TL;DR#
Many languages in India lack resources for natural language processing (NLP) research, hindering development of accurate and culturally sensitive AI models. This is a significant issue because these languages represent a substantial part of global communication and accessibility needs. The paper addresses this problem by introducing a comprehensive benchmark.
The benchmark, called IndicMMLU-Pro, evaluates large language models (LLMs) across nine major Indian languages using a wide range of tasks. It builds upon the MMLU Pro framework, adapting it to the unique linguistic challenges of these languages. Results from state-of-the-art multilingual models show significant performance variability across languages, highlighting the need for language-specific approaches and further research. IndicMMLU-Pro is publicly available, promoting reproducibility and advancing research in Indic language AI.
Key Takeaways#
Why does it matter?#
This paper is crucial for NLP researchers focusing on low-resource languages. It introduces IndicMMLU-Pro, a comprehensive benchmark for evaluating language models in Indic languages, addressing the scarcity of resources in this area. The benchmark’s public availability promotes reproducibility and facilitates further research, potentially driving significant advancements in Indic language AI.
Visual Insights#

🔼 This figure details the creation and validation pipeline for the IndicMMLU-Pro dataset. Starting with the English MMLU-Pro dataset, a machine translation model (IndicTrans2) translates the content into nine Indic languages. Rigorous quality checks are then performed, including back-translation to English and evaluation using multiple metrics (chrF++, BLEU, METEOR, TER, SacreBLEU). Only translations passing these quality thresholds are included in the final dataset. Finally, 13 expert reviewers assess the semantic accuracy, fluency, and linguistic style of the translations, ensuring high quality and cultural sensitivity. This process creates a multilingual benchmark that retains the integrity of the original English dataset while accurately reflecting Indic language nuances.
read the caption
Figure 1: IndicMMLU-Pro Dataset Construction and Evaluation Pipeline. The diagram illustrates the end-to-end process of creating and validating the IndicMMLU-Pro dataset across nine Indic languages. Starting with the English MMLU-Pro dataset, content is translated using IndicTrans2 (1B parameters) and undergoes rigorous quality assurance through back-translation and multiple metric evaluations (chrF++, BLEU, METEOR, TER, and SacreBLEU). Only translations meeting quality thresholds proceed to the final dataset. The workflow also shows the comprehensive evaluation process including expert proofreading involving 13 reviewers who assess semantic accuracy, fluency, and linguistic style. This systematic approach ensures the creation of a high-quality, multilingual benchmark dataset that maintains the integrity of the original MMLU-Pro while adapting to the linguistic nuances of Indic languages.
| Language | GPT-4o | GPT-4o mini | Llama-3.1-8B | IndicBART | IndicBERT | RemBERT | MuRIL |
|---|---|---|---|---|---|---|---|
| Hindi | 44.80 | 32.33 | 18.61 | 11.21 | 10.78 | 11.41 | 10.87 |
| Bengali | 44.38 | 31.11 | N/A | 12.52 | 10.39 | 12.00 | 9.90 |
| Punjabi | 40.60 | 26.25 | N/A | 11.78 | 10.36 | 11.06 | 10.36 |
| Marathi | 42.20 | 27.13 | N/A | 11.65 | 10.59 | 12.93 | 11.79 |
| Urdu | 44.18 | 31.13 | N/A | 12.11 | 11.63 | 11.32 | 11.20 |
| Gujarati | 41.77 | 28.29 | N/A | 12.14 | 11.06 | 12.13 | 10.79 |
| Telugu | 41.34 | 26.78 | N/A | 12.05 | 11.36 | 10.20 | 9.96 |
| Tamil | 38.46 | 35.08 | N/A | 11.70 | 10.96 | 10.98 | 11.00 |
| Kannada | 38.97 | 25.75 | N/A | 11.51 | 11.71 | 10.87 | 10.62 |
🔼 This table presents a performance comparison of various large language models (LLMs) on the IndicMMLU-Pro benchmark. The benchmark evaluates LLMs across nine major Indic languages: Hindi, Bengali, Telugu, Marathi, Tamil, Gujarati, Urdu, Kannada, and Punjabi. These languages are categorized into Indo-Aryan and Dravidian language families. The table shows the accuracy (in percentage) achieved by each model on the IndicMMLU-Pro benchmark for each language. The LLMs compared include GPT-4o, GPT-4o mini, IndicBART, IndicBERT, RemBERT, MuRIL, and Llama-3.1-8B-Instruct. This allows for a comparison of the performance of both general-purpose and Indic-language-specific models across a diverse set of Indic languages.
read the caption
Table 1: Performance comparison of language models on the IndicMMLU-Pro benchmark across nine Indic languages, including Indo-Aryan (Hindi, Bengali, Punjabi, Marathi, Urdu, and Gujarati) and Dravidian (Telugu, Tamil, and Kannada) languages. Accuracy scores are shown as percentages. Models compared include GPT-4o, GPT-4o mini, IndicBART, IndicBERT, RemBERT, MuRIL, and Llama-3.1-8B-Instruct.
In-depth insights#
Indic NLP Gaps#
The field of Indic NLP faces significant challenges due to limited resources, linguistic diversity, and data scarcity. The imbalance in research funding and attention compared to globally dominant languages like English creates a gap in the availability of high-quality datasets, tools, and pre-trained models crucial for developing accurate and effective NLP systems. This lack of resources disproportionately affects low-resource Indic languages, hindering progress in areas like machine translation, text classification, and question answering. Furthermore, the complexity of Indic languages, with their rich morphology and diverse scripts, poses unique challenges for NLP model development. Addressing these gaps requires a multi-pronged approach, including increased investment in research and development, collaborative efforts to create and share high-quality datasets, and the development of robust and adaptable NLP techniques tailored to the unique characteristics of Indic languages.
Benchmark Design#
The effective design of a benchmark is crucial for evaluating large language models (LLMs). A well-designed benchmark should accurately reflect real-world tasks and challenges, ensuring that the evaluation results are meaningful and generalizable. It needs to be comprehensive, covering a broad range of tasks and abilities. Linguistic diversity, especially in the context of low-resource languages, is critical and must be incorporated. The benchmark must be rigorously tested and verified for bias, to avoid skewed or misleading results. Furthermore, the benchmark’s tasks should be clearly defined and consistently evaluated, with transparent metrics to allow researchers to understand and compare model performance. A strong benchmark design also facilitates the identification of strengths and weaknesses of different models, enabling future advancements.
Model Variablity#
Analysis of the research paper reveals significant model variability in performance across different Indic languages. This highlights the challenge of applying generalized multilingual models to diverse linguistic contexts. No single model consistently outperforms others across all languages, indicating a need for language-specific model architectures or extensive fine-tuning. The observed variability underscores the complexity of Indic languages and the limitations of current multilingual approaches. Future research should focus on developing models that are either explicitly tailored for specific Indic languages or employ techniques that effectively address cross-lingual transfer challenges. Understanding the reasons behind this variability is crucial for advancing NLP research for low-resource languages. Investigating the impact of factors such as script, morphology, and data scarcity is essential for creating more robust and effective models. The substantial performance differences suggest that a one-size-fits-all approach is insufficient and that more nuanced, context-aware models are necessary.
Translation Quality#
The research paper section on Translation Quality is crucial for evaluating the reliability of the multilingual benchmark dataset. The use of back-translation, a technique to assess translation accuracy by re-translating into the original language, is a key strength. Multiple metrics (chrF++, BLEU, METEOR, TER, SacreBLEU) were used, providing a comprehensive evaluation. While the high scores for Hindi and Gujarati suggest good quality, the limited data for other languages is a major limitation. This highlights the need for rigorous quality control and complete reporting across all languages in the dataset to ensure the validity and fairness of the benchmark. The threshold values used for each metric should be clearly defined and justified in the context of Indic languages. Future work should aim for a more comprehensive evaluation of translation quality across all nine languages to strengthen the credibility of the entire dataset and the study’s findings.
Future Directions#
The ‘Future Directions’ section of this research paper would ideally highlight crucial next steps for advancing Indic language AI. Data collection is paramount, emphasizing the need for high-quality, diverse datasets across all Indic languages, especially for low-resource ones. Model development should focus on architectures and training techniques robust enough to handle the linguistic complexities of these languages, addressing morphology and script diversity. Cross-lingual transfer techniques, leveraging related languages to improve performance, especially for low-resource ones, are another key area. Finally, the paper should stress the importance of task-specific fine-tuning, developing strategies to effectively adapt large multilingual models to particular Indic language tasks, as well as refining evaluation metrics to better capture the nuances of the languages and cultural contexts.
More visual insights#
More on figures

🔼 This figure demonstrates the machine translation and back-translation process used to create the IndicMMLU-Pro dataset. It shows an example of an English text, its translation into Hindi using the IndicTrans2 model, and the subsequent back-translation of the Hindi text back into English. Comparing the original English text with the back-translated version helps to assess the quality and accuracy of the translation process, ensuring the integrity of the dataset.
read the caption
Figure 2: The original text sample, its Hindi translation, and the corresponding back-translated text

🔼 Figure 3 displays a three-column comparison of text. The left column shows the original English text of a sample question from the IndicMMLU-Pro benchmark. The middle column presents the Gujarati translation of the English text, demonstrating the machine translation process used to create the IndicMMLU-Pro dataset. The rightmost column shows the result of back-translating the Gujarati text back into English. This back-translation serves as a quality assurance check, allowing assessment of how accurately the machine translation preserved the original meaning and intent.
read the caption
Figure 3: The original text sample, its Gujarati translation, and the corresponding back-translated text

🔼 Figure 4 displays the original English text of a sample question from the IndicMMLU-Pro benchmark, its translation into Tamil using the IndicTrans2 model, and the result of back-translating the Tamil version back into English. This process demonstrates the quality assurance step used to validate the accuracy of the IndicMMLU-Pro dataset. By comparing the original and back-translated English text, researchers can assess the fidelity of the translation.
read the caption
Figure 4: The original text sample, its Tamil translation, and the corresponding back-translated text

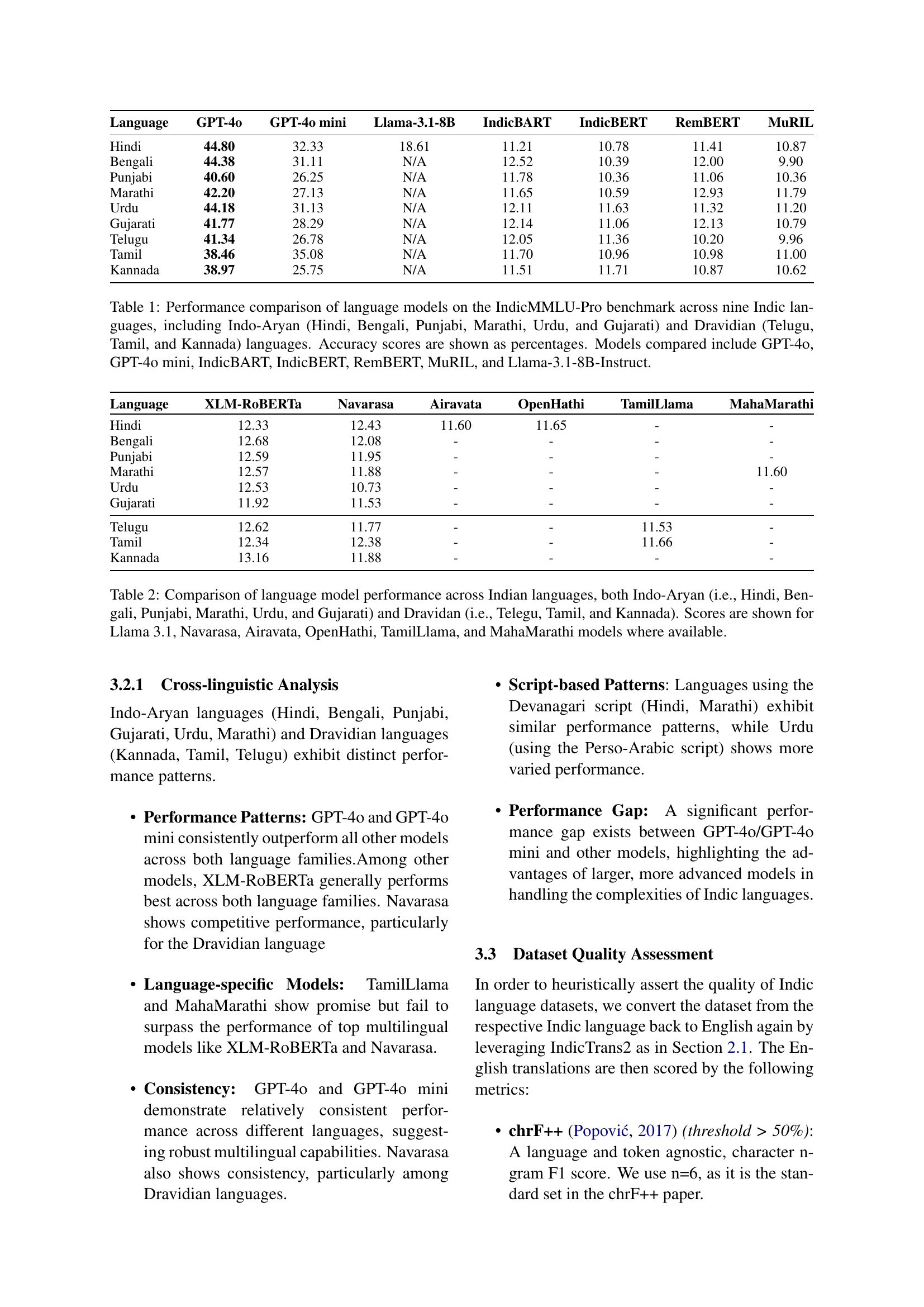
🔼 This figure is a bar chart showing the accuracy of various language models across nine different Indic languages. The models are represented on the y-axis, and the languages are on the x-axis. The height of each bar represents the percentage accuracy of a given model on a particular language. This allows for a direct comparison of model performance across languages, highlighting strengths and weaknesses of each model in handling the diverse linguistic characteristics of Indic languages.
read the caption
Figure 5: Model Accuracy Across Different Languages

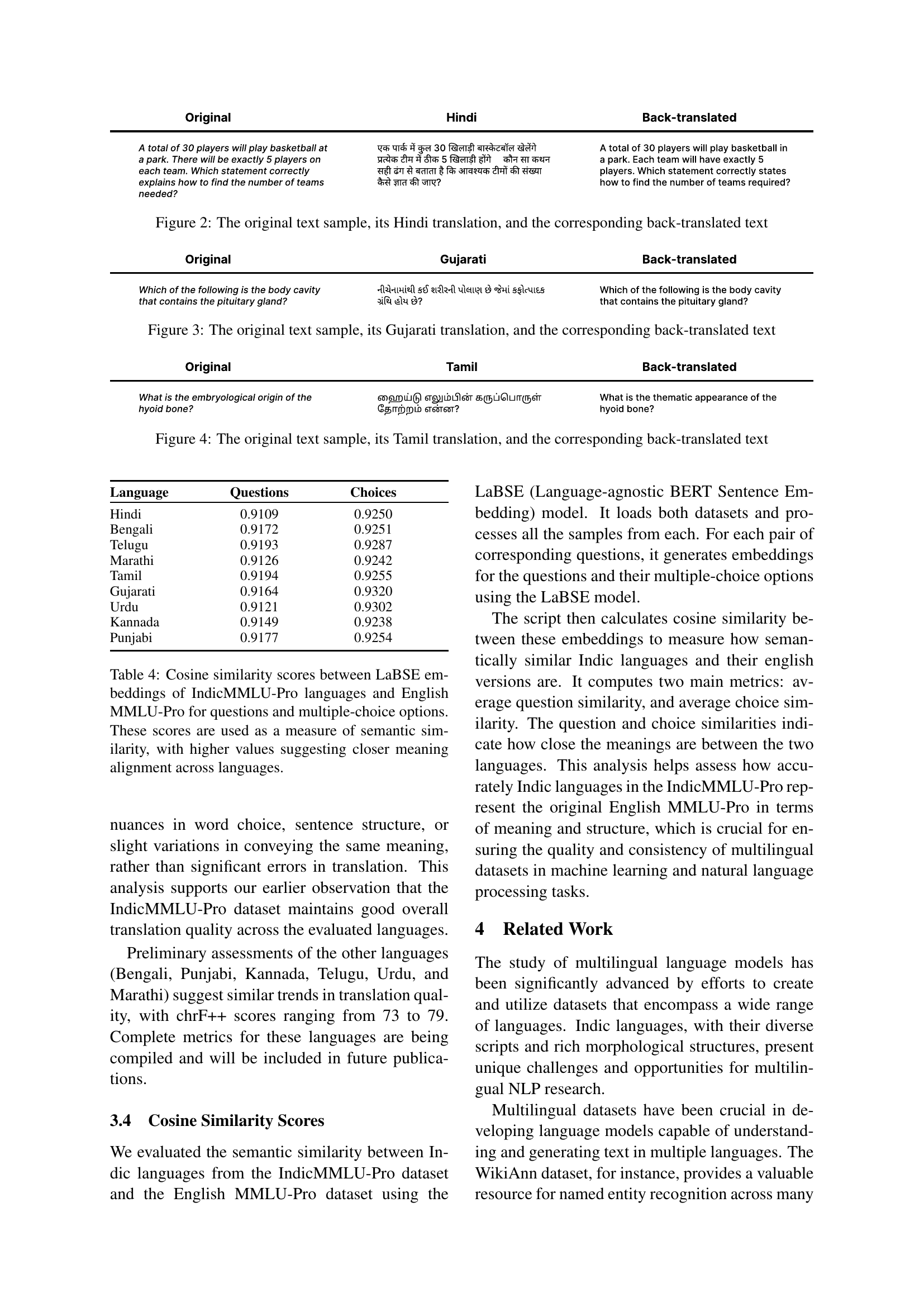
🔼 This figure displays the average lengths of questions and their corresponding options (choices) across nine Indic languages in the IndicMMLU-Pro dataset. Lengths are presented in both number of words and number of tokens, providing insights into the linguistic characteristics of the dataset and potential implications for model performance.
read the caption
Figure 6: Average Question and Option Lengths in # Words and # Tokens

🔼 This figure displays three sets of text: the original English text, its translation into Hindi using IndicTrans2, and the back-translation of the Hindi text back into English. This process demonstrates the machine translation workflow and helps assess the accuracy and fluency of the translations. The comparison between the original and back-translated English texts highlights the effectiveness of the translation method in preserving meaning and linguistic integrity.
read the caption
Figure 7: Additional examples showcasing the machine translation workflow, including the original text samples, their Hindi translations, and the corresponding back-translated texts.

🔼 Figure 8 presents several examples illustrating the machine translation process used in the creation of the IndicMMLU-Pro dataset. For each example, the original English text is shown alongside its Gujarati translation and the result of back-translating the Gujarati text back into English. This demonstrates the entire workflow and allows for a visual assessment of the accuracy and fidelity of the translation process. The comparison reveals how well the meaning and structure of the original English text are preserved in the translation and back-translation steps, highlighting the quality of the translation model used for creating the IndicMMLU-Pro dataset.
read the caption
Figure 8: Additional examples showcasing the machine translation workflow, including the original text samples, their Gujarati translations, and the corresponding back-translated texts.

🔼 Figure 9 presents several examples illustrating the machine translation process used in creating the IndicMMLU-Pro dataset. For each example, the figure shows the original English text, its translation into Tamil, and the subsequent back-translation of the Tamil text into English. This allows for a visual comparison of the original and back-translated English text, demonstrating the accuracy and consistency of the translation process. The examples highlight the system’s ability to handle the nuances of the Tamil language while maintaining the semantic meaning of the original text.
read the caption
Figure 9: Additional examples showcasing the machine translation workflow, including the original text samples, their Tamil translations, and the corresponding back-translated texts.
More on tables
| Language | XLM-RoBERTa | Navarasa | Airavata | OpenHathi | TamilLlama | MahaMarathi |
|---|---|---|---|---|---|---|
| Hindi | 12.33 | 12.43 | 11.60 | 11.65 | - | - |
| Bengali | 12.68 | 12.08 | - | - | - | - |
| Punjabi | 12.59 | 11.95 | - | - | - | - |
| Marathi | 12.57 | 11.88 | - | - | - | 11.60 |
| Urdu | 12.53 | 10.73 | - | - | - | - |
| Gujarati | 11.92 | 11.53 | - | - | - | - |
| Telugu | 12.62 | 11.77 | - | - | 11.53 | - |
| Tamil | 12.34 | 12.38 | - | - | 11.66 | - |
| Kannada | 13.16 | 11.88 | - | - | - | - |
🔼 This table presents a comparison of the performance of various language models on the IndicMMLU-Pro benchmark, broken down by language family (Indo-Aryan and Dravidian) and individual language. It shows the accuracy scores achieved by several models, including Llama 3.1, Navarasa, Airavata, OpenHathi, TamilLlama, and MahaMarathi, on tasks designed to evaluate the models’ ability to understand and process the nine major Indic languages included in the benchmark. The scores provide insights into the strengths and weaknesses of different models in handling the linguistic nuances of each language and give an indication of the current state of the art in Indic language AI.
read the caption
Table 2: Comparison of language model performance across Indian languages, both Indo-Aryan (i.e., Hindi, Bengali, Punjabi, Marathi, Urdu, and Gujarati) and Dravidan (i.e., Telegu, Tamil, and Kannada). Scores are shown for Llama 3.1, Navarasa, Airavata, OpenHathi, TamilLlama, and MahaMarathi models where available.
| Language | chrF++ | BLEU | METEOR | TER | SacreBLEU |
|---|---|---|---|---|---|
| Hindi | 78.06 | 0.59 | 0.56 | 42.27 | 59.07 |
| Gujarati | 77.67 | 0.58 | 0.55 | 43.09 | 58.28 |
| Tamil | 74.32 | 0.54 | 0.52 | 46.41 | 53.64 |
🔼 This table presents the quality assessment of the IndicMMLU-Pro dataset’s translations using back-translation. It specifically focuses on three Indic languages: Hindi, Gujarati, and Tamil. The quality is evaluated using several metrics including chrF++, BLEU, METEOR, TER, and SacreBLEU, providing insights into the accuracy, fluency, and semantic similarity of the translations compared to the original English source.
read the caption
Table 3: Back-translation evaluation metrics for the IndicMMLU-Pro dataset for 3 Indic languages.
| Language | Questions | Choices |
|---|---|---|
| Hindi | 0.9109 | 0.9250 |
| Bengali | 0.9172 | 0.9251 |
| Telugu | 0.9193 | 0.9287 |
| Marathi | 0.9126 | 0.9242 |
| Tamil | 0.9194 | 0.9255 |
| Gujarati | 0.9164 | 0.9320 |
| Urdu | 0.9121 | 0.9302 |
| Kannada | 0.9149 | 0.9238 |
| Punjabi | 0.9177 | 0.9254 |
🔼 This table presents cosine similarity scores calculated using LaBSE embeddings. It compares the semantic similarity between IndicMMLU-Pro datasets (in nine Indic languages) and the English MMLU-Pro dataset for both questions and their corresponding multiple-choice options. Higher scores indicate greater semantic similarity and better alignment of meaning across languages. This provides insight into the quality and consistency of the translations from English to the Indic languages within the IndicMMLU-Pro benchmark.
read the caption
Table 4: Cosine similarity scores between LaBSE embeddings of IndicMMLU-Pro languages and English MMLU-Pro for questions and multiple-choice options. These scores are used as a measure of semantic similarity, with higher values suggesting closer meaning alignment across languages.
Full paper#