TL;DR#
Current methods for generating game videos struggle with scene generalization, limiting their application to existing games with fixed styles and scenes. Existing video-based game generation methods often fail to address the critical challenge of scene generalization, hindering their applicability. This research introduces GameFactory, a novel framework that leverages pre-trained video diffusion models and a multi-phase training strategy to overcome this limitation.
GameFactory addresses the scene generalization challenge by decoupling game style learning from action control. This allows the model to learn action control from a small-scale game dataset and transfer this ability to open-domain videos, enabling the creation of new games in diverse and dynamic environments. It also introduces GF-Minecraft, a high-quality action-annotated video dataset and extends its framework to enable autoregressive action-controllable game video generation, resulting in unlimited-length interactive game videos. The proposed approach demonstrates the effectiveness of the framework in producing diverse and controllable game videos, pushing the boundaries of AI-driven game generation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework, GameFactory, for creating new games using generative interactive videos. This addresses the crucial challenge of scene generalization in game video generation, a significant limitation of existing methods. The research also introduces a new dataset and techniques for controllable and autoregressive video generation, paving the way for more realistic and engaging AI-driven games. Its open-domain generalizability extends beyond gaming to other fields like robotics and autonomous driving.
Visual Insights#

🔼 GameFactory is a framework that uses pre-trained video models to generate new games. It learns action controls from a small Minecraft dataset and applies them to open-domain videos. This allows for the creation of games in various, realistic settings. The figure shows four examples of this, demonstrating action control (indicated by yellow buttons for key presses and arrows for mouse movements) in diverse generated scenes.
read the caption
Figure 1: We propose GameFactory, a framework that leverages the powerful generative capabilities of pre-trained video models for the creation of new games. By learning action control from a small-scale first-person Minecraft dataset, this framework can transfer these control abilities to open-domain videos, ultimately allowing the creation of new games within open-domain scenes. As illustrated in (1)-(4), GameFactory supports action control across diverse, newly generated scenes in open domains, paving the way for the development of entirely new game experiences. The yellow buttons indicate pressed keys, and the arrows represent the direction of mouse movements.
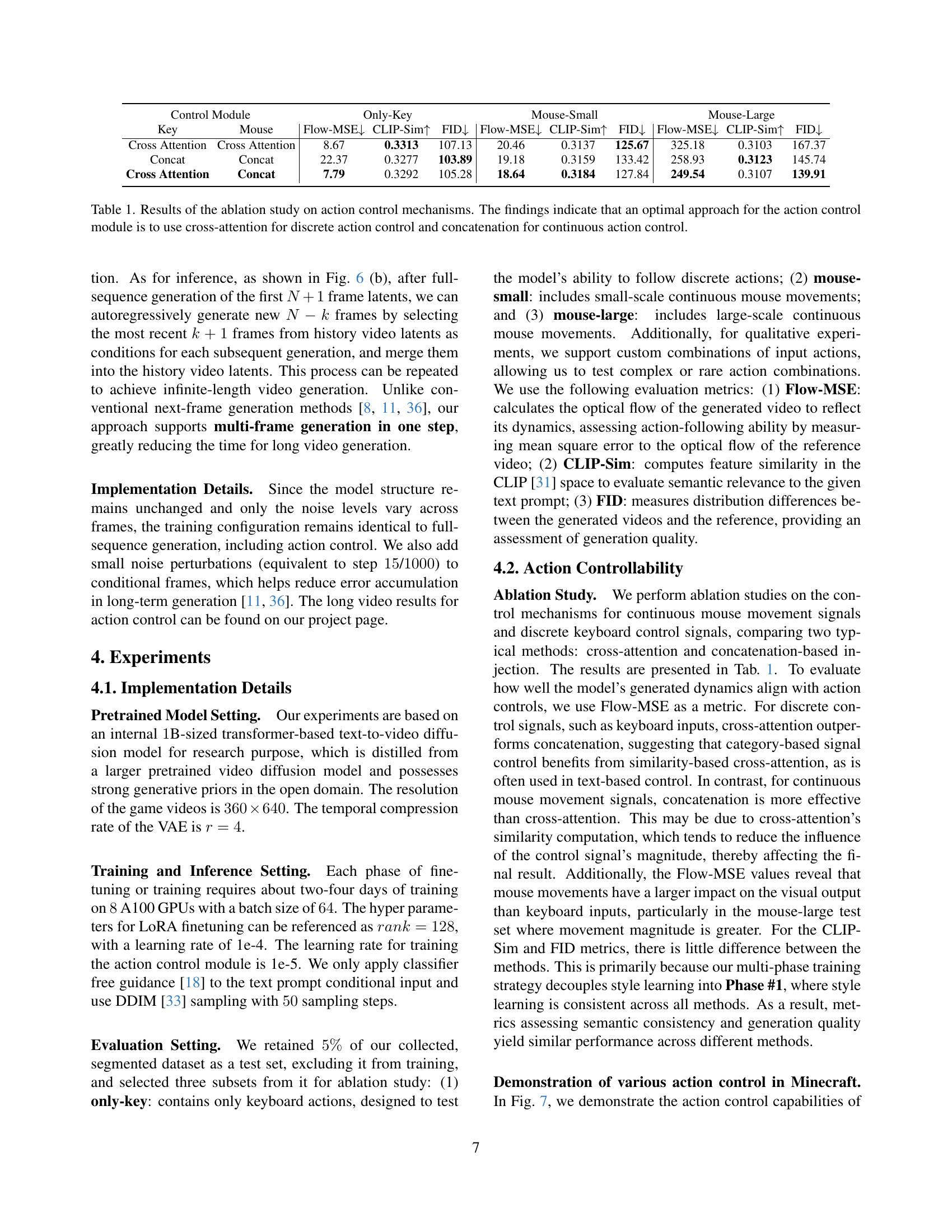
| Control Module | Only-Key | Mouse-Small | Mouse-Large | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Key | Mouse | Flow-MSE | CLIP-Sim | FID | Flow-MSE | CLIP-Sim | FID | Flow-MSE | CLIP-Sim | FID |
| Cross Attention | Cross Attention | 8.67 | 0.3313 | 107.13 | 20.46 | 0.3137 | 125.67 | 325.18 | 0.3103 | 167.37 |
| Concat | Concat | 22.37 | 0.3277 | 103.89 | 19.18 | 0.3159 | 133.42 | 258.93 | 0.3123 | 145.74 |
| Cross Attention | Concat | 7.79 | 0.3292 | 105.28 | 18.64 | 0.3184 | 127.84 | 249.54 | 0.3107 | 139.91 |
🔼 This table presents the results of an ablation study comparing different action control mechanisms within a video generation model for game creation. The study investigates the effectiveness of two primary methods for integrating action information: cross-attention and concatenation. Results are shown using three metrics: Flow-MSE (measures the quality of the generated videos’ movement compared to a reference video); CLIP-Sim (measures the semantic similarity between the generated video and a text description); and FID (Fréchet Inception Distance, a metric for assessing the quality of generated images). The table helps determine which method (cross-attention or concatenation) is better suited for different types of game actions: discrete actions (like key presses) versus continuous actions (like mouse movements). The findings show that cross-attention is superior for discrete actions, while concatenation performs better for continuous actions. This informs the optimal design of the action control module.
read the caption
Table 1: Results of the ablation study on action control mechanisms. The findings indicate that an optimal approach for the action control module is to use cross-attention for discrete action control and concatenation for continuous action control.
In-depth insights#
Generative Game AI#
Generative Game AI represents a significant advancement in game development, automating content creation and potentially revolutionizing the industry. Game engines are evolving from manually crafted experiences to AI-driven systems capable of generating diverse game worlds and assets. This shift promises reduced development costs and timelines. However, challenges remain, notably in scene generalization, where current models often struggle to create new game environments beyond those seen during training. The paper’s GameFactory addresses this by leveraging pre-trained video diffusion models, enhancing generalization capabilities. A key contribution is the introduction of a novel training strategy that decouples game style from action control. This is critical for preventing the model from overfitting to a specific style while still retaining controllability. Further research should focus on refining scene generalization, potentially by exploring larger and more diverse training datasets and improved methods of action control. The long-term implications of Generative Game AI are vast, envisioning a future where games are continuously generated and personalized to player preferences, leading to richer and more dynamic gaming experiences.
Action Control#
The concept of ‘Action Control’ within the context of AI-driven game generation is crucial, focusing on how user inputs translate into game events. The paper highlights the challenge of achieving robust action control while maintaining scene generalization. A key innovation is the multi-phase training strategy, decoupling style learning from action control. This approach leverages pre-trained models for scene generation and fine-tunes a dedicated action control module on a smaller, action-annotated dataset, like GF-Minecraft. This two-stage process prevents the model from overfitting to a specific game style, thus enabling control across diverse and open-domain environments. Furthermore, the paper explores different control mechanisms—cross-attention for discrete actions (keyboard) and concatenation for continuous actions (mouse)—to effectively handle varied input modalities. The resulting framework allows for the generation of open-domain, action-controllable game videos, showing significant potential for revolutionizing game development by automating content creation and reducing manual workload.
Scene Generalization#
Scene generalization in game video generation is a crucial challenge addressed by GameFactory. Existing methods often fail to generalize beyond specific games due to overfitting on limited datasets. GameFactory tackles this by leveraging pre-trained video generation models, which have learned rich scene representations from vast amounts of open-domain data. This approach allows for the generation of diverse and novel game scenes without extensive manual annotation. A multi-phase training strategy is key, separating style learning from action control. Initially, the model learns game-specific style using LoRA (Low-Rank Adaptation), and subsequently the action control module is trained while keeping the style parameters frozen. This effectively decouples style from action, allowing the generated scenes to retain open-domain flexibility while exhibiting precise action control. Furthermore, autoregressive generation extends the framework to produce arbitrarily long, continuous game videos, overcoming the limitation of fixed-length outputs found in existing models. The resulting system provides scene generalization beyond any single game, enabling diverse and realistic game creation, opening vast possibilities for AI-driven game development.
Multi-Phase Training#
The multi-phase training strategy is a core innovation in the GameFactory framework, designed to address the challenge of scene generalization in game video generation. Decoupling style learning from action control is key; the initial phase fine-tunes a pre-trained model using a small, action-annotated dataset (GF-Minecraft) via Low-Rank Adaptation (LoRA) to acquire game-specific stylistic features without affecting its open-domain capabilities. Subsequently, with stylistic aspects frozen, a separate action control module is trained, focusing solely on learning action control. This decoupling prevents the model from overly specializing to the Minecraft style, promoting better generalization to novel, open-domain scenarios. The final phase utilizes the trained action control module independently, leveraging the pre-trained model’s open-domain priors, thus achieving both action controllability and scene generalization. This approach elegantly separates stylistic and functional aspects of game generation, creating a more versatile and adaptable system for generating diverse, action-controllable game videos across different visual contexts.
Future Directions#
Future research should prioritize enhancing the generalizability of GameFactory. While the current model demonstrates impressive scene generalization capabilities, further investigation into extending its applicability beyond Minecraft and racing game scenarios is crucial. This requires exploring diverse game types and creating more comprehensive datasets that capture a wider range of action inputs and environmental interactions. A key challenge lies in developing robust control methods for increasingly complex and nuanced gameplay situations. Research should also focus on improving the efficiency of the autoregressive video generation, potentially through exploring more efficient architectures or training strategies. Addressing the computational cost associated with generating long, high-quality videos is essential for practical applications. Finally, future work should investigate the integration of more sophisticated game elements such as physics engines, realistic character interactions, and complex storylines to create truly immersive and compelling game experiences. Exploring innovative methods for integrating player feedback and adaptive game difficulty would further enhance the user experience.
More visual insights#
More on figures
🔼 GameFactory uses a pre-trained large video generation model to create new games. The model’s open-domain generative capabilities are shown in the upper blue section. The lower green section illustrates how a smaller action control module, trained on a small game dataset, is added to control the generation process, allowing creation of new games within various scenes. This demonstrates the transfer of action control abilities from a known dataset to open-domain videos, resulting in novel game experiences.
read the caption
Figure 2: A schematic of our GameFactory creating new games based on pre-trained large video generation models. The upper blue section shows the generative capabilities of the pre-trained model in an open-domain, while the lower green section demonstrates how the action control module, learned from a small amount of game data, can be plugged in to create new games.

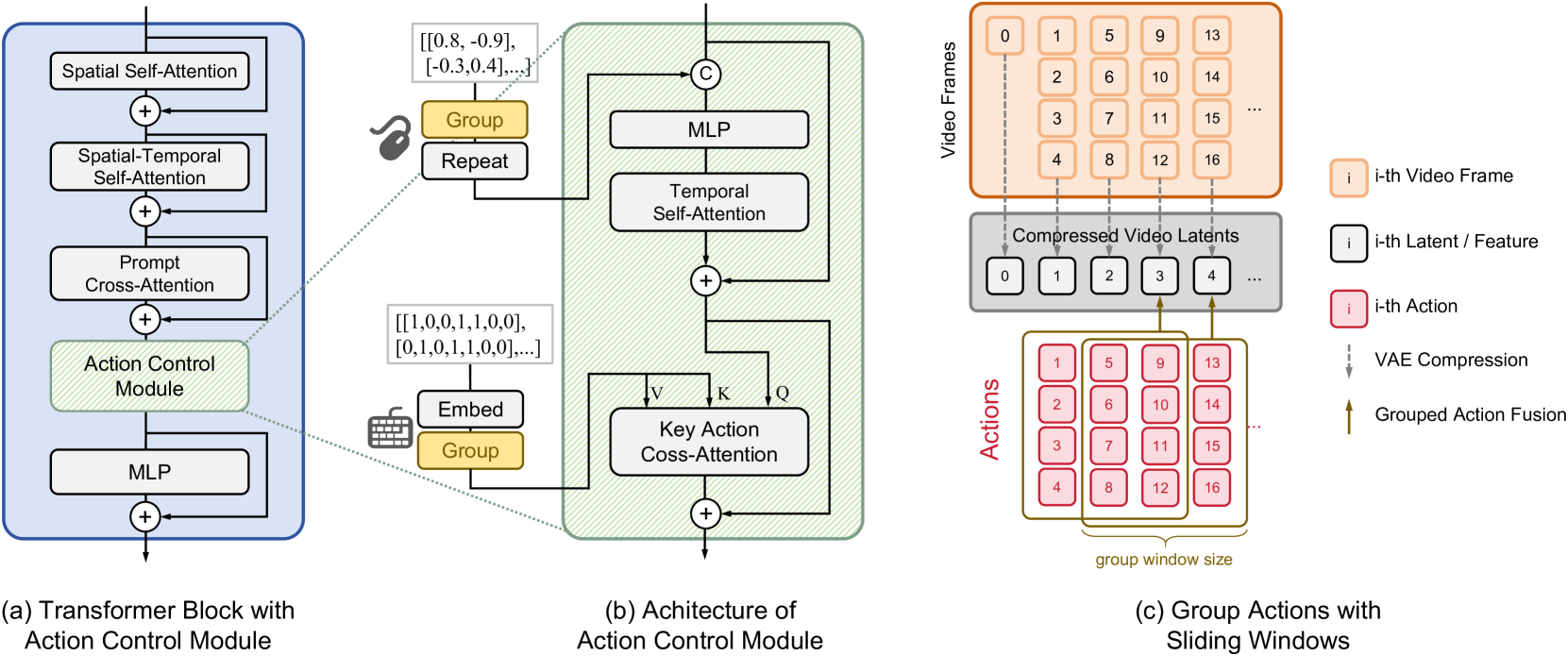
🔼 Figure 3 illustrates how the action control module is integrated into a video diffusion model for generating action-controlled videos. Panel (a) shows the module’s placement within the transformer blocks of the video diffusion model. Panel (b) details the different control mechanisms used for continuous mouse movements and discrete keyboard inputs; a key difference is that continuous signals are concatenated with latent video features while discrete signals use a cross-attention mechanism. Panel (c) addresses a problem caused by temporal compression of the input video. Because the video is compressed, the number of latent features is not equal to the number of actions. A grouping mechanism with a sliding window is used to align the features and actions so they can be correctly fused.
read the caption
Figure 3: (a) Integration of Action Control Module into transformer blocks of the video diffusion model. (b) Different control mechanisms for continuous mouse signals and discrete keyboard signals (detailed analysis in Sec 3.3). (c) Due to temporal compression (compression ratio r=4𝑟4r=4italic_r = 4), the number of latent features differs from the number of actions, causing granularity mismatch during fusion. Grouping aligns these sequences for fusion. Additionally, the i𝑖iitalic_i-th latent feature can fuse with action groups within a previous window (window size w=3𝑤3w=3italic_w = 3), accounting for delayed action effects (e.g., ‘jump’ key affects several subsequent frames).

🔼 The figure shows that fine-tuning a pre-trained video generation model directly on Minecraft data results in the generated videos inheriting the blocky style of Minecraft. This creates a problem because the goal is to generate videos in various styles and not just the Minecraft style. To address this issue, the authors propose a multi-phase training approach that separates learning the game’s style from learning action control. This allows the model to generalize to new scenes and styles while maintaining the ability to respond to user actions.
read the caption
Figure 4: Style bias in video game generation. The model tuned on Minecraft data inherits its distinctive pixelated block style, creating a domain gap from the original parameters. This motivates decoupling action control learning from data style learning through specialized training strategies.

🔼 This figure illustrates the multi-phase training strategy employed in GameFactory. Phase #0 involves pretraining a video generation model on a large, open-domain dataset. Phase #1 fine-tunes this model using LoRA (Low-Rank Adaptation) on game-specific video data to learn the style of the target game without affecting the action control. Phase #2 focuses exclusively on training the action control module while keeping the pre-trained model and LoRA parameters frozen. This decoupling ensures style-independent action control. Finally, Phase #3 demonstrates the system’s ability to generate action-controlled videos in open domains, leveraging the generalized action control from Phase #2 and the open-domain scene generation capabilities from Phase #0.
read the caption
Figure 5: Phase #0: pretraining a video generation model on open-domain data. Phase #1: finetuning with LoRA for game video data. Phase #2: training the action control module while fixing other parameters. Phase #3: inference for action-controlled open-domain generation. To decouple style learning from action control, Phase #1 learns game-specific style while Phase #2 focuses on style-independent action control. This design preserves the open-domain capabilities from Phase #0, enabling generalization in Phase #3.

🔼 Figure 6 illustrates the autoregressive video generation process. In the training stage (a), a sequence of video frames (from 0 to N) is used, with a random subset (k frames) serving as conditioning. The model learns to predict the noise in the remaining (N-k) frames. Only the noise prediction loss for these frames contributes to the training objective. The inference stage (b) leverages this learned ability to generate longer videos iteratively. Starting with k+1 initial frames, the model predicts the next N-k frames, appends them to the initial sequence, and then uses the most recent k+1 frames to predict further frames, continuing this process until the desired video length is achieved. This allows for the creation of arbitrarily long videos.
read the caption
Figure 6: Illustration of autoregressive video generation. The frames from index 00 to k𝑘kitalic_k serve as conditional frames, while the remaining N−k𝑁𝑘N-kitalic_N - italic_k frames are for prediction, with k𝑘kitalic_k randomly selected. (a) Training stage: Loss computation and optimization focus only on the noise of predicted frames. (b) Inference stage: The model iteratively selects the latest k+1𝑘1k+1italic_k + 1 frames as conditions to generate N−k𝑁𝑘N-kitalic_N - italic_k new frames, enabling autoregressive generation.

🔼 This figure showcases the model’s ability to control actions within the Minecraft game environment. The model successfully learned fundamental atomic actions, such as moving forward, backward, left, and right, using the WASD keys, as well as controlling the camera’s yaw and pitch using the mouse. Importantly, the model can combine these basic actions to perform more complex movements. The text under each video frame provides a descriptive label explaining the action, rather than being a text prompt used to generate the video.
read the caption
Figure 7: Demonstration of action control capabilities in the Minecraft domain. The model has successfully learned basic atomic actions (WASD keys) and mouse-based yaw and pitch controls. Additionally, it can combine these atomic actions to execute more complex movements. Note that the text below each video frame is a descriptive label of the content, not a text prompt provided to the model.

🔼 Figure 8 showcases the model’s ability to handle collisions, a frequent event in Minecraft navigation. The figure displays two example videos demonstrating the model’s response to encountering obstacles: one where the agent stops upon hitting a wall, and another where it stops when encountering an obstacle. Importantly, the text under each video frame serves only as a descriptive label; it was not given to the model as a prompt.
read the caption
Figure 8: Demonstration of the learned response to collision, one of the most common interactions in Minecraft navigation. Note that the text below each video frame is a descriptive label of the content, not a text prompt provided to the model.

🔼 The figure showcases the model’s ability to generalize to a new game type, a racing game, using knowledge learned from the Minecraft domain. It highlights that the ‘yaw’ control (rotation around the vertical axis), learned in Minecraft, seamlessly transfers to steering control in the racing game. Conversely, actions not directly related to steering, such as moving backward, left, or right, and adjustments to the pitch angle (rotation around the horizontal axis), are automatically reduced or eliminated in the racing game context. This demonstrates that the model effectively distinguishes and transfers relevant skills while suppressing irrelevant ones.
read the caption
Figure 9: Our model demonstrates the ability to generalize to a different game type, a racing game. Interestingly, the yaw control learned in Minecraft seamlessly transfers to steering control in the racing game, while unrelated actions, such as moving backward, left, or right, and pitch angle adjustments, automatically diminish.

🔼 This figure shows an example from the GF-Minecraft dataset. A video clip from the game is presented along with its corresponding textual annotation. The annotation uses natural language to describe the scene’s visual elements, including the terrain, plants, and other objects (such as a zombie-like figure). Key words used in the description are highlighted in red and boldface for emphasis. This demonstrates how the dataset includes both video data and associated textual descriptions, which are used to train the model in understanding and generating game scenes with associated descriptions.
read the caption
Figure 10: An example of video clip annotation, where words describing scenes and objects are highlighted in red and bolded.

🔼 This figure compares the performance of cross-attention and concatenation methods in handling discrete key inputs for action control. The results show that cross-attention is significantly better at correctly responding to key presses than concatenation. In some cases, the concatenation method fails entirely to register the key presses, while cross-attention consistently reflects the intended actions. The yellow buttons in the images represent the keys pressed during the actions.
read the caption
Figure 11: Qualitative comparison of key input control performance. It can be observed that cross-attention significantly outperforms concatenation in handling discrete key input signals, while concatenation may fail to respond to the key input. The yellow buttons indicate pressed keys.
More on tables
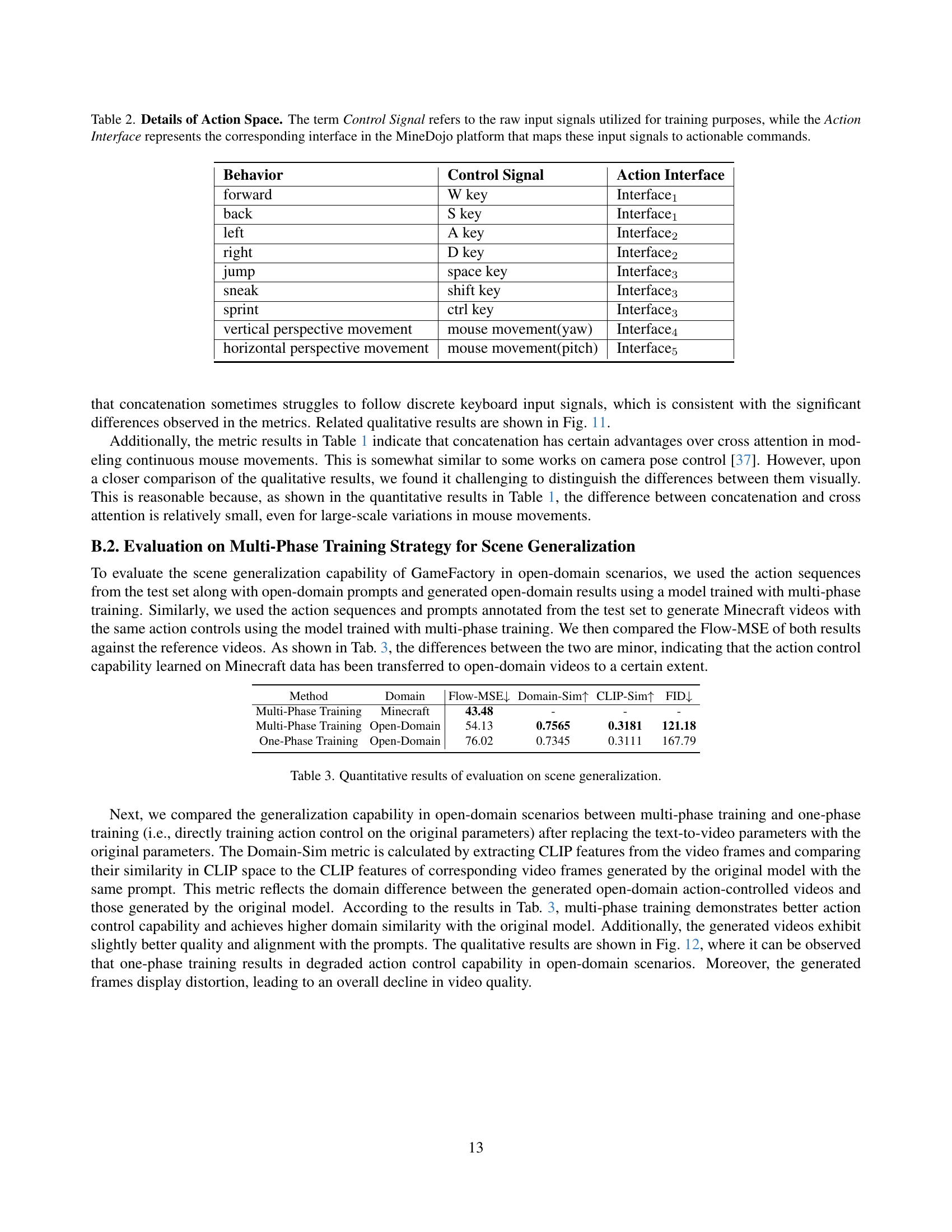
| Behavior | Control Signal | Action Interface |
|---|---|---|
| forward | W key | Interface1 |
| back | S key | Interface1 |
| left | A key | Interface2 |
| right | D key | Interface2 |
| jump | space key | Interface3 |
| sneak | shift key | Interface3 |
| sprint | ctrl key | Interface3 |
| vertical perspective movement | mouse movement(yaw) | Interface4 |
| horizontal perspective movement | mouse movement(pitch) | Interface5 |
🔼 Table 2 details the action space used in the GF-Minecraft dataset for training the video generation model. It lists various behaviors (e.g., moving forward, backward, jumping), their corresponding control signals (key presses or mouse movements), and the MineDojo interface responsible for translating those signals into actions within the Minecraft game environment. This clarifies how the different input types were handled and categorized for training.
read the caption
Table 2: Details of Action Space. The term Control Signal refers to the raw input signals utilized for training purposes, while the Action Interface represents the corresponding interface in the MineDojo platform that maps these input signals to actionable commands.
| Method | Domain | Flow-MSE | Domain-Sim | CLIP-Sim | FID |
|---|---|---|---|---|---|
| Multi-Phase Training | Minecraft | 43.48 | - | - | - |
| Multi-Phase Training | Open-Domain | 54.13 | 0.7565 | 0.3181 | 121.18 |
| One-Phase Training | Open-Domain | 76.02 | 0.7345 | 0.3111 | 167.79 |
🔼 This table presents a quantitative comparison of scene generalization capabilities between different training strategies for a video generation model. It shows the results on two datasets: Minecraft and an open-domain dataset. Metrics include Flow-MSE (optical flow mean squared error, assessing action-following ability), Domain-Sim (semantic similarity between generated and original videos), CLIP-Sim (semantic similarity using CLIP embeddings), and FID (Fréchet Inception Distance, measuring the visual quality). The comparison is between a multi-phase training approach (separating style and action control learning) and a single-phase method, allowing assessment of the effectiveness of the proposed multi-phase training for generalization to unseen scenes.
read the caption
Table 3: Quantitative results of evaluation on scene generalization.
Full paper#