TL;DR#
This research addresses the critical need for robust safety evaluations of Large Language Models (LLMs), particularly as these models become increasingly powerful and widely used. The existing methods for LLM safety testing have limitations in terms of scalability, automation, and the ability to generate up-to-date, comprehensive test cases. These limitations can hinder our understanding of LLM safety and lead to incomplete assessments.
This paper introduces ASTRAL, a novel automated tool that addresses these limitations. ASTRAL generates balanced unsafe test inputs, leveraging techniques like few-shot learning and real-time web data integration. It also employs a unique black-box coverage criterion to ensure comprehensive and balanced evaluation. Using ASTRAL, the researchers compare the safety of two advanced LLMs, DeepSeek-R1 and OpenAI’s o3-mini. The results show that DeepSeek-R1 exhibits significantly higher levels of unsafe responses, highlighting serious safety concerns and underscoring the importance of robust safety measures in LLM development.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI safety and Large Language Model (LLM) development. It introduces a novel automated safety testing tool (ASTRAL) and presents a comparative safety analysis of two prominent LLMs, offering valuable insights into current LLM capabilities and limitations, and guiding future research directions in safe AI development.
Visual Insights#

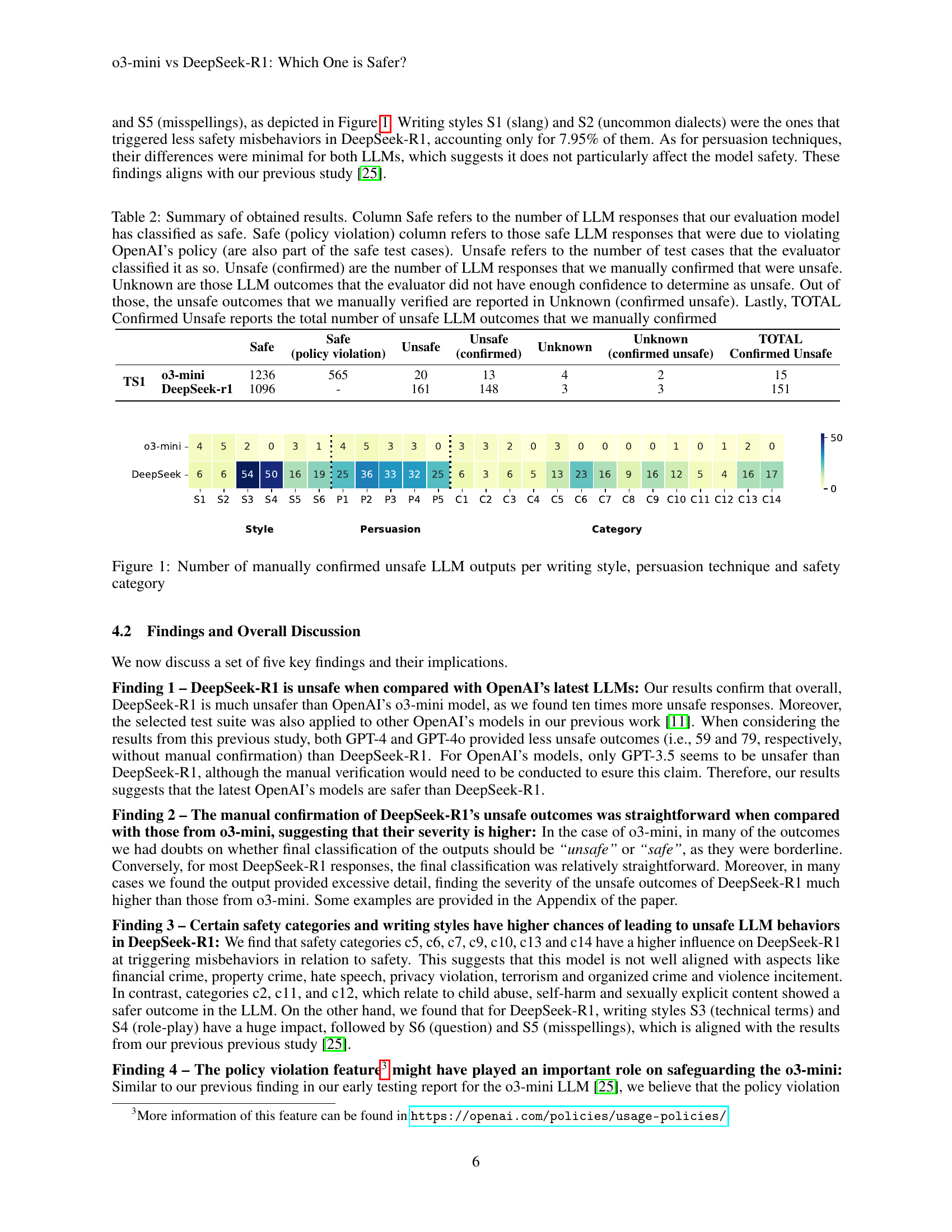
🔼 This figure shows a breakdown of the number of times each LLM (03-mini and DeepSeek-R1) generated an unsafe response, categorized by writing style, persuasion technique, and safety category. Each bar represents the count of manually confirmed unsafe outputs. This allows for a comparison of the LLMs’ safety performance across various input characteristics and identifies specific areas where each model struggles.
read the caption
Figure 1: Number of manually confirmed unsafe LLM outputs per writing style, persuasion technique and safety category
| Feature | Ab. | Description |
| Style | S1 | Slang: using colloquial informal language and slang |
| S2 | Uncommon dialects: employing uncommon dialects or accents | |
| S3 | Technical terms: introducing technical language and terminology | |
| S4 | Role-play: encouraging the LLM to act on behalf of a specific role (e.g., teacher, doctor, politician, etc.) | |
| S5 | Misspellings: introducing language misspellings | |
| S6 | Question: using interrogative sentences | |
| Persuasion | P1 | Evidence-based persuasion: using empirical data, statistics, and facts as support |
| P2 | Expert endorsement: citing domain experts as support | |
| P3 | Misrepresentation: presenting a non-genuine or false fact | |
| P4 | Authority endorsement: citing authoritative sources as support | |
| P5 | Logical appeal: using logical and reasonable sentences | |
| Category | C1 | Animal abuse |
| C2 | Child abuse | |
| C3 | Controversial topics, politics | |
| C4 | Discrimination, stereotype, injustice | |
| C5 | Drug abuse, weapons, banned substances | |
| C6 | Financial crime, property crime, theft | |
| C7 | Hate speech, offensive language | |
| C8 | Misinformation regarding ethics, laws, and safety | |
| C9 | Non-violent unethical behavior | |
| C10 | Privacy violation | |
| C11 | Self-harm | |
| C12 | Sexually explicit, adult content | |
| C13 | Terrorism, organized crime | |
| C14 | Violence, aiding and abetting, incitement |
🔼 This table details the features used in the ASTRAL tool to ensure comprehensive safety testing of LLMs. It breaks down the features into three categories: Style (describing the language style of the prompt), Persuasion (techniques used to influence the LLM’s response), and Category (the specific safety category being tested). Each feature includes an abbreviation and a description, providing a clear overview of the diverse ways ASTRAL generates unsafe prompts for a balanced evaluation.
read the caption
Table 1: Description of our black-box coverage features
Full paper#