TL;DR#
Current Large Vision Language Models (LVLMs) often produce inaccurate outputs. While reward models (RMs) offer improvement potential, publicly available multi-modal RMs for LVLMs are lacking, hindering progress. This research addresses this gap by introducing InternLM-XComposer2.5-Reward (IXC-2.5-Reward), a simple yet effective multi-modal RM. The model uses a high-quality multi-modal preference corpus for training, encompassing text, image, and video data across various domains.
The study demonstrates IXC-2.5-Reward’s effectiveness in three key applications. First, it provides a supervisory signal for reinforcement learning (RL), improving instruction following and multi-modal dialogue. Second, it enables test-time scaling by selecting the best response from candidates. Third, it filters noisy samples from training data. IXC-2.5-Reward outperforms existing models on benchmark evaluations and shows competitive results even on text-only benchmarks. The authors have open-sourced all model weights and training recipes to encourage further research.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the scarcity of publicly available multi-modal reward models for Large Vision Language Models (LVLMs). It introduces InternLM-XComposer2.5-Reward (IXC-2.5-Reward), a simple yet effective model, demonstrates its effectiveness across various benchmarks and applications (RL training, test-time scaling, data cleaning), and open-sources its weights and training recipes, thus advancing research and development in LVLMs. Its findings have strong implications for improving the quality and reliability of LVLMs in diverse applications.
Visual Insights#

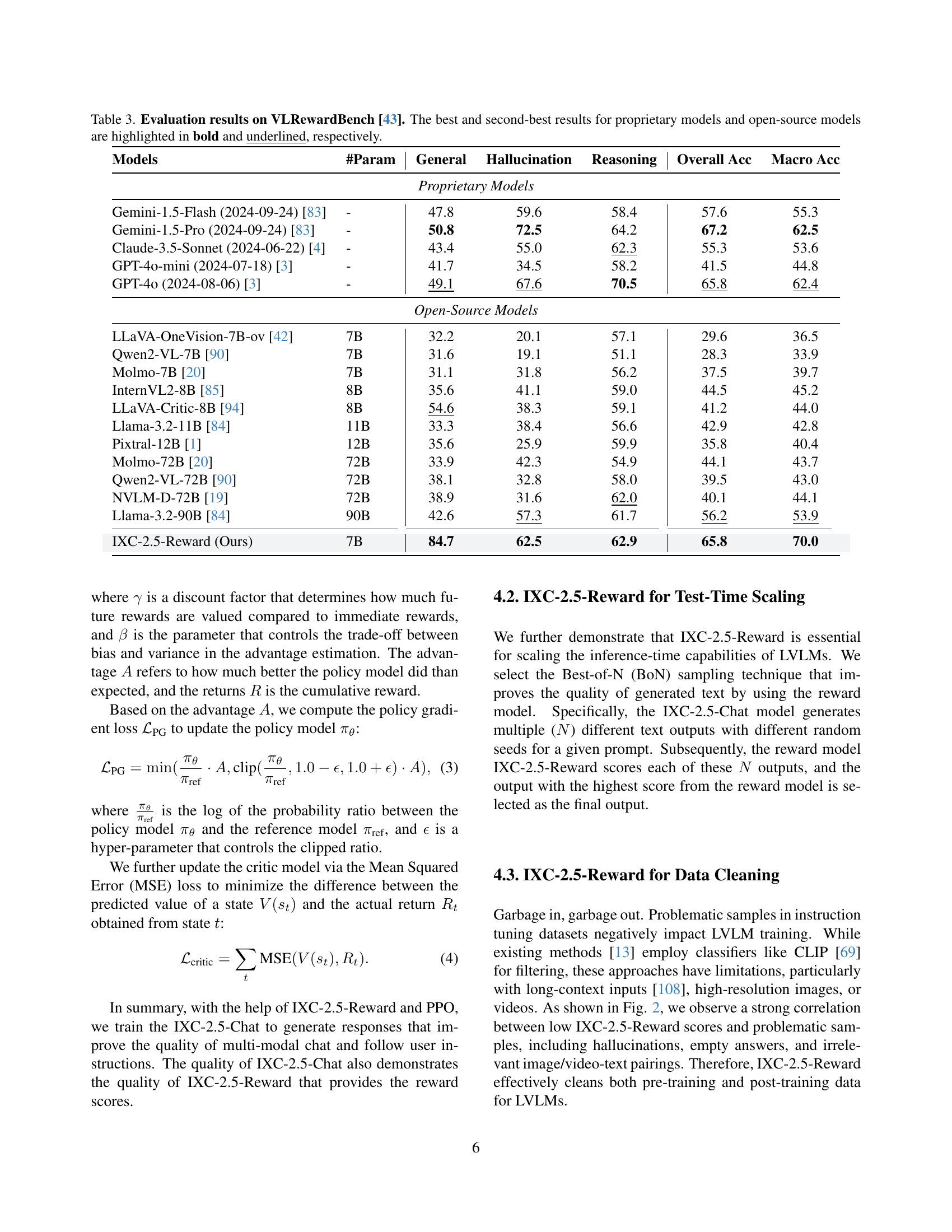
🔼 Figure 1 illustrates the training and application of the InternLM-XComposer2.5-Reward (IXC-2.5-Reward) model. Panel (a) shows the diverse multi-modal dataset used for training, encompassing various domains (natural scenes, text-rich documents, reasoning tasks) and modalities (image, text, video). Panel (b) details the IXC-2.5-Reward model architecture, highlighting its components such as vision encoders, tokenizers, large language models, and a score head for reward prediction. Panel (c) demonstrates the role of IXC-2.5-Reward in reinforcement learning, specifically guiding the training of IXC-2.5-Chat by providing a reward signal to improve the policy.
read the caption
Figure 1: (a) To train the IXC-2.5-Reward, we construct a multi-modal preference dataset spanning diverse domains (e.g., natural scenes, text-rich, reasoning) and modalities (image, text, video). (b) The framework of IXC-2.5-Reward. (c) The IXC-2.5-Reward guides policy training for IXC-2.5-Chat via reinforcement learning.
| Category | Dataset |
|---|---|
| Text | |
| IF General | Tulu-3-IF-augmented-on-policy-8b [40] |
| UltraFeedback [17] | |
| Safety | hhh alignment [5], PKU-Safe [18] |
| SHP [24], Anthropic-hhrlhf [6] | |
| Image | |
| Chat | WildVision-Battle [62] |
| General | LLaVA-Critic [94], VL-Feedback [44], |
| RLAIF-V [101] MIA-DPO [54] | |
🔼 This table presents the performance comparison of various models on the VLRewardBench benchmark. The benchmark evaluates the quality of responses generated by large vision-language models (LVLMs) across multiple aspects, such as general understanding, hallucination detection, and reasoning abilities. The table shows the performance scores for each model in terms of accuracy across these aspects. Proprietary and open-source models are compared, with the best and second-best performances within each group highlighted for clarity.
read the caption
Table 3: Evaluation results on VLRewardBench [43]. The best and second-best results for proprietary models and open-source models are highlighted in bold and underlined, respectively.
In-depth insights#
Multimodal Reward#
Multimodal reward models represent a significant advancement in AI, particularly for large vision-language models (LVLMs). Their core function is to bridge the gap between model outputs and human preferences across diverse modalities, such as text, images, and video. Unlike unimodal reward models that focus solely on text, multimodal models offer a more holistic evaluation framework, leading to more natural and nuanced assessments of LVLMs. The challenge lies in creating high-quality, multi-modal datasets that accurately capture human judgment on the various combinations of input types. The effectiveness of a multimodal reward model hinges on its capacity to generalize across different domains and scenarios, not just perform well on specific, limited tasks. This generalizability is crucial for building robust and reliable LVLMs for real-world applications. Furthermore, the use of multimodal rewards facilitates effective reinforcement learning from human feedback (RLHF). It allows for better fine-tuning of LVLMs, leading to improved performance in instruction following, dialogue generation, and overall model safety.
RLHF & Test-Time#
The section on “RLHF & Test-Time” would explore the crucial role of reinforcement learning from human feedback (RLHF) and test-time techniques in enhancing Large Vision Language Models (LVLMs). RLHF, a key training methodology, uses reward models (RMs) to guide the LVLMs toward aligning with human preferences, thereby improving the quality and safety of their outputs. The discussion would likely highlight the challenges in creating effective multi-modal RMs, particularly the scarcity of publicly available datasets and the complexities of incorporating diverse modalities like images and videos into the training process. Test-time techniques, such as best-of-N sampling, further enhance LVLMs by leveraging RMs to select the best outputs from a set of candidate responses. The analysis would likely demonstrate how these two approaches complement each other to improve model performance and address limitations. The researchers might showcase empirical results that quantitatively show the benefits of RLHF in refining LVLMs through enhanced instruction following and multi-modal dialogue capabilities and the advantages of test-time scaling in selecting superior responses, leading to a substantial enhancement of the overall model’s efficiency and precision.
Benchmark Results#
Benchmark results are crucial for evaluating the effectiveness of any new model, and this paper is no exception. The authors meticulously present results across multiple benchmarks, showcasing superior performance of their InternLM-XComposer2.5-Reward model, especially on multi-modal benchmarks like VLRewardBench. The consistent outperformance across various metrics, even when compared against larger proprietary models, strongly suggests the model’s robustness and effectiveness. Further, the inclusion of results on text-only benchmarks allows for a comprehensive comparison, highlighting the model’s capability to generalize across different modalities. Specific numerical results from these benchmarks would be essential to fully assess the extent of the model’s improvements over existing models. However, the discussion of these results could be further strengthened by a deeper analysis of why the model outperforms others on certain tasks—providing insight into the model’s strengths and potential weaknesses.
Data Cleaning Use#
The application of InternLM-XComposer2.5-Reward for data cleaning is a significant contribution. It leverages the model’s ability to identify low-quality samples, such as those with hallucinations or mismatched content between image/video and text, by assigning low reward scores. This automated process greatly improves efficiency, replacing manual data cleaning which is time-consuming and prone to errors. The strong correlation between low reward scores and problematic samples highlights the model’s effectiveness as a filter for improving the quality of training data. This automated data filtering is particularly valuable for multi-modal datasets, where inconsistencies can be harder to detect manually. The open-sourcing of the model and its training recipes allows for broader adoption and further exploration of this data cleaning technique, fostering advancements in multi-modal training and improving the overall quality of LVLMs.
Future of Multimodal#
The future of multimodal AI hinges on several key factors. Data remains a critical bottleneck, with the need for larger, more diverse, and higher-quality datasets spanning various modalities and domains. Benchmarking and evaluation require significant improvements to accurately assess model performance across different tasks and modalities. While current benchmarks exist, they often lack the scope and sophistication needed to capture the full capabilities of these advanced systems. Model architectures need further refinement, moving beyond simple concatenation or fusion methods toward more sophisticated approaches that capture complex intermodal relationships. Explainability and interpretability are crucial, especially for high-stakes applications where trust and reliability are paramount. Finally, research into ethical considerations regarding bias, fairness, and potential misuse of multimodal systems is vital for responsible development and deployment.
More visual insights#
More on figures

🔼 Table 1 provides an overview of existing datasets used to train IXC-2.5-Reward, a multi-modal reward model. It categorizes the datasets based on their focus (Instruction Following, Safety, Chat, General) and lists specific dataset names for each category. This table highlights the diversity of data sources utilized in training the reward model, which contributes to its robustness and performance.
read the caption
Table 1: Overview of existing preference datasets used in IXC-2.5-Reward. IF denotes to Instruction Following.

🔼 Table 2 shows the sources of the newly collected dataset used to train the InternLM-XComposer2.5-Reward model. The dataset is categorized by data modality (image or text), and then further sub-categorized by the task or domain the data originates from. Each sub-category lists specific datasets used in the creation of the multi-modal preference data. This illustrates the diversity of data sources used to ensure the model’s robustness across various situations.
read the caption
Table 2: Overview of the source of newly collected data used in IXC-2.5-Reward.

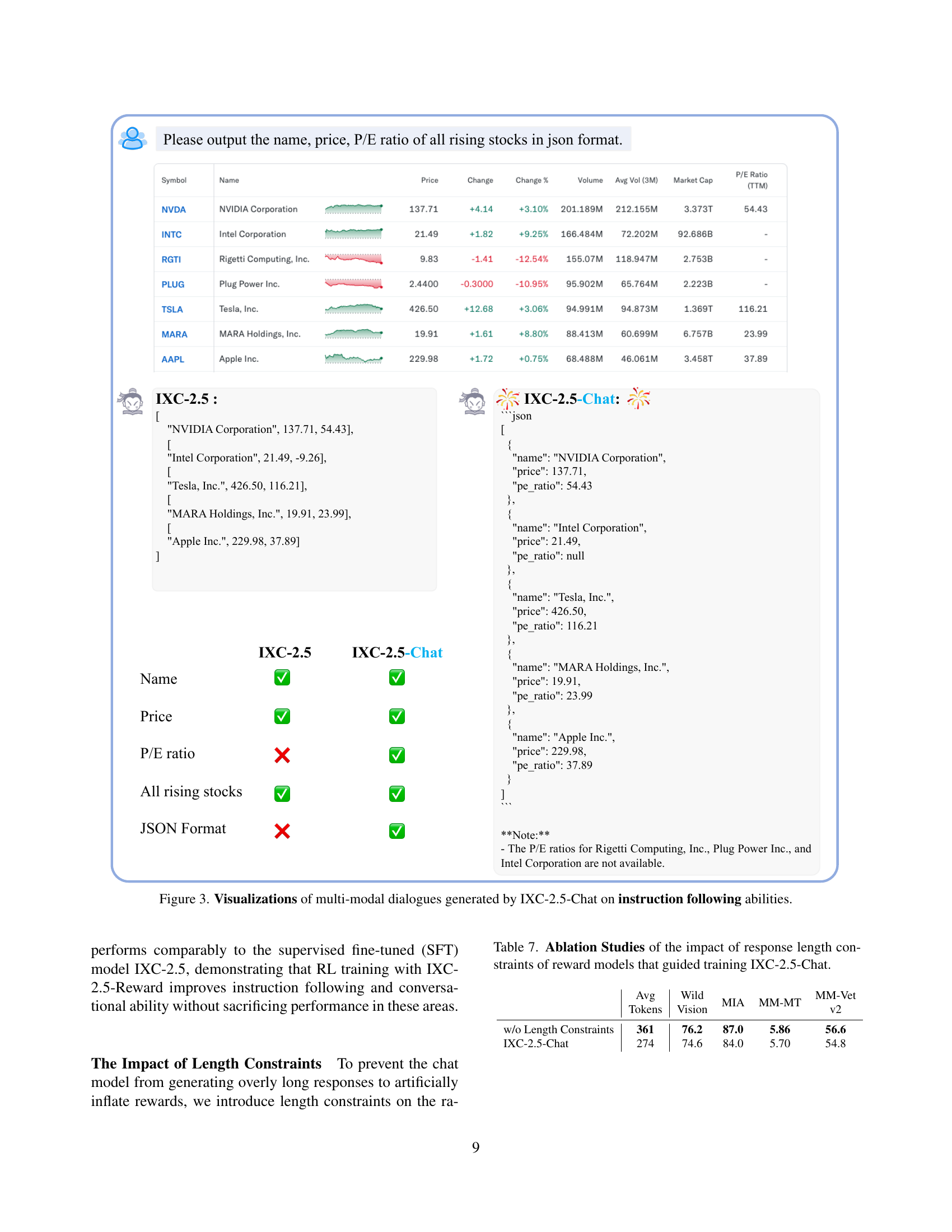
🔼 Figure 2 showcases examples of outlier and noisy data points identified by the InternLM-XComposer2.5-Reward model. These data points, sourced from the ALLaVA [10] and LLaVA-Video-178K [115] datasets, received low reward scores, indicating a mismatch between the model’s response and human expectations. The figure visually presents these examples, alongside human expert explanations of the errors, highlighting instances of hallucinations, missing answers, and misalignment between visual and textual content. These visualizations help illustrate how the IXC-2.5-Reward model facilitates data cleaning and improves the quality of training datasets for large vision-language models.
read the caption
Figure 2: Using IXC-2.5-Reward for Data Cleaning. We visualize the outlier and noisy examples detected by IXC-2.5-Reward with low reward scores from existing image and video instruction-tuning datasets, such as ALLaVA [10] and LLaVA-Video-178K [115]. The “Explain” refers to explanations of error causes as identified by human experts, rather than outputs generated by the reward model.
More on tables
| Category | Dataset |
|---|---|
| Image | |
| IF General | in-house (will release) |
| KVQA [76], A-OKVQA [73], PMC-VQA [114] | |
| Text-Rich | AI2D [37], IconQA [56], TQA [38] |
| ChartQA [63], DVQA [36], ScienceQA [57] | |
| Reasoning | GeoQA [11], CLEVR-Math [47] |
| Super-CLEVR [45], TabMWP [58] | |
| Video | |
| General | TrafficQA [96], FunQA [93], MiraData [35] |
🔼 This table presents a comparison of the performance of various reward models (RMs) on the Reward Bench benchmark [41]. It includes both language-only reward models (representing the state-of-the-art) and multi-modal generative reward models. The evaluation metrics cover several aspects, including the models’ performance on chat, chat hard, safety, and reasoning tasks. The table allows for a comparison of language-only RMs against multi-modal RMs, highlighting the strengths and weaknesses of each type of model in various aspects.
read the caption
Table 4: Evaluation results on Reward Bench [41]. We report the performance of selective representative language-only RMs and previous multi-modal generative RMs.
| Models | #Param | General | Hallucination | Reasoning | Overall Acc | Macro Acc |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| Gemini-1.5-Flash (2024-09-24) [83] | - | 47.8 | 59.6 | 58.4 | 57.6 | 55.3 |
| Gemini-1.5-Pro (2024-09-24) [83] | - | 50.8 | 72.5 | 64.2 | 67.2 | 62.5 |
| Claude-3.5-Sonnet (2024-06-22) [4] | - | 43.4 | 55.0 | 62.3 | 55.3 | 53.6 |
| GPT-4o-mini (2024-07-18) [3] | - | 41.7 | 34.5 | 58.2 | 41.5 | 44.8 |
| GPT-4o (2024-08-06) [3] | - | 49.1 | 67.6 | 70.5 | 65.8 | 62.4 |
| Open-Source Models | ||||||
| LLaVA-OneVision-7B-ov [42] | 7B | 32.2 | 20.1 | 57.1 | 29.6 | 36.5 |
| Qwen2-VL-7B [90] | 7B | 31.6 | 19.1 | 51.1 | 28.3 | 33.9 |
| Molmo-7B [20] | 7B | 31.1 | 31.8 | 56.2 | 37.5 | 39.7 |
| InternVL2-8B [85] | 8B | 35.6 | 41.1 | 59.0 | 44.5 | 45.2 |
| LLaVA-Critic-8B [94] | 8B | 54.6 | 38.3 | 59.1 | 41.2 | 44.0 |
| Llama-3.2-11B [84] | 11B | 33.3 | 38.4 | 56.6 | 42.9 | 42.8 |
| Pixtral-12B [1] | 12B | 35.6 | 25.9 | 59.9 | 35.8 | 40.4 |
| Molmo-72B [20] | 72B | 33.9 | 42.3 | 54.9 | 44.1 | 43.7 |
| Qwen2-VL-72B [90] | 72B | 38.1 | 32.8 | 58.0 | 39.5 | 43.0 |
| NVLM-D-72B [19] | 72B | 38.9 | 31.6 | 62.0 | 40.1 | 44.1 |
| Llama-3.2-90B [84] | 90B | 42.6 | 57.3 | 61.7 | 56.2 | 53.9 |
| IXC-2.5-Reward (Ours) | 7B | 84.7 | 62.5 | 62.9 | 65.8 | 70.0 |
🔼 This table presents the performance of various reward models on the RM-Bench benchmark [51]. Reward models are categorized into three types: sequence classifiers, generative models, and implicit DPO models. The evaluation considers four domains (Chat, Math, Code, Safety) and three difficulty levels (Easy, Normal, Hard) for each domain, providing a comprehensive assessment of the models’ performance across various tasks and complexities. The average score across all domains and difficulty levels is also provided for each model.
read the caption
Table 5: Evaluation results on RM-Bench [51]. We classify reward models into three types: sequence classifiers (Seq.), generative models, and implicit DPO models. Performance is reported across four domains (Chat, Math, Code, Safety) and three difficulty levels (Easy, Normal, Hard), along with average scores (Avg).
| Model Name | LLM | Chat | Chat Hard | Safety | Reasoning | Avg Score |
|---|---|---|---|---|---|---|
| Language-Only Reward Models | ||||||
| InternLM2-7B-Reward [8] | InternLM2-7B | 99.2 | 69.5 | 87.2 | 94.5 | 87.6 |
| InternLM2-20B-Reward [8] | InternLM2-20B | 98.9 | 76.5 | 89.5 | 95.8 | 90.2 |
| Skyword-Reward-Llama3.1-8B [48] | Llama3.1-8B | 95.8 | 87.3 | 90.8 | 96.2 | 92.5 |
| INF-ORM-Llama3.1-70B [97] | Llama3.1-70B | 96.6 | 91.0 | 93.6 | 99.1 | 95.1 |
| Multi-Modal Reward Models | ||||||
| QWen2-VL-7B [90] | QWen2-7B | 96.6 | 57.0 | 73.9 | 94.3 | 83.8 |
| LLaVA-Critic-8B [94] | LLaMA3-7B | 96.9 | 52.8 | 81.7 | 83.5 | 80.0 |
| IXC-2.5-Reward (Ours) | InternL2-7B | 90.8 | 83.8 | 87.8 | 90.0 | 88.6 |
🔼 This table compares the performance of the IXC-2.5-Chat model against state-of-the-art (SOTA) proprietary and open-source models with parameters less than or equal to 10 billion. The results are sourced from the OpenVLM Leaderboard and the Open LMM Reasoning Leaderboard, accessed on January 1st, 2025. The table presents a performance evaluation across multiple categories (Instruction Following & Chat, Knowledge, Reasoning, Text-Rich) and benchmarks within those categories. Best and second-best results for each benchmark are highlighted to showcase the relative strengths and weaknesses of IXC-2.5-Chat.
read the caption
Table 6: Evaluation results of our IXC-2.5-Chat model against previous SOTA proprietary and open-source models ≤\leq≤10B (results are copied from OpenVLM Leaderboard and Open LMM Reasoning Leaderboard, accessed 01-Jan-2025). Best and second best results are highlighted.
| Model Name | Type | Chat | Math | Code | Safety | Easy | Normal | Hard | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Language-Only Reward Models | |||||||||
| Tulu-2-dpo-13b [32] | Implicit | 66.4 | 51.4 | 51.8 | 85.4 | 86.9 | 66.7 | 37.7 | 63.8 |
| InternLM2-7B-Reward [8] | Seq. | 61.7 | 71.4 | 49.7 | 85.5 | 85.4 | 70.7 | 45.1 | 67.1 |
| InternLM2-20B-Reward [8] | Seq. | 63.1 | 66.8 | 56.7 | 86.5 | 82.6 | 71.6 | 50.7 | 68.3 |
| Nemotron-4-340B-Reward [92] | Generative | 71.2 | 59.8 | 59.4 | 87.5 | 81.0 | 71.4 | 56.1 | 69.5 |
| URM-LLaMa-3.1-8B [55] | Seq. | 71.2 | 61.8 | 54.1 | 93.1 | 84.0 | 73.2 | 53.0 | 70.0 |
| Skyword-Reward-Llama3.1-8B [48] | Seq. | 69.5 | 60.6 | 54.5 | 95.7 | 89.0 | 74.7 | 46.6 | 70.1 |
| Multi-Modal Reward Models | |||||||||
| IXC-2.5-Reward (Ours) | Seq. | 65.5 | 55.9 | 51.7 | 93.8 | 87.5 | 71.3 | 47.4 | 68.8 |
🔼 This table presents the results of ablation studies investigating the effect of response length constraints on the performance of the IXC-2.5-Chat model. The study examined how different length constraints during training, specifically with and without constraints, affected the model’s performance across several benchmarks. These benchmarks assess various aspects of the model’s capabilities, including instruction following, visual question answering, and overall performance. The metrics used likely include accuracy, token count, and other relevant measures of model quality. The purpose of this ablation study is to demonstrate how the length constraint in the reward model design impacts the overall quality and performance of the resulting chatbot.
read the caption
Table 7: Ablation Studies of the impact of response length constraints of reward models that guided training IXC-2.5-Chat.
| Category | Benchmark | Evaluation | Proprietary API | Open-Source Model (10B) | ||
| Previous-SOTA | Previous-SOTA | IXC-2.5 | IXC-2.5-Chat | |||
| Instruction | WildVision(0617) [62] | Open | 89.2 [31] | 67.3 [94] | 37.5 | 74.6 |
| Following | MIA [68] | Open | 88.6 [31] | 80.7 [90] | 80.4 | 84.0 |
| & Chat | MM-MT [1] | Open | 7.72 [31] | 5.45 [90] | 3.85 | 5.70 |
| MM-Vet v2 [103] | Open | 71.8 [4] | 58.1 [14] | 45.8 | 54.8 | |
| Knowledge | MMBench [52] | MCQ | 85.7 [74] | 82.7 [61] | 79.4 | 79.0 |
| MMMU [106] | MCQ | 70.7 [31] | 56.2 [14] | 42.9 | 44.1 | |
| MMStar [12] | MCQ | 72.7 [74] | 63.2 [14] | 59.9 | 59.6 | |
| Reasoning | MathVista [59] | VQA | 78.4 [74] | 66.5 [60] | 63.7 | 63.4 |
| MathVerse [113] | VQA | 54.8 [26] | 26.6 [50] | 16.2 | 19.0 | |
| MathVision [89] | VQA | 43.6 [26] | 22.0 [50] | 17.8 | 18.8 | |
| Text-Rich | TextVQA [79] | VQA | 82.0 [64] | 78.5 [42] | 78.2 | 81.3 |
| ChartQA [63] | VQA | 81.2 [64] | 82.4 [99] | 82.2 | 80.5 | |
| OCRBench [49] | VQA | 89.4 [74] | 82.2 [14] | 69.0 | 70.0 | |
🔼 This table presents the results of using the Best-of-N (BoN) sampling technique to improve the test-time performance of the IXC-2.5-Chat model. BoN involves generating multiple outputs for a given input and selecting the one with the highest score according to the IXC-2.5-Reward model. The table shows the impact of BoN on various metrics, including average token length and performance scores across different benchmarks like WildVision, MIA, MM-MT, and MM-Vet.
read the caption
Table 8: Results of Best-of-N𝑁Nitalic_N (BoN) sampling for test-time scaling with IXC-2.5-Reward.
Full paper#