TL;DR#
Generating high-quality 3D assets remains a challenge due to the complexity and time involved in traditional methods. Current automated approaches often struggle with creating high-resolution models with detailed textures and proper alignment to given conditions. There is a need for an efficient and accessible system that addresses these issues.
Hunyuan3D 2.0 directly tackles this by introducing a two-stage generation pipeline. First, a large-scale shape generation model (Hunyuan3D-DiT) creates high-fidelity meshes aligned with condition images. Then, a texture synthesis model (Hunyuan3D-Paint) generates vibrant, high-resolution texture maps for these meshes. The whole process is made easily accessible through a user-friendly platform, Hunyuan3D-Studio, enabling creation and manipulation of 3D assets efficiently. Evaluations demonstrate that Hunyuan3D 2.0 outperforms existing methods, significantly improving geometry details, condition alignment, and texture quality. The system is publicly released to promote open-source contributions to the field.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Hunyuan3D 2.0, a novel large-scale 3D asset generation system that outperforms existing models in geometry detail, condition alignment, and texture quality. Its open-source nature democratizes access to advanced 3D generation capabilities, fostering collaboration and innovation within the research community. The work also presents a versatile production platform, Hunyuan3D-Studio, significantly simplifying the 3D asset creation process for both professionals and amateurs. This opens up exciting new avenues for research in various areas, including game development, animation, virtual reality, and AI applications.
Visual Insights#

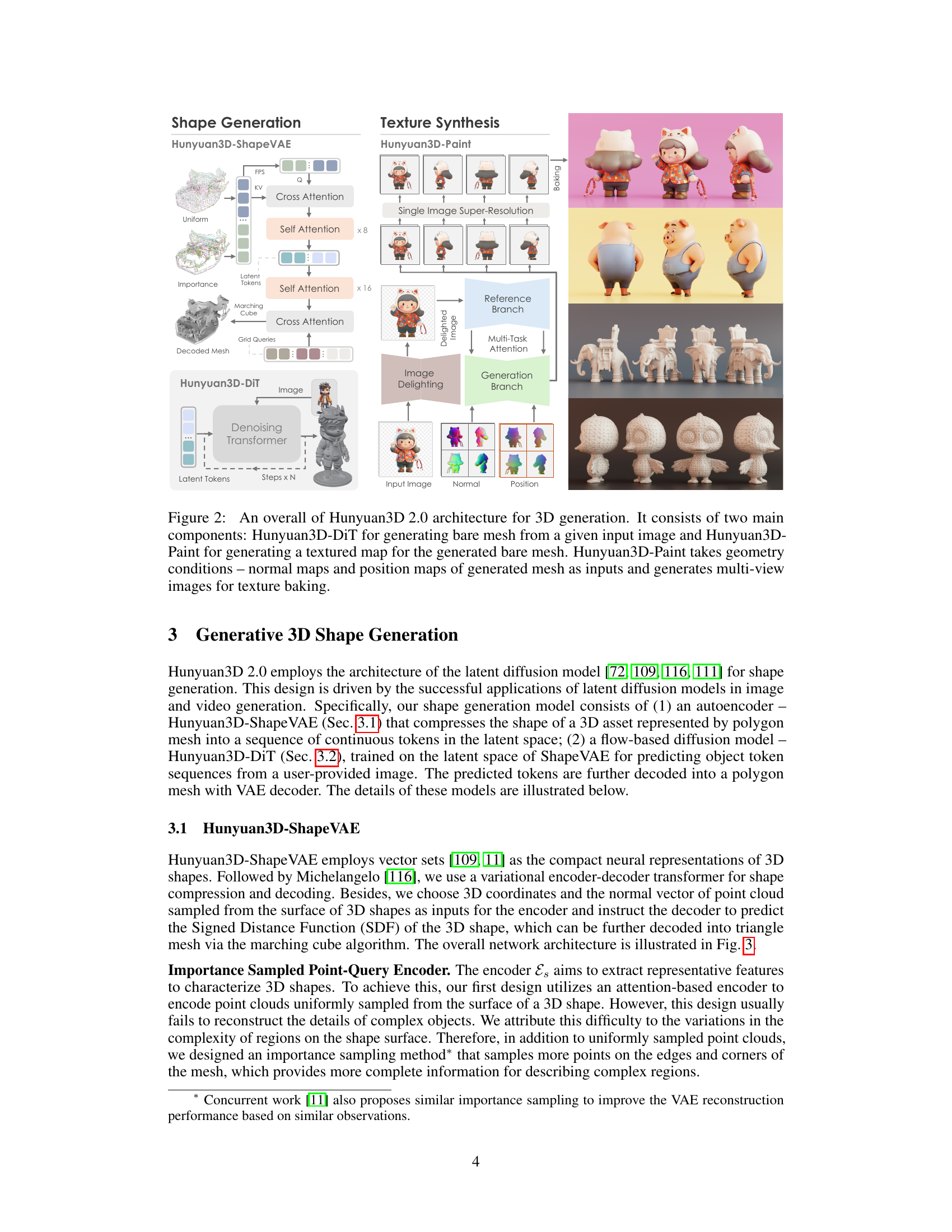
🔼 This figure provides a high-level overview of the Hunyuan3D 2.0 system architecture. It shows the three main components: Hunyuan3D-DiT (for generating the 3D mesh), Hunyuan3D-Paint (for generating the textures), and Hunyuan3D-Studio (a user-friendly platform that integrates the mesh and texture generation components for easier 3D asset creation and manipulation). Examples of generated outputs from each component are visually displayed to showcase the system’s capabilities in creating realistic and detailed 3D assets.
read the caption
Figure 1: An overall of Hunyuan3D 2.0 system.
| 3DShape2VecSet [109] | Michelangelo [116] | Direct3D [96] | Hunyuan3D-ShapeVAE (Ours) | |
|---|---|---|---|---|
| V-IoU() | 87.88% | 84.93% | 88.43% | 93.6% |
| S-IoU() | 80.66% | 76.27% | 81.55% | 89.16% |
🔼 This table presents a quantitative comparison of the 3D shape reconstruction performance of the Hunyuan3D-ShapeVAE model against several baseline methods. The comparison uses two key metrics: Volume Intersection over Union (V-IoU) and Surface Intersection over Union (S-IoU). Higher values for both metrics indicate better reconstruction accuracy. The results demonstrate that Hunyuan3D-ShapeVAE significantly outperforms all the other methods.
read the caption
Table 1: Numerical comparisons. We evaluate the reconstruction performance of Hunyuan3D-ShapeVAE and baselines based on volume IoU (V-IoU) and Surface (S-IoU). The results indicate Hunyuan3D-ShapeVAE overwhelms all baselines in the reconstruction performance.
In-depth insights#
Scaling 3D Diffusion#
Scaling 3D diffusion models presents exciting opportunities and significant challenges. Increased scale, through larger datasets and model parameters, is crucial for improving the quality and detail of generated 3D assets, enabling higher resolutions and more intricate geometries. However, computational costs rise dramatically with scale, demanding efficient architectures and training strategies. Memory limitations become a bottleneck, requiring techniques like efficient latent representations and optimized data handling. Furthermore, evaluation metrics for assessing the quality of high-resolution 3D models need refinement to capture subtle details and overall fidelity effectively. Addressing these challenges will likely involve exploring novel architectures like efficient transformers, developing advanced sampling methods for faster generation, and creating more robust evaluation metrics that reflect human perception of 3D asset quality. Open-source initiatives are vital to encourage collaboration and accelerate the development of scalable 3D diffusion, ensuring wider accessibility and fostering rapid advancements in the field. Data augmentation strategies and careful consideration of dataset bias will play key roles in the success of scaled 3D diffusion.
Hunyuan3D Architecture#
The Hunyuan3D architecture is a two-stage pipeline designed for high-resolution textured 3D asset generation. The initial stage focuses on shape generation, utilizing a large-scale flow-based diffusion model (Hunyuan3D-DiT) built upon a ShapeVAE autoencoder. This autoencoder leverages importance sampling to capture detailed mesh information, efficiently compressing 3D shapes into latent tokens. These tokens are then processed by Hunyuan3D-DiT to generate a bare mesh aligning with a given condition image. The second stage involves texture synthesis, employing Hunyuan3D-Paint. This model uses a novel mesh-conditioned multi-view generation pipeline, pre-processing input images and generating multi-view images to create a high-resolution texture map. Multi-view consistency is ensured via multi-task attention mechanisms. The entire system is designed to be versatile and user-friendly, facilitating manipulation and animation of 3D assets through a platform called Hunyuan3D-Studio. The architecture cleverly decouples shape and texture generation, offering flexibility in handling both generated and handcrafted meshes, ultimately producing high-quality results.
Multi-view Synthesis#
Multi-view synthesis in 3D generation aims to create a consistent and realistic representation of an object from multiple viewpoints. The core challenge lies in generating views that align geometrically and photometrically, avoiding inconsistencies such as self-occlusions or lighting artifacts. Successful multi-view synthesis requires sophisticated models that understand spatial relationships and lighting conditions. The integration of techniques like geometry-aware viewpoint selection, image delighting (removing lighting effects to improve consistency), and robust multi-task attention mechanisms are crucial for producing high-quality multi-view outputs. These advancements allow for efficient texture baking and the creation of high-fidelity textured 3D assets. Ultimately, high-quality multi-view synthesis is fundamental to creating realistic and usable 3D models for applications such as gaming, animation, and virtual reality. Addressing the self-occlusion problem, improving the consistency of lighting and shadows, and enabling the generation of textures from limited views are ongoing research areas in this field.
Hunyuan3D Studio#
The heading ‘Hunyuan3D Studio’ suggests a user-friendly platform built around the Hunyuan3D 2.0 system. It’s likely a comprehensive suite of tools aimed at simplifying the 3D asset creation process, bridging the gap between professionals and novice users. Key features highlighted in the paper likely include Sketch-to-3D capabilities, enabling users to convert 2D sketches into realistic 3D models. This suggests an intuitive workflow involving image processing techniques. Another important feature is Low-polygon Stylization, which would optimize meshes for reduced computational costs and enhanced efficiency in various applications. This capability is crucial for streamlining the development pipeline and making the creation of high-quality 3D assets more accessible. Finally, the mention of Autonomous Character Animation points towards the inclusion of tools for creating animated 3D characters, streamlining the workflow and expanding the possibilities of the platform. Overall, Hunyuan3D Studio appears to be designed to promote ease of use and broad accessibility within the 3D asset creation domain, fostering creativity and innovation across different skill levels.
Future of 3D Gen#
The future of 3D generation hinges on several key advancements. Improved model scalability will be crucial, allowing for the creation of increasingly complex and detailed 3D assets with higher resolution and fidelity. This requires both more powerful hardware and more efficient model architectures. Enhanced data diversity and quality are equally essential; current datasets are limited in size and variety, hindering model generalization and the creation of truly realistic 3D objects. Therefore, expanding dataset size and incorporating diverse real-world data will unlock new possibilities. Seamless integration of different modalities is paramount, allowing users to generate 3D models from diverse inputs, such as text, images, and sketches. Methods that smoothly merge and align these different modalities will improve user experience and broaden applications. Advanced control and editing capabilities are also essential for practical use. Users should have intuitive tools for manipulating generated 3D models, customizing textures, and animating scenes. Finally, focus on ethical considerations such as bias mitigation and responsible use of generative models in 3D asset creation will ensure its long-term positive impact. Addressing these challenges will enable the creation of innovative tools, accelerate adoption, and unlock exciting possibilities in various industries.
More visual insights#
More on figures

🔼 Hunyuan3D 2.0 is a two-stage 3D generation system. First, Hunyuan3D-DiT, a diffusion model, creates a 3D mesh from an input image. Then, Hunyuan3D-Paint, another diffusion model, generates a texture map. Hunyuan3D-Paint uses the normal and position maps from the generated mesh to create multi-view images, which are then baked into a final texture.
read the caption
Figure 2: An overall of Hunyuan3D 2.0 architecture for 3D generation. It consists of two main components: Hunyuan3D-DiT for generating bare mesh from a given input image and Hunyuan3D-Paint for generating a textured map for the generated bare mesh. Hunyuan3D-Paint takes geometry conditions – normal maps and position maps of generated mesh as inputs and generates multi-view images for texture baking.

🔼 Hunyuan3D-ShapeVAE is an autoencoder that converts a 3D mesh into a sequence of tokens, which are then used by the diffusion model to generate new meshes. The architecture uses an encoder that incorporates both uniform and importance sampling of the input mesh’s point cloud. Importance sampling focuses on high-frequency details like edges and corners, providing more information for representing complex shapes and enhancing reconstruction accuracy. The encoder then uses cross-attention to create a set of tokens. The decoder reconstructs the 3D mesh from these tokens via a marching cubes algorithm. Farthest Point Sampling (FPS) is used separately on both the uniform and importance sampled point clouds during point query construction. This two-pronged sampling approach is crucial to capturing the full spectrum of details in the input 3D mesh.
read the caption
Figure 3: The overall architecture of Hunyuan3D-ShapeVAE. Instead of only using uniform sampling on mesh surface, We have developed an importance sampling strategy to extract high-frequency detail information from the input mesh surface, such as edges and corners. This allows the model to better capture and represent the intricate details of 3D shapes. Note that during the point query construction, the Farthest Point Sampling (FPS) operation is performed separately for the uniform point cloud and the importance sampling point cloud.

🔼 Hunyuan3D-DiT uses a transformer architecture with double- and single-stream blocks to process latent tokens (shape information) and condition tokens (image information). The double-stream blocks allow interaction between the shape and image modalities, improving mesh generation quality. Single-stream blocks process the information separately before combining them. Orange blocks are non-trainable, blue blocks are trainable, and gray blocks represent modules containing additional details not shown in the main diagram. This architecture allows the model to generate high-fidelity bare meshes from input image prompts.
read the caption
Figure 4: Overview of Hunyuan3D-DiT. It adopts a transformer architecture with both double- and single-stream blocks. This design benefits the interaction between modalities of shape and image, helping our model to generate bare meshes with exceptional quality. (Note that the orange blocks have no learnable parameters, the blue blocks contain trainable parameters, and the gray blocks indicate a module composed of more details.)

🔼 Hunyuan3D-Paint uses a three-stage pipeline. First, an image delighting module converts the input image into a light-invariant representation. Second, a double-stream image conditioning reference-net feeds conditional image features to the model. This network is designed to produce texture maps closely matching the input image. Finally, a multi-task attention module ensures that the generated images are multi-view consistent, maintaining coherence and alignment with the input across all viewpoints.
read the caption
Figure 5: Overview of Hunyuan3D-Paint. We leverage an image delighting module to convert the input image to an unlit state to produce light-invariant texture maps. The system features a double-stream image conditioning reference-net, which provides faithfully conditional image features to the model. Furthermore, it facilitates the production of texture maps that conform closely to the input image. The multi-task attention module ensures that the model synthesizes multi-view consistent images. This module maintains the coherence of all generated images while adhering to the input.

🔼 This figure presents a visual comparison of 3D mesh reconstruction results between Hunyuan3D-ShapeVAE and other methods (Michelangelo, 3DShape2VecSet, Direct3D). Each row shows the ground truth mesh and the reconstruction attempts by the various models for the same object. The visualization highlights that Hunyuan3D-ShapeVAE excels at reconstructing meshes with more fine-grained surface details and cleaner geometry, lacking the artifacts or omissions seen in the other models’ outputs.
read the caption
Figure 6: Visual comparisons. We illustrate the reconstructed mesh (blue paint aims to show more details) in the figure, which showcases that only Hunyuan3D-ShapeVAE reconstructs mesh with fine-grained surface details and neat space. (Better viewed by zooming in.)

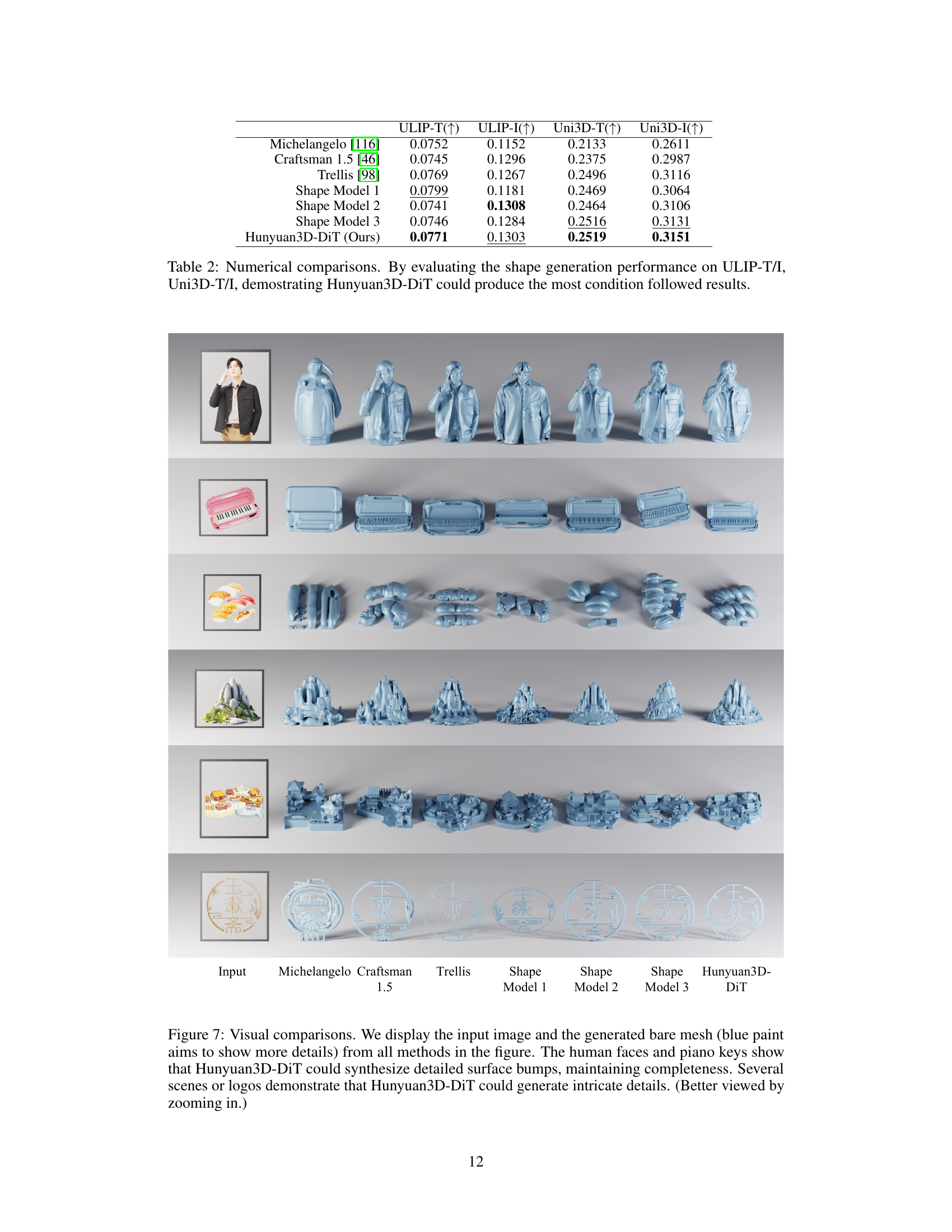
🔼 Figure 7 presents a visual comparison of 3D shape generation results from various methods, including Hunyuan3D-DiT and several baselines. For each example, the input image and the generated bare mesh (highlighted with blue paint to emphasize details) are shown. The results for Hunyuan3D-DiT showcase the model’s ability to accurately reproduce fine surface details, such as the textures of human faces and piano keys, while maintaining the overall completeness of the generated shape. In addition, the figure displays several objects with complex details and intricate features, further illustrating Hunyuan3D-DiT’s ability to create high-fidelity 3D assets from diverse image prompts.
read the caption
Figure 7: Visual comparisons. We display the input image and the generated bare mesh (blue paint aims to show more details) from all methods in the figure. The human faces and piano keys show that Hunyuan3D-DiT could synthesize detailed surface bumps, maintaining completeness. Several scenes or logos demonstrate that Hunyuan3D-DiT could generate intricate details. (Better viewed by zooming in.)

🔼 Figure 8 presents a visual comparison of texture maps generated by Hunyuan3D-Paint and other methods on various 3D models (fish, rabbit, soccer ball, castle, bear). The results highlight Hunyuan3D-Paint’s superior performance in generating text-conforming texture maps that are both seamless and detailed. The fish and rabbit examples particularly demonstrate the model’s ability to closely match the textual description, while the football showcases its ability to produce clean and seamless textures. The castle and bear further illustrate the model’s capability to handle complex textures.
read the caption
Figure 8: Visual comparisons. We demonstrate several generated texture maps on different bare meshes. The fish and rabbit texture map showcases that Hunyuan3D-Paint produces the most text-conforming results. The football indicates that our model could synthesize seamless and clean texture maps. Moreover, Hunyuan3D-Paint could generate complex texture maps, like the castle and bear. (Better viewed by zooming in.)

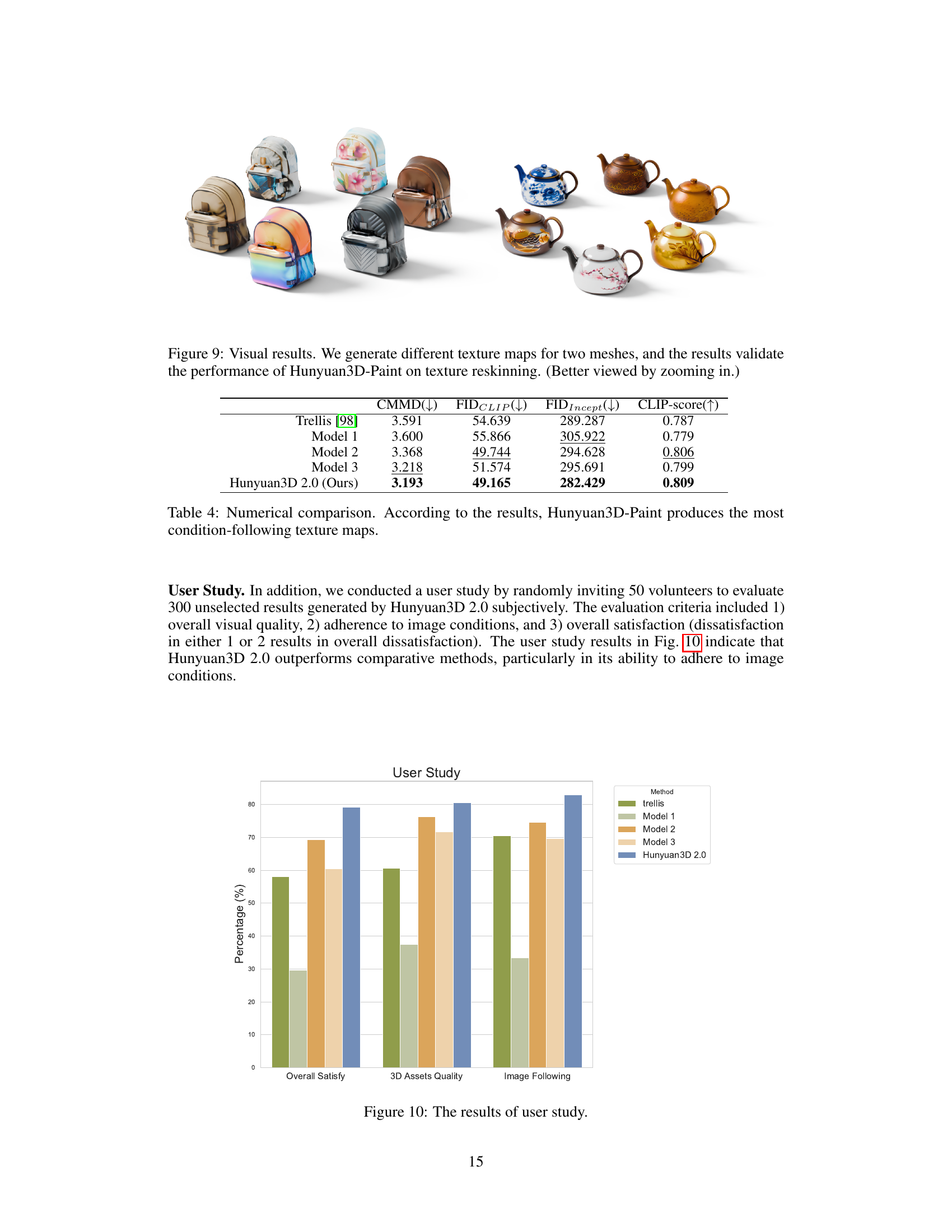
🔼 This figure displays the results of applying the Hunyuan3D-Paint model to generate different textures for the same 3D model. Two example 3D models (a backpack and a teapot) are shown, each rendered with multiple distinct textures. This showcases the model’s ability to perform texture reskinning – changing the surface texture of a model without modifying its geometry. The various textures demonstrate the diverse range of results achievable by the model in response to different inputs or conditions.
read the caption
Figure 9: Visual results. We generate different texture maps for two meshes, and the results validate the performance of Hunyuan3D-Paint on texture reskinning. (Better viewed by zooming in.)

🔼 The figure presents a bar chart summarizing the results of a user study comparing Hunyuan3D 2.0 to several other methods across three criteria: overall user satisfaction, 3D asset quality, and adherence to image conditions. Each bar represents the average percentage score for a given metric and method. This allows for a direct visual comparison of the different models’ performance from a user perspective.
read the caption
Figure 10: The results of user study.

🔼 Figure 11 presents a visual comparison of 3D model generation results from Hunyuan3D 2.0 and other methods. The top row shows penguins, highlighting the ability of Hunyuan3D 2.0 to generate realistic surface details and textures. The middle row features a small animated character, showcasing the system’s capacity to produce models capable of complex poses. The bottom row depicts mountain ranges, illustrating the generation of intricate details in geometry and textures by Hunyuan3D-DiT and Hunyuan3D-Paint.
read the caption
Figure 11: Visual comparisons. The first case reflects that Hunyuan3D 2.0 could synthesize detailed surface bumps and correct texture maps. The second penguin showcases our model’s ability to handle complex actions. The last mountain demonstrates that Hunyuan3D-DiT could produce intricate structures, and Hunyuan3D-Paint can synthesize vivid texture maps. (Better viewed by zooming in.)
More on tables
| ULIP-T() | ULIP-I() | Uni3D-T() | Uni3D-I() | |
|---|---|---|---|---|
| Michelangelo [116] | 0.0752 | 0.1152 | 0.2133 | 0.2611 |
| Craftsman 1.5 [46] | 0.0745 | 0.1296 | 0.2375 | 0.2987 |
| Trellis [98] | 0.0769 | 0.1267 | 0.2496 | 0.3116 |
| Shape Model 1 | 0.0799 | 0.1181 | 0.2469 | 0.3064 |
| Shape Model 2 | 0.0741 | 0.1308 | 0.2464 | 0.3106 |
| Shape Model 3 | 0.0746 | 0.1284 | 0.2516 | 0.3131 |
| Hunyuan3D-DiT (Ours) | 0.0771 | 0.1303 | 0.2519 | 0.3151 |
🔼 This table presents a quantitative comparison of the shape generation capabilities of Hunyuan3D-DiT against several state-of-the-art baselines. The comparison uses two metrics, ULIP-T/I and Uni3D-T/I, which evaluate the similarity between generated shapes and both textual and image-based conditions. Higher scores indicate better alignment between the generated shape and the given conditions, reflecting improved generation quality. The results demonstrate that Hunyuan3D-DiT outperforms other models in this regard, accurately generating shapes that closely match the specified input conditions.
read the caption
Table 2: Numerical comparisons. By evaluating the shape generation performance on ULIP-T/I, Uni3D-T/I, demostrating Hunyuan3D-DiT could produce the most condition followed results.
| CMMD() | FIDCLIP() | CLIP-score() | LPIPS() | |
|---|---|---|---|---|
| TEXTure [71] | 3.047 | 35.75 | 0.8499 | 0.0076 |
| Text2Tex [9] | 2.811 | 31.72 | 0.8680 | 0.0071 |
| SyncMVD [56] | 2.584 | 29.93 | 0.8751 | 0.0063 |
| Paint3D [108] | 2.810 | 30.29 | 0.8724 | 0.0063 |
| TexPainter [110] | 2.483 | 28.83 | 0.8789 | 0.0062 |
| Hunyuan3D-Paint (Ours) | 2.318 | 26.44 | 0.8893 | 0.0059 |
🔼 This table presents a quantitative comparison of Hunyuan3D-Paint against several state-of-the-art texture generation methods. The comparison uses multiple metrics to evaluate the quality of the generated texture maps, focusing on how well the generated textures conform to the input conditions (e.g., text or image prompts). Lower values for CMMD and FIDCLIP, and higher values for CLIP-score indicate better performance. The results demonstrate that Hunyuan3D-Paint surpasses the baselines, producing texture maps that exhibit the highest degree of condition conformance.
read the caption
Table 3: Numerical comparisons. We compare Hunyuan3D-Paint with baselines on various metrics, and the results indicate that our model could produce the most condition-conforming texture maps.
| CMMD() | FIDCLIP() | FIDIncept() | CLIP-score() | |
|---|---|---|---|---|
| Trellis [98] | 3.591 | 54.639 | 289.287 | 0.787 |
| Model 1 | 3.600 | 55.866 | 305.922 | 0.779 |
| Model 2 | 3.368 | 49.744 | 294.628 | 0.806 |
| Model 3 | 3.218 | 51.574 | 295.691 | 0.799 |
| Hunyuan3D 2.0 (Ours) | 3.193 | 49.165 | 282.429 | 0.809 |
🔼 This table presents a quantitative comparison of Hunyuan3D-Paint against other state-of-the-art texture generation methods. The comparison uses four metrics: CMMD (CLIP Maximum-Mean Discrepancy), FIDCLIP (a CLIP-version of Fréchet Inception Distance), FIDIncept (Fréchet Inception Distance), and CLIP-score. Lower values for CMMD and FIDCLIP indicate better performance, while higher values for FIDIncept and CLIP-score indicate better performance. The results show that Hunyuan3D-Paint outperforms the other methods in terms of generating texture maps that closely adhere to the input conditions.
read the caption
Table 4: Numerical comparison. According to the results, Hunyuan3D-Paint produces the most condition-following texture maps.
Full paper#