TL;DR#
Current methods for generating personalized images struggle with handling multiple concepts and composing them flexibly from various sources. They often require segmentation masks or bounding boxes, and struggle to disentangle multiple concepts within a single image, limiting their versatility. Existing approaches either fine-tune the model, limiting seamless concept integration, or optimize the input text embedding, lacking the expressiveness to fully capture the nuances of concepts.
TokenVerse overcomes these issues using an optimization-based framework applied to a pre-trained text-to-image diffusion model. It disentangles visual concepts from images using only accompanying captions. The method utilizes the modulation space of the model to learn personalized representations for text tokens which can then be flexibly incorporated into new prompts to generate images with creative compositions of multiple concepts. Experiments show improved results over existing techniques in image personalization and composition tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents TokenVerse, a novel framework for multi-concept personalization in image generation. It addresses limitations of existing methods by enabling flexible combination of concepts from multiple images without requiring masks or additional supervision. This opens avenues for creative content generation and diverse applications. The work is highly relevant to the current research trends in text-to-image generation, particularly in addressing controllability and disentanglement issues. The proposed method and insights into token modulation space will impact the work of researchers in computer vision and AI.
Visual Insights#

🔼 TokenVerse is a novel framework that enables multi-concept image generation with personalized attributes extracted from multiple source images. The top row shows example source images, each containing various visual concepts (e.g., objects, attributes, poses, lighting). TokenVerse independently processes each source image and its caption to learn a disentangled representation for each concept, without needing masks or other supervision. It achieves this by learning a unique embedding for each word in the caption. Then, these personalized text tokens (shown in color in the caption below the generated images) are combined flexibly to create new and diverse images (bottom row) that express combinations of learned concepts.
read the caption
Figure 1: TokenVerse extracts distinct complex visual concepts from a set of concept images (top), and allows users to generate images that depict these concepts in novel versatile compositions (bottom row). Our framework independently processes each concept image, and learns to disentangle its concepts based solely on an accompanying caption, without any additional supervision or masks. This is achieved by learning a personalized representation for each token in the source caption. Our personalized text tokens, extracted from multiple images, are then flexibly incorporated into new text prompts (colored words) to generate novel creative images.
| Concept | Concept | masks | |
|---|---|---|---|
| Method | Decomposition | Composition | free |
| DB LoRA | |||
| Break-A-Scene | |||
| ConceptExpress | |||
| OMG | |||
| TokenVerse (Ours) |
🔼 Table 1 compares the capabilities of five different methods for generating images with personalized concepts: DreamBooth, Break-a-Scene, ConceptExpress, OMG, and the authors’ proposed method (TokenVerse). The table focuses on two key aspects: concept decomposition (extracting and personalizing multiple distinct concepts from a single image) and concept composition (combining concepts learned from multiple images to generate new images). The comparison highlights the unique advantage of TokenVerse in performing both tasks without requiring segmentation masks, unlike previous methods which often need masks or other visual cues for concept isolation.
read the caption
Table 1: Capabilities of competing baselines. The table lists the capabilities of DreamBooth [32], BAS [8], ConceptExpress [14], OMG [23] and our method. Concept decomposition is the task of disentangling and personalizing multiple objects from a single image. Composition is the task of combining separately learned concepts in a new generated image. Unlike existing approaches, our method enables mask-free multi-object disentangled personalization, as well as the composition of multiple objects from several reference images.
In-depth insights#
TokenVerse: A Novel Method#
TokenVerse presents a novel approach to multi-concept personalization in image generation. Its core innovation lies in leveraging the modulation space of diffusion transformers (DiTs) for disentangling and composing visual concepts. Unlike methods relying on fine-tuning or explicit masking, TokenVerse extracts concept representations directly from image-caption pairs through an optimization process. This allows for unsupervised disentanglement of multiple concepts within a single image, even complex ones involving objects, accessories, poses, and lighting. The method’s strength is its modularity, enabling the seamless combination of concepts extracted from various images, creating novel and coherent compositions without user-provided segmentation. This plug-and-play approach significantly broadens the scope of personalized image generation. By focusing on the per-token modulation space (M+), TokenVerse achieves highly localized control, avoiding unwanted side effects often seen in global modulation. The framework’s efficiency and versatility are demonstrated through both quantitative and qualitative evaluations, showing superior performance over existing techniques in multi-concept personalization and composition tasks. The method’s ability to handle a wide range of concepts with minimal supervision positions it as a significant advancement in the field of AI-based image generation, opening avenues for creative applications such as storytelling and personalized content creation.
Multi-Concept Personalization#
Multi-concept personalization, as a research area, presents a significant challenge and opportunity in AI. It tackles the problem of generating images that seamlessly integrate multiple distinct concepts extracted from various sources, such as different images or text descriptions. This surpasses the limitations of single-concept personalization which struggles with complex scene generation. The core difficulty lies in disentangling individual concepts and learning their personalized representations in a way that allows for flexible composition. Unsupervised methods, which learn solely from image-caption pairs without requiring additional supervision like segmentation masks, are particularly valuable because they are more scalable and adaptable to various concepts. Successfully addressing multi-concept personalization requires novel approaches to representation learning that capture intricate relationships between concepts, and generation methods capable of fine-grained control over these relationships to achieve coherent and creative output. The ability to combine concepts extracted from diverse sources offers exciting possibilities for content creation and various other applications.
Modulation Space Control#
The concept of ‘Modulation Space Control’ in the context of generative models, particularly diffusion models, is a powerful technique for achieving fine-grained control over image generation. It leverages the model’s internal representation, specifically the modulation space, to directly manipulate the generated image’s features. Unlike traditional methods that rely on modifying text prompts or fine-tuning model weights, modulation space control offers a more direct and localized approach. By identifying specific directions within this space, corresponding to semantic attributes like object characteristics, poses, or lighting, one can selectively enhance or suppress these features in the generated image. This allows for a level of personalization and customization not readily available through other methods. The key advantage lies in its disentanglement capabilities, enabling independent control over multiple concepts within a single image. This disentanglement facilitates the creation of novel image compositions by combining different attributes extracted from multiple source images. However, the success of this technique hinges on the quality of the learned directions, requiring careful optimization to prevent interference or unwanted modifications to other features. Further research into efficient and robust methods for learning these directions, as well as a deeper understanding of the underlying semantic structure of the modulation space, is crucial for unlocking the full potential of this promising approach.
Disentangled Concept Learning#
The concept of ‘Disentangled Concept Learning’ within the context of a text-to-image model centers on the ability to isolate and independently manipulate individual visual elements within a generated image. Instead of treating an image as a monolithic entity, this approach seeks to parse it into constituent components such as objects, textures, poses, and lighting. The goal is to learn separate, disentangled representations for each concept, enabling flexible recombination and personalization. This disentanglement allows for granular control; the user can selectively modify certain aspects of an image without affecting others, which is a significant improvement over previous methods that frequently struggled with holistic image manipulation. Successful disentangled learning facilitates plug-and-play composition, where concepts extracted from diverse source images can be seamlessly integrated into novel compositions. This modular approach opens possibilities for creative image generation and personalized content creation exceeding the capabilities of previous techniques that primarily focused on single-concept manipulation or required explicit image segmentation.
Future Research Directions#
Future research could explore several promising avenues. Improving the disentanglement of concepts within the modulation space is crucial; the current method sometimes struggles with highly similar concepts or those sharing name identifiers, leading to blending or unpredictable results. Developing more robust methods for handling incompatible concepts would significantly enhance the versatility of the model. Currently, attempting complex combinations can produce unexpected outputs. Investigating the potential of incorporating external knowledge graphs or semantic relationships could further improve concept understanding and combination. This would allow the model to reason about concepts in a more sophisticated way, generating even more creative and coherent results. Exploring different model architectures beyond Diffusion Transformers could reveal novel approaches to achieve improved disentanglement and compositional flexibility. Furthermore, the method’s effectiveness with diverse data types and image modalities should be investigated, expanding beyond natural images to encompass, for example, 3D models, videos, or other visual formats. Finally, a deeper understanding of the underlying mechanisms of the modulation space and its relationship to semantic meaning would open new possibilities for enhanced user control and concept manipulation.
More visual insights#
More on figures

🔼 Figure 2 illustrates the effect of modifying the modulation vector in the global modulation space (ℳ) and the per-token modulation space (ℳ+). The top row shows a generated image. Part (a) demonstrates modifying the global modulation vector to change concepts in the image. This often causes unintended changes to other concepts. Part (b) shows how modifying the modulation vector for only a single token (e.g., ‘dog’) results in localized changes that primarily affect the selected concept. This localized control is key to the proposed approach for multi-concept personalization.
read the caption
Figure 2: Directions in the global modulation space (ℳℳ\mathcal{M}caligraphic_M) and our per-token modulation space (ℳ+superscriptℳ\mathcal{M}^{+}caligraphic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT). Given a generated image (top row), we modify it using text-driven directions in both ℳℳ\mathcal{M}caligraphic_M and ℳ+superscriptℳ\mathcal{M}^{+}caligraphic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT spaces. (a) Adding a direction to the vector that is used to modulate all the text and image tokens (i.e. a direction in the space ℳℳ\mathcal{M}caligraphic_M) can be used to effectively modify desired concepts in the generated image. Yet, this often results in non-local changes that also affect other concepts in the generated image. (b) Adding a direction only to the modulation vector of a specific text token, like “dog” or “ball” (i.e. a direction in the space ℳ+superscriptℳ\mathcal{M}^{+}caligraphic_M start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT) leads to a localized modification that mostly affects the concept of interest.

🔼 This figure provides a detailed overview of the TokenVerse framework. Panel (a) illustrates the architecture of a pre-trained text-to-image diffusion transformer (DiT) model, highlighting the modulation, attention, and feed-forward modules within each DiT block. The modulation block’s function of modulating tokens using a vector derived from a pooled text embedding is emphasized. Panel (b) depicts the training process of TokenVerse. It shows how, given a concept image and its caption, personalized modulation vector offsets are learned for each text token. These offsets represent unique directions within the modulation space, learned through a reconstruction objective. Panel (c) demonstrates the inference stage. It explains how the pre-learned direction vectors are applied to modulate text tokens during image generation, enabling the incorporation of personalized concepts into the resulting images.
read the caption
Figure 3: TokenVerse overview. (a) A pre-trained text-to-image DiT model processes both image and text tokens via a series of DiT blocks. Each block consists of modulation, attention and feed-forward modules. We focus on the modulation block, in which the tokens are modulated via a vector y𝑦yitalic_y, which is derived from a pooled text embedding. (b) Given a concept image and its corresponding caption, TokenVerse learns a personalized modulation vector offset ΔΔ\Deltaroman_Δ for each text token. These offsets represent personalized directions in the modulation space and are learned using a simple reconstruction objective. (c) At inference, the pre-learned direction vectors are used to modulate the text tokens, enabling the injection of personalized concepts into the generated images.

🔼 This figure illustrates the concept isolation loss used in training the Concept-Mod model. During training, the model is presented with a concept image and its caption in 50% of the training steps. In addition, the model is presented with a second image and its caption that is unrelated to the concept image. The goal is for the model to learn directions in the modulation space that only modify the portions of the generated image corresponding to the concept image, leaving the unrelated image mostly unaffected. This is done by minimizing a loss function that encourages similarity between the portions of the generated image not relevant to the target concept image and its counterpart in the unrelated image.
read the caption
Figure 4: Concept isolation loss. When training Concept-Mod we apply an additional concept isolation loss in 50% of the training steps. This loss encourages learning directions that do not interfere with other images by enforcing that the parts in the image that should not be affected by the directions remain similar.

🔼 This figure showcases qualitative results of the TokenVerse model. Each row presents four source images, each containing several distinct visual concepts. The model independently extracts these concepts from each source image. The right side of the figure then displays three newly generated images. These generated images demonstrate the model’s ability to seamlessly combine the extracted concepts into novel, coherent compositions, showcasing the versatility and effectiveness of TokenVerse in multi-concept personalization and image generation.
read the caption
Figure 5: Qualitative results. Each row begins with a bank of four source images, from which our method independently extracts concepts. To the right, three generated images are shown, demonstrating the seamless combination of these concepts into new, coherent outputs.

🔼 Figure 6 showcases the capability of TokenVerse to handle extreme multi-concept personalization. Unlike other methods, TokenVerse doesn’t have limitations on the number of concepts that can be combined within a single generated image. The figure demonstrates this by showing an example image that successfully integrates many different concepts, highlighting the model’s flexibility and power.
read the caption
Figure 6: Extreme multi-concept personalization. Our method has no technical constraint on the number of concepts that can be combined in an image. As can be seen, TokenVerse can generate images composing a significant number of concepts.

🔼 Figure 7 showcases TokenVerse’s ability to personalize and combine various visual concepts beyond just objects. Three concept types are demonstrated: object (a bear, though its source image isn’t displayed), pose (shown in the left column), and lighting (top row). The results highlight that TokenVerse effectively learns distinct representations for pose and lighting without being overly influenced by the specific subject or lighting setup, a significant advancement in disentangled concept learning.
read the caption
Figure 7: Concepts beyond objects. We demonstrate the composition of three types of personalized concepts: object (the bear; concept image not shown), pose (left column) and lighting (top row). TokenVerse successfully learns the pose and lighting without overfitting to the identity of the poser or the specific lit scene.

🔼 Figure 8 presents a qualitative comparison of different methods for multi-concept image generation. Each row shows two source images (concept images) and several generated images created by different techniques: ConceptExpress, Break-a-Scene, DreamBooth, OMG, and the proposed method (TokenVerse). The generated images combine concepts extracted from the two source images. The caption highlights that TokenVerse most effectively integrates the concepts while preserving their individual fidelity.
read the caption
Figure 8: Qualitative comparisons. Each row depicts two concept images (left) and images containing a combination of those concepts, generated by ConceptExpress [14], BAS [8], DreamBooth [32], OMG [23] and our method. The concepts associated with the green and blue words are taken from the left and right concept images, respectively. As can be seen, our method best composes the two concepts while preserving concept fidelity.

🔼 Figure 9 presents a quantitative comparison of the proposed TokenVerse method against other baselines across three tasks: concept composition (combining concepts from different images), concept decomposition (extracting concepts from a single image), and a full task combining both. The comparison is based on two metrics: concept preservation and prompt fidelity, both evaluated using DreamBench++ and a user study. TokenVerse consistently outperforms other methods in concept preservation while achieving high prompt fidelity, as detailed in Appendix C.2.
read the caption
Figure 9: Quantitative comparison. We compare our method to other baselines on concept preservation and prompt fidelity (higher is better) using DreamBench++ and a user study. (a) We compare three different settings: (i)𝑖(i)( italic_i ) composing two concepts from different images (concept composition), (ii)𝑖𝑖(ii)( italic_i italic_i ) decomposing two concepts from the same image (concept decomposition), and (iii)𝑖𝑖𝑖(iii)( italic_i italic_i italic_i ) the combination of the two (full task). (b) We conduct a user study, comparing our method to existing methods on our full task. Our method consistently scores best in terms of concept preservation while maintaining high prompt fidelity scores. See App. C.2 for the exact metrics.

🔼 This ablation study demonstrates the effect of progressively adding components to the TokenVerse model. The leftmost part of the figure displays the source concepts used to generate the images. Column (a) shows results without using the M+ space, applying direction vectors directly to input text tokens before entering the transformer. Column (b) incorporates the M+ space, adding the directions to modulation vectors of individual text tokens. Column (c) further refines the results by adding per-block directions. Finally, column (d) presents the full TokenVerse model, including the isolation loss to mitigate interference between concepts from different images. The progressive integration of these components highlights their individual contributions to the model’s overall performance in generating images with multiple concepts from multiple sources.
read the caption
Figure 10: Ablations. The left pane shows all the concepts used to generate the result images. Columns (a) to (d) shows the results of our method as additional components are progressively integrated.

🔼 Figure 11 demonstrates limitations of the TokenVerse model. It shows examples where the model struggles with certain combinations of concepts, primarily due to the independent training process for each concept. Panel (a) shows instances of rare blending between concepts, which can be addressed through joint training. Panel (b) illustrates difficulties when concepts share the same name, resolved by using distinct names. Lastly, panel (c) shows that incompatible combinations (like a doll with tiny limbs in a complex pose) produce undesirable outputs.
read the caption
Figure 11: Limitations. Concept images are shown in the top row, with the generated images using TokenVerse below in each case. While our method supports both disentangled learning and multi-concept composition, limitations remain. (a) Rare blending can occur in specific combinations due to independent training of concepts; We provide analysis and mitigations in App. F. (b) Challenges arise with concepts sharing the same name identifier, which can be mitigated by using distinct terms. (c) Certain incompatible combinations, such as a doll with tiny limbs in a complex pose, may result in undesired outputs.

🔼 This ablation study investigates the impact of data augmentations on the model’s performance. The top row displays the source concepts used to generate images. Column (a) presents the results obtained using the full method, which incorporates both text and image augmentations during training. Column (b) shows the results when these augmentations are omitted, highlighting their contribution to improved image generation.
read the caption
Figure 12: Augmentations Ablation. The top row shows the concepts used to generate the result images. Column (a) displays the results of our full method, while column (b) shows the results without text and image augmentations.

🔼 This figure demonstrates the progressive composition of concepts using TokenVerse. Each row shows a sequence of images, starting with a base image and progressively adding new personalized concepts (object, pose, lighting, and hair) while keeping other aspects consistent through text prompts. The background changes with each row, showcasing the flexibility of concept control through text input. For example, the top row shows the same subject in various poses and lighting conditions, set against backgrounds specified in the captions such as a city, garden, and mars.
read the caption
Figure 13: Progressive composition of concepts. TokenVerse can be used to progressively add concepts into a generated image, while controlling all other aspects of the generated images via text. In each row, the object, pose, lighting, and hair are personalized, while the background is described by text (e.g. “NY city”, “garden”, and “Mars” for the top row.)

🔼 This figure illustrates a limitation of the TokenVerse model when highly similar modulation tokens are used. Panel (a) shows a successful combination of a doll and a dog, representing a typical scenario where the model functions as expected. Panel (b) demonstrates a failure case where independent training leads to the generation of a hybrid object (characteristics of both the doll and the dog are merged). Panel (c) proposes a solution: employing joint training on both concepts during the model’s training phase, which addresses the issue of generating hybrid objects by mitigating the similarity of modulation tokens. This demonstrates that training methodology affects the resulting images.
read the caption
Figure 14: Limitation – highly similar modulated tokens. (a) The common scenario of combining two distinct objects, such as a doll and a dog, into a single image. (b) A failure case where independent training of concepts leads to the creation of hybrid objects. (c) A potential mitigation for this issue by employing joint training on both concepts.

🔼 Figure 15 demonstrates a limitation of the TokenVerse model: when two objects in different images share the same textual identifier (e.g., both are described as ‘dolls’), the model struggles to generate images with both objects distinct and correctly represented. This issue is easily fixed by using different textual identifiers for each object during the initial training phase. The image shows two examples: (a) colliding captions where the model produces an unsatisfactory result; and (b) distinct captions where the model generates a satisfactory result.
read the caption
Figure 15: Limitations – colliding captions. Our method may fail when handling cases of colliding identifiers, such as two dolls (a). This issue can be easily resolved by assigning distinct identifiers to each object during the initial training (b).

🔼 This figure showcases the qualitative results of the TokenVerse model. Each row presents a set of four source images that exemplify distinct visual concepts (such as a doll, a dog, a man in various poses, lighting conditions, etc.). These concepts are independently extracted by TokenVerse from their respective images and are then seamlessly combined to generate novel image compositions. For each concept image set, the figure displays two generated images demonstrating the flexible and versatile nature of TokenVerse in creating novel image compositions that incorporate multiple visual concepts.
read the caption
Figure 16: Qualitative results. Each row contains two result images and the source images of the concepts that they contain.

🔼 This figure showcases qualitative results of the TokenVerse model. Each row presents four source images depicting various concepts (e.g., a doll in different poses, a dog with different accessories, a person in various settings, etc.). To the right of each set of source images, are two images generated by the model. These generated images demonstrate the model’s ability to combine and personalize the extracted concepts in novel ways. The generated images show diverse compositions and attributes of the concepts, highlighting the model’s flexibility in handling multiple concepts and its capacity for seamless integration of personalized elements from various sources.
read the caption
Figure 17: Qualitative results. Each row contains two result images and the source images of the concepts that they contain.

🔼 Figure 18 presents qualitative results showcasing TokenVerse’s ability to generate images by combining concepts extracted from multiple source images. Each row displays four concept images followed by two generated images. The generated images demonstrate how TokenVerse successfully integrates the concepts from the source images into novel compositions. This visually demonstrates the model’s ability to disentangle and recombine visual attributes (objects, poses, lighting conditions, etc.) from different sources seamlessly.
read the caption
Figure 18: Qualitative results. Each row contains two result images and the source images of the concepts that they contain.

🔼 This figure demonstrates the application of the TokenVerse method to storytelling. The left side displays the characters, scenes, and poses used in the story. The story itself, created by a large language model (LLM), is shown on the right. The LLM further processed the story to generate prompts for image generation using TokenVerse, resulting in the images shown in the figure.
read the caption
Figure 19: Storytelling results. Demonstration of our method’s usability for storytelling applications. All the characters, scenes, and poses featured in the story are shown on the left. On the right is the story itself, generated by a language model (LLM). This story was then reprocessed by the LLM to generate prompts, which were used to create the accompanying images.

🔼 This figure shows example questions from a user study conducted to evaluate the quality of generated images. Participants were shown a generated image and asked to rate how well it matched a given text description (prompt alignment) and how well it incorporated specific concepts from input images (concept preservation). Concept preservation was assessed separately for different visual elements present in the image.
read the caption
Figure 20: An example of the questions asked in the user study. Given a generated image the users are asked about its alignment with both the text and the input concepts
More on tables
| Composition | Decomposition | Full task | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Metric | CP | PF | CP PF | CP | PF | CP PF | CP | PF | CP PF |
| Dreambooth | 0.280242 | 0.844422 | 0.236642 | 0.668524 | 0.660167 | 0.441337 | 0.207116 | 0.827521 | 0.171393 |
| DreamBooth | 0.371304 | 0.619288 | 0.229944 | 0.668524 | 0.660167 | 0.441337 | 0.306262 | 0.591337 | 0.181104 |
| OMG | 0.238606 | 0.743968 | 0.177515 | 0.267477 | 0.791793 | 0.211787 | 0.207787 | 0.843395 | 0.175246 |
| Break-A-Scene | 0.392912 | 0.372664 | 0.154380 | 0.598387 | 0.641935 | 0.384126 | 0.499054 | 0.641236 | 0.320011 |
| ConceptExpress | 0.214718 | 0.548723 | 0.117821 | 0.246387 | 0.695087 | 0.171260 | 0.187853 | 0.733286 | 0.137750 |
| Ours | 0.470108 | 0.688061 | 0.323463 | 0.669940 | 0.747698 | 0.500431 | 0.553125 | 0.821875 | 0.454600 |
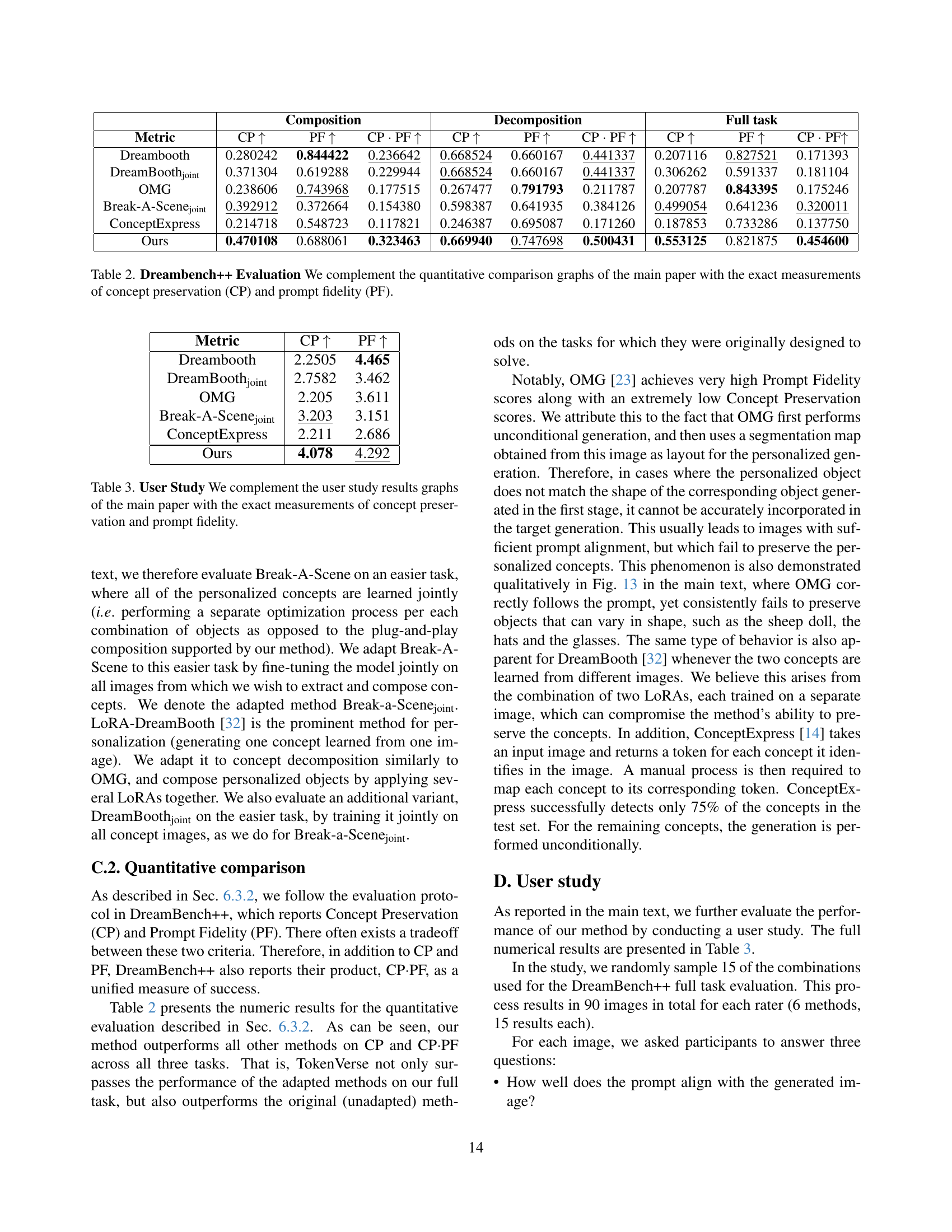
🔼 This table presents a quantitative comparison of different methods for image generation, focusing on two key metrics: concept preservation (CP) and prompt fidelity (PF). Concept preservation measures how well the generated image retains the specific features of the target concept, while prompt fidelity assesses how accurately the image matches the text prompt. The table provides precise numerical values for CP and PF, allowing for a detailed comparison across multiple approaches and evaluation scenarios (composition, decomposition, and a combined full task). These results supplement the visual comparisons shown in the main paper.
read the caption
Table 2: Dreambench++ Evaluation We complement the quantitative comparison graphs of the main paper with the exact measurements of concept preservation (CP) and prompt fidelity (PF).
| Metric | CP | PF |
|---|---|---|
| Dreambooth | 2.2505 | 4.465 |
| DreamBooth | 2.7582 | 3.462 |
| OMG | 2.205 | 3.611 |
| Break-A-Scene | 3.203 | 3.151 |
| ConceptExpress | 2.211 | 2.686 |
| Ours | 4.078 | 4.292 |
🔼 This table presents the quantitative results of a user study evaluating the performance of TokenVerse. It complements the graphical representations in the main paper by providing the precise numerical scores for concept preservation and prompt fidelity, metrics used to assess how well the generated images retain the original concepts and adhere to the text prompts, respectively. The results are presented for different methods, allowing for direct comparison of TokenVerse against other approaches.
read the caption
Table 3: User Study We complement the user study results graphs of the main paper with the exact measurements of concept preservation and prompt fidelity.
Full paper#