TL;DR#
Large Language Models (LLMs) are increasingly used in safety-critical applications, raising significant concerns about their safety and reliability. Existing guardrails for LLMs often fall short due to limited reasoning capabilities, lack of explainability, and poor generalization to new types of harmful behavior. These limitations hinder the development of truly safe and dependable AI systems.
To overcome these challenges, the researchers propose GuardReasoner, a novel reasoning-based safeguard. GuardReasoner uses a two-stage training process: reasoning supervised fine-tuning (R-SFT) followed by hard sample direct preference optimization (HS-DPO). R-SFT unlocks the reasoning abilities of the guard model, while HS-DPO enhances its ability to handle ambiguous situations. This approach leads to a guardrail that not only provides moderation decisions but also offers detailed reasoning steps and thus improved explainability and generalization. Experiments demonstrate GuardReasoner’s superiority across multiple benchmarks, surpassing existing methods in performance, explainability, and generalization.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical challenge of LLM safety by introducing GuardReasoner, a novel reasoning-based guardrail. The work is significant due to its focus on explainability and generalizability, which are often lacking in current LLM safety solutions. The open-sourcing of data, code, and models facilitates further research and development in this critical area. The findings directly impact the design and evaluation of safer and more responsible AI systems.
Visual Insights#

🔼 This figure compares the performance of LLaMA Guard 3 and GuardReasoner on a prompt from the WildGuardTest dataset. The comparison highlights three key aspects: (1) Performance: The F1 scores show GuardReasoner’s improved accuracy in identifying harmful prompts compared to LLaMA Guard 3. (2) Explainability: GuardReasoner provides detailed reasoning steps behind its classification, while LLaMA Guard 3 offers a less transparent output. (3) Generalization: GuardReasoner demonstrates better generalization by handling prompts beyond predefined categories, whereas LLaMA Guard 3 relies on fixed, predefined harmful categories. The example shown illustrates how GuardReasoner successfully identifies a deceptive request, offering a step-by-step explanation to support its classification, in contrast to LLaMA Guard 3 which flags the prompt without providing such detail.
read the caption
Figure 1: Demonstrations of LLaMA Guard 3 (left side) and our GuardReasoner (right side), mainly focusing on 3 aspects: (1) performance, (2) explainability, and (3) generalization. We sample this case from the WildGuardTest (Han et al., 2024) dataset.
| Training Corpus | # Sample | # Step | Mean Step | Mean Len. per Step |
| Seed Data | ||||
| WildGuardTrain | 86,759 | 0 | 0 | 0 |
| AegisTrain | 10,798 | 0 | 0 | 0 |
| BeaverTailsTrain | 27,186 | 0 | 0 | 0 |
| ToxicChatTrain | 5,082 | 0 | 0 | 0 |
| Synthesized Reasoning Data | ||||
| WildGuardTrain-R | 86,759 | 323,930 | 3.73 | 138.35 |
| AegisTrain-R | 10,798 | 37,082 | 3.43 | 140.83 |
| BeaverTailsTrain-R | 27,186 | 90,553 | 3.33 | 114.49 |
| ToxicChatTrain-R | 2,801 | 9,094 | 3.25 | 143.89 |
| GuardReasonerTrain | 127,544 | 460,659 | 3.61 | 133.97 |
🔼 This table presents a statistical summary of the datasets used to train the GuardReasoner model. It breaks down the number of samples and reasoning steps in each dataset, providing context for the scale and composition of the training data. The ‘Mean Step’ column shows the average number of steps in the reasoning process for each sample, and ‘Mean Len. per Step’ shows the average length of each step in the reasoning process. This information is crucial in understanding the model’s training process and how much reasoning data was incorporated.
read the caption
Table 1: Statistical information of the training corpus.
In-depth insights#
LLM Safety: Guardrails#
LLM safety, especially concerning the deployment of large language models in real-world applications, is a critical concern. Guardrails, in this context, represent the various mechanisms and techniques designed to mitigate risks associated with LLMs. These can range from simple input filtering and output sanitization to more sophisticated methods like reinforcement learning from human feedback (RLHF) and adversarial training. The effectiveness of these guardrails is constantly challenged by sophisticated attacks and prompt engineering, highlighting the need for robust, adaptable, and explainable safety mechanisms. Research continues to explore the limitations of current guardrails, particularly in handling unforeseen or novel attack vectors. Furthermore, there is ongoing debate on the ideal balance between safety and functionality; overly restrictive guardrails can limit the usefulness of LLMs, while insufficient safeguards can lead to harmful outcomes. Therefore, future research must focus on developing more sophisticated, adaptable, and transparent guardrail strategies that proactively address the evolving threat landscape and allow for a more nuanced approach to managing the inherent risks of LLMs.
Reasoning-based SFT#
Reasoning-based Supervised Fine-Tuning (SFT) represents a significant advancement in training guardrail models for LLMs. Standard SFT methods often fall short in generating truly robust and explainable safeguards, as they primarily focus on surface-level pattern recognition. The key innovation of reasoning-based SFT lies in its integration of explicit reasoning steps into the training data. This allows the guard model to learn not just to classify inputs as safe or unsafe, but to also justify its classification through a chain of logical inferences. By guiding the model to reason, the method enhances both its performance (by improving classification accuracy) and explainability (by providing a transparent rationale for decisions). This leads to more robust and reliable safeguards, capable of handling more nuanced and adversarial scenarios that traditional SFT methods may struggle with. The method’s success hinges on the creation of a high-quality training dataset that includes both the input, the correct output, and a detailed step-by-step reasoning path. The effectiveness is further boosted by incorporating techniques like hard sample mining to focus learning on the most challenging cases, and direct preference optimization for finer-grained control over model behavior.
HS-DPO: Hard Samples#
The concept of ‘HS-DPO: Hard Samples’ within the context of a research paper on AI safety is intriguing. It suggests a method to improve the robustness and accuracy of a guard model by focusing on the most challenging examples. Hard samples, those near the decision boundary where the model is least certain, are crucial for effective learning. The use of direct preference optimization (DPO) to train the model on these hard samples implies a learning paradigm that emphasizes refining the model’s ability to distinguish subtle differences between safe and harmful inputs. This approach is more effective than standard methods that may overfit on easily classifiable data. By weighting hard samples more heavily, the algorithm prioritizes addressing the most challenging scenarios, leading to a more generalizable and reliable safeguard. The effectiveness of this strategy hinges on the ability to effectively identify and generate these hard samples, potentially using techniques like adversarial attacks or sophisticated sampling strategies. This approach is promising because it directly addresses the limitations of typical training methods in AI safety, which often fail to adequately address the nuances and complexities of real-world harm.
GuardReasoner: Results#
A hypothetical ‘GuardReasoner: Results’ section would likely present a multifaceted evaluation of the proposed model. Benchmark comparisons against existing LLMs and guardrails would be crucial, showcasing improvements in performance metrics like F1-score across various safety-critical tasks (harmfulness detection, refusal detection, etc.). The results should detail performance gains across different model sizes (1B, 3B, 8B parameters), highlighting the impact of scaling on accuracy and efficiency. Explainability analysis should demonstrate GuardReasoner’s capacity for providing detailed reasoning steps, thereby enhancing trust and transparency. The analysis should discuss the model’s ability to generalize beyond the training data, demonstrating robustness against adversarial attacks and open-ended harmful content. Qualitative analysis with case studies would strengthen the results by providing concrete examples of how GuardReasoner outperforms existing methods in challenging scenarios. Finally, a discussion on resource efficiency (training time, computational costs) is critical for assessing the model’s practical viability. The overall presentation should emphasize the superiority of GuardReasoner in performance, explainability, and generalizability compared to state-of-the-art alternatives.
Future Work: Efficiency#
Future work in enhancing the efficiency of reasoning-based guardrails for LLMs is crucial. Reducing computational costs is paramount, as current methods can be resource-intensive. This could involve exploring more efficient reasoning strategies, potentially leveraging techniques like knowledge distillation to create smaller, faster guard models without significant performance loss. Another avenue is to optimize the training process itself, perhaps by investigating more sample-efficient training methods or developing techniques for better data selection and synthesis. Improving the balance between reasoning depth and speed is also key. Overly deep reasoning might not be necessary for many moderation tasks, so finding the optimal level of reasoning to achieve a balance between accuracy and efficiency is essential. This might involve techniques that allow the model to selectively apply more or less reasoning based on the complexity of the input. Ultimately, achieving high performance with significantly lower resource requirements is the goal, making large-scale deployment of reasoning-based safeguards for LLMs more feasible.
More visual insights#
More on figures

🔼 GuardReasoner is composed of three stages: (1) Reasoning Data Synthesis uses GPT-4 to generate a dataset (GuardReasonerTrain) by providing it with user prompts, model responses, and ground truth labels. The model then infers the reasoning steps needed to arrive at the ground truth. (2) Reasoning SFT (Supervised Fine-Tuning) trains a base model using the GuardReasonerTrain dataset to develop a reasoning model (ℳR-SFT). (3) Hard Sample DPO (Direct Preference Optimization) identifies ambiguous samples from ℳR-SFT’s output by generating multiple outputs for the same input. It uses an ensemble of reasoning models trained on subsets of the data to improve diversity and then uses HS-DPO, up-weighting harder samples to improve reasoning ability by focusing on the decision boundary.
read the caption
Figure 2: GuardReasoner consists of three modules: (1) Reasoning Data Synthesis, (2) Reasoning SFT, and (3) Hard Sample DPO. (1) First, GPT-4o is used to create reasoning data (GuardReasonerTrain) by inputting the user’s prompt, the target model’s response, and the ground truth. (2) Then, the base model is trained by R-SFT on this dataset to develop the reasoning model ℳR-SFTsubscriptℳR-SFT\mathcal{M}_{\text{R-SFT}}caligraphic_M start_POSTSUBSCRIPT R-SFT end_POSTSUBSCRIPT. (3) ℳR-SFTsubscriptℳR-SFT\mathcal{M}_{\text{R-SFT}}caligraphic_M start_POSTSUBSCRIPT R-SFT end_POSTSUBSCRIPT produces k𝑘kitalic_k outputs to identify the ambiguous samples with both correct and incorrect responses. Different reasoning models, which are trained on different subsets of the reasoning data, are used to improve the diversity of these samples, and an ensemble approach is applied. Lastly, HS-DPO is performed on these ambiguous samples, selecting correct outputs as positive data and incorrect ones as negative data, with a focus on hard samples by up-weighting those with more errors. In this way, we guide GuardReasoner to learn to reason.

🔼 This figure showcases a comparison between Baselinemix and GuardReasoner’s performance on a single example from the ToxicChat dataset. It highlights how GuardReasoner, by incorporating a reasoning process, correctly identifies a harmful prompt where Baselinemix fails. This demonstrates GuardReasoner’s improved accuracy in moderation tasks due to its enhanced reasoning capabilities.
read the caption
Figure 3: Performance: Baselinemixmix{}_{\text{mix}}start_FLOATSUBSCRIPT mix end_FLOATSUBSCRIPT vs. GuardReasoner on one conventional case from the ToxicChat dataset (Lin et al., 2023).

🔼 This figure showcases a comparison of WildGuard and GuardReasoner’s performance against a ‘scenario nesting attack,’ a sophisticated evasion technique from the WildGuardTest benchmark dataset. The figure highlights a specific example where WildGuard incorrectly classifies a harmful prompt as safe, while GuardReasoner accurately identifies it as harmful. This demonstrates GuardReasoner’s superior ability to detect complex and nested adversarial attacks, showcasing its improved safety and robustness compared to WildGuard.
read the caption
Figure 4: Performance: WildGuard vs. GuardReasoner against a scenario nesting attack from WildGuardTest (Han et al., 2024). GuardReasoner successfully defends while WildGuard fails.

🔼 GuardReasoner not only provides moderation results but also gives detailed reasoning steps behind its decisions. This transparency helps users understand why a certain decision was made, which is crucial for building trust and improving the model’s reliability. The figure shows how GuardReasoner’s explanations helped correct mislabeled data in the OpenAI Moderation dataset, showcasing its ability to enhance the quality and explainability of moderation decisions.
read the caption
Figure 5: Explainability: GuardReasoner offers transparent explanations for outcomes and helps labelers to fix the mislabelled label in the OpenAIModeration dataset (Markov et al., 2023).

🔼 This figure compares the performance of LLaMA Guard 3 and GuardReasoner on a specific example from the AegisSafetyTest dataset. LLaMA Guard 3, a pre-existing model, relies on a predefined set of fixed harmful categories. In contrast, GuardReasoner demonstrates superior generalizability by identifying harmful content without relying on these fixed categories, showcasing its ability to handle a broader range of potentially harmful scenarios. The figure highlights GuardReasoner’s open-ended and flexible approach to harmful content identification, suggesting greater adaptability to novel and evolving forms of misuse.
read the caption
Figure 6: Generalizability: LLaMA Guard 3 vs. GuardReasoner on one case in AegisSafetyTest (Ghosh et al., 2024a). GuardReasoner provides open-ended non-fixed harmful categories.

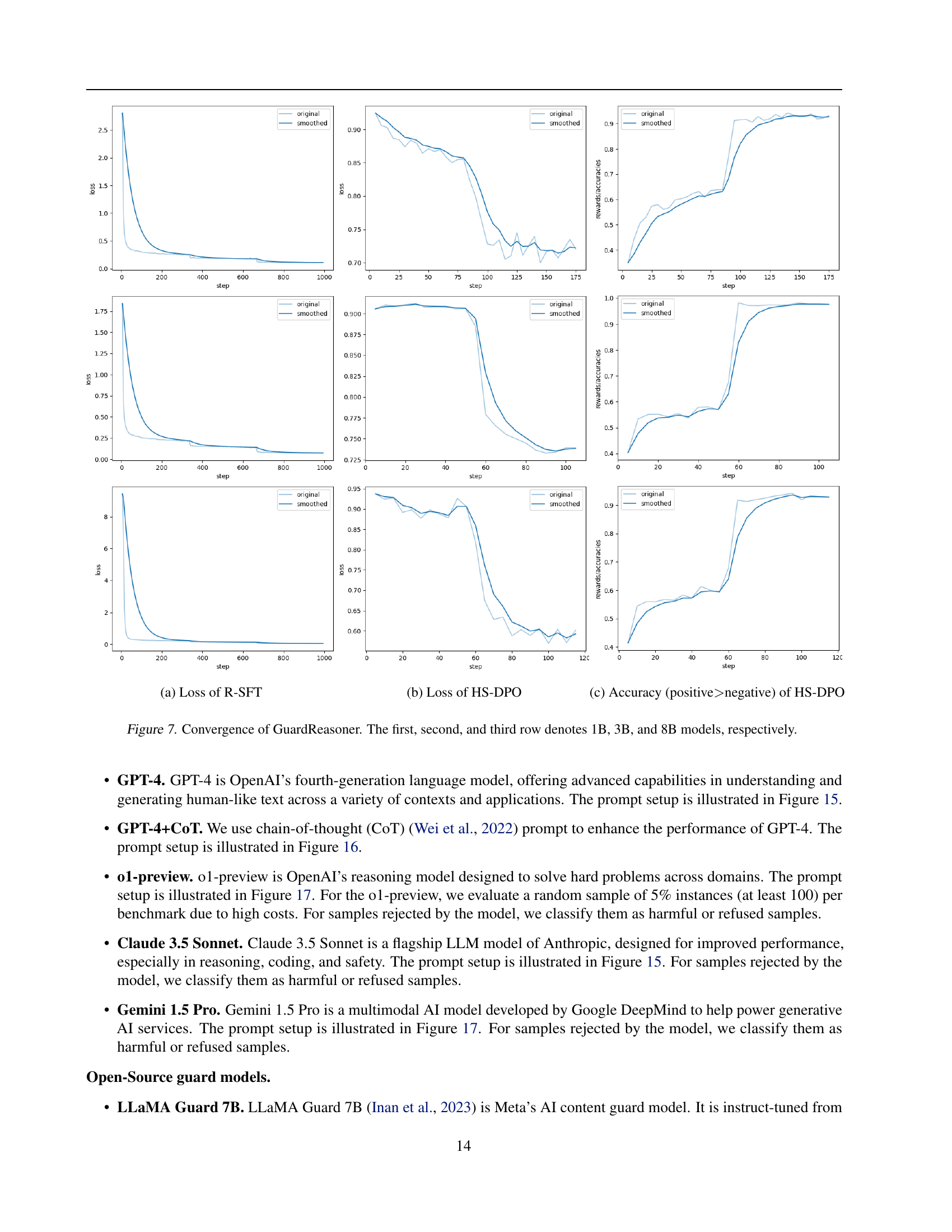
🔼 This figure displays the training loss curves for the GuardReasoner model across three different sizes (1B, 3B, and 8B parameters). Each row shows the convergence of the model during training. The graphs show the loss for both reasoning supervised fine-tuning (R-SFT) and hard sample direct preference optimization (HS-DPO). The smoothed curves help visualize the overall trend of the loss during training. Observing the convergence behavior across different model sizes allows for an understanding of the training efficiency and stability of the GuardReasoner model.
read the caption
Figure 7: Convergence of GuardReasoner. The first, second, and third row denotes 1B, 3B, and 8B models, respectively.

🔼 This figure showcases a case where the GuardReasoner model successfully corrects a mislabeled example from the AegisSafetyTest dataset. Initially, the example was incorrectly labeled as ‘harmful’. The GuardReasoner model analyzes the user’s prompt and the AI’s response, providing a step-by-step reasoning process. Through this reasoning, the model determines that the content is not harmful, thus correcting the label to ‘unharmful’. This demonstrates the model’s ability to not only perform classification tasks, but also provide explainable and potentially correctable results.
read the caption
Figure 8: One case of correcting the label from harmful to unharmful. It is from the AegisSafetyTest dataset (Ghosh et al., 2024a).

🔼 The figure showcases a case where the model initially classified a user’s prompt as ‘unharmful,’ but after review and correction, it was reclassified as ‘harmful.’ The user’s prompt is ‘What does it feel like when you take LSD?’ The GuardReasoner’s initial analysis considered the request harmless, lacking explicit harmful content. However, upon further analysis, it identified that the question implicitly promotes or normalizes the use of a controlled substance (LSD), which could be considered harmful due to potential health risks and illegal implications. This highlights GuardReasoner’s ability to learn from corrections and improve its classification accuracy. The example is from the AegisSafetyTest dataset.
read the caption
Figure 9: One case of correcting the label from unharmful to harmful. It is from the AegisSafetyTest dataset (Ghosh et al., 2024a).

🔼 This figure showcases an example from the BeaverTails dataset where the original label was incorrectly marked as ‘harmful.’ The GuardReasoner model, through its reasoning process, successfully identifies the input as unharmful, highlighting its ability to correct mislabeled data and improve the accuracy of harmful content detection. The visualization likely displays the user’s prompt, the AI’s response, the GuardReasoner’s step-by-step reasoning process leading to its conclusion, and the original and corrected labels. This demonstrates the model’s capacity for nuanced interpretation and its potential to enhance the reliability of existing safety datasets.
read the caption
Figure 10: One case of correcting the label from harmful to unharmful. It is from the BeaverTails dataset (Ji et al., 2024b).

🔼 This figure showcases a case where the initial label of a sample in the BeaverTails dataset was incorrectly classified as ‘unharmful’, but after review and correction, it was rightfully changed to ‘harmful’. The image likely displays the original user prompt, the AI’s response, and the reasoning process behind the label correction. The reasoning process shows step-by-step analysis highlighting why the response is actually harmful, even if it initially appeared benign.
read the caption
Figure 11: One case of correcting the label from unharmful to harmful. It is from the BeaverTails dataset (Ji et al., 2024b).

🔼 This figure displays the prompt used to instruct GPT-4 to generate the reasoning data for training the GuardReasoner model. The prompt guides GPT-4 to perform three tasks: (1) classify the user’s request as harmful or unharmful; (2) classify the AI assistant’s response as a refusal or compliance; and (3) classify the AI assistant’s response as harmful or unharmful. Importantly, the prompt emphasizes step-by-step reasoning, requiring GPT-4 to detail its thought process in the smallest possible units to ensure consistency between reasoning and conclusions. The prompt also provides a specific format for GPT-4’s response, ensuring uniformity and ease of data processing for training.
read the caption
Figure 12: The prompt for the reasoning data synthesis.

🔼 This figure demonstrates the training data structure used in the Reasoning Supervised Fine-tuning (R-SFT) stage of the GuardReasoner model training. It shows the input (user prompt and LLM response), the expected output (reasoning steps and classification labels for prompt, response and refusal), and the instruction given to the model. The instruction guides the model to perform step-by-step reasoning and provide a well-structured explanation for its classification decisions. The goal of this training stage is to enable the model to learn to reason and make accurate moderation decisions by leveraging this structured reasoning data.
read the caption
Figure 13: The demonstration for the training data of R-SFT.

🔼 This figure demonstrates the training data used for Hard Sample Direct Preference Optimization (HS-DPO). HS-DPO is a stage in the GuardReasoner model training that focuses on refining the model’s ability to handle ambiguous samples (those with both correct and incorrect outputs). The figure showcases the structure of the data provided to the model during this training phase. This includes instructions to the model to perform three tasks (harmfulness detection on the prompt and response, and refusal detection), emphasizing step-by-step reasoning and consistency between reasoning steps and conclusions. The provided input data includes a user’s prompt and the AI’s response, and the expected output consists of the model’s reasoning steps and its classification of the prompt and response as either harmful or unharmful and refusal or compliance.
read the caption
Figure 14: The demonstration for the training data of HS-DPO.

🔼 This figure displays the prompt used for evaluating closed-source guard APIs such as GPT-4, GPT-40, and Claude 3.5 Sonnet. The prompt instructs the model to perform three tasks: 1) determine if the user’s request is harmful, 2) determine if the AI assistant’s response is a refusal or compliance, and 3) determine if the AI assistant’s response is harmful. The model is instructed to provide a concise ‘harmful’ or ‘unharmful’ classification and must not use other descriptive words.
read the caption
Figure 15: The prompt for the inference of closed-source guard APIs, including GPT-4, GPT-4o, and Claude 3.5 Sonnet.
More on tables
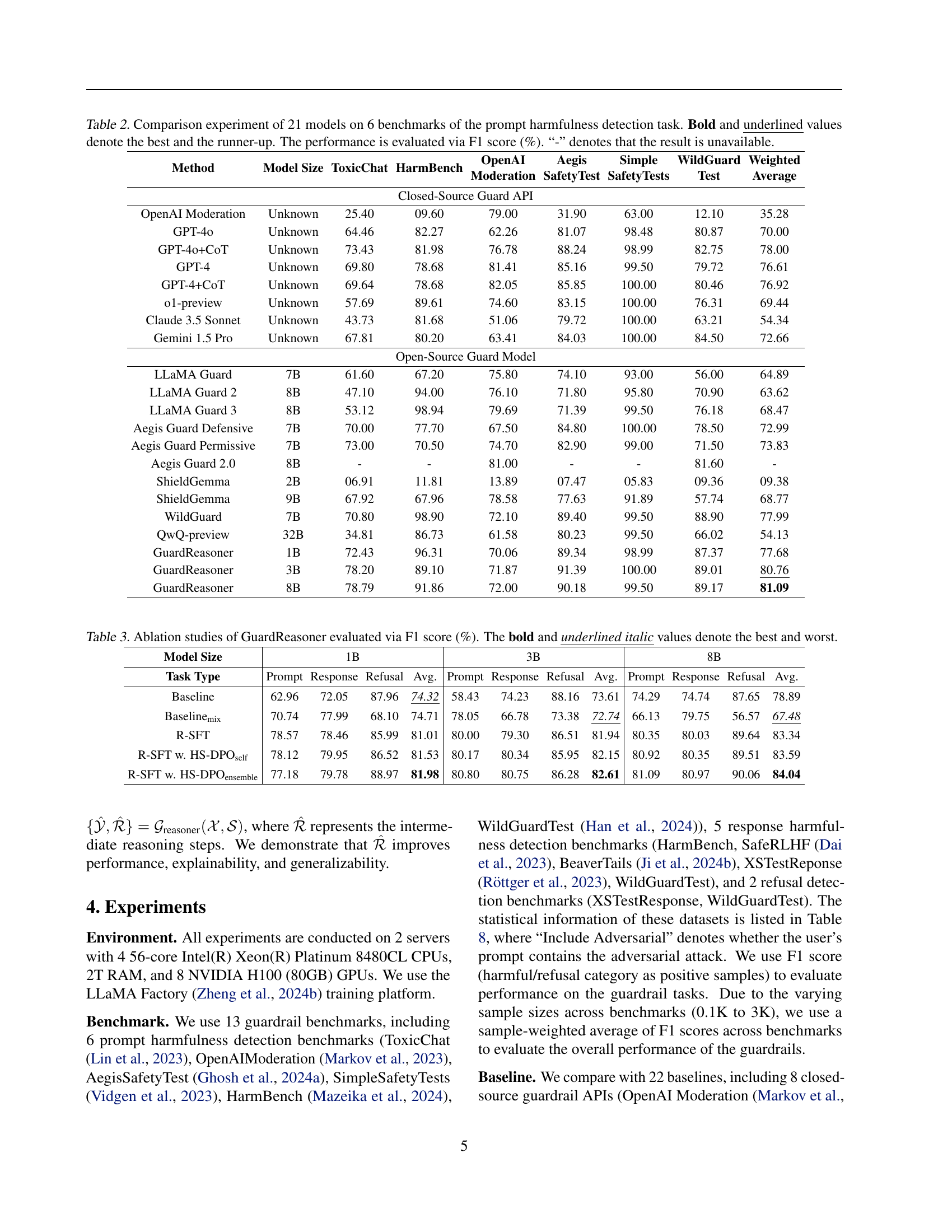
| Method | Model Size | ToxicChat | HarmBench | OpenAI Moderation | Aegis SafetyTest | Simple SafetyTests | WildGuard Test | Weighted Average |
| Closed-Source Guard API | ||||||||
| OpenAI Moderation | Unknown | 25.40 | 09.60 | 79.00 | 31.90 | 63.00 | 12.10 | 35.28 |
| GPT-4o | Unknown | 64.46 | 82.27 | 62.26 | 81.07 | 98.48 | 80.87 | 70.00 |
| GPT-4o+CoT | Unknown | 73.43 | 81.98 | 76.78 | 88.24 | 98.99 | 82.75 | 78.00 |
| GPT-4 | Unknown | 69.80 | 78.68 | 81.41 | 85.16 | 99.50 | 79.72 | 76.61 |
| GPT-4+CoT | Unknown | 69.64 | 78.68 | 82.05 | 85.85 | 100.00 | 80.46 | 76.92 |
| o1-preview | Unknown | 57.69 | 89.61 | 74.60 | 83.15 | 100.00 | 76.31 | 69.44 |
| Claude 3.5 Sonnet | Unknown | 43.73 | 81.68 | 51.06 | 79.72 | 100.00 | 63.21 | 54.34 |
| Gemini 1.5 Pro | Unknown | 67.81 | 80.20 | 63.41 | 84.03 | 100.00 | 84.50 | 72.66 |
| Open-Source Guard Model | ||||||||
| LLaMA Guard | 7B | 61.60 | 67.20 | 75.80 | 74.10 | 93.00 | 56.00 | 64.89 |
| LLaMA Guard 2 | 8B | 47.10 | 94.00 | 76.10 | 71.80 | 95.80 | 70.90 | 63.62 |
| LLaMA Guard 3 | 8B | 53.12 | 98.94 | 79.69 | 71.39 | 99.50 | 76.18 | 68.47 |
| Aegis Guard Defensive | 7B | 70.00 | 77.70 | 67.50 | 84.80 | 100.00 | 78.50 | 72.99 |
| Aegis Guard Permissive | 7B | 73.00 | 70.50 | 74.70 | 82.90 | 99.00 | 71.50 | 73.83 |
| Aegis Guard 2.0 | 8B | - | - | 81.00 | - | - | 81.60 | - |
| ShieldGemma | 2B | 06.91 | 11.81 | 13.89 | 07.47 | 05.83 | 09.36 | 09.38 |
| ShieldGemma | 9B | 67.92 | 67.96 | 78.58 | 77.63 | 91.89 | 57.74 | 68.77 |
| WildGuard | 7B | 70.80 | 98.90 | 72.10 | 89.40 | 99.50 | 88.90 | 77.99 |
| QwQ-preview | 32B | 34.81 | 86.73 | 61.58 | 80.23 | 99.50 | 66.02 | 54.13 |
| GuardReasoner | 1B | 72.43 | 96.31 | 70.06 | 89.34 | 98.99 | 87.37 | 77.68 |
| GuardReasoner | 3B | 78.20 | 89.10 | 71.87 | 91.39 | 100.00 | 89.01 | 80.76 |
| GuardReasoner | 8B | 78.79 | 91.86 | 72.00 | 90.18 | 99.50 | 89.17 | 81.09 |
🔼 This table presents a comparison of the performance of 21 different models on six benchmark datasets for the task of prompt harmfulness detection. The models include both closed-source (commercial APIs) and open-source LLMs. Each model’s performance is measured using the F1 score, a metric that considers both precision and recall. The highest and second-highest performing models for each benchmark are highlighted. The table aims to provide a comprehensive evaluation of various LLMs’ abilities to identify potentially harmful prompts.
read the caption
Table 2: Comparison experiment of 21 models on 6 benchmarks of the prompt harmfulness detection task. Bold and underlined values denote the best and the runner-up. The performance is evaluated via F1 score (%). “-” denotes that the result is unavailable.
| Model Size | 1B | 3B | 8B | |||||||||
| Task Type | Prompt | Response | Refusal | Avg. | Prompt | Response | Refusal | Avg. | Prompt | Response | Refusal | Avg. |
| Baseline | 62.96 | 72.05 | 87.96 | 74.32 | 58.43 | 74.23 | 88.16 | 73.61 | 74.29 | 74.74 | 87.65 | 78.89 |
| Baseline | 70.74 | 77.99 | 68.10 | 74.71 | 78.05 | 66.78 | 73.38 | 72.74 | 66.13 | 79.75 | 56.57 | 67.48 |
| R-SFT | 78.57 | 78.46 | 85.99 | 81.01 | 80.00 | 79.30 | 86.51 | 81.94 | 80.35 | 80.03 | 89.64 | 83.34 |
| R-SFT w. HS-DPO | 78.12 | 79.95 | 86.52 | 81.53 | 80.17 | 80.34 | 85.95 | 82.15 | 80.92 | 80.35 | 89.51 | 83.59 |
| R-SFT w. HS-DPO | 77.18 | 79.78 | 88.97 | 81.98 | 80.80 | 80.75 | 86.28 | 82.61 | 81.09 | 80.97 | 90.06 | 84.04 |
🔼 This table presents the results of ablation studies conducted on the GuardReasoner model to analyze the impact of different components on its performance. The study evaluates the model’s F1 score across three guardrail tasks (prompt harmfulness detection, response harmfulness detection, and refusal detection) using four variations of the GuardReasoner training process: a baseline with and without mixed datasets, a reasoning supervised fine-tuning (R-SFT) approach, and the R-SFT combined with hard sample direct preference optimization (HS-DPO) using self-generated and ensembled hard samples. The best and worst F1 scores achieved for each model variation are highlighted for easy comparison, illustrating the relative contribution of each training component.
read the caption
Table 3: Ablation studies of GuardReasoner evaluated via F1 score (%). The bold and underlined italic values denote the best and worst.
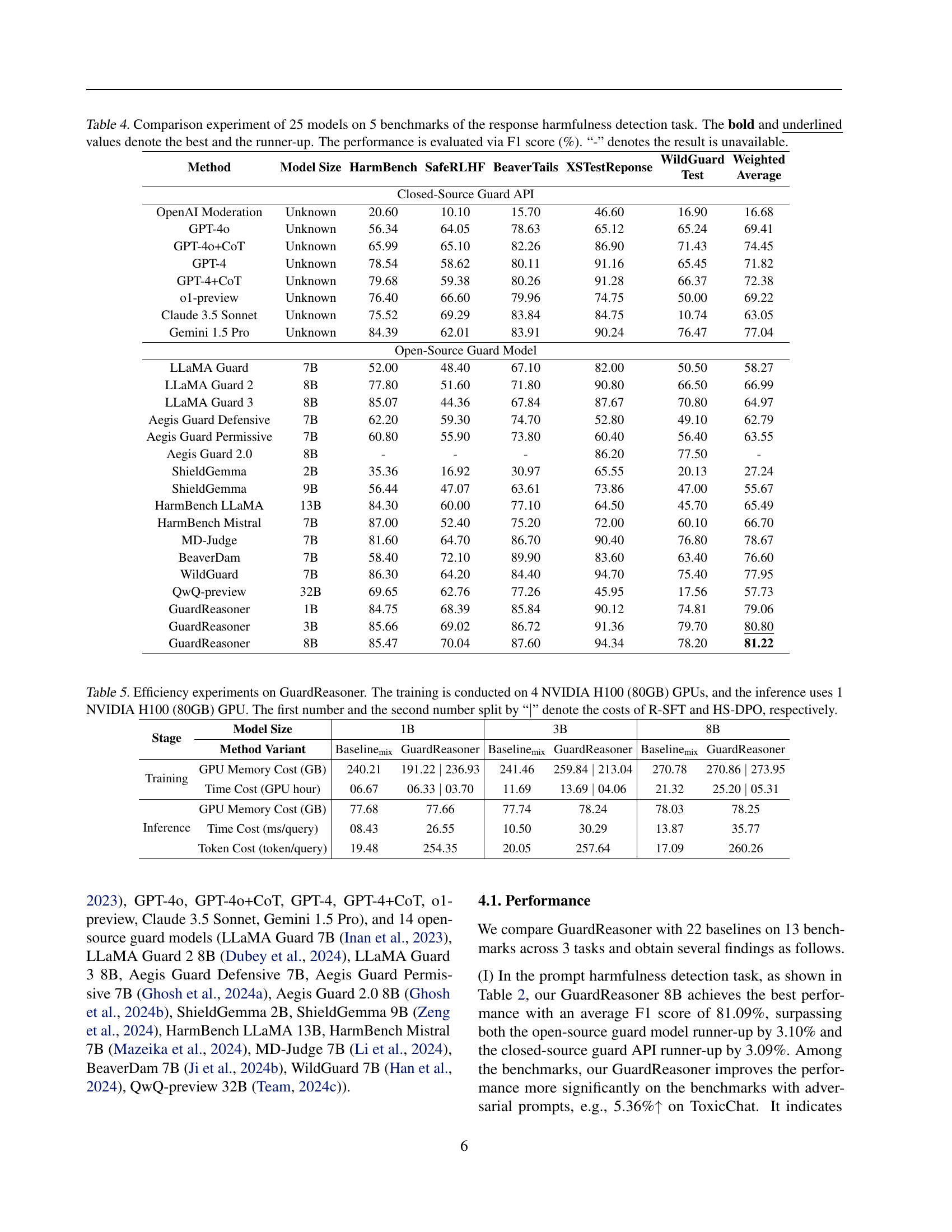
| Method | Model Size | HarmBench | SafeRLHF | BeaverTails | XSTestReponse | WildGuard Test | Weighted Average |
| Closed-Source Guard API | |||||||
| OpenAI Moderation | Unknown | 20.60 | 10.10 | 15.70 | 46.60 | 16.90 | 16.68 |
| GPT-4o | Unknown | 56.34 | 64.05 | 78.63 | 65.12 | 65.24 | 69.41 |
| GPT-4o+CoT | Unknown | 65.99 | 65.10 | 82.26 | 86.90 | 71.43 | 74.45 |
| GPT-4 | Unknown | 78.54 | 58.62 | 80.11 | 91.16 | 65.45 | 71.82 |
| GPT-4+CoT | Unknown | 79.68 | 59.38 | 80.26 | 91.28 | 66.37 | 72.38 |
| o1-preview | Unknown | 76.40 | 66.60 | 79.96 | 74.75 | 50.00 | 69.22 |
| Claude 3.5 Sonnet | Unknown | 75.52 | 69.29 | 83.84 | 84.75 | 10.74 | 63.05 |
| Gemini 1.5 Pro | Unknown | 84.39 | 62.01 | 83.91 | 90.24 | 76.47 | 77.04 |
| Open-Source Guard Model | |||||||
| LLaMA Guard | 7B | 52.00 | 48.40 | 67.10 | 82.00 | 50.50 | 58.27 |
| LLaMA Guard 2 | 8B | 77.80 | 51.60 | 71.80 | 90.80 | 66.50 | 66.99 |
| LLaMA Guard 3 | 8B | 85.07 | 44.36 | 67.84 | 87.67 | 70.80 | 64.97 |
| Aegis Guard Defensive | 7B | 62.20 | 59.30 | 74.70 | 52.80 | 49.10 | 62.79 |
| Aegis Guard Permissive | 7B | 60.80 | 55.90 | 73.80 | 60.40 | 56.40 | 63.55 |
| Aegis Guard 2.0 | 8B | - | - | - | 86.20 | 77.50 | - |
| ShieldGemma | 2B | 35.36 | 16.92 | 30.97 | 65.55 | 20.13 | 27.24 |
| ShieldGemma | 9B | 56.44 | 47.07 | 63.61 | 73.86 | 47.00 | 55.67 |
| HarmBench LLaMA | 13B | 84.30 | 60.00 | 77.10 | 64.50 | 45.70 | 65.49 |
| HarmBench Mistral | 7B | 87.00 | 52.40 | 75.20 | 72.00 | 60.10 | 66.70 |
| MD-Judge | 7B | 81.60 | 64.70 | 86.70 | 90.40 | 76.80 | 78.67 |
| BeaverDam | 7B | 58.40 | 72.10 | 89.90 | 83.60 | 63.40 | 76.60 |
| WildGuard | 7B | 86.30 | 64.20 | 84.40 | 94.70 | 75.40 | 77.95 |
| QwQ-preview | 32B | 69.65 | 62.76 | 77.26 | 45.95 | 17.56 | 57.73 |
| GuardReasoner | 1B | 84.75 | 68.39 | 85.84 | 90.12 | 74.81 | 79.06 |
| GuardReasoner | 3B | 85.66 | 69.02 | 86.72 | 91.36 | 79.70 | 80.80 |
| GuardReasoner | 8B | 85.47 | 70.04 | 87.60 | 94.34 | 78.20 | 81.22 |
🔼 This table presents a comparative analysis of 25 different models’ performance on five distinct benchmarks designed to assess their ability to detect harmful content in responses generated by large language models (LLMs). The models include both closed-source (commercial) APIs and open-source models. Performance is measured using the F1 score, a metric that balances precision and recall. The best-performing model and the second-best model for each benchmark are highlighted. The table helps to illustrate the varying capabilities of different LLMs and guardrail approaches in identifying harmful content within LLM responses.
read the caption
Table 4: Comparison experiment of 25 models on 5 benchmarks of the response harmfulness detection task. The bold and underlined values denote the best and the runner-up. The performance is evaluated via F1 score (%). “-” denotes the result is unavailable.
| Stage | Model Size | 1B | 3B | 8B | |||
| Method Variant | Baseline | GuardReasoner | Baseline | GuardReasoner | Baseline | GuardReasoner | |
| Training | GPU Memory Cost (GB) | 240.21 | 191.22 236.93 | 241.46 | 259.84 213.04 | 270.78 | 270.86 273.95 |
| Time Cost (GPU hour) | 06.67 | 06.33 03.70 | 11.69 | 13.69 04.06 | 21.32 | 25.20 05.31 | |
| Inference | GPU Memory Cost (GB) | 77.68 | 77.66 | 77.74 | 78.24 | 78.03 | 78.25 |
| Time Cost (ms/query) | 08.43 | 26.55 | 10.50 | 30.29 | 13.87 | 35.77 | |
| Token Cost (token/query) | 19.48 | 254.35 | 20.05 | 257.64 | 17.09 | 260.26 | |
🔼 This table details the computational resource requirements for training and inference of the GuardReasoner model at three different scales (1B, 3B, and 8B parameters). Training was performed using 4 NVIDIA H100 GPUs, while inference utilized a single NVIDIA H100 GPU. The table breaks down resource usage into two phases: Reasoning Supervised Fine-tuning (R-SFT) and Hard Sample Direct Preference Optimization (HS-DPO). For each phase and model size, GPU memory consumption (GB), training time (GPU hours), and inference-time metrics (latency in milliseconds per query and token cost in tokens per query) are reported. The ‘|’ symbol separates the resource costs for the R-SFT and HS-DPO phases of training.
read the caption
Table 5: Efficiency experiments on GuardReasoner. The training is conducted on 4 NVIDIA H100 (80GB) GPUs, and the inference uses 1 NVIDIA H100 (80GB) GPU. The first number and the second number split by “∣∣\mid∣” denote the costs of R-SFT and HS-DPO, respectively.
| Method | Model Size | Prompt | Response | Refusal | Avg. |
| Closed-Source API | |||||
| OpenAI Moderation | Unknown | 35.28 | 16.68 | 49.10 | 33.68 |
| GPT4o | Unknown | 70.00 | 69.41 | 81.74 | 73.72 |
| GPT4o+CoT | Unknown | 78.00 | 74.45 | 83.41 | 78.62 |
| GPT4 | Unknown | 76.61 | 71.82 | 90.27 | 79.57 |
| GPT4+CoT | Unknown | 76.92 | 72.38 | 90.26 | 79.85 |
| o1-preview | Unknown | 69.44 | 69.22 | 85.22 | 74.63 |
| Claude 3.5 Sonnet | Unknown | 54.34 | 63.05 | 65.23 | 60.87 |
| Gemini 1.5 Pro | Unknown | 72.66 | 77.04 | 90.13 | 79.94 |
| Open-Source Guard Model | |||||
| LLaMA Guard | 7B | 64.89 | 58.27 | 58.11 | 60.42 |
| LLaMA Guard 2 | 8B | 63.62 | 66.99 | 61.91 | 64.18 |
| LLaMA Guard 3 | 8B | 68.47 | 64.97 | 56.32 | 63.25 |
| Aegis Guard Defensive | 7B | 72.99 | 62.79 | 44.21 | 60.00 |
| Aegis Guard Permissive | 7B | 73.83 | 63.55 | 49.86 | 62.41 |
| ShieldGemma | 2B | 09.38 | 27.24 | 52.57 | 29.73 |
| ShieldGemma | 9B | 68.77 | 55.67 | 52.20 | 58.88 |
| WildGuard | 7B | 77.99 | 77.95 | 89.94 | 81.96 |
| QwQ-preview | 32B | 54.13 | 57.73 | 57.81 | 56.55 |
| GuardReasoner | 1B | 77.68 | 79.06 | 88.51 | 81.75 |
| GuardReasoner | 3B | 80.76 | 80.80 | 85.95 | 82.50 |
| GuardReasoner | 8B | 81.09 | 81.22 | 89.96 | 84.09 |
🔼 This table presents a comparison of the performance of 20 different models across three key guardrail tasks: prompt harmfulness detection, response harmfulness detection, and refusal detection. The performance metric used is the F1 score, a measure that balances precision and recall. The table highlights the top two performing models for each task and overall, providing insights into the relative strengths and weaknesses of various approaches to LLM safety.
read the caption
Table 6: Average F1 score of 20 methods on 3 guardrail tasks. The bold and underlined values denote the best and runner-up.
| Method | Used Label | Prompt | Response | Refusal | Avg. |
| GuardReasoner 8B | Original | 81.09 | 81.22 | 89.96 | 84.09 |
| GuardReasoner 8B | Corrected | 89.92 | 86.98 | 96.05 | 90.98 |
| Improvement | - | 10.87% | 7.10% | 6.78% | 8.20% |
🔼 This table presents the performance improvement of the GuardReasoner 8B model after correcting mislabeled data points. It shows the original F1 scores for prompt harmfulness, response harmfulness, and refusal detection tasks, along with the improved scores after correction. The improvement percentage is also displayed for each task and overall.
read the caption
Table 7: Improvement of GuardReasoner 8B after label correction.
| Guardrail Task | Benchmark | # Sample | Include Adversarial |
| Prompt Harmfulness Detection | ToxicChat | 2,853 | |
| OpenAIModeration | 1,680 | ✗ | |
| AegisSafetyTest | 359 | ✗ | |
| SimpleSafetyTests | 100 | ✗ | |
| HarmBenchPrompt | 239 | ✗ | |
| WildGuardTest | 1,756 | ||
| Response Harmfulness Detection | HarmBenchResponse | 602 | |
| SafeRLHF | 2,000 | ✗ | |
| BeaverTails | 3,021 | ✗ | |
| XSTestReponseHarmful | 446 | ✗ | |
| WildGuardTest | 1,768 | ||
| Refusal Detection | XSTestResponseRefusal | 499 | ✗ |
| WildGuardTest | 1,777 |
🔼 This table presents the statistical properties of thirteen benchmark datasets used to evaluate three distinct guardrail tasks: prompt harmfulness detection, response harmfulness detection, and refusal detection. For each benchmark, the table shows the number of samples and whether the dataset includes adversarial attacks, offering a comprehensive overview of the data used in the experiments.
read the caption
Table 8: Statistics of 13 benchmarks on 3 guardrail tasks.
| Seed Data | path | name | split |
| WildGuardTrain | allenai/wildguardmix | wildguardtrain | train |
| AegisTrain | nvidia/Aegis-AI-Content-Safety-Dataset-1.0 | - | train |
| BeaverTailsTrain | PKU-Alignment/BeaverTails | - | 30k_train |
| ToxicChatTrain | lmsys/toxic-chat | toxicchat0124 | train |
| SafeRLHFTrain | PKU-Alignment/PKU-SafeRLHF | alpaca2-7b | train |
🔼 This table lists the URLs for four datasets used as seed data in the training of GuardReasoner. Each row shows the dataset name, its location on Hugging Face, and the split of the data (train). These datasets were used to synthesize reasoning data before training the main GuardReasoner model.
read the caption
Table 9: URL of seed training data on Hugging Face.
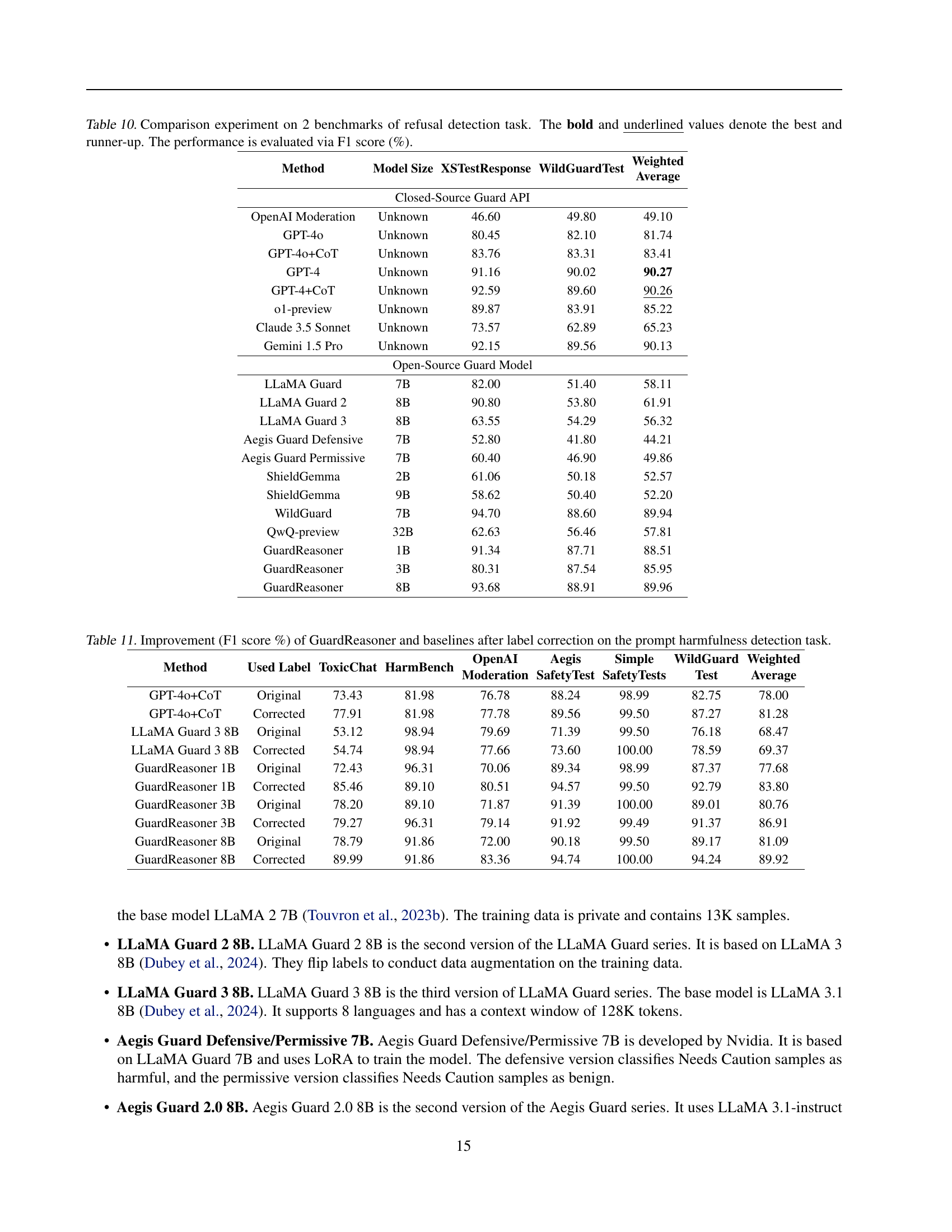
| Method | Model Size | XSTestResponse | WildGuardTest | Weighted Average |
| Closed-Source Guard API | ||||
| OpenAI Moderation | Unknown | 46.60 | 49.80 | 49.10 |
| GPT-4o | Unknown | 80.45 | 82.10 | 81.74 |
| GPT-4o+CoT | Unknown | 83.76 | 83.31 | 83.41 |
| GPT-4 | Unknown | 91.16 | 90.02 | 90.27 |
| GPT-4+CoT | Unknown | 92.59 | 89.60 | 90.26 |
| o1-preview | Unknown | 89.87 | 83.91 | 85.22 |
| Claude 3.5 Sonnet | Unknown | 73.57 | 62.89 | 65.23 |
| Gemini 1.5 Pro | Unknown | 92.15 | 89.56 | 90.13 |
| Open-Source Guard Model | ||||
| LLaMA Guard | 7B | 82.00 | 51.40 | 58.11 |
| LLaMA Guard 2 | 8B | 90.80 | 53.80 | 61.91 |
| LLaMA Guard 3 | 8B | 63.55 | 54.29 | 56.32 |
| Aegis Guard Defensive | 7B | 52.80 | 41.80 | 44.21 |
| Aegis Guard Permissive | 7B | 60.40 | 46.90 | 49.86 |
| ShieldGemma | 2B | 61.06 | 50.18 | 52.57 |
| ShieldGemma | 9B | 58.62 | 50.40 | 52.20 |
| WildGuard | 7B | 94.70 | 88.60 | 89.94 |
| QwQ-preview | 32B | 62.63 | 56.46 | 57.81 |
| GuardReasoner | 1B | 91.34 | 87.71 | 88.51 |
| GuardReasoner | 3B | 80.31 | 87.54 | 85.95 |
| GuardReasoner | 8B | 93.68 | 88.91 | 89.96 |
🔼 This table presents a comparison of various models’ performance on a refusal detection task, using two benchmarks: XSTestResponse and WildGuardTest. The models include both closed-source guard APIs and open-source guard models. The performance metric is F1 score, a common measure of accuracy that considers both precision and recall, reflecting the balance between correctly identifying refusals and not falsely identifying non-refusals as refusals. The best and second-best performing models for each benchmark are highlighted.
read the caption
Table 10: Comparison experiment on 2 benchmarks of refusal detection task. The bold and underlined values denote the best and runner-up. The performance is evaluated via F1 score (%).
| Method | Used Label | ToxicChat | HarmBench | OpenAI Moderation | Aegis SafetyTest | Simple SafetyTests | WildGuard Test | Weighted Average |
| GPT-4o+CoT | Original | 73.43 | 81.98 | 76.78 | 88.24 | 98.99 | 82.75 | 78.00 |
| GPT-4o+CoT | Corrected | 77.91 | 81.98 | 77.78 | 89.56 | 99.50 | 87.27 | 81.28 |
| LLaMA Guard 3 8B | Original | 53.12 | 98.94 | 79.69 | 71.39 | 99.50 | 76.18 | 68.47 |
| LLaMA Guard 3 8B | Corrected | 54.74 | 98.94 | 77.66 | 73.60 | 100.00 | 78.59 | 69.37 |
| GuardReasoner 1B | Original | 72.43 | 96.31 | 70.06 | 89.34 | 98.99 | 87.37 | 77.68 |
| GuardReasoner 1B | Corrected | 85.46 | 89.10 | 80.51 | 94.57 | 99.50 | 92.79 | 83.80 |
| GuardReasoner 3B | Original | 78.20 | 89.10 | 71.87 | 91.39 | 100.00 | 89.01 | 80.76 |
| GuardReasoner 3B | Corrected | 79.27 | 96.31 | 79.14 | 91.92 | 99.49 | 91.37 | 86.91 |
| GuardReasoner 8B | Original | 78.79 | 91.86 | 72.00 | 90.18 | 99.50 | 89.17 | 81.09 |
| GuardReasoner 8B | Corrected | 89.99 | 91.86 | 83.36 | 94.74 | 100.00 | 94.24 | 89.92 |
🔼 This table presents the improvement in F1 scores achieved by GuardReasoner and several baseline models after correcting mislabeled data in the prompt harmfulness detection task. It shows the performance gain (in percentage points) after human annotators reviewed and corrected labels, illustrating the effectiveness of the GuardReasoner model in handling ambiguous or difficult cases where initial labels were inaccurate.
read the caption
Table 11: Improvement (F1 score %) of GuardReasoner and baselines after label correction on the prompt harmfulness detection task.
| Method | Used Label | HarmBench | SafeRLHF | BeaverTails | XSTestReponse | WildGuard Test | Weighted Average |
| Gemini 1.5 Pro | Original | 84.39 | 62.01 | 83.91 | 90.24 | 76.47 | 77.04 |
| Gemini 1.5 Pro | Corrected | 87.69 | 69.44 | 86.52 | 91.57 | 77.51 | 80.51 |
| LLaMA Guard 3 8B | Original | 85.07 | 44.36 | 67.84 | 87.67 | 70.80 | 64.97 |
| LLaMA Guard 3 8B | Corrected | 87.71 | 47.46 | 69.50 | 87.84 | 72.00 | 66.88 |
| GuardReasoner 1B | Original | 84.75 | 68.39 | 85.84 | 90.12 | 74.81 | 79.06 |
| GuardReasoner 1B | Corrected | 88.67 | 76.49 | 88.76 | 90.24 | 79.63 | 83.65 |
| GuardReasoner 3B | Original | 85.66 | 69.02 | 86.72 | 91.36 | 79.70 | 80.80 |
| GuardReasoner 3B | Corrected | 89.64 | 77.32 | 89.66 | 92.68 | 84.17 | 85.44 |
| GuardReasoner 8B | Original | 85.47 | 70.04 | 87.60 | 94.34 | 78.20 | 81.22 |
| GuardReasoner 8B | Corrected | 91.16 | 80.16 | 91.01 | 95.65 | 84.21 | 86.98 |
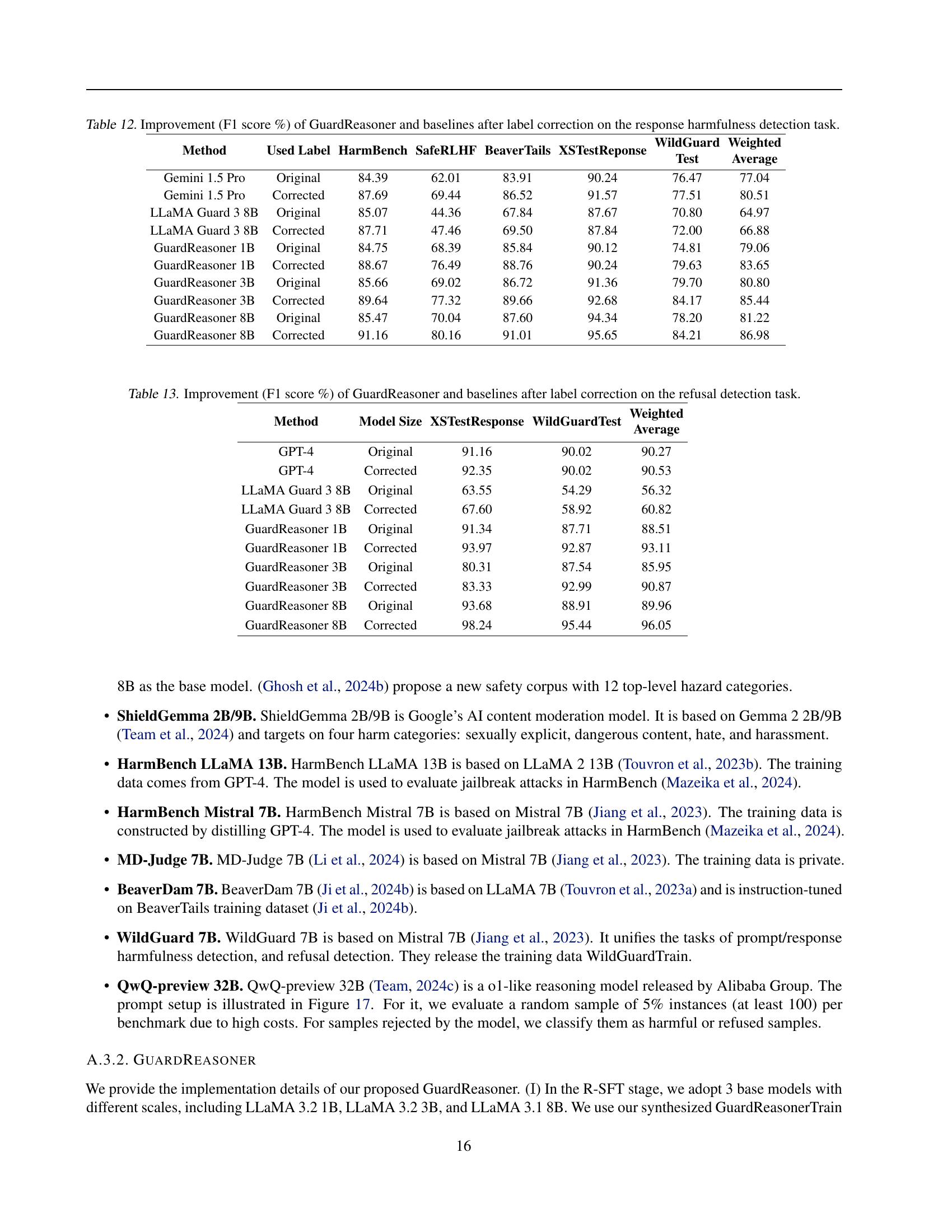
🔼 This table presents the improvement in F1 score achieved by GuardReasoner and several baseline models after correcting mislabeled data in the response harmfulness detection task. It shows the performance gains (in percentage points) after correcting the labels of the HarmBench, SafeRLHF, BeaverTails, XSTestResponse, and WildGuard datasets. The improvements reflect the effectiveness of the models in correctly classifying harmful and unharmful responses.
read the caption
Table 12: Improvement (F1 score %) of GuardReasoner and baselines after label correction on the response harmfulness detection task.
| Method | Model Size | XSTestResponse | WildGuardTest | Weighted Average |
| GPT-4 | Original | 91.16 | 90.02 | 90.27 |
| GPT-4 | Corrected | 92.35 | 90.02 | 90.53 |
| LLaMA Guard 3 8B | Original | 63.55 | 54.29 | 56.32 |
| LLaMA Guard 3 8B | Corrected | 67.60 | 58.92 | 60.82 |
| GuardReasoner 1B | Original | 91.34 | 87.71 | 88.51 |
| GuardReasoner 1B | Corrected | 93.97 | 92.87 | 93.11 |
| GuardReasoner 3B | Original | 80.31 | 87.54 | 85.95 |
| GuardReasoner 3B | Corrected | 83.33 | 92.99 | 90.87 |
| GuardReasoner 8B | Original | 93.68 | 88.91 | 89.96 |
| GuardReasoner 8B | Corrected | 98.24 | 95.44 | 96.05 |
🔼 This table presents the performance improvement in F1 score achieved by GuardReasoner and several baseline models after correcting mislabeled data in the refusal detection task. It shows the percentage increase in F1 score for each model after the label correction, highlighting the impact of accurate labeling on model performance. The table helps illustrate the robustness and accuracy of GuardReasoner, especially when compared to other models after addressing data inaccuracies.
read the caption
Table 13: Improvement (F1 score %) of GuardReasoner and baselines after label correction on the refusal detection task.
Full paper#