orbital videos generated by CityDreamer4D. The videos were captured from a circular trajectory around a scene, and the red ring in the image highlights the estimated camera positions during the video recording. The clarity and density of the resulting point cloud illustrate the high quality and consistency of CityDreamer4D’s rendering across the entire sequence of frames.
read the caption
Figure 12: COLMAP Reconstruction of 600-frame Orbital Videos. The red ring shows the camera positions, and the clear point clouds demonstrate CityDreamer4D’s consistent rendering. Note that ”Recon.” stands for ”Reconstruction.”

🔼 This figure demonstrates the relighting effect achieved in CityDreamer4D. It showcases three images: (a) shows the lighting intensity based on Lambertian shading, which provides uniform lighting across all directions; (b) shows the lighting intensity based on shadow mapping, which accounts for light visibility and occlusion; (c) combines both Lambertian shading and shadow mapping to produce a realistic relighting effect, with the camera positioned on the left side of the scene.
read the caption
Figure 13: Directional Light Relighting Effect. (a) and (b) show the lighting intensity. (c) illustrates the relighting effect. Note that “S.M.” denotes “Shadow Mapping”.
More on tables
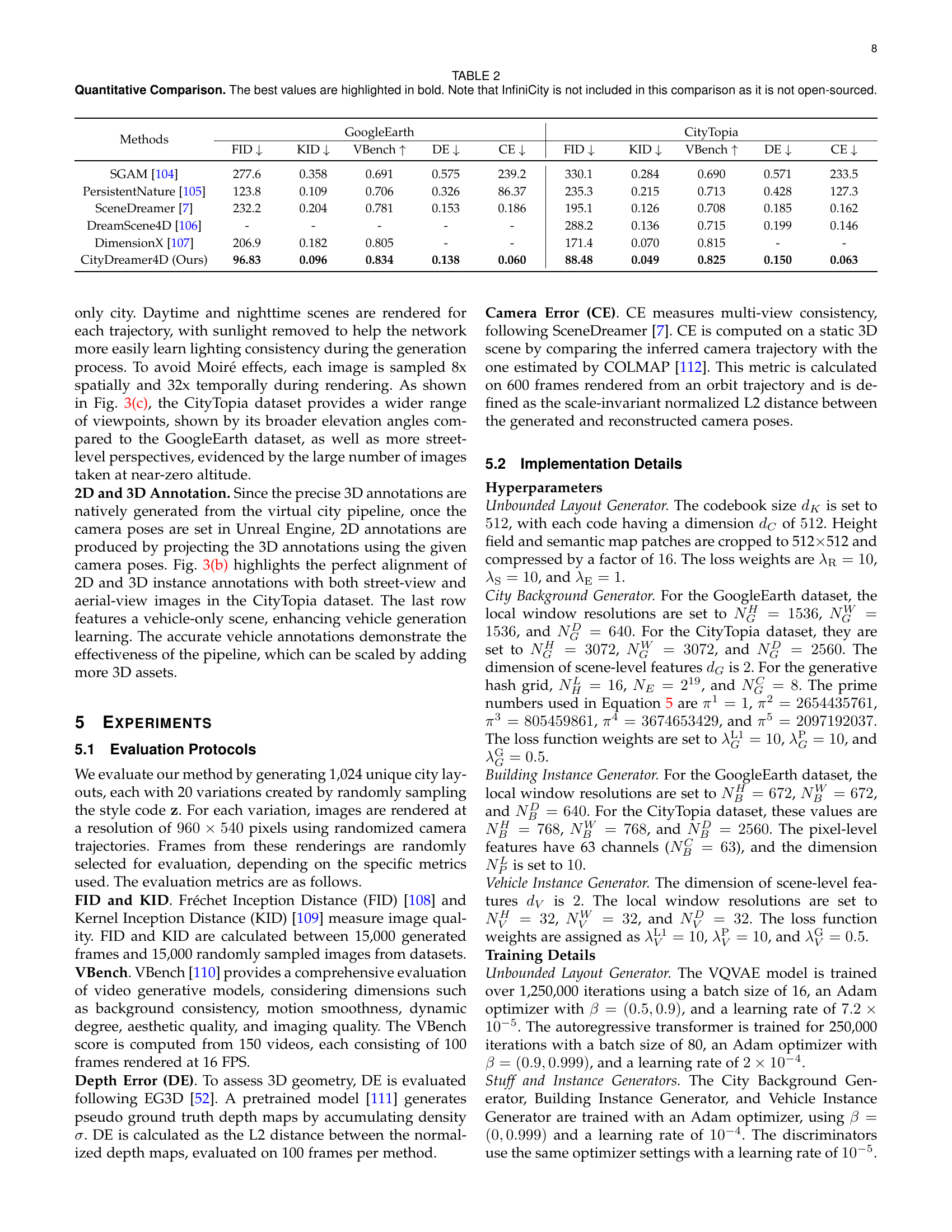
| Methods | GoogleEarth | CityTopia | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FID | KID | VBench | DE | CE | FID | KID | VBench | DE | CE | |
| SGAM [104] | 277.6 | 0.358 | 0.691 | 0.575 | 239.2 | 330.1 | 0.284 | 0.690 | 0.571 | 233.5 |
| PersistentNature [105] | 123.8 | 0.109 | 0.706 | 0.326 | 86.37 | 235.3 | 0.215 | 0.713 | 0.428 | 127.3 |
| SceneDreamer [7] | 232.2 | 0.204 | 0.781 | 0.153 | 0.186 | 195.1 | 0.126 | 0.708 | 0.185 | 0.162 |
| DreamScene4D [106] | - | - | - | - | - | 288.2 | 0.136 | 0.715 | 0.199 | 0.146 |
| DimensionX [107] | 206.9 | 0.182 | 0.805 | - | - | 171.4 | 0.070 | 0.815 | - | - |
| CityDreamer4D (Ours) | 96.83 | 0.096 | 0.834 | 0.138 | 0.060 | 88.48 | 0.049 | 0.825 | 0.150 | 0.063 |
🔼 This table presents a quantitative comparison of CityDreamer4D against other state-of-the-art methods for 4D city generation on the Google Earth and CityTopia datasets. The comparison uses several metrics: Fréchet Inception Distance (FID), Kernel Inception Distance (KID), VBench (for video generation quality), Depth Error (DE), and Camera Error (CE). Lower FID and KID scores indicate better image quality. Higher VBench scores reflect better video quality. Lower DE and CE scores represent better 3D geometry accuracy and view consistency respectively. CityDreamer4D’s performance is highlighted in bold for each metric, demonstrating its superiority across the board. Note that InfiniCity is excluded from the comparison due to its closed-source nature.
read the caption
TABLE II: Quantitative Comparison. The best values are highlighted in bold. Note that InfiniCity is not included in this comparison as it is not open-sourced.
🔼 This table presents a quantitative comparison of different unbounded layout generators, focusing on their performance in generating city layouts. The comparison uses the Fréchet Inception Distance (FID) and Kernel Inception Distance (KID) metrics, which measure the quality of generated images, with lower scores indicating better image quality. The table also indicates the size of the generated images (4096x4096 pixels after central cropping). The best-performing method for each metric is highlighted in bold. This allows for a direct comparison of the effectiveness of various methods in generating high-quality, expansive city layouts.
read the caption
TABLE III: Quantitative Comparison of Ubounded Layout Generator (UIG). The best values are highlighted in bold. The generated images are centrally cropped to a size of 4096×\times×4096.
| BIG | Inst. | Encoder | Pos.Enc. | Evaluation Metrics | |||||
| G | L | Hash | SinCos | FID | KID | DE | CE | ||
| ✗ | ✗ | - | - | - | - | 195.1 | 0.126 | 0.185 | 0.162 |
| ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | 167.8 | 0.094 | 0.157 | 0.087 |
| ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | 196.8 | 0.124 | 0.165 | 0.159 |
| ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | 197.9 | 0.132 | 0.162 | 0.152 |
| ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | 182.3 | 0.111 | 0.155 | 0.092 |
| ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | 88.48 | 0.049 | 0.150 | 0.063 |
🔼 This table presents a quantitative comparison of different variations of the Building Instance Generator (BIG) within the CityDreamer4D model. The variations are created by systematically changing key components of the BIG, such as the inclusion of instance labels, the type of positional encoding (SinCos or generative hash grids), and the use of global or local encoders. The table evaluates the performance of these variations using FID (Fréchet Inception Distance), KID (Kernel Inception Distance), Depth Error (DE), and Camera Error (CE). Lower FID and KID scores indicate higher image quality, while lower DE and CE scores suggest better depth and multi-view consistency. The best performing variant for each metric is highlighted in bold.
read the caption
TABLE IV: Quantitative Comparison of Building Instance Generator Variants. The best values are highlighted in bold. Note that “Inst.” and “Pos.Enc.” refer to “Instance Labels” and “Positional Encoding”, while “G” and “L” denote “Global Encoder” and “Local Encoder”, respectively.
| VIG | Can. | Encoder | Pos.Enc. | Evaluation Metrics | |||||
| G | L | Hash | SinCos | FID | KID | DE | CE | ||
| ✗ | ✗ | - | - | - | - | 419.3 | 0.576 | 0.364 | 1.276 |
| ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | 273.4 | 0.530 | 0.289 | 0.966 |
| ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | 229.2 | 0.428 | 0.259 | 0.989 |
| ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | 273.4 | 0.521 | 0.265 | 0.997 |
| ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | 142.3 | 0.276 | 0.202 | 0.824 |
| ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | 200.5 | 0.403 | 0.332 | 1.117 |
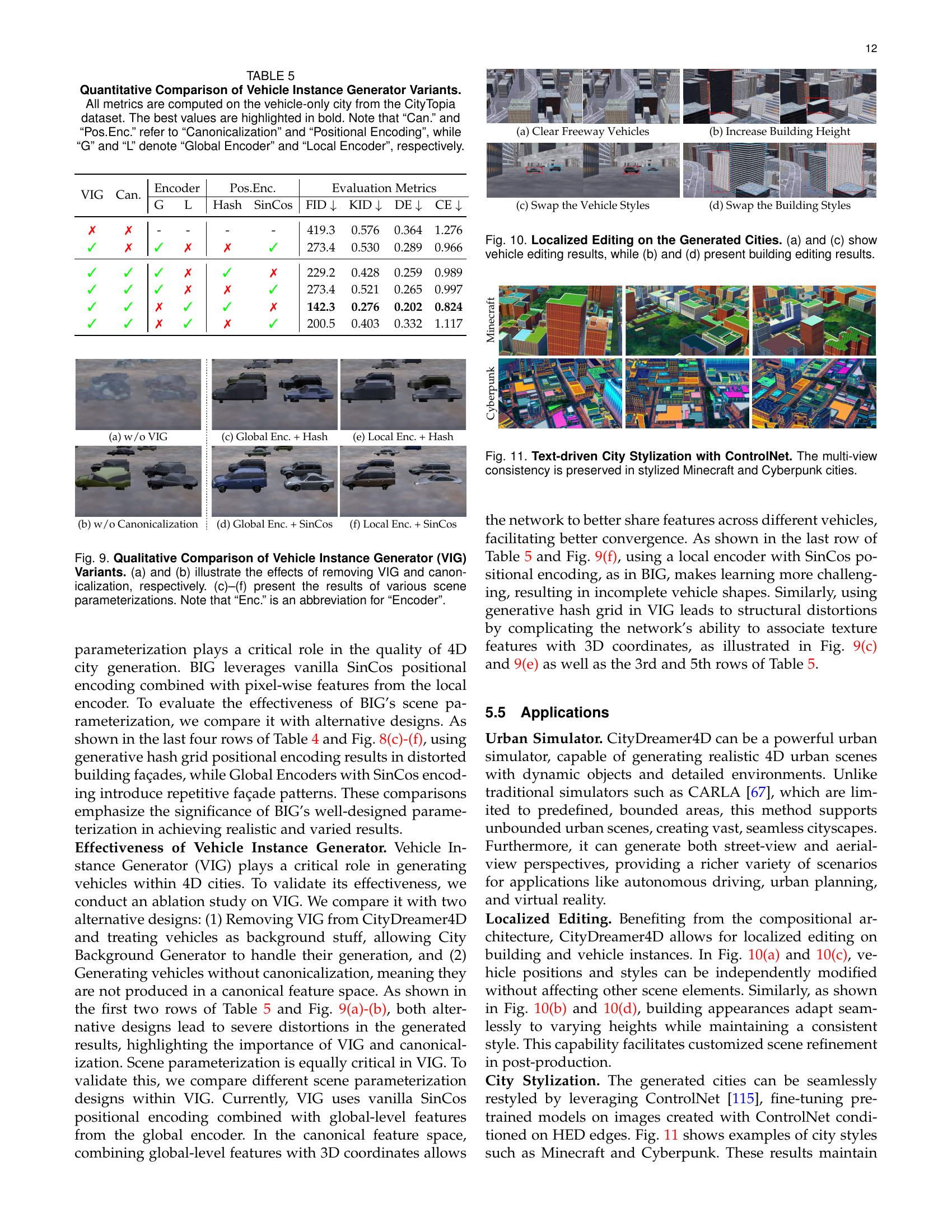
🔼 This table presents a quantitative comparison of different variations of the Vehicle Instance Generator (VIG), a key component of the CityDreamer4D model. The variations involve using different encoders (global or local), positional encoding methods (hash or sinusoidal), and whether canonicalization is applied. All results are based on vehicle-only scenes from the CityTopia dataset, making the comparisons consistent. The metrics used for comparison are Fréchet Inception Distance (FID), Kernel Inception Distance (KID), Depth Error (DE), and Camera Error (CE), providing a comprehensive assessment of the generated vehicle quality and consistency. Lower FID and KID values indicate higher visual fidelity; lower DE and CE values indicate more accurate 3D geometry and multi-view consistency.
read the caption
TABLE V: Quantitative Comparison of Vehicle Instance Generator Variants. All metrics are computed on the vehicle-only city from the CityTopia dataset. The best values are highlighted in bold. Note that “Can.” and “Pos.Enc.” refer to “Canonicalization” and “Positional Encoding”, while “G” and “L” denote “Global Encoder” and “Local Encoder”, respectively.
Full paper#