TL;DR#
Current AI research heavily relies on text-based models for knowledge learning, neglecting the vast amount of knowledge present in visual data, especially videos. This paper explores an alternative approach by training a deep generative model, called VideoWorld, solely on unlabeled video data. The model’s ability to learn complex concepts such as rules and reasoning is evaluated through video-based Go and robotic control tasks. The existing methods struggles to learn from pure visual data and usually relies on text or labels or need to use reinforcement learning with rewards which are not always available.
VideoWorld uses a novel latent dynamics model to efficiently represent visual changes which enhances its knowledge acquisition ability. The results demonstrate that video-only training is sufficient for learning knowledge, including rules, reasoning, and planning. VideoWorld achieves remarkable success, reaching a professional level in Go and exhibiting strong generalization in robotic control. The model’s code and data are open-sourced, furthering the research and development of knowledge acquisition from purely visual data.
Key Takeaways#
Why does it matter?#
This paper is important because it challenges the prevailing paradigm of text-based knowledge learning by demonstrating that deep generative models can acquire complex knowledge solely from visual input. This opens up new avenues for AI research, particularly in robotics and areas where visual information is primary. The development of VideoWorld and its open-sourcing facilitates further research and advancements in this exciting field.
Visual Insights#

🔼 The figure illustrates VideoWorld, a novel approach to learning knowledge directly from unlabeled video data. It contrasts VideoWorld with traditional methods like reinforcement learning (RL), supervised learning (SL), and text-based learning. The core idea is that VideoWorld learns complex knowledge, including task-specific rules, reasoning, and planning abilities, solely by observing videos. The figure highlights three key advantages of VideoWorld: First, its unified visual representation enables better generalization across various tasks and interfaces compared to RL and SL. Second, it significantly reduces the need for manual annotation, a significant advantage over SL and text-based methods. Third, learning directly from video data allows VideoWorld to acquire richer real-world information than methods relying solely on text.
read the caption
Figure 1: VideoWorld explores learning knowledge from unlabeled videos, ranging from task-specific rules to high-level reasoning and planning capabilities. Compared to other learning methods: reinforcement learning (RL), supervised learning (SL) and text-based learning, it offers three advantages: 1) better generalization with unified visual representation for various tasks and interfaces, 2) lower manual annotation burden, and 3) learning richer real-world information than text description.
| Idx | Agent | Train | w/o Search | Input | Legal rate (%) | Action-Value (%) | Best Action Acc. (%) | Tournament Elo |
| 1 | KataGO-human-1d | RL | ✗ | State | 100 | 67.6 | 64.5 | 201923 |
| 2 | KataGO-human-5d | RL | ✗ | State | 100 | 83.5 | 83.7 | 225320 |
| 3 | KataGO-human-9d (Oracle) | RL | ✗ | State | 100 | 100 | 100 | 2700 |
| 4 | Transformer 300M | SL | ✓ | State | 99.8 | 79.7 | 87.2 | 230821 |
| 5 | Transformer 300M | SL | ✓ | Video | 99.6 | 59.7 | 58.9 | 199838 |
| 6 | VideoWorld 50M (ours) | SL | ✓ | Video | 99.5 | 73.9 | 80.9 | 209325 |
| 7 | VideoWorld 150M (ours) | SL | ✓ | Video | 99.7 | 82.0 | 86.7 | 221823 |
| 8 | VideoWorld 300M (ours) | SL | ✓ | Video | 99.7 | 83.7 | 88.1 | 231725 |
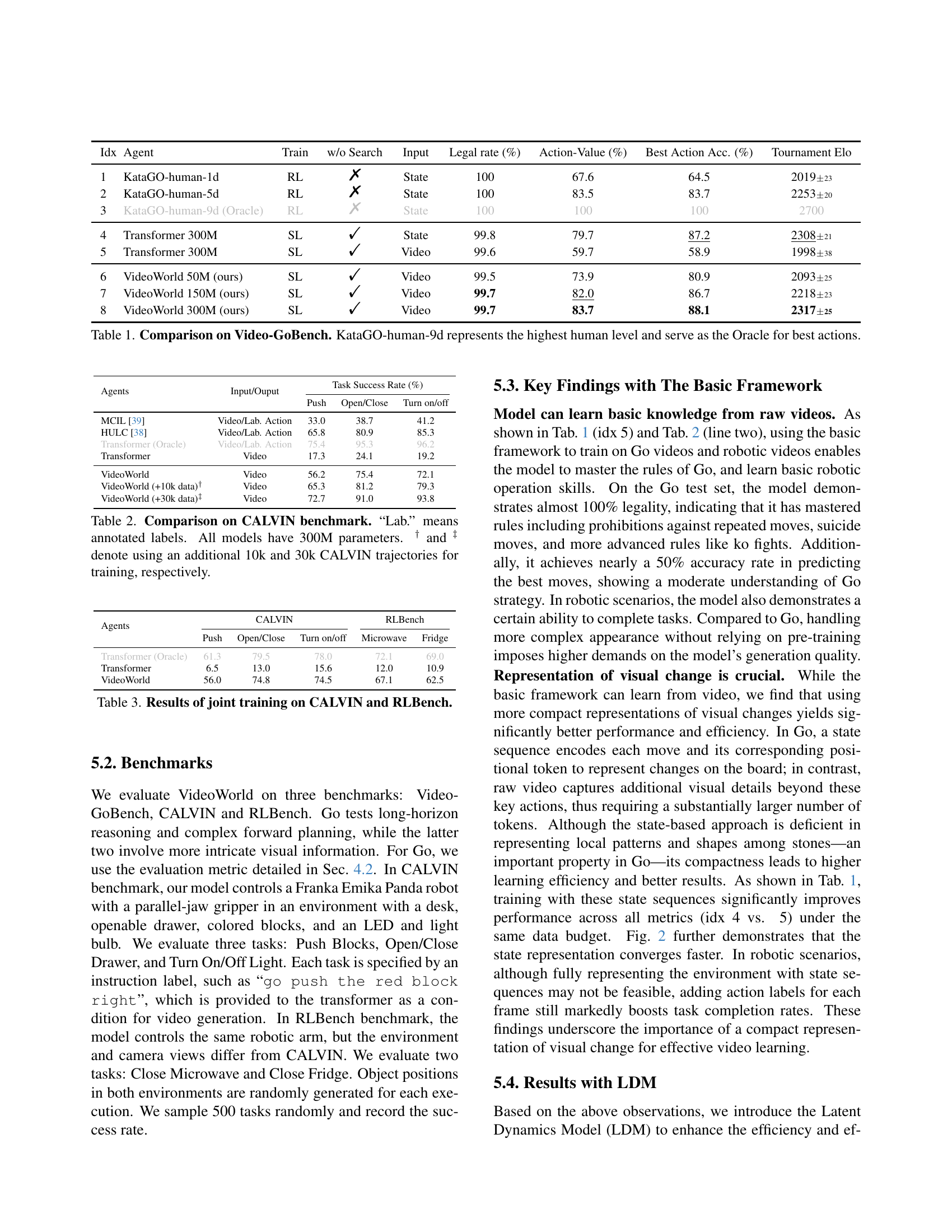
🔼 This table compares the performance of different models on the Video-GoBench benchmark, a purely visual Go game environment. The models are evaluated against three versions of the KataGo engine (trained to match human skill levels of 1-dan, 5-dan, and 9-dan) and against a model trained using only the state information (not video). The performance metrics reported are the legal move rate (percentage of legal moves made), action-value (average score for moves made, using KataGo-9d as a reference), best action accuracy (percentage of moves matching KataGo-9d’s best choice), and tournament Elo rating (relative skill level based on pairwise comparisons). The KataGo-human-9d model serves as an oracle, representing the highest level of human performance.
read the caption
Table 1: Comparison on Video-GoBench. KataGO-human-9d represents the highest human level and serve as the Oracle for best actions.
In-depth insights#
Visual Knowledge#
The concept of “Visual Knowledge” in AI research is fascinating and complex. It explores how AI systems can acquire and utilize knowledge directly from visual data, without relying on textual descriptions or pre-defined labels. This approach is crucial because a significant portion of real-world information exists in visual form, inaccessible to text-based models. VideoWorld’s innovative methodology addresses this by training a generative model on unlabeled videos, enabling it to learn rules, reasoning, and even planning capabilities. This demonstrates the richness of visual information for knowledge acquisition and the potential to overcome limitations of text-dependent AI. A critical factor identified is the effective representation of visual change over time, as simply processing raw video frames is insufficient for efficient learning. The model’s successful performance in complex tasks like Go and robotic control underlines the power of this paradigm and the immense potential of directly leveraging the vast, unlabeled repository of visual data available. Further research into efficient visual representation methods and scaling up this approach will likely unlock further breakthroughs in AI’s capacity for visual learning and understanding.
LDM’s Role#
The Latent Dynamics Model (LDM) plays a crucial role in VideoWorld by efficiently representing the temporal dynamics of visual changes in videos. Unlike simply encoding raw video frames, which can be inefficient and lead to redundant information, the LDM compresses multi-step visual changes into compact latent codes. This not only enhances learning efficiency but also allows the model to better capture and reason about complex visual information crucial for tasks involving multi-step planning and decision-making, such as Go and robotic manipulation. The LDM’s design and implementation showcase the significance of focusing on representing relevant visual changes instead of redundant visual data for effective knowledge learning. The results clearly demonstrate the significant performance improvement achieved by incorporating the LDM, highlighting its importance in enabling VideoWorld to reach advanced levels in Go and robotic tasks. Integrating the LDM with an auto-regressive transformer further enhances the model’s ability to learn complex knowledge solely from visual data. The LDM’s impact on VideoWorld’s success underscores the importance of efficient and effective visual representation for knowledge acquisition in AI.
VideoWorld’s Power#
VideoWorld demonstrates remarkable capabilities in learning complex knowledge solely from unlabeled video data. Unlike text-based models, it leverages the next-token prediction paradigm on raw video, acquiring rules, reasoning, and planning abilities. Its success in Go, achieving a 5-dan professional level, showcases its ability to understand intricate rules and strategies. Further, its performance on robotic control tasks, approaching that of oracle models in CALVIN and RLBench, reveals strong generalization across environments. VideoWorld’s strength lies in its ability to learn from purely visual information, opening new avenues for AI that surpasses traditional methods relying on explicit labels or rewards. The Latent Dynamics Model (LDM) significantly boosts its efficiency by compactly representing visual changes, making it more adept at handling long-term, complex tasks. This innovative approach offers a promising path towards creating truly general AI agents capable of learning sophisticated knowledge through observation, mirroring the learning processes of biological organisms.
Benchmarking#
The benchmarking section of a research paper is crucial for evaluating the performance of a proposed model or algorithm. A robust benchmarking strategy should involve multiple, relevant datasets to demonstrate generalizability beyond specific test cases. It’s essential to compare against established state-of-the-art baselines and to employ a variety of metrics that capture different aspects of performance. Quantitative metrics are vital, such as accuracy, precision, and recall, alongside qualitative analyses that offer a deeper understanding. The paper should transparently explain experimental setups, ensuring reproducibility. Furthermore, a thorough discussion of results is key, highlighting both strengths and limitations of the model in relation to benchmarks. This includes analyzing scenarios where the model excels or underperforms, offering insights into its capabilities and potential for future improvement. Clearly articulated conclusions summarizing the benchmarking findings and their implications for the broader research area are essential.
Future Works#
Future research directions stemming from this work on knowledge learning from unlabeled videos could explore more complex and diverse tasks. The current benchmarks (Go and robotics) provide valuable insights, but expanding to other domains, such as visual reasoning in natural scenes or multi-agent interactions, would demonstrate broader capabilities. Improving the visual representation and incorporating temporal dynamics is also crucial. While the Latent Dynamics Model (LDM) shows promise, further refinement and exploration of different architectural choices could lead to even more efficient and effective knowledge acquisition. It would be beneficial to conduct extensive scalability studies using larger video datasets and more powerful computing resources to better understand the model’s limitations and potential. Furthermore, investigating methods for interpretability is important; understanding how the model reasons and makes decisions from visual input alone is key to building trust and facilitating further development. Finally, it will be imperative to explore the implications of knowledge acquisition from purely visual data within ethical and societal considerations. This includes researching bias detection and mitigation techniques to ensure the fairness and robustness of future models.
More visual insights#
More on figures

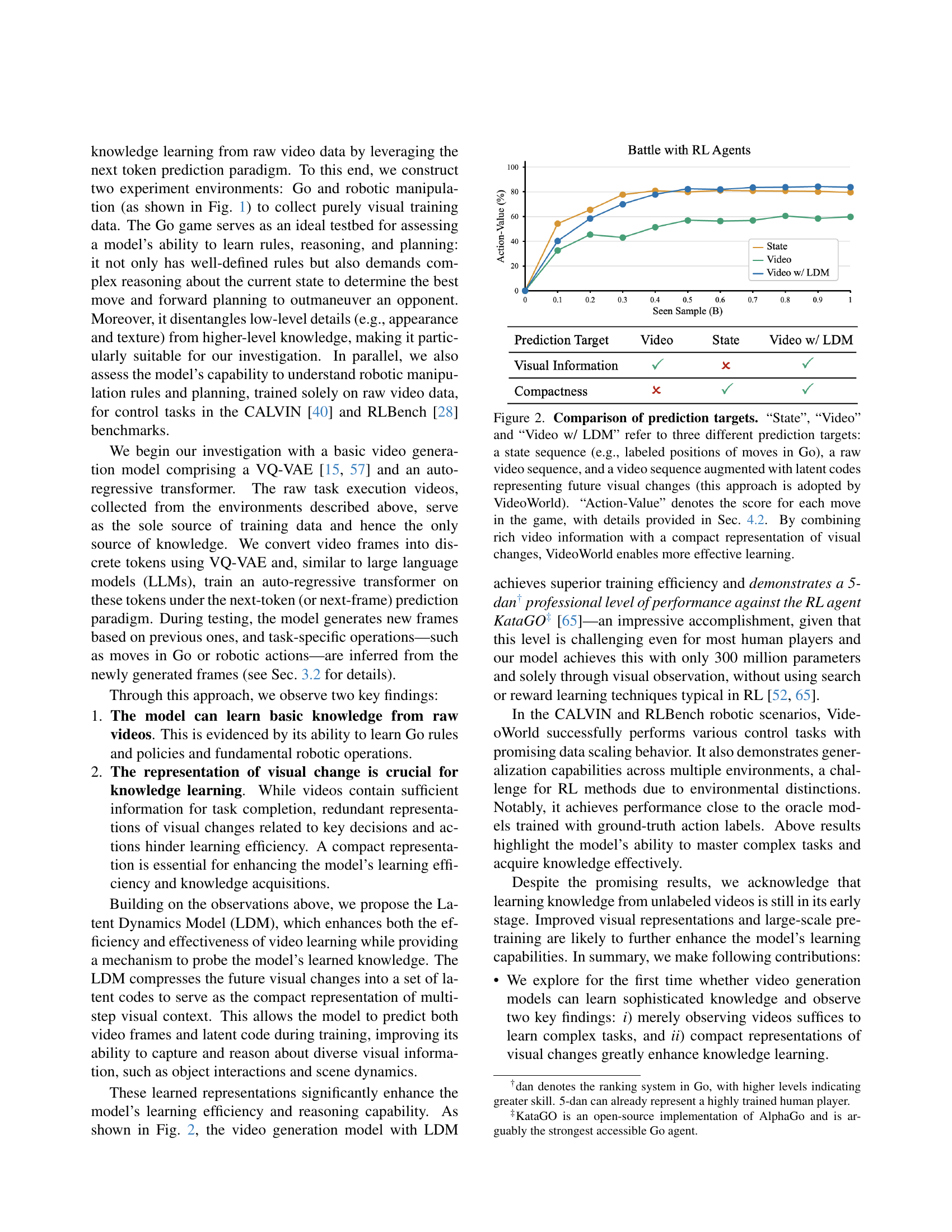
🔼 The figure compares three different approaches to predicting the next move in a game of Go: using only the game state, using raw video, and using video enhanced with latent codes to represent future visual changes. The graph shows that using video with latent dynamics improves learning efficiency. The ‘Action-Value’ metric represents the quality of each move prediction.
read the caption
Figure 2: Comparison of prediction targets. “State”, “Video” and “Video w/ LDM” refer to three different prediction targets: a state sequence (e.g., labeled positions of moves in Go), a raw video sequence, and a video sequence augmented with latent codes representing future visual changes (this approach is adopted by VideoWorld). “Action-Value” denotes the score for each move in the game, with details provided in Sec. 4.2. By combining rich video information with a compact representation of visual changes, VideoWorld enables more effective learning.

🔼 Figure 3 illustrates the architecture of VideoWorld, a novel video generation model designed for knowledge learning from unlabeled videos. The left panel shows the overall architecture, which comprises a VQ-VAE (Vector Quantized Variational Autoencoder) for encoding video frames into discrete tokens, and an autoregressive transformer for predicting the next token (or next frame) based on the previous tokens. The right panel focuses on the Latent Dynamics Model (LDM), a key component of VideoWorld. The LDM efficiently handles long-range dependencies in video sequences by first compressing the visual changes from each frame to its subsequent H frames into a set of latent codes and then seamlessly integrating these codes with the next token prediction paradigm of the autoregressive transformer. This two-stage process enhances both efficiency and effectiveness of the video generation and knowledge acquisition in VideoWorld.
read the caption
Figure 3: Overview of the proposed VideoWorld model architecture. (Left) Overall architecture. (Right) The proposed latent dynamics model (LDM). First, LDM compresses the visual changes from each frame to its subsequent H𝐻Hitalic_H frames into a set of latent codes. Then, an auto-regressive transformer seamlessly integrates the output of LDM with the next token prediction paradigm.

🔼 This figure visualizes the latent codes learned by the Latent Dynamics Model (LDM) during training on Go and robotic manipulation tasks. The left panel shows UMAP projections of latent codes from the Go game, where each point represents a latent code generated by the LDM before quantization. Odd steps correspond to white player moves and even steps to black player moves. Black moves in steps 2, 4, and 6 are highlighted to demonstrate common patterns for new black moves. These patterns are further clarified with additional color and lines on the board. The right panel shows UMAP projections of latent codes from the robotic arm’s movement in the CALVIN dataset. Here, each point represents a latent code, and the points are color-coded according to the magnitude of displacement along the X, Y, and Z axes at intervals of 1, 5, and 10 frames. Purple and red colors indicate the maximum displacement in opposite directions.
read the caption
Figure 4: UMAP projection [34] of the learned latent code on the Go (Left) and CALVIN (right) training set. Each point represents the continuous (pre-quantization) latent code generated by the LDM. In Go examples, odd steps represent white’s moves, and even steps represent black’s moves. We visualize the latent codes of black moves in steps 2/4/6. The legend shows examples of common patterns learned for new black moves. For clarity, these moves are highlighted on the board with added colors and lines to indicate new patterns. On the right, we visualize the latent codes of the robotic arm’s movement along the X/Y/Z axes at intervals of 1, 5, and 10 frames. Points are color-coded by displacement range, with purple and red indicating the maximum displacement in opposite directions along each axis.

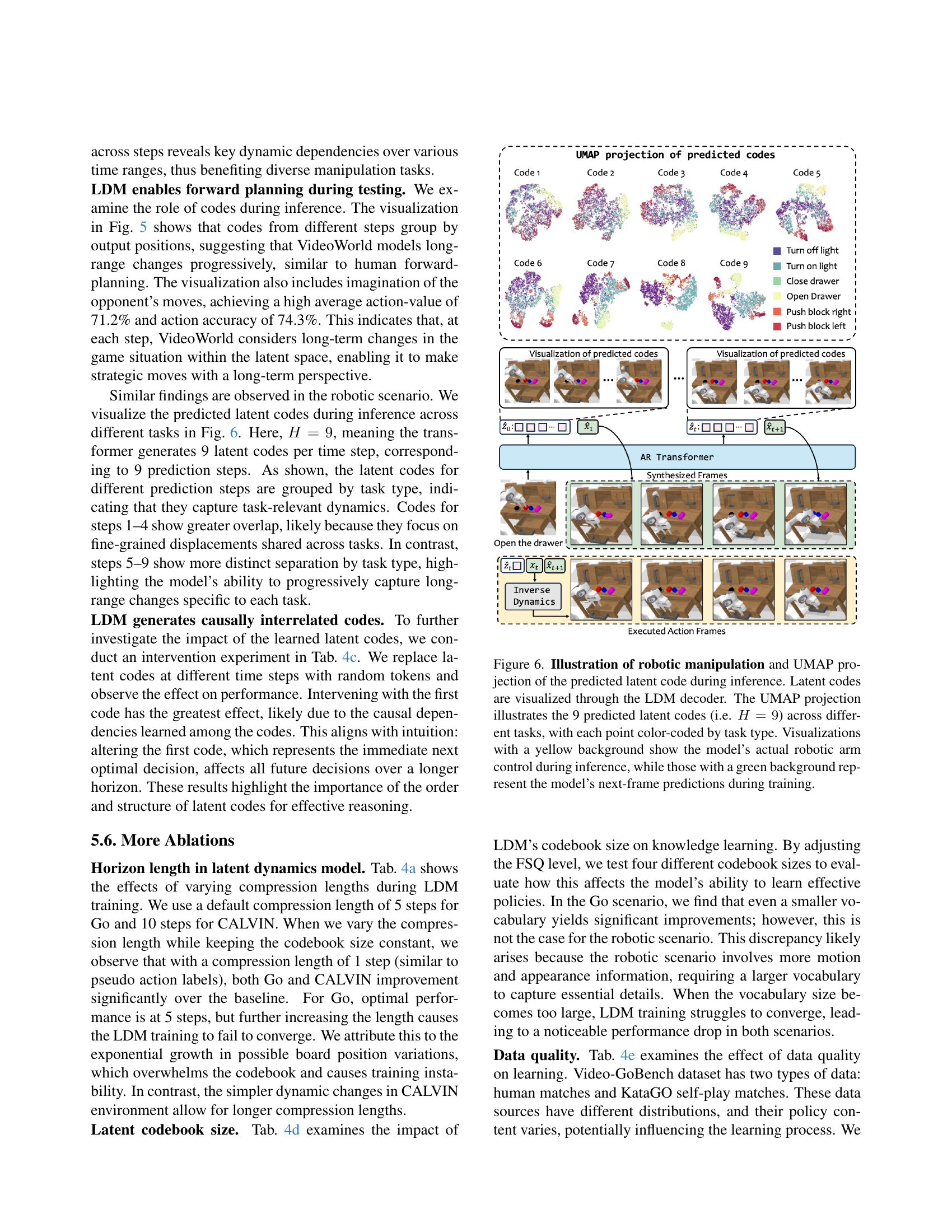
🔼 This figure demonstrates a game of Go between the VideoWorld model and KataGO. The VideoWorld model plays as black. The visualization uses UMAP to project the latent codes generated by the model’s Latent Dynamics Model (LDM). The colors of the new stones placed on the Go board correspond to the colors of the projected latent codes, showing how the model’s internal representation (latent codes) relates to its actions in the game. The clustering of the latent codes suggests that the model is not just reacting to the immediate game state but also considering future possibilities, demonstrating forward planning capabilities.
read the caption
Figure 5: Illustration of playing against KataGO and UMAP projection [34] of the predicted latent code. Our model plays as black. The generated latent code is visualized through the LDM decoder and new stones in the visualization are marked with colors to match the legend. The visualization serves as a probe, indicating that the model shows signs of forward planning.

🔼 This figure shows the comparison of prediction targets. It compares three different prediction targets: a state sequence (e.g., labeled positions of moves in Go), a raw video sequence, and a video sequence augmented with latent codes representing future visual changes. The x-axis represents the number of seen samples and the y-axis represents the Action-Value. It demonstrates that VideoWorld, by combining rich video information with a compact representation of visual changes, achieves superior training efficiency compared to using only state or video information.
read the caption
(a)

🔼 This figure shows the results of an ablation study on the compression length of the latent dynamics model (LDM) in the CALVIN environment. The x-axis represents different compression lengths (H), indicating how many future frames are compressed into a latent code. The y-axis shows the task success rate for three robotic manipulation tasks: Push, Open/Close, and Turn On/Off. The baseline represents the performance without LDM. Different compression lengths were tested, revealing the optimal H value for each task that balances compression and information retention for effective learning.
read the caption
(b)

🔼 The figure shows the results of intervening latent codes with different indices. It demonstrates the impact of altering latent codes at different time steps on the model’s performance. By replacing latent codes with random tokens, the experiment shows how altering earlier codes (those representing immediate next steps) has a greater effect than altering later codes. This highlights the importance of the causal relationships and temporal ordering of information within the latent code sequence for effective reasoning and task completion.
read the caption
(c)

🔼 The figure shows the ablation study of different codebook sizes in the latent dynamics model (LDM) on the performance of Go and CALVIN tasks. The results demonstrate how different codebook sizes (729, 15625, 64000, and 262144) impact the model’s ability to learn and achieve high accuracy in both Go and CALVIN tasks, showcasing the importance of selecting an appropriate codebook size for effective knowledge acquisition.
read the caption
(d)

🔼 This ablation study investigates the impact of the data source on the performance of the VideoWorld model. It compares the model’s performance using only human-generated Go data, only KataGo-generated data, and a combination of both. The results demonstrate how different data sources affect the model’s ability to learn and perform the game, highlighting the role of data quality and diversity in knowledge acquisition.
read the caption
(e)

🔼 This figure visualizes the latent codes generated by the Latent Dynamics Model (LDM) during inference for robotic manipulation tasks. The UMAP projection shows how these latent codes (9 codes representing 9 future time steps, H=9) cluster based on the task being performed. Each point in the UMAP plot represents a latent code, and the color indicates the specific task. The images on the right side show the model’s actions. Yellow-background images depict the actual robotic arm movements during inference. Green-background images show the model’s predictions of the next frames while it was training, illustrating its planning ability.
read the caption
Figure 6: Illustration of robotic manipulation and UMAP projection of the predicted latent code during inference. Latent codes are visualized through the LDM decoder. The UMAP projection illustrates the 9 predicted latent codes (i.e. H=9𝐻9H=9italic_H = 9) across different tasks, with each point color-coded by task type. Visualizations with a yellow background show the model’s actual robotic arm control during inference, while those with a green background represent the model’s next-frame predictions during training.

🔼 This figure shows the UMAP projection of the learned latent codes on the Go (left) and CALVIN (right) training sets. Each point represents the continuous (pre-quantization) latent code generated by the LDM. The Go visualizations show odd steps representing white’s moves and even steps representing black’s moves. The legend shows examples of common patterns learned for new black moves; these are highlighted on the board with colors and lines. The CALVIN visualizations show the latent codes of robotic arm movements along the X, Y, and Z axes at different frame intervals. Points are color-coded by displacement range, with purple and red indicating maximum displacement in opposite directions.
read the caption
(a)
More on tables
| Agents | Input/Ouput | Task Success Rate (%) | ||
| Push | Open/Close | Turn on/off | ||
| MCIL [39] | Video/Lab. Action | 33.0 | 38.7 | 41.2 |
| HULC [38] | Video/Lab. Action | 65.8 | 80.9 | 85.3 |
| Transformer (Oracle) | Video/Lab. Action | 75.4 | 95.3 | 96.2 |
| Transformer | Video | 17.3 | 24.1 | 19.2 |
| VideoWorld | Video | 56.2 | 75.4 | 72.1 |
| VideoWorld (+10k data)† | Video | 65.3 | 81.2 | 79.3 |
| VideoWorld (+30k data)‡ | Video | 72.7 | 91.0 | 93.8 |
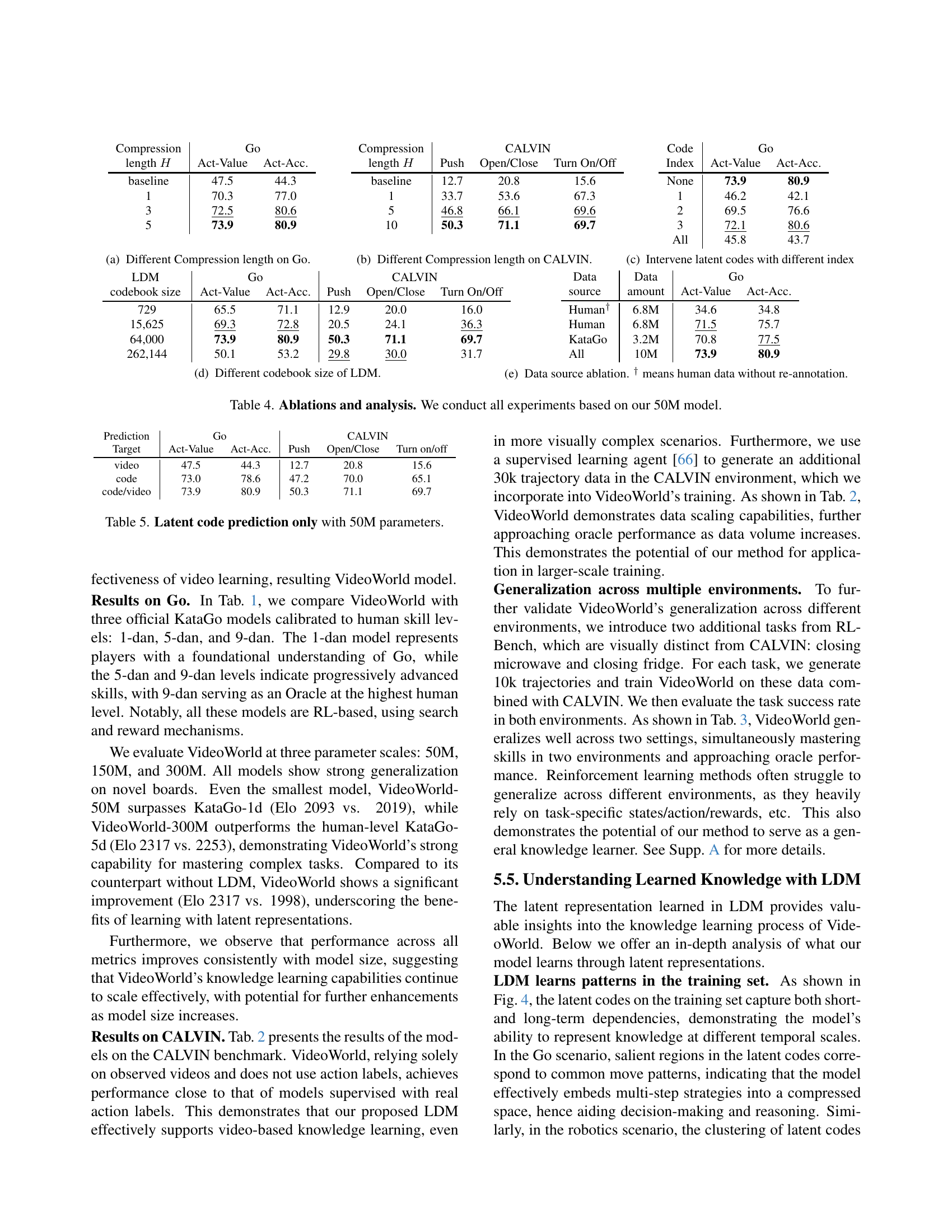
🔼 This table presents a comparison of different models’ performance on the CALVIN benchmark, a robotic manipulation task. The benchmark evaluates the ability of models to perform three tasks: Push Blocks, Open/Close Drawer, and Turn On/Off Light. The table compares a baseline model (MCIL), a state-of-the-art model (HULC), a Transformer model trained with labelled data (Oracle), and the VideoWorld model at varying training data sizes. The ‘Input/Output’ column specifies whether the models use video input and labelled action output (Lab), or only video input. The success rate for each task is given as a percentage for each model. The table highlights that VideoWorld, trained solely on unlabeled video data, performs comparably to models trained with labelled data, demonstrating its ability to learn complex tasks from visual data alone.
read the caption
Table 2: Comparison on CALVIN benchmark. “Lab.” means annotated labels. All models have 300M parameters. † and ‡ denote using an additional 10k and 30k CALVIN trajectories for training, respectively.
| Agents | CALVIN | RLBench | |||
| Push | Open/Close | Turn on/off | Microwave | Fridge | |
| Transformer (Oracle) | 61.3 | 79.5 | 78.0 | 72.1 | 69.0 |
| Transformer | 6.5 | 13.0 | 15.6 | 12.0 | 10.9 |
| VideoWorld | 56.0 | 74.8 | 74.5 | 67.1 | 62.5 |
🔼 This table presents the results of a joint training experiment on two robotic manipulation benchmarks: CALVIN and RLBench. It compares the performance of a VideoWorld model trained only on visual data to an oracle model (Transformer) trained with ground truth action labels. The table shows success rates (percentage of successful task completions) for three distinct tasks across both benchmarks: Push, Open/Close, and Turn on/off in CALVIN; and Close Microwave and Close Fridge in RLBench. The comparison highlights the VideoWorld model’s ability to achieve promising results despite lacking ground truth action labels, demonstrating its capacity for knowledge acquisition from visual inputs alone.
read the caption
Table 3: Results of joint training on CALVIN and RLBench.
| Compression length | Go | |
| Act-Value | Act-Acc. | |
| baseline | 47.5 | 44.3 |
| 1 | 70.3 | 77.0 |
| 3 | 72.5 | 80.6 |
| 5 | 73.9 | 80.9 |
🔼 This table presents ablation studies and analysis on the VideoWorld model (50M parameter version). It shows the impact of different design choices on model performance, including varying compression lengths for the latent dynamics model (LDM) in Go and CALVIN environments, experimenting with different codebook sizes in the LDM, and analyzing the effect of different data sources (human vs. KataGo). The results demonstrate the influence of these choices on both action value and accuracy metrics.
read the caption
Table 4: Ablations and analysis. We conduct all experiments based on our 50M model.
| Compression length | CALVIN | ||
| Push | Open/Close | Turn On/Off | |
| baseline | 12.7 | 20.8 | 15.6 |
| 1 | 33.7 | 53.6 | 67.3 |
| 5 | 46.8 | 66.1 | 69.6 |
| 10 | 50.3 | 71.1 | 69.7 |
🔼 This table presents ablation study results, focusing on the impact of using only latent codes for prediction, without including the video frames. It compares the performance of a 50M parameter model on Go and CALVIN tasks when predicting only latent codes versus predicting both latent codes and video frames, highlighting the contribution of latent codes to model performance. The metrics used are Action-Value and Action Accuracy, demonstrating how the model’s ability to predict and utilize the latent codes translates to overall task performance.
read the caption
Table 5: Latent code prediction only with 50M parameters.
| Code Index | Go | |
| Act-Value | Act-Acc. | |
| None | 73.9 | 80.9 |
| 1 | 46.2 | 42.1 |
| 2 | 69.5 | 76.6 |
| 3 | 72.1 | 80.6 |
| All | 45.8 | 43.7 |
🔼 This table details the hyperparameters used for training both the latent dynamics model (LDM) and the autoregressive transformer. It lists the optimizer, learning rate, weight decay, momentum, batch size, learning rate schedule, warmup iterations, maximum iterations, augmentations, training loss type, and the target for training (reconstruction or next token prediction). Separate configurations are provided for the LDM and the transformer.
read the caption
Table A.1: Training configurations for the latent dynamics model (LDM) and auto-regressive (AR) transformer.
Full paper#