TL;DR#
Generating realistic and synchronized talking head videos from audio is a challenging task. Existing methods often struggle to capture the intricate relationship between audio and full-body movements, resulting in unnatural or inaccurate animations. This is especially true when trying to generate both detailed facial expressions and realistic hand gestures, which are crucial for conveying the expressiveness of human speech.
To address this, EMO2 proposes a novel two-stage approach. The first stage focuses on generating hand poses directly from audio, leveraging the strong correlation between audio and hand movements. The second stage uses a diffusion model to synthesize video frames, incorporating the generated hand poses to produce realistic facial expressions and body movements. This approach significantly simplifies the generation process and improves synchronization. The results demonstrate that EMO2 surpasses state-of-the-art methods in terms of visual quality, synchronization accuracy, and motion diversity, paving the way for more realistic and engaging audio-driven avatar video generation.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to audio-driven avatar video generation, addressing the challenge of generating realistic and synchronized facial expressions and hand gestures. The two-stage framework, focusing on hand pose generation as an intermediary step, improves the accuracy and expressiveness of the final videos. This work has the potential to advance research in areas such as virtual reality, animation, and human-computer interaction, opening up new possibilities for creating engaging and lifelike virtual characters.
Visual Insights#

🔼 This figure illustrates the core concept of the proposed method. It draws an analogy between human movement and robotic control. In robotics, the ’end-effector’ (EE), often a hand or tool at the end of a robotic arm, is the part that interacts directly with the environment. The robot’s control system plans the EE’s movements first, and the rest of the robot’s body adapts accordingly through inverse kinematics (IK). The authors propose a similar approach for generating human videos: they focus on generating hand movements (EE) first, directly from the audio input, and then use a diffusion model to generate the rest of the body’s movements, ensuring synchronization with the hand gestures. The hand poses serve as a guiding signal, simplifying the generation process and improving naturalness.
read the caption
Figure 1: The motivation behind our method. Human motion, similar to that of robots, involves planning the ”end-effector” (EE), typically the hands, towards the target position. The rest of the body then cooperates accordingly with the EE, abiding by inverse kinematics principles.
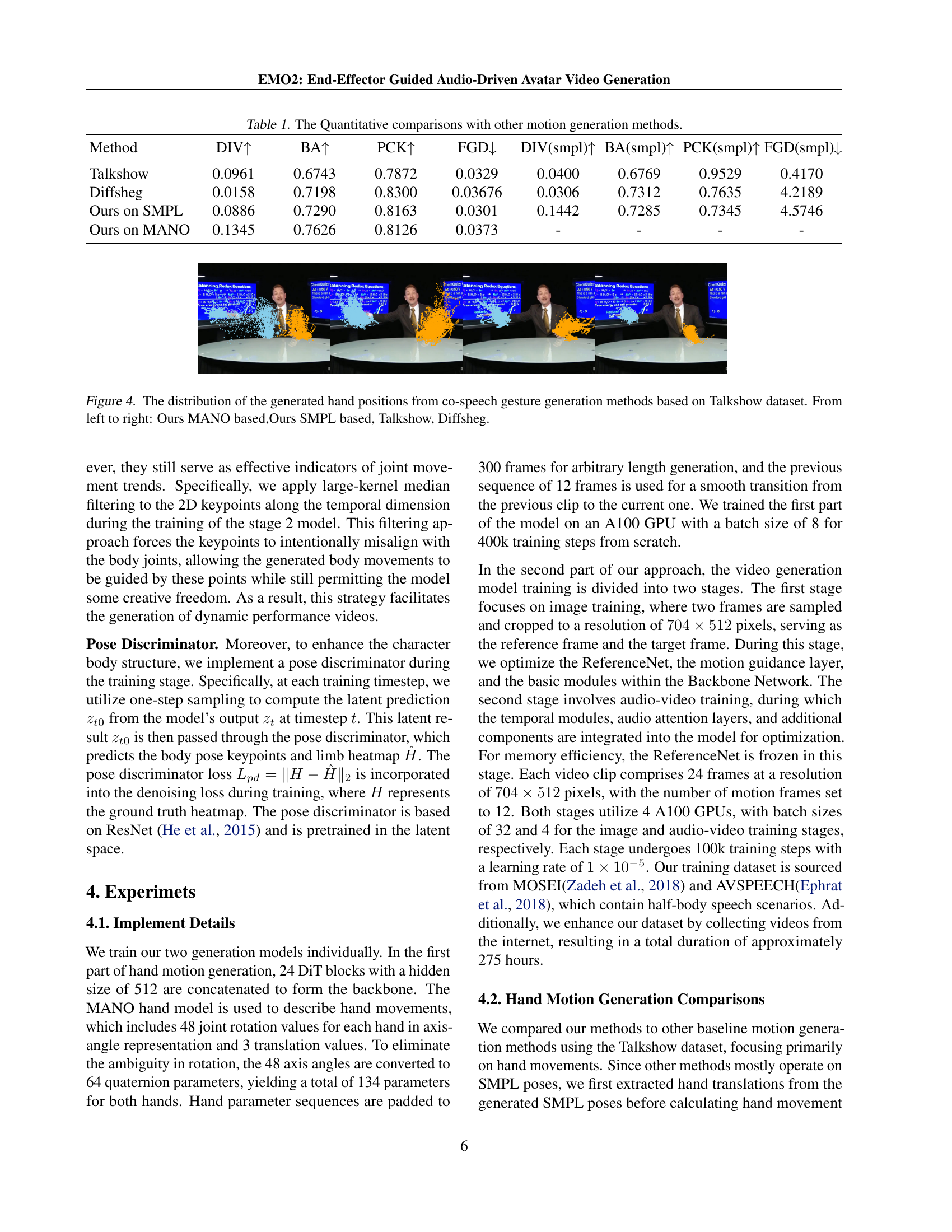
| Method | DIV | BA | PCK | FGD | DIV(smpl) | BA(smpl) | PCK(smpl) | FGD(smpl) |
|---|---|---|---|---|---|---|---|---|
| Talkshow | 0.0961 | 0.6743 | 0.7872 | 0.0329 | 0.0400 | 0.6769 | 0.9529 | 0.4170 |
| Diffsheg | 0.0158 | 0.7198 | 0.8300 | 0.03676 | 0.0306 | 0.7312 | 0.7635 | 4.2189 |
| Ours on SMPL | 0.0886 | 0.7290 | 0.8163 | 0.0301 | 0.1442 | 0.7285 | 0.7345 | 4.5746 |
| Ours on MANO | 0.1345 | 0.7626 | 0.8126 | 0.0373 | - | - | - | - |
🔼 This table presents a quantitative comparison of different motion generation methods, including the proposed method and existing state-of-the-art techniques. The comparison is based on several metrics, including diversity (DIV), beat alignment (BA), Percentage of Correct Keypoints (PCK), and Fréchet Gesture Distance (FGD). Higher DIV and BA scores indicate better performance, while lower PCK and FGD scores are preferred.
read the caption
Table 1: The Quantitative comparisons with other motion generation methods.
In-depth insights#
Audio-Driven Gesture#
Audio-driven gesture generation, a core aspect of embodied AI, aims to synthesize realistic and synchronized body movements from audio input. Early methods relied on rule-based systems, mapping phonemes to pre-defined gestures, resulting in simplistic and unnatural animations. Data-driven approaches leverage neural networks trained on large datasets of audio-gesture pairs, enabling more nuanced and expressive motion. However, challenges persist in capturing the complex interplay between speech and body language, especially concerning the subtle coordination across multiple body joints. The recent adoption of diffusion models offers a promising avenue for addressing these issues. These models excel at generating high-fidelity videos with realistic motion detail, and by conditioning the generation process on audio features, can produce highly natural and synchronized audio-driven gestures. A key innovation is the focus on end-effector control, recognizing that hand movements strongly correlate with audio. By generating hand poses directly from the audio and then using diffusion models to synthesize the rest of the body’s motion, a more intuitive and effective approach can be achieved. This reduces complexity and improves accuracy, enabling smoother and more expressive full-body gestures.
Two-Stage Framework#
The proposed two-stage framework offers a novel approach to audio-driven avatar video generation by tackling the challenge of co-speech gesture generation. The first stage cleverly focuses on the strong correlation between audio and hand movements, directly generating hand poses from audio input. This is a significant simplification, avoiding the complexities of full-body pose prediction often encountered in existing methods. By using hands as the primary ‘end-effector,’ the model leverages the intuitive relationship between audio and hand gestures, resulting in more natural and expressive movements. The second stage utilizes a diffusion model to synthesize video frames, integrating the pre-generated hand poses. This ‘pixels prior IK’ approach, inspired by robotics, allows the model to generate realistic facial expressions and body movements while maintaining coherence. This decomposition into two stages is crucial, as it allows for precise control over hand gestures in the first stage and leverages the strengths of diffusion models for realistic video generation in the second. Overall, this framework demonstrates a significant improvement in both visual quality and synchronization accuracy, showcasing a more efficient and effective method for generating expressive audio-driven avatar videos.
Diffusion Model#
Diffusion models are a cornerstone of the presented research, forming the backbone of both the hand motion generation and the video frame synthesis stages. The core concept revolves around a forward diffusion process that progressively adds noise to data, culminating in pure noise, and a reverse process trained to denoise and reconstruct the original data given the noisy input. The use of diffusion models offers several advantages, including the generation of high-quality, realistic images and videos and the ability to handle intricate conditional inputs such as audio and hand poses for guiding the generative process. The researchers leveraged the strengths of diffusion models to refine the co-speech gesture synthesis task. In the first stage, a diffusion transformer model maps audio input to hand poses, taking advantage of the strong correlation between audio signals and hand movements. This simplification enables precise control over gesture generation. In the second stage, a diffusion model refines video frames using the generated hand poses and audio, generating realistic facial expressions and body movements. The integration of pre-trained models and various enhancements such as hand masks and confidence scores further improves the quality and accuracy of the output. Overall, the choice and application of diffusion models in this research are strategically crucial, driving the methodological innovation and the improved performance.
Hand Pose Generation#
The paper introduces a novel two-stage framework for audio-driven avatar video generation. A crucial component is the hand pose generation stage, which leverages the strong correlation between audio signals and hand movements. This is a key departure from existing methods that focus on full-body pose generation, often struggling with the weak correspondence between audio and complex body motions. The method directly maps audio input to hand poses using a diffusion transformer model. This simplifies the problem, enabling more precise control over gesture generation and allowing for more expressive and realistic hand movements. The integration of style and speed embeddings further enhances the diversity of generated hand poses. Importantly, a hand motion mask addresses issues with inaccurate or missing hand annotations in training data, improving the model’s robustness. The generated hand poses are then incorporated into the second stage, a diffusion-based video generation model, to create realistic facial expressions and full-body movements. The choice to prioritize hand pose generation demonstrates a deep understanding of the human-computer interaction process and the role of hand gestures in communication. This novel approach promises a significant step towards generating more expressive and natural co-speech videos.
Video Synthesis#
The research paper focuses on audio-driven avatar video generation, a complex process involving several stages. Video synthesis is the culmination of these stages, where a diffusion model generates video frames from intermediate representations. This synthesis step is crucial because it transforms abstract representations (like hand poses and audio features) into a visually coherent and realistic video output. The effectiveness of the synthesis hinges on several factors including: the quality of the intermediate representations (accurate hand pose generation is particularly important), the capacity of the diffusion model to handle complex spatiotemporal dependencies in video data, and the successful integration of audio cues to ensure lip synchronization and natural-looking body movements. The choice of using a diffusion model for video synthesis, instead of other generative methods, is likely due to its strength in handling high-resolution image generation and producing sharp, detailed videos. Successfully addressing the challenges of temporal consistency, fine-grained control, and generalization to diverse inputs are vital for creating compelling and believable results, indicating video synthesis is a critical component that directly determines the system’s ability to generate high-quality, audio-synchronized avatar videos.
More visual insights#
More on figures

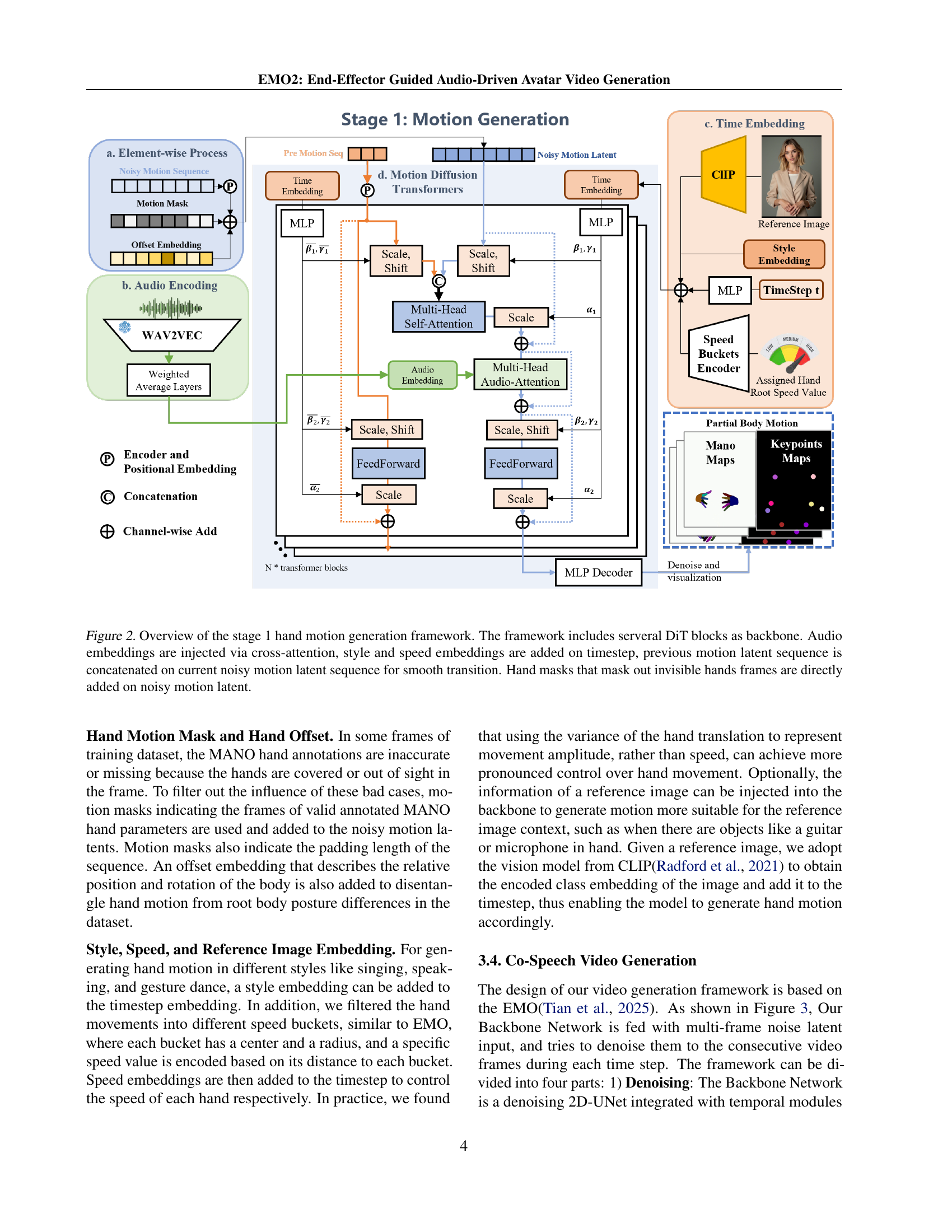
🔼 This figure illustrates the architecture of Stage 1 in the proposed two-stage framework for audio-driven gesture generation. The core is built using several Diffusion Transformers (DiT) blocks. Audio embeddings are integrated through cross-attention mechanisms, allowing the model to incorporate audio information into the generation process. Style and speed embeddings are added at each timestep, allowing control over the generated motion style and speed. To maintain smooth transitions between frames, the previous motion latent sequence is concatenated with the current noisy motion sequence. Finally, hand masks are incorporated to handle cases where hands are not visible in the training data, ensuring more robust and accurate hand pose generation.
read the caption
Figure 2: Overview of the stage 1 hand motion generation framework. The framework includes serveral DiT blocks as backbone. Audio embeddings are injected via cross-attention, style and speed embeddings are added on timestep, previous motion latent sequence is concatenated on current noisy motion latent sequence for smooth transition. Hand masks that mask out invisible hands frames are directly added on noisy motion latent.

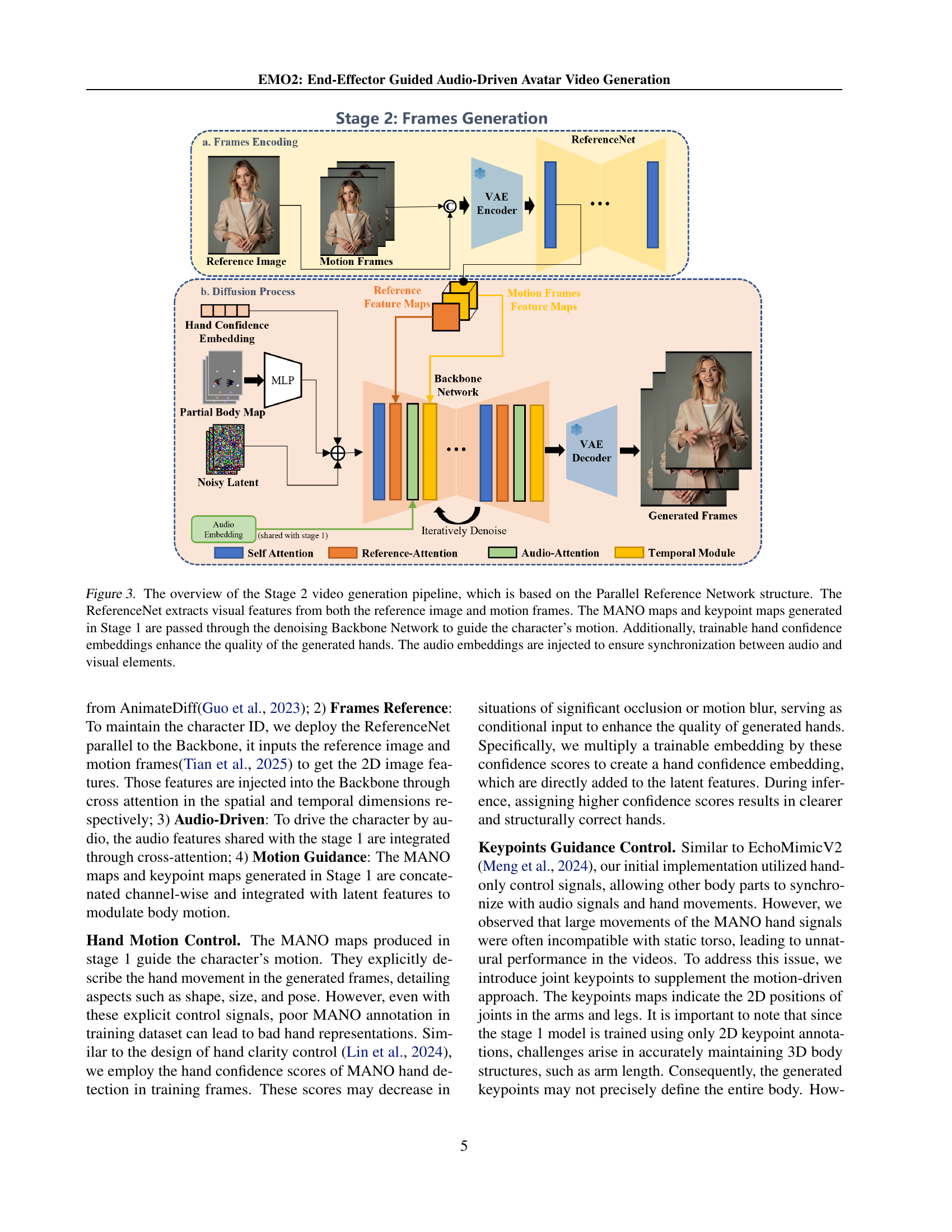
🔼 This figure illustrates the second stage of the proposed audio-driven avatar video generation framework. It uses a Parallel Reference Network architecture, which combines visual features from a reference image and motion frames generated in the previous stage. The model incorporates MANO maps and keypoint maps to guide character motion, and trainable hand confidence embeddings improve hand realism. Audio embeddings are integrated to ensure synchronization between audio and the generated video.
read the caption
Figure 3: The overview of the Stage 2 video generation pipeline, which is based on the Parallel Reference Network structure. The ReferenceNet extracts visual features from both the reference image and motion frames. The MANO maps and keypoint maps generated in Stage 1 are passed through the denoising Backbone Network to guide the character’s motion. Additionally, trainable hand confidence embeddings enhance the quality of the generated hands. The audio embeddings are injected to ensure synchronization between audio and visual elements.

🔼 Figure 4 presents a comparison of hand position distributions generated by different co-speech gesture generation methods using the Talkshow dataset. The figure visually illustrates the spatial dispersion of generated hand poses. Each method is represented in a separate plot, enabling a direct comparison of hand position distributions across different models. The plots are ordered from left to right as follows: the proposed method using MANO (a model for hand pose estimation), the proposed method using SMPL (a more general human body model), the Talkshow model, and the Diffsheg method. This allows for an easy visual assessment of the differences in variability and accuracy of hand pose generation among the various approaches.
read the caption
Figure 4: The distribution of the generated hand positions from co-speech gesture generation methods based on Talkshow dataset. From left to right: Ours MANO based,Ours SMPL based, Talkshow, Diffsheg.

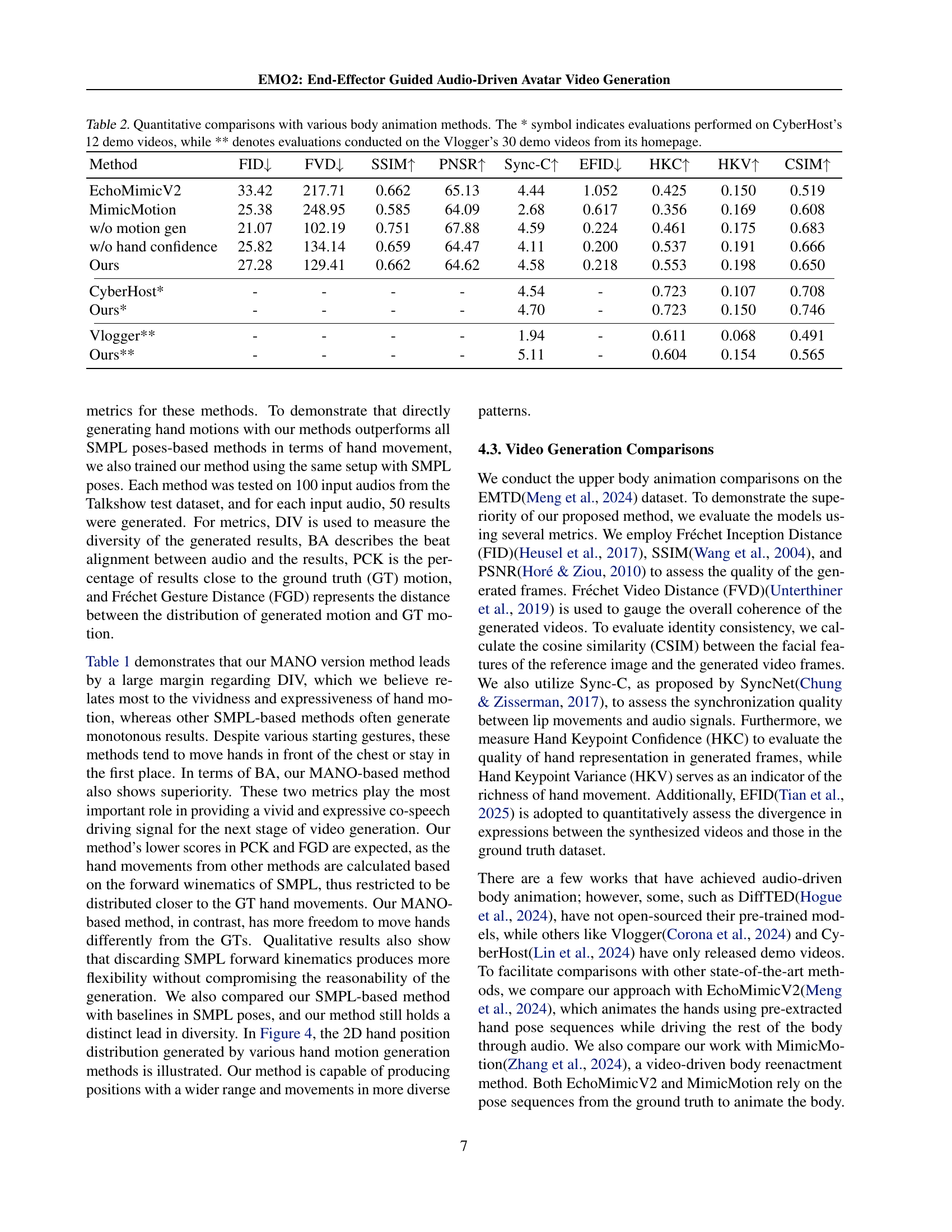
🔼 Figure 5 presents a qualitative comparison of avatar video generation results from different methods using the EMTD dataset. It visually demonstrates the differences in body animation quality, particularly focusing on the naturalness and expressiveness of the generated movements. The figure includes a reference image, results from EchoMimicV2, MimicMotion, and the proposed method (both with and without hand confidence embeddings). This allows for a direct visual comparison to assess the overall quality of each approach, highlighting advantages and shortcomings in generating realistic and fluid body movements synchronized with audio.
read the caption
Figure 5: The qualitative comparisons with pose-driven body animation methods, based on the EMTD dataset.

🔼 Figure 6 presents a qualitative comparison of video generation results from several audio-driven body animation methods, including CyberHost, Vlogger, and the proposed method. It visually demonstrates the differences in realism, expressiveness, and overall quality of the generated videos. Each row showcases the reference image, followed by results from CyberHost, Vlogger and the proposed method, respectively, using the same audio and reference image for all methods.
read the caption
Figure 6: The qualitative comparisons with audio-driven body animation methods.
Full paper#