TL;DR#
Current speech super-resolution (SR) techniques often use separate networks for feature extraction and waveform generation, leading to inconsistent representations and lower quality, particularly for out-of-domain audio. This often results in poor speech quality and generalization. This paper introduces HiFi-SR, which uses a unified transformer-convolutional generator to address this issue. The unified approach facilitates the seamless prediction of latent representations and their conversion into high-resolution waveforms.
HiFi-SR incorporates a multi-band, multi-scale discriminator and mel-spectrogram loss for enhanced high-frequency fidelity. Experiments show that HiFi-SR substantially outperforms existing methods in both objective and subjective evaluations, demonstrating its effectiveness and robustness across various datasets, including those outside its original training domain. The unified approach of HiFi-SR, its superior performance, and its generalization capabilities make it a significant advancement in the field of speech super-resolution.
Key Takeaways#
Why does it matter?#
This paper is important because it presents HiFi-SR, a novel approach to speech super-resolution that significantly outperforms existing methods. Its unified network architecture and end-to-end training offer a more robust and generalizable solution, addressing limitations of previous two-stage approaches. The results, showing improvements across objective and subjective metrics, open new avenues for high-fidelity speech processing and related applications.
Visual Insights#

🔼 The figure illustrates the architecture of HiFi-SR, a novel generative adversarial network designed for high-fidelity speech super-resolution. It uses a unified transformer-convolutional generator, combining a MossFormer (a type of transformer) and a recurrent network to process low-resolution mel-spectrograms. The output of this generator is then fed into a HiFi-GAN generator to create a high-resolution waveform. Three discriminators (MSD, MPD, and MBD) evaluate the generated audio, guiding the training process through adversarial learning. The overall training objective minimizes both feature matching loss and mel-spectrogram reconstruction loss to achieve high-fidelity audio.
read the caption
Fig. 1: Overview of our proposed generative transformer-convolutional adversarial network for speech super-resolution (HiFi-SR). The transformer-convolutional generator includes a hybrid MossFormer and recurrent network followed by a reused HiFi-GAN generator. Three discriminators of MSD, MPD and MBD are combined with feature matching loss ℒfsubscriptℒ𝑓\mathcal{L}_{f}caligraphic_L start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT and mel-spectrogram loss ℒmsubscriptℒ𝑚\mathcal{L}_{m}caligraphic_L start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT for high-fidelity adversarial training.
| Model | No. Parameters | 4 kHz | 8 kHz | 16 kHz | 24 kHz | AVG |
|---|---|---|---|---|---|---|
| Unprocessed | - | 6.08 | 5.15 | 4.85 | 3.84 | 4.98 |
| Nu-wave | 3.0M4 | 1.42 | 1.42 | 1.36 | 1.22 | 1.36 |
| WSRGlow | 229.9M4 | 1.12 | 0.98 | 0.85 | 0.79 | 0.94 |
| AudioSR-Speech | - | 1.15 | 1.03 | 0.82 | 0.69 | 0.92 |
| NVSR | 99.0M | 0.98 | 0.91 | 0.81 | 0.70 | 0.85 |
| HiFi-SR w/o MBD | 101M | 0.97 | 0.88 | 0.79 | 0.69 | 0.83 |
| HiFi-SR w/o | 101M | 0.98 | 0.89 | 0.80 | 0.70 | 0.84 |
| HiFi-SR (proposed) | 101M | 0.95 | 0.86 | 0.77 | 0.68 | 0.82 |
🔼 This table presents objective evaluation results for speech super-resolution models. It compares the performance of various models (including Nu-wave, WSRGlow, AudioSR, NVSR, and the proposed HiFi-SR) in upscaling speech audio from lower sampling rates (4kHz, 8kHz, 16kHz, and 24kHz) to a target rate of 48kHz. The evaluation metric used is the Log-Spectral Distance (LSD), with lower values indicating better performance. Note that Nu-wave and WSRGlow are limited to processing speech at a single input sampling rate and do not support the other resolutions presented in this table.
read the caption
Table 1: Objective evaluation results for 48 kHz speech super-resolution from input sampling rates of 4 kHz, 8 kHz, 16 kHz, and 24 kHz on the VCTK test set. The evaluation metric is the average LSD across all utterances, with lower values indicating better performance. Nu-wave and WSRGlow have fixed input resolutions.
In-depth insights#
Unified GANs for SR#
The concept of “Unified GANs for SR” suggests a significant advancement in speech super-resolution (SR). Traditional GAN-based SR methods often involve separate networks for feature extraction and waveform generation, leading to potential inconsistencies between representations. A unified approach, however, would seamlessly integrate these stages within a single GAN architecture. This promises improved coherence and fidelity in the generated high-resolution speech. By directly mapping low-resolution inputs to high-resolution outputs, a unified GAN could avoid suboptimal intermediate representations that might hinder the overall quality. The end-to-end training paradigm in such a model would also simplify the training process, potentially enhancing efficiency and performance. Furthermore, a unified architecture could be more robust, especially in handling out-of-domain data, as the entire system is trained to optimize for overall SR quality, rather than relying on separate, potentially mismatched, modules. The resulting model would likely achieve higher accuracy and a more natural, high-fidelity output. Ultimately, the promise of a unified GAN lies in its potential to push the boundaries of speech SR, resulting in a more efficient and effective system.
Transformer-CNN Synergy#
The concept of ‘Transformer-CNN Synergy’ in high-fidelity speech super-resolution is intriguing. It leverages the strengths of both architectures: Transformers excel at capturing long-range dependencies in sequential data like speech, while CNNs are adept at processing local features and performing efficient upsampling. Combining them allows for a more robust and accurate SR model. The transformer acts as a powerful encoder, mapping low-resolution spectrograms to a rich latent representation that encapsulates crucial temporal information. This representation is then fed into the CNN, which skillfully reconstructs the high-resolution waveform, effectively translating the latent information into a detailed audio signal. This synergy enables the model to handle both the global context and local details of speech, ultimately improving the quality and naturalness of the super-resolved audio. A unified framework, avoiding the pitfalls of independent training and concatenation, ensures consistent representations throughout the process, leading to improved generalization and robustness, particularly in out-of-domain scenarios.
Multi-scale Discriminator#
A multi-scale discriminator in speech super-resolution aims to enhance the model’s ability to capture and distinguish audio features across various frequency ranges. By incorporating multiple scales, the discriminator becomes more robust to variations in the input signal, improving the quality of generated high-resolution audio. The multi-scale approach helps the model learn a more comprehensive representation of the input’s time-frequency characteristics. A key benefit is the enhanced ability to identify artifacts and inconsistencies in the generated audio, leading to better overall fidelity. This approach is particularly useful in speech SR, where high-frequency details are crucial but often challenging to reconstruct accurately. Moreover, the multi-scale nature allows the discriminator to focus on various levels of detail, from coarse-grained structural aspects to fine-grained high-frequency components, leading to a more refined and realistic audio output. Using multi-scale discriminators alongside GAN-based training strategies usually proves successful in improving model performance.
ABX Testing & Results#
An ABX test, a type of listening test, is crucial for evaluating the perceptual quality of speech super-resolution (SR) systems. In this context, it would involve comparing the original high-fidelity audio (X), a reference SR output from a known system (A), and the SR output from the proposed HiFi-SR system (B). Listeners would be tasked with identifying which of A or B sounds more similar to X. The results would provide objective evidence of HiFi-SR’s performance against the state-of-the-art, especially in out-of-domain scenarios. Statistical significance of the results would need to be analyzed to determine if HiFi-SR’s perceived quality is genuinely superior. The success of HiFi-SR in the ABX test would validate its claim of improved high-frequency fidelity and better generalization. A detailed reporting of the ABX test setup, including participant selection, the number of trials, and any statistical analysis methods used, is crucial for validating the study’s conclusions. The comparative results from the ABX test would offer a valuable user-centric assessment, supplementing the objective metrics used.
SR Generalization#
Speech super-resolution (SR) models often struggle with generalization, especially when encountering out-of-domain data. The core issue lies in the model’s ability to learn underlying representations robust enough to handle variations in speaker characteristics, recording conditions, and speech styles. HiFi-SR’s unified architecture, combining transformer and convolutional networks, is a key factor in improving generalization. By seamlessly handling latent representation prediction and time-domain waveform conversion, it avoids the inconsistencies that can arise from independently trained modules. The use of a multi-band, multi-scale time-frequency discriminator further enhances the model’s ability to discern fine-grained details across various frequency bands and time scales, leading to improved high-frequency fidelity and generalization across diverse acoustic environments. The comprehensive experimental results across both in-domain and out-of-domain datasets demonstrate HiFi-SR’s superior generalization capabilities compared to existing methods. This success showcases the importance of a unified architecture and advanced discriminative training for robust and generalized speech SR.
More visual insights#
More on figures

🔼 Figure 2 presents a visual comparison of spectrograms generated by three different speech super-resolution (SR) models: the unprocessed low-resolution input, the output of the NVSR model, and the output of the proposed HiFi-SR model. All spectrograms are derived from the same sample input taken from the VocalSet singing dataset. The figure highlights the superior performance of HiFi-SR in accurately reconstructing the high-resolution details of the original singing voice compared to the NVSR model, as evidenced by the more detailed and structurally accurate spectrogram. This visual representation helps to demonstrate the significant improvement in the high-fidelity speech enhancement achieved by the HiFi-SR model over the baseline NVSR model.
read the caption
Fig. 2: Spectrogram illustrations of different system outputs for a sample input from the VocalSet singing test set. It demonstrates that HiFi-SR significantly outperforms the baseline NVSR model.

🔼 This figure displays a bar chart comparing the performance of NVSR and HiFi-SR speech super-resolution models on the EXPRESSO dataset. The x-axis represents four different input sampling rates (4kHz, 8kHz, 16kHz, and 32kHz), all upscaled to a target rate of 48kHz. The y-axis shows the Log-Spectral Distance (LSD) values, a metric measuring the difference between the generated and ground-truth audio. Lower LSD values indicate better performance. Separate bars are shown for the unprocessed low-resolution audio, the NVSR model output, and the HiFi-SR model output for each input sampling rate, allowing for a direct comparison of the two models’ performance at various input resolutions.
read the caption
Fig. 3: Comparison results of NVSR and HiFi-SR on EXPRESSO test set with 48 kHz target sampling rate and four input sampling rates.

🔼 This figure displays a comparison of the performance of NVSR and HiFi-SR models on the VocalSet dataset. The results show the Log-Spectral Distance (LSD) values for both models across four different input sampling rates (4kHz, 8kHz, 16kHz, and 32kHz), all upscaled to a 48kHz target sampling rate. Lower LSD values indicate better performance, with HiFi-SR consistently outperforming NVSR across all input rates.
read the caption
Fig. 4: Comparison results of NVSR and HiFi-SR on VocalSet test set with 48 kHz target sampling rate and four input sampling rates.

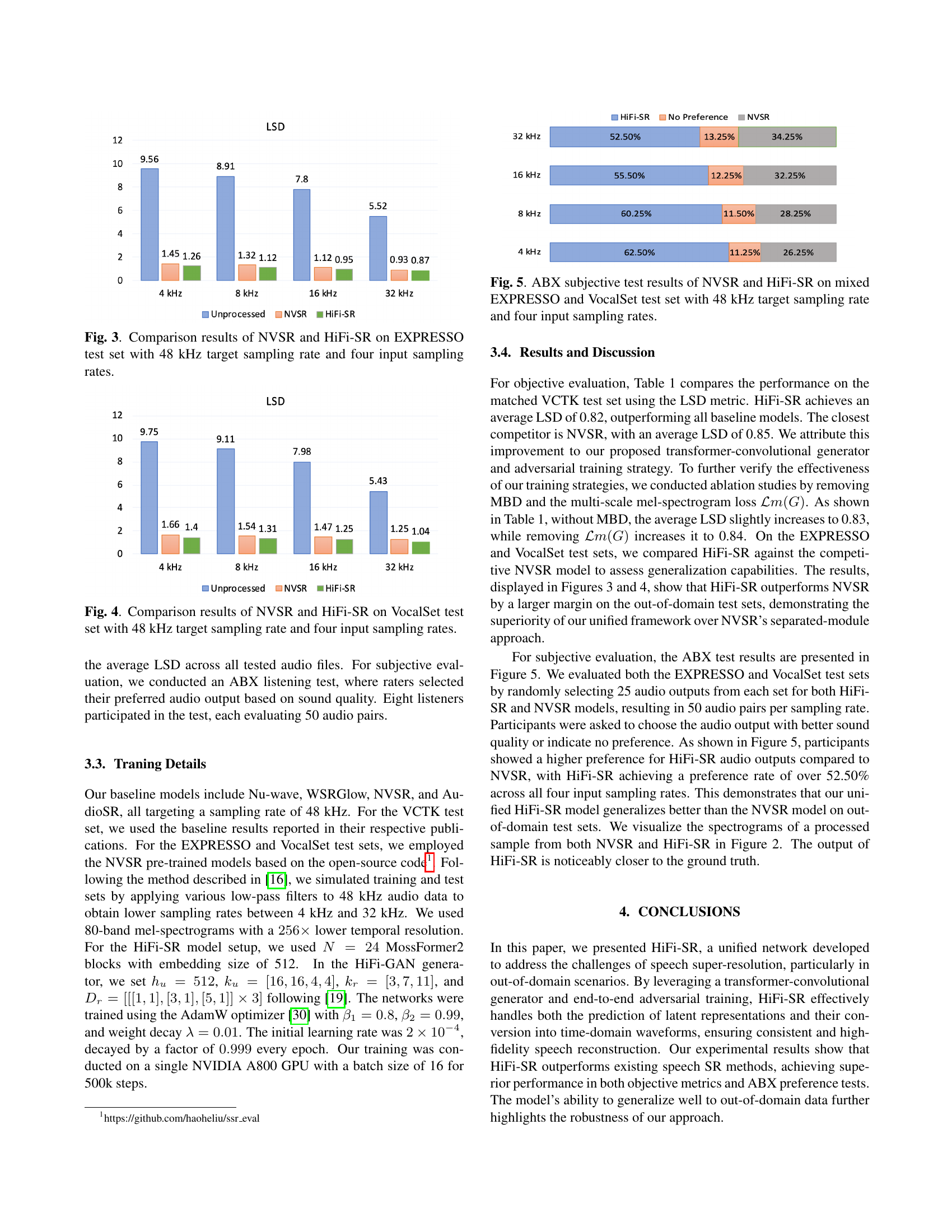
🔼 This ABX test compares the subjective audio quality of NVSR and HiFi-SR across different input sampling rates (4 kHz, 8 kHz, 16 kHz, and 32 kHz) upscaled to 48 kHz. The test utilizes a mixed dataset combining the EXPRESSO and VocalSet datasets, ensuring a diverse range of speech and singing styles. The figure presents the percentage of times HiFi-SR was preferred over NVSR by listeners, demonstrating its superior audio quality.
read the caption
Fig. 5: ABX subjective test results of NVSR and HiFi-SR on mixed EXPRESSO and VocalSet test set with 48 kHz target sampling rate and four input sampling rates.
Full paper#