TL;DR#
Current methods for improving Large Language Model (LLM) reasoning, such as chain-of-thought and self-consistency, often struggle with complex problems. These approaches frequently require problem formalization, limiting their applicability to tasks easily represented formally. This paper addresses these limitations by exploring a new evolutionary search strategy that leverages the LLM itself to improve problem-solving ability.
The proposed method, Mind Evolution, uses the LLM to generate, recombine, and refine solution candidates based on feedback from an evaluator. This iterative process allows for both broad exploration and deep refinement of solutions without the need for explicit problem formalization. The results demonstrate that Mind Evolution significantly outperforms existing inference strategies, achieving remarkable success rates on natural language planning benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers exploring LLM reasoning and problem-solving. It introduces a novel evolutionary search strategy, significantly advancing the state-of-the-art in natural language planning. The findings are highly relevant to current trends in LLM scaling and efficient inference, opening new avenues for combining evolutionary algorithms with LLMs for complex tasks.
Visual Insights#

🔼 Mind Evolution is a genetic algorithm that uses a large language model (LLM) to iteratively improve a population of natural language solutions. The figure depicts the process for a travel planning task. The LLM generates, recombines (crossover), and refines (mutation) solution candidates based on feedback from an evaluator. The process continues until a satisfactory solution is found or a computational budget is reached. The algorithm combines divergent thinking (exploration of many solutions in parallel) and convergent thinking (iterative refinement and selection of top-performing solutions).
read the caption
Figure 1: Mind Evolution is a genetic-based evolutionary search strategy that operates in natural language space. The figure illustrates how Mind Evolution evolves a population of solution candidates toward higher quality candidates for a travel planning task. The candidate population is improved through an iterative process, where an LLM is used to recombine and refine candidates in each iteration.
| Parameter | Default Value | Description |
| 10 | The maximum number of generations to search for a solution. | |
| 4 | How many independent populations to evolve. | |
| 5 | How many conversations per island. | |
| 4 | How many turns per conversation. | |
| 3 | How frequently to reset islands in generations. | |
| 2 | How many islands to reset. Lowest mean score islands are chosen. | |
| 5 | How many starting parents to transfer to islands when reset. | |
| 15 | How many candidate parents to consider when resetting islands with the LLM. | |
| 5 | Maximum number of parents a conversation can have. | |
| 1/6 | Probability of a conversation having no parents. | |
| 5 | How many plans to emigrate to the next island after each island. | |
| 5 | How many times to try to generate a plan before giving up at each turn. |
🔼 This table lists and describes the hyperparameters used in the Mind Evolution algorithm. It includes the default value for each hyperparameter and explains the role it plays in the evolutionary process. The product of the first four hyperparameters determines the maximum number of candidate solutions generated, which is 800 in the default configuration.
read the caption
Table 1: Definition of hyperparameters in Mind Evolution. Unless otherwise specified, the experiments in work use the default values. The product of the first four hyperparameters gives the maximum number of candidate solutions generated (800 in the default setting).
In-depth insights#
LLM Evolutionary Search#
LLM evolutionary search represents a novel paradigm in leveraging large language models (LLMs) for complex problem-solving. Instead of relying on single-pass inference or simple iterative refinement, this approach introduces a genetic algorithm framework. Candidate solutions are generated, recombined, and refined iteratively based on feedback from an evaluator. This mimics biological evolution, with higher-performing solutions having a greater probability of survival and reproduction, ultimately leading to more sophisticated answers. The key advantage lies in its capacity to explore a diverse solution space efficiently, moving beyond the limitations of traditional methods such as best-of-N approaches. It is particularly powerful for tasks lacking a formal representation, as it avoids the need for explicit problem formalization. However, challenges such as hyperparameter tuning and effective prompt engineering need careful consideration. The computational cost of such an approach must be weighed against the potential improvements in solution quality. Further research should explore different genetic operators and fitness functions to optimize performance across various domains and problem types. The scalability and potential for parallelization are significant factors for future development.
Mind Evolution Algorithm#
A hypothetical “Mind Evolution Algorithm” in a research paper would likely detail a novel approach to problem-solving using large language models (LLMs). It would probably involve an iterative process of generating, evaluating, and refining candidate solutions through an evolutionary framework. Genetic algorithms are a likely foundation, with LLMs generating an initial population of solutions, then using feedback from an evaluator to guide the selection, recombination (crossover), and mutation of solutions across generations. The algorithm’s core strength would be its avoidance of formal problem representation, relying instead on the LLM’s ability to operate directly within the space of natural language. This makes it applicable to problems challenging for traditional methods. Parallelization is a key consideration to handle the computational demands. The evaluation function’s design is crucial; it must provide informative feedback guiding the evolutionary process and might leverage LLMs themselves for nuanced critiques. The algorithm’s success would hinge on the evaluator’s effectiveness and the LLM’s capacity for creative solution generation and insightful refinement. Areas for analysis would include the impact of hyperparameters on performance, exploration vs. exploitation trade-offs, and comparisons with other LLM-based search techniques.
Genetic Search Strategy#
A genetic search strategy, in the context of large language models (LLMs), offers a powerful approach to enhance problem-solving capabilities by leveraging the power of evolutionary algorithms. It addresses the challenge of efficiently exploring a vast solution space, particularly within natural language tasks where formal problem representation is difficult. The core idea is to evolve a population of candidate solutions, iteratively refining and recombining them based on feedback from an evaluator. This process mimics natural selection, with fitter solutions (those deemed higher-quality by the evaluator) being more likely to survive and reproduce, leading to progressive improvement over generations. The use of LLMs is crucial in this process, not only for generating initial candidates and refining existing ones, but also for implementing recombination operators (crossover and mutation) using natural language prompting. This avoids the constraints of searching through formalized program spaces, making the approach readily applicable to complex, ill-defined problems. The strength of this strategy lies in its combination of broad exploration and focused exploitation, balancing the exploration of diverse solutions with the refinement of promising candidates. This blend leads to potentially superior performance compared to simpler strategies like Best-of-N or sequential revision. Overall, the genetic search strategy presents a robust and adaptable method for solving complex problems with LLMs.
Natural Language Planning#
Natural Language Planning (NLP) focuses on enabling computers to understand and execute plans described in natural language. This is a complex task due to the inherent ambiguity and flexibility of human language. Effective NLP planning requires robust natural language understanding, reasoning capabilities, and plan generation techniques. The challenge lies in bridging the gap between the high-level, often incomplete instructions provided by a human and the precise, low-level actions required by a machine. Current research explores various methods, including leveraging Large Language Models (LLMs) to generate and refine plan candidates. LLMs’ ability to generate multiple plans and iterate on feedback is crucial for achieving high-quality solutions. However, evaluating plans generated from LLMs remains challenging, and research is ongoing to improve the reliability and accuracy of evaluation methods. Combining LLMs with search strategies, such as evolutionary algorithms, is a promising approach, allowing for more comprehensive exploration of potential solutions and improving overall plan quality. Future work is needed to address the limitations of current NLP planning systems, including handling uncertainty and unexpected events in dynamic environments, and to develop robust evaluation techniques for broader applicability.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending Mind Evolution to other problem domains beyond natural language planning is crucial, requiring the development of robust, LLM-based evaluators for diverse problem types. Investigating the impact of different LLM architectures and prompting strategies on Mind Evolution’s performance would provide valuable insights. A deeper understanding of the interplay between evolutionary parameters, LLM capabilities, and problem complexity is needed. Addressing limitations such as the computational cost associated with extensive LLM calls warrants further research, potentially through techniques like efficient prompt engineering or approximation methods. Finally, a thorough investigation into the theoretical properties of Mind Evolution, including its convergence speed and solution quality, would enhance its understanding and enable further optimization. Exploring the potential benefits of integrating other advanced search heuristics or incorporating uncertainty quantification into Mind Evolution’s framework is another compelling direction for future work.
More visual insights#
More on figures

🔼 The figure illustrates the iterative refinement process within the Mind Evolution framework. It begins with an initial solution generated by the LLM. This solution is then evaluated using a programmatic evaluator which provides feedback on the solution’s quality. This feedback is then fed back into the LLM along with the initial solution, but this time using two distinct personas within the prompt: a ‘critic’ who analyzes the solution and its flaws, and an ‘author’ who uses the feedback and criticism to generate a revised, improved solution. This cycle of evaluation, criticism, and refinement repeats until a satisfactory solution is reached or a termination condition is met.
read the caption
Figure 2: Illustrating the Refinement through Critical Conversation (RCC) process, where an initial solution is first proposed, then evaluated and subjected to feedback from a critic, after which an author proposed a refined solution and the process iterates.

🔼 This figure shows the success rates of different LLM-based planning strategies on the TravelPlanner benchmark. The x-axis categorizes problem instances by their difficulty (Easy, Medium, Hard) and the length of the trip (3, 5, or 7 days). The y-axis represents the success rate, indicating the percentage of problem instances solved correctly by each method. This visualization allows for a comparison of the performance of various methods across different problem difficulty levels and trip durations.
read the caption
Figure 3: Success rate on the validation set of the TravelPlanner benchmark, organized by problem instance difficulty and the number of travel days.

🔼 This figure shows the success rate achieved by different methods on the Trip Planning task of the Natural Plan benchmark. The x-axis represents the number of cities to visit in the trip planning task, and the y-axis represents the success rate. Different methods are compared, showing how their performance varies depending on the number of cities involved.
read the caption
Figure 4: Success rate on the validation set of the Trip Planning benchmark per number of cities to visit.

🔼 This figure shows how the success rate of Mind Evolution varies depending on the number of people the model needs to schedule meetings with in the Meeting Planning task of the Natural Plan benchmark. The x-axis represents the number of people to meet, and the y-axis displays the success rate (percentage of problem instances solved successfully). It allows for comparison of Mind Evolution’s performance against three baseline methods: 1-Pass, Best-of-N, and Sequential Revision+.
read the caption
Figure 5: Success rate on the validation set of the Meeting Planning benchmark per number of people to meet with.

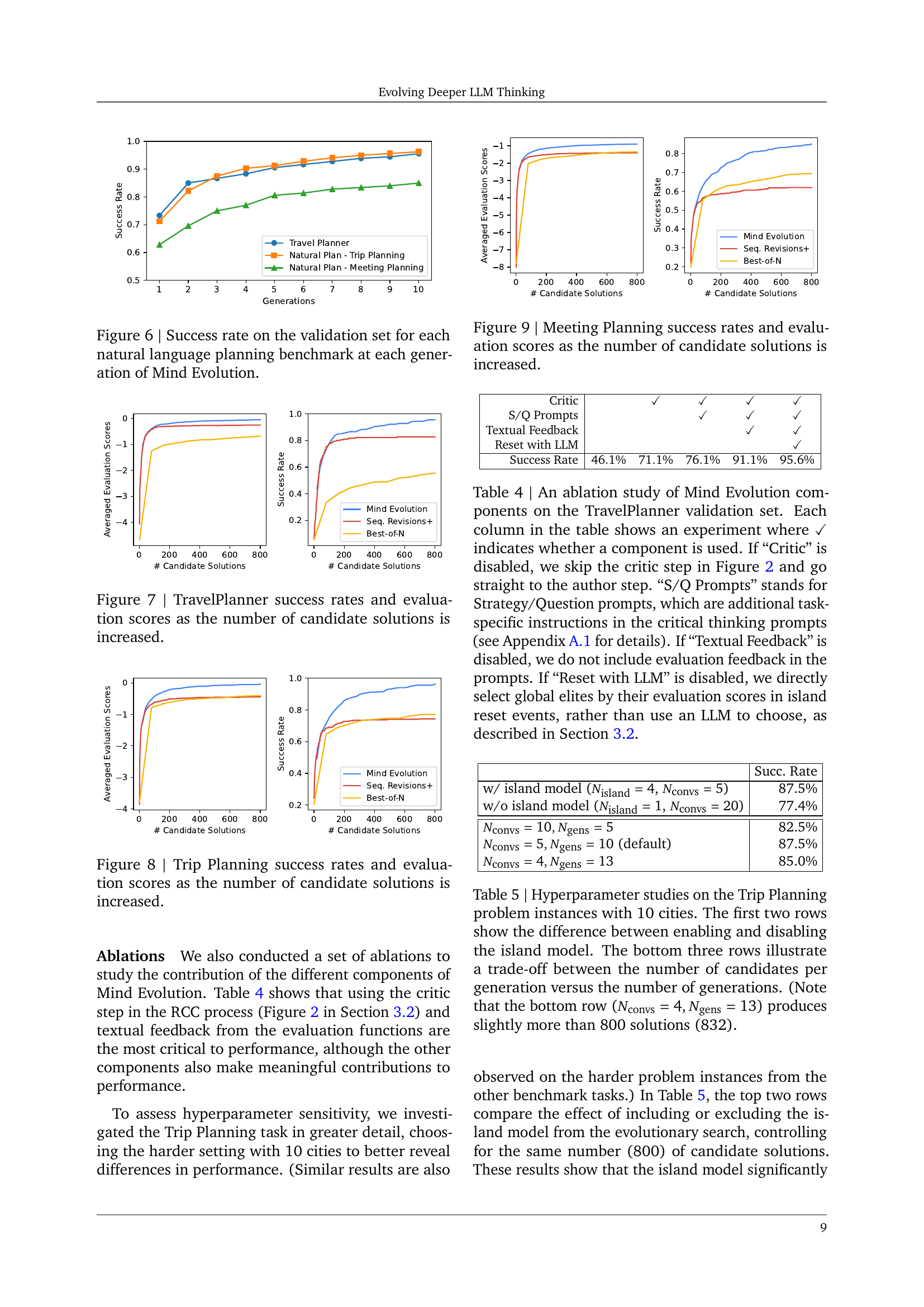
🔼 This figure displays the success rate achieved by the Mind Evolution model across three different natural language planning benchmarks (TravelPlanner, Trip Planning, and Meeting Planning) over multiple generations. Each line represents a benchmark, showing how the model’s success rate improves with each successive generation of the evolutionary algorithm. The x-axis represents the generation number, and the y-axis represents the success rate (percentage of problem instances solved correctly). This visualization illustrates the iterative improvement of the model’s problem-solving capabilities through the evolutionary search process.
read the caption
Figure 6: Success rate on the validation set for each natural language planning benchmark at each generation of Mind Evolution.

🔼 This figure shows the relationship between the number of candidate solutions generated and the success rate and average evaluation score for the TravelPlanner task. It plots the success rate and the average evaluation score (a measure of solution quality) against the number of candidate solutions that are considered by different search strategies (Mind Evolution, Sequential-Revision+, and Best-of-N). The graph illustrates how the performance of each search strategy improves as more solutions are explored.
read the caption
Figure 7: TravelPlanner success rates and evaluation scores as the number of candidate solutions is increased.

🔼 This figure shows the performance of different search strategies on the Trip Planning task in the Natural Language Planning benchmark. Specifically, it plots the success rate and average evaluation score against the number of candidate solutions generated by each strategy (Mind Evolution, Sequential-Revision+, and Best-of-N). The x-axis represents the number of candidate solutions, and the y-axis shows both the success rate (left y-axis) and average evaluation score (right y-axis). This visualization helps demonstrate how the success rate and solution quality improve as more candidate solutions are explored, allowing for a comparison of the effectiveness of each search algorithm.
read the caption
Figure 8: Trip Planning success rates and evaluation scores as the number of candidate solutions is increased.

🔼 This figure illustrates the performance of Mind Evolution and baseline methods on the Meeting Planning task from the Natural Plan benchmark. It shows the success rate (the percentage of problem instances solved correctly) and average evaluation score (a measure of solution quality, with higher scores indicating better solutions) as a function of the number of candidate solutions generated. The x-axis represents the number of candidate solutions, while the y-axis displays both success rate and average evaluation score. Different colored lines represent different search strategies. This visualization helps to understand how each search method’s performance scales with increased computational cost, as more candidate solutions generally imply a higher cost but can also lead to higher accuracy and better solution quality.
read the caption
Figure 9: Meeting Planning success rates and evaluation scores as the number of candidate solutions is increased.

🔼 This figure demonstrates an example of the StegPoet task, a new benchmark introduced in the paper. The left side shows the problem instance, which includes a hidden message (M) represented as a sequence of numbers and the desired style and topic for the generated text. The right side displays a correct solution, where the numbers in M have been encoded using a number-to-word cipher into a poem that matches the specified style (children’s poetry) and topic. The solution also includes the cipher itself. Note that the length of the hidden message (|M|) in this example is 12, and the code words in the poem are capitalized for clarity.
read the caption
Figure 10: StegPoet example. Example of the encoding of a StegPoet problem instance (left) and a correct solution (right) that includes the number-to-word cipher and a poem in the style of a children’s poetry author. Note that |M|=12𝑀12|M|=12| italic_M | = 12 in this instance. We added capitalization to the code words to highlight them.

🔼 Figure 11 is a histogram showing the success rate of different methods on the StegPoet task, categorized by difficulty level. The x-axis represents the different difficulty levels of the StegPoet task (likely based on the length of the hidden message, the number of repetitions of numbers, how close the repeated numbers are, and the spacing between cipher words). The y-axis represents the success rate (percentage of problems solved correctly). The histogram visually compares the performance of Mind Evolution against baseline methods (Best-of-N and Sequential-Revision+). The 1-Pass method is not shown in the histogram because it failed to solve any problems.
read the caption
Figure 11: Histogram of Success Rate for each difficulty level. 1-Pass returns valid responses, but fails to solve any of the problems, so it is not visible in the histogram.

🔼 This figure shows a prompt for the Meeting Planning task, a sub-task of the Natural Language Planning benchmark. The prompt includes general instructions, a few example tasks and solutions, and the specific task description. The model response showcases parent solutions (previous attempts at the task) and the corresponding feedback. This is part one of a multi-part figure illustrating the interaction of the prompt and the model’s iterative response generation process within the Mind Evolution algorithm.
read the caption
Figure 12: Example Meeting Planning prompt and model response with parent solutions given (Part 1)

🔼 This figure shows a prompt used in the Meeting Planning task within the Mind Evolution framework. The prompt includes general instructions, examples of previous tasks and solutions, and the current task requirements. Notably, the prompt presents ‘parent solutions’ (previously generated solutions) along with feedback from an evaluator to guide the LLM in generating a refined solution. This illustrates the iterative refinement process of Mind Evolution, where the LLM learns from previous attempts and critiques to produce improved solutions. The model’s response (a proposed meeting plan) demonstrates how the LLM uses this feedback to generate a refined plan that addresses earlier errors and attempts to meet the scheduling requirements more effectively.
read the caption
Figure 13: Example Meeting Planning prompt and model response with parent solutions given (Part 2)

🔼 This figure shows a prompt used in the Meeting Planning task of the Mind Evolution approach. It illustrates the ‘Refinement through Critical Conversation (RCC)’ process, where the LLM acts as both critic and author to refine the solution. The prompt includes instructions for the LLM to analyze previously proposed plans, identify shortcomings, and offer suggestions for improvement. It also presents parent solutions (previous plans) with their corresponding evaluation feedback, guiding the LLM towards creating a higher-quality solution that considers the given constraints and addresses the identified issues.
read the caption
Figure 14: Example Meeting Planning prompt and model response with parent solutions given (Part 3)

🔼 This figure shows a prompt used in the Mind Evolution process for the Meeting Planning task. It illustrates the ‘Refinement through Critical Conversation’ strategy, where an LLM plays the roles of both critic and author. The critic analyzes previously proposed plans and highlights shortcomings, while the author uses these critiques to create improved plans. This is an iterative process, aiming to generate increasingly better solutions.
read the caption
Figure 15: Example Meeting Planning prompt and model response with parent solutions given (Part 4)

🔼 This figure shows a detailed example of the Meeting Planning prompt used in the Mind Evolution method. It displays the instructions given to the Large Language Model (LLM), including general instructions, example tasks and solutions, and the specific task requirements. It also illustrates the ‘previous plans’ section, showing previously generated plans along with their associated issues. Furthermore, it presents the ‘critical thinking instructions’ which guide the LLM to improve the plans through a structured critical conversation between a critic and an author, leading to a refined solution. The figure includes prompts and the LLM’s response illustrating the iterative refinement process within a single generation.
read the caption
Figure 16: Example Meeting Planning prompt and model response with parent solutions given (Part 5)

🔼 This figure displays a prompt used for the TravelPlanner task within the Mind Evolution framework. The prompt provides background information and instructions to the large language model (LLM), including general instructions, examples of proper formatting for the expected response, and a specific task prompt. The prompt also incorporates ‘parent solutions’ which are previous responses from the LLM that failed to fully meet the requirements of the task; this is a key part of the Mind Evolution process. The parent solutions are followed by instructions on how to improve upon those solutions. This aims to guide the LLM towards a more successful plan and showcases the iterative refinement process within the Mind Evolution system.
read the caption
Figure 17: Example TravelPlanner prompt and model response with parent solutions given (Part 1)

🔼 This figure shows a prompt given to a large language model (LLM) for a travel planning task and the LLM’s response. The prompt includes instructions, examples of well-formatted responses, and specific requirements for the plan (including budget, dates, number of people, and preferred cuisines). The parent solutions section shows previous attempts that were deemed inadequate with reasons why. The figure is part of a larger demonstration of a genetic algorithm used to improve LLM performance in natural language planning tasks. It is a continuation of Figure 17, suggesting that multiple figures were used to fully display this example due to its length.
read the caption
Figure 18: Example TravelPlanner prompt and model response with parent solutions given (Part 2)

🔼 This figure shows a prompt given to a large language model (LLM) for a travel planning task. The prompt includes instructions and example solutions to guide the LLM. The figure also shows example parent solutions (previously generated plans) and their corresponding issues. The parent solutions and their problems highlight areas where the LLM should improve. This sets the stage for the LLM to generate a new, improved travel plan based on the examples and feedback. The figure is part of a process to improve LLMs’ ability to generate solutions through an iterative process of generating, critiquing, and refining plans, which is described in detail in the paper.
read the caption
Figure 19: Example TravelPlanner prompt and model response with parent solutions given (Part 3)

🔼 This figure shows a detailed example of the prompt and model response within the TravelPlanner task. Part 4 of the prompt guides the LLM to critically analyze previously proposed travel plans and their associated feedback. It then instructs the LLM to generate a significantly improved travel plan by incorporating the feedback and addressing the identified issues. The prompt includes specific strategies and questions to aid the LLM in improving the plan’s quality and efficiency.
read the caption
Figure 20: Example TravelPlanner prompt and model response with parent solutions given (Part 4)

🔼 This figure shows a specific example of the Mind Evolution process applied to the TravelPlanner task. It displays the prompt given to the LLM, which includes instructions, examples, the problem statement, and previous failed attempts (parent solutions) with feedback. The response section shows ‘Jane’s Analysis’, where the LLM critically evaluates the previous solutions, identifying weaknesses and suggesting improvements. Then, ‘John’s Reasoning’ presents the LLM’s improved plan, along with a step-by-step explanation of the reasoning process. This illustrates the iterative refinement and critical thinking capabilities of the Mind Evolution method. This is part 5 of a multi-part figure.
read the caption
Figure 21: Example TravelPlanner prompt and model response with parent solutions given (Part 5)

🔼 This figure shows a detailed example of the Mind Evolution process applied to the TravelPlanner task. Part 6 of the prompt and response exchange between the LLM and the evaluator is displayed. This section illustrates how the LLM, in the role of ‘author’, refines a candidate solution based on feedback from the critic’s analysis. The feedback highlights issues with the previous plan, such as exceeding budget and accommodation selection problems. The ‘author’ then proposes a revised travel plan that addresses these issues by incorporating cost-effective alternatives and ensuring adherence to constraints. The provided JSON structure demonstrates the format for expressing the travel plans.
read the caption
Figure 22: Example TravelPlanner prompt and model response with parent solutions given (Part 6)

🔼 This figure shows the first part of the Python code for the Meeting Planning evaluation function. This function evaluates the quality of a proposed meeting plan, considering factors such as time constraints, travel distances, and the duration of meetings. The code iterates through the plan steps, parsing information about travel times, waiting periods, and meeting durations. It checks for inconsistencies (e.g., meeting times conflicting with schedules or travel times exceeding available time) and calculates a score reflecting the plan’s quality. The first part focuses on parsing the plan steps and handling time calculations.
read the caption
Figure 23: The Meeting Planning evaluation function (part 1).

🔼 This figure shows the second part of the Python code implementing the evaluation function for the Meeting Planning task in the Mind Evolution algorithm. The code evaluates the quality of a proposed plan by checking constraints (e.g., scheduling conflicts, travel time), ensuring consistency with the format, and providing textual feedback. It handles various scenarios like travel time calculations, waiting periods, and meeting time verifications, assigning scores and feedback messages accordingly. The evaluation function leverages the previously defined variables and structures from part 1 of the function.
read the caption
Figure 24: The Meeting Planning evaluation function (part 2).
More on tables
| Set | Success Rate | LLM Calls | Input Tokens | Output Tokens | API Cost (Oct 2024) | |
| TravelPlanner [42] | ||||||
| 1-Pass | val | 1 | M | M | US$ | |
| (o1-preview 1-Pass) | val | 1 | M | M | US$ | |
| Best-of-N | val | 472 | M | M | US$ | |
| Sequential-Revision+ | val | 280 | M | M | US$ | |
| Mind Evolution | val | 174 | M | M | US$ | |
| (+pro) | val | (257) | (M) | (M) | (US$) | |
| Mind Evolution | test | 167 | M | M | US$ | |
| (+pro) | test | (67) | (M) | (M) | (US$) | |
| Natural Plan [47] Trip Planning | ||||||
| 1-Pass | val | 1 | M | M | US$ | |
| (o1-preview 1-Pass) | val | 1 | M | M | US$ | |
| Best-of-N | val | 274 | M | M | US$ | |
| Sequential-Revision+ | val | 391 | M | M | US$ | |
| Mind Evolution | val | 168 | M | M | US$ | |
| (+pro) | val | (111) | (M) | (M) | (US$) | |
| Mind Evolution | test | 196 | M | M | US$ | |
| (+pro) | test | (211) | (M) | (M) | (US$) | |
| Natural Plan [47] Meeting Planning | ||||||
| 1-Pass | val | 1 | M | M | US$ | |
| (o1-preview 1-Pass) | val | 1 | M | M | US$ | |
| Best-of-N | val | 444 | M | M | US$ | |
| Sequential-Revision+ | val | 484 | M | M | US$ | |
| Mind Evolution | val | 406 | M | M | US$ | |
| (+pro) | val | (890) | (M) | (M) | (US$) | |
| Mind Evolution | test | 394 | M | M | US$ | |
| (+pro) | test | (828) | (M) | (M) | (US$) | |
🔼 This table presents the performance of different LLMs and search strategies on three natural language planning benchmarks: TravelPlanner, Trip Planning, and Meeting Planning. The benchmarks evaluate the ability of the models to generate valid and complete plans given natural language descriptions of the problem and constraints. For each benchmark, the table compares the success rate, the number of LLM calls, the number of input and output tokens, and the total API cost of the various methods. It also includes a comparison using a two-stage approach where, if the initial LLM (Gemini 1.5 Flash) fails, a more powerful LLM (Gemini 1.5 Pro) is used to solve the problem. This allows for a cost-effective comparison between methods. Results from OpenAI’s 01-preview model are included as a reference point.
read the caption
Table 2: Experimental results on benchmark natural language planning tasks. “(+pro)” denotes the two-stage results, where we use Gemini 1.5 Pro to solve the problems that were not solved in experiments using Gemini 1.5 Flash. Number of LLM calls, token counts, and API cost are averaged across the validation or test problem set, and they are calculated only on the remaining problems for the “(+pro)” experiments. Here, we also show OpenAI o1-preview results as a reference.
| Q: You plan to visit 5 European cities for 16 days in total. You only take direct flights to commute between cities. You want to spend 5 days in Madrid. From day 3 to day 7, there is a annual show you want to attend in Madrid. You plan to stay in Zurich for 3 days. You would like to visit Frankfurt for 3 days. You would like to visit Santorini for 6 days. You are going to attend a wedding in Santorini between day 7 and day 12. You want to spend 3 days in Riga. Here are the cities that have direct flights: Zurich and Riga, Frankfurt and Riga, Santorini and Zurich, Madrid and Zurich, Frankfurt and Zurich, Madrid and Santorini, Frankfurt and Madrid. Find a trip plan of visiting the cities for 16 days by taking direct flights to commute between them. | |
| Method | Answer |
| 1-Pass | Madrid (Day 1-7) \faAngleRight Santorini (Day 7-12) \faAngleRight Zurich (Day 12-14) \faAngleRight Frankfurt (Day 14-16) \faAngleRight Riga (Day 16-19) \faClose 7 days for Madrid instead of 5; 4 days for Riga instead of 3; 19 days in total instead of 16. |
| Best-of-N | Madrid (Day 1-7) \faAngleRight Santorini (Day 7-12) \faAngleRight Zurich (Day 12-14) \faAngleRight Frankfurt (Day 14-16) \faAngleRight Riga (Day 16-16) \faClose 7 days for Madrid instead of 5; 1 day for Riga instead of 3. |
| Sequential Revisions+ | Zurich (Day 1-3) \faAngleRight Frankfurt (Day 3-5) \faAngleRight Riga (Day 5-7) \faAngleRight Santorini (Day 7-12) \faAngleRight Madrid (Day 12-16) \faClose omitted the show in Madrid (Day 3-7); no direct flight from Riga to Santorini. |
| Mind Evolution (ours) | Frankfurt (Day 1-3) \faAngleRight Madrid (Day 3-7) \faAngleRight Santorini (Day 7-12) \faAngleRight Zurich (Day 12-14) \faAngleRight Riga (Day 14-16) \faCheck |
🔼 Table 3 presents a sample problem from the Natural Plan’s Trip Planning task, comparing the solution generated by Mind Evolution with those from three baseline methods: 1-Pass, Best-of-N, and Sequential Revision. The problem involves creating a 16-day European trip with specific constraints, including time spent in various cities and attending events. The table shows that while 1-Pass and Best-of-N fail to meet the specified number of days, they do successfully meet other requirements such as visiting specific locations. Sequential Revision correctly gets the number of days but fails to correctly address the constraint of attending an event in Madrid and proposes a non-existent flight. Mind Evolution, however, is the only method that meets all requirements.
read the caption
Table 3: An example problem instance from the Trip Planning task in Natural Plan, with the predicted plans from Mind Evolution and the baselines. 1-Pass and Best-of-N both make mistakes on number of days to stay, but satisfy the requirements of being in Madrid and Santorini on specific days. The Sequential-Revision+ plan omits the annual show in Madrid and plans a non-existent flight, but is correct in the number of days. In contrast, the Mind Evolution plan satisfies all specified requirements.
| Critic | ✓ | ✓ | ✓ | ✓ | |
| S/Q Prompts | ✓ | ✓ | ✓ | ||
| Textual Feedback | ✓ | ✓ | |||
| Reset with LLM | ✓ | ||||
| Success Rate |
🔼 This table presents an ablation study analyzing the impact of different components within the Mind Evolution model on the TravelPlanner validation set. Each column represents a variation of the model, indicating with a checkmark (✓) which components are included. The study specifically examines the effects of removing the ‘Critic’ step (shortening the critical conversation process), removing the ‘S/Q Prompts’ (task-specific instructions), removing ‘Textual Feedback’ (feedback from the evaluator), and removing the use of an LLM for ‘Island Reset’ (instead directly selecting high-performing solutions). The results show how each component contributes to the overall performance of the Mind Evolution model.
read the caption
Table 4: An ablation study of Mind Evolution components on the TravelPlanner validation set. Each column in the table shows an experiment where ✓ indicates whether a component is used. If “Critic” is disabled, we skip the critic step in Figure 2 and go straight to the author step. “S/Q Prompts” stands for Strategy/Question prompts, which are additional task-specific instructions in the critical thinking prompts (see Section A.1 for details). If “Textual Feedback” is disabled, we do not include evaluation feedback in the prompts. If “Reset with LLM” is disabled, we directly select global elites by their evaluation scores in island reset events, rather than use an LLM to choose, as described in Section 3.2.
| Succ. Rate | |
| w/ island model (, ) | 87.5% |
| w/o island model (, ) | 77.4% |
| 82.5% | |
| (default) | 87.5% |
| 85.0% |
🔼 This table presents an ablation study on the hyperparameters of the Mind Evolution algorithm, specifically focusing on the Trip Planning task with problem instances involving 10 cities. The study investigates the impact of the island model (a technique used to maintain diversity in the evolutionary process) and the trade-off between the number of candidate solutions generated per generation (Nconvs) and the total number of generations (Ngens). The first two rows compare the success rate with and without the island model, while the subsequent three rows explore different combinations of Nconvs and Ngens, demonstrating how the algorithm’s performance changes with varying computational budgets. Note that one configuration produces slightly more than the usual 800 solutions.
read the caption
Table 5: Hyperparameter studies on the Trip Planning problem instances with 10 cities. The first two rows show the difference between enabling and disabling the island model. The bottom three rows illustrate a trade-off between the number of candidates per generation versus the number of generations. (Note that the bottom row (Nconvs=4,Ngens=13formulae-sequencesubscript𝑁convs4subscript𝑁gens13N_{\text{convs}}=4,N_{\text{gens}}=13italic_N start_POSTSUBSCRIPT convs end_POSTSUBSCRIPT = 4 , italic_N start_POSTSUBSCRIPT gens end_POSTSUBSCRIPT = 13) produces slightly more than 800 solutions (832).
| Task | Results (Cipher and Poem) | |
| ⬇ Message To Encode (M): 10,20,30,40, 50,60,70,80, 90,100,10,20 Style: Poem Inspiration: Shel Silverstein Words Between (B): 4 Topic: "The Fun of Walking" | ⬇ 10 : rooster; 20 : flowers; 30 : bright; 40 : flames; 50 : cherry; 60 : crimson; 70 : sunset; 80 : ruby; 90 : scarlet; 100 : burning; | ⬇ I like to walk, I like to stride, With ROOSTER crows and FLOWERS by my side. I like to walk, I like to roam, Past BRIGHT green fields and FLAMES at home. I like to walk, I like to stroll, To see the CHERRY trees and a CRIMSON hole. I like to walk, I like to ramble, To watch the SUNSET and hold a RUBY’s gamble. I like to walk, I like to wander, To watch a SCARLET leaf, and a fire, BURNING, under. I like to walk, I like to stride, With ROOSTER crows and FLOWERS by my side. |
🔼 This table presents the performance of different LLM-based search methods on the StegPoet task. The Success Rate indicates the percentage of problems each method successfully solved. The number of LLM calls, input tokens, output tokens, and API costs (in USD from October 2024) represent the computational resources consumed. The results are divided into those obtained using the Gemini 1.5 Flash model and a two-stage approach using Gemini 1.5 Pro (for problems unsolved by Flash). The two-stage approach highlights the potential for cost-effective problem-solving by leveraging a more powerful model only when necessary.
read the caption
Table 6: Experimental results on StegPoet. Price and token counts are averages per problem. All results use Gemini 1.5 Flash, except (+pro), which solves the problems that were not solved in the Flash runs, using Gemini 1.5 Pro.
| Set | Success Rate | Input Tokens | Output Tokens | API Cost (Oct 2024) | |
| 1-Pass | val | M | M | $ | |
| Best-of-N | val | M | M | $ | |
| Sequential-Revision+ | val | M | M | $ | |
| Mind Evolution | val | M | M | $ | |
| (+pro) | val | M | M | $ | |
| Mind Evolution | test | $ | M | M | |
| (+pro) | test | $ | M | M |
🔼 This table presents the performance results of the Mind Evolution model when using the GPT-40-mini language model. It shows the success rates achieved by Mind Evolution on three different natural language planning benchmarks: TravelPlanner, Trip Planning, and Meeting Planning. The results are specifically for the validation sets of each benchmark, offering a comparison of Mind Evolution’s performance against other baseline methods.
read the caption
Table 7: Mind Evolution with GPT-4o-Mini results on validation sets.
🔼 Table 8 presents the pricing for different large language models (LLMs) in October 2024. It shows the cost per million input tokens and the cost per million output tokens for each model. These pricing differences serve as a relative comparison of the computational costs associated with using each model, allowing for a more informed assessment of the efficiency of different search strategies.
read the caption
Table 8: Pricing at the time of writing (October 2024). These differences serve as a proxy for real computational cost differences among models.
| Model | Input Token | Output Token |
| Gemini 1.5 Flash | $/M | $/M |
| Gemini 1.5 Pro | $/M | $/M |
| GPT-4o-Mini | $ | $ |
| OpenAI o1-preview | $/M | $/M |
🔼 This table showcases a sample TravelPlanner task, which involves creating a travel plan based on specific constraints (budget, dates, preferences, etc.). It compares the plans generated by Mind Evolution against three baseline methods: 1-Pass (a single LLM forward pass), Best-of-N (multiple LLM generations), and Sequential-Revision+ (iterative refinement of initial plans). The comparison highlights the strengths and weaknesses of each approach in terms of plan feasibility, cost-effectiveness, and adherence to constraints.
read the caption
Table 9: An example TravelPlanner task and the solutions proposed by Mind Evolution and the baselines method.
| Q: Could you construct a 3-day journey for two people from Chicago to Albany that takes place from March 22nd to March 24th, 2022? Our budget is $2,300. We require accommodations that allow smoking and should ideally be entire rooms. We will not be self-driving during this trip. On the subject of cuisine, we’re open to any suggestions you might have. [Transportation Options] Taxi: N/A, Self-Driving: N/A, Flights: F3732604 […] [Accommodation Options in Albany] 2Br Union square Newly furnished (minimum 30 nights), […] […] | |
| Method | Answer |
| 1-Pass | [Day 1] city: ’from Chicago to Albany’, accommodation: ’Spacious room with huge bay window & natural light, Albany’, attraction: ’-’, breakfast: ’-’, dinner: ’Kaiser, Albany’, lunch: ’-’, transportation’: ’Flight Number: F3983351, from Chicago to Albany, Departure Time: 20:20, Arrival Time: 23:04’ [Day 2] city: ’Albany’, accommodation: ’Spacious room with huge bay window & natural light, Albany’, attraction: ’Albany Pine Bush Preserve, Albany;New York State Museum, Albany;’, breakfast: ’Desi Villa, Albany’, lunch: ’Just Parkash, Albany’, dinner: ’Kaiser, Albany’, ’transportation’: ’-’ [Day 3] city: ’from Albany to Chicago’, accommodation: ’-’, attraction: ’Hear about Here, Albany;’, breakfast: ’Cafe Coffee Day The Square, Albany’, lunch: ’PiccoLicko, Albany’, dinner: ’StarvinḾarvin, Albany’, transportation: ’Flight Number: F3813300, from Albany to Chicago, Departure Time: 16:40, Arrival Time: 17:52’ \faCloseThe total cost exceeds the budget of $2300 by $114, […] |
| Best-of-N | [Day 1] city: ’from Chicago to Albany’, accommodation: ’Mid Town East Side Apartment, Albany’, attraction: ’New York State Museum, Albany’, breakfast: ’-’, dinner: ’Kaiser, Albany’, lunch: ’-’, transportation’: ’Taxi, from Chicago to Albany, duration: 12 hours 53 mins, distance: 723 km, cost: 532’ [Day 2] city: ’Albany’, accommodation: ’Mid Town East Side Apartment, Albany’, attraction: ’Albany Institute of History & Art, Albany’, breakfast: ’Echoes Satyaniketan, Albany’, lunch: ’Cafe Coffee Day The Square, Albany’, dinner: ’Urban Punjab, Albany’, ’transportation’: ’-’ [Day 3] city: ’from Albany to Chicago’, accommodation: ’-’, attraction: ’Historic Cherry Hill, Albany’, breakfast: ’Just Parkash, Albany’, lunch: ’BKś The Juice Bar, Albany’, dinner: ’-’, transportation: ’Flight Number: F4008387, from Albany to Chicago, Departure Time: 05:05, Arrival Time: 06:11’ \faCloseTaxi from Chicago to Albany on day 1 is not a valid option, […] |
| Sequential Revisions+ | [Day 1] city: ’from Chicago to Albany’, accommodation: ’2Br Union square Newly furnished’, Albany’, attraction: ’-’, breakfast: ’-’, dinner: ’-’, lunch: ’-’, transportation’: ’Flight Number: F3983350, from Chicago to Albany, Departure Time: 14:29, Arrival Time: 17:03’ [Day 2] city: ’Albany’, accommodation: ’2Br Union square Newly furnished’, attraction: ’New York State Museum, Albany;Albany Pine Bush Preserve, Albany’, breakfast: ’Cafe Coffee Day, Albany’, lunch: ’PiccoLicko, Albany’, dinner: ’Kaiser, Albany’, ’transportation’: ’-’ [Day 3] city: ’from Albany to Chicago’, accommodation: ’-’, attraction: ’The McPherson Legacy to the City of Albany - Robert Burns Statue, Albany’, breakfast: ’-’, lunch: ’-’, dinner: ’-’, transportation: ’Flight Number: F3732604, from Albany to Chicago, Departure Time: 05:53, Arrival Time: 07:24’ \faClose’2Br Union square Newly furnished’ requires staying at least 30 nights, […] |
| Mind Evolution (ours) | [Day 1] city: ’from Chicago to Albany’, accommodation: ’Mid Town East Side Apartment, Albany’, attraction: ’-’, breakfast: ’-’, dinner: ’-’, lunch: ’-’, transportation’: ’Flight Number: F3983350, from Chicago to Albany, Departure Time: 14:29, Arrival Time: 17:03’ [Day 2] city: ’Albany’, accommodation: ’Mid Town East Side Apartment, Albany’, attraction: ’Albany Institute of History & Art, Albany’, breakfast: ’StarvinḾarvin, Albany’, lunch: ’Cafe Coffee Day The Square, Albany’, dinner: ’PiccoLicko, Albany’, ’transportation’: ’-’ [Day 3] city: ’from Albany to Chicago’, accommodation: ’-’, attraction: ’The McPherson Legacy to the City of Albany - Robert Burns Statue, Albany’, breakfast: ’-’, lunch: ’-’, dinner: ’-’, transportation: ’Flight Number: F4008387, from Albany to Chicago, Departure Time: 05:05, Arrival Time: 06:11’ \faCheck |
🔼 This table presents a sample problem from the Meeting Planning benchmark dataset and showcases how different solution methods address it. It compares the solutions generated by Mind Evolution against three baseline approaches: 1-Pass, Best-of-N, and Sequential Revisions. Each row displays the solution from a particular method, highlighting strengths and weaknesses (e.g., missed meetings, infeasible schedules). This comparison illustrates Mind Evolution’s ability to generate more comprehensive and accurate plans by leveraging iterative refinement and considering various constraints and schedules.
read the caption
Table 10: An example Meeting Planning task and the solutions proposed by Mind Evolution and the baselines method.
Full paper#