TL;DR#
Current mobile assistants struggle with complex, multi-step tasks and lack the ability to learn from past experiences. They often fall short in addressing real-world human needs and are not efficient in handling long-horizon tasks. This necessitates the development of more sophisticated mobile agents capable of handling these challenges.
Mobile-Agent-E tackles these issues with a hierarchical framework that separates high-level planning from low-level actions and includes a self-evolution module. This module learns from past experiences, improving performance and efficiency over time. Experiments using the new Mobile-Eval-E benchmark demonstrate significant improvements over previous state-of-the-art methods. The self-evolution module shows promising results in improving both efficiency and accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing mobile agents by introducing a novel hierarchical multi-agent framework, Mobile-Agent-E, capable of self-evolution. It also introduces a new benchmark, Mobile-Eval-E, which better reflects real-world mobile task complexities. The self-evolution module is a significant contribution, enabling continuous improvement in task performance and efficiency. This work opens new avenues for research in mobile agent design, self-learning algorithms, and benchmark development.
Visual Insights#

🔼 Mobile-Agent-E is a novel hierarchical multi-agent mobile assistant. It surpasses previous state-of-the-art models on complex real-world tasks by separating high-level planning from low-level actions. A key feature is its self-evolution module, which learns from past experiences to generate reusable ‘Shortcuts’ (efficient action sequences) and general ‘Tips’ (advice) that improve performance and efficiency. The figure illustrates the Mobile-Agent-E architecture and provides example task outputs.
read the caption
Figure 1: We propose Mobile-Agent-E, a novel hierarchical multi-agent mobile assistant that outperforms previous state-of-the-art approaches (Zhang et al., 2023; Wang et al., 2024b, a) on complex real-world tasks. Mobile-Agent-E disentangles high-level planning and low-level action decision with dedicated agents. Equipped with a newly introduced self-evolution module that learns general Tips and reusable Shortcuts from past experiences, Mobile-Agent-E demonstrates further improvements in both performance and efficiency.
| Notation | Description |
| Environment | |
| Input task query | |
| Action††† can represent either a single atomic operation or a sequence of atomic operations if performing a Shortcut. at time | |
| Phone state (screenshot) at time | |
| Agents | |
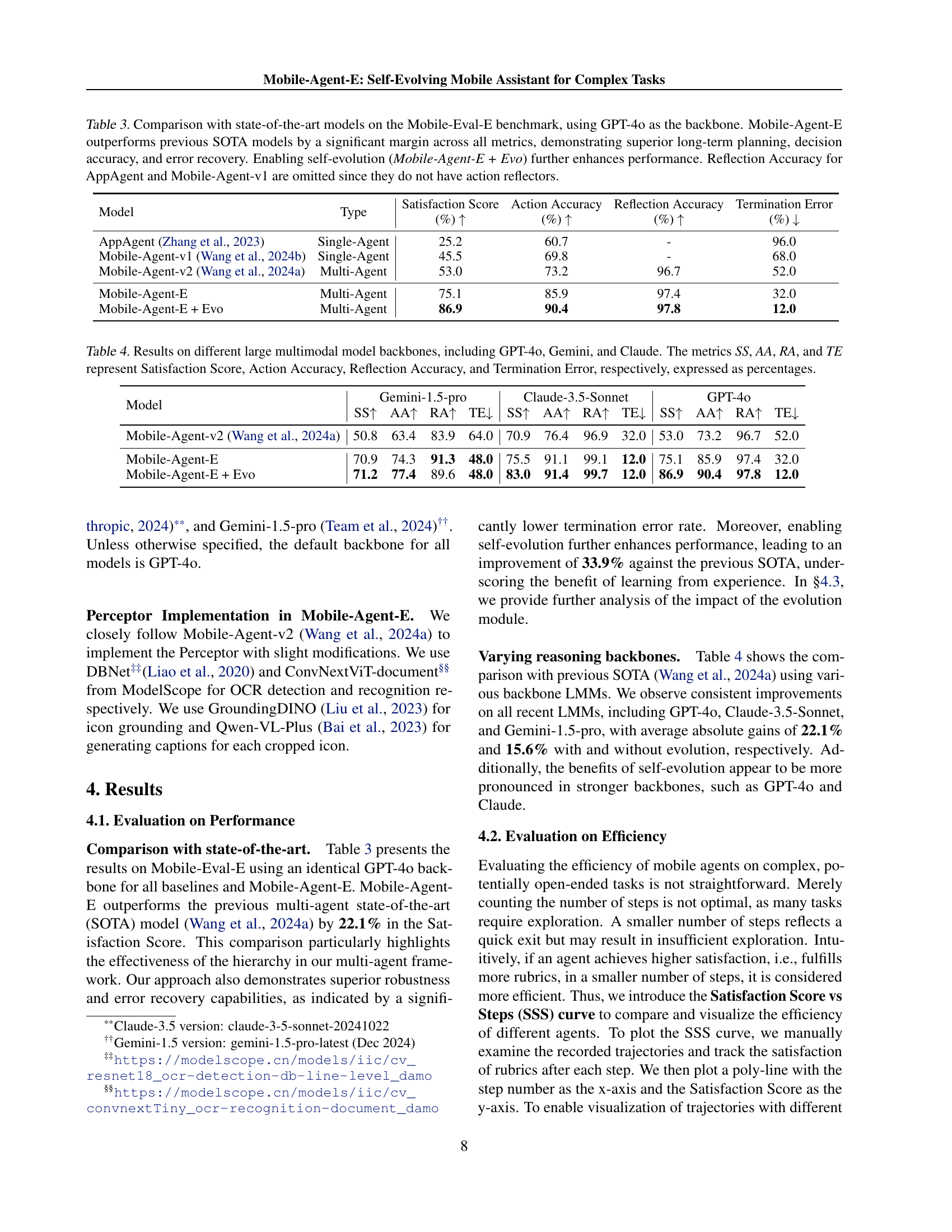
| Perceptor | |
| Manager | |
| Operator | |
| Action Reflector | |
| Notetaker | |
| Experience Reflector for Shortcuts | |
| Experience Reflector for Tips | |
| Working Memory | |
| Visual perception result at time | |
| Overall plan (decomposed subgoals) at time | |
| Current subgoal at time | |
| Progress status at time | |
| Important notes at time | |
| Error Escalation Flag at time | |
| Action history with outcome status | |
| Error history with feedback | |
| Long-term Memory | |
| Shortcuts | |
| Tips | |
🔼 This table lists notations used in the paper and their corresponding descriptions. It provides a comprehensive glossary of terms and symbols that are essential for understanding the Mobile-Agent-E framework and its associated algorithms. The table is divided into two main sections: Environment and Agents. Environment includes notations for task input, actions, and phone states. Agents include notations for different agents involved in the system along with notations for the working memory and long-term memory.
read the caption
Table 1: Notation definitions.
In-depth insights#
Mobile Agent E#
Mobile Agent E presents a novel approach to mobile assistance, addressing limitations of prior methods by introducing a hierarchical multi-agent framework. This architecture separates high-level planning from low-level execution, improving efficiency and robustness. The system’s self-evolution module is a key innovation, enabling continuous learning from past experiences. This learning is manifested through the acquisition of reusable Shortcuts and general Tips stored in long-term memory. The framework demonstrates significant performance gains on a new benchmark, Mobile-Eval-E, which features complex real-world tasks. However, the paper also acknowledges limitations, particularly concerning the generation and use of Shortcuts, suggesting that future work should refine shortcut generation and validation. Overall, Mobile Agent E offers a promising advancement in mobile assistance, showcasing the potential of combining hierarchical reasoning with self-learning capabilities.
Hierarchical Framework#
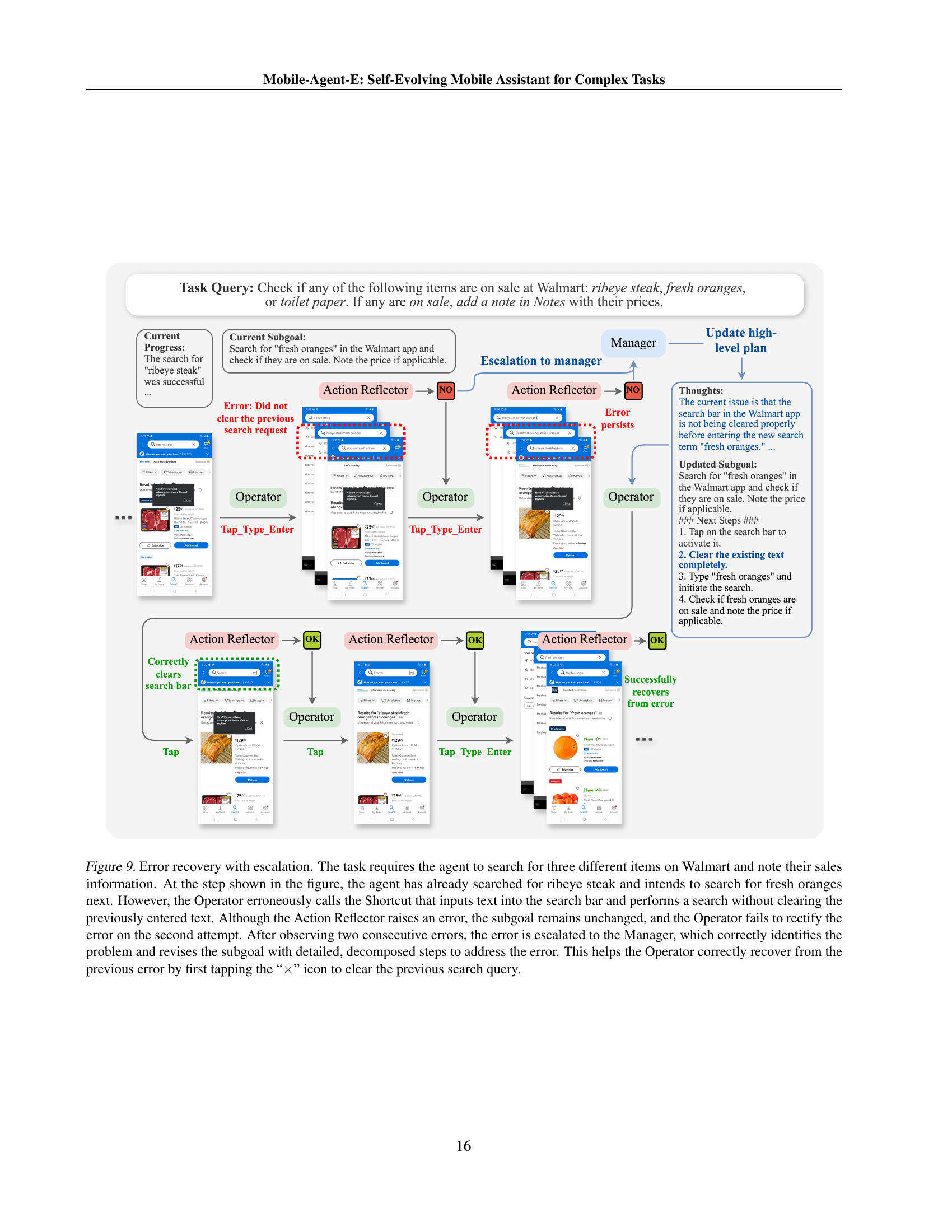
A hierarchical framework in a mobile agent system is crucial for effectively managing complex tasks. It promotes efficiency by decomposing high-level goals into smaller, manageable sub-goals. This decomposition allows for parallel processing and specialization of agents, each focusing on a specific aspect of the task. A manager agent coordinates the actions of these lower-level agents, ensuring that sub-goals are completed in the correct order and resources are allocated effectively. This approach is particularly beneficial for handling long-horizon tasks where intricate reasoning and multiple interactions with various mobile apps are necessary. The hierarchical structure enhances robustness and error recovery by allowing higher-level agents to intervene and adjust strategies when lower-level agents encounter unexpected situations. The framework also allows for easier integration of self-evolution modules, which can learn from past experiences and refine agent behavior to improve overall performance and efficiency. Clear separation of concerns between planning and execution is another key advantage, preventing the conflation of high-level strategic decisions with low-level operational details, enhancing the system’s overall scalability and maintainability.
Self-Evolution Module#
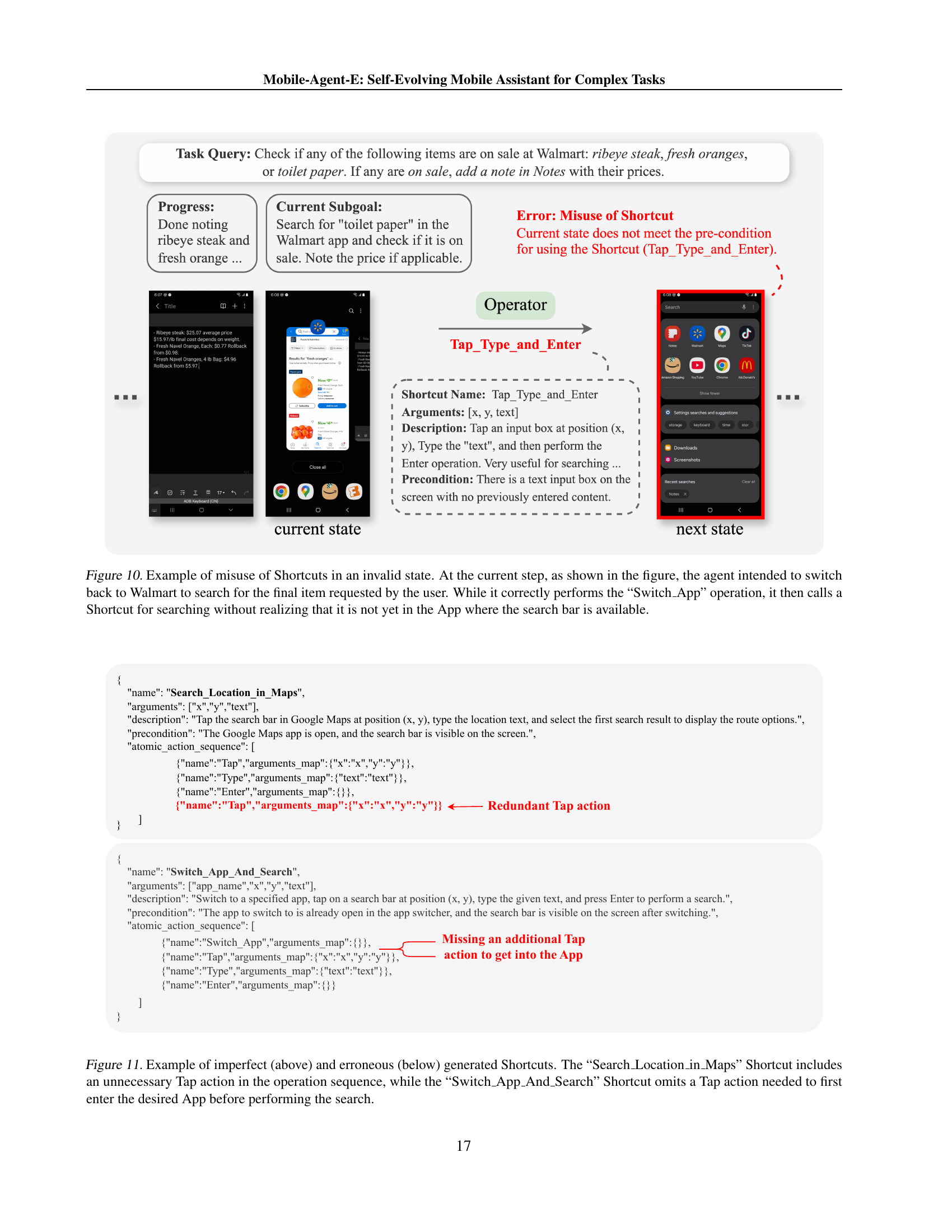
The Self-Evolution Module is a crucial component of Mobile-Agent-E, designed to enhance its efficiency and adaptability over time. It leverages a persistent long-term memory that stores both Tips (general guidelines) and Shortcuts (reusable atomic operation sequences). These are continuously updated after each task by the Experience Reflectors, which analyze the interaction history. Tips are akin to human episodic memory, providing general guidance and lessons learned from past interactions. Shortcuts, on the other hand, represent procedural knowledge, offering efficient, pre-defined solutions for recurring subroutines. The inclusion of both Tips and Shortcuts promotes continuous refinement of task performance. This self-evolution mechanism addresses a critical limitation of prior mobile agents: the inability to learn and adapt from past experiences, enabling Mobile-Agent-E to significantly outperform existing approaches in complex, real-world tasks.
Mobile-Eval-E Benchmark#
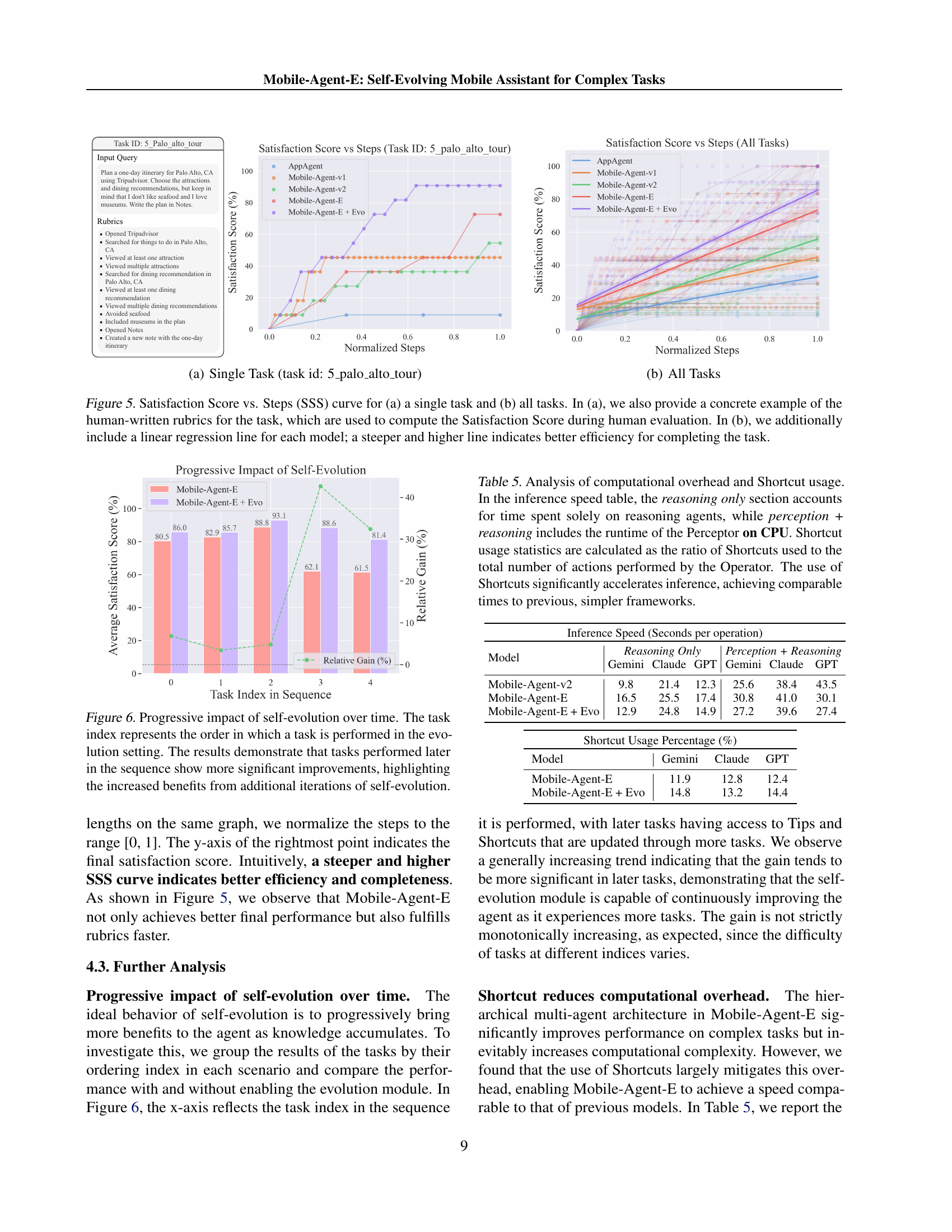
The Mobile-Eval-E benchmark is a crucial contribution to the field of mobile agent research because it addresses a significant gap in existing benchmarks. Unlike previous benchmarks focusing on simple, short-horizon tasks, Mobile-Eval-E introduces complex, real-world scenarios requiring multi-app interactions and long-horizon planning. This increased complexity better reflects the challenges faced by human users when performing multi-step tasks on their mobile devices. The benchmark’s design incorporates a novel evaluation metric, the Satisfaction Score, which moves beyond binary success/failure measurements to assess more nuanced aspects of task completion aligned with human preferences. This shift towards human-centric evaluation makes the benchmark more meaningful and directly applicable to real-world use cases. By using the SSS curve, the benchmark enables a more comprehensive analysis of both performance and efficiency. Mobile-Eval-E’s challenges push the boundaries of mobile agent capabilities, promoting further innovation and more robust, human-aligned mobile assistant development.
Future Work#
The authors of the Mobile-Agent-E research paper outline several crucial avenues for future work. Improving the generation and utilization of Shortcuts is paramount, as current methods sometimes produce erroneous or inapplicable shortcuts. Developing more robust mechanisms for validating shortcut preconditions and revising or discarding faulty shortcuts is essential. A key area for improvement lies in enhancing the personalization of the agent, tailoring its behavior and strategies to individual user preferences and needs. This involves exploring techniques like adaptive learning and user feedback integration to create more customized experiences. Strengthening safety and privacy protocols is also highlighted. The authors acknowledge the potential risks of autonomous decision-making and emphasize the necessity of integrating robust safeguards to prevent unintended actions and protect user data. This could include explicit consent workflows for sensitive actions and mechanisms for detecting and rectifying potentially harmful behavior. Finally, the authors suggest further exploring the interplay between agent capabilities and user interaction, aiming to create a more collaborative and efficient system. This might involve investigations into seamless human-agent interaction methods, improved error handling, and enhanced feedback mechanisms to support more intuitive task management.
More visual insights#
More on tables
| Benchmark | #Tasks |
|
|
|
| |||||||
| Mobile-Eval | 33 | 3 | 10 | 5.55 | 183 | |||||||
| Mobile-Eval-v2 | 44 | 4 | 10 | 5.57 | 245 | |||||||
| AppAgent | 45 | 0 | 9 | 6.31 | 284 | |||||||
| Mobile-Eval-E | 25 | 19 | 15 | 14.56 | 364 |
🔼 This table compares Mobile-Eval-E with other existing mobile device evaluation benchmarks. It highlights key differences in terms of task complexity, the number of apps involved in each task, the average number of operations needed to complete each task, and the total number of operations across all tasks. Mobile-Eval-E is shown to feature significantly more complex tasks involving interactions across multiple applications, requiring substantially more operations than previous benchmarks. This increased complexity better reflects real-world mobile task scenarios.
read the caption
Table 2: Comparison with existing dynamic evaluation benchmarks on real devices. Mobile-Eval-E emphasizes long-horizon, complex tasks that require significantly more operations and a wider variety of apps.
| #Multi-App |
| Tasks |
🔼 This table presents a quantitative comparison of Mobile-Agent-E’s performance against state-of-the-art (SOTA) mobile agent models on the Mobile-Eval-E benchmark. Using GPT-40 as the foundation model for all agents, the table shows the Satisfaction Score (a human-evaluated metric reflecting task completion and user satisfaction), Action Accuracy (the percentage of correctly performed actions), Reflection Accuracy (the percentage of correctly assessed action outcomes, omitted for models lacking an action reflector), and Termination Error rate (the percentage of tasks prematurely ended due to errors). The results demonstrate Mobile-Agent-E’s substantial performance gains over previous SOTA models in all evaluated metrics, highlighting its superior capabilities in long-term planning, decision-making, and error recovery. Furthermore, the table illustrates that incorporating a self-evolution module (Mobile-Agent-E + Evo) leads to even more significant improvements.
read the caption
Table 3: Comparison with state-of-the-art models on the Mobile-Eval-E benchmark, using GPT-4o as the backbone. Mobile-Agent-E outperforms previous SOTA models by a significant margin across all metrics, demonstrating superior long-term planning, decision accuracy, and error recovery. Enabling self-evolution (Mobile-Agent-E + Evo) further enhances performance. Reflection Accuracy for AppAgent and Mobile-Agent-v1 are omitted since they do not have action reflectors.
| #Apps |
🔼 This table presents a comparison of the performance of Mobile-Agent-E using three different large language models (LLMs) as its backbone: GPT-40, Gemini, and Claude. The evaluation metrics used are Satisfaction Score (SS), Action Accuracy (AA), Reflection Accuracy (RA), and Termination Error (TE). Each metric is expressed as a percentage, providing a comprehensive view of the model’s performance across different LLMs. Higher percentages for SS, AA, and RA indicate better performance, while a lower percentage for TE represents fewer errors.
read the caption
Table 4: Results on different large multimodal model backbones, including GPT-4o, Gemini, and Claude. The metrics SS, AA, RA, and TE represent Satisfaction Score, Action Accuracy, Reflection Accuracy, and Termination Error, respectively, expressed as percentages.
| Avg # |
| Ops |
🔼 This table analyzes the computational efficiency of the Mobile-Agent-E model by comparing the time taken for reasoning alone versus the combined time for reasoning and perception. It also shows how frequently Shortcuts (pre-defined sequences of actions) were used. The results demonstrate that using Shortcuts significantly speeds up the model’s inference, making it comparable to previous, less complex models despite the increased sophistication of Mobile-Agent-E.
read the caption
Table 5: Analysis of computational overhead and Shortcut usage. In the inference speed table, the reasoning only section accounts for time spent solely on reasoning agents, while perception + reasoning includes the runtime of the Perceptor on CPU. Shortcut usage statistics are calculated as the ratio of Shortcuts used to the total number of actions performed by the Operator. The use of Shortcuts significantly accelerates inference, achieving comparable times to previous, simpler frameworks.
| Total # |
| Ops |
🔼 This table investigates the unique contribution of evolved Tips to task success, excluding the impact of newly generated Shortcuts. By analyzing a subset of task instances where only evolved Tips were used, the study quantifies the improvement in Satisfaction Score attributable solely to these learned guidelines. The results demonstrate that the evolved Tips significantly enhance task performance even without the benefit of new Shortcuts.
read the caption
Table 6: To investigate the unique impact of Tips, we compute the Satisfaction Score on a subset of instances where no newly generated Shortcuts are used in the trajectory. The results show distinctive benefits from the evolved Tips.
| Model | Type |
|
|
|
| ||||||||
| AppAgent (Zhang et al., 2023) | Single-Agent | 25.2 | 60.7 | - | 96.0 | ||||||||
| Mobile-Agent-v1 (Wang et al., 2024b) | Single-Agent | 45.5 | 69.8 | - | 68.0 | ||||||||
| Mobile-Agent-v2 (Wang et al., 2024a) | Multi-Agent | 53.0 | 73.2 | 96.7 | 52.0 | ||||||||
| Mobile-Agent-E | Multi-Agent | 75.1 | 85.9 | 97.4 | 32.0 | ||||||||
| Mobile-Agent-E + Evo | Multi-Agent | 86.9 | 90.4 | 97.8 | 12.0 |
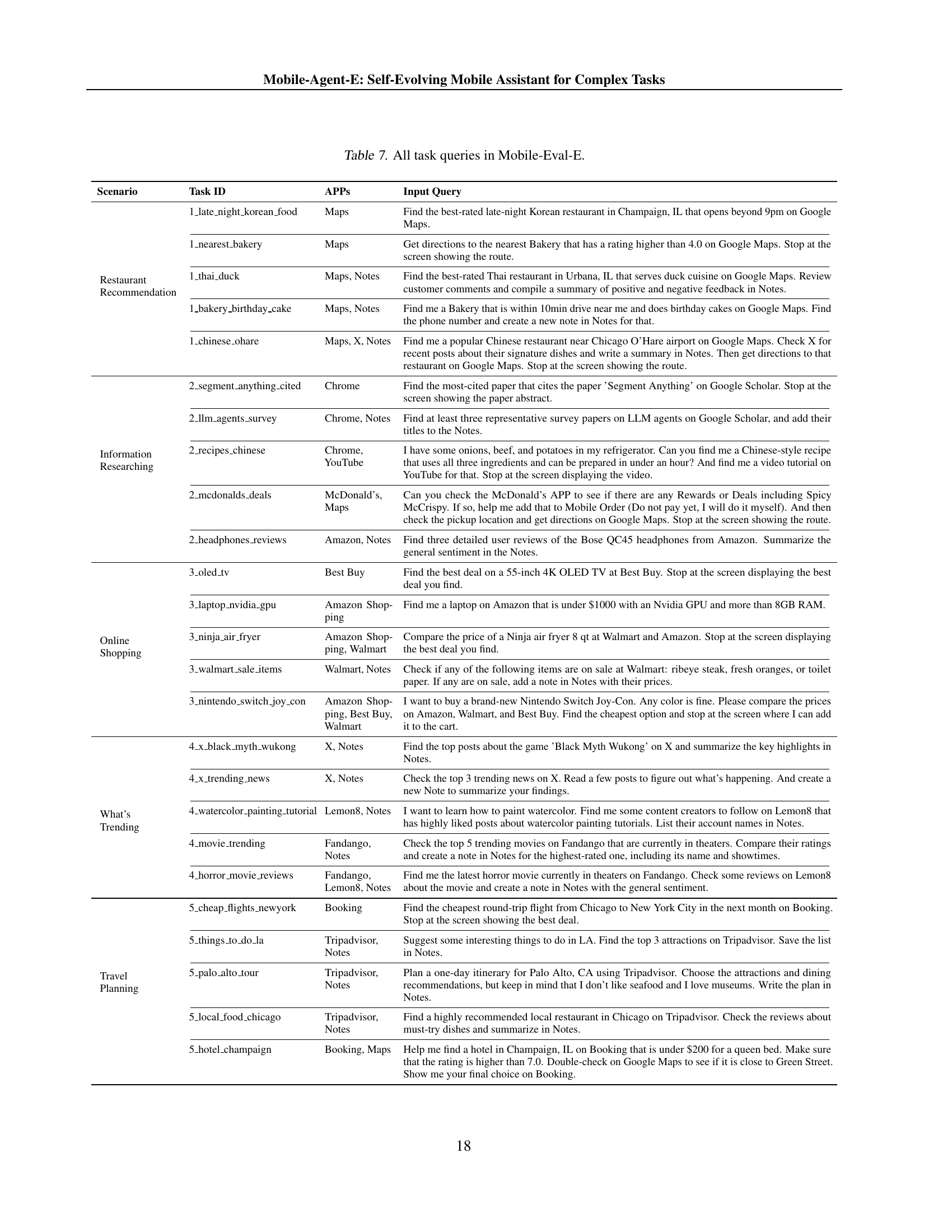
🔼 This table lists all 25 tasks included in the Mobile-Eval-E benchmark dataset. For each task, it provides the task ID, the apps involved in completing the task, the input query given to the agent, and the scenario to which the task belongs. The scenarios represent different real-world task categories, such as restaurant recommendations, online shopping, and travel planning. The table is designed to show the complexity of tasks in Mobile-Eval-E, highlighting the multi-app and reasoning aspects frequently encountered in everyday mobile use.
read the caption
Table 7: All task queries in Mobile-Eval-E.
| Satisfaction Score |
| (%) |
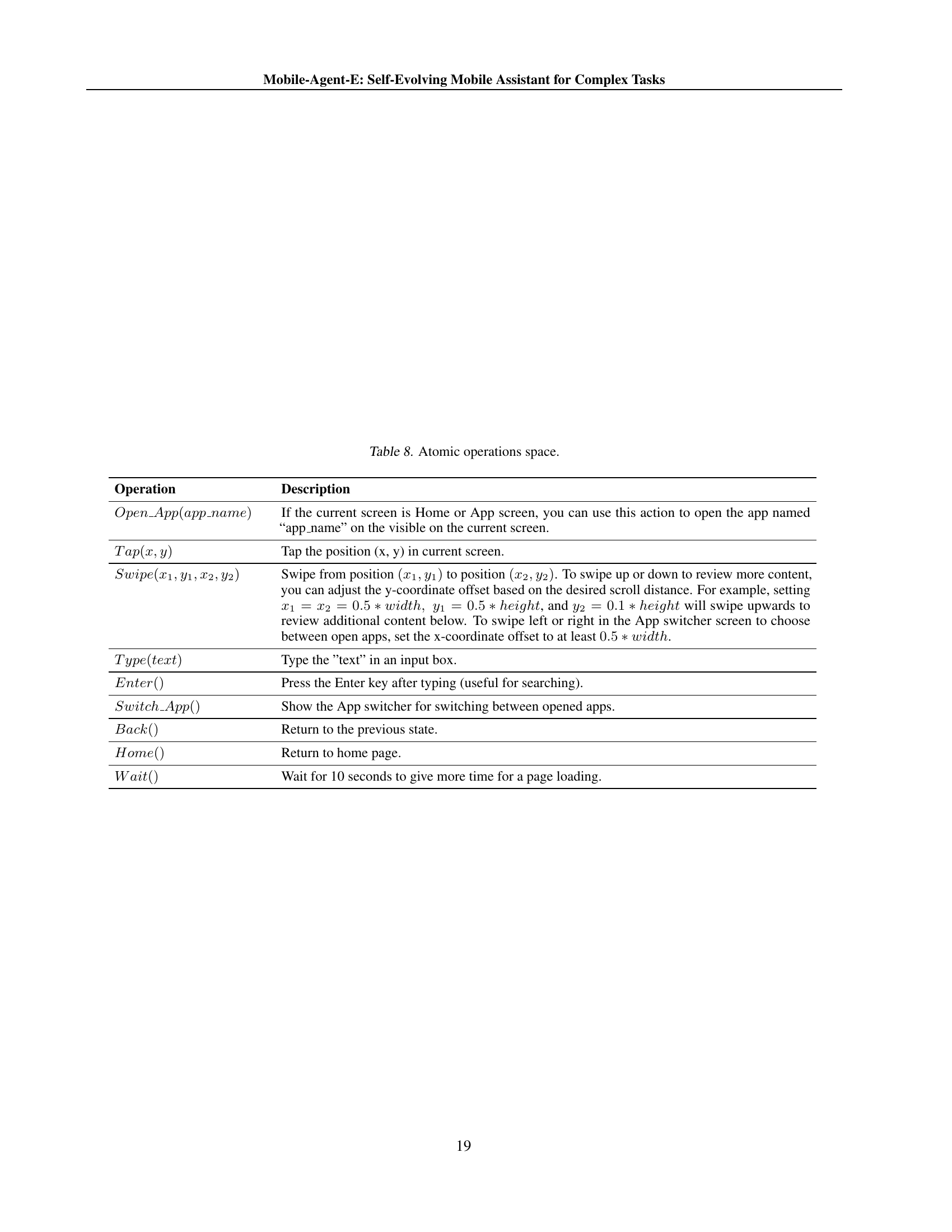
🔼 This table lists the atomic operations used by the Mobile-Agent-E system. These are the fundamental actions the system can perform, such as tapping on the screen, swiping, typing text, etc. These atomic operations are combined to create more complex actions and sequences, allowing Mobile-Agent-E to interact with mobile applications.
read the caption
Table 8: Atomic operations space.
Full paper#