TL;DR#
Current text-to-video generation models, while impressive, struggle with producing videos that have both high-quality spatial details and smooth, natural transitions between frames. This is largely due to how these models process information across different layers in their network, leading to inconsistencies in the features used to generate successive video frames. The paper investigates this issue, showing that instability in the intermediate features across layers results in lower quality outputs.
To solve this, the authors propose RepVideo. This method improves how information is managed across layers, creating a more stable representation of the video’s features and improving both the spatial and temporal qualities of the final video output. RepVideo achieves this by aggregating features from several layers of the network, creating a more stable and consistent representation that is then fed back into the network, leading to more coherent and higher quality videos. Extensive testing shows this new method outperforms existing models, indicating that focusing on intermediate feature representation is a promising avenue for advancing text-to-video generation technology.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in current video generation models: the lack of understanding regarding how intermediate feature representations affect the final output. By demonstrating the negative impact of unstable features and proposing a solution (RepVideo), it opens new avenues for improving video generation quality, particularly temporal coherence and spatial detail. This work directly relates to the currently trending focus on transformer-based diffusion models, suggesting potential improvements for existing approaches and guiding future research in this domain.
Visual Insights#

🔼 Figure 1 showcases example video outputs generated by the RepVideo model. These examples highlight the model’s capability to generate diverse video content with improved temporal coherence (smooth and realistic transitions between frames) and fine-grained spatial details (clear and sharp visuals). The videos depict a variety of scenes, demonstrating RepVideo’s ability to handle different levels of complexity and visual styles.
read the caption
Figure 1: The examples generated by RepVideo. RepVideo effectively generates diverse videos with enhanced temporal coherence and fine-grained spatial details.
| Method | Total Score | Motion Smoothness | Object Class | Multiple Objects | Spatial Relationship |
| LaVie [17] | 77.08% | 96.38% | 91.82% | 33.32% | 34.09% |
| VideoCrafter-2.0 [55] | 80.44% | 97.73% | 92.55% | 40.66% | 35.86% |
| OpenSoraPlan-v1.1 | 78.00% | 98.28% | 76.30% | 40.35% | 53.11% |
| OpenSora-1.2 [56] | 79.76% | 98.50% | 82.22% | 51.83% | 68.56% |
| Gen-3 [57] | 82.32% | 99.23% | 87.81% | 53.64% | 65.09% |
| Gen-2 [58] | 80.58% | 99.58% | 90.92% | 55.47% | 66.91% |
| Pika-1.0 [59] | 80.69% | 99.50% | 88.72% | 43.08% | 61.03% |
| CogVideoX-2B [31] | 80.91% | 97.73% | 83.37% | 62.63% | 69.90% |
| CogVideoX-5B [31] | 81.61% | 96.92% | 85.23% | 62.11% | 66.35% |
| Vchitect-2.0 [60] | 81.57% | 97.76% | 87.81% | 69.35% | 54.64% |
| RepVideo (Ours) | 81.94% | 98.13% | 87.83% | 71.18% | 74.74% |
🔼 This table presents a quantitative comparison of RepVideo’s performance against several state-of-the-art text-to-video generation models using the VBench [54] benchmark. VBench provides a comprehensive evaluation across multiple metrics, including overall video quality, motion smoothness, object classification accuracy, the ability to generate multiple distinct objects, and spatial relationships between objects. The table allows for a direct comparison of RepVideo’s strengths and weaknesses relative to existing approaches, highlighting its performance in various aspects of video generation.
read the caption
TABLE I: Comparison with previous methods on VBench [54] .
In-depth insights#
RepVideo: Core Idea#
RepVideo’s core idea centers on enhancing the stability and quality of video generation by addressing limitations in existing transformer-based diffusion models. The core issue identified is the inconsistency in feature representations across different transformer layers. This inconsistency leads to unstable semantics, affecting both spatial detail and temporal coherence in generated videos. To resolve this, RepVideo introduces a feature cache module which aggregates features from neighboring layers, creating enriched representations with more stable semantic information. These enriched features are then integrated with the original transformer inputs via a gating mechanism, allowing the model to dynamically balance enhanced representations with layer-specific details. This approach directly tackles the core problem of unstable intermediate representations, leading to improved spatial detail, enhanced temporal coherence, and ultimately, higher-quality video generation.
Attention Map Analysis#
Analyzing attention maps in video generation models reveals crucial insights into model behavior. The researchers observed significant variations in attention patterns across different transformer layers, indicating each layer focuses on unique feature aspects. This layer-wise specialization, while allowing the model to capture diverse spatial information, can lead to fragmented representations, reducing spatial coherence within frames. Furthermore, attention map analysis across consecutive frames highlighted a decrease in similarity as layer depth increased. This suggests that deeper layers, while enriching feature representations, also reduce temporal consistency by increasing the differentiation between adjacent frame features. These findings underscore the importance of investigating and improving how models integrate information across both spatial and temporal dimensions, informing strategies for enhancing overall video quality and coherence.
RepVideo: Framework#
The RepVideo framework tackles the limitations of existing video generation models by focusing on enhancing cross-layer representations within transformer-based diffusion models. It directly addresses the instability of semantic features and the decline in temporal coherence observed across different layers of these models. This is achieved primarily through a novel Feature Cache Module that aggregates features from multiple adjacent transformer layers, creating more stable and comprehensive representations. A gating mechanism then dynamically integrates these aggregated features with the original transformer inputs, balancing enhanced semantic richness with layer-specific detail. This approach doesn’t require extensive architectural modifications, making it computationally efficient while significantly improving the quality and coherence of generated videos. RepVideo’s core innovation lies in its ability to learn more robust and consistent feature representations, ultimately resulting in videos with enhanced spatial fidelity, better temporal consistency, and improved alignment with textual descriptions. The framework’s simplicity and effectiveness are highlighted by its competitive performance compared to existing state-of-the-art models in quantitative and qualitative evaluations, demonstrating its significant contribution to the field of text-to-video generation.
Ablation Study: Results#
An ablation study for a video generation model, RepVideo, would systematically remove or modify components to assess their individual contributions. Results would demonstrate the impact of each component on key metrics, such as FID (Fréchet Inception Distance) for image quality and metrics measuring temporal consistency (e.g., frame-to-frame similarity). Removing the feature cache module, for instance, would likely show a decrease in temporal coherence and possibly spatial quality, as this module aggregates features across layers to improve stability. Similarly, disabling the gating mechanism that blends aggregated and original features might lead to less precise control over detail, potentially reducing the overall quality of the generated videos. By comparing results across different ablation configurations, the study would quantify the relative importance of each component in achieving RepVideo’s improved performance and clarify the interplay between spatial detail and temporal consistency, providing critical insights for future model development. The key finding would likely highlight the synergistic effect of both components, where their combined use achieves better results than either alone, demonstrating the effectiveness of the proposed RepVideo architecture.
Future Work: Directions#
Future research directions for enhancing text-to-video generation models should prioritize improving efficiency and scalability. Current methods, while showing promise, are computationally expensive, limiting real-time applications. Addressing inherent biases and constraints from pretrained models is crucial; these models may lack diversity and struggle with scenarios outside their training data. Further investigation into more robust and flexible feature aggregation techniques is needed, balancing the benefits of multi-layer integration with the need for efficient processing. Exploring alternative model architectures beyond transformers could lead to new breakthroughs. Finally, advancing research on fine-grained temporal modeling and control is key, enabling the generation of smoother transitions and more realistic motions. Focusing on the nuances of human actions and complex interactions will create even more compelling and realistic videos.
More visual insights#
More on figures

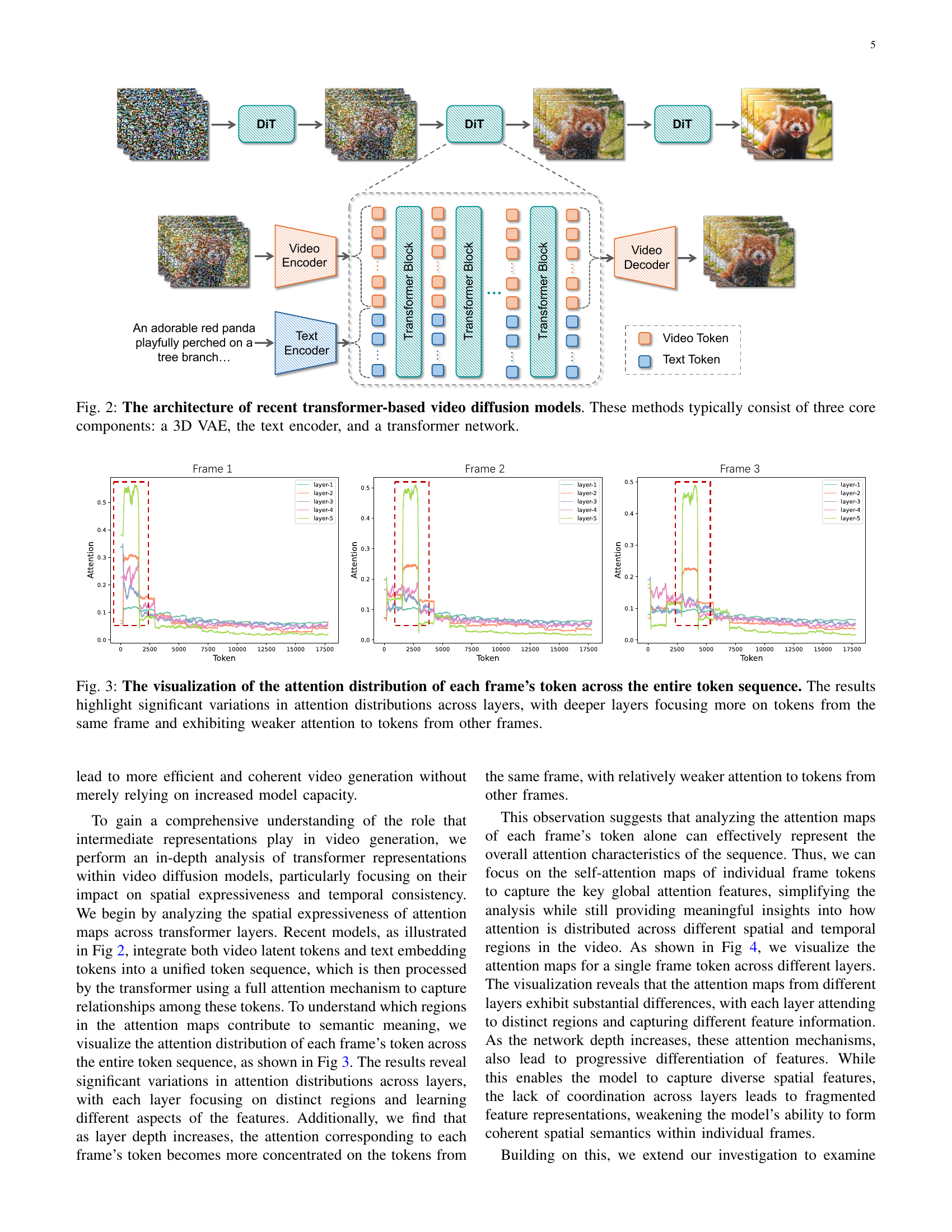
🔼 This figure illustrates the typical architecture of modern transformer-based video diffusion models. It breaks down the process into three main components: a 3D Variational Autoencoder (VAE) which compresses the input video into a lower-dimensional latent representation; a text encoder that processes the textual input prompt (e.g., a description of the desired video) and translates it into a numerical representation suitable for the model; and a transformer network that takes both the latent video representation and the text embedding as input to generate the final video. The 3D VAE handles the temporal aspects of video processing. The transformer network, with its attention mechanisms, is key to capturing the complex spatial and temporal relationships within the video for a coherent output.
read the caption
Figure 2: The architecture of recent transformer-based video diffusion models. These methods typically consist of three core components: a 3D VAE, the text encoder, and a transformer network.

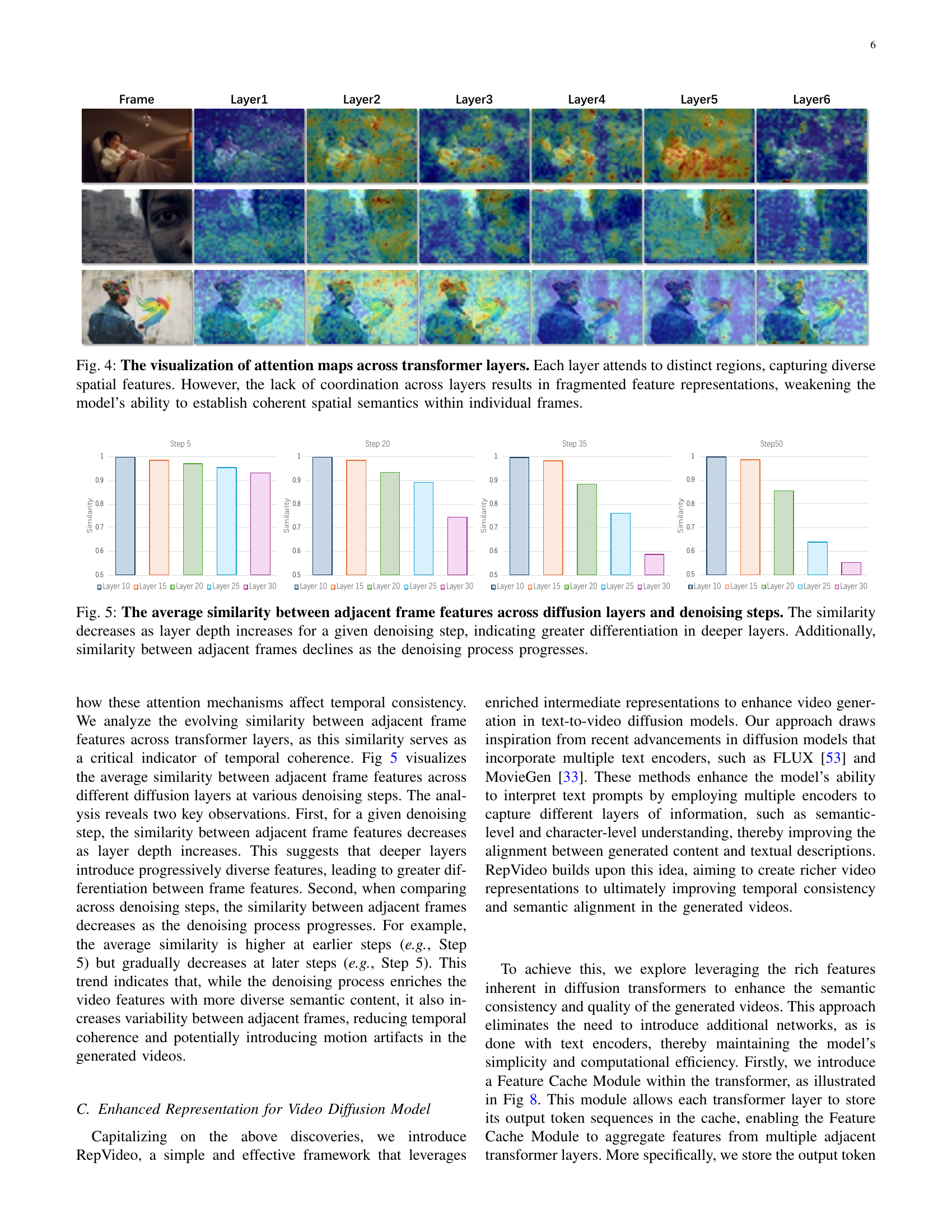
🔼 This figure visualizes how attention mechanisms in a transformer-based video generation model distribute attention across different frames within a video sequence. The visualizations show attention maps for tokens representing each frame at various layers of the transformer. Key observations are that shallower layers distribute attention more evenly across frames, indicating a broader contextual awareness. Conversely, deeper layers exhibit significantly more focused attention on tokens from the current frame, highlighting the increasing specificity of the model’s representation as it processes through subsequent layers. This shift toward intra-frame focus in deeper layers suggests a transition from global contextual understanding to fine-grained feature analysis within individual frames.
read the caption
Figure 3: The visualization of the attention distribution of each frame’s token across the entire token sequence. The results highlight significant variations in attention distributions across layers, with deeper layers focusing more on tokens from the same frame and exhibiting weaker attention to tokens from other frames.

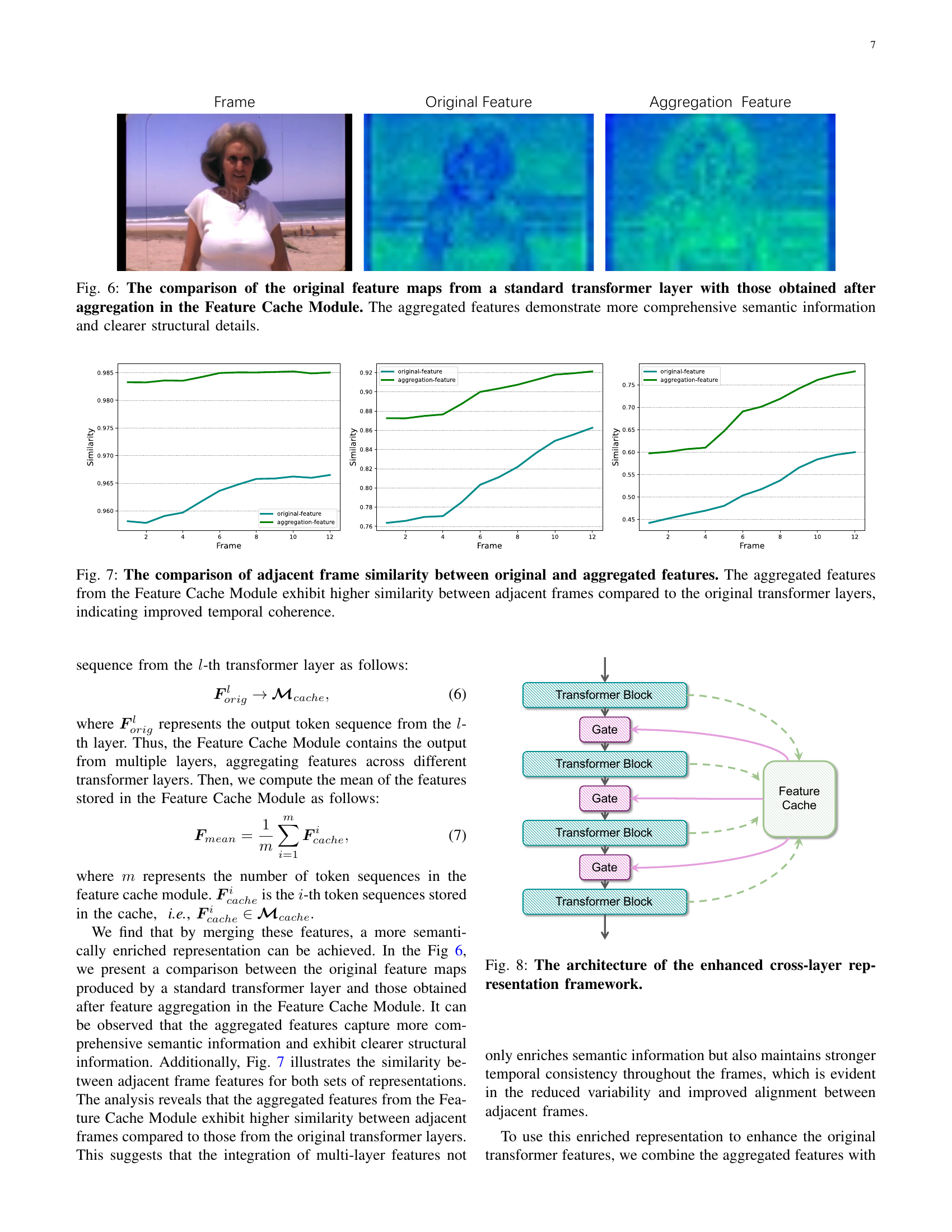
🔼 This figure visualizes attention maps across different layers of a transformer network used in video generation. Each layer focuses on different spatial regions, showcasing the model’s ability to capture diverse features. However, the lack of coordination between layers leads to fragmented representations, hindering the model’s ability to create consistent spatial relationships and semantic coherence within individual frames. This inconsistency between layers negatively impacts the overall quality and coherence of generated videos, as it impacts the model’s ability to produce internally consistent and semantically meaningful frames.
read the caption
Figure 4: The visualization of attention maps across transformer layers. Each layer attends to distinct regions, capturing diverse spatial features. However, the lack of coordination across layers results in fragmented feature representations, weakening the model’s ability to establish coherent spatial semantics within individual frames.

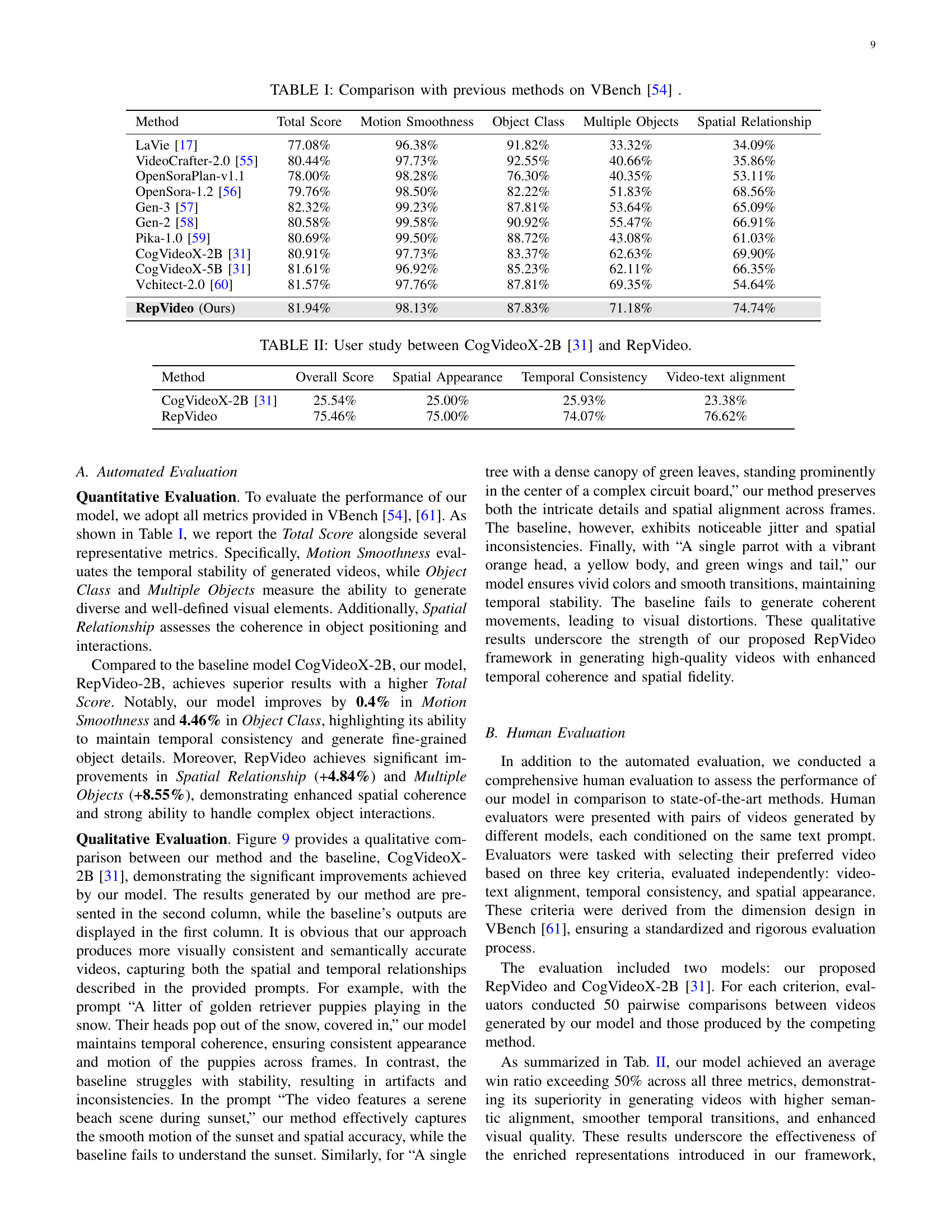
🔼 This figure visualizes the average similarity between features of adjacent frames in a video generation model. Two key trends are observed. First, at any given step in the denoising process, similarity decreases as you go deeper through the model’s layers. This shows that deeper layers differentiate features more strongly between frames. Second, across the denoising process (as the steps progress), the similarity between adjacent frames gradually decreases. This decrease suggests that although the model refines video features over the denoising process, it also increases variability between frames, potentially introducing artifacts such as abrupt motion changes.
read the caption
Figure 5: The average similarity between adjacent frame features across diffusion layers and denoising steps. The similarity decreases as layer depth increases for a given denoising step, indicating greater differentiation in deeper layers. Additionally, similarity between adjacent frames declines as the denoising process progresses.

🔼 This figure compares feature maps from a standard transformer layer with those produced by the Feature Cache Module in the RepVideo model. The Feature Cache Module aggregates features from multiple adjacent transformer layers, resulting in aggregated features that show more comprehensive semantic information and clearer structural details compared to the original feature maps. This demonstrates the effectiveness of the module in improving the quality of video generation by providing richer, more stable representations.
read the caption
Figure 6: The comparison of the original feature maps from a standard transformer layer with those obtained after aggregation in the Feature Cache Module. The aggregated features demonstrate more comprehensive semantic information and clearer structural details.

🔼 Figure 7 presents a comparative analysis of the similarity between adjacent frames’ features. Two sets of features are compared: the original features directly from the transformer layers of a video generation model, and the aggregated features produced by the Feature Cache Module (a component of the RepVideo framework introduced in the paper). The graph shows that the aggregated features exhibit substantially higher similarity between consecutive frames. This improved similarity is a key indicator of enhanced temporal coherence in the generated videos, signifying smoother and more natural transitions between frames. The enhanced coherence is achieved because the Feature Cache Module combines features from multiple transformer layers, creating a more stable and consistent representation.
read the caption
Figure 7: The comparison of adjacent frame similarity between original and aggregated features. The aggregated features from the Feature Cache Module exhibit higher similarity between adjacent frames compared to the original transformer layers, indicating improved temporal coherence.

🔼 The figure illustrates the RepVideo architecture, an enhanced cross-layer representation framework designed to improve video generation. It shows how features from multiple adjacent transformer layers are aggregated using a feature cache module. This aggregated information is then combined with the original transformer inputs via a gating mechanism, creating enriched feature representations that are fed into subsequent transformer layers. This process aims to enhance both the temporal consistency and the spatial details of the generated videos by stabilizing feature representation across the layers and reducing inconsistencies between adjacent frames.
read the caption
Figure 8: The architecture of the enhanced cross-layer representation framework.

🔼 This figure presents a qualitative comparison of video generation results between the proposed RepVideo model and the baseline CogVideoX-2B model. The comparison uses four different video prompts, each visualized across two rows. The top row displays the output from CogVideoX-2B, while the bottom row shows the improved results generated by RepVideo. The visualization clearly showcases that RepVideo produces videos with superior visual quality and enhanced temporal and spatial coherence, demonstrating a significant improvement in video generation capabilities. Each set of videos, generated from the same prompt, allows for direct comparison of the model’s performance in terms of color accuracy, scene consistency, and movement fluidity. The improved quality in RepVideo’s output is evident across all prompts.
read the caption
Figure 9: The qualitative comparison between our method and the baseline CogVideoX-2B [31]. The first row shows results from the baseline CogVideoX-2B [31], while the second row presents the results generated by RepVideo, demonstrating significant improvements in quality and coherence.

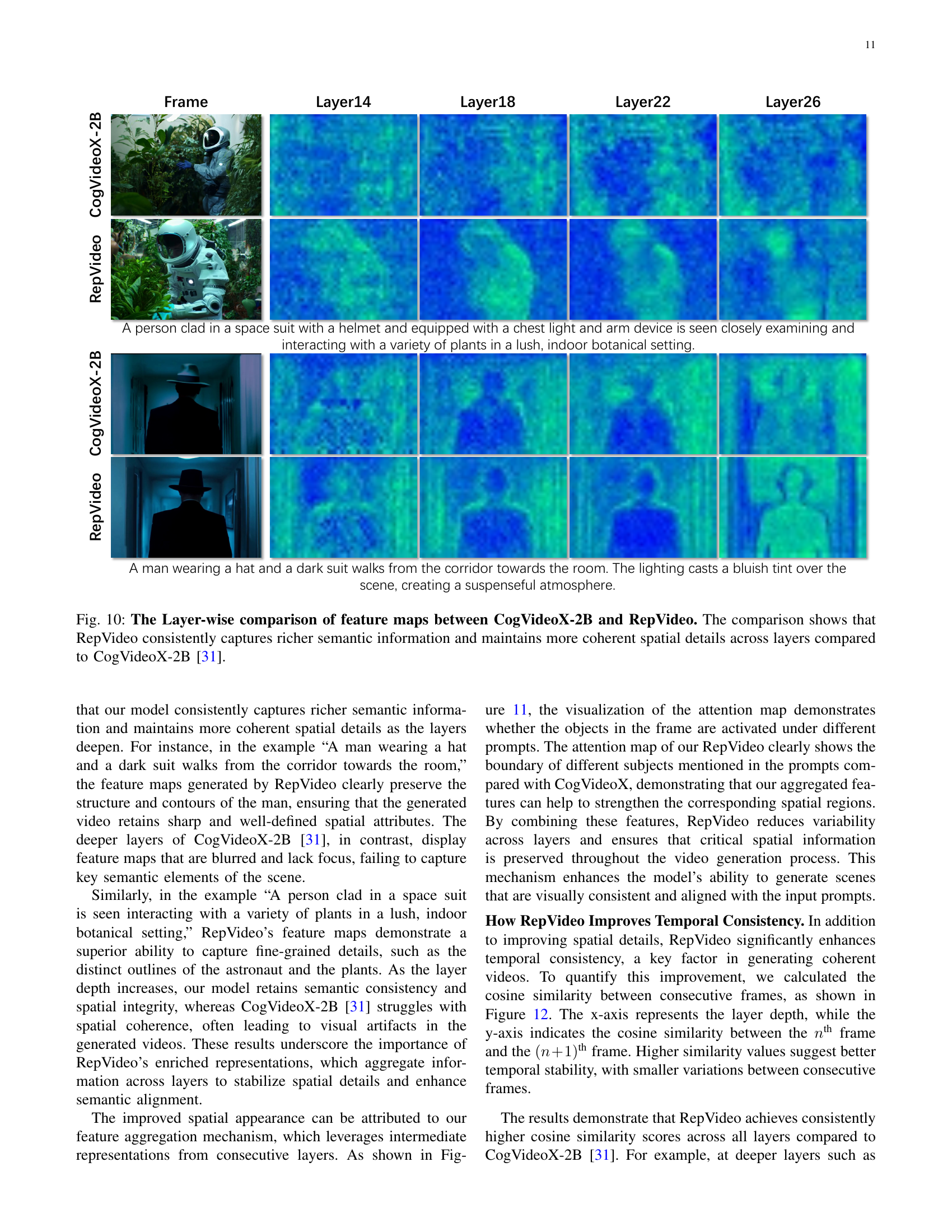
🔼 Figure 10 presents a layer-by-layer comparison of feature maps generated by RepVideo and CogVideoX-2B. The visualization reveals that RepVideo consistently produces feature maps with richer semantic information and more coherent spatial details throughout the different layers of the transformer network. In contrast, CogVideoX-2B shows a decline in the quality of feature maps, indicating less coherent spatial representations and less semantic information in deeper layers. Two example images are shown to illustrate this difference.
read the caption
Figure 10: The Layer-wise comparison of feature maps between CogVideoX-2B and RepVideo. The comparison shows that RepVideo consistently captures richer semantic information and maintains more coherent spatial details across layers compared to CogVideoX-2B [31].

🔼 Figure 11 visualizes a comparison of attention maps generated by two different video generation models: CogVideoX-2B and RepVideo. The images show attention map visualizations across multiple layers for a single frame generated under the same prompt. The main point is to highlight that RepVideo, unlike CogVideoX-2B, maintains a more consistent and coherent semantic relationship across the various layers of its network. This consistency is reflected in the visual attention patterns, indicating better alignment and understanding of the scene elements. Inconsistency in CogVideoX-2B’s attention maps across layers suggests the model struggles to maintain a unified understanding of the subject and context across different processing stages, potentially leading to less coherent and lower quality video generation.
read the caption
Figure 11: The comparison of attention maps between CogVideoX-2B and RepVideo. The comparison demonstrates that RepVideo could maintain more consistent semantic relationship compared to CogVideoX-2B [31].

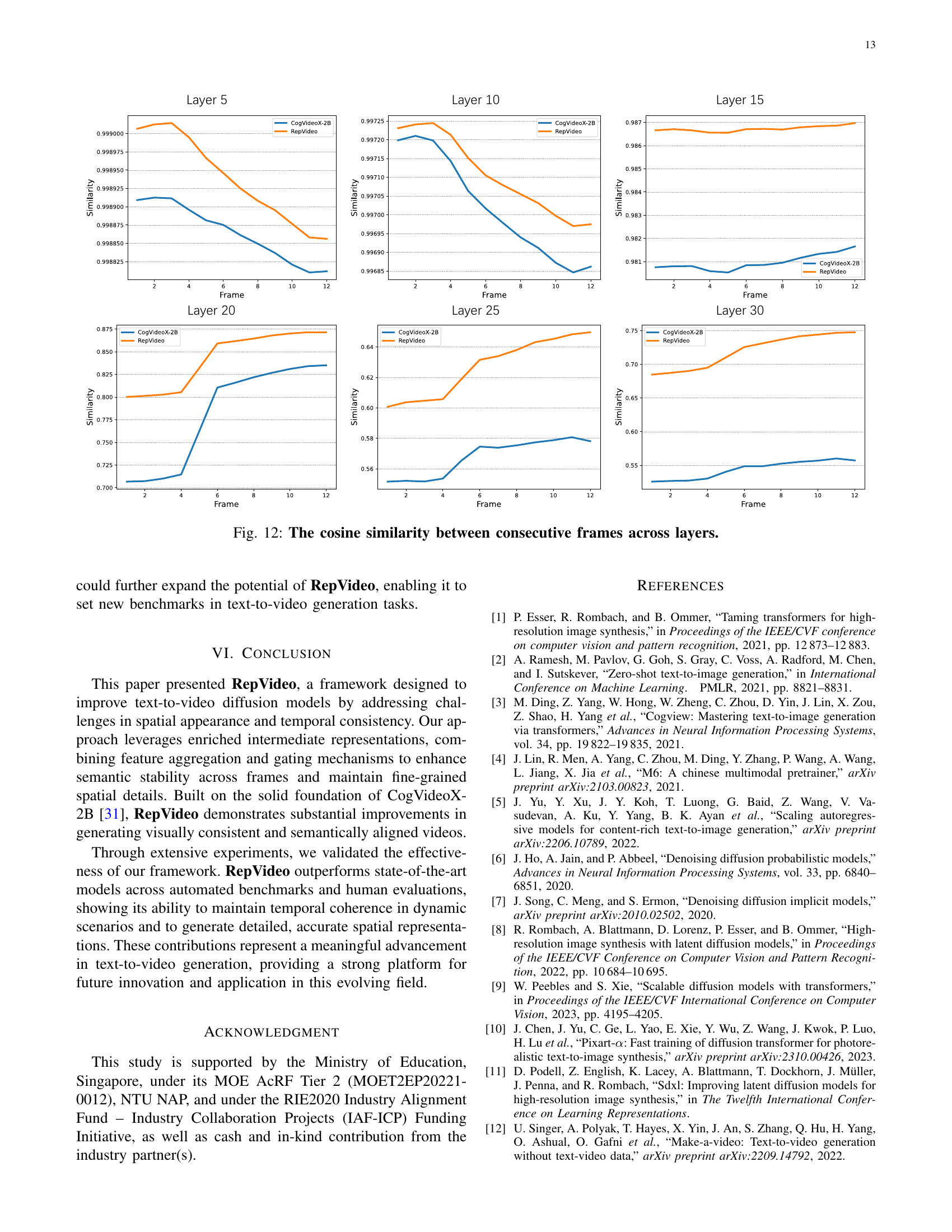
🔼 This figure visualizes the temporal consistency of video generation across different layers of a transformer network. It plots the cosine similarity between consecutive frames as a function of layer depth within the network. Higher cosine similarity indicates stronger temporal coherence, meaning smoother transitions between frames. The figure shows that, as the layer depth increases, the cosine similarity tends to decrease, suggesting that deeper layers introduce greater variability and potentially disrupt temporal coherence in the video generation process. Different lines within the plot represent the similarity at different steps in the denoising process of the diffusion model, further illustrating how temporal consistency evolves across layers and during the denoising process.
read the caption
Figure 12: The cosine similarity between consecutive frames across layers.
Full paper#