TL;DR#
Current first-in-first-out (FIFO) video diffusion methods struggle to maintain long-range temporal consistency in generated videos due to the lack of correspondence modeling across frames and the independent Gaussian noise enqueued at the tail. This leads to issues with content discrepancies and visual coherence.
The proposed Ouroboros-Diffusion addresses these issues with three key strategies. First, it uses a coherent tail latent sampling to improve structural consistency by extracting low-frequency components from prior frames to inform the generation of new frames, ensuring smooth transitions. Second, a Subject-Aware Cross-Frame Attention (SACFA) mechanism aligns subjects across frames to enhance subject consistency. Third, self-recurrent guidance leverages information from previous cleaner frames to guide the denoising of noisier frames, which further improves overall consistency. The results demonstrate the superiority of Ouroboros-Diffusion, particularly in terms of subject consistency, motion smoothness, and temporal consistency.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to generate long, consistent videos without extensive fine-tuning, a significant challenge in video diffusion models. It addresses the limitations of existing methods by focusing on both structural and subject consistency, opening new avenues for research in long video generation and potentially impacting applications in film, animation, and virtual reality.
Visual Insights#
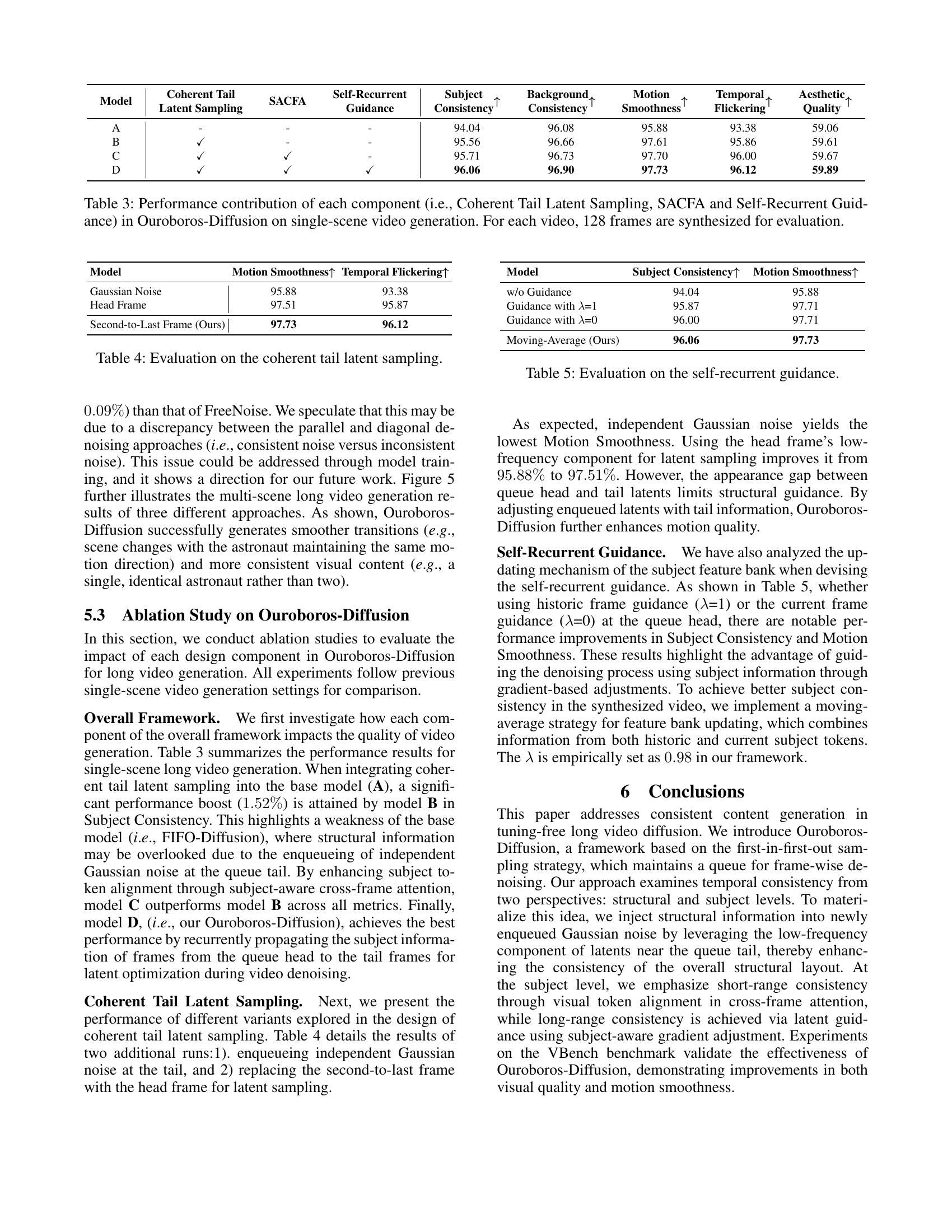
🔼 This figure illustrates the processes of FIFO-Diffusion and Ouroboros-Diffusion for generating long videos without the need for model fine-tuning. The top panel shows FIFO-Diffusion, where a queue of video frames with progressively increasing noise levels is maintained. Clean frames are continuously output from the queue’s head while noisy frames are added to the tail. The bottom panel depicts Ouroboros-Diffusion, which enhances structural and content consistency through novel techniques like coherent tail latent sampling, subject-aware cross-frame attention (SACFA), and self-recurrent guidance. These additions aim to resolve the temporal inconsistencies often found in FIFO-Diffusion’s output.
read the caption
Figure 1: Illustration of FIFO-Diffusion (Kim et al. 2024) (top) and our Ouroboros-Diffusion (bottom) for tuning-free long video generation.
| Approach | Subject Consistency | Background Consistency | Motion Smoothness | Temporal Flickering | Aesthetic Quality | |
| StreamingT2V (Henschel et al. 2024) | 90.70 | 95.46 | 97.34 | 95.93 | 54.98 | |
| StreamingT2V-VideoTetris (Tian et al. 2024) | 89.06 | 94.80 | 96.79 | 95.30 | 52.89 | |
| FIFO-Diffusion (Kim et al. 2024) | 94.04 | 96.08 | 95.88 | 93.38 | 59.06 | |
| FreeNoise (Qiu et al. 2024) | 94.50 | 96.45 | 95.42 | 93.62 | 59.32 | |
| Ouroboros-Diffusion | 96.06 | 96.90 | 97.73 | 96.12 | 59.89 |
🔼 This table presents a quantitative comparison of different video generation approaches on the VBench benchmark, focusing on single-scene videos. Each method generated 128 frames per video. The table shows the performance of each method across several metrics, including Subject Consistency, Background Consistency, Motion Smoothness, Temporal Flickering, and Aesthetic Quality. These metrics provide insights into the visual coherence, temporal stability, and overall aesthetic appeal of the generated videos.
read the caption
Table 1: Single-scene video generation performances on VBench. For each video, 128 frames are synthesized for evaluation.
In-depth insights#
FIFO Diffusion Limits#
FIFO (First-In-First-Out) diffusion, while innovative for long video generation, suffers from key limitations. Its diagonal denoising approach, though efficient, lacks explicit modeling of global visual consistency. As frames are processed, older frames are discarded, preventing the model from leveraging information across the entire video for coherent generation. This results in inconsistencies over time and leads to subject drift and other visual artifacts, particularly as video length increases. Additionally, the independent sampling of Gaussian noise at the queue tail creates a discrepancy between newly enqueued noisy frames and partially denoised frames already in the queue, further exacerbating temporal inconsistencies. These limitations highlight the need for techniques that explicitly model global context and ensure consistent information flow throughout the generation process, ultimately enhancing the visual quality and temporal coherence of generated long videos.
Ouroboros’s Design#
Ouroboros-Diffusion’s design centers on seamlessly integrating information across time to enhance video generation consistency. Three core principles guide its framework: present infers future (predicting future frames from current ones), present influences present (improving coherence among contemporaneous frames), and past informs present (leveraging past information). Coherent tail latent sampling addresses structural inconsistencies by using low-frequency components from previous frames, ensuring smooth transitions. The Subject-Aware Cross-Frame Attention (SACFA) mechanism improves subject consistency by aligning subjects across short segments. Finally, self-recurrent guidance uses information from earlier clean frames, fostering rich contextual interactions for enhanced global consistency and preventing the appearance changes. This multifaceted approach creates temporally coherent and visually consistent long-form videos. The Ouroboros metaphor, symbolizing self-renewal and wholeness, effectively encapsulates this design philosophy.
Cross-Frame Attention#
Cross-frame attention, in the context of video generation, is a crucial mechanism for enhancing temporal consistency. It addresses the challenge of maintaining coherent visual information across consecutive frames by explicitly modeling relationships between them. Instead of treating each frame independently, cross-frame attention allows the model to leverage contextual information from neighboring frames to improve the quality of the current frame’s generation. This is particularly important for generating long videos, where maintaining consistency over extended sequences is difficult. Effective cross-frame attention mechanisms carefully consider the relationships between different features (e.g., objects, motion, background) in the frames, aligning relevant elements to ensure a smooth and natural transition. This can involve various strategies, such as attending to specific regions of interest or incorporating temporal information to guide the attention process. By explicitly modeling these inter-frame dependencies, cross-frame attention helps to reduce visual inconsistencies such as flickering, abrupt changes, or semantic drift, ultimately resulting in higher-quality and more realistic-looking videos.
Recurrent Guidance#
The concept of “Recurrent Guidance” in the context of long video generation is crucial for maintaining temporal consistency. It suggests a mechanism where past information is leveraged to inform the generation of future frames. This is a significant improvement over methods that treat frame generation independently. The use of a “Subject Feature Bank” to store information about previously generated subjects is a key innovation. This bank acts as a form of memory, allowing the model to maintain coherence in the visual elements across the length of the video. This recurrent guidance, combined with the Subject-Aware Cross-Frame Attention (SACFA), ensures that not only structural consistency but also subject-level consistency is maintained. By guiding the denoising process using this long-term memory of past subjects, the model reduces inconsistencies and improves temporal coherence. The effectiveness of this approach, as shown by the experimental results, highlights the importance of employing long-range memory and contextual information in complex generative processes like long video synthesis. The moving average strategy used to update the subject feature bank further refines this memory, allowing for smooth transitions and avoiding abrupt changes. The use of the gradient is an elegant way to subtly influence the ongoing video generation, maintaining visual continuity and preventing the degradation often seen in purely sequential approaches.
Ablation Study#
The ablation study systematically evaluates the contribution of each component in the Ouroboros-Diffusion model. By removing components one at a time and measuring the performance drop, the study isolates the impact of each part. Removing the coherent tail latent sampling significantly reduces subject consistency, highlighting its importance in maintaining visual coherence throughout the generated video. Similarly, excluding the Subject-Aware Cross-Frame Attention (SACFA) leads to a noticeable decrease in subject consistency, emphasizing the role of SACFA in aligning subjects across frames. Finally, the absence of self-recurrent guidance negatively impacts both subject consistency and motion smoothness, underscoring the effectiveness of using past frame information to guide the denoising process. The results of this ablation study clearly show that each proposed component plays a crucial role in enhancing the overall performance and it validates the design choices of the proposed Ouroboros-Diffusion model. The ablation study also helps to quantify the specific contribution of each component, thus providing strong evidence for the proposed framework’s design and efficacy.
More visual insights#
More on figures

🔼 Ouroboros-Diffusion is composed of three key components working together to improve long video generation: 1) Coherent Tail Latent Sampling: Instead of using random noise, this component intelligently samples the next frame’s latent representation from the previous frame’s low-frequency component, ensuring smoother transitions and structural consistency. 2) Subject-Aware Cross-Frame Attention (SACFA): This module aligns subjects across consecutive frames by using subject tokens from multiple frames as a context, enhancing visual coherence. 3) Self-Recurrent Guidance: Using information from all previously generated clean frames, this mechanism provides global information to guide the denoising of the noisier frames in the queue, leading to more consistent and contextualized results. The figure visually depicts how these components interact within the Ouroboros-Diffusion framework.
read the caption
Figure 2: An overview of our Ouroboros-Diffusion. The whole framework (a) contains three key components: coherent tail latent sampling in queue manager , (b) Subject-Aware Cross-frame Attention (SACFA), and (c) self-recurrent guidance. The coherent tail latent sampling in queue manager derives the enqueued frame latents at the queue tail to improve structural consistency. The Subject-Aware Cross-frame Attention (SACFA) aligns subjects across frames within short segments for better visual coherence. The self-recurrent guidance leverages information from all historical cleaner frames to guide the denoising of noisier frames, fostering rich and contextual global information interaction.

🔼 This figure details the process of coherent tail latent sampling within the Ouroboros-Diffusion queue manager. It shows how, instead of using purely random Gaussian noise, the model generates the new latent vector for the tail of the queue by combining the low-frequency components of the second-to-last frame latent (obtained via a Fast Fourier Transform filter) with the high-frequency components of random Gaussian noise. This approach aims to maintain structural consistency between consecutive frames while still introducing necessary dynamic variation.
read the caption
Figure 3: The detailed illustration of coherent tail latent sampling in the queue manager.

🔼 This figure displays visual results of single-scene long video generation using five different methods: StreamingT2V, StreamingT2V-VideoTetris, FIFO-Diffusion, FreeNoise, and Ouroboros-Diffusion. Each method was tasked with generating a video based on the prompt: “A cat wearing sunglasses and working as a lifeguard at a pool.” The figure allows for a direct visual comparison of the different models’ ability to maintain visual consistency, motion smoothness, and overall video quality when generating long-form videos. The generated videos are shown as a sequence of frames for each method.
read the caption
Figure 4: Visual examples of single-scene long video generation by different approaches. The text prompt is “A cat wearing sunglasses and working as a lifeguard at a pool.”

🔼 Figure 5 presents a comparison of multi-scene long video generation results from four different methods: Ouroboros-Diffusion, FreeNoise, and FIFO-Diffusion. Each method was given three sequential prompts describing an astronaut riding different vehicles in space (horse, dragon, motorcycle). The figure visually demonstrates the differences in subject consistency, background consistency, and overall video coherence produced by each approach. The goal is to showcase how Ouroboros-Diffusion excels in maintaining consistent visual elements and smooth transitions between the scenes.
read the caption
Figure 5: Visual examples of multi-scene long video generation by different approaches. The multi-scene prompts are: 1). an astronaut is riding a horse in space; 2). an astronaut is riding a dragon in space; 3). an astronaut is riding a motorcycle in space.
More on tables
| Approach | Subject Consistency | Background Consistency | Motion Smoothness | Temporal Flickering | Aesthetic Quality |
| FIFO-Diffusion (Kim et al. 2024) | 93.96 | 96.17 | 96.36 | 93.59 | 60.12 |
| FreeNoise (Qiu et al. 2024) | 95.07 | 96.52 | 96.57 | 95.06 | 61.26 |
| Ouroboros-Diffusion | 95.73 | 96.82 | 97.77 | 95.82 | 61.17 |
🔼 This table presents a quantitative comparison of different video generation methods on the VBench benchmark, focusing on multi-scene videos. Each method generated 256 frames per video. The metrics evaluated include Subject Consistency, Background Consistency, Motion Smoothness, Temporal Flickering, and Aesthetic Quality, providing a comprehensive assessment of the generated videos’ visual fidelity and temporal coherence across multiple scenes.
read the caption
Table 2: Multi-scene video generation performances on VBench. For each video, 256 frames are synthesized for evaluation.
| Model | Coherent Tail Latent Sampling | SACFA | Self-Recurrent Guidance | Subject Consistency | Background Consistency | Motion Smoothness | Temporal Flickering | Aesthetic Quality |
| A | - | - | - | 94.04 | 96.08 | 95.88 | 93.38 | 59.06 |
| B | ✓ | - | - | 95.56 | 96.66 | 97.61 | 95.86 | 59.61 |
| C | ✓ | ✓ | - | 95.71 | 96.73 | 97.70 | 96.00 | 59.67 |
| D | ✓ | ✓ | ✓ | 96.06 | 96.90 | 97.73 | 96.12 | 59.89 |
🔼 This table presents an ablation study evaluating the individual and combined contributions of three key components of the Ouroboros-Diffusion model on single-scene video generation. The components analyzed are: Coherent Tail Latent Sampling, Subject-Aware Cross-Frame Attention (SACFA), and Self-Recurrent Guidance. The table shows the performance of the model with different combinations of these components, using standard video generation metrics, to understand their impact on overall video quality. Each experiment involves generating 128 frames for each video to ensure sufficient evaluation data.
read the caption
Table 3: Performance contribution of each component (i.e., Coherent Tail Latent Sampling, SACFA and Self-Recurrent Guidance) in Ouroboros-Diffusion on single-scene video generation. For each video, 128 frames are synthesized for evaluation.
| Model | Motion Smoothness | Temporal Flickering |
| Gaussian Noise | 95.88 | 93.38 |
| Head Frame | 97.51 | 95.87 |
| Second-to-Last Frame (Ours) | 97.73 | 96.12 |
🔼 This table presents an ablation study on the coherent tail latent sampling method used in Ouroboros-Diffusion. It compares the performance of using Gaussian noise, the head frame’s low-frequency component, and the second-to-last frame’s low-frequency component (the proposed method) for generating the tail latent. The comparison is made based on Motion Smoothness and Temporal Flickering metrics.
read the caption
Table 4: Evaluation on the coherent tail latent sampling.
| Model | Subject Consistency | Motion Smoothness |
| w/o Guidance | 94.04 | 95.88 |
| Guidance with =1 | 95.87 | 97.71 |
| Guidance with =0 | 96.00 | 97.71 |
| Moving-Average (Ours) | 96.06 | 97.73 |
🔼 This table presents an ablation study evaluating the impact of the self-recurrent guidance mechanism within the Ouroboros-Diffusion model. It compares the performance on Motion Smoothness and Temporal Flickering metrics across different configurations: using no guidance, guidance from the head frame only, guidance from the second-to-last frame (the Ouroboros-Diffusion approach), and a moving average of guidance from multiple frames. The results illustrate how different guidance strategies affect the model’s ability to generate temporally consistent and smoothly moving videos.
read the caption
Table 5: Evaluation on the self-recurrent guidance.
Full paper#