TL;DR#
Many large language models (LLMs) predominantly focus on high-resource languages like English, neglecting low-resource languages crucial for global healthcare access. This study investigates the challenges of developing LLMs proficient in both multilingual understanding and medical knowledge, specifically focusing on Arabic. It highlights that simply translating existing medical datasets is not a solution, because it doesn’t guarantee satisfactory performance on clinical tasks in the target language.
The researchers experimented with different language ratios in training data and various fine-tuning methods. They found that the optimal language mix varies significantly across different medical tasks. Larger models with carefully balanced language ratios achieved superior performance, suggesting that data-intensive pretraining methods are essential for optimal multilingual medical performance. These findings offer important guidance for the development of more inclusive medical AI systems suitable for diverse linguistic communities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multilingual NLP and healthcare AI because it directly addresses the limitations of current LLMs in handling low-resource languages for clinical tasks. The findings on optimal data mixes and the challenges of simple translation will guide future research toward building more effective and inclusive medical AI systems. Its focus on Arabic, a low-resource language with unique linguistic features, makes it especially relevant to researchers working on bridging the language gap in global healthcare.
Visual Insights#
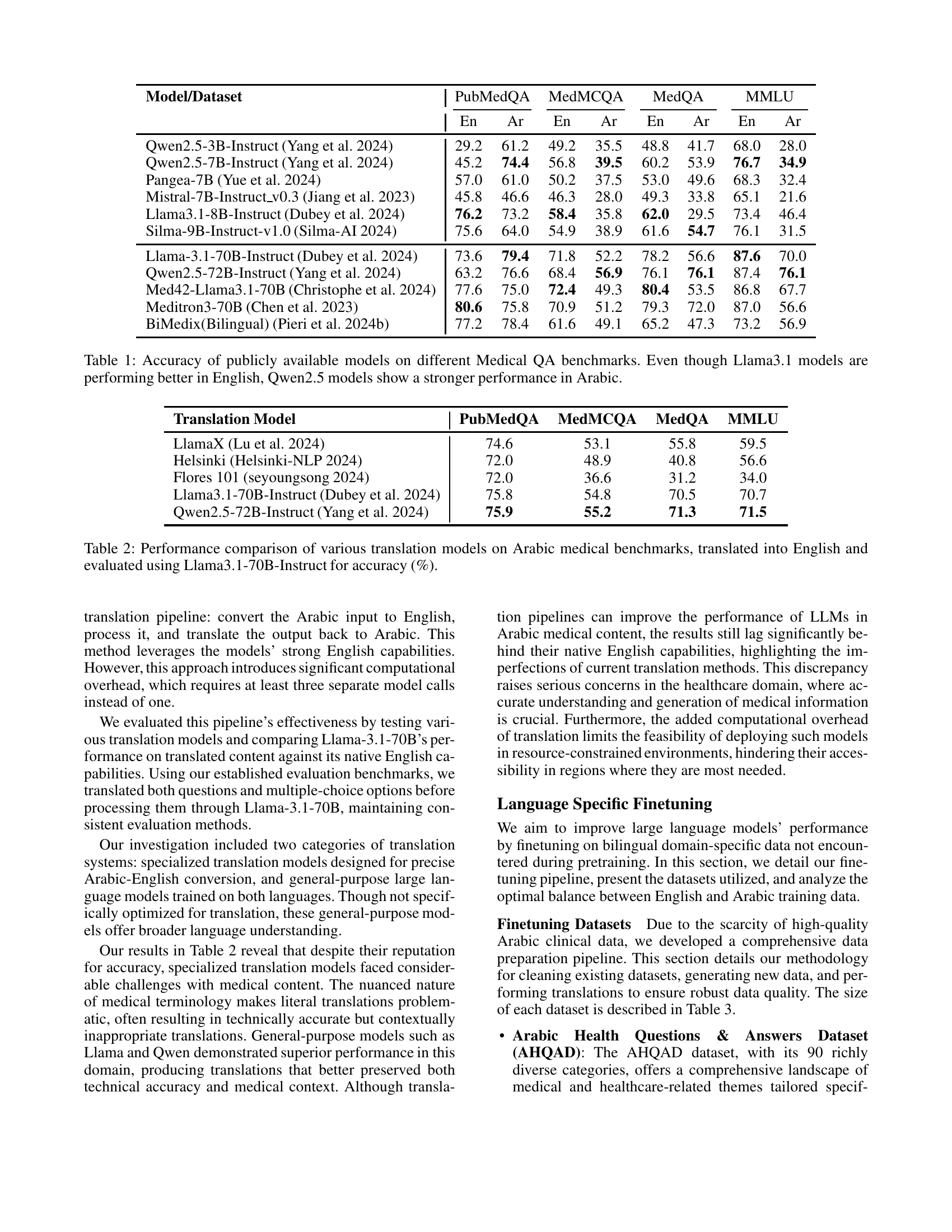
| Model/Dataset | PubMedQA | MedMCQA | MedQA | MMLU | ||||
| En | Ar | En | Ar | En | Ar | En | Ar | |
| Qwen2.5-3B-Instruct (Yang et al. 2024) | 29.2 | 61.2 | 49.2 | 35.5 | 48.8 | 41.7 | 68.0 | 28.0 |
| Qwen2.5-7B-Instruct (Yang et al. 2024) | 45.2 | 74.4 | 56.8 | 39.5 | 60.2 | 53.9 | 76.7 | 34.9 |
| Pangea-7B (Yue et al. 2024) | 57.0 | 61.0 | 50.2 | 37.5 | 53.0 | 49.6 | 68.3 | 32.4 |
| Mistral-7B-Instruct_v0.3 (Jiang et al. 2023) | 45.8 | 46.6 | 46.3 | 28.0 | 49.3 | 33.8 | 65.1 | 21.6 |
| Llama3.1-8B-Instruct (Dubey et al. 2024) | 76.2 | 73.2 | 58.4 | 35.8 | 62.0 | 29.5 | 73.4 | 46.4 |
| Silma-9B-Instruct-v1.0 (Silma-AI 2024) | 75.6 | 64.0 | 54.9 | 38.9 | 61.6 | 54.7 | 76.1 | 31.5 |
| Llama-3.1-70B-Instruct (Dubey et al. 2024) | 73.6 | 79.4 | 71.8 | 52.2 | 78.2 | 56.6 | 87.6 | 70.0 |
| Qwen2.5-72B-Instruct (Yang et al. 2024) | 63.2 | 76.6 | 68.4 | 56.9 | 76.1 | 76.1 | 87.4 | 76.1 |
| Med42-Llama3.1-70B (Christophe et al. 2024) | 77.6 | 75.0 | 72.4 | 49.3 | 80.4 | 53.5 | 86.8 | 67.7 |
| Meditron3-70B (Chen et al. 2023) | 80.6 | 75.8 | 70.9 | 51.2 | 79.3 | 72.0 | 87.0 | 56.6 |
| BiMedix(Bilingual) (Pieri et al. 2024b) | 77.2 | 78.4 | 61.6 | 49.1 | 65.2 | 47.3 | 73.2 | 56.9 |
🔼 Table 1 presents the performance of various publicly available large language models (LLMs) on a series of medical question answering (QA) benchmarks. The benchmarks assess the models’ abilities on English and Arabic language medical questions. The results show a performance disparity between the models in English versus Arabic. While Llama 3.1 models generally perform better on English benchmarks, Qwen 2.5 models exhibit relatively stronger performance on the Arabic benchmarks. This highlights the challenge of developing LLMs that generalize well across different languages and, specifically, in the medical domain.
read the caption
Table 1: Accuracy of publicly available models on different Medical QA benchmarks. Even though Llama3.1 models are performing better in English, Qwen2.5 models show a stronger performance in Arabic.
In-depth insights#
Arabic LLMs in Healthcare#
The application of Arabic LLMs in healthcare presents a significant opportunity to overcome language barriers and improve access to quality care for Arabic-speaking populations. Developing effective Arabic LLMs for healthcare requires addressing the scarcity of high-quality, domain-specific training data. This necessitates innovative approaches such as data augmentation techniques, leveraging existing multilingual models, and careful translation of existing datasets. Evaluation methodologies must be adapted to account for the complexities of the Arabic language and the specific needs of clinical tasks, considering nuanced medical terminology and the unique linguistic features of Arabic dialects. Furthermore, research should focus on achieving optimal language ratios in training data, exploring the balance of Arabic and other languages to enhance cross-lingual understanding and performance. Finally, the development of Arabic LLMs in healthcare should be guided by ethical considerations, ensuring fairness, inclusivity, and mitigating potential biases.
Multilingual Model Limits#
Multilingual models, while offering the promise of inclusivity, face significant limitations in handling diverse languages, particularly within specialized domains like healthcare. Data scarcity in low-resource languages severely hinders effective training, resulting in subpar performance compared to models trained predominantly on high-resource languages such as English. Direct translation of existing datasets is often insufficient, as it fails to capture the linguistic nuances and subtle contextual differences crucial for accurate understanding in clinical settings. Furthermore, the optimal language mix within training data varies considerably across different medical tasks. Simply relying on larger models or fine-tuning alone is not a guaranteed solution. Effective multilingual medical AI necessitates computationally intensive pre-training methods and careful data curation strategies that address both linguistic diversity and domain-specific terminology.
Data Augmentation Impact#
Data augmentation significantly impacts the performance of Arabic LLMs in medical applications. The study explores various augmentation techniques, revealing that simply translating existing datasets is insufficient. Optimal performance is achieved through careful calibration of the language mix in training data, suggesting that a balanced or Arabic-majority approach often outperforms English-only or English-majority approaches. This highlights the crucial role of high-quality Arabic medical data and demonstrates that direct translation might not sufficiently capture the nuances of medical terminology and context in Arabic. Further research is needed to explore additional augmentation techniques and optimal data mix strategies for different clinical tasks to enhance the overall effectiveness and inclusivity of Arabic LLMs in healthcare.
Translation Pipeline Effects#
A dedicated section analyzing ‘Translation Pipeline Effects’ within a research paper would delve into how the accuracy and efficacy of a multilingual model are impacted by the translation process. Different translation models will introduce varying levels of noise and inaccuracy, potentially skewing results and affecting downstream tasks like fine-tuning. The analysis would likely compare multiple translation approaches, perhaps contrasting those designed for specialized medical terminology with general-purpose models. Key metrics to examine would include BLEU scores (measuring translation quality) and subsequent performance metrics on Arabic medical benchmarks, potentially revealing whether certain translation pipelines introduce biases toward specific medical tasks. A thoughtful analysis should also discuss the computational cost of each pipeline, considering the trade-off between accuracy and efficiency, especially within resource-constrained settings. Ultimately, the section would aim to provide critical insights into selecting the optimal translation approach, impacting both the development of robust multilingual clinical LLMs and their practical deployment.
Future Research Needs#
Future research should prioritize expanding the scope of Arabic LLMs in healthcare. More comprehensive benchmarks are needed, moving beyond question-answering tasks to evaluate complex clinical reasoning and decision-making abilities. Addressing the scarcity of high-quality Arabic medical data is crucial through improved data collection, augmentation techniques, and potentially the creation of synthetic data while carefully considering biases. Investigating the optimal training strategies for multilingual medical LLMs is essential. Exploration of different pretraining methods, fine-tuning techniques, and language ratios is required. Research should delve into handling dialectal variations within Arabic to ensure inclusivity and effectiveness across diverse populations. Finally, a thorough examination of the ethical implications of using LLMs in diverse healthcare settings is paramount to ensure fairness, accountability, and trustworthiness.
More visual insights#
More on tables
| Translation Model | PubMedQA | MedMCQA | MedQA | MMLU |
|---|---|---|---|---|
| LlamaX (Lu et al. 2024) | 74.6 | 53.1 | 55.8 | 59.5 |
| Helsinki (Helsinki-NLP 2024) | 72.0 | 48.9 | 40.8 | 56.6 |
| Flores 101 (seyoungsong 2024) | 72.0 | 36.6 | 31.2 | 34.0 |
| Llama3.1-70B-Instruct (Dubey et al. 2024) | 75.8 | 54.8 | 70.5 | 70.7 |
| Qwen2.5-72B-Instruct (Yang et al. 2024) | 75.9 | 55.2 | 71.3 | 71.5 |
🔼 This table compares the accuracy of different translation models in translating Arabic medical benchmarks into English. The accuracy is assessed using the Llama3.1-70B-Instruct model. It helps to understand which translation model performs best for medical terminology and how accurate the subsequent English text is for the downstream task.
read the caption
Table 2: Performance comparison of various translation models on Arabic medical benchmarks, translated into English and evaluated using Llama3.1-70B-Instruct for accuracy (%).
| Dataset | Original | Description | Final | # of Tokens | ||
| 1. AHQAD | Arabic |
| Arabic | 8.33 M | ||
| 2. Translated MED42 Dataset | English |
| Arabic | 230.69 M | ||
| 3. CIDAR | Arabic |
| Arabic | 1.34 M | ||
| 4. Med42 Dataset | English | Full English FT dataset | English | 464.97 M | ||
| 5. Synthetic Open-Ended | English |
| Arabic | 240 M | ||
| Total # of Arabic Tokens | 480.36 M | |||||
| Total # of English Tokens | 469.97 M | |||||
🔼 Table 3 provides a detailed overview of the datasets used in the study, categorized by their original language (Arabic or English), a description of their creation and processing (e.g., sampling methods, translation techniques), and the final number of tokens in each dataset. It also shows the total number of Arabic and English tokens used for training, which is critical for understanding the language distribution in the training data and the focus on Arabic.
read the caption
Table 3: Dataset Overview with Language Distribution
| 100K sampled based on completeness and |
| paraphrased with Qwen-72B-Instruct |
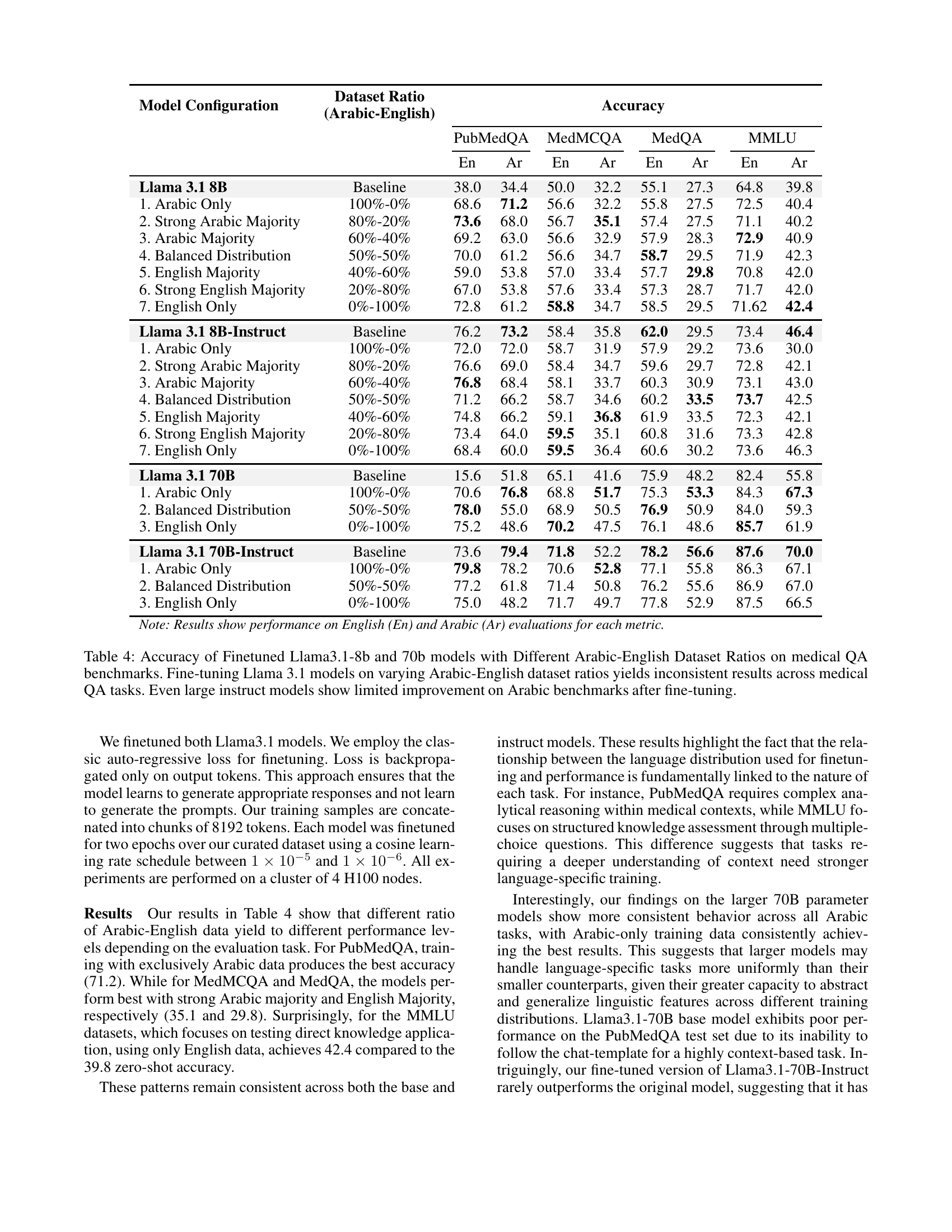
🔼 This table presents the accuracy of fine-tuned Llama 3.1 models (8B and 70B parameters) across various medical question answering (QA) benchmarks. Different ratios of Arabic and English data were used for fine-tuning. The results show inconsistent performance across different benchmarks, revealing that the optimal training data composition varies by task. Even the larger, instruction-tuned (Instruct) 70B model shows limited performance gains over the baseline in Arabic after fine-tuning.
read the caption
Table 4: Accuracy of Finetuned Llama3.1-8b and 70b models with Different Arabic-English Dataset Ratios on medical QA benchmarks. Fine-tuning Llama 3.1 models on varying Arabic-English dataset ratios yields inconsistent results across medical QA tasks. Even large instruct models show limited improvement on Arabic benchmarks after fine-tuning.
Full paper#