TL;DR#
Current human image animation methods often struggle to generate truly lifelike and expressive animations due to issues like loss of dynamic details and rigid motions. These limitations arise from shortcomings in existing approaches that focus on human pose control, often neglecting the complexity of natural human movements and environmental interactions. Existing methods often cause the loss of dynamic details, resulting in static backgrounds and unnatural human motion. This paper also finds that prior methods for maintaining appearance consistency can lead to overly strong constraints, hindering the generation of fluid and dynamic scenes.
The researchers present X-Dyna, a novel zero-shot diffusion-based method that addresses these issues. X-Dyna uses a “Dynamics-Adapter” module to effectively integrate reference appearance into spatial attentions without sacrificing dynamic details. It also incorporates a local face control module for more precise facial expression transfer. The model is trained on a diverse dataset of human motion and natural scene videos, allowing it to learn subtle human dynamics and fluid environmental effects. Comprehensive evaluations show X-Dyna outperforms state-of-the-art methods, demonstrating superior expressiveness, identity preservation, and visual quality.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances the field of human image animation. It addresses limitations of prior methods by generating more realistic and expressive animations, thus opening up new avenues for research in areas such as virtual humans, digital arts, and social media. The introduction of the Dynamics-Adapter module and a novel training strategy are particularly significant contributions, paving the way for more lifelike and controllable human image animation.
Visual Insights#

🔼 This figure illustrates the X-Dyna architecture, a diffusion-based model for human image animation. It uses a pretrained diffusion UNet, enhanced with a Dynamics Adapter (D) to integrate reference image context into spatial attention, improving dynamic detail generation without sacrificing pose control. A ControlNet (CP) handles body pose, while a local face control module (CF) manages facial expressions using synthesized cross-identity face patches. The model is trained on a diverse dataset of human motion and natural scene videos, resulting in realistic animations with accurate pose and expression transfer.
read the caption
Figure 1: We leverage a pretrained diffusion UNet backbone for controlled human image animation, enabling expressive dynamic details and precise motion control. Specifically, we introduce a dynamics adapter D𝐷Ditalic_D that seamlessly integrates the reference image context as a trainable residual to the spatial attention, in parallel with the denoising process, while preserving the original spatial and temporal attention mechanisms within the UNet. In addition to body pose control via a ControlNet CPsubscript𝐶𝑃C_{P}italic_C start_POSTSUBSCRIPT italic_P end_POSTSUBSCRIPT , we introduce a local face control module CFsubscript𝐶𝐹C_{F}italic_C start_POSTSUBSCRIPT italic_F end_POSTSUBSCRIPT that implicitly learns facial expression control from a synthesized cross-identity face patch. We train our model on a diverse dataset of human motion videos and natural scene videos simultaneously. Our model achieves remarkable transfer of body poses and facial expressions, as well as highly vivid and detailed dynamics for both the human and the scene.
| Method | FG-DTFVD | BG-DTFVD | DTFVD |
|---|---|---|---|
| MagicAnimate [49] | 1.753 | 2.142 | 2.601 |
| Animate-Anyone [16] | 1.789 | 2.034 | 2.310 |
| MagicPose [4] | 1.846 | 1.901 | 2.412 |
| MimicMotion [54] | 2.639 | 3.274 | 3.590 |
| X-Dyna | 0.900 | 1.101 | 1.518 |
🔼 This table presents a quantitative comparison of the X-Dyna model against state-of-the-art methods in terms of dynamics texture generation. The metrics used are FG-DTFVD (foreground dynamics texture Frechet Video Distance), BG-DTFVD (background dynamics texture Frechet Video Distance), and DTFVD (overall dynamics texture Frechet Video Distance). Lower scores indicate better performance. The DTFVD metric is specifically calculated by replacing the pre-trained backbone of the FVD (Frechet Video Distance) metric with one trained on the DTDB (Dynamics Texture Database) dataset. This allows for a more focused evaluation of the dynamic texture quality in the generated videos.
read the caption
Table 1: Quantitative comparisons of X-Dyna with the recent state-of-the-art (SOTA) methods on dynamics texture generation. A downward-pointing arrow indicates that lower values are better and vise versa. DTFVD [5] is calculated by replacing the FVD pre-trained backbone with one trained on DTDB [10]. FG-DTFVD denotes the DTFVD is running on the foreground parts of the videos after segmentation, and BG-DTFVD denotes the DTFVD of the background parts.
In-depth insights#
X-Dyna: Background#
X-Dyna’s background likely involves a review of existing human image animation techniques. The authors probably discussed limitations of previous approaches, such as difficulties in generating realistic, dynamic motions while maintaining identity consistency, particularly with zero-shot methods. Prior methods may have struggled with dynamic background generation, often resulting in static or unrealistic environments. Therefore, X-Dyna aims to address these shortcomings by introducing novel methods to handle both human motion and scene dynamics simultaneously. This likely involved researching various architectures, such as diffusion models, and exploring ways to effectively integrate appearance information from a single reference image while preserving fine details and fluid movements. The background section would set the stage by highlighting the challenges faced and the gap that X-Dyna attempts to fill within the broader field of computer vision and video generation. A thorough exploration of existing diffusion models and control mechanisms would have formed a crucial part of the background research. Finally, the background section likely positioned X-Dyna by comparing it to state-of-the-art approaches, demonstrating its improvement and novel contributions.
Dynamics Adapter#
The Dynamics Adapter is a crucial innovation enhancing the X-Dyna model. It directly addresses the shortcomings of prior methods by seamlessly integrating reference appearance context into the diffusion process without hindering the generation of dynamic details. Unlike previous approaches that rely on fully trainable parallel UNets (ReferenceNet) or simple residual connections (IP-Adapter), which often lead to static backgrounds and limited expressiveness, the Dynamics Adapter cleverly leverages a lightweight module that propagates context via trainable query and output projection layers within the self-attention mechanism of the diffusion backbone. This subtle yet effective integration preserves the UNet’s inherent ability to synthesize fluid and intricate dynamics while ensuring that the generated human image and scene maintain visual consistency with the provided reference image. The design is ingenious in its efficiency, achieving high-quality results with minimal added parameters, thereby avoiding the limitations of heavier, fully trainable modules. By disentangling appearance from motion synthesis, the Dynamics Adapter demonstrates a significant step toward more realistic and expressive human image animation.
Face Expression Ctrl#
The concept of ‘Face Expression Ctrl’ within the context of a research paper on human image animation is crucial for achieving realism. It suggests a method for precisely controlling facial expressions in generated animations, going beyond simple pose imitation. This is likely achieved through techniques that isolate facial features from body movements, enabling independent manipulation. Deep learning models might be employed, trained on datasets of diverse facial expressions paired with corresponding control signals. A critical aspect would be disentangling identity from expression, ensuring that changes in expression don’t alter the identity of the animated person. This could involve employing generative adversarial networks (GANs) or diffusion models, carefully designed to preserve identity features while allowing for nuanced expression changes. The success of ‘Face Expression Ctrl’ would significantly impact the quality of the animations, moving them closer to photorealistic levels and offering a greater degree of creative control.
Training & Results#
A thorough analysis of a research paper’s “Training & Results” section should delve into the specifics of the training process, encompassing the dataset used, model architecture, hyperparameters, and training methodology. Crucially, it should evaluate the chosen metrics for assessing model performance and discuss their limitations. The results section needs to present a comprehensive evaluation, including both quantitative (e.g., precision, recall, F1-score, AUC) and qualitative (e.g., visual inspection, user studies) analyses. Statistical significance of findings should be established, avoiding overfitting and highlighting potential biases in the dataset. The discussion should compare results to prior work, emphasizing novelty and improvements. Finally, any limitations of the training or evaluation processes, potential sources of error, and future research directions should be explicitly addressed.
Future of X-Dyna#
The future of X-Dyna hinges on addressing its current limitations and expanding its capabilities. Improving handling of extreme pose variations is crucial; the model struggles when target poses deviate significantly from the reference image. Enhancing hand pose generation is another key area for improvement, requiring potentially higher-resolution data and advanced hand-pose representation models. Exploring integration with more advanced diffusion models like Stable Diffusion 3 and incorporating camera trajectory or drag control would enhance user interaction and control. Extending the training data to include more diverse scenes and dynamic backgrounds will further improve the realism of generated animations. Finally, research into disentanglement techniques for better separation of appearance, motion, and background elements will allow for finer-grained control and higher-quality results. Addressing these aspects will solidify X-Dyna’s position as a leading technology in human image animation.
More visual insights#
More on figures

🔼 Figure 2 illustrates a comparison of three different methods for incorporating reference images into a diffusion model for human image animation. Panel (a) shows the results using IP-Adapter, which generates vivid textures but struggles to preserve the appearance of the reference image. Panel (b) displays the results obtained using ReferenceNet, which successfully maintains identity but generates static backgrounds and lacks dynamic elements. Finally, panel (c) presents the results achieved using the proposed Dynamics-Adapter, demonstrating its ability to produce both expressive details and consistent identities.
read the caption
Figure 2: a) IP-Adapter [50] can generate vivid texture from the reference image but fails to preserve the appearance. b) Though ReferenceNet [16] can preserve the identity from the human reference, it generates a static background without any dynamics. c) Dynamics-Adapter provides both expressive details and consistent identities.

🔼 Figure 3 illustrates three different approaches to integrating reference image information into a Stable Diffusion (SD) model for controlled image generation. (a) shows the IP-Adapter method, where the reference image is encoded as a CLIP embedding and added as a residual to the cross-attention layers of the SD UNet. (b) depicts ReferenceNet, which uses a parallel, trainable UNet to process the reference image and concatenate its self-attention features with those of the SD UNet. (c) presents the Dynamics-Adapter, a more efficient method that uses a partially shared-weight UNet to process the reference image and learns a residual within the self-attention mechanism of the SD UNet using trainable query and output layers, while keeping the rest of the SD UNet’s weights frozen.
read the caption
Figure 3: a) IP-Adapter [50] encodes the reference image as an image CLIP embedding and injects the information into the cross-attention layers in SD as the residual. b) ReferenceNet [16] is a trainable parallel UNet and feeds the semantic information into SD via concatenation of self-attention features. c) Dynamics-Adapter encodes the reference image with a partially shared-weight UNet. The appearance control is realized by learning a residual in the self-attention with trainable query and output linear layers. All other components share the same frozen weight with SD.

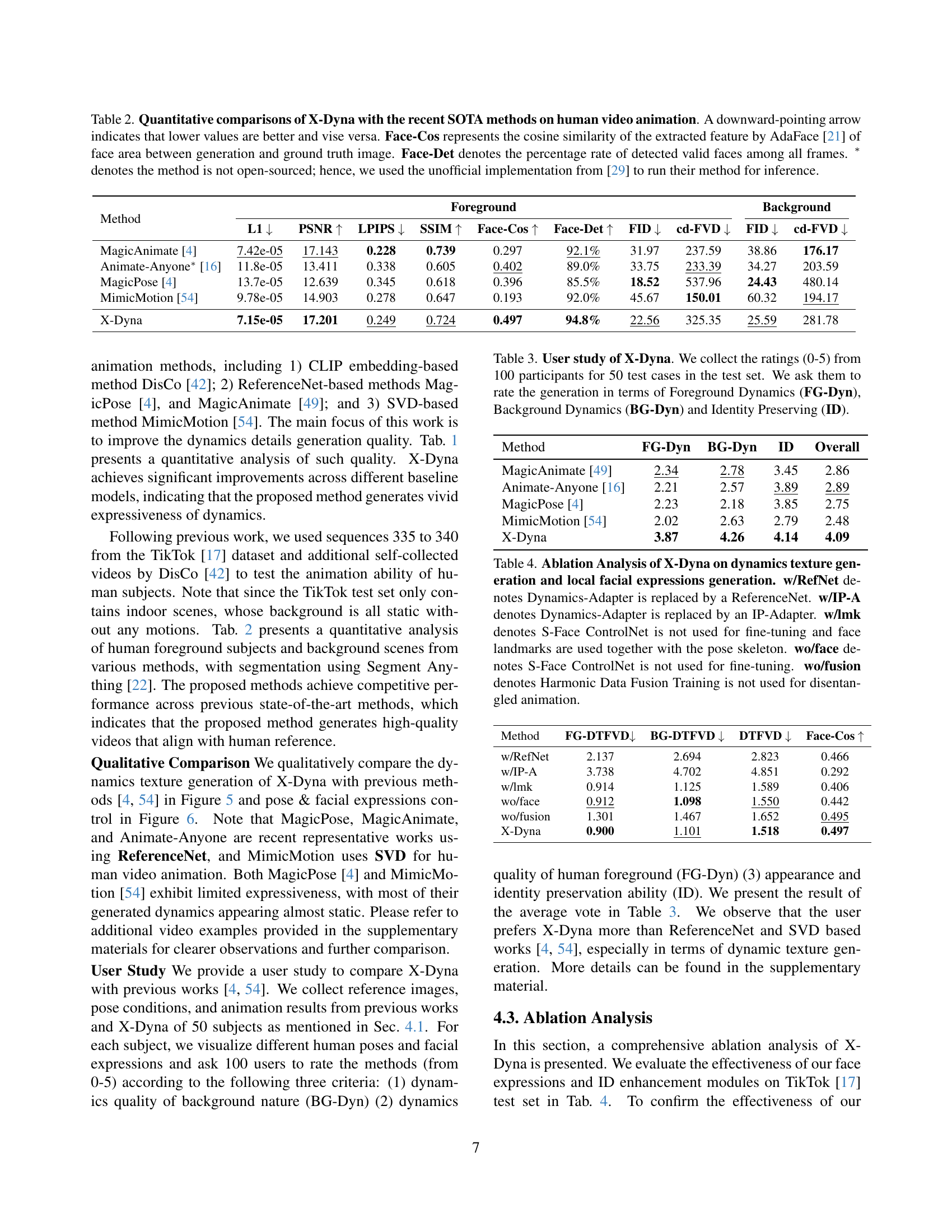
🔼 This figure shows a qualitative comparison of human image animation results in dynamic scenes. It compares the output of the proposed X-Dyna method against several state-of-the-art (SOTA) techniques. The goal is to highlight X-Dyna’s ability to generate realistic human and scene dynamics while maintaining the original image structure. The comparison demonstrates that unlike the existing methods, X-Dyna successfully generates consistent and lifelike interactions between the animated human and their environment.
read the caption
Figure 4: Qualitative Comparison on Human in Dynamic Scene. While existing SOTA methods struggle to generate consistent and realistic scene dynamics involving humans, our method successfully produces dynamic human-scene interactions while preserving the structure of the reference image.

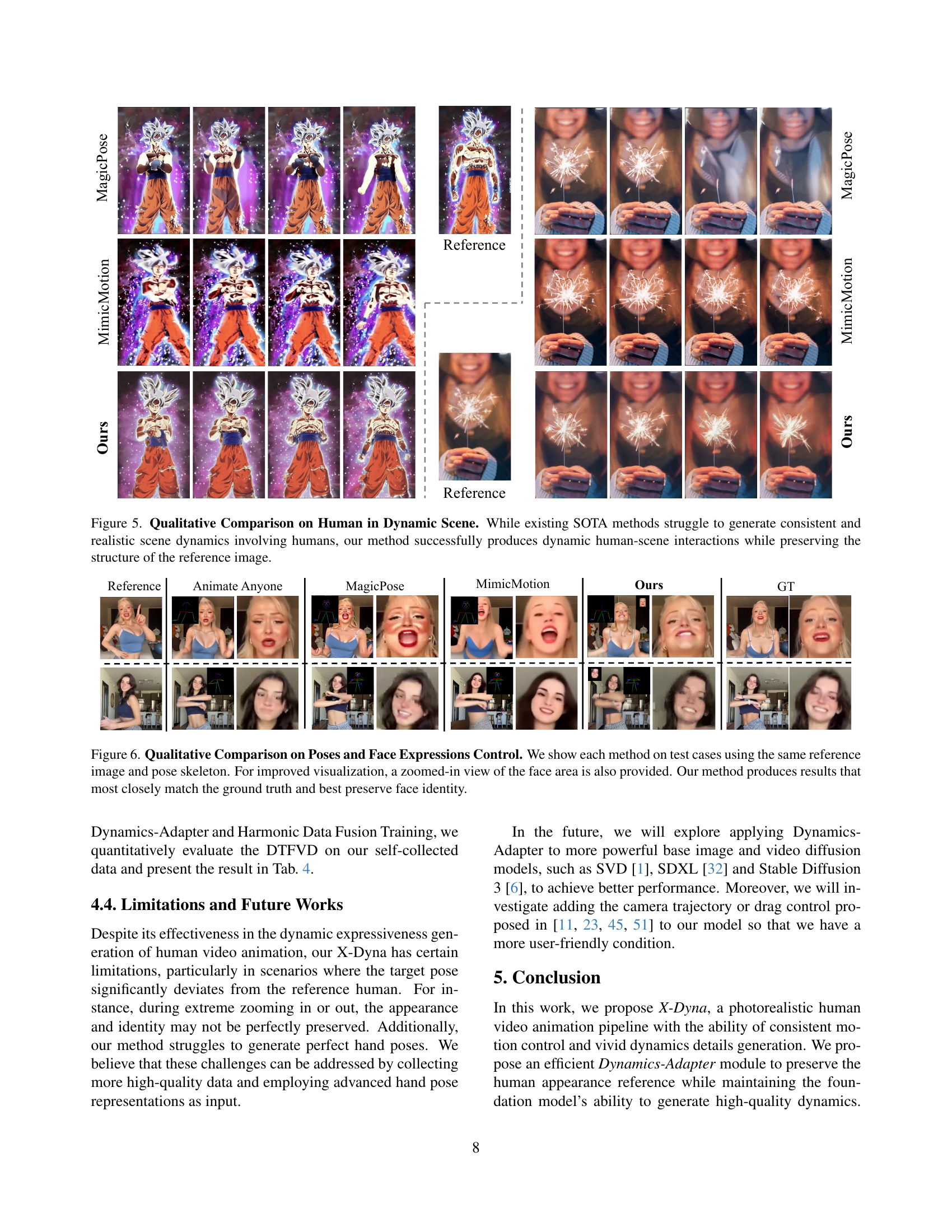
🔼 This figure compares the results of different human image animation methods on pose and facial expression control. Each method is tested using the same reference image and pose skeleton. Zoomed-in views of the face are included for detailed comparison. The results show that the proposed method (X-Dyna) most accurately matches the ground truth and best preserves the identity of the subject.
read the caption
Figure 5: Qualitative Comparison on Poses and Face Expressions Control. We show each method on test cases using the same reference image and pose skeleton. For improved visualization, a zoomed-in view of the face area is also provided. Our method produces results that most closely match the ground truth and best preserve face identity.
More on tables
| Method | Foreground | Background | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L1 | PSNR | LPIPS | SSIM | Face-Cos | Face-Det | FID | cd-FVD | FID | cd-FVD | |
| MagicAnimate [4] | 7.42e-05 | 17.143 | 0.228 | 0.739 | 0.297 | 92.1% | 31.97 | 237.59 | 38.86 | 176.17 |
| Animate-Anyone∗ [16] | 11.8e-05 | 13.411 | 0.338 | 0.605 | 0.402 | 89.0% | 33.75 | 233.39 | 34.27 | 203.59 |
| MagicPose [4] | 13.7e-05 | 12.639 | 0.345 | 0.618 | 0.396 | 85.5% | 18.52 | 537.96 | 24.43 | 480.14 |
| MimicMotion [54] | 9.78e-05 | 14.903 | 0.278 | 0.647 | 0.193 | 92.0% | 45.67 | 150.01 | 60.32 | 194.17 |
| X-Dyna | 7.15e-05 | 17.201 | 0.249 | 0.724 | 0.497 | 94.8% | 22.56 | 325.35 | 25.59 | 281.78 |
🔼 This table quantitatively compares the performance of X-Dyna against other state-of-the-art (SOTA) methods in human video animation. It uses several metrics to assess quality: L1 loss (lower is better, indicating less error), PSNR (higher is better, measuring peak signal-to-noise ratio), LPIPS (lower is better, representing perceptual similarity), SSIM (higher is better, indicating structural similarity), Face-Cosine Similarity (higher is better, showing how well face identity is preserved), and the percentage of frames where a face is successfully detected (Face-Det, higher is better). It also includes FID and cd-FVD scores (lower is better), evaluating the quality of generated videos overall. The asterisk (*) indicates that results for one method were obtained using an unofficial implementation because the original code wasn’t publicly available.
read the caption
Table 2: Quantitative comparisons of X-Dyna with the recent SOTA methods on human video animation. A downward-pointing arrow indicates that lower values are better and vise versa. Face-Cos represents the cosine similarity of the extracted feature by AdaFace [21] of face area between generation and ground truth image. Face-Det denotes the percentage rate of detected valid faces among all frames. ∗ denotes the method is not open-sourced; hence, we used the unofficial implementation from [29] to run their method for inference.
| Method | FG-Dyn | BG-Dyn | ID | Overall |
|---|---|---|---|---|
| MagicAnimate [49] | 2.34 | 2.78 | 3.45 | 2.86 |
| Animate-Anyone [16] | 2.21 | 2.57 | 3.89 | 2.89 |
| MagicPose [4] | 2.23 | 2.18 | 3.85 | 2.75 |
| MimicMotion [54] | 2.02 | 2.63 | 2.79 | 2.48 |
| X-Dyna | 3.87 | 4.26 | 4.14 | 4.09 |
🔼 This user study evaluates X-Dyna’s performance in generating high-quality human video animations by collecting ratings from 100 participants on 50 different video clips. Each participant provided scores (0-5) assessing three aspects of the generated videos: Foreground Dynamics (how well the model animates the foreground human), Background Dynamics (how well it animates the background elements), and Identity Preservation (how well the model maintains the identity of the reference image). The results provide insights into X-Dyna’s capability in various aspects of video animation.
read the caption
Table 3: User study of X-Dyna. We collect the ratings (0-5) from 100 participants for 50 test cases in the test set. We ask them to rate the generation in terms of Foreground Dynamics (FG-Dyn), Background Dynamics (BG-Dyn) and Identity Preserving (ID).
| Method | FG-DTFVD | BG-DTFVD | DTFVD | Face-Cos |
|---|---|---|---|---|
| w/RefNet | 2.137 | 2.694 | 2.823 | 0.466 |
| w/IP-A | 3.738 | 4.702 | 4.851 | 0.292 |
| w/lmk | 0.914 | 1.125 | 1.589 | 0.406 |
| wo/face | 0.912 | 1.098 | 1.550 | 0.442 |
| wo/fusion | 1.301 | 1.467 | 1.652 | 0.495 |
| X-Dyna | 0.900 | 1.101 | 1.518 | 0.497 |
🔼 This table presents an ablation study evaluating the impact of different components of the X-Dyna model on dynamics texture generation and facial expression control. It compares the performance of the full X-Dyna model against variations where specific modules are removed or replaced. Specifically, it shows results with and without the Dynamics-Adapter, using alternative reference modules (ReferenceNet, IP-Adapter), with and without the S-Face ControlNet (which handles facial expressions using local face control rather than landmarks), and with and without Harmonic Data Fusion Training (which mixes data from human videos and natural scenes). The metrics used likely assess the quality of generated video dynamics and perhaps facial realism.
read the caption
Table 4: Ablation Analysis of X-Dyna on dynamics texture generation and local facial expressions generation. w/RefNet denotes Dynamics-Adapter is replaced by a ReferenceNet. w/IP-A denotes Dynamics-Adapter is replaced by an IP-Adapter. w/lmk denotes S-Face ControlNet is not used for fine-tuning and face landmarks are used together with the pose skeleton. wo/face denotes S-Face ControlNet is not used for fine-tuning. wo/fusion denotes Harmonic Data Fusion Training is not used for disentangled animation.
| Method | DTFVD | FID | Face-Exp |
|---|---|---|---|
| MagicAnimate [49] | 6.708 | 250.75 | 0.134 |
| Animate-Anyone [16] | 6.820 | 253.29 | 0.123 |
| MagicPose [4] | 7.062 | 244.25 | 0.121 |
| MimicMotion [54] | 6.823 | 258.91 | 0.109 |
| X-Dyna | 5.923 | 246.16 | 0.105 |
🔼 Table 5 presents a quantitative comparison of X-Dyna’s performance against state-of-the-art (SOTA) methods in cross-driving human animation. Lower values indicate better performance for all metrics. The table uses DTFVD (Dynamic Texture Frechet Video Distance) and FID (Frechet Inception Distance) to assess the overall quality of the generated videos. Face-Exp represents the absolute error between facial expressions in the generated and driving videos. This table provides a numerical comparison of the different methods’ performance across these key metrics.
read the caption
Table 5: Quantitative comparisons of X-Dyna with recent state-of-the-art (SOTA) methods on cross-driving human animation. A downward-pointing arrow indicates that lower values are better. DTFVD and FID are used to evaluate the overall quality of generated videos. Face-Exp denotes the absolute error of facial expressions between generated videos and driving videos.
| Metric | F-statistic | p-value |
|---|---|---|
| FG-Dyn | 7.495 | 0.000007 |
| BG-Dyn | 5.327 | 0.000331 |
| ID | 4.685 | 0.001016 |
| Overall | 5.617 | 0.000199 |
🔼 This table presents the results of a one-way analysis of variance (ANOVA) test performed on user ratings from a user study. The study evaluated three criteria: Foreground Dynamics (FG-Dyn), Background Dynamics (BG-Dyn), and Identity Preservation (ID), along with an overall score. The ANOVA test determines if there are statistically significant differences in the ratings across different methods. The F-statistic indicates the strength of these differences, and the p-value shows if these differences are statistically significant (p≤0.05 indicates significance).
read the caption
Table 6: ANOVA Test Results for Ratings from the User Study.
Full paper#