TL;DR#
Current methods for 3D head avatar editing struggle with motion occlusion (e.g., teeth hidden by lips) and maintaining consistency across different viewpoints and animation frames. Existing text-driven editing techniques often lack the ability to handle these complex scenarios effectively, leading to artifacts and inconsistencies in the final output. The paper tackles the challenges of editing animatable 3D Gaussian head avatars, which are particularly complex due to the inherent difficulty of addressing occlusions and maintaining consistency across various frames of an animation.
This paper introduces GaussianAvatar-Editor, a novel framework that addresses these issues. It uses a Weighted Alpha Blending Equation (WABE) to enhance the blending of visible Gaussians while suppressing the influence of those that are occluded. Furthermore, it incorporates conditional adversarial learning to refine the edited results and maintain consistency across different time steps and perspectives. The proposed method achieves high-quality, photorealistic editing results, demonstrating superiority over existing approaches in handling complex animation challenges and significantly enhancing the realism of the final avatar rendering.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel framework for editing animatable 3D Gaussian head avatars, addressing challenges in motion occlusion and temporal consistency. It offers a significant advancement in the field of 3D avatar manipulation, particularly for applications in virtual reality, film, and telepresence. The proposed Weighted Alpha Blending Equation (WABE) and conditional adversarial learning techniques are valuable contributions, opening new avenues for research in 4D consistent editing and high-quality animation.
Visual Insights#

🔼 This figure showcases the capabilities of GaussianAvatar-Editor, a novel method for modifying animatable 3D head models using text prompts. The top row displays a variety of editing tasks achieved through text-based instructions, demonstrating the system’s ability to control expression, pose, and viewpoint. The bottom row shows several more examples of avatar editing. The results highlight the system’s ability to generate photorealistic and consistent edits across time and space, even for complex changes. The figure provides compelling visual evidence of the system’s capabilities.
read the caption
Figure 1: We introduce GaussianAvatar-Editor, a method for text-driven editing of animatable Gaussian head avatars with fully controllable expression, pose, and viewpoint. We show qualitative results of our GaussianAvatar-Editor at the inference time above. Our edited avatars can achieve photorealistic editing results with strong spatial and temporal consistency.
| Novel view rendering | Self-reenactment | Cross-identity reenactment | ||||
|---|---|---|---|---|---|---|
| CLIP-S | CLIP-C | CLIP-S | CLIP-C | CLIP-S | CLIP-C | |
| INSTA+I-N2N | 0.181 | 0.955 | 0.042 | 0.923 | 0.043 | 0.936 |
| GA+I-N2N | 0.236 | 0.968 | 0.044 | 0.938 | 0.069 | 0.941 |
| Control4D | 0.222 | 0.980 | 0.058 | 0.938 | / | / |
| Ours w/o WABE | 0.236 | 0.968 | 0.061 | 0.948 | 0.077 | 0.950 |
| Ours w/o adv | 0.266 | 0.976 | 0.077 | 0.950 | 0.070 | 0.946 |
| Ours | 0.275 | 0.978 | 0.081 | 0.951 | 0.081 | 0.951 |
🔼 This table presents a quantitative comparison of the proposed method (GaussianAvatar-Editor) against existing techniques for three different tasks: novel view rendering, self-reenactment, and cross-identity reenactment. The evaluation uses two metrics, CLIP-S and CLIP-C, to assess the consistency between generated images and text prompts. It includes ablation studies that remove key components of the proposed method to show their individual contributions to the overall performance. The results demonstrate the superiority of the GaussianAvatar-Editor approach in generating high-quality and consistent results across all three tasks.
read the caption
Table 1: Quantitative comparisons and ablation studies with CLIP-S and CLIP-C. We compare our method with existing methods for novel view rendering, self-reenactment, and cross-identity reenactment. Our method obtains superior results than other methods.
In-depth insights#
4D Gaussian Editing#
The concept of “4D Gaussian Editing” integrates the strengths of Gaussian splatting for efficient 3D scene representation with the power of text-driven editing techniques. The “4D” aspect signifies handling both spatial and temporal dimensions, crucial for animating head avatars. Key challenges addressed include motion occlusion and maintaining spatiotemporal consistency. Motion occlusion, where parts of the avatar are temporarily hidden (e.g., teeth behind lips), causes inaccurate gradient updates. The authors propose a Weighted Alpha Blending Equation (WABE) to mitigate this by preferentially weighting visible Gaussians during the editing process. To ensure temporal coherence in the animation, conditional adversarial learning is introduced. This strategy helps maintain visual consistency between different frames and viewpoints, preventing artifacts and improving overall quality. The combination of WABE and adversarial learning makes this approach highly effective for photorealistic and consistent 4D Gaussian head avatar editing, exceeding the capabilities of existing methods. It opens exciting possibilities for high-quality, controllable animation and opens many avenues for future research.
WABE Function#
The Weighted Alpha Blending Equation (WABE) function is a crucial innovation within the GaussianAvatar-Editor framework, specifically designed to address the challenges of motion occlusion during the editing of animatable 3D Gaussian head avatars. Traditional alpha blending techniques indiscriminately update all Gaussians, regardless of visibility, leading to artifacts and inconsistencies, especially in regions temporarily obscured by other parts of the avatar (e.g., teeth hidden by lips). WABE cleverly modifies the blending weights, significantly enhancing the contribution of visible Gaussians while suppressing the influence of occluded ones. This selective weighting ensures that edits accurately reflect the visible components of the avatar, preventing erroneous propagation of gradients and preserving the integrity of occluded regions. The function’s effectiveness is highlighted through qualitative and quantitative results showing a marked improvement in editing quality and a higher degree of spatio-temporal consistency in the final animations. WABE’s success hinges on its ability to differentiate between visible and invisible Gaussians, allowing for precise and artifact-free editing, even in complex scenarios involving substantial motion occlusion. This makes WABE a significant step forward in achieving high-fidelity, text-driven editing of animatable 3D models.
Adversarial Learning#
The research paper leverages adversarial learning to enhance the temporal consistency of the edited animatable Gaussian avatars. Standard reconstruction losses alone often result in inconsistencies between rendered frames, leading to blurry or distorted results. By introducing a discriminator network trained to distinguish real (consistently edited) image pairs from fake ones, the method encourages the generation of temporally coherent sequences. This adversarial training refines the edited results, ensuring a smooth and natural animation. The discriminator is crucial, as it explicitly learns to identify inconsistencies and provides feedback to the generator network to improve the overall quality and realism of the animation, particularly in challenging situations like motion occlusion.
Motion Occlusion#
Motion occlusion presents a significant challenge in editing animatable 3D Gaussian head avatars. The core problem stems from the inherent nature of alpha blending in 3D Gaussian splatting, where gradients from visible pixels (e.g., occluders like lips or eyelids) can erroneously affect invisible Gaussians (e.g., teeth or eyeballs). This leads to artifacts and inconsistencies in the editing process, particularly during animation. The Weighted Alpha Blending Equation (WABE) is introduced to mitigate this issue by suppressing the influence of non-visible Gaussians while enhancing the blending weight of visible ones. This selective weighting ensures that edits are correctly applied only to visible regions, preserving the integrity of occluded parts throughout the animation. Addressing motion occlusion is crucial for maintaining spatial-temporal consistency, a key requirement for high-quality and realistic results in animatable avatar editing. Failure to address this properly results in inconsistencies across different time steps and viewpoints, degrading the overall quality of the edited avatar.
Future Directions#
Future research could explore improving the robustness of GaussianAvatar-Editor to handle more complex scenarios, such as significant changes in lighting or drastic occlusions. Expanding the editing capabilities beyond textual prompts to include image-based or example-based editing would offer greater flexibility. Investigating more efficient training strategies and exploring the use of lighter-weight neural networks are important for wider accessibility and deployment. A key area for improvement is addressing the limitations imposed by the underlying FLAME model, specifically its inability to accurately represent details like tongues. Integrating more advanced facial expression models would enhance realism. Finally, thorough evaluations on diverse datasets are crucial to ensure the generalization and robustness of the method across different demographics and head shapes.
More visual insights#
More on figures

🔼 This figure illustrates the GaussianAvatar-Editor pipeline. It begins with an animatable Gaussian avatar, which is then rendered. This rendering is then passed to a 2D diffusion editor, allowing for text-based modifications. The core innovation is the Weighted Alpha Blending Equation (WABE), which addresses motion occlusion issues by weighting the contribution of visible and invisible Gaussian components. Novel loss functions are applied to maintain spatial-temporal consistency throughout the animation process, ensuring high-quality and consistent results. The final output is an edited avatar capable of high-quality and consistent 4D rendering, controllable by other actors.
read the caption
Figure 2: The overview of our method. We follow a render-edit-aggregate optimization pipeline as in Instruct-NeRF2NeRF [9]. We introduce a Weighted Alpha Blending Equation (WABE) to overcome the motion occlusion problem and our novel loss functions to enhance the spatial-temporal consistency. Our edited avatars can generate high-quality and consistent 4D renderings and can be controlled by other actors.

🔼 This figure demonstrates the Weighted Alpha Blending Equation (WABE). The left side shows the result of editing an animated 3D head model without WABE. Notice how the editing artifacts affect the occluded areas (teeth, tongue). The right side shows the improved result with WABE enabled. The algorithm successfully prioritizes visible areas during editing, leading to a more natural and accurate result, even in areas that were previously occluded.
read the caption
Figure 3: Illustration of the Weighted alpha blending equation (WABE), which is adjusted to suppress non-visible parts while enhancing visible parts. Lower left: results when WABE is disabled. Lower right: when WABE is enabled, motion-occluded regions like teeth and tongue can be successfully optimized.

🔼 This figure showcases the capabilities of the GaussianAvatar-Editor in generating novel views of edited avatars. Using the text prompt ‘Turn her into the Tolkien Elf,’ the model transforms an original avatar into a version resembling a Tolkien elf. The results demonstrate the model’s ability to produce photorealistic and consistent results across different viewpoints, highlighting its capacity for text-driven editing of animatable Gaussian head avatars.
read the caption
Figure 4: Our results on novel view synthesis. We show our edited results using the text prompt “Turn her into the Tolkien Elf”.

🔼 This figure compares novel view synthesis results from different methods, including the proposed approach and several baselines. It demonstrates that the proposed method generates higher-quality images and maintains better consistency across multiple viewpoints compared to the other methods. Each column shows the rendered views from the same method, with the rows showing different viewpoints. The visual differences highlight the improved quality and consistency achieved by the proposed approach.
read the caption
Figure 5: Comparison on novel view synthesis. Our method produces more high-quality and multi-view consistent results than baselines.

🔼 Figure 6 presents results demonstrating the model’s self-reenactment capabilities. It shows the original avatar and several edited versions generated using different text prompts. Each row represents an edit based on a different prompt. The model is able to generate new head poses and expressions that were not present in the original training data. Importantly, the edits are consistent across all 16 training camera viewpoints, indicating strong spatial and temporal consistency.
read the caption
Figure 6: Our results on self-reenactment. Self-reenactment renders held-out unseen head pose and expressions from 16 training camera viewpoints. The bottom part shows the text prompts.

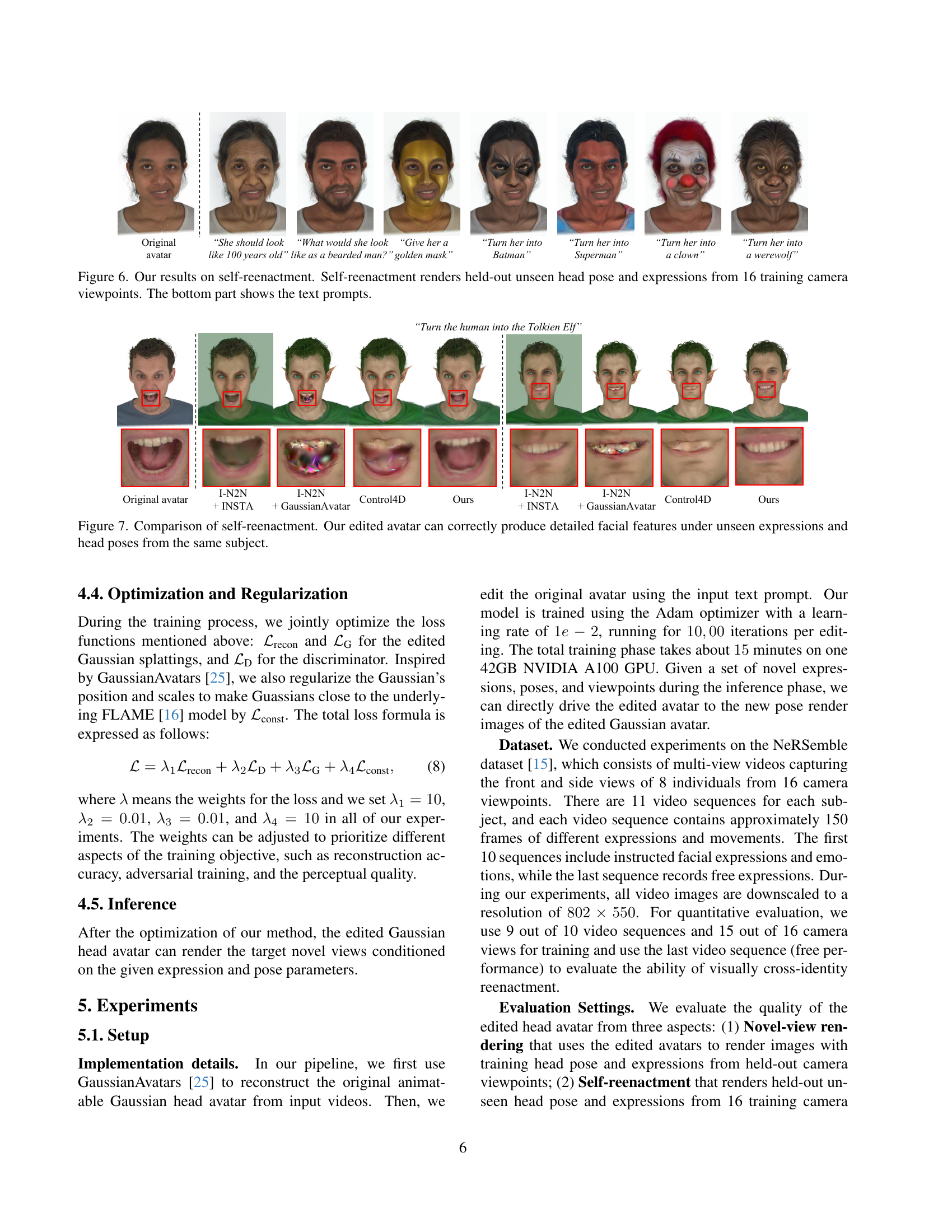
🔼 Figure 7 presents a comparison of self-reenactment results. It showcases the ability of the proposed GaussianAvatar-Editor to generate high-quality and consistent 4D renderings of head avatars, even under unseen expressions and head poses. The figure highlights the superior performance of the proposed method in producing detailed and realistic facial features compared to baseline methods, demonstrating its robustness and effectiveness in handling various scenarios.
read the caption
Figure 7: Comparison of self-reenactment. Our edited avatar can correctly produce detailed facial features under unseen expressions and head poses from the same subject.

🔼 This figure demonstrates the capabilities of GaussianAvatar-Editor in cross-identity reenactment. It shows how the system can animate a head avatar with unseen head poses and facial expressions from video sequences of a different person than the original avatar. The top portion displays the results generated by the model, illustrating the ability to transfer the style and characteristics to a new identity. The bottom portion provides examples of the text prompts used to drive the editing process, showcasing the text-to-image capability of the framework.
read the caption
Figure 8: Our results on cross-identity reenactment. Cross-identity reenactment animates the avatar to render images with unseen head poses and expressions from sequences of a different actor. The bottom part shows the text prompts.

🔼 Figure 9 presents a comparison of cross-identity reenactment results, where different methods are used to edit avatars controlled by the same source actor. The goal is to generate novel facial expressions. The figure showcases that the proposed method produces high-quality results with realistic and detailed facial features, unlike baseline methods which exhibit noticeable artifacts and distortions in the generated expressions.
read the caption
Figure 9: Comparison of Cross-identity reenactment. Different edited avatars are controlled by the same source actor. Our method can render high-quality results with novel expressions, while baseline methods suffer from artifacts.
Full paper#