TL;DR#
Current LLM evaluation often relies on multiple-choice question accuracy, neglecting confidence. This paper investigates how LLMs’ confidence changes when asked to provide reasoning before answering. This is an important factor because the accuracy metric alone does not reflect the certainty the LLM has in its own answers. The study explores whether explaining the answer influences the LLM’s confidence level.
The study evaluates seven LLMs across diverse topics. The results show that LLMs exhibit higher confidence when reasoning precedes the answer, regardless of correctness. This mirrors human behavior, where explaining an answer enhances confidence. The findings highlight limitations of current LLM evaluation methods and suggest a need for more nuanced approaches that consider both accuracy and confidence.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a critical limitation in current LLM evaluation methods and offers new insights into how LLMs form confidence in their answers. This understanding is vital for improving LLM development and assessment, which is a key area of focus in AI research. The study’s findings will influence the design of more robust evaluation strategies and inspire new research into the relationship between reasoning, confidence, and accuracy in both LLMs and humans.
Visual Insights#

🔼 This figure presents a comparison of the accuracy achieved by different large language models (LLMs) when answering questions from the Massive Multitask Language Understanding (MMLU) benchmark. Two prompting methods are compared: a ‘direct’ prompt, where the model is asked to answer directly, and a ‘Chain of Thought’ (CoT) prompt, where the model is first asked to provide reasoning before selecting an answer. The chart displays the accuracy rates for each LLM under both prompting methods, allowing for a direct visual comparison of the effect of CoT prompting on model performance across different LLMs.
read the caption
Figure 1: Accuracy Comparison Across Models on MMLU Categories with Direct and CoT Prompts
In-depth insights#
LLM Confidence Metrics#
LLM confidence metrics are crucial for evaluating the reliability and trustworthiness of Large Language Models (LLMs). Current approaches often rely on the accuracy of LLM outputs, but this alone is insufficient. Confidence scores, derived from the model’s internal probability distributions, offer a more nuanced evaluation. However, these probabilities present challenges. LLMs may exhibit overconfidence, assigning high probabilities to incorrect answers, particularly when employing reasoning steps before outputting a final answer. This suggests that the act of reasoning itself, while often improving accuracy, can also inflate the model’s perceived certainty, irrespective of the answer’s correctness. Therefore, a comprehensive approach needs to examine both accuracy and the model’s confidence, ideally with a focus on understanding how these metrics interact and how confidence is affected by different prompt strategies (e.g., chain-of-thought prompting). Further research is needed to calibrate LLM confidence scores and to develop more robust metrics that accurately reflect the models’ true uncertainty. This will involve a deeper investigation into the internal mechanisms of LLMs and how those relate to the expressed confidence in their outputs.
CoT’s Impact on LLMs#
The study investigates Chain of Thought (CoT)’s influence on Large Language Models (LLMs) performance and confidence in answering multiple-choice questions (MCQs). CoT prompting, which encourages LLMs to articulate their reasoning process before selecting an answer, demonstrably boosts their self-reported confidence levels. This effect is observed regardless of whether the final answer is correct or incorrect, suggesting that CoT introduces a bias in LLMs’ confidence estimations. The increased confidence, even with incorrect answers, may stem from the LLM’s internal processing of the reasoning steps, making it more certain of its output, irrespective of accuracy. This phenomenon aligns with similar observations in human behavior where explaining enhances confidence. The research highlights that LLM-estimated probabilities should be interpreted cautiously due to the intrinsic limitations and biases revealed by this investigation. While CoT improves accuracy in some question categories, particularly those requiring complex reasoning, its impact on confidence surpasses its impact on accuracy. This emphasizes that overconfidence in LLMs, even when using CoT, is a notable concern. Further research is needed to better understand and mitigate these biases to improve the reliability of LLM evaluations.
Reasoning and Accuracy#
The interplay between reasoning and accuracy in LLMs is a critical area of research. The paper investigates how prompting LLMs to reason before answering multiple-choice questions (MCQs) affects both their accuracy and their self-reported confidence. A key finding is that the act of reasoning increases LLM confidence, irrespective of whether the final answer is correct or not. This suggests that the reasoning process itself influences the probability assigned to the selected answer, regardless of its truthfulness. This observation highlights a potential limitation of using LLMs’ self-reported probabilities as a direct measure of confidence, since confidence is seemingly inflated by the reasoning step. Further study is needed to understand how these behaviors relate to human cognition, and how to design better evaluation methods that account for this disconnect between reasoning, confidence, and actual accuracy. The research emphasizes the need for caution when interpreting LLMs’ confidence scores, particularly in cases requiring more complex reasoning.
LLM vs. Human Reasoning#
A comparison of Large Language Model (LLM) and human reasoning reveals key differences. Humans utilize diverse cognitive processes, including intuition, experience, and analytical thinking, to solve problems and make judgments, often integrating multiple sources of information. In contrast, LLMs operate algorithmically, relying on statistical patterns in their training data to generate outputs. While LLMs can mimic human-like reasoning in certain contexts, they lack the fundamental understanding and flexibility of human cognition. LLMs are prone to overconfidence, even when incorrect, a characteristic less prevalent in humans. This difference highlights the limitations of LLMs in complex tasks requiring genuine understanding and nuanced judgment. Furthermore, human reasoning is adaptable and context-aware, adjusting strategies depending on the specific situation, while LLM approaches remain relatively consistent. A deeper understanding of these differences is crucial for developing more robust and reliable AI systems.
Future Research Needs#
Future research should prioritize a deeper investigation into the discrepancy between LLM confidence and accuracy, especially when reasoning is involved. It’s crucial to understand why LLMs become more confident, even when wrong, after generating reasoning. Further analysis should explore whether this overconfidence stems from inherent limitations in probabilistic prediction or from a deeper issue related to how LLMs process and weigh evidence. Comparative studies directly comparing LLM reasoning processes with human reasoning are needed to shed light on the nature of this discrepancy. Benchmarking across diverse question types and domains is necessary to determine if this overconfidence is consistent across various reasoning tasks. Finally, research should focus on developing evaluation metrics that are less susceptible to the biases of LLM self-reported confidence, perhaps by incorporating other qualitative and quantitative measures of performance.
More visual insights#
More on figures

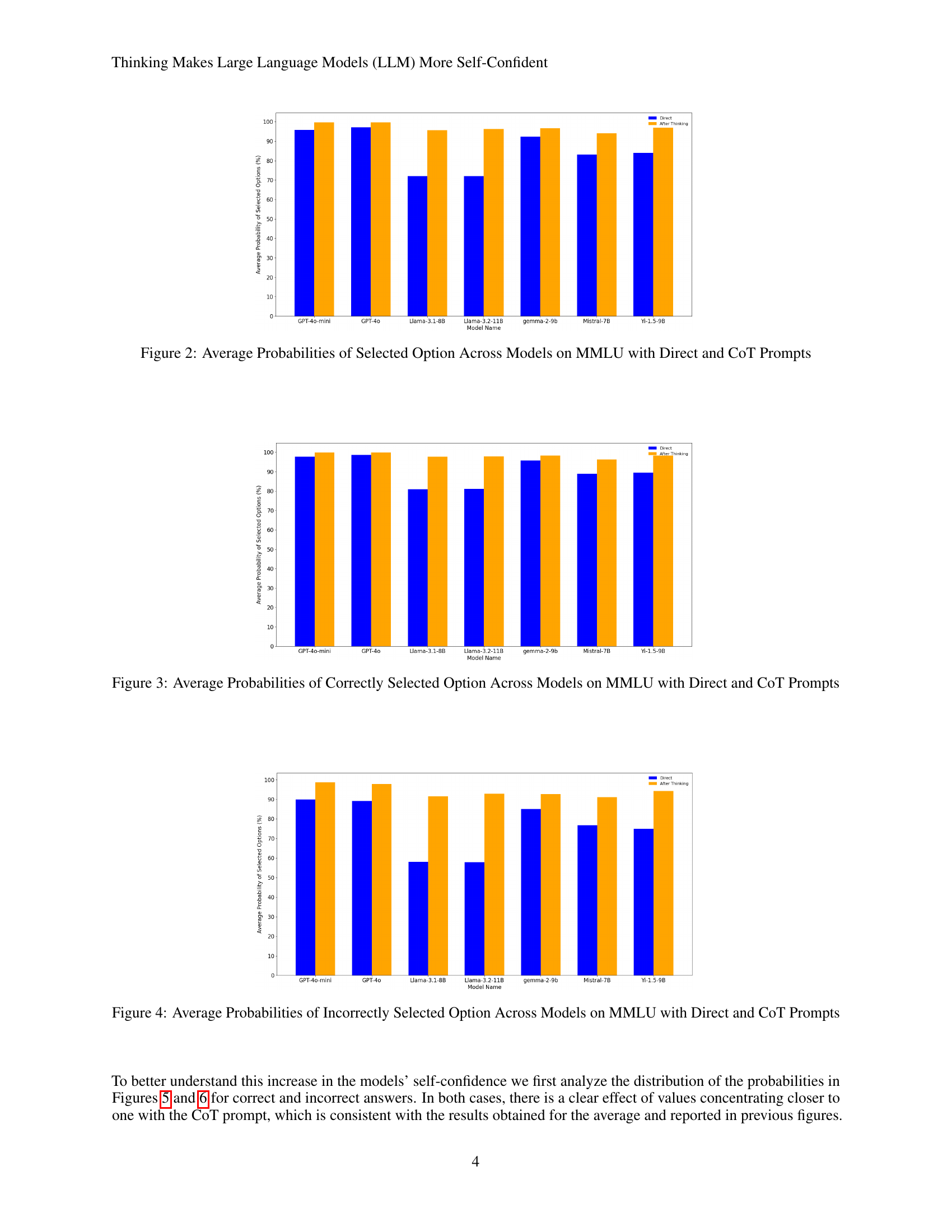
🔼 This figure displays the average probability assigned by seven different Large Language Models (LLMs) to their selected answer option across the Massive Multitask Language Understanding (MMLU) benchmark. It compares the confidence levels when the models answer directly versus when they utilize chain-of-thought (CoT) prompting, which involves generating reasoning before selecting an answer. The graph visually represents the average confidence across all questions within the MMLU dataset for each model, providing a comparison of model certainty with and without the explicit reasoning step.
read the caption
Figure 2: Average Probabilities of Selected Option Across Models on MMLU with Direct and CoT Prompts

🔼 This figure displays a bar chart comparing the average probabilities of correctly selected options across seven different Large Language Models (LLMs) when using two distinct prompting methods: ‘Direct’ and ‘Chain of Thought’ (CoT). The x-axis represents the different LLMs tested, and the y-axis shows the average probability of the model selecting the correct answer for the MMLU (Massive Multitask Language Understanding) benchmark. Each LLM has two bars, one for the Direct prompt, where the model answers directly, and one for the CoT prompt, where the model first provides reasoning before selecting an answer. The chart visually represents the difference in confidence levels (reflected in the probabilities) between these two prompting techniques when the models give correct answers. This allows for comparison of how the confidence of each model is affected by reasoning before answering.
read the caption
Figure 3: Average Probabilities of Correctly Selected Option Across Models on MMLU with Direct and CoT Prompts

🔼 This figure displays a comparison of the average probabilities assigned to incorrectly chosen options across multiple Large Language Models (LLMs). The comparison is made between two prompting methods: ‘Direct,’ where the model directly selects an answer, and ‘CoT’ (Chain of Thought), where the model provides reasoning before selecting an answer. The x-axis represents the different LLMs tested, and the y-axis represents the average probability of selecting an incorrect option. The figure visually demonstrates whether the LLMs exhibit higher confidence (higher probability) in their incorrect answers when using the CoT prompting method compared to the Direct method.
read the caption
Figure 4: Average Probabilities of Incorrectly Selected Option Across Models on MMLU with Direct and CoT Prompts

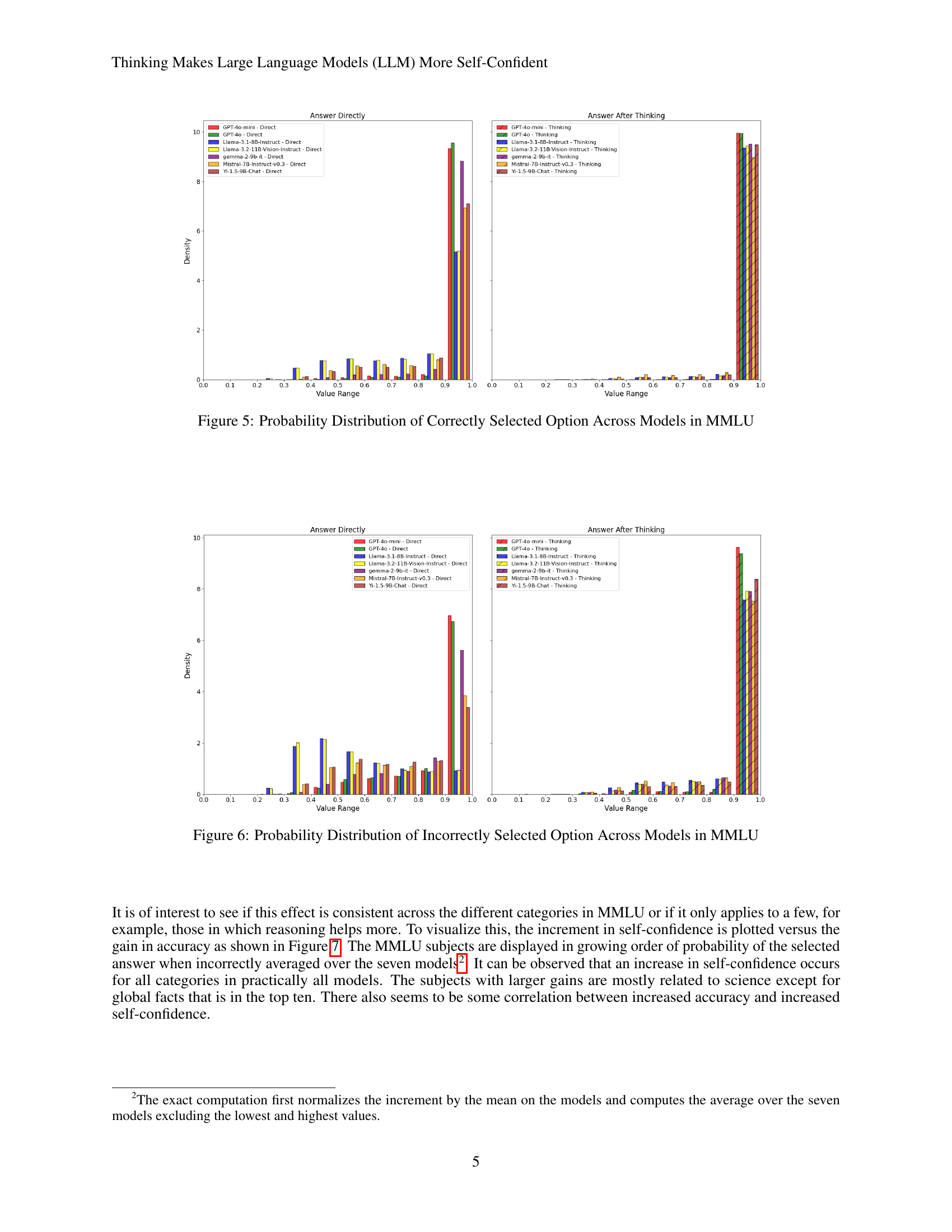
🔼 This figure presents a detailed comparison of the probability distributions for correctly selected options across different Large Language Models (LLMs) evaluated on the Massive Multitask Language Understanding (MMLU) benchmark. Each LLM’s distribution is shown separately for both ‘direct’ and ‘chain-of-thought’ (CoT) prompting methods. The x-axis represents the probability range (0 to 1), and the y-axis represents the frequency or density of answers falling within each probability bin. This allows for a visual analysis of the confidence levels exhibited by each model under different prompting conditions. The goal is to show how the distribution of probabilities changes with CoT prompting, indicating higher confidence (probabilities closer to 1) in the correctly selected answers.
read the caption
Figure 5: Probability Distribution of Correctly Selected Option Across Models in MMLU

🔼 This figure presents the distribution of probabilities assigned to incorrectly selected options across various Large Language Models (LLMs) evaluated on the Massive Multitask Language Understanding (MMLU) benchmark. Each bar represents an LLM, and different colors represent the probability range of the incorrectly chosen answer. The distribution of probabilities demonstrates that, for incorrectly answered questions, many LLMs exhibit high confidence scores in their wrong answers, particularly when chain of thought (CoT) prompting was utilized. This visualization helps to illustrate the relationship between the confidence estimates of the LLMs and the accuracy of their responses, particularly highlighting the cases where models are both incorrect and highly confident.
read the caption
Figure 6: Probability Distribution of Incorrectly Selected Option Across Models in MMLU

🔼 Figure 7 is a heatmap visualizing the changes in model confidence and accuracy across different subjects within the Massive Multitask Language Understanding (MMLU) benchmark. It compares the performance of seven different large language models (LLMs) using two prompting techniques: direct answering and chain-of-thought (CoT) prompting. The heatmap shows the increase (or decrease) in accuracy and the change in the probability assigned to the selected option (representing confidence). This breakdown is presented separately for correctly and incorrectly answered questions, providing a nuanced view of how reasoning affects both accuracy and confidence levels across various tasks within the MMLU.
read the caption
Figure 7: Increments in accuracy, in the probability of the selected option, in the probability of the selected option for correct answers and in the probability of the selected option for incorrect answers for the different subjects in MMLU across models.
Full paper#