TL;DR#
Academic paper search is challenging due to long-tail queries and the need for comprehensive surveys. Existing tools often fall short, causing researchers to spend considerable time conducting literature reviews. This paper introduces PaSa, an AI-powered paper search agent that can autonomously manage multiple tasks such as invoking search tools, reading papers, and selecting relevant references. This is achieved by using Large Language Models (LLMs) and optimizing it with reinforcement learning.
PaSa is trained using a new synthetic dataset, AutoScholarQuery, and then evaluated using a real-world benchmark dataset, RealScholarQuery. The results show PaSa significantly outperforms existing baselines in terms of recall and precision, demonstrating its effectiveness in addressing complex scholarly queries. The method includes a Crawler LLM agent that automatically invokes search tools and extracts citations, and a Selector LLM agent that carefully reads each paper to assess its relevance. The study also provides both datasets and code for reproducibility, making it a valuable contribution to the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers seeking to improve academic literature searches. PaSa’s autonomous approach to literature review, using LLMs to refine queries, read papers, and navigate citations, is highly relevant to current research trends and offers a significant improvement over existing methods. The study also provides valuable datasets (AutoScholarQuery and RealScholarQuery) that can benefit the wider research community. It paves the way for future work developing more sophisticated AI-powered research tools.
Visual Insights#

🔼 PaSa’s architecture centers around two large language model (LLM) agents: the Crawler and the Selector. The Crawler starts by processing a user’s research query. It then autonomously interacts with search engines, retrieves papers, and expands its search by following citations. All retrieved papers are added to a queue. The Selector then takes each paper from the queue and evaluates whether it matches the user’s query criteria, effectively filtering results based on relevance.
read the caption
Figure 1: Architecture of PaSa. The system consists of two LLM agents, Crawler and Selector. The Crawler processes the user query and can access papers from the paper queue. It can autonomously invoke the search tool, expand citations, or stop processing of the current paper. All papers collected by the Crawler are appended to the paper queue. The Selector reads each paper in the paper queue to determine whether it meets the criteria specified in the user query.
| Query: Could you provide me some studies that proposed hierarchical neural models to capture spatiotemporal features in sign videos? Query Date: 2023-05-02 Answer Papers: [1] TSPNet: Hierarchical Feature Learning via Temporal Semantic Pyramid for Sign Language Translation [2] Sign Language Translation with Hierarchical Spatio-Temporal Graph Neural Network |
| Source: SLTUnet: A Simple Unified Model for Sign Language Translation, ICLR 2023 |
| Query: Which studies have focused on nonstationary RL using value-based methods, specifically Upper Confidence Bound (UCB) based algorithms? Query Date: 2023-08-10 Answer Papers: [1] Reinforcement Learning for Non-Stationary Markov Decision Processes: The Blessing of (More) Optimism [2] Efficient Learning in Non-Stationary Linear Markov Decision Processes [3] Nonstationary Reinforcement Learning with Linear Function Approximation Source: Provably Efficient Algorithm for Nonstationary Low-Rank MDPs, NeurIPS 2023 |
| Query: Which studies have been conducted in long-form text generation, specifically in story generation? Query Date: 2024-01-26 Answer Papers: [1] Strategies for Structuring Story Generation [2] MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models Source: ProxyQA: An Alternative Framework for Evaluating Long-Form Text Generation with Large Language Models, ACL 2024 |
🔼 This table presents example queries from the AutoScholarQuery dataset and their corresponding papers. Each row shows a sample scholarly query, the date the query was generated, and a list of papers identified as relevant to the query. The purpose is to illustrate the complexity and nuance of academic research queries and the level of detail captured in the dataset.
read the caption
Table 1: Examples of queries and corresponding papers in AutoScholarQuery.
In-depth insights#
LLM-Agent Design#
Designing an effective LLM-agent for academic paper search involves careful consideration of several key aspects. Modular Design is crucial, separating functionalities like query generation, search execution, paper selection, and citation analysis into distinct modules. This allows for easier development, testing, and potential future expansion. Agent Interaction needs to be clearly defined. How do the different modules communicate and exchange information? A robust state management system is vital to track the agent’s progress and maintain context across multiple steps. The agent should efficiently store and retrieve information on processed papers, search results, and discovered citations. Reinforcement learning is likely essential for optimization, allowing the agent to learn effective strategies through trial and error based on a well-defined reward function. Data efficiency must be prioritized; the agent should ideally learn effectively with limited data, reducing the need for massive training datasets. Finally, evaluation metrics beyond simple recall and precision must be developed to comprehensively assess the agent’s performance in handling complex research queries and navigating nuanced citation networks.
RL Training#
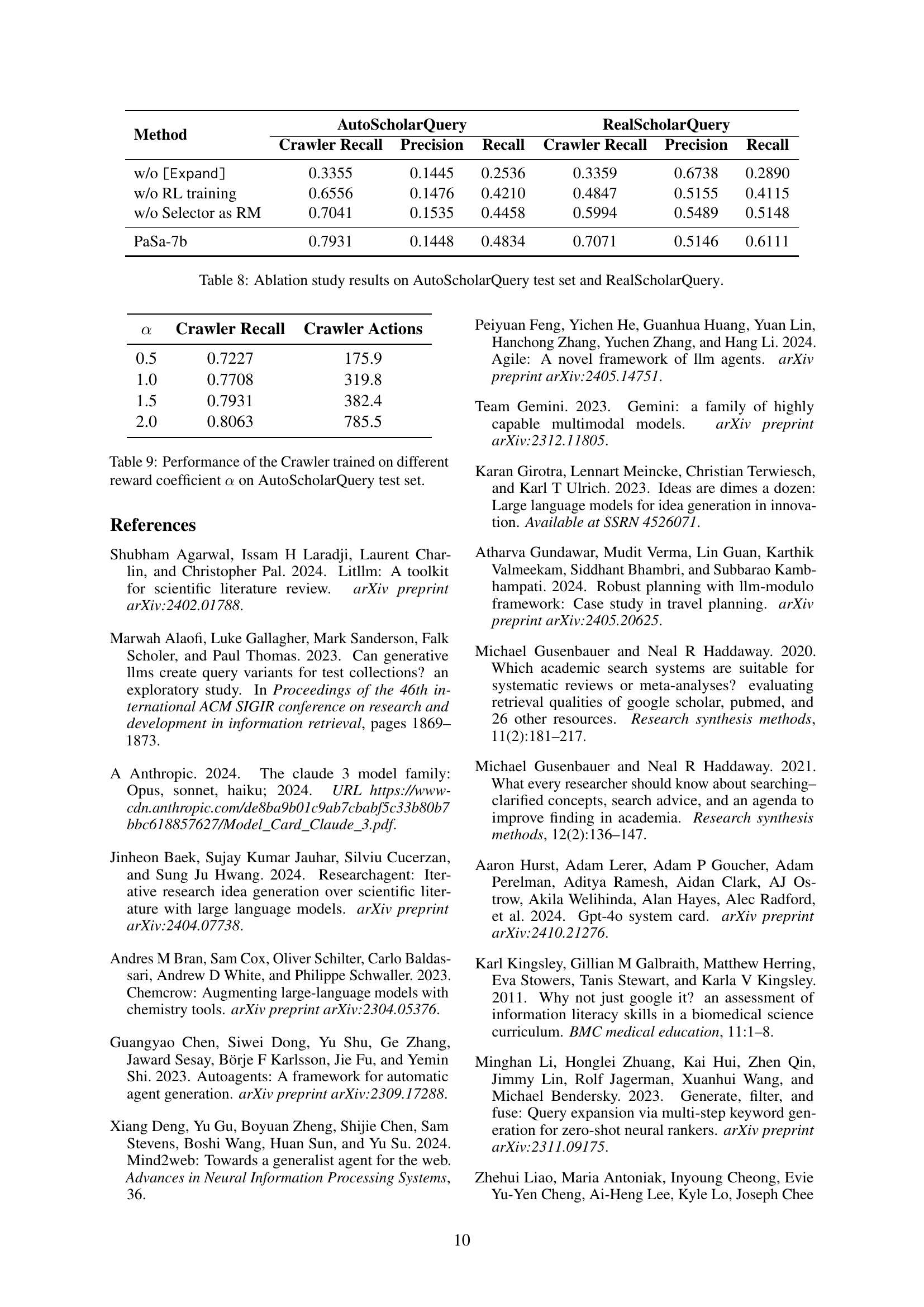
The section on “RL Training” would detail the reinforcement learning process used to optimize the PaSa agent. This would involve describing the chosen RL algorithm (likely Proximal Policy Optimization or a variant), the reward function design which is crucial for guiding the agent’s learning towards desired behavior, the specifics of the training environment (likely involving synthetic and real-world academic query datasets), and any challenges encountered during training. Key aspects to look for include how the sparse reward problem was addressed, given the inherent difficulty in automatically evaluating the relevance of papers to complex queries, and how the long trajectories characteristic of academic research were handled. The description should also cover the training setup, including computational resources and the implementation details such as the use of session-level training and imitation learning to enhance learning efficiency and stability. The evaluation metrics used to monitor the training process, such as recall, precision, and potentially custom metrics tailored to the specific task of academic paper search would also be critical to understanding the effectiveness of the RL approach. Finally, the authors would ideally discuss the convergence of the training process and the final performance achieved by the trained agent on benchmark datasets.
Benchmark Datasets#
Benchmark datasets are crucial for evaluating the performance of any academic paper search agent. A well-constructed benchmark should reflect real-world search scenarios, including diverse query types and complexities, and incorporate a range of relevant and irrelevant papers. Synthetic datasets can offer controlled environments for initial model training and validation, but real-world datasets are essential for assessing generalizability and robustness. The ideal benchmark balances the benefits of controlled, high-quality synthetic data with the realistic challenges of real-world queries. Ideally, a dataset includes a clear methodology for data collection, annotation, and evaluation metrics. Careful consideration of dataset bias and limitations is necessary for fair comparison and to avoid misleading conclusions. Furthermore, the process of creating a comprehensive benchmark is iterative, and datasets should be updated regularly to reflect the evolution of research and the dynamics of information retrieval.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In a research paper, this section would detail experiments where aspects of the proposed method (e.g., specific modules, training techniques, or data augmentation strategies) are selectively omitted. The results, often presented as performance metrics, reveal the impact of each removed component. A well-executed ablation study demonstrates the importance of each element, justifying design choices and supporting the overall claims of the paper. It is crucial to carefully select which elements to ablate to address the central research questions. The interpretation of results requires a nuanced understanding, acknowledging potential interactions between components and the limitations of the experimental setup. Inconsistencies or unexpected results may highlight areas for future investigation and refinement. The value of an ablation study lies in its ability to dissect a complex system, isolating the effects of individual parts and providing deeper insights into the model’s inner workings. It offers more than just validation – it reveals the why behind the model’s effectiveness. The clarity and thoroughness of the ablation study contribute significantly to the paper’s scientific credibility and its broader impact.
Future Research#
Future research directions stemming from this paper could fruitfully explore several avenues. Firstly, a deeper investigation into the limitations of current LLM architectures for complex academic search is warranted. This would include analyzing the impact of different LLM sizes and architectural designs on the accuracy and efficiency of the search process, potentially identifying bottlenecks or areas for optimization. Secondly, the development of more sophisticated evaluation metrics beyond recall and precision is crucial to fully assess the performance of these systems. Existing benchmarks may not capture the nuances of complex, nuanced academic queries and retrieval. Thirdly, expanding the scope of the datasets used to train and evaluate these models, incorporating additional domains and query types, would enhance the robustness and generalizability of the system. Finally, integrating user feedback mechanisms could lead to models capable of adapting dynamically to individual user needs and search styles, creating truly personalized and intuitive academic research tools. The current work provides a strong foundation, and these research directions will contribute to improved search capabilities.
More visual insights#
More on figures

🔼 The figure illustrates the PaSa system’s workflow, focusing on the Crawler agent’s actions. The Crawler uses multiple search queries (diverse and complementary) to retrieve papers. It also assesses the long-term impact of its actions and explores citation networks deeply to find relevant papers, even if some intermediate papers aren’t directly related to the user’s query.
read the caption
Figure 2: An example of the PaSa workflow. The Crawler runs multiple [Search] using diverse and complementary queries. In addition, the Crawler can evaluate the long-term value of its actions. Notably, it discovers many relevant papers as it explores deeper on the citation network, even when intermediate papers along the path do not align with the user query.

🔼 This figure displays the return and value function loss curves throughout the Proximal Policy Optimization (PPO) training process. The curves are smoothed using an exponential moving average (EMA) method, with a smoothing weight of 0.95, consistent with the smoothing technique used in TensorBoard. The x-axis represents training steps, while the y-axis shows the return and value function loss.
read the caption
Figure 3: Return and value function loss curves during the PPO training process. The smoothing method of the curve in the figures is the exponential moving average(EMA) formula that aligns with the one used in TensorBoard, and the smoothing weight is set to 0.95.
More on tables
| Conference | - | - | |||
|---|---|---|---|---|---|
| ICLR 2023 | 888 | 5204 | 2.46 | 2.0 | 5.0 |
| ICML 2023 | 981 | 5743 | 2.37 | 2.0 | 5.0 |
| NeurIPS 2023 | 1948 | 11761 | 2.59 | 2.0 | 5.0 |
| CVPR 2024 | 1336 | 9528 | 2.94 | 2.0 | 6.0 |
| ACL 2024 | 485 | 3315 | 2.16 | 2.0 | 4.0 |
🔼 This table presents statistics for the AutoScholarQuery dataset, which is a collection of academic search queries and their corresponding papers. The columns detail the total number of papers (|P|) and queries (|Q|) from each of the five AI conferences used to create the dataset (ICLR 2023, ICML 2023, NeurIPS 2023, ACL 2024, and CVPR 2024). Additionally, it shows the average number of relevant papers per query (Ans(/Q)), and the 50th and 90th percentiles of the number of answers per query (Ans-50 and Ans-90) providing insight into the distribution of answer counts.
read the caption
Table 2: Statistics of AutoScholarQuery. |P|𝑃|P|| italic_P | and |Q|𝑄|Q|| italic_Q | represent the total number of papers and queries collected for each conference. Ans(/Q)Ans(/Q)italic_A italic_n italic_s ( / italic_Q ) denotes the average number of answer papers per query. Ans𝐴𝑛𝑠Ansitalic_A italic_n italic_s-50505050 and Ans𝐴𝑛𝑠Ansitalic_A italic_n italic_s-90909090 refers to the 50th and 90th percentiles of answer paper counts per query.
| Name | Implementation |
|---|---|
| Generate a search query and invoke | |
| [Search] | the search tool. Append all resulting |
| papers to the paper queue. | |
| Generate a subsection name, then | |
| [Expand] | add all referenced papers in the sub- |
| section to the paper queue. | |
| [Stop] | Reset the context to the user query and |
| the next paper in the paper queue. |
🔼 This table details the three primary functions of the Crawler, a key component of the PaSa system. The Crawler is an LLM agent responsible for autonomously searching for and collecting relevant papers. Each function involves different actions and interactions with the system, such as searching using online tools, expanding the search based on citations, or stopping the search process when enough information has been gathered. The descriptions provide a high-level understanding of how the Crawler uses these functions to manage the search process.
read the caption
Table 3: Functions of the Crawler.
| Name | Value | |
| (Equation 1) | 1.5 | |
| (Equation 1) | 0.1 | |
| (Equation 1) | 0.1 | |
| (Equation 1) | 0.0 | |
| (Equation 4.2) | 1.0 | |
| (Equation 4.2) | 0.1 | |
| (Equation 4.2) | 0.1 | |
| (Equation 5, Equation 4.2) | 0.2 | |
| (Equation 8) | 10 | |
| learning rate | 1e-6 | |
| epoch per step | 2 | |
| forward batch size | 1 | |
| accumulate batch size | 16 | |
| NVIDIA H100 GPU | 16 | |
| policy freezing step | 50 | |
| total step | 250 | |
🔼 This table lists the hyperparameters used during the Proximal Policy Optimization (PPO) training phase of the Crawler, one of the two main components of the PaSa system. The hyperparameters control aspects of the training process, such as reward scaling, action costs, discount factors, learning rates, batch sizes, and the number of training steps. Understanding these settings is crucial to interpreting the performance of the PaSa model and its training process.
read the caption
Table 4: The hyperparameters used in PPO training.
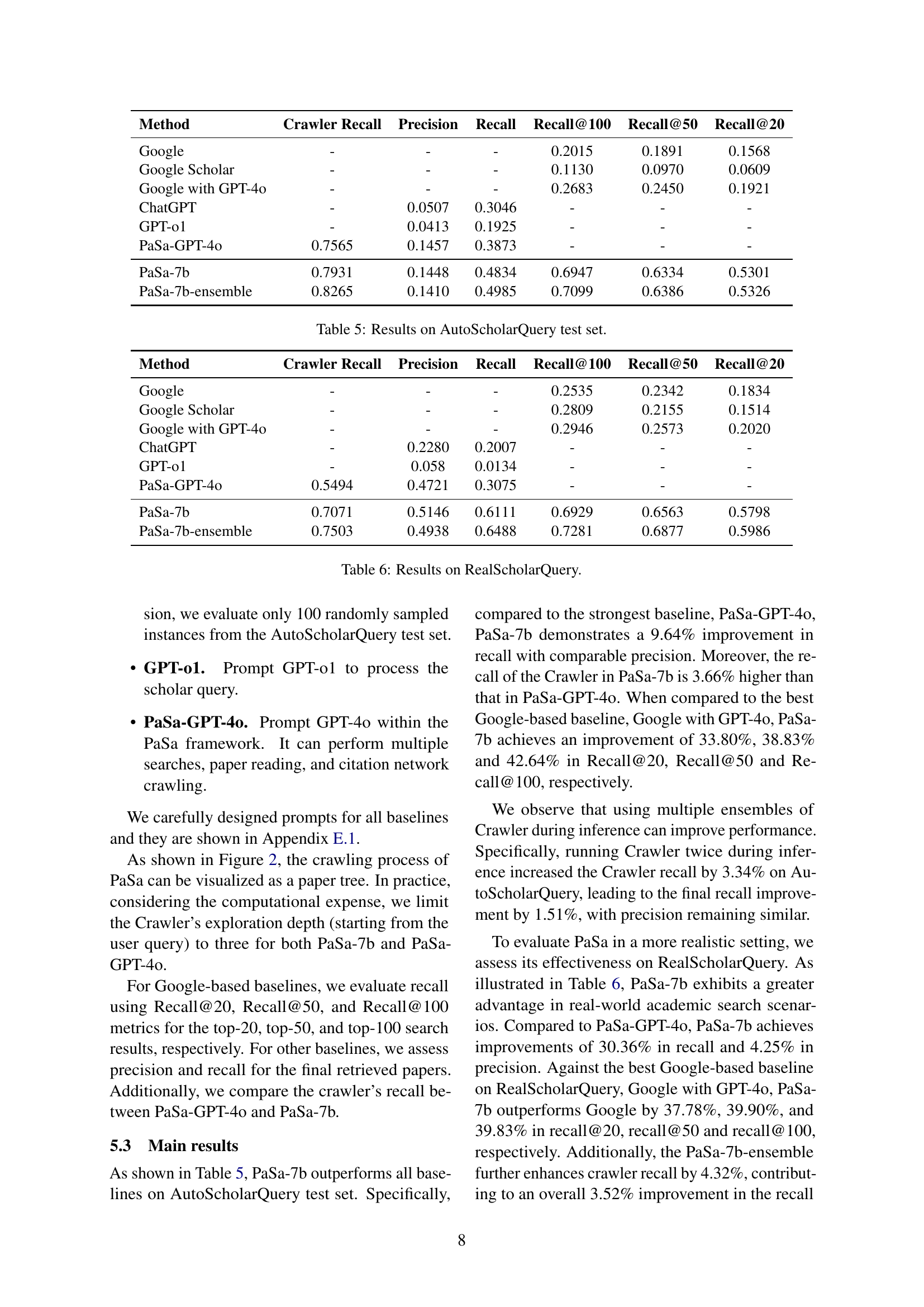
| Method | Crawler Recall | Precision | Recall | Recall@100 | Recall@50 | Recall@20 |
|---|---|---|---|---|---|---|
| - | - | - | 0.2015 | 0.1891 | 0.1568 | |
| Google Scholar | - | - | - | 0.1130 | 0.0970 | 0.0609 |
| Google with GPT-4o | - | - | - | 0.2683 | 0.2450 | 0.1921 |
| ChatGPT | - | 0.0507 | 0.3046 | - | - | - |
| GPT-o1 | - | 0.0413 | 0.1925 | - | - | - |
| PaSa-GPT-4o | 0.7565 | 0.1457 | 0.3873 | - | - | - |
| PaSa-7b | 0.7931 | 0.1448 | 0.4834 | 0.6947 | 0.6334 | 0.5301 |
| PaSa-7b-ensemble | 0.8265 | 0.1410 | 0.4985 | 0.7099 | 0.6386 | 0.5326 |
🔼 This table presents the performance of various methods on the AutoScholarQuery test set, a benchmark dataset for academic paper search. It compares the recall and precision of different approaches, including Google, Google Scholar, Google with GPT-40, ChatGPT, GPT-01, PaSa-GPT-40, and PaSa-7B. The metrics are evaluated at different recall thresholds (@20, @50, @100), providing a comprehensive assessment of each method’s ability to retrieve relevant papers.
read the caption
Table 5: Results on AutoScholarQuery test set.
| Method | Crawler Recall | Precision | Recall | Recall@100 | Recall@50 | Recall@20 |
|---|---|---|---|---|---|---|
| - | - | - | 0.2535 | 0.2342 | 0.1834 | |
| Google Scholar | - | - | - | 0.2809 | 0.2155 | 0.1514 |
| Google with GPT-4o | - | - | - | 0.2946 | 0.2573 | 0.2020 |
| ChatGPT | - | 0.2280 | 0.2007 | - | - | - |
| GPT-o1 | - | 0.058 | 0.0134 | - | - | - |
| PaSa-GPT-4o | 0.5494 | 0.4721 | 0.3075 | - | - | - |
| PaSa-7b | 0.7071 | 0.5146 | 0.6111 | 0.6929 | 0.6563 | 0.5798 |
| PaSa-7b-ensemble | 0.7503 | 0.4938 | 0.6488 | 0.7281 | 0.6877 | 0.5986 |
🔼 This table presents the results of the PaSa-7B model and several baseline models on the RealScholarQuery dataset. RealScholarQuery consists of 50 real-world academic search queries with annotated relevant papers, designed to evaluate the performance in realistic scenarios. The table shows the recall, precision, and recall@k (where k=20, 50, 100) for each model. It demonstrates how PaSa-7B compares against baselines such as Google search, Google Scholar, Google search paired with GPT-40 for paraphrased queries, ChatGPT, GPT-01, and PaSa implemented with GPT-40. The performance metrics offer a comprehensive comparison of PaSa-7B’s effectiveness compared to existing search methods for complex academic research queries.
read the caption
Table 6: Results on RealScholarQuery.
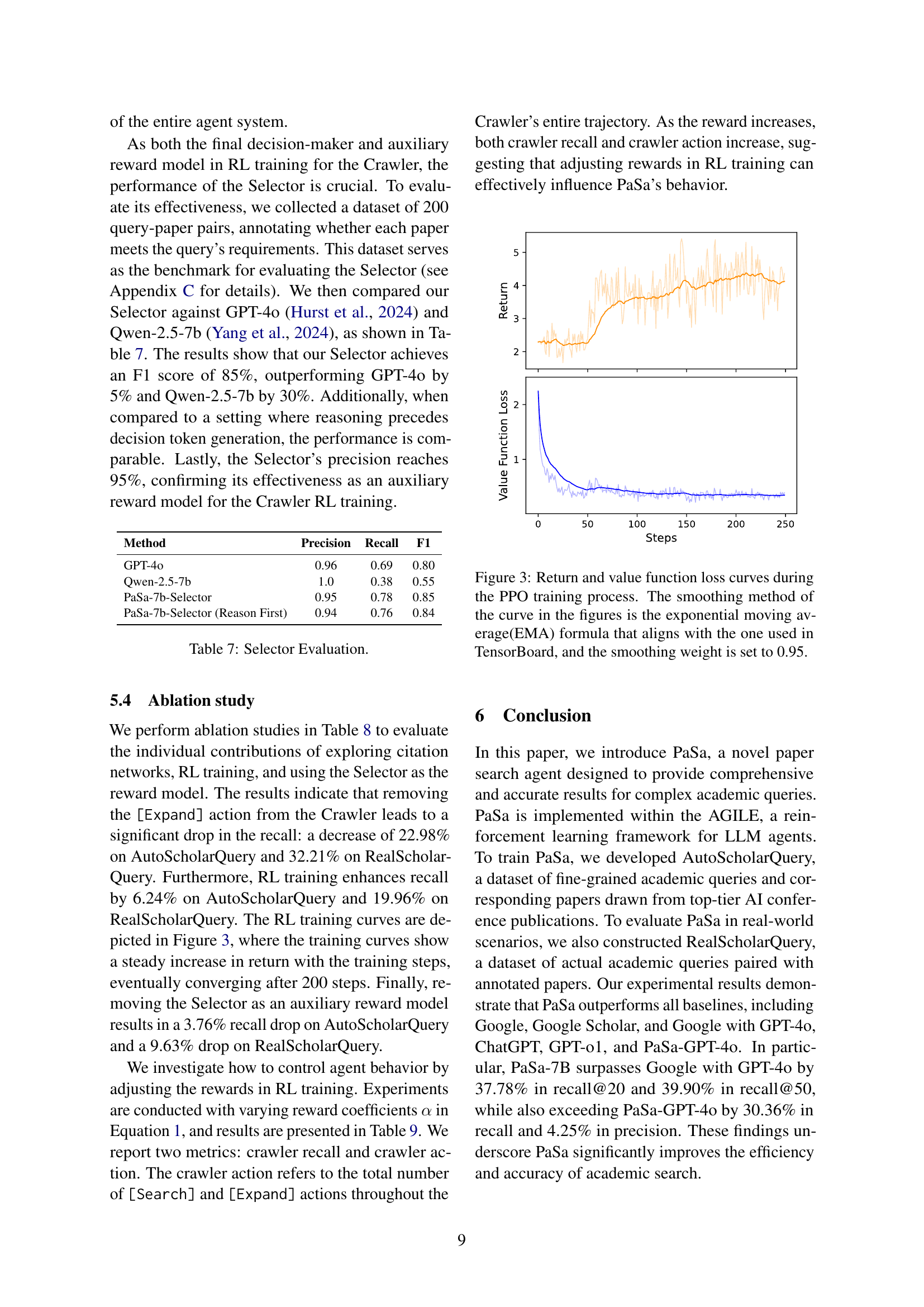
| Method | Precision | Recall | F1 |
|---|---|---|---|
| GPT-4o | 0.96 | 0.69 | 0.80 |
| Qwen-2.5-7b | 1.0 | 0.38 | 0.55 |
| PaSa-7b-Selector | 0.95 | 0.78 | 0.85 |
| PaSa-7b-Selector (Reason First) | 0.94 | 0.76 | 0.84 |
🔼 This table presents the results of evaluating the performance of the Selector model, a crucial component of the PaSa system. The evaluation compares the F1 score, precision, and recall of the PaSa-7b Selector against two baseline models: GPT-40 and Qwen-2.5-7b. It also shows a comparison with a variant of the PaSa-7b Selector where the reasoning is generated before the decision.
read the caption
Table 7: Selector Evaluation.
| Method | AutoScholarQuery | RealScholarQuery | ||||
|---|---|---|---|---|---|---|
| Crawler Recall | Precision | Recall | Crawler Recall | Precision | Recall | |
| w/o [Expand] | 0.3355 | 0.1445 | 0.2536 | 0.3359 | 0.6738 | 0.2890 |
| w/o RL training | 0.6556 | 0.1476 | 0.4210 | 0.4847 | 0.5155 | 0.4115 |
| w/o Selector as RM | 0.7041 | 0.1535 | 0.4458 | 0.5994 | 0.5489 | 0.5148 |
| PaSa-7b | 0.7931 | 0.1448 | 0.4834 | 0.7071 | 0.5146 | 0.6111 |
🔼 This table presents the results of an ablation study conducted to analyze the impact of different components of the PaSa model on its performance. It shows the recall, precision, and other metrics achieved by PaSa on both the AutoScholarQuery test set (a synthetic dataset) and the RealScholarQuery dataset (a real-world dataset). The ablation study involves removing key elements such as the Crawler’s ability to explore citations ([Expand] action), the reinforcement learning (RL) training process, and the Selector (used as an auxiliary reward model). By comparing the performance of these variations against the full PaSa model, the study investigates the importance of each component to the overall search effectiveness.
read the caption
Table 8: Ablation study results on AutoScholarQuery test set and RealScholarQuery.
| Crawler Recall | Crawler Actions | |
|---|---|---|
| 0.5 | 0.7227 | 175.9 |
| 1.0 | 0.7708 | 319.8 |
| 1.5 | 0.7931 | 382.4 |
| 2.0 | 0.8063 | 785.5 |
🔼 This table presents the performance of the Crawler model, a key component of the PaSa system, trained with different reward coefficients (alpha). It shows how varying the alpha value impacts the Crawler’s recall (the proportion of relevant papers retrieved) and the number of actions it takes during the search process. This helps to analyze the impact of reward shaping on the Crawler’s efficiency and effectiveness in retrieving relevant documents within the AutoScholarQuery test dataset.
read the caption
Table 9: Performance of the Crawler trained on different reward coefficient α𝛼\alphaitalic_α on AutoScholarQuery test set.
| The prompt for search query generation. |
| You are an elite researcher in the field of AI, please generate some mutually exclusive queries in a list to search the relevant papers according to the User Query. Searching for a survey paper would be better. User Query: {user_query} The semantics between generated queries are not mutually inclusive. The format of the list is: [“query1”, “query2”, …] Queries: |
🔼 This table displays the prompt used to instruct GPT-40 to generate a series of search queries based on a given user query. The goal is to obtain a list of relevant search queries for use in an academic paper search.
read the caption
Table 10: The prompt for GPT-4o to generate search queries from the user query.
| Search Session starting from | Expand Session starting from | |
|---|---|---|
| prompt | Please, generate some mutually exclusive queries in a list to search the relevant papers according to the User Query. Searching for survey papers would be better. User Query: {user_query} | You are conducting research on '{user_query}'. You need to predict which sections to look at to get more relevant papers. Title: {title} Abstract: {abstract} Sections: {sections} |
| response | [Search] {query 1} [Search] {query 2} … [Stop] | [Expand] {section 1} [Expand] {section 2} … [Stop] |
🔼 This table presents the templates used by the Crawler agent in the PaSa system. It shows how the Crawler generates its trajectories, which involve sequences of actions such as searching using online tools, expanding on citations, and stopping to examine a paper to determine whether it is relevant to the user’s query. The templates guide the Crawler’s decision-making process during training and inference, which involves exploring a graph of papers via search and expansion steps and stopping.
read the caption
Table 11: The session trajectory templates of the Crawler.
| Query: Give me papers about how to rank search results by the use of LLM Query Date: 2024-10-01 Answer Papers: [0] Instruction Distillation Makes Large Language Models Efficient Zero-shot Rankers [1] Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels [2] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting [3] A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models [4] RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models [5] PaRaDe: Passage Ranking using Demonstrations with Large Language Models [6] Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents [7] Large Language Models are Zero-Shot Rankers for Recommender Systems [8] TourRank: Utilizing Large Language Models for Documents Ranking with a Tournament-Inspired Strategy [9] ExaRanker: Explanation-Augmented Neural Ranker [10] RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs [11] Make Large Language Model a Better Ranker [12] LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking [13] Improving Zero-shot LLM Re-Ranker with Risk Minimization [14] Zero-Shot Listwise Document Reranking with a Large Language Model [15] Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing [16] Re-Ranking Step by Step: Investigating Pre-Filtering for Re-Ranking with Large Language Models [17] Large Language Models for Relevance Judgment in Product Search [18] PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval [19] Passage-specific Prompt Tuning for Passage Reranking in Question Answering with Large Language Models [20] When Search Engine Services meet Large Language Models: Visions and Challenges [21] RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze! [22] Rank-without-GPT: Building GPT-Independent Listwise Rerankers on Open-Source Large Language Models [23] MuGI: Enhancing Information Retrieval through Multi-Text Generation Integration with Large Language Models [24] Discrete Prompt Optimization via Constrained Generation for Zero-shot Re-ranker [25] REAR: A Relevance-Aware Retrieval-Augmented Framework for Open-Domain Question Answering [26] Agent4Ranking: Semantic Robust Ranking via Personalized Query Rewriting Using Multi-agent LLM [27] FIRST: Faster Improved Listwise Reranking with Single Token Decoding [28] Leveraging LLMs for Unsupervised Dense Retriever Ranking [29] Unsupervised Contrast-Consistent Ranking with Language Models [30] Enhancing Legal Document Retrieval: A Multi-Phase Approach with Large Language Models [31] Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models [32] Fine-Tuning LLaMA for Multi-Stage Text Retrieval [33] Zero-shot Audio Topic Reranking using Large Language Models [34] Uncovering ChatGPT’s Capabilities in Recommender Systems [35] Cognitive Personalized Search Integrating Large Language Models with an Efficient Memory Mechanism [36] Towards More Relevant Product Search Ranking Via Large Language Models: An Empirical Study [37] Pretrained Language Model based Web Search Ranking: From Relevance to Satisfaction [38] Open-source large language models are strong zero-shot query likelihood models for document ranking |
🔼 This table presents sample queries from the RealScholarQuery dataset, a benchmark of real-world academic search queries, and their corresponding relevant papers. It highlights the complexity and diversity of actual research questions and the associated publications needed to answer them effectively, illustrating the challenges addressed by the PaSa system.
read the caption
Table 12: Examples of queries and corresponding papers in RealScholarQuery.
| The prompt for search query paraphrase. |
| Generate a search query suitable for Google based on the given academic paper-related query. Here’s the structure and requirements for generating the search query: Understand the Query: Read and understand the given specific academic query. Identify Key Elements: Extract the main research field and the specific approaches or topics mentioned in the query. Formulate the Search Query: Combine these elements into a concise query that includes terms indicating academic sources. Do not add any site limitations to your query. [User’s Query]: {user_query} [Generated Search Query]: |
🔼 This table displays the prompt template used to instruct GPT-40 to paraphrase a user’s academic search query into a format suitable for Google search. The prompt guides GPT-40 to understand the user’s query, identify key elements (research field and approaches), and formulate a concise, academically-focused query for improved search results. The output should be a single search query string.
read the caption
Table 13: The prompt for search query paraphrase.
| The prompt for ChatGPT (search-enabled GPT-4o). |
| [User’s Query] You should return the Arxiv papers. You should provide more than 10 papers you searched in JSON format: {"paper_1": {"title": , ’authors’: , ’link’: }, "paper_2": {"title": , ’authors’: , ’link’: }} |
🔼 This table presents the prompt used to instruct ChatGPT (a search-enabled version of GPT-4) to conduct a scholarly search and return results in a specific JSON format. The prompt specifies that the response should include relevant Arxiv papers and should return more than 10 papers in a structured JSON format, containing the title, authors, and link for each paper.
read the caption
Table 14: The prompt for Chatgpt (search-enabled GPT-4o).
| The prompt for paper selection. |
| You are an elite researcher in the field of AI, conducting research on {user_query}. Evaluate whether the following paper fully satisfies the detailed requirements of the user query and provide your reasoning. Ensure that your decision and reasoning are consistent. Searched Paper: Title: {title} Abstract: {abstract} User Query: {user_query} Output format: Decision: True/False Reason:… Decision: |
🔼 This table describes the prompt used to evaluate whether a given research paper satisfies a user’s query. The prompt provides the paper’s title and abstract, the user query, and requests a boolean decision (True/False) along with a rationale explaining the decision.
read the caption
Table 15: The prompt used with pasa selector or GPT-4o to judge the selection of the paper.
| The prompt for AutoScholarQuery generation. |
| You are provided a ‘Related Work’ section of a research paper. The researcher reviewed the relevant work, conducted a literature survey, and cited corresponding references in this text (enclosed by ‘\cite’ tags with IDs). Can you guess what research questions the researcher might have posed when preparing this text? The answers to these questions should be the references cited in this passage. Please list questions and provide the corresponding answers. [Requirements:] 1. Craft questions similar to those a researcher would pose when reviewing related works, such as “Which paper studied …?”, “Any works about…?”, “Could you provide me some works…?” 2. Construct the question-answer pairs based on [Section from A Research Paper]. The answer should be the cited papers in [Section from A Research Paper]. 3. Do not ask questions including "or" or "and" that may involve more than one condition. 4. Clarity: Formulate questions clearly and unambiguously to prevent confusion. 5. Contextual Definitions: Include explanations or definitions for specialized terms and concepts used in the questions. 6. Format the output as a JSON array containing five objects corresponding to the three question-answer pairs. Here are some examples: [Begin of examples] {Section from A Research Paper-1} {OUTPUT-1} {Section from A Research Paper-2} {OUTPUT-2} {Section from A Research Paper-3} {OUTPUT-3} [End of examples] {Section from A Research Paper} [OUTPUT]: |
🔼 This table details the prompt used to instruct GPT-40 in automatically generating the AutoScholarQuery dataset. The prompt guides GPT-40 to extract relevant research questions and their corresponding answers from the ‘Related Work’ sections of research papers. It emphasizes the importance of clear, unambiguous questions with contextual definitions for specialized terms. The output is formatted as a JSON array, with each object representing a question-answer pair.
read the caption
Table 16: The prompt used with GPT-4o to automatically generate AutoScholarQuery.
Full paper#