TL;DR#
Current GUI agent frameworks rely heavily on large language models and often require complex, handcrafted workflows, limiting their scalability and adaptability. This leads to performance bottlenecks and difficulty handling diverse real-world scenarios. The paper introduces several key innovations that improve the capabilities of GUI interaction, enhancing perception and grounding abilities.
The proposed solution, UI-TARS, uses a native GUI agent model that solely relies on screenshots as input. This end-to-end model achieves state-of-the-art performance in several benchmarks. The model incorporates enhanced perception, unified action modeling, system-2 reasoning, and iterative training with reflective online traces to overcome the data bottleneck and improve accuracy. The open-sourcing of UI-TARS allows for further research and development in the field.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in AI, particularly those working on agent-based systems, GUI interaction, and multimodal learning. It presents a novel approach to automated GUI interaction that addresses current limitations, showing significant performance improvements. The open-sourcing of the model and dataset further enhances its value, making it a valuable resource for the research community and potentially impacting various applications.
Visual Insights#

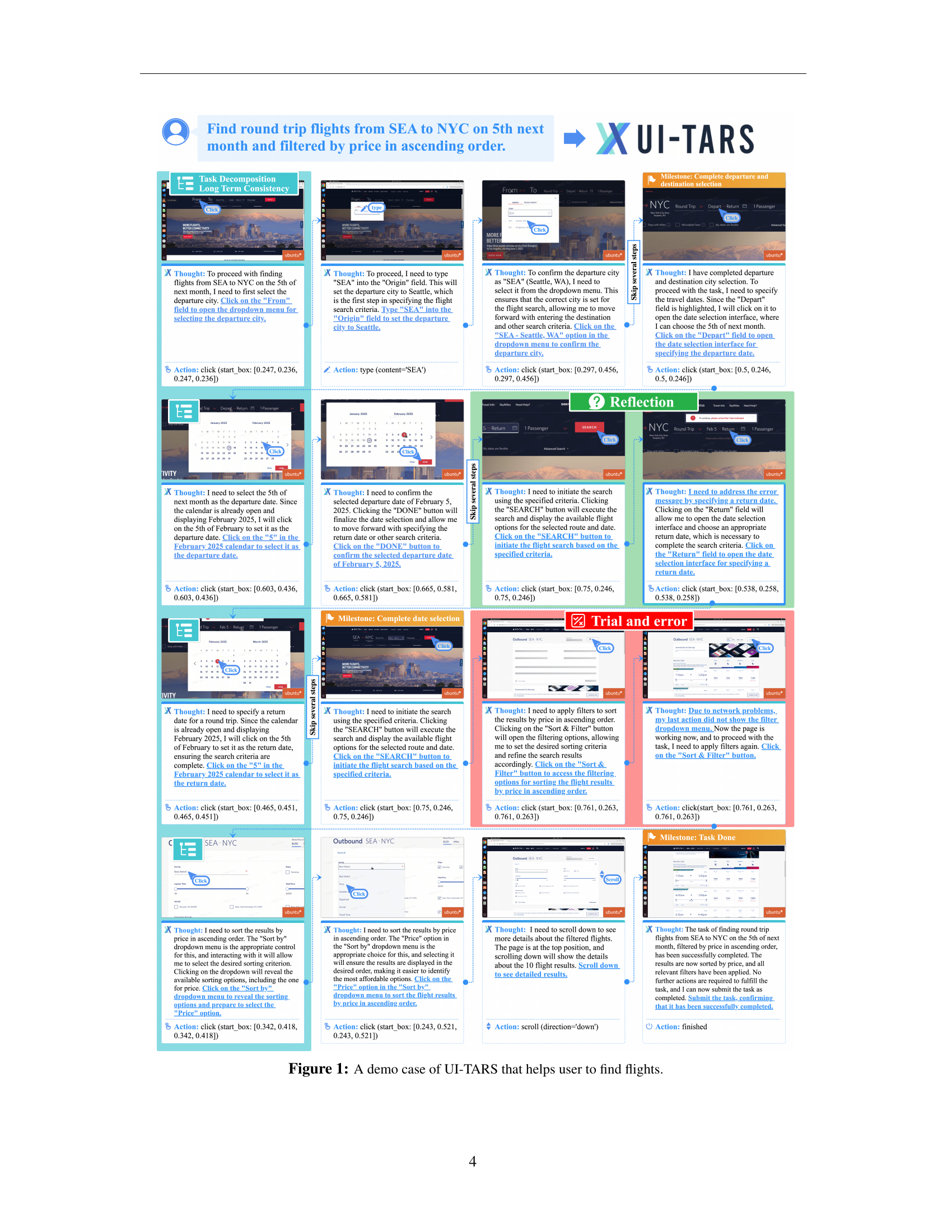
🔼 This figure showcases a step-by-step demonstration of UI-TARS, a native GUI agent, performing a complex flight search task. It highlights the agent’s capabilities, including understanding natural language instructions, interacting with various GUI elements (e.g., text fields, dropdowns, buttons, calendars), handling unexpected situations (like error messages), employing iterative reasoning, and ultimately achieving the user’s goal. Each step shows screenshots of the GUI alongside the agent’s ’thoughts’ and actions. The process reveals UI-TARS’s ability to decompose the task into smaller subtasks, employ reflective thinking to adjust its strategy based on the context, and continuously learn from both successes and failures.
read the caption
Figure 1: A demo case of UI-TARS that helps user to find flights.
| Environment | Action | Definition |
| Shared | Click(x, y) | Clicks at coordinates (x, y). |
| Drag(x1, y1, x2, y2) | Drags from (x1, y1) to (x2, y2). | |
| Scroll(x, y, direction) | Scrolls at (x, y) in the given direction. | |
| Type(content) | Types the specified content. | |
| Wait() | Pauses for a brief moment. | |
| Finished() | Marks the task as complete. | |
| CallUser() | Requests user intervention. | |
| Desktop | Hotkey(key) | Presses the specified hotkey. |
| LeftDouble(x, y) | Double-clicks at (x, y). | |
| RightSingle(x, y) | Right-clicks at (x, y). | |
| Mobile | LongPress(x, y) | Long presses at (x, y). |
| PressBack() | Presses the “back” button. | |
| PressHome() | Presses the “home” button. | |
| PressEnter() | Presses the “enter” key. |
🔼 This table presents the results of evaluating various models’ performance on three GUI perception benchmarks: VisualWebBench, WebSRC, and ScreenQA-short. These benchmarks assess different aspects of visual understanding of GUIs, including webpage content understanding (VisualWebBench), web structure comprehension (WebSRC), and mobile screen understanding through question-answering tasks (ScreenQA-short). The table shows the scores achieved by different models on each benchmark, allowing for a comparison of their performance in various aspects of GUI perception. Higher scores indicate better performance.
read the caption
Table 3: Results on GUI Perception benchmarks.
In-depth insights#
Native GUI Agent Rise#
The rise of native GUI agents signifies a paradigm shift in human-computer interaction. Unlike previous rule-based or modular agents heavily reliant on external LLMs and handcrafted workflows, native agents directly perceive and interpret GUI screenshots, eliminating the need for intermediate textual representations or API calls. This approach leads to improved generalization and adaptability, enabling agents to seamlessly handle diverse tasks and interfaces without retraining. End-to-end models allow for efficient learning from large-scale data, and incorporating System-2 reasoning enhances decision-making capabilities. While challenges remain in data collection and the complexity of GUI environments, the inherent flexibility and scalability of native agents make them a promising direction for automating complex GUI-based workflows. The key advantages are enhanced perception, direct action modeling, and the capacity for continual learning.
UI-TARS Architecture#
The UI-TARS architecture likely involves a multi-stage process beginning with user query input. The system then employs enhanced perception to process screenshots, extracting visual features and understanding GUI elements using techniques like dense captioning, question answering, and set-of-mark prompting. This results in a rich representation of the user interface state. A unified action model facilitates cross-platform interaction by translating actions into a common representation, enabling precise grounding of actions within the GUI. This is then fed into a system-2 reasoning module, which incorporates deliberate, multi-step planning and reflective thinking mechanisms to ensure robust execution, even in complex scenarios. The iterative training loop involving reflective online traces further enables UI-TARS to continuously learn and refine its actions, minimizing human intervention and improving performance. The model likely incorporates short-term and long-term memory components to store information pertaining to past interactions and relevant background knowledge which guides future actions and decisions. The entire architecture emphasizes an end-to-end approach and data-driven learning, aiming to achieve human-level proficiency in GUI interaction.
Iterative Training#
Iterative training, in the context of machine learning models, is a powerful technique for continuous improvement and adaptation. Unlike traditional methods that rely on static datasets and fixed model parameters, iterative training involves a cyclical process of model training, evaluation, and refinement using newly collected data. This approach is particularly valuable when dealing with dynamic environments or tasks with evolving requirements, like GUI interaction. The process begins by training an initial model on an existing dataset. Then, the model is deployed in a real-world environment (or a realistic simulation), where it interacts with the environment and generates new data reflecting its performance. This newly generated data is then used to fine-tune or retrain the model, leading to improvements in accuracy, efficiency, and robustness. Crucially, reflection plays a significant role in this process. The model’s performance is assessed, errors are identified, and corrective actions are made, resulting in continuous learning from mistakes and improved decision-making. This iterative process can cycle multiple times, gradually enhancing the model’s generalization abilities and reducing the need for substantial manual intervention during each iterative step. This is a key advantage over traditional methods, allowing models to adapt organically to previously unseen situations, improving the overall effectiveness of the model and enabling long-term adaptability and resilience.
System-2 Reasoning#
The concept of ‘System-2 Reasoning’ in the context of a GUI agent signifies a significant advancement in AI, moving beyond reactive, rule-based systems. It introduces deliberate, multi-step thinking, mirroring human cognitive processes. Instead of simply reacting to visual cues, a System-2 agent engages in reflective planning and problem-solving. This involves breaking down complex tasks into smaller, manageable subtasks (task decomposition), maintaining a consistent focus on the overall goal (long-term consistency), and recognizing checkpoints along the way (milestone recognition). Crucially, it also incorporates error handling; the agent learns from mistakes (trial and error), analyzes failures, and adapts its strategy (reflection). This approach necessitates more sophisticated reasoning capabilities and potentially a larger model capacity than simpler, System-1 agents. The benefits include enhanced reliability, adaptability, and the capacity to tackle complex, dynamic tasks typically beyond the capabilities of simpler, reactive agents.
Future GUI Agents#
Future GUI agents hold the potential for a paradigm shift in human-computer interaction. Moving beyond current limitations, such as reliance on pre-defined rules or inflexible frameworks, future agents will leverage advanced machine learning techniques for seamless adaptation and generalization. Active and lifelong learning capabilities will enable these agents to continuously refine their behavior based on real-world experiences, minimizing the need for human intervention. This will lead to more robust and adaptable systems capable of handling a wider range of complex tasks and unforeseen situations. Seamless integration with diverse environments will be a key characteristic, ensuring compatibility across various operating systems and interfaces. Furthermore, enhanced perception capabilities will enable precise understanding of dynamic GUI elements, facilitating more nuanced and accurate interactions. Improved reasoning and planning abilities will enable agents to execute multi-step tasks efficiently and reliably, while advanced memory management will allow them to leverage past experiences to inform future decisions. Ethical considerations will also be paramount, ensuring these powerful agents are developed and deployed responsibly, to avoid bias and unintended consequences.
More visual insights#
More on figures

🔼 This figure illustrates the evolution of Graphical User Interface (GUI) agents over time, categorized into four stages based on their level of autonomy and reliance on human intervention. It visually represents the shift from simple rule-based agents to more complex, adaptable models leveraging large language models (LLMs) and machine learning. The figure shows the increase in generalization capabilities and the decrease in human oversight needed as GUI agents evolve.
read the caption
Figure 2: The evolution path for GUI agents.

🔼 This figure provides a comprehensive overview of the core capabilities and evaluation metrics for GUI agents. It illustrates the interconnectedness of four key aspects: perception (how the agent understands the GUI), action (how the agent interacts with the GUI), reasoning (the agent’s decision-making process, encompassing both fast, intuitive System 1 thinking and slower, deliberate System 2 thinking), and memory (short-term and long-term storage for information). Different evaluation methods are also shown, categorized by offline versus online evaluation and further separated into metrics that evaluate each core capability (perception, grounding, and agent capabilities). This visualization helps clarify how these components work together and how their performance is measured.
read the caption
Figure 3: An overview of core capabilities and evaluation for GUI agents.

🔼 Figure 4 provides a detailed illustration of UI-TARS’ architecture and its core components. It visually depicts the model’s interaction with the environment, showing how it receives user queries, processes observations from screenshots, generates thoughts (reasoning steps), selects actions, and then receives feedback from the environment to further improve its performance. Key capabilities like perception (enhanced GUI understanding from screenshots), action (standardized across different platforms), System-2 Reasoning (incorporating deliberate reasoning into multi-step decisions), and learning from prior experiences (through online trace bootstrapping and reflection tuning) are integrated within the architecture. This visualization helps to understand the iterative, data-driven nature of UI-TARS and how its components work together to enable effective GUI interaction.
read the caption
Figure 4: Overview of UI-TARS. We illustrate the architecture of the model and its core capabilities.

🔼 Figure 5 presents example data used for perception and grounding tasks in the UI-TARS model. It illustrates five key aspects of the model’s perception capabilities: (1) Element Description: provides detailed descriptions of GUI elements including type, visual appearance, location, and function. (2) Task Grounding: demonstrates how the model accurately locates and interacts with GUI elements based on provided queries. (3) Question Answering (QA): shows the model’s ability to answer questions about GUI elements and their contextual relationships. (4) Set-of-Mark Perception: showcases the model’s capacity to locate and identify elements using visual markers for improved accuracy. (5) Dense Captioning: illustrates the model’s capability to generate detailed captions describing the entire GUI layout, including spatial relationships and interactions between elements. Each aspect is demonstrated using specific examples from different GUI screenshots, highlighting the model’s precise understanding and interaction with various GUI elements.
read the caption
Figure 5: Data example of perception and grounding data.

🔼 This table presents a unified action space designed to standardize actions across various platforms (web, mobile, desktop). Instead of platform-specific actions, it uses a common set of operations such as ‘click’, ’type’, ‘scroll’, and ‘drag’. Additionally, it includes actions from language agents (like API calls), improving agent versatility. The actions are categorized into atomic (single operations) and compositional (sequences of actions). This standardized approach enhances the transferability and efficiency of actions across different GUI environments.
read the caption
Table 1: Unified action space for different platforms.

🔼 This table presents a quantitative comparison of the datasets used for training UI-TARS. It contrasts data gathered from two main sources: an annotated dataset created by the researchers, and a collection of open-source datasets. The comparison highlights differences across various platforms (web, mobile, and desktop) and focuses on two key metrics: * Number of elements (Ele.): Represents the total count of distinct GUI elements identified and annotated within each dataset. This metric reflects the richness and diversity of GUI elements covered in each source. * Number of action traces (Trace): Indicates the quantity of sequential interactions logged, capturing the steps involved in completing tasks in the respective datasets. This metric is crucial for evaluating the model’s ability to learn and perform multi-step operations. By breaking down the dataset characteristics by platform, the table reveals potential variations in data distribution and the complexity of GUI elements present. This information is essential for understanding the strengths and limitations of the training data and assessing its impact on the model’s performance across different GUI types.
read the caption
Table 2: Basic statistics for grounding and multi-step action trace data, comparing both our annotated dataset and open-source data across different platforms (web, mobile, and desktop). We report the number of elements (Ele.) and the number of action traces (Trace).

🔼 This figure showcases various reasoning patterns employed by the UI-TARS model. Each example demonstrates a different type of reasoning, such as task decomposition, long-term consistency, milestone recognition, trial and error, and reflection. The screenshots illustrate how these reasoning processes manifest in the model’s ’thoughts’, which are intermediate steps generated before executing an action. These ’thoughts’ provide insight into the model’s decision-making process, showing how it breaks down complex tasks, maintains consistency across multiple steps, identifies milestones, learns from mistakes, and reflects on its performance.
read the caption
Figure 6: Various reasoning patterns in our augmented thought.

🔼 This figure illustrates the iterative process of online data bootstrapping used to enhance UI-TARS’s learning. It starts with a set of initial task instructions. These are then used to generate interaction traces using the current UI-TARS model on virtual machines. The raw traces go through a multi-step filtering process involving rule-based reward functions, VLM scoring, and human review, producing high-quality filtered traces. These filtered traces are then used to fine-tune the model, creating an improved version. New instructions are generated, and the process repeats, iteratively refining the data and improving the model’s performance. The process also includes a reflection tuning step, where errors identified by the model (or humans) are used to create improved interaction traces, further enhancing the model’s ability to learn from mistakes.
read the caption
Figure 7: Overview of the online bootstrapping process.

🔼 Figure 8 presents a comparison of the performance of System-1 (intuition-based) and System-2 (deliberative) reasoning models in both in-domain and out-of-domain GUI benchmarks. The in-domain benchmarks (Mind2Web, AndroidControl, GUI Odyssey) represent tasks the models were trained on, while the out-of-domain benchmark (AndroidWorld) tests generalization capabilities on unseen tasks. The graph displays the success rates (or other relevant metrics) for each model across the different benchmarks at various sample sizes (BoN values of 1, 16, and 64). This allows for an analysis of how the reasoning method (System-1 vs. System-2) and sample size affect performance, revealing the trade-offs between speed (intuition) and accuracy (deliberation).
read the caption
Figure 8: Performance of system-1 (no-thought) and system-2 (with thought) in in-domain (Mind2Web, AndroidControl, GUI Odyssey) and out-of-domain (AndroidWorld) benchmarks.

🔼 This figure showcases a demonstration of UI-TARS, a native GUI agent, performing a task within the Ubuntu Impress software. The specific task is to modify the background color of slide 2 to match the color of the title on slide 1. The figure presents a sequence of screenshots illustrating the steps UI-TARS takes to accomplish this, including selecting the relevant slide, accessing color settings, and choosing the appropriate color. Each screenshot is accompanied by UI-TARS’s internal thought process, demonstrating its reasoning and decision-making capabilities throughout the task.
read the caption
Figure 9: Test case on Ubuntu impress scene from UI-TARS. The task is: Make the background color of slide 2 same as the color of the title from slide 1.

🔼 This figure showcases a demonstration of UI-TARS’s capabilities on an Android device. The user task is to play a specific song, ‘Under Mount Fuji (富士山下)’. The figure visually depicts a step-by-step sequence of UI interactions made by UI-TARS. Each step is shown with a screenshot, indicating the actions performed, along with the agent’s accompanying thought process at that step. The visual progression demonstrates the agent’s ability to locate and interact with the relevant UI elements (e.g., the music app icon, search bar) to successfully complete the task, which involves locating the song within the music player app and starting playback.
read the caption
Figure 10: Test case on Android from UI-TARS. The task is: Play the song under Mount Fuji.
🔼 This figure showcases a demonstration of UI-TARS, a native GUI agent, performing the task of installing the ‘autoDocstring’ extension in the VS Code editor. The figure is a sequence of screenshots capturing UI-TARS’s interaction with the VS Code interface, showing the steps taken, including launching VS Code, navigating to the extensions panel, typing the extension name, clicking to install it, handling an error, and finally confirming the successful installation. Each screenshot is accompanied by a description of UI-TARS’s reasoning process (its internal ’thoughts’ shown as text boxes) explaining the rationale behind each action. This visualization provides insights into how UI-TARS processes visual information, reasons, and interacts with the GUI to achieve a given task, highlighting its functionality as a native agent without reliance on pre-programmed workflows or human intervention.
read the caption
Figure 11: Test case on Ubuntu VSCode scene from UI-TARS. The task is: Please help me install the autoDocstring extension in VS Code.

🔼 This figure showcases a test case demonstrating UI-TARS’s ability to interact with a Chrome browser on a Windows system. The goal is to configure Chrome settings to display the bookmarks bar by default. The figure visually depicts a step-by-step sequence of UI-TARS’s actions: launching Chrome, accessing settings through the three-dot menu, navigating to the Appearance settings, and finally, activating the ‘Show bookmarks bar’ toggle switch. Each step is accompanied by UI-TARS’s corresponding ’thought’ process, revealing its internal decision-making logic, as well as the precise coordinates of each mouse click action (start_box). This detailed visualization effectively demonstrates UI-TARS’s functionality, including its capability to perceive UI elements accurately, execute multi-step sequences of actions, and apply reasoning to complete the task successfully.
read the caption
Figure 12: Test case on Windows chrome scene from UI-TARS. The task is: I want to show bookmarks bar by default in chrome.

🔼 The figure shows an example of dense captioning from the UI-TARS model. The input is a screenshot of a webpage showing a TSB Bank advertisement for a cashback offer on a current account. The output is a detailed description of the webpage’s layout and elements, including the navigation bar, the main advertisement, supporting images and text, and several icons linking to other services. The caption provides very detailed information about each element’s visual appearance, location, and function, demonstrating the model’s ability to understand a complex GUI interface at a granular level.
read the caption
Figure 13: Dense caption example.
More on tables
| Data Type | Grounding | MultiStep | |||
| Ele. | Ele./Image | Trace | avg steps | ||
| Open Source | Web | M | k | ||
| Mobile | M | k | |||
| Desktop | M | 0 | 0 | ||
| Ours | * | * | |||
🔼 This table presents a comparison of the performance of various models on the ScreenSpot-Pro benchmark. ScreenSpot-Pro is a challenging GUI grounding benchmark featuring high-resolution screenshots from diverse real-world professional applications across multiple platforms (mobile, desktop, web). The table shows the average performance of each model across various categories within the benchmark. These categories likely include different types of GUI elements (text, icon/widgets), various difficulty levels of tasks, and different application domains. The results demonstrate the relative strengths and weaknesses of each model in handling the complexities of real-world GUI interfaces.
read the caption
Table 4: Comparison of various models on ScreenSpot-Pro.
| Model | VisualWebBench | WebSRC | ScreenQA-short |
| Qwen2-VL-7B (Wang et al., 2024c) | |||
| Qwen-VL-Max (Bai et al., 2023b) | |||
| Gemini-1.5-Pro (Team et al., 2024) | |||
| UIX-Qwen2-7B (Wang et al., 2024d) | |||
| Claude-3.5-Sonnet (Anthropic, 2024a) | |||
| GPT-4o (Hurst et al., 2024) | |||
| UI-TARS-2B | |||
| UI-TARS-7B | |||
| UI-TARS-72B |
🔼 This table presents a comparison of the performance of different planning and grounding methods on the ScreenSpot benchmark. It shows how various approaches to guiding an agent’s interaction with a graphical user interface (GUI) affect its ability to accurately identify and interact with specific GUI elements. The benchmark likely evaluates aspects like the accuracy of element location prediction and the effectiveness of the planning strategies employed. Results are broken down by different agent frameworks and models, allowing for a comparison of performance across various techniques.
read the caption
Table 5: Comparison of various planners and grounding methods on ScreenSpot.
| Agent Model | Development | Creative | CAD | Scientific | Office | OS | Avg | ||||||||||||||
| Text | Icon | Avg | Text | Icon | Avg | Text | Icon | Avg | Text | Icon | Avg | Text | Icon | Avg | Text | Icon | Avg | Text | Icon | Avg | |
| QwenVL-7B (Bai et al., 2023b) | |||||||||||||||||||||
| GPT-4o (Hurst et al., 2024) | |||||||||||||||||||||
| SeeClick (Cheng et al., 2024) | |||||||||||||||||||||
| Qwen2-VL-7B (Wang et al., 2024c) | |||||||||||||||||||||
| OS-Atlas-4B (Wu et al., 2024b) | |||||||||||||||||||||
| ShowUI-2B (Lin et al., 2024b) | |||||||||||||||||||||
| CogAgent-18B (Hong et al., 2024) | |||||||||||||||||||||
| Aria-UI (Yang et al., 2024a) | |||||||||||||||||||||
| UGround-7B (Gou et al., 2024a) | |||||||||||||||||||||
| Claude Computer Use (Anthropic, 2024b) | |||||||||||||||||||||
| OS-Atlas-7B (Wu et al., 2024b) | |||||||||||||||||||||
| UGround-V1-7B (Gou et al., 2024a) | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |||||||
| UI-TARS-2B | |||||||||||||||||||||
| UI-TARS-7B | |||||||||||||||||||||
| UI-TARS-72B | |||||||||||||||||||||
🔼 This table presents a comparison of different planning and grounding methods’ performance on the ScreenSpot-V2 benchmark. ScreenSpot-V2 is a dataset designed to evaluate the accuracy of GUI agents in locating and interacting with interface elements. The table compares various approaches, including different agent frameworks and agent models, across three GUI interaction types: mobile, desktop, and web. For each method and platform, the table shows the performance metrics for both ’text’ and ‘icon/widget’ interactions. These results highlight the relative effectiveness of each method in precisely identifying and acting upon GUI elements, providing a detailed performance comparison across different types of GUIs.
read the caption
Table 6: Comparison of various planners and grounding methods on ScreenSpot-V2.
| Method | Mobile | Desktop | Web | Avg | ||||
| Text | Icon/Widget | Text | Icon/Widget | Text | Icon/Widget | |||
| Agent Framework | ||||||||
| GPT-4 (OpenAI, 2023b) | SeeClick (Cheng et al., 2024) | |||||||
| OmniParser (Lu et al., 2024b) | ||||||||
| UGround-7B (Gou et al., 2024a) | ||||||||
| GPT-4o (Hurst et al., 2024) | SeeClick (Cheng et al., 2024) | |||||||
| UGround-7B (Gou et al., 2024a) | ||||||||
| Agent Model | ||||||||
| GPT-4 (OpenAI, 2023b) | ||||||||
| GPT-4o (Hurst et al., 2024) | ||||||||
| CogAgent (Hong et al., 2024) | ||||||||
| CogAgent-9B-20241220 (Hong et al., 2024) | - | - | - | - | - | - | ||
| SeeClick (Cheng et al., 2024) | ||||||||
| Qwen2-VL (Wang et al., 2024c) | ||||||||
| UGround-7B (Gou et al., 2024a) | ||||||||
| Aguvis-G-7B (Xu et al., 2024) | ||||||||
| OS-Atlas-7B (Wu et al., 2024b) | ||||||||
| Claude Computer Use (Anthropic, 2024b) | - | - | - | - | - | - | ||
| Gemini 2.0 (Project Mariner) (GoogleDeepmind, 2024) | - | - | - | - | - | - | ||
| Aguvis-7B (Xu et al., 2024) | ||||||||
| Aguvis-72B (Xu et al., 2024) | ||||||||
| UI-TARS-2B | ||||||||
| UI-TARS-7B | ||||||||
| UI-TARS-72B | ||||||||
🔼 This table presents a performance comparison of various models on the Multimodal Mind2Web benchmark across different settings. The benchmark evaluates the ability of models to perform complex tasks by interacting with a webpage. The table compares different agent models’ performance on this benchmark, assessing the performance in terms of three key metrics: Element Accuracy (Ele.Acc), which measures how accurately the model identifies and extracts relevant elements from the webpage; Operation F1 score (Op.F1), reflecting the precision and recall of the actions performed by the agent; and Step Success Rate (Step SR), indicating the success rate of the models on the webpage-based tasks. Different settings within the benchmark potentially involve varied task complexities, prompting variations, or interactions, allowing for a more comprehensive assessment of the agent’s capabilities.
read the caption
Table 7: Performance comparison on Multimodal Mind2Web across different settings. We report element accuracy (Ele.Acc), operation F1 (Op.F1), and step success rate (Step SR).
| Method | Mobile | Desktop | Web | Avg | ||||
| Text | Icon/Widget | Text | Icon/Widget | Text | Icon/Widget | |||
| Agent Framework | ||||||||
| GPT-4o (Hurst et al., 2024) | SeeClick (Cheng et al., 2024) | |||||||
| OS-Atlas-4B (Wu et al., 2024b) | ||||||||
| OS-Atlas-7B (Wu et al., 2024b) | ||||||||
| Agent Model | ||||||||
| SeeClick (Cheng et al., 2024) | ||||||||
| OS-Atlas-4B (Wu et al., 2024b) | ||||||||
| OS-Atlas-7B (Wu et al., 2024b) | ||||||||
| UI-TARS-2B | ||||||||
| UI-TARS-7B | ||||||||
| UI-TARS-72B | ||||||||
🔼 This table presents the results of evaluating the performance of various GUI agents on two mobile-focused benchmarks: AndroidControl and GUI Odyssey. AndroidControl assesses agents’ abilities in both high-level (autonomous planning and execution) and low-level (step-by-step execution based on predefined human actions) tasks. GUI Odyssey focuses on cross-application navigation tasks, evaluating an agent’s capability to navigate across multiple applications within a mobile environment. The table reports two performance settings for AndroidControl: Low and High, reflecting the complexity of the tasks. For each benchmark and setting, the table shows the success rate (Step SR), grounding success rate, and the type of task.
read the caption
Table 8: Results on mobile tasks (AndroidControl and GUI Odyssey). For AndroidControl, we report two settings (Low and High).
| Method | Cross-Task | Cross-Website | Cross-Domain | |||||||
| Ele.Acc | Op.F1 | Step SR | Ele.Acc | Op.F1 | Step SR | Ele.Acc | Op.F1 | Step SR | ||
| Agent Framework | ||||||||||
| GPT-4o (Hurst et al., 2024) | SeeClick (Cheng et al., 2024) | - | - | - | - | - | - | |||
| GPT-4o (Hurst et al., 2024) | UGround (Gou et al., 2024a) | - | - | - | - | - | - | |||
| GPT-4o (Hurst et al., 2024) | Aria-UI (Yang et al., 2024a) | - | - | - | - | - | - | |||
| GPT-4V (OpenAI, 2023a) | OmniParser (Lu et al., 2024b) | |||||||||
| Agent Model | ||||||||||
| GPT-4o (Hurst et al., 2024) | ||||||||||
| GPT-4(SOM) (Achiam et al., 2023) | - | - | - | |||||||
| GPT-3.5(Text-only) (OpenAI, 2022) | ||||||||||
| GPT-4(Text-only) (Achiam et al., 2023) | ||||||||||
| Claude* (Anthropic, 2024b) | ||||||||||
| Aguvis-7B (Xu et al., 2024) | ||||||||||
| CogAgent (Hong et al., 2024) | - | - | - | - | - | - | ||||
| Aguvis-72B (Xu et al., 2024) | ||||||||||
| UI-TARS-2B | ||||||||||
| UI-TARS-7B | ||||||||||
| UI-TARS-72B | ||||||||||
🔼 This table presents the results of online benchmark evaluations focusing on two key environments: OSWorld and AndroidWorld. For OSWorld, the evaluation was conducted under screenshot-only conditions, limiting the maximum number of steps allowed to 15. The table compares various agent models (both framework-based and native agent models) by showing their performance in terms of task success rate. This allows for a direct comparison of different model architectures and approaches to GUI interaction.
read the caption
Table 9: Results on online benchmarks. We evaluate performance under the screenshot-only setting on OSWorld, limiting the maximum number of steps to 15.
Full paper#