TL;DR#
Evaluating large language models (LLMs) is crucial but challenging. Human evaluation is expensive and slow, while existing automated methods using LLMs as judges often suffer from biases and inconsistencies. This leads to unreliable assessments of LLM capabilities.
Atla Selene Mini addresses these issues by introducing a novel, small language model designed specifically for evaluation. The model excels on multiple benchmarks and shows improved zero-shot performance in real-world scenarios. Its training incorporates both direct preference optimization and supervised fine-tuning, along with a rigorous data curation process to improve quality and reduce bias. The open-source release of the model and its weights allows researchers to use and improve this innovative evaluation tool.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM evaluation. It introduces a novel, high-performing small language model (SLMJ) that addresses existing limitations like bias and cost. The model’s open-source nature and strong real-world performance make it a valuable tool for the community, fostering further research and development in this critical area. The method of data curation and training also provides insights into creating more robust and effective evaluation metrics.
Visual Insights#

🔼 Figure 1 presents a comparative analysis of Atla Selene Mini’s performance against other state-of-the-art small language models as judges (SLMJs). Part (a) shows the overall average performance across multiple evaluation tasks, highlighting Atla Selene Mini’s superior performance. Part (b) provides a detailed breakdown of the performance across specific benchmark tasks and task types (absolute scoring, classification, and pairwise preference), offering a granular view of Atla Selene Mini’s strengths and weaknesses in comparison to other SLMJs. Table 1 in the paper provides a complete listing of the benchmarks and their results.
read the caption
Figure 1: Atla Selene Mini outperforms current state-of-the-art SLMJs: a) Overall task-average performance, comparing Atla Selene Mini (black) with the best and most widely used SLMJs. b) Breakdown of performance by task type and benchmark – see Table 1 for full comparison.
| Model | CRAFT-MD | Finance | |||
|---|---|---|---|---|---|
| Medical | Most likely | Relevant | Overall | Bench | |
| terminology | diagnosis | med. hist. | |||
| Atla-Selene-Mini | 0.92 | 0.62 | 0.68 | 0.74 | 0.717 |
| LLama-3.1-8B-Instruct | 0.79 | 0.51 | 0.62 | 0.64 | 0.664 |
🔼 This table presents a detailed comparison of the performance of different small language models used as judges (SLMJs) across various evaluation benchmarks. The benchmarks are categorized into three types of tasks: absolute scoring, classification, and pairwise preference. For each model and benchmark, the table shows the performance score, with bold numbers highlighting the best score achieved in each benchmark column. The table also indicates which models’ previously published performance results are reported here, marked with a † symbol. Atla Selene Mini’s overall performance, averaged across all tasks and benchmarks, is the highest among all the models.
read the caption
Table 1: Detailed breakdown of SLMJ performance: Bold numbers indicate the highest score per column. Atla Selene Mini has the highest overall performance averaged over tasks (sections) and benchmarks (columns). † indicates models for which we report previously published numbers.
In-depth insights#
SLMJ Evaluation#
SLMJ (Small Language Model as Judge) evaluation is a crucial aspect of developing effective and reliable automated evaluation systems for LLMs. A robust evaluation framework needs to consider multiple factors. First, the benchmarks used must be diverse and representative of real-world tasks. This ensures that the SLMJ is not overfit to specific types of problems and can generalize well across various domains. Second, the metrics used to evaluate the SLMJ’s performance are crucial. Simple accuracy may not be sufficient; more nuanced metrics might include correlation with human judgments, consistency across different prompts, and resistance to known biases. Third, the SLMJ’s performance must be compared against strong baselines and other state-of-the-art SLMJs to provide a clear understanding of its strengths and weaknesses. Furthermore, transparency is important. The data used to train and evaluate the SLMJ, along with the evaluation methodology itself, should be made publicly available to facilitate reproducibility and further research. Finally, the impact of factors like prompt engineering and model size needs thorough investigation. These considerations will lead to the development of more rigorous and trustworthy evaluation protocols for SLMJs.
Data Curation#
Data curation in this research paper is a critical process, significantly impacting the performance of the Atla Selene Mini model. The researchers employ a principled data curation strategy that extends beyond simply using existing public datasets. They augment these datasets with synthetically generated critiques and judgments, creating a more comprehensive and balanced training corpus. This augmentation aims to address potential biases in existing data and improve the model’s ability to handle diverse and nuanced evaluation scenarios. A key element of this strategy is the implementation of rigorous filtering and dataset ablation techniques. This step is essential for ensuring high-quality data and mitigating the risk of introducing noise or biases during the training process. The careful selection and filtering of data are crucial for the overall success of the evaluation model, demonstrating a commitment to data quality over quantity. The use of both direct preference optimization and supervised fine-tuning highlights a multifaceted approach that underscores the sophistication of their curation approach and reinforces its importance in creating a high-performing and robust model.
DPO+NLL Training#
The research paper section on “DPO+NLL Training” likely details a novel training approach for language models used in evaluation. Direct Preference Optimization (DPO), a method focusing on directly optimizing for the preferred model output, is combined with Negative Log-Likelihood (NLL) loss. This hybrid approach aims to enhance the model’s ability to discern high-quality outputs. The integration of NLL loss likely ensures the model’s predictions align well with the ground truth. This blend should improve accuracy and robustness, creating an evaluator less susceptible to biases commonly found in LLM evaluations. The results section likely demonstrates the efficacy of this hybrid approach by comparing its performance against models trained using only DPO or SFT, highlighting improvements in accuracy and promptability.
Real-world Robustness#
Real-world robustness is a crucial aspect for evaluating the practical applicability of any model, especially in the context of large language models (LLMs). A model demonstrating strong performance on benchmark datasets might still fail in real-world scenarios due to various factors like noisy or ambiguous inputs, unexpected context shifts, or diverse user interaction styles. Real-world robustness testing goes beyond the confines of curated datasets and necessitates evaluating performance in diverse, unpredictable environments such as interactions with real users, handling unstructured data, and adapting to unforeseen circumstances. The ability of the model to generalize effectively and demonstrate consistent performance despite these variations is key. This often necessitates a shift from purely quantitative metrics to a more holistic evaluation process, potentially incorporating human evaluation to assess the quality of output and overall user experience. Furthermore, robustness testing should specifically target aspects like prompt engineering and resilience against adversarial attacks, where malicious inputs aim to manipulate the model’s output. A thorough assessment of real-world robustness is critical for building trust and ensuring that LLMs can reliably deliver on their intended capabilities in actual applications.
Future of LLMs#
The future of LLMs is bright but uncertain. Continued advancements in model architecture and training techniques will likely lead to even more powerful and versatile models. However, ethical considerations, such as bias mitigation, responsible use, and the potential for misuse, will remain central challenges. Addressing these ethical concerns will require collaboration between researchers, policymakers, and the public. The integration of LLMs into various applications will undoubtedly grow, but success will hinge on developing robust and reliable evaluation metrics to ensure alignment with human values and expectations. Furthermore, research into interpretability and explainability will be critical to foster trust and understand limitations. Ultimately, the future trajectory of LLMs will depend on navigating the complex interplay between technological progress and societal impact.
More visual insights#
More on figures

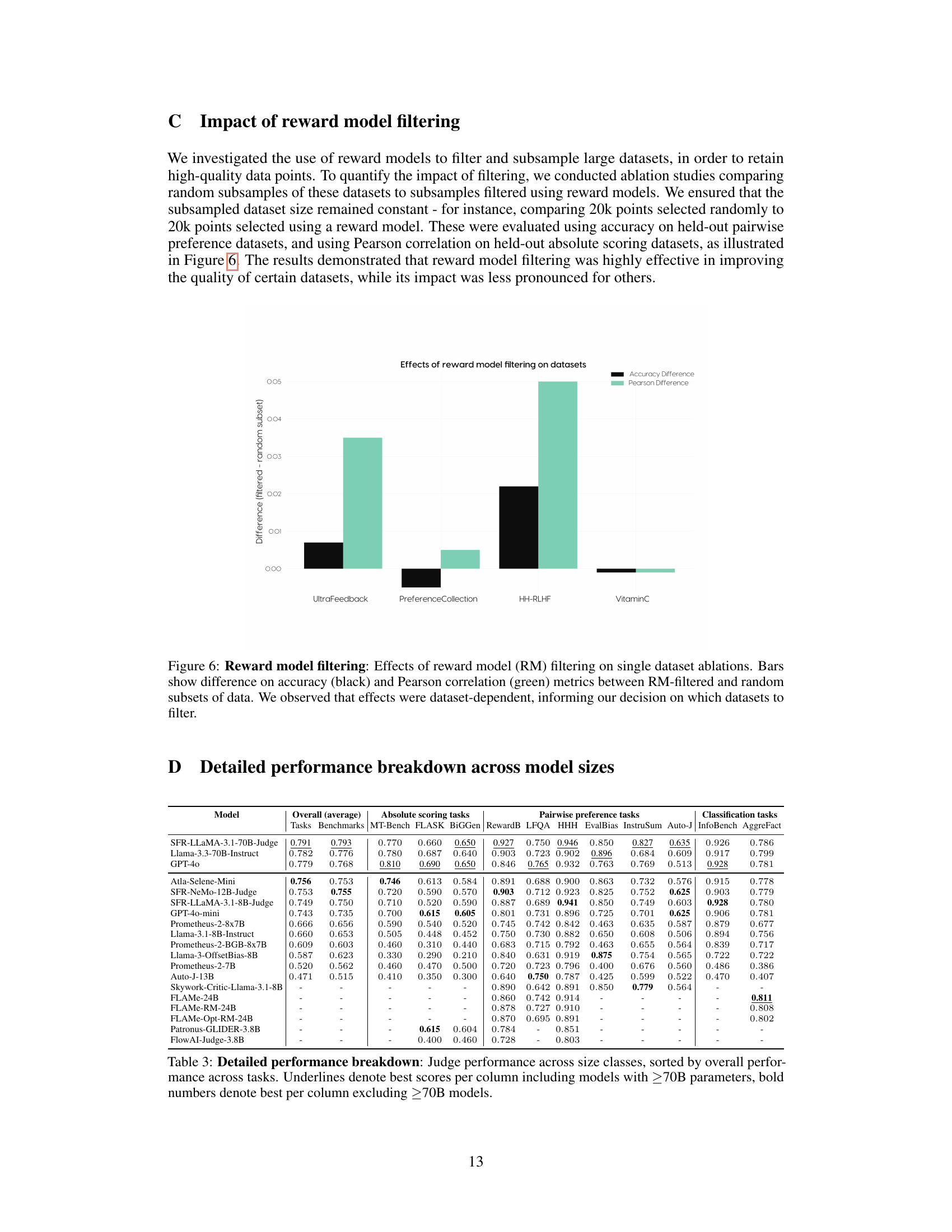
🔼 This figure illustrates the process of creating a high-quality training dataset for Atla Selene Mini. It starts with a candidate dataset, applies filtering to remove low-quality data points, and uses synthetic data generation to augment the dataset with ‘chosen’ and ‘rejected’ pairs. These pairs are generated with chain-of-thought critiques to aid in preference optimization. Ablation studies are performed to determine which datasets to include or exclude from the final training mix. Yellow boxes indicate filtering, purple indicates synthetic pair generation, and red circles represent ablation-informed decisions.
read the caption
Figure 2: Data curation strategy: The process of transforming a candidate dataset (left) into the final training mix (right). Yellow boxes indicate filtering steps, purple represents synthetic generation of chosen and rejected pairs (blue and red) for preference optimization, and red circles highlight ablation-informed decisions, such as reward thresholds and dataset inclusion.

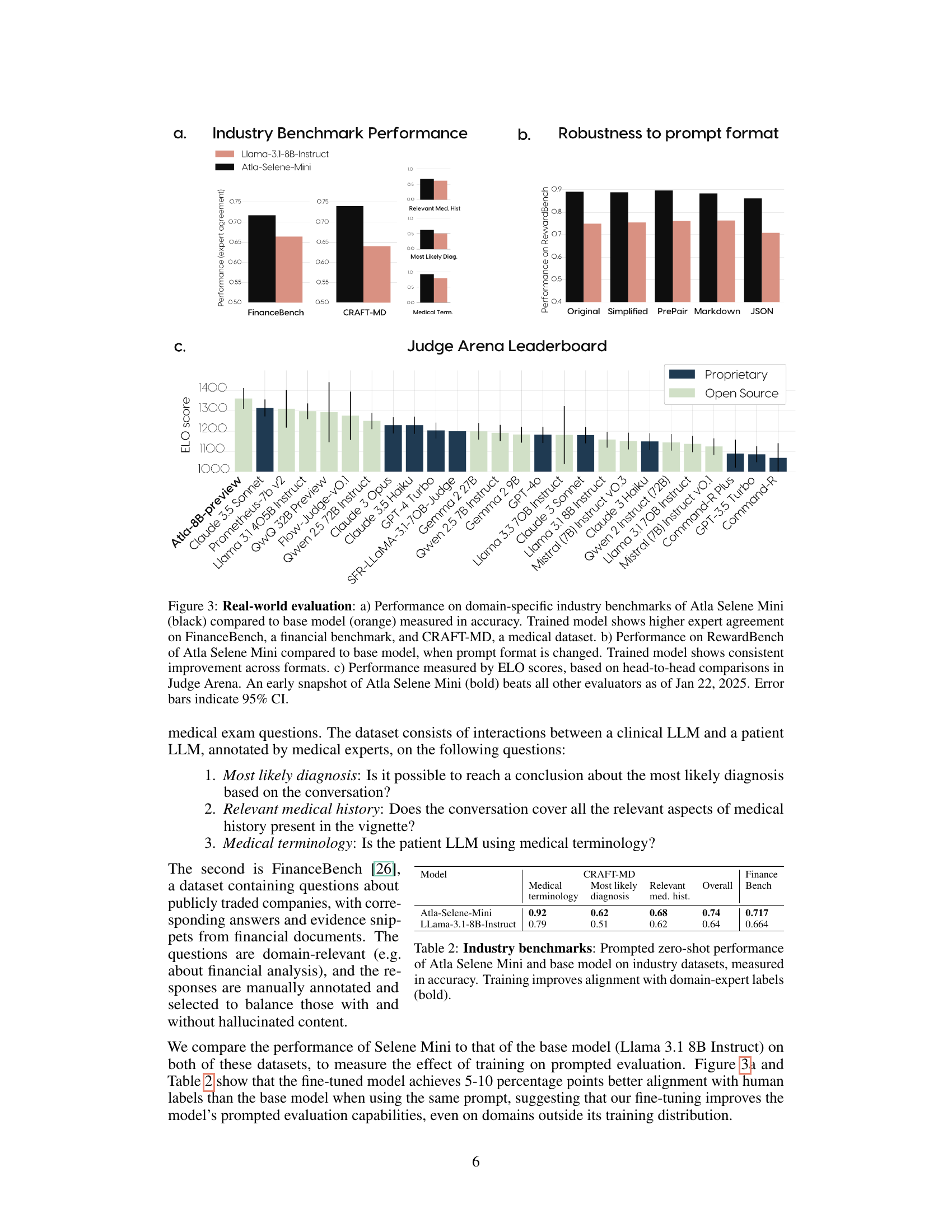
🔼 Figure 3 presents a real-world evaluation of Atla Selene Mini’s performance. Panel (a) shows accuracy comparisons on domain-specific industry benchmarks (FinanceBench and CRAFT-MD), demonstrating improved expert agreement for the trained model versus a base model. Panel (b) illustrates the model’s robustness to prompt format variations on RewardBench, showing consistent performance improvements. Finally, panel (c) displays the model’s ELO score in a community-driven Judge Arena, showcasing its superior performance against other evaluators as of January 22, 2025. Error bars represent 95% confidence intervals.
read the caption
Figure 3: Real-world evaluation: a) Performance on domain-specific industry benchmarks of Atla Selene Mini (black) compared to base model (orange) measured in accuracy. Trained model shows higher expert agreement on FinanceBench, a financial benchmark, and CRAFT-MD, a medical dataset. b) Performance on RewardBench of Atla Selene Mini compared to base model, when prompt format is changed. Trained model shows consistent improvement across formats. c) Performance measured by ELO scores, based on head-to-head comparisons in Judge Arena. An early snapshot of Atla Selene Mini (bold) beats all other evaluators as of Jan 22, 2025. Error bars indicate 95% CI.

🔼 This figure visualizes the training data used for Atla Selene Mini. Using Nomic Atlas, a tool for visualizing datasets, the data is displayed as a two-dimensional embedding. The data points are clustered by topic, providing a visual representation of the diverse topics covered in the training data and how they relate to one another. This helps illustrate the breadth and depth of the training data’s subject matter.
read the caption
Figure 4: Training dataset map: Topic-stratified, two-dimensional embedding representation of Atla Selene Mini’s training dataset generated using Nomic Atlas [33].

🔼 Figure 5 displays a training data example from the FeedbackCollection dataset [34]. It showcases how a prompt, an LLM response, scoring rubrics, and a reference response are used to train Atla Selene Mini. The example includes the evaluation criteria, the LLM’s response, and two different evaluations (one ‘chosen’ and one ‘rejected’) with reasoning for each score. The evaluation is structured to focus on the humor and wit in the author’s note and provides a numeric score from 1 to 5, referencing the provided rubric. The reference answer serves as a guide for assessing the quality of the LLM’s response. This specific prompt template is similar to the one used in [10].
read the caption
Figure 5: Example data point: Training example from FeedbackCollection [34], including the reference response, which is an optional field for Atla Selene Mini. This instance uses a similar prompt template to [10].
Full paper#