TL;DR#
Current methods for evaluating the aesthetics of AI-generated art are limited, lacking interpretability and alignment with human preferences. This paper tackles this challenge by focusing on how multimodal large language models (MLLMs) can be used to evaluate the aesthetics of artworks. Existing approaches often use metrics that are not well-aligned with human judgment, resulting in systems that produce visually appealing but not aesthetically pleasing artworks.
The researchers address these limitations by developing MM-StyleBench, a new large-scale dataset for artistic stylization. They propose ArtCoT, a prompting method that uses a chain-of-thought approach to guide the LLM’s reasoning and reduce the likelihood of subjective or hallucinatory outputs. Their experiments demonstrate that ArtCoT significantly improves the aesthetic alignment of the model with human preferences, providing a more reliable and interpretable way to evaluate AI-generated art.
Key Takeaways#
Why does it matter?#
This paper is important because it bridges the gap between art and AI, exploring a largely uncharted area of research. It introduces a novel dataset and method for evaluating AI-generated art, addressing a critical need in the field of computer vision and art. The findings provide valuable insights into how to effectively prompt and evaluate large language models (LLMs) to achieve human-aligned aesthetic assessment. This opens new avenues for research into AI-driven art creation and evaluation methods.
Visual Insights#

🔼 This figure presents the MM-StyleBench dataset, a novel large-scale dataset for multimodal stylization, in two parts. (a) shows the distribution of various attributes within the dataset, highlighting its diversity in terms of content, style, and other relevant features such as composition, color diversity, and element density. The detailed attribute annotations ensure a comprehensive and robust evaluation of stylization methods. (b) provides visual examples of content and style instances from the dataset. The top row showcases diverse content images, representing a broad range of scenes and objects. The bottom row displays their corresponding stylized versions, demonstrating the variety of styles included within MM-StyleBench. These examples illustrate the dataset’s capability to benchmark multimodal stylization methods effectively.
read the caption
Figure 1: The MM-StyleBench dataset. (a) The distribution of different attributes in MM-StyleBench. the proposed dataset contains diverse images and text prompts with detailed attribute annotations. (b) Examples of content (top) and style (bottom) instances in MM-StyleBench.
| Dataset/Protocol | # Content | # Style | Multimodal | Dense Annotation |
|---|---|---|---|---|
| DiffStyler [2] | 20 | 25 | ✗ | ✗ |
| StyleID [34] | 20 | 40 | ✗ | ✗ |
| LAION-Aesthetics [7] | - | 50 | ✗ | ✗ |
| ArtBench [35] | - | 10 | ✗ | ✗ |
| StyleBench [36] | 20 | 73 | ✓ | ✗ |
| Ours | 1000 | 1000 | ✓ | ✓ |
🔼 This table compares the scale, modality, and annotation detail of several benchmark datasets used for evaluating artistic stylization models. It highlights that the proposed MM-StyleBench dataset significantly surpasses existing datasets in terms of the number of content and style examples available, and also in the richness and granularity of its multimodal annotations (both image and text). This makes MM-StyleBench more suitable for robustly evaluating and comparing the performance of stylization models.
read the caption
TABLE I: Comparison of representative stylization benchmark datasets. The proposed MM-StyleBench offers significantly more content and style instance, with fine-grained multimodal annotations.
In-depth insights#
Aesthetic Reasoning#
Aesthetic reasoning, in the context of multimodal large language models (MLLMs) applied to art, presents a fascinating challenge. The ability to quantify and interpret aesthetic qualities transcends simple visual feature extraction; it requires an understanding of cultural context, emotional impact, and artistic principles. While MLLMs show promise in leveraging multimodal data for this task, the inherent subjectivity of aesthetics presents a significant hurdle. Hallucinations, where the MLLM generates subjective and often inaccurate judgments, are a major obstacle to achieving human-level alignment in aesthetic evaluation. To improve MLLM performance, methods like task decomposition and the use of concrete language are crucial, forcing the model to engage in more structured reasoning instead of relying on vague, emotional descriptors. The development of large-scale, high-quality datasets like MM-StyleBench, with detailed annotations, is also vital for training and evaluating these models. Ultimately, success in MLLM-based aesthetic reasoning requires a multi-faceted approach, combining advancements in model architecture with careful prompt engineering and a deeper understanding of how humans perceive and articulate aesthetic value.
MM-StyleBench#
The heading ‘MM-StyleBench’ strongly suggests a multimodal dataset designed for evaluating and benchmarking artistic style transfer models. The ‘MM’ likely stands for ‘Multimodal,’ emphasizing the use of both visual (image) and textual (style descriptions) data. This is a crucial aspect, as it allows for a more nuanced and comprehensive assessment of aesthetics beyond purely visual metrics. A key insight is the focus on stylization, which indicates that the dataset is specifically curated for tasks related to transferring artistic styles from one image to another. The ‘Bench’ element points towards the benchmarking functionality of the dataset, implying its potential to be a standard for evaluating the performance of various style transfer methods. This dataset likely contains a wide range of image-style pairs, allowing researchers to assess the generalization ability of models across diverse art styles and image content. Overall, MM-StyleBench represents a significant contribution towards establishing a more robust and objective evaluation framework for the field of artistic stylization.
ArtCoT Prompting#
ArtCoT prompting is a novel approach designed to enhance the aesthetic evaluation capabilities of large language models (LLMs) in the context of artwork. It tackles the inherent hallucination problem often observed in LLMs, where subjective language leads to unreliable assessments. ArtCoT structures the prompting process into three distinct phases: content and style analysis, art critique, and summarization. This decomposition helps break down complex aesthetic judgment into manageable subtasks, guiding the LLM toward a more objective and reasoned evaluation. The use of concrete language and art-specific task decomposition is key to ArtCoT’s success, reducing hallucinations and improving alignment with human aesthetic preferences. By decomposing the task into smaller, more focused prompts, ArtCoT facilitates a more detailed and nuanced understanding of the artwork’s aesthetic qualities before reaching a final judgment. This method effectively mimics the structured reasoning process employed by art critics, thereby enhancing the reliability and accuracy of LLM-based aesthetic assessment.
Hallucination Issue#
The phenomenon of ‘hallucination’ in large language models (LLMs), particularly within the context of art evaluation, presents a significant challenge. LLMs, trained on massive datasets, sometimes generate outputs that are factually inaccurate or nonsensical, even when seemingly coherent. In art analysis, this manifests as subjective and often unfounded claims about artistic elements or stylistic influences. The paper highlights how LLMs tend to favor subjective language and emotional responses, rather than objective analysis, leading to hallucinations. Addressing this requires careful prompting and task decomposition, guiding the LLM towards concrete visual descriptions and reasoning. The authors propose methods to mitigate hallucinations by introducing specific sub-tasks (analysis, critique, summarization) to encourage more structured and less subjective outputs. This approach aims to align LLM assessments more closely with human perceptions of aesthetic quality by reducing the model’s tendency towards creative fabrication and improving the factual accuracy of its artistic evaluations. Ultimately, reducing hallucination is crucial for enhancing the reliability and trustworthiness of LLMs in art-related applications.
Future of MLLMs#
The future of Multimodal Large Language Models (MLLMs) is incredibly promising, yet also presents significant challenges. Improved alignment with human preferences is crucial; current models often exhibit biases and hallucinations, hindering their reliability in tasks demanding nuanced understanding, such as aesthetic evaluation. Addressing this requires advancements in prompting techniques and model architectures, possibly incorporating more sophisticated reasoning mechanisms inspired by cognitive science. Data quality and diversity are key, as MLLMs’ performance is directly tied to the richness and representativeness of their training data. We can expect to see more robust benchmark datasets and better evaluation metrics to facilitate progress. Furthermore, responsible development and deployment are paramount; mitigating potential harms associated with bias, misinformation, and misuse will be vital in shaping the future of MLLMs and ensuring their ethical integration into society. Enhanced explainability and interpretability are also needed to build trust and allow for better debugging and refinement.
More visual insights#
More on figures

🔼 This figure illustrates the alignment evaluation pipeline used to assess the aesthetic judgment of multimodal large language models (MLLMs). The process begins by sampling content and style pairs from the MM-StyleBench dataset. These pairs undergo stylization, generating multiple stylistic versions of the same content. Then, pairwise comparisons (2AFC) are created from these versions, and human preference is collected for ranking. This data is then filtered and aggregated into global rankings. The figure then showcases ArtCoT, a prompting method designed to improve the MLLM’s aesthetic alignment by incorporating art-specific task decomposition into three stages: content/style analysis, art criticism, and summarization. Finally, the correlation between MLLM rankings generated using ArtCoT and the human rankings is calculated to measure the aesthetic alignment.
read the caption
Figure 2: Overview of our alignment evaluation pipeline. First, (a) we sample content and style from MM-StyleBench for stylization, and construct 2AFC comparison sets by sampling from all possible candidate comparisons. (b) Human preference data is collected and filtered with two heuristic indicators, which is finally aggregated as global rankings. (c) We propose ArtCoT, which involves three art-specific phases to reduce MLLMs’ hallucinations. Finally, we calculate the correlation of rankings from MLLMs and humans as indicators of aesthetic alignment.

🔼 This figure presents a fine-grained analysis of how different prompting methods for Multimodal Large Language Models (MLLMs) affect their ability to align with human aesthetic preferences. The Spearman’s rank correlation coefficient (ρ) is used to measure the alignment between MLLM rankings and human rankings of stylized images. The analysis is broken down by various attributes of the MM-StyleBench dataset, including content and style characteristics, revealing how these attributes influence MLLM performance. The results demonstrate that the ArtCoT prompting method consistently achieves superior alignment across different attribute categories, particularly for complex and detailed prompts. This underscores the significant impact of ArtCoT in enhancing MLLM’s aesthetic reasoning capabilities.
read the caption
Figure 3: Fine-grained comparison of different MLLM prompting scheme. We show the spearman’s ρ𝜌\rhoitalic_ρ for per-instance alignment, grouped by representative attribute provided by MM-StyleBench. ArtCoT elicits aesthetic reasoning for all scenarios, especially for instances with long and detailed prompts.

🔼 This figure depicts the user interface used for collecting human preference data in a two-alternative forced choice (2AFC) task. The top section shows the original source image. The middle section presents two stylized images, generated by different stylization models. Participants choose their preferred image from the two presented by clicking the ‘left’ or ‘right’ button. The bottom section provides the style prompt that guided the stylization process, which helps to contextualize the comparison task. This carefully designed interface ensures that the user understands the context and rationale for their preference selection.
read the caption
Figure 4: User Interface for Preference Annotation. We present user with the source image (top), 2AFC (middle) and style prompt (bottom). The user is required to choose the preferred one by clicking on the “left” or “right” button.

🔼 This algorithm aims to sample a connected subgraph from a complete graph, where the number of edges is controlled. The key constraint is to ensure a uniform degree distribution in the resulting subgraph, meaning each node in the subgraph has a similar number of connections. The algorithm starts by creating a minimum spanning tree using Kruskal’s algorithm to guarantee connectivity. It then iteratively adds edges to the subgraph, prioritizing those that minimize the degree imbalance between nodes, until the desired number of edges is reached. This approach helps to generate a subgraph that is both connected and has a balanced structure.
read the caption
Algorithm 1 Sample a Connected Subgraph with Uniform Degree Distribution

🔼 This figure showcases examples of stylized images generated using various stylization techniques. Two sets of images are presented, each demonstrating a different artistic style: Impressionism and Cubism. The figure highlights the diversity in the quality and aesthetic appeal of the generated images, ranging from highly successful to less satisfactory results. This variation underscores the challenges and complexities involved in evaluating the effectiveness of image stylization algorithms and their ability to produce visually appealing and aesthetically pleasing artworks. The wide range of results shown demonstrates the need for more robust and comprehensive evaluation metrics in artistic stylization.
read the caption
Figure 5: Examples of Stylized Image. We show two uncurated examples from different stylization results, the image order are randomized. The styles are impressionist and cubism, respectively. The results covers a wide range of stylization performance, setting a realistic and challenging task for artistic evaluation.
More on tables
| Model | Prompting | Per-Method Alignment | Per-Instance Alignment | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Elo | Bradley-Terry | Elo | Bradley-Terry | ||||||
| -value | -value | -value | -value | ||||||
| Random guess | – | -0.115 | 0.751 | 0.067 | 0.855 | 0.068 | 0.153 | 0.026 | 0.290 |
| Aesthetics Predictor [7] | – | 0.406 | 0.244 | 0.406 | 0.244 | 0.427 | 0.428 | ||
| GPT-4o | Base | 0.248 | 0.489 | 0.284 | 0.425 | 0.328 | 0.003 | 0.331 | 0.006 |
| Gemini 1.5-flash | Base | 0.467 | 0.173 | 0.552 | 0.09 | 0.479 | 0.353 | ||
| Claude 3.5-sonnet | Base | -0.261 | 0.467 | -0.321 | 0.365 | 0.312 | 0.367 | ||
| GPT-4o | Zero-shot CoT | 0.345 +13% | 0.328 | 0.357 +10% | 0.313 | 0.299 -4% | 0.097 | 0.313 -3% | 0.031 |
| Gemini 1.5-flash | Zero-shot CoT | 0.018 -84% | 0.962 | 0.236 -62% | 0.511 | 0.376 -20% | 0.327 -4% | ||
| Claude 3.5-sonnet | Zero-shot CoT | -0.345 -7% | 0.328 | -0.309 +1% | 0.385 | 0.108 -30% | 0.068 | 0.081 -45% | 0.082 |
| GPT-4o | ArtCoT | 0.576 +43% | 0.08 | 0.721 +61% | 0.001 | 0.591 +39% | 0.548 +32% | ||
| Gemini 1.5-flash | ArtCoT | 0.697 +43% | 0.025 | 0.782 +51% | 0.007 | 0.624 +28% | 0.577 +35% | ||
| Claude 3.5-sonnet | ArtCoT | 0.612 +69% | 0.059 | 0.600 +70% | 0.066 | 0.492 +26% | 0.487 +19% | ||
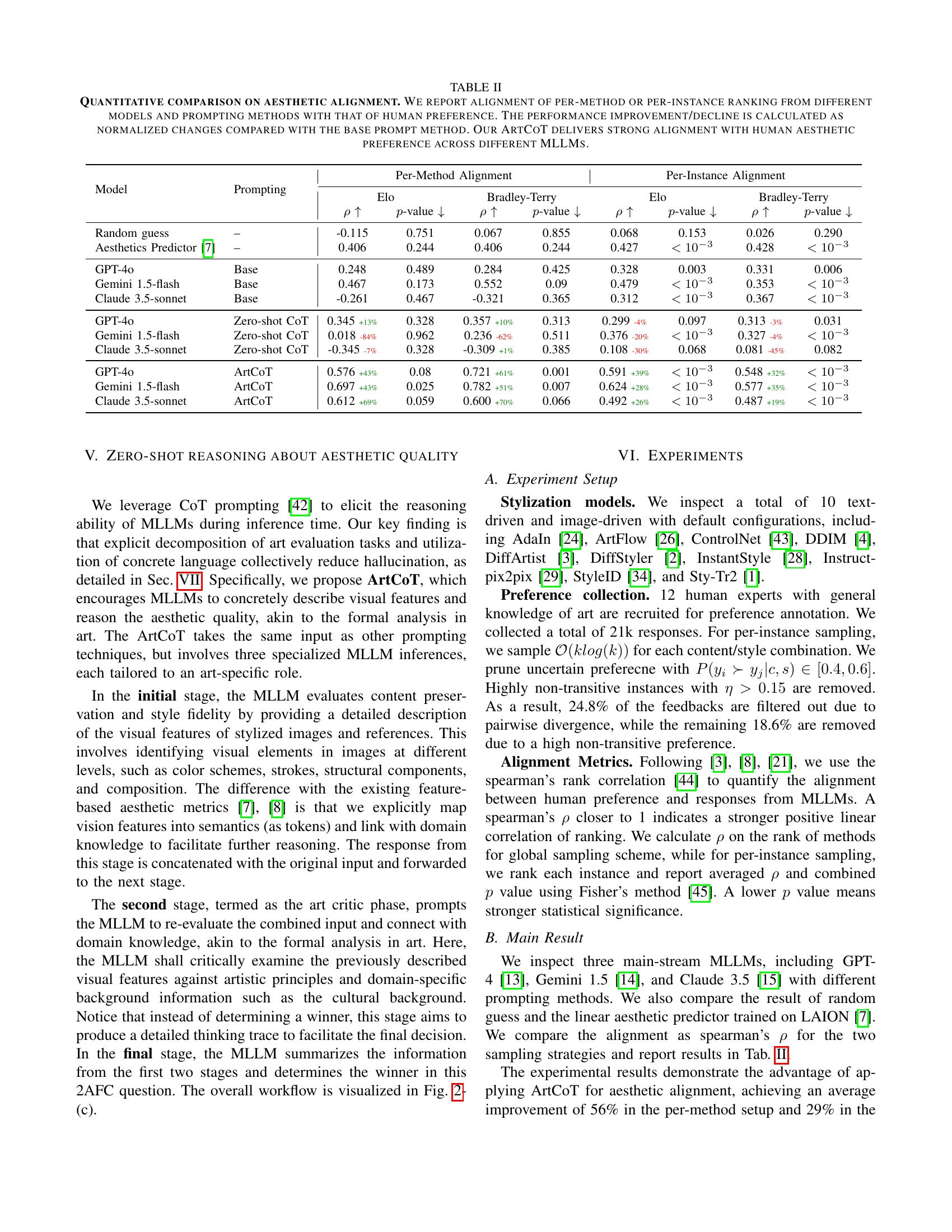
🔼 This table presents a quantitative analysis of the alignment between Multimodal Large Language Models (MLLMs) and human aesthetic preferences in evaluating stylized images. It compares the performance of three different MLLMs (GPT-4, Gemini 1.5-flash, and Claude 3.5-sonnet) across various prompting methods: a baseline, zero-shot Chain-of-Thought (CoT), and the proposed ArtCoT. Alignment is measured using two metrics: Elo and Bradley-Terry, calculated for both per-method and per-instance rankings. The results show the degree of agreement between the MLLMs’ rankings and human preference rankings, with percentage improvements/declines calculated relative to the baseline prompting method. ArtCoT consistently demonstrates the strongest alignment, showcasing its effectiveness in improving MLLMs’ aesthetic reasoning.
read the caption
TABLE II: Quantitative comparison on aesthetic alignment. We report alignment of per-method or per-instance ranking from different models and prompting methods with that of human preference. The performance improvement/decline is calculated as normalized changes compared with the base prompt method. Our ArtCoT delivers strong alignment with human aesthetic preference across different MLLMs.
| Method | Subjectivity | Subjective word frequency () |
|---|---|---|
| Zero-Shot CoT | 0.44 | 20.15 |
| ArtCoT | 0.23 | 5.51 |
🔼 This table presents a quantitative analysis of response subjectivity using different prompting methods for Multimodal Large Language Models (MLLMs). It compares the subjectivity scores (a lower score indicates less subjectivity) and the frequency of subjective words in MLLM responses generated using three different prompting methods: the baseline method, a zero-shot Chain of Thought (CoT) method, and the proposed ArtCoT method. The results demonstrate that ArtCoT significantly reduces response subjectivity compared to the other methods, making the MLLM’s responses more objective and aligned with human aesthetic preferences.
read the caption
TABLE III: Response subjectivity from different prompting method. Responses from MLLM prompted by ArtCoT are less subjective.
| CS-analyzer | Critic | Per-method | Per-instance |
|---|---|---|---|
| ✗ | ✓ | 0.630 | 0.532 |
| ✓ | ✗ | 0.531 | 0.366 |
| ✓ | ✓ | 0.739 | 0.607 |
🔼 This table presents the results of an ablation study on the ArtCoT method. The ArtCoT method, designed for evaluating the aesthetic alignment of multimodal large language models (MLLMs), consists of three components: a content/style analyzer, an art critic, and a summarizer. This ablation study systematically removes each component to determine its individual contribution to the overall performance. The table shows the impact of removing each component (content/style analyzer and art critic) on the aesthetic alignment performance, measured using two metrics: per-method Spearman’s rank correlation (ρ) and per-instance Spearman’s rank correlation (ρ). The table demonstrates that the complete ArtCoT method, using all three components, achieves the best aesthetic alignment.
read the caption
TABLE IV: Ablation on component of ArtCoT. We ablate the content/style analyzer and the art critic. The full method achieves the best aesthetic alignment.
| Content | Style | Resolution | Per-method | Per-instance |
|---|---|---|---|---|
| ✓ | ✓ | 1/4 | 0.630 -42% | 0.432 -44% |
| ✓ | ✓ | 1/8 | 0.502 -91% | 0.285 -82% |
| ✗ | ✗ | 1/2 (default) | 0.476 -100% | 0.416 -49% |
| ✗ | ✓ | 1/2 (default) | 0.678 -23% | 0.465 -36% |
| ✓ | ✗ | 1/2 (default) | 0.557 -69% | 0.521 -22% |
| ✓ | ✓ | 1/2 (default) | 0.739 | 0.607 |
🔼 This table presents an ablation study on the impact of image resolution and input modalities (content image and style prompt) on the performance of aesthetic alignment evaluation. Specifically, it shows how the correlation (ρ) between human and model rankings changes when different combinations of image resolution (sub-sampled factors of 1/4, 1/8, and 1/2) and input modalities (presence or absence of content image and/or style prompt) are used. The correlation values are averaged across two different ranking methods (Elo and Bradley-Terry). This helps to understand which input factors are most crucial for accurate aesthetic alignment.
read the caption
TABLE V: Ablation on image resolution and source information. We report the correlation ρ𝜌\rhoitalic_ρ (averaged from Elo and Bradley-Terry) of different input setups: content image, style prompt, and image sub-sampling factor.
| Content | Style | ||||
| Source | Generated | MS-COCO | SA-1B | WikiArt | DiffusionDB |
| Number | 500 | 250 | 250 | 764 | 236 |
🔼 Table VI details the composition of the MM-StyleBench dataset, highlighting the diverse sources used to gather content and style data. It aims to show how the dataset avoids bias by drawing from a variety of sources, including text-to-image generated content, existing image datasets (SA-1B, MS-COCO), and established art databases (WikiArt, DiffusionDB). The table indicates the number of samples contributed by each source to both the content and style subsets of the dataset.
read the caption
TABLE VI: Content and Style Sources MM-StyleBench is built from diverse sources to eliminate bias.
| Base Prompt | Zero-Shot CoT | ArtCoT | ||
| C-S Analyzer | Art Critic | Summarizer | ||
| ‘[IMAGE]‘ You are an expert in fine art. A source image (top) and two different stylized images (bottom) in the style of ‘[STYLE]‘ are presented to you. Consider both the content and style, which stylized image is better in terms of overall aesthetic quality as an artwork? Return your decision in a Python Dict, [’winner’:int]. ‘0‘ means the left is better while ‘1‘ means the right is better. Do not answer any other things. | ‘[IMAGE]‘ {”request”: ”You are an expert in fine art. A source image (top) and two different stylized images (bottom) in the style of ‘style‘ are presented to you. Consider both the content and style, which stylized image is better in terms of overall aesthetic quality as an artwork?”. Return the reason and your decision in short in format of a Python Dict ’thinking’:str, ’winner’:int. ‘0‘ means the left is better while ‘1‘ means the right is better.”, ”response”: ”{’thinking’: ’ Let’s’ think step by step, | ‘[IMAGE]‘ You are an expert in fine art. A source image (top) Two stylized images (bottom left and bottom right) in the style of ‘[STYLE]‘ are presented to you. Compare the content preservation and style fidelity of the two images, which one is better. Return your answer in a Python Dict, [’style_reason’:str, ’content_reason’:str, ’style_winner’:int, ’content_winner’:int]. ‘0‘ means the left is better while ‘1‘ means the right is better. Do not include any other string in your response. | ‘[IMAGE]‘ Take a closer look at the two stylized images at the bottom in the style of ‘[STYLE]‘. As an expert in art, do you agree with above analysis? Compare and consider the following questions. What visual features is essential for the style of ‘[STYLE]‘? Is the content at top well-preserved in the specific art style? Is there any artifact, distortion or inharmonious color patterns in either painting? Return your answer in a Python Dict, [reflection’:str]. | ‘[IMAGE]‘ Now we summarize. Based on above analysis and reflection, which stylized image at the bottom is better in terms of overall aesthetic quality as an **painting of the original content (top) in another style**? Return your answer in a Python Dict, [’winner’:int]. ‘0‘ means the left is better while ‘1‘ means the right is better. Do not include any other string in your response. |
🔼 This table presents the different prompt templates used in the paper for various prompting methods. It shows how the prompts are structured for each method to elicit different types of responses from the multimodal large language models (MLLMs). The prompts include placeholders for the style prompt ([STYLE]) and the image tokens ([IMAGE]). The prompts are designed to encourage reasoning, analysis, comparison, and summarization related to aesthetic evaluation.
read the caption
TABLE VII: Template for different prompting methods. [STYLE] stands for placeholder for the style prompt, and [IMAGE] stands for placeholder for image tokens.
Full paper#