TL;DR#
Existing monocular depth estimation models struggle with temporal inconsistency when processing videos, limiting their use in applications requiring consistent depth across video frames. This inconsistency is especially problematic for long videos. Researchers have tried to solve this using video generation models or optical flow and camera pose data; however, these methods are inefficient or only work on short videos.
This research introduces “Video Depth Anything,” which uses Depth Anything V2 as a base and adds a new spatial-temporal head and a temporal consistency loss. This solves the temporal inconsistency problem while maintaining efficiency. The key-frame-based inference strategy allows processing of very long videos. Extensive testing demonstrates state-of-the-art performance in both accuracy and consistency, setting a new standard for video depth estimation.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of existing monocular depth estimation models: temporal inconsistency in videos. This significantly expands the applicability of depth estimation to various fields like robotics and AR/VR, opening new avenues for research in high-quality, efficient video processing. The proposed approach’s success in handling super-long videos is a notable advancement and could inspire further work in efficient and consistent video analysis.
Visual Insights#

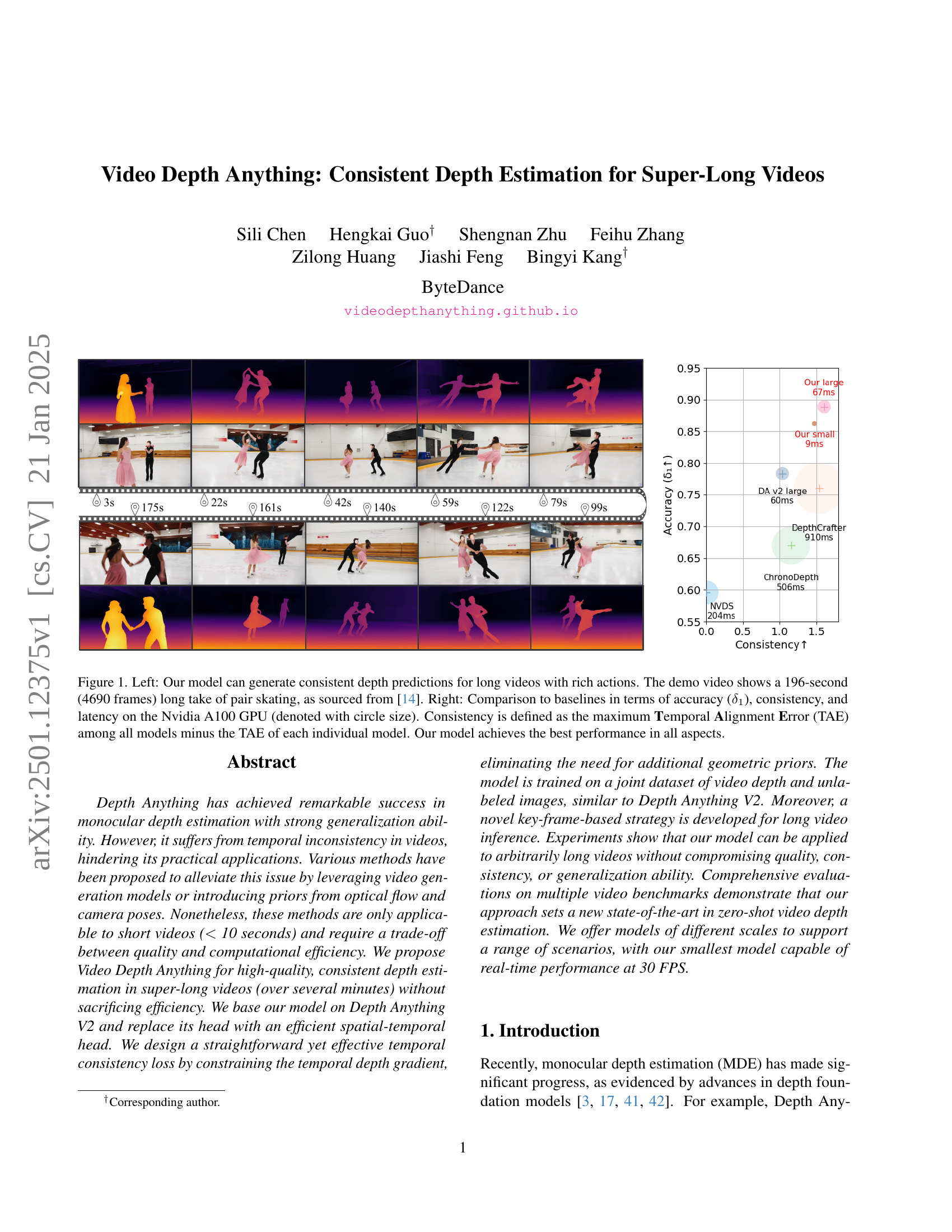
🔼 Figure 1 demonstrates the model’s capabilities in two aspects. The left panel showcases the model’s ability to generate consistent depth maps for a long video (196 seconds, 4690 frames) depicting pair figure skating. This highlights the model’s performance on complex, real-world actions within extended video sequences. The right panel presents a quantitative comparison against several baseline methods, using three key metrics: accuracy (δ1), consistency (measured as the difference between the maximum Temporal Alignment Error (TAE) across all models and the individual model’s TAE), and inference speed (latency) on an Nvidia A100 GPU. Circle size in the chart represents latency. The results show that the proposed model outperforms the baselines across all three metrics, indicating superior performance in both accuracy and temporal consistency for long-form video depth estimation.
read the caption
Figure 1: Left: Our model can generate consistent depth predictions for long videos with rich actions. The demo video shows a 196-second (4690 frames) long take of pair skating, as sourced from [14]. Right: Comparison to baselines in terms of accuracy (δ1subscript𝛿1\delta_{1}italic_δ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT), consistency, and latency on the Nvidia A100 GPU (denoted with circle size). Consistency is defined as the maximum Temporal Alignment Error (TAE) among all models minus the TAE of each individual model. Our model achieves the best performance in all aspects.
| Method / Metrics | KITTI [11] | Scannet [7] | Bonn [24] | NYUv2 [22] | Sintel [5](~50 frames) | Scannet (170 frames[40]) | Rank | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | TAE (↓) | ||
| DAv2-L [42] | 0.137 | 0.815 | 0.150 | 0.768 | 0.127 | 0.864 | 0.094 | 0.928 | 0.390 | 0.541 | 1.140 | 3.6 |
| NVDS [38] | 0.233 | 0.614 | 0.207 | 0.628 | 0.199 | 0.674 | 0.217 | 0.598 | 0.408 | 0.464 | 2.176 | 6.8 |
| NVDS [38] + DAv2-L [42] | 0.227 | 0.617 | 0.194 | 0.658 | 0.191 | 0.700 | 0.184 | 0.679 | 0.449 | 0.503 | 2.536 | 5.8 |
| ChoronDepth [32] | 0.243 | 0.576 | 0.199 | 0.665 | 0.199 | 0.665 | 0.173 | 0.771 | 0.192 | 0.673 | 1.022 | 5.2 |
| DepthCrafter [13] | 0.164 | 0.753 | 0.169 | 0.730 | 0.153 | 0.803 | 0.141 | 0.822 | 0.299 | 0.695 | 0.639 | 3.4 |
| DepthAnyVideo [40] | - | - | - | - | - | - | - | - | 0.405 | 0.659 | 0.967 | - |
| VDA-S (Ours) | 0.086 | 0.942 | 0.110 | 0.876 | 0.083 | 0.950 | 0.077 | 0.959 | 0.339 | 0.584 | 0.703 | 2.6 |
| VDA-L (Ours) | 0.083 | 0.944 | 0.089 | 0.926 | 0.071 | 0.959 | 0.062 | 0.971 | 0.295 | 0.644 | 0.570 | 1.6 |
🔼 This table presents a quantitative comparison of the proposed Video Depth Anything (VDA) model’s performance on five video datasets against several state-of-the-art methods for zero-shot video depth estimation. The metrics used to evaluate the models are Absolute Relative Error (AbsRel), δ1 (delta-one), and Temporal Alignment Error (TAE). The table shows both VDA model variants (VDA-S with a smaller ViT backbone and VDA-L with a larger ViT backbone), allowing for a comparison of performance versus model size and computational cost. The best and second-best results for each metric and dataset are highlighted to clearly show the model’s superior performance. This comparison includes both single-image depth estimation methods and methods specifically designed for videos.
read the caption
Table 1: Zero-shot video depth estimation results. We compare with representative single-image [42] and video depth estimation models [38, 32, 13, 40]. “VDA-S” denotes our model with ViT-Small backbone. “VDA-L” denotes our model with ViT-Large backbone. The best and the second best results are highlighted.
In-depth insights#
Long Video Depth#
The concept of “Long Video Depth” in the context of this research paper addresses the challenge of accurately estimating depth in videos that extend beyond the typical short durations handled by existing models. The paper highlights the limitations of current methods which struggle with temporal inconsistency, leading to flickering and motion blur. The core innovation lies in addressing this temporal inconsistency by introducing a novel spatial-temporal head and a temporal gradient matching loss, improving depth estimations in long videos. The proposed model successfully handles super-long video sequences by employing a key-frame-based inference strategy, ensuring both computational efficiency and accuracy. The results demonstrate the ability to maintain high-quality, consistent depth predictions even with significantly extended video durations, surpassing existing state-of-the-art models. A significant contribution is the ability to handle arbitrary video lengths without sacrificing quality or efficiency, showcasing substantial improvements for long-form video applications in robotics, augmented reality, and beyond.
Temporal Consistency#
Temporal consistency in video depth estimation is crucial for realistic applications. Inconsistent depth maps, resulting in flickering or motion blur, severely hinder the use of depth data in areas like augmented reality or robotics. The paper tackles this problem directly by focusing on methods to maintain smooth and consistent depth across video frames. This involves not only improving the accuracy of individual depth predictions but also ensuring a stable temporal gradient, which prevents abrupt changes in estimated depth over time. The proposed temporal gradient matching loss is particularly innovative, offering a direct and efficient approach to enforcing temporal consistency without relying on additional geometric priors or computationally intensive methods like optical flow warping. This is a significant advancement, as reliance on optical flow can introduce further errors, undermining the overall accuracy. The key-frame-based inference strategy for super-long videos is another notable contribution, allowing the model to handle extended sequences effectively, paving the way for practical applications involving longer videos, where temporal stability is paramount.
STH Architecture#
The STH (Spatio-Temporal Head) architecture is a crucial component of the proposed Video Depth Anything model. It cleverly integrates temporal information processing into the existing Depth Anything V2 architecture, enhancing its capabilities for video depth estimation. The key innovation is the incorporation of temporal attention layers within STH, enabling the model to learn robust temporal dependencies among video frames without explicit reliance on optical flow or geometric constraints. This is a significant departure from previous approaches which often suffer from the accumulation of errors or computational inefficiency. By carefully designing this attention mechanism within the head, rather than as a separate module, the authors aim to preserve the efficiency and generalization ability of the original Depth Anything V2 encoder, while significantly boosting temporal consistency. The use of a straightforward yet effective temporal gradient matching loss further refines the depth prediction, directly constraining temporal depth gradients and avoiding the complications of warping techniques. This modular design is also significant in that it allows for easy adaptation and scalability to various video lengths. This is achieved through a key-frame based strategy and novel processing techniques that efficiently handles long videos during inference without sacrificing performance or consistency. Overall, the STH architecture presents a well-integrated and efficient solution to the longstanding problem of temporal inconsistency in video depth estimation.
Ablation Studies#
The ablation study section of the research paper is crucial for understanding the contribution of individual components to the overall performance. It systematically removes or alters parts of the model (e.g., loss functions, network modules, training strategies) to isolate their impact. The results from these experiments provide strong evidence supporting the design choices. For instance, by comparing different temporal consistency loss functions, the authors demonstrate the superiority of their proposed TGM loss over alternatives like OPW, highlighting its robustness and efficiency. Similarly, the ablation of various inference strategies reveals the importance of the key-frame-based approach for handling super-long videos. These findings not only validate the design choices but also offer insights into the relative importance of different aspects of the model. In particular, the impact of choosing a specific loss function is clearly visible, as is the importance of handling very long video sequences. Ultimately, the ablation study strengthens the paper’s claims by providing a clear understanding of each component’s contribution to the overall success and demonstrates a rigorous approach to model development.
Future Directions#
Future research should focus on improving the model’s robustness to various challenging conditions, such as low light, adverse weather, and motion blur. Expanding the dataset with more diverse and higher-quality video data, especially focusing on long videos with rich annotations, will be critical for enhancing the model’s generalization capability. Addressing computational efficiency remains a key challenge; exploring more efficient architectures and training strategies is crucial for real-time applications. Finally, investigating the integration of Video Depth Anything with other computer vision tasks like object detection, tracking, and scene understanding could open up new avenues of research and create impactful applications in areas such as autonomous driving, robotics, and augmented reality.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architecture of the Video Depth Anything model. The left panel shows the overall pipeline, highlighting the joint training process on video data with ground truth depth and unlabeled images with pseudo labels generated by a teacher model. Only the spatio-temporal head is trained, keeping the Depth Anything V2 encoder frozen. The right panel focuses on the details of the spatio-temporal head, showing how it’s built upon the DPT head [28] by incorporating multiple temporal attention layers. This design aims to effectively integrate temporal information for consistent depth estimation without significantly altering the existing DPT architecture.
read the caption
Figure 2: Overall pipeline and the spatio-temporal head. Left: Our model is composed of a backbone encoder from Depth Anything V2 and a newly proposed spatio-temporal head. We jointly train our model on video data using ground-truth depth labels for supervision and on unlabeled images with pseudo labels generated by a teacher model. During training, only the head is learned. Right: Our spatiotemporal head inserts several temporal layers into the DPT head, while preserving the original structure of DPT head [28].

🔼 This figure illustrates the inference strategy used for processing long videos. The model processes the video in segments. Each segment includes future frames, overlapping frames from the previous segment, and keyframes selected from even further back. This approach ensures temporal consistency by using overlapping frames for alignment and keyframes to maintain consistent scale and shift across segments. The specific parameters used are N (total frames in segment) = 32, To (overlapping frames) = 8, Tk (key frames) = 2, and Δk (interval between keyframes) = 12.
read the caption
Figure 3: Inference strategy for long videos. N𝑁Nitalic_N is the video clip lenght consumed by our model. Each inference video clip is built by N−To−Tk𝑁subscript𝑇𝑜subscript𝑇𝑘N-T_{o}-T_{k}italic_N - italic_T start_POSTSUBSCRIPT italic_o end_POSTSUBSCRIPT - italic_T start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT future frames, Tosubscript𝑇𝑜T_{o}italic_T start_POSTSUBSCRIPT italic_o end_POSTSUBSCRIPT overlapping/adjacent frames, and Tksubscript𝑇𝑘T_{k}italic_T start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT key frames. The key frames are selected by taking every ΔksubscriptΔ𝑘\Delta_{k}roman_Δ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT-th frame going backward. Then, the new depth predictions will be scale-shift-aligned to the previous frames based on the Tksubscript𝑇𝑘T_{k}italic_T start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT overlapping frames. We use N=32,To=8,Tk=2,Δk=12formulae-sequence𝑁32formulae-sequencesubscript𝑇𝑜8formulae-sequencesubscript𝑇𝑘2subscriptΔ𝑘12N=32,T_{o}=8,T_{k}=2,\Delta_{k}=12italic_N = 32 , italic_T start_POSTSUBSCRIPT italic_o end_POSTSUBSCRIPT = 8 , italic_T start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = 2 , roman_Δ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = 12.

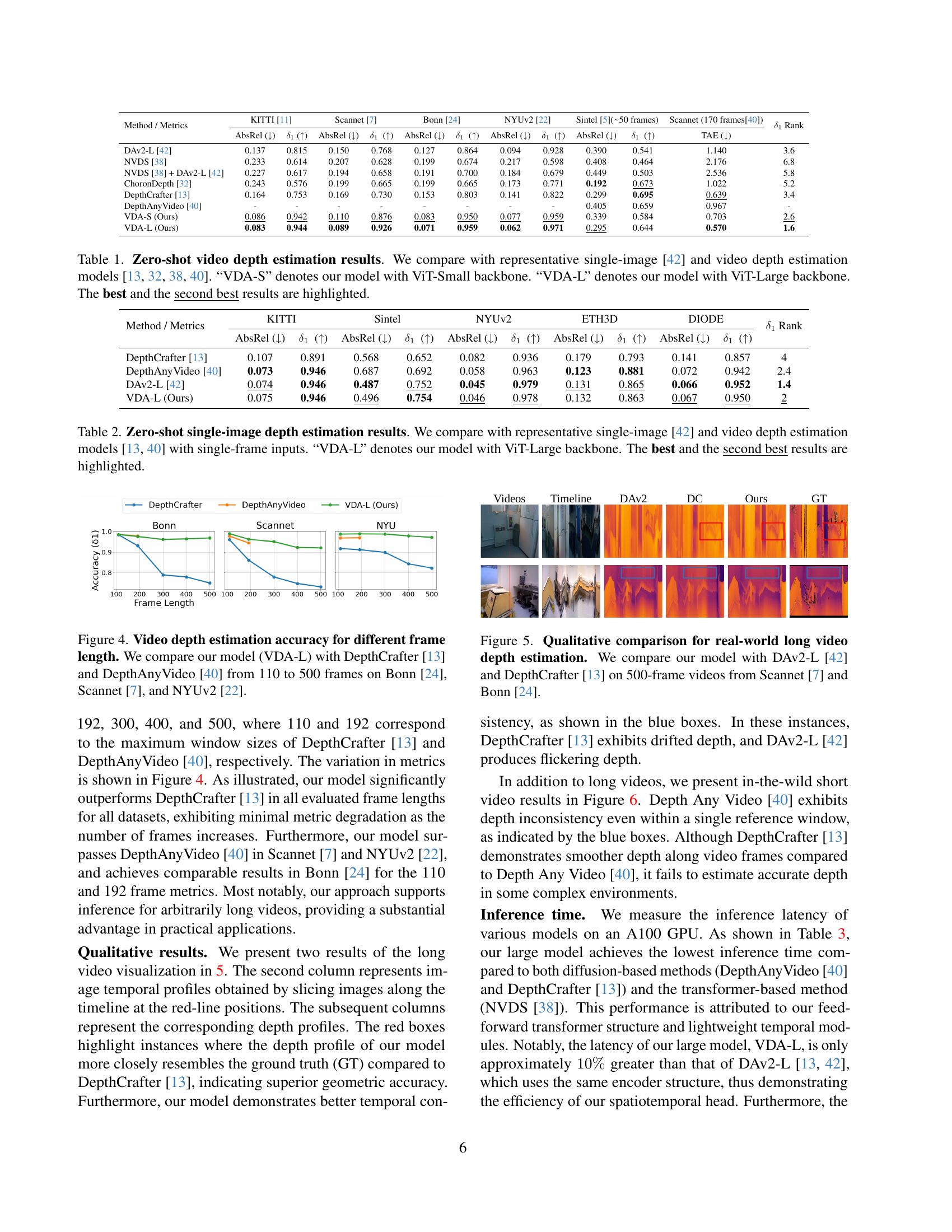
🔼 This figure displays a comparison of video depth estimation accuracy across varying video lengths. The accuracy (δ₁) of three different models—the authors’ Video Depth Anything (VDA-L), DepthCrafter [13], and DepthAnyVideo [40]—is assessed using the metrics AbsRel and δ₁ for video lengths ranging from 110 to 500 frames. The comparison is made across three distinct datasets: Bonn [24], Scannet [7], and NYUv2 [22], to demonstrate the performance of the proposed model (VDA-L) in handling long videos.
read the caption
Figure 4: Video depth estimation accuracy for different frame length. We compare our model (VDA-L) with DepthCrafter [13] and DepthAnyVideo [40] from 110 to 500 frames on Bonn [24], Scannet [7], and NYUv2 [22].

🔼 Figure 5 presents a qualitative comparison of real-world long-video depth estimation results. Three models are compared: the authors’ proposed Video Depth Anything model, DepthCrafter [13], and Depth Anything v2 [42]. The comparison uses 500-frame video sequences from the Scannet [7] and Bonn [24] datasets. The figure visually demonstrates the performance differences between the models in terms of depth accuracy and temporal consistency. It highlights instances where the authors’ model produces superior depth estimates, particularly in scenarios with complex lighting or object movement, indicating better handling of challenging real-world conditions.
read the caption
Figure 5: Qualitative comparison for real-world long video depth estimation. We compare our model with DAv2-L [42] and DepthCrafter [13] on 500-frame videos from Scannet [7] and Bonn [24].

🔼 This figure shows a qualitative comparison of depth estimation results for short, in-the-wild videos. Four different methods are compared: Depth-Anything-V2, DepthCrafter, DepthAnyVideo, and the proposed method. The methods are evaluated on videos from the DAVIS dataset, all under 100 frames. Red boxes highlight examples where the depth estimations are incorrect, while blue boxes point to inconsistencies in the depth maps over time. This visualization demonstrates the relative strengths and weaknesses of each method in terms of accuracy and temporal consistency for short, real-world video sequences.
read the caption
Figure 6: Qualitative comparison for in-the-wild short video depth estimation. We compare with Depth-Anything-V2 [42], DepthCrafter [13] and DepthAnyVideo [40] on videos with less than 100 frames from DAVIS [26]. Red boxes show incorrect depth estimation while blue boxes show inconsistent depth estimation.

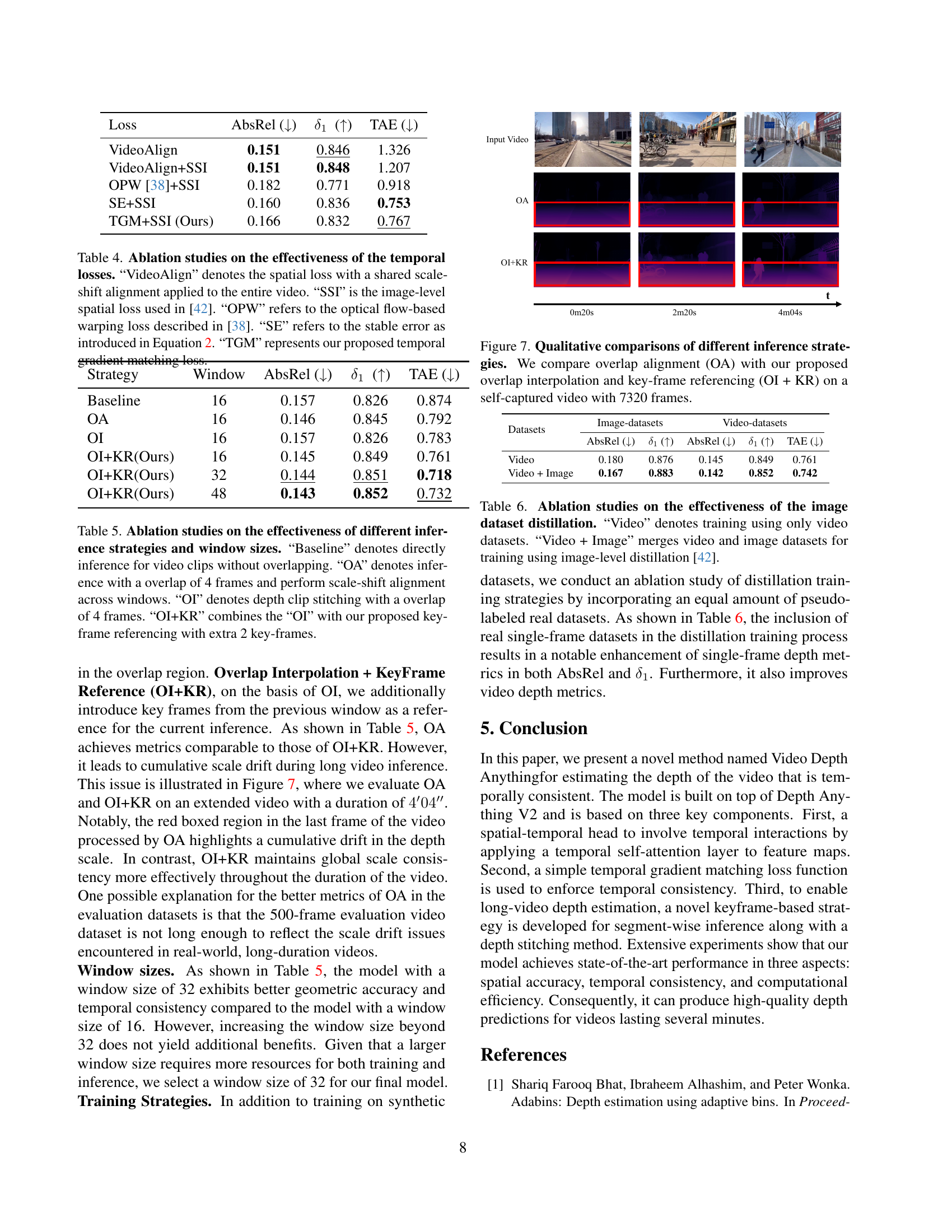
🔼 This figure compares two different inference strategies for processing super-long videos (videos with over 7000 frames): overlap alignment (OA) and overlap interpolation with key-frame referencing (OI+KR). OA simply concatenates results from sequentially processed video segments. OI+KR, the authors’ proposed method, uses overlapping segments and keyframes to maintain temporal consistency and avoid accumulating errors over very long videos. The figure visually demonstrates how OI+KR produces significantly smoother and more accurate depth estimations compared to OA, especially over extended durations.
read the caption
Figure 7: Qualitative comparisons of different inference strategies. We compare overlap alignment (OA) with our proposed overlap interpolation and key-frame referencing (OI + KR) on a self-captured video with 7320 frames.

🔼 Figure 8 presents a qualitative comparison of static image depth estimation results from four different models: the proposed Video Depth Anything model, Depth-Anything-V2, DepthCrafter, and Depth Any Video. The figure visually demonstrates the depth maps generated by each model for several example images. This allows for a direct comparison of the accuracy and detail present in each model’s depth prediction. The results showcase that the proposed model achieves comparable performance to Depth-Anything-V2 in terms of visualization quality, suggesting a successful transfer of the strong image depth estimation capabilities of Depth-Anything-V2 to the video domain.
read the caption
Figure 8: Qualitative comparison for static image depth estimation. We compare our model with Depth-Anything-V2 [42], DepthCrafter [13], and Depth Any Video [40] on static image depth estimation. Our model demonstrates visualization results comparable to those of Depth-Anything-V2 [42].

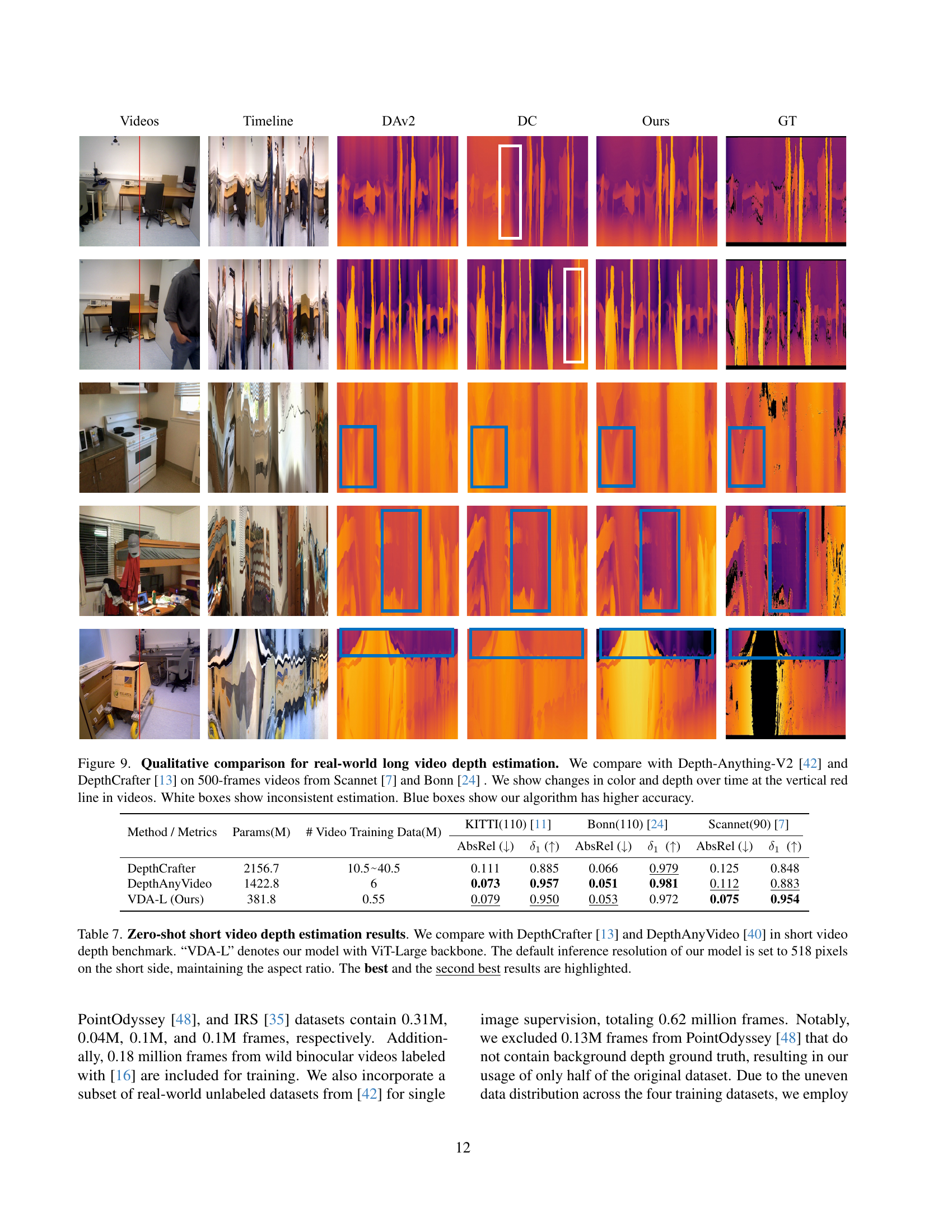
🔼 Figure 9 presents a qualitative comparison of real-world long-video depth estimation results. It compares the model’s performance against Depth-Anything-V2 and DepthCrafter on videos containing 500 frames from the Scannet and Bonn datasets. The figure visually demonstrates the temporal consistency (or inconsistency) of the depth estimation across the video sequence by highlighting changes in color and depth over time along vertical red lines. White boxes highlight areas where depth estimation is inconsistent, whereas blue boxes highlight areas where the proposed method shows higher accuracy than the baselines. This allows for a visual assessment of temporal consistency and accuracy comparison.
read the caption
Figure 9: Qualitative comparison for real-world long video depth estimation. We compare with Depth-Anything-V2 [42] and DepthCrafter [13] on 500-frames videos from Scannet [7] and Bonn [24] . We show changes in color and depth over time at the vertical red line in videos. White boxes show inconsistent estimation. Blue boxes show our algorithm has higher accuracy.

🔼 This figure illustrates a temporal layer within the spatiotemporal head of the Video Depth Anything model. The input features undergo a transformation to prepare them for the temporal attention mechanism. The temporal attention operates along the temporal dimension (number of frames), allowing the model to effectively capture and utilize the temporal relationships between frames within the input video sequence. The output features then return to the original shape for further processing. This layer is crucial for maintaining temporal consistency in the final depth prediction.
read the caption
Figure 10: Temporal layer. The feature shape is adjusted for temporal attention.

🔼 This figure demonstrates the application of the Video Depth Anything model to generate a 3D video from a standard 2D video. The input video is sourced from the DAVIS dataset [26]. The model processes the 2D video frames, estimating depth information for each frame. This depth information is then used to reconstruct a 3D representation of the scene, effectively converting the original 2D video into a 3D video. This showcases the model’s ability to not only estimate depth accurately but also to utilize that depth information for higher-level tasks such as 3D video generation.
read the caption
Figure 11: 3D Video Conversion. A video from the DAVIS dataset [26] is transformed into a 3D video using our model.
More on tables
| Method / Metrics | KITTI | Sintel | NYUv2 | ETH3D | DIODE | Rank | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | ||
| DepthCrafter [13] | 0.107 | 0.891 | 0.568 | 0.652 | 0.082 | 0.936 | 0.179 | 0.793 | 0.141 | 0.857 | 4 |
| DepthAnyVideo [40] | 0.073 | 0.946 | 0.687 | 0.692 | 0.058 | 0.963 | 0.123 | 0.881 | 0.072 | 0.942 | 2.4 |
| DAv2-L [42] | 0.074 | 0.946 | 0.487 | 0.752 | 0.045 | 0.979 | 0.131 | 0.865 | 0.066 | 0.952 | 1.4 |
| VDA-L (Ours) | 0.075 | 0.946 | 0.496 | 0.754 | 0.046 | 0.978 | 0.132 | 0.863 | 0.067 | 0.950 | 2 |
🔼 This table presents a comparison of zero-shot single-image depth estimation methods. Several models, including DepthCrafter [13], DepthAny Video [40], and Depth Anything V2 [42], are evaluated alongside the authors’ model (VDA-L, using a ViT-Large backbone) on the task of estimating depth from a single input image. The evaluation metrics assess the accuracy of the depth maps generated by each method. The best and second-best performing models for each metric are highlighted.
read the caption
Table 2: Zero-shot single-image depth estimation results. We compare with representative single-image [42] and video depth estimation models [13, 40] with single-frame inputs. “VDA-L” denotes our model with ViT-Large backbone. The best and the second best results are highlighted.
| Method | Precision | Latency (ms) |
|---|---|---|
| ChronoDepth | FP16 | 506 |
| DepthCrafter | FP16 | 910 |
| DepthAnyVideo | FP16 | 159 |
| NVDS | FP32 | 204 |
| DAv2-L | FP32 | 60 |
| VDA-L (Ours) | FP32 | 67 |
| VDA-S (Ours) | FP32 | 9.1 |
🔼 This table presents the inference time (in milliseconds) for different video depth estimation methods. The measurements were conducted on a single NVIDIA A100 GPU, processing frames with a resolution of 518x518 pixels. The table compares various models and shows their efficiency in processing a single video frame.
read the caption
Table 3: Inference latency comparisons for video depth estimation. We measure average runtime for each frame on a single A100 GPU with a resolution of 518×518518518518\times 518518 × 518.
| Loss | AbsRel (↓) | (↑) | TAE (↓) |
|---|---|---|---|
| VideoAlign | 0.151 | 0.846 | 1.326 |
| VideoAlign+SSI | 0.151 | 0.848 | 1.207 |
| OPW [38]+SSI | 0.182 | 0.771 | 0.918 |
| SE+SSI | 0.160 | 0.836 | 0.753 |
| TGM+SSI (Ours) | 0.166 | 0.832 | 0.767 |
🔼 This table presents an ablation study comparing different temporal consistency loss functions for video depth estimation. The goal is to determine which loss function best maintains temporal consistency in video depth predictions. Several methods are compared, including a baseline (VideoAlign) that uses a simple spatial loss with scale-shift alignment across the entire video, an optical flow-based method (OPW), a stable error loss (SE), and the proposed temporal gradient matching loss (TGM). Each method is combined with a scale-shift invariant spatial loss (SSI). The results show the impact of each loss on the absolute relative error (AbsRel), the δ1 metric (a measure of accuracy), and the temporal alignment error (TAE, a measure of consistency).
read the caption
Table 4: Ablation studies on the effectiveness of the temporal losses. “VideoAlign” denotes the spatial loss with a shared scale-shift alignment applied to the entire video. “SSI” is the image-level spatial loss used in [42]. “OPW” refers to the optical flow-based warping loss described in [38]. “SE” refers to the stable error as introduced in Equation 2. “TGM” represents our proposed temporal gradient matching loss.
| Strategy | Window | AbsRel (↓) | (↑) | TAE (↓) |
|---|---|---|---|---|
| Baseline | 16 | 0.157 | 0.826 | 0.874 |
| OA | 16 | 0.146 | 0.845 | 0.792 |
| OI | 16 | 0.157 | 0.826 | 0.783 |
| OI+KR(Ours) | 16 | 0.145 | 0.849 | 0.761 |
| OI+KR(Ours) | 32 | 0.144 | 0.851 | 0.718 |
| OI+KR(Ours) | 48 | 0.143 | 0.852 | 0.732 |
🔼 This table presents an ablation study comparing different inference strategies for processing super-long videos in the context of video depth estimation. The strategies are compared in terms of their impact on depth estimation accuracy (AbsRel and δ1) and temporal consistency (TAE). The strategies investigated include a baseline with no overlap, an approach using overlap and scale-shift alignment, a method involving overlap and depth clip stitching, and a combination of stitching with key-frame referencing. The impact of varying the window size is also explored.
read the caption
Table 5: Ablation studies on the effectiveness of different inference strategies and window sizes. “Baseline” denotes directly inference for video clips without overlapping. “OA” denotes inference with a overlap of 4 frames and perform scale-shift alignment across windows. “OI” denotes depth clip stitching with a overlap of 4 frames. “OI+KR” combines the “OI” with our proposed key-frame referencing with extra 2 key-frames.
| Datasets | Image-datasets | Video-datasets | |||
|---|---|---|---|---|---|
| AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | TAE (↓) | |
| Video | 0.180 | 0.876 | 0.145 | 0.849 | 0.761 |
| Video + Image | 0.167 | 0.883 | 0.142 | 0.852 | 0.742 |
🔼 This table presents the results of an ablation study investigating the impact of incorporating image data distillation into the training process of a video depth estimation model. The study compares the model’s performance when trained exclusively on video data versus when trained on a combination of video and image data using image-level distillation, as described in the referenced work [42]. The results are likely presented using metrics that assess the accuracy and consistency of the model’s depth estimations.
read the caption
Table 6: Ablation studies on the effectiveness of the image dataset distillation. “Video” denotes training using only video datasets. “Video + Image” merges video and image datasets for training using image-level distillation [42].
| Method / Metrics | Params(M) | # Video Training Data(M) | KITTI(110) [11] | Bonn(110) [24] | Scannet(90) [7] | |||
|---|---|---|---|---|---|---|---|---|
| AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | AbsRel (↓) | (↑) | |||
| DepthCrafter | 2156.7 | 10.5~40.5 | 0.111 | 0.885 | 0.066 | 0.979 | 0.125 | 0.848 |
| DepthAnyVideo | 1422.8 | 6 | 0.073 | 0.957 | 0.051 | 0.981 | 0.112 | 0.883 |
| VDA-L (Ours) | 381.8 | 0.55 | 0.079 | 0.950 | 0.053 | 0.972 | 0.075 | 0.954 |
🔼 This table presents a comparison of zero-shot short-video depth estimation results between the proposed model (VDA-L, using a ViT-Large backbone), DepthCrafter [13], and DepthAnyVideo [40]. The comparison is done using three metrics: Absolute Relative Error (AbsRel), δ₁, and Temporal Alignment Error (TAE), across three datasets: KITTI, Bonn, and Scannet. The table also specifies the number of parameters, number of video training data and the inference resolution used for each model. Best and second-best results for each metric are highlighted.
read the caption
Table 7: Zero-shot short video depth estimation results. We compare with DepthCrafter [13] and DepthAnyVideo [40] in short video depth benchmark. “VDA-L” denotes our model with ViT-Large backbone. The default inference resolution of our model is set to 518 pixels on the short side, maintaining the aspect ratio. The best and the second best results are highlighted.
Full paper#