TL;DR#
Generating high-quality 3D content from text or images is challenging due to limited high-quality 3D datasets and the inconsistencies arising from 2D multi-view generation methods. Current methods either struggle with training 3D diffusion models from scratch or encounter challenges in maintaining consistency when using 2D priors. These limitations hinder the fidelity and generalizability of 3D content creation.
This paper introduces DIFFSPLAT, a novel 3D generative framework that directly generates 3D Gaussian splats using pre-trained large-scale text-to-image diffusion models. By utilizing web-scale 2D priors, DIFFSPLAT maintains 3D consistency in a unified model. A lightweight reconstruction model is used to instantly generate multi-view Gaussian splat grids for efficient dataset curation. A 3D rendering loss is incorporated to enhance 3D coherence. Extensive experiments showcase DIFFSPLAT’s superiority in various generation tasks and its compatibility with existing image generation techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient method for 3D content generation, addressing the limitations of existing techniques. Its use of pre-trained 2D image diffusion models significantly reduces the need for large 3D datasets, making it more accessible to researchers with limited resources. The findings could spur further research in leveraging 2D priors for 3D generation and lead to advancements in various applications like game design, virtual reality, and digital arts.
Visual Insights#

🔼 This figure compares four different approaches to 3D content generation using diffusion models. Method (1) trains a 3D diffusion model directly on 3D data, which is limited by the scarcity of high-quality 3D datasets. Method (2) uses 2D supervision via differentiable rendering techniques but suffers from the same dataset limitation. Method (3) leverages pre-trained 2D diffusion models to generate multi-view images that are then used to reconstruct 3D content, but suffers from consistency issues in the generated multi-view images. In contrast, the proposed method (4), DiffSplat, directly generates 3D Gaussian splats using pre-trained image diffusion models and leverages 2D priors while maintaining 3D consistency. This approach bypasses the need for large-scale 3D datasets, directly utilizing the power of web-scale 2D image data.
read the caption
Figure 1: Comparison with Previous 3D Diffusion Generative Models. (1) Native 3D methods and (2) rendering-based methods encounter challenges in training 3D diffusion models from scratch with limited 3D data. (3) Reconstruction-based methods struggle with inconsistencies in generated multi-view images. In contrast, (4) DiffSplat leverages pretrained image diffusion models for the direct 3DGS generation, effectively utilizing 2D diffusion priors and maintaining 3D consistency. “GT” refers to ground-truth samples in a 3D representation used for diffusion loss computation.
| DiffSplat | GVGEN | LN3Diff | DIRECT-3D | 3DTopia | LGM† | GRM† | ||
| Single Object | CLIP Sim.% | 30.95 | 23.66 | 24.36 | 24.80 | 25.55 | 29.96 | 28.19 |
| CLIP R-Prec.% | 81.00 | 23.25 | 27.25 | 30.75 | 34.50 | 78.00 | 64.75 | |
| ImageReward | -0.491 | -2.156 | -2.008 | -2.005 | -1.998 | -0.720 | -1.337 | |
| Single Object w/ Sur. | CLIP Sim.% | 30.20 | 22.65 | 22.75 | 23.05 | 24.31 | 27.79 | 26.24 |
| CLIP R-Prec.% | 80.75 | 26.75 | 22.00 | 25.75 | 39.00 | 55.00 | 51.25 | |
| ImageReward | -0.674 | -2.251 | -2.244 | -2.191 | -2.230 | -1.772 | -1.869 | |
| Multiple Objects | CLIP Sim.% | 29.46 | 21.48 | 21.65 | 21.89 | 22.88 | 27.07 | 24.33 |
| CLIP R-Prec.% | 69.50 | 8.00 | 8.75 | 7.75 | 16.50 | 51.00 | 26.50 | |
| ImageReward | -0.849 | -2.272 | -2.267 | -2.249 | -2.225 | -1.731 | -2.116 | |
🔼 This table presents a quantitative comparison of different text-to-3D generation methods on the T3Bench benchmark. The metrics used are CLIP similarity score (%), CLIP R-Precision (%), and ImageReward, which assess the alignment between generated 3D models and text prompts, and the aesthetic quality of the generated models, respectively. The results are categorized into three scenarios: single objects, single objects with surroundings, and multiple objects. The ‘†’ symbol indicates methods that rely on pre-trained multi-view image generation models as an additional step for reconstruction-based 3D generation, highlighting the direct generative nature of the other approaches.
read the caption
Table 1: Quantitive evaluations on T3Bench prompts for text-conditioned generation. † indicates reconstruction-based methods that require additional text-conditioned multi-view generative models.
In-depth insights#
3D Diffusion’s Limits#
3D diffusion models, while showing promise, face significant limitations. Data scarcity is a major hurdle; high-quality, diverse 3D datasets are far less abundant than their 2D counterparts, hindering training and generalization. The inherent complexity of 3D space introduces computational challenges, making training and inference significantly more resource-intensive than 2D diffusion. Maintaining 3D consistency across multiple viewpoints remains a difficult problem; many current methods generate plausible individual views but fail to create a coherent 3D representation. Furthermore, evaluation metrics for 3D content are still under development and lack the robustness and standardization of 2D metrics, complicating objective comparison and progress assessment. Finally, current 3D diffusion models struggle with generating highly detailed, realistic objects, often producing results with artifacts and inaccuracies. Addressing these limitations will require further research into novel 3D representations, more efficient training techniques, and the development of more sophisticated evaluation methods. Ultimately, overcoming these obstacles is essential to unlock the true potential of 3D diffusion for creating realistic and complex 3D content.
DIFFSPLAT’s Approach#
DIFFSPLAT presents a novel approach to 3D Gaussian splat generation by effectively repurposing the power of pre-trained 2D image diffusion models. Instead of training a 3D model from scratch, which is data-intensive and computationally expensive, DIFFSPLAT leverages the vast amount of data and learned representations inherent in these 2D models. It achieves this by representing 3D objects as structured Gaussian splat grids, which are then processed by the adapted 2D diffusion model. This clever technique bypasses the need for extensive 3D training data. A key innovation is the use of a lightweight reconstruction model to instantly generate these splat grids from multi-view images, significantly accelerating dataset creation. The approach cleverly incorporates a 3D rendering loss in addition to the standard diffusion loss to ensure consistency across views and enforce 3D coherence. This fusion of 2D and 3D methodologies results in a scalable and efficient 3D generation framework capable of generating high-quality outputs. The model’s adaptability, thanks to its compatibility with a broad range of image diffusion models, allows easy integration of existing image generation techniques and further enhances its effectiveness. DIFFSPLAT demonstrates a significant advancement in 3D generation by bridging the gap between the rich resources of 2D image generation and the challenges of 3D model training.
Scalable Data Curation#
Scalable data curation is crucial for training high-performing 3D generative models, especially when dealing with the limitations of existing 3D datasets. The core challenge lies in acquiring sufficient high-quality 3D data, which is often time-consuming and expensive to obtain. This paper addresses this challenge by proposing a novel approach that leverages readily available 2D image data and pre-trained 2D diffusion models. Instead of directly creating 3D data, the method focuses on efficiently generating structured 2D representations (Gaussian splat grids) that implicitly capture 3D information. This strategy allows for scalable data curation because it bypasses the need for explicitly creating large 3D datasets. A lightweight reconstruction model is trained to regress these 2D grids from multi-view images, enabling rapid generation of training data. This approach is particularly effective because it combines the power of large-scale 2D priors with 3D consistency constraints, overcoming limitations of methods relying solely on either 2D or 3D supervision. The proposed method’s ability to efficiently generate training data paves the way for training more powerful 3D generative models and facilitates advancements in high-quality, scalable 3D content creation.
Ablation Study Insights#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of 3D generation, this could involve removing different loss functions (e.g., removing the rendering loss to isolate the impact of the diffusion loss), altering network architectures, or varying the input data. Key insights would surface from observing how these changes impact the quality of 3D model generation: Does removing the rendering loss drastically reduce 3D consistency across views? Does a simpler architecture compromise the level of detail or the overall visual fidelity? Does reducing the input data (e.g., using fewer views) dramatically affect the reconstruction accuracy and model training stability? The ablation study would not only quantify these changes (e.g., by measuring metrics such as PSNR, SSIM, and LPIPS) but also help to identify which components are essential for high-quality 3D model generation, and which may be redundant or even detrimental. Understanding this interplay would be critical for optimizing model design, streamlining the training process, and potentially achieving greater efficiency in terms of computational resources and training time. A thoughtful ablation study can illuminate the design choices and thus provide crucial guidance for future improvements and optimization in the field of 3D generation.
Future 3D Directions#
Future research in 3D generation should prioritize scalability and efficiency, moving beyond reliance on limited, high-quality datasets. Improving the integration of 2D and 3D techniques is crucial, leveraging the wealth of pre-trained 2D models to boost 3D model training and generation speed. Addressing the challenge of generating high-fidelity, consistent multi-view 3D assets remains a critical area for development. This involves exploring innovative model architectures and training strategies that explicitly enforce 3D consistency across viewpoints. Research into novel 3D representations, beyond current methods such as point clouds, voxels, and implicit functions, is also necessary to enhance the efficiency and realism of generated 3D content. Finally, incorporating physical-based rendering and material properties into the generation process will be vital for creating truly photorealistic and interactive 3D experiences.
More visual insights#
More on figures
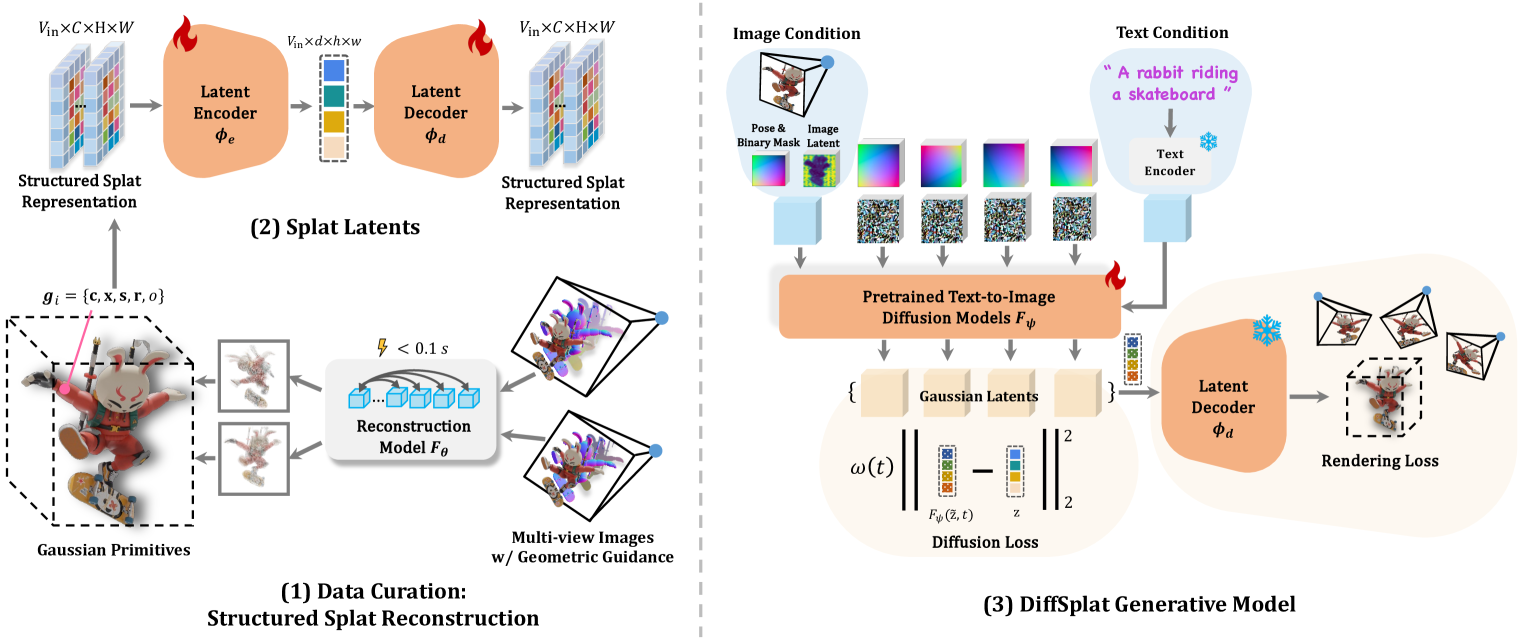
🔼 This figure illustrates the three main stages of the DIFFSPLAT method. First, a lightweight reconstruction model takes multi-view images as input and generates a structured representation of 3D Gaussian splats. This serves to create a ‘pseudo’ dataset for training. Second, an image Variational Autoencoder (VAE) is fine-tuned; its purpose is to encode the properties of these Gaussian splats into a lower-dimensional latent space shared with the pre-trained image diffusion model. Finally, the core DIFFSPLAT model uses this latent space to generate new 3D content conditioned on either text or image inputs. This leverages the power of pre-trained 2D image diffusion models to enable native 3D Gaussian splat generation.
read the caption
Figure 2: Method Overview. (1) A lightweight reconstruction model provides high-quality structured representation for “pseudo” dataset curation. (2) Image VAE is fine-tuned to encode Gaussian splat properties into a shared latent space. (3) DiffSplat is natively capable of generating 3D contents by image and text conditions utilizing 2D priors from text-to-image diffusion models.

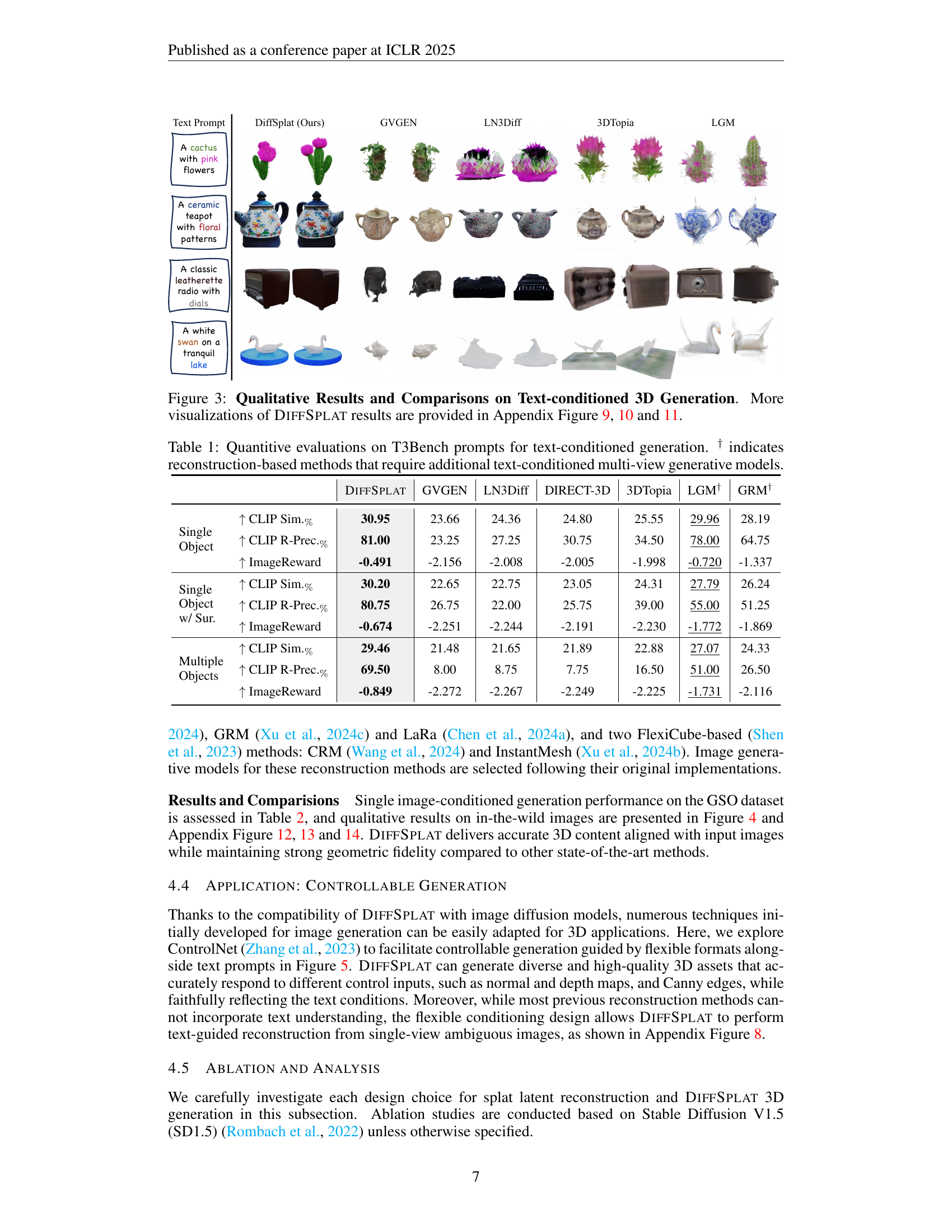
🔼 This figure presents a qualitative comparison of text-to-3D generation results between DiffSplat and several other state-of-the-art methods. Each model is given the same text prompt, and the generated 3D objects are shown. DiffSplat’s outputs are compared visually with results from GVGEN, LN3Diff, 3DTopia, LGM, and GRM. The figure highlights DiffSplat’s ability to generate high-quality, detailed 3D models that closely match the input text descriptions, in comparison to other models. Additional visualizations are available in the appendix for a more comprehensive evaluation.
read the caption
Figure 3: Qualitative Results and Comparisons on Text-conditioned 3D Generation. More visualizations of DiffSplat results are provided in Appendix Figure 9, 10 and 11.

🔼 Figure 4 presents a qualitative comparison of image-conditioned 3D generation results using different methods. It showcases the 3D models generated from single input images by DiffSplat and other state-of-the-art methods. The figure highlights DiffSplat’s ability to produce high-quality 3D models that accurately reflect the input images. For a more comprehensive view of the results generated by DiffSplat, refer to Appendix Figures 12, 13, and 14.
read the caption
Figure 4: Qualitative Results and Comparisons on Image-conditioned 3D Generation. More visualizations of DiffSplat results are provided in Appendix Figure 12, 13 and 14.

🔼 Figure 5 showcases the adaptability of ControlNet with DiffSplat. ControlNet’s ability to incorporate various image formats, including normal maps, depth maps, and Canny edge maps, as guidance for text-to-3D generation is highlighted. The figure demonstrates how these different input formats enhance the control and precision of the 3D model generation process within the DiffSplat framework. This allows for more fine-grained control over the final output, resulting in more realistic and nuanced 3D objects.
read the caption
Figure 5: Controllable Generation. ControlNet can seamlessly adapt to DiffSplat for controllable text-to-3D generation in various formats, such as normal and depth maps, and Canny edges.

🔼 This table presents an ablation study on the impact of different inputs used for reconstructing structured splat representations. The goal is to determine which inputs are most effective for generating high-quality 3D Gaussian splat grids. The experiment compares the performance of using RGB images only versus incorporating additional geometric guidance such as normal and coordinate maps. The results are quantified using PSNR, SSIM, and LPIPS metrics to evaluate the quality of the reconstructed splats.
read the caption
Table 3: Ablation study of inputs for structured splat reconstruction.

🔼 This table presents an ablation study on different strategies for auto-encoding Gaussian splat properties. It compares the performance of various methods for encoding these properties into a latent space suitable for use with a diffusion model. The methods compared involve using a pretrained VAE (Variational Autoencoder) either frozen or fine-tuned, and with or without incorporating a rendering loss into the training process. The table shows the impact of these choices on the quality of the reconstructed Gaussian splat grids, measured by metrics such as PSNR, SSIM, and LPIPS.
read the caption
Table 4: Ablation study for Gaussian splat property auto-encoding strategies.

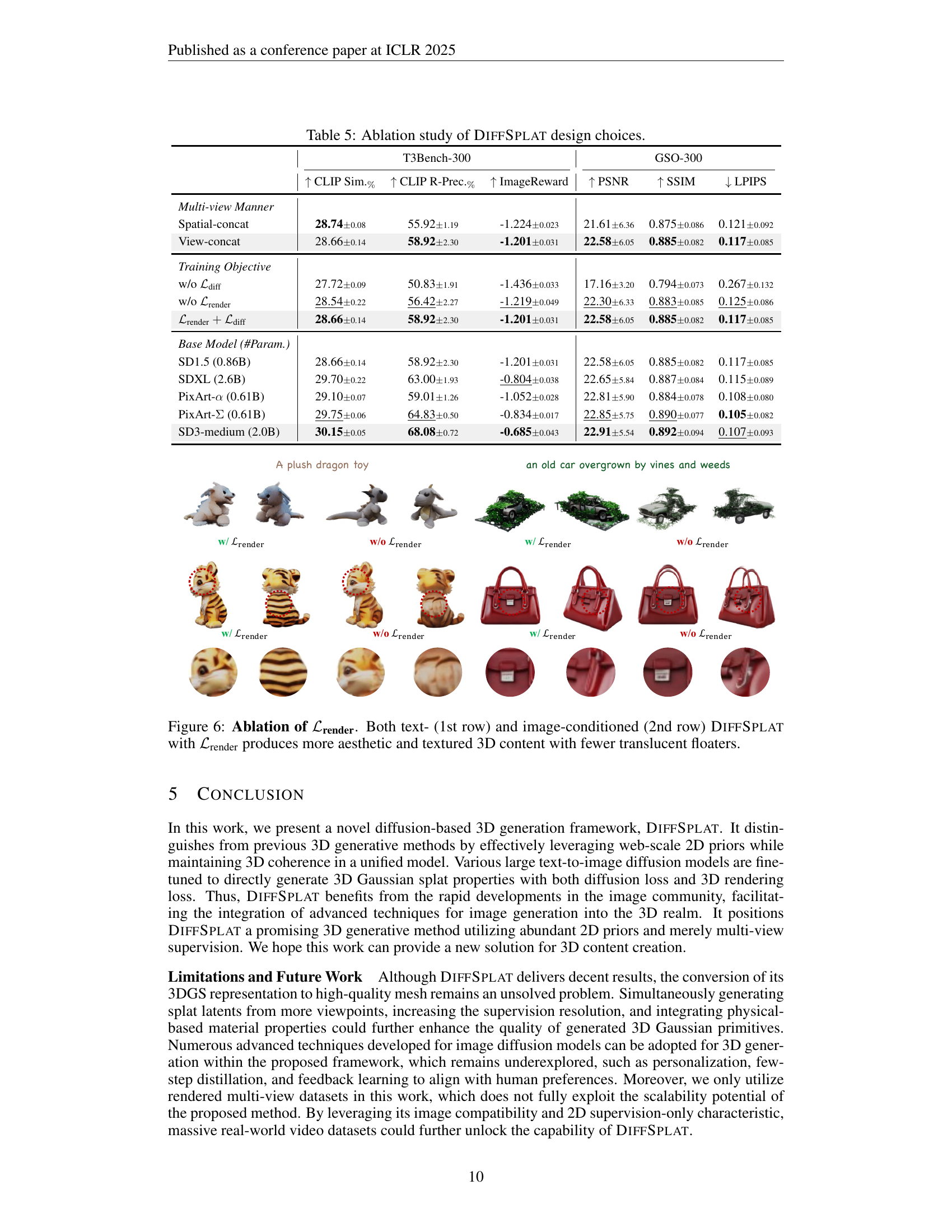
🔼 Figure 6 demonstrates the effect of the rendering loss (ℒrender) on the quality of 3D content generated by DiffSplat. The top row shows results from text-conditioned generation, and the bottom row shows image-conditioned generation. In both cases, the inclusion of the rendering loss leads to more visually appealing results with richer textures and a reduction in translucent artifacts (areas that appear semi-transparent). The comparison highlights the importance of the rendering loss in improving the overall quality and realism of the 3D models produced by the DiffSplat model.
read the caption
Figure 6: Ablation of ℒrendersubscriptℒrender\mathcal{L}_{\text{render}}caligraphic_L start_POSTSUBSCRIPT render end_POSTSUBSCRIPT. Both text- (1st row) and image-conditioned (2nd row) DiffSplat with ℒrendersubscriptℒrender\mathcal{L}_{\text{render}}caligraphic_L start_POSTSUBSCRIPT render end_POSTSUBSCRIPT produces more aesthetic and textured 3D content with fewer translucent floaters.

🔼 Figure 7 visualizes the latent representations (splat latents) used in the DIFFSPLAT model. It shows how the properties of 3D Gaussian splats—color, depth, opacity, scale, and rotation—are organized into structured 2D grids. The figure highlights how these splat grids are encoded by a Variational Autoencoder (VAE) and then decoded using a pretrained image diffusion model’s decoder. The ‘Decoded GS’ section demonstrates the result of decoding the splat latents back into an image-like representation, revealing that they maintain meaningful information related to the 3D object’s appearance and structure. This visualization helps illustrate the core concept of DIFFSPLAT’s approach: using image diffusion models to generate and manipulate 3D Gaussian splat representations.
read the caption
Figure 7: Splat Latents Visualization. 3DGS properties are structured in grids. “Decoded GS” shows the splat latents decoded by an image diffusion VAE.

🔼 Figure 8 showcases the capability of DiffSplat to generate 3D models using both text and image cues. Instead of requiring multiple views, it successfully reconstructs a 3D object from a single image, demonstrating its ability to integrate textual context with visual information for improved accuracy and detail in the reconstruction process. The examples visually demonstrate how different image and text prompts lead to variations in the generated 3D output. This highlights the model’s capacity for text understanding in conjunction with visual input during reconstruction.
read the caption
Figure 8: Controllable Generation with Multi-modal Conditions. DiffSplat can effectively utilize both text and image conditions for single-view reconstruction with text understanding.

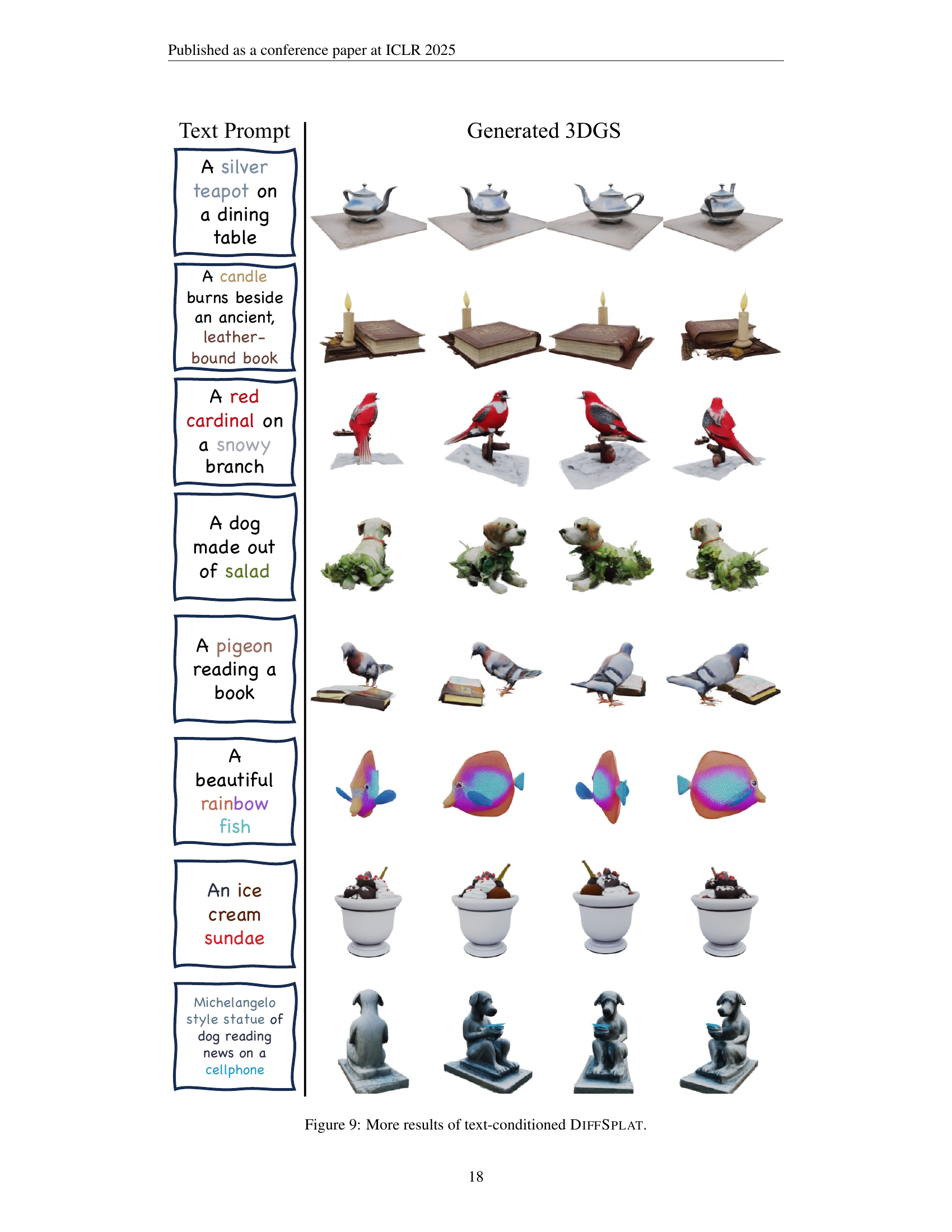
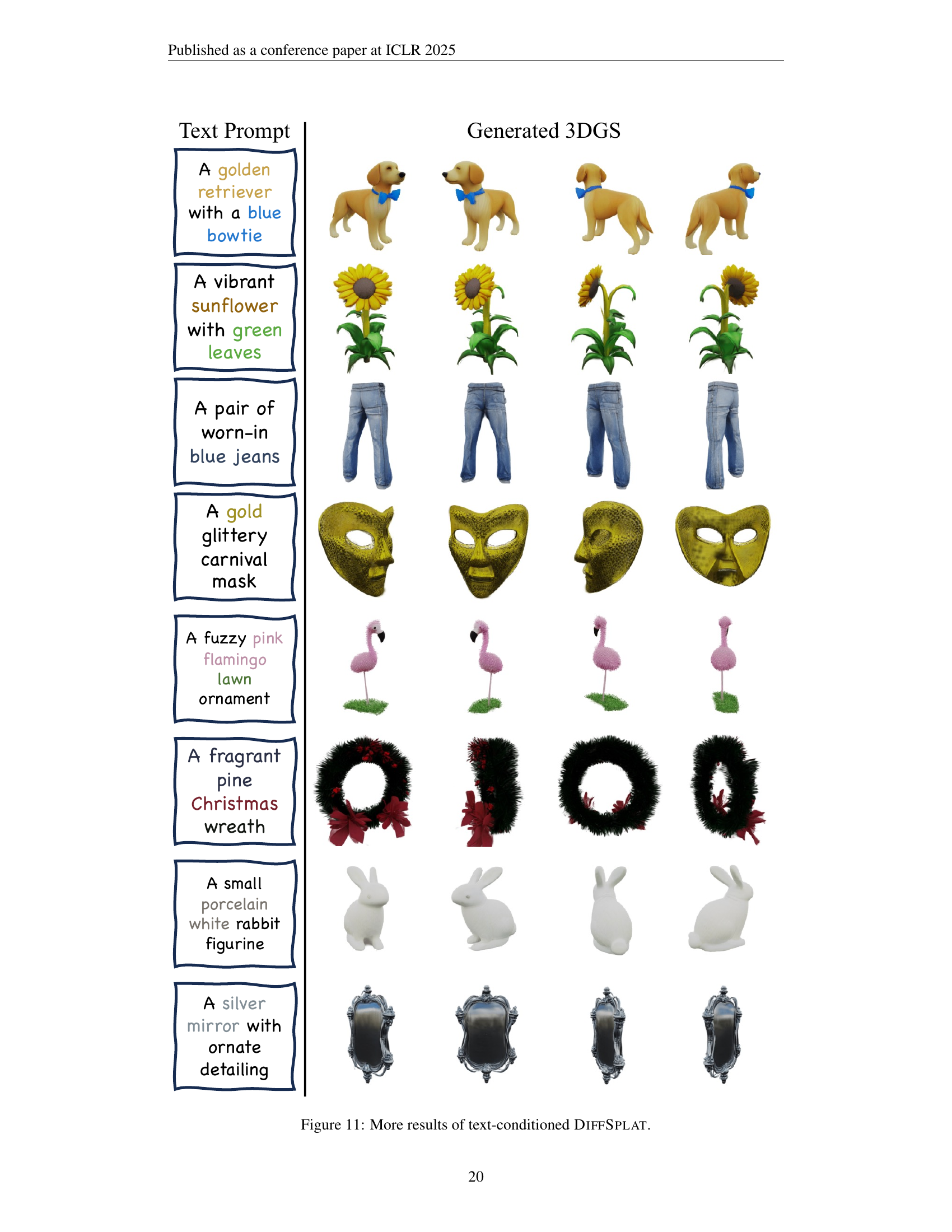
🔼 This figure showcases various 3D models generated by the DiffSplat model using different text prompts as input. Each row displays a different text prompt and the corresponding generated 3D object from multiple viewpoints. The models are detailed and realistic, demonstrating the model’s capability for generating high-quality 3D content based on text descriptions. The variety of objects presented highlights the versatility of DiffSplat in generating diverse 3D scenes.
read the caption
Figure 9: More results of text-conditioned DiffSplat.

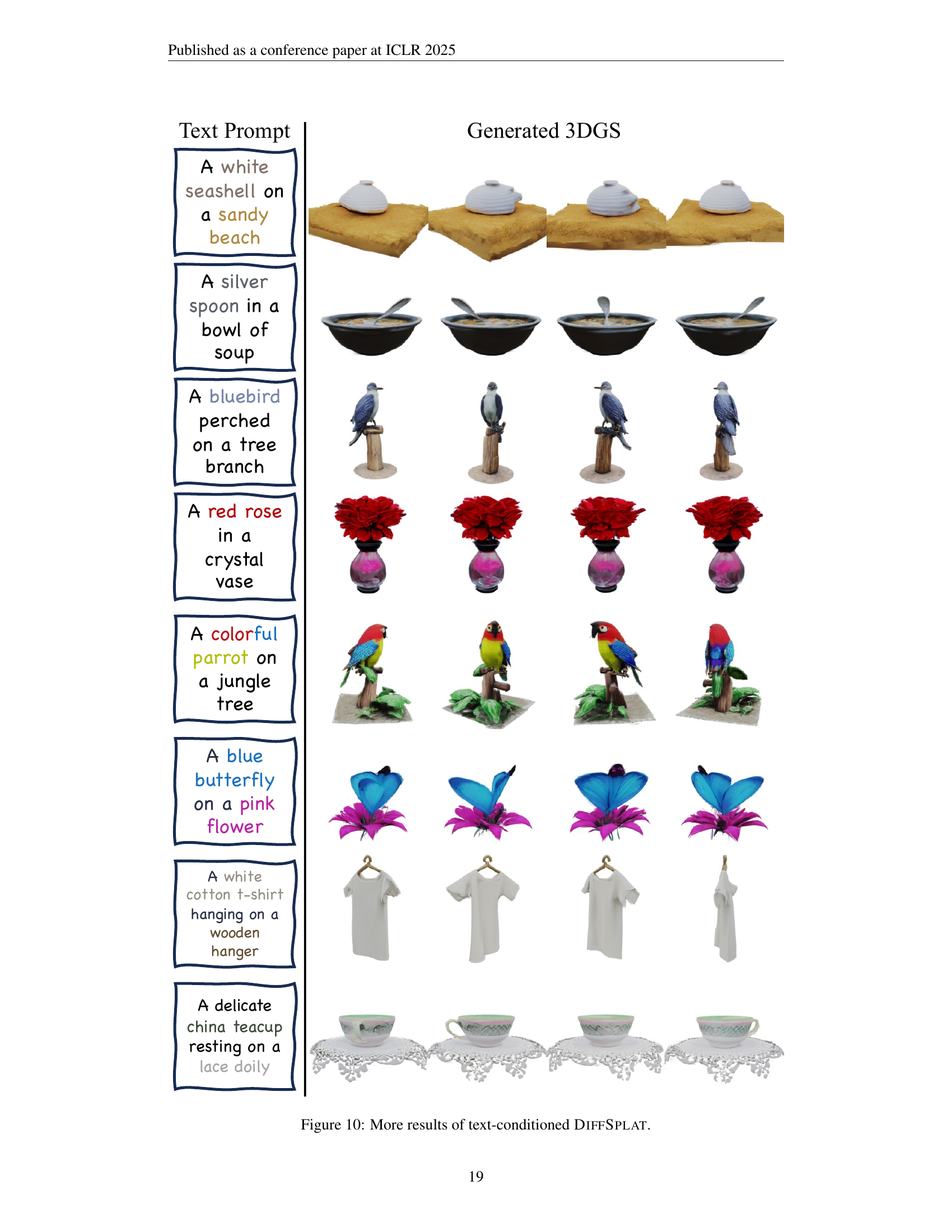
🔼 This figure displays additional examples of 3D models generated by the DiffSplat model using text prompts as input. It showcases the model’s ability to generate diverse and high-quality 3D objects from a range of descriptive text prompts, highlighting its capacity for detailed and nuanced object creation based on textual descriptions. The figure visually demonstrates the variety of objects, textures, and contexts that DiffSplat can generate from text alone.
read the caption
Figure 10: More results of text-conditioned DiffSplat.

🔼 This figure displays more examples of 3D models generated by the DiffSplat model using text prompts as input. Each row shows a different text prompt (e.g., ‘A golden retriever with a blue bowtie’) and the corresponding generated 3D Gaussian splat representations from multiple viewpoints. The figure demonstrates the model’s ability to generate diverse and detailed 3D objects based on textual descriptions.
read the caption
Figure 11: More results of text-conditioned DiffSplat.

🔼 This figure showcases additional examples of 3D models generated using the image-conditioned DiffSplat method. Each row presents a single input image followed by multiple views (front, back, and side) of the corresponding 3D object generated by the model. The variety of objects demonstrates the model’s ability to handle diverse shapes and textures.
read the caption
Figure 12: More results of image-conditioned DiffSplat.
More on tables
| DiffSplat | 3DTopia-XL | LN3Diff | LGM† | GRM† | LaRa† | CRM† | InstantMesh† | |
| PSNR | 22.91 | 17.27 | 16.67 | 18.25 | 19.65 | 18.87 | 18.56 | 19.14 |
| SSIM | 0.892 | 0.840 | 0.831 | 0.841 | 0.869 | 0.852 | 0.855 | 0.876 |
| LPIPS | 0.107 | 0.175 | 0.177 | 0.166 | 0.141 | 0.202 | 0.149 | 0.128 |
🔼 This table presents a quantitative comparison of different methods for image-conditioned 3D generation, focusing on the GSO dataset. The metrics used to evaluate performance are PSNR, SSIM, and LPIPS, which measure peak signal-to-noise ratio, structural similarity index, and learned perceptual image patch similarity, respectively. Lower LPIPS scores indicate better perceptual similarity. The methods compared include DIFFSPLAT and several baselines, both native 3D methods and reconstruction-based methods. The † symbol next to certain methods indicates that those techniques require additional image generation models to convert a single image to a 3D representation before evaluation, highlighting a key difference in approach and computational cost.
read the caption
Table 2: Quantitative evaluations on GSO for image-conditioned generation. † indicates reconstruction methods that require additional image generation models for single image-to-3D generation.
| PSNR | SSIM | LPIPS | #Param. | |
| LGM | 26.48 | 0.892 | 0.077 | 415M |
| GRM | 28.04 | 0.959 | 0.031 | 179M |
| RGB | 27.43 | 0.956 | 0.041 | 42M |
| Normal | 28.89 | 0.957 | 0.033 | 42M |
| Coord. | 29.87 | 0.961 | 0.028 | 42M |
| Ours | 30.09 | 0.963 | 0.027 | 42M |
🔼 This table presents the results of ablation studies performed on the DIFFSPLAT model’s design choices. It shows the quantitative impact of various design decisions on the model’s performance, across different metrics and experimental settings. Specifically, it analyzes the effects of different multi-view generation approaches (spatial-concat vs. view-concat), training objective functions (with or without the diffusion and rendering losses), and the choice of base diffusion model. The metrics used to evaluate performance include CLIP similarity, CLIP R-Precision, ImageReward, PSNR, SSIM, and LPIPS, providing a comprehensive assessment of both the qualitative and quantitative aspects of the generated 3D models.
read the caption
Table 5: Ablation study of DiffSplat design choices.
Full paper#