TL;DR#
Large language models (LLMs) like OpenAI’s o1 excel at complex reasoning but often exhibit ‘underthinking’— prematurely abandoning potentially correct reasoning paths, leading to inaccurate answers, particularly on complex mathematical problems. This is further exacerbated by frequent switching between reasoning thoughts without sufficient exploration, especially when models fail to reach a correct solution.
To address this, the researchers introduce a novel underthinking metric that measures token efficiency in incorrect responses; a low score suggests that a larger proportion of tokens don’t contribute to finding the correct answer. They then propose a decoding strategy, thought switching penalty (TIP), to mitigate underthinking by encouraging deeper exploration of reasoning paths. Experimental results demonstrate that TIP improves accuracy across challenging datasets without model fine-tuning, showcasing its effectiveness in enhancing LLM reasoning capabilities.
Key Takeaways#
Why does it matter?#
This paper is important because it identifies and addresses a critical limitation of large language models (LLMs), namely, underthinking. By quantifying underthinking and proposing a novel decoding strategy, the research opens up new avenues for improving LLM reasoning capabilities and enhancing their performance on complex tasks. This is highly relevant given the increasing use of LLMs across various domains. The findings can inform the design of more effective and efficient LLMs, leading to significant advancements in artificial intelligence.
Visual Insights#
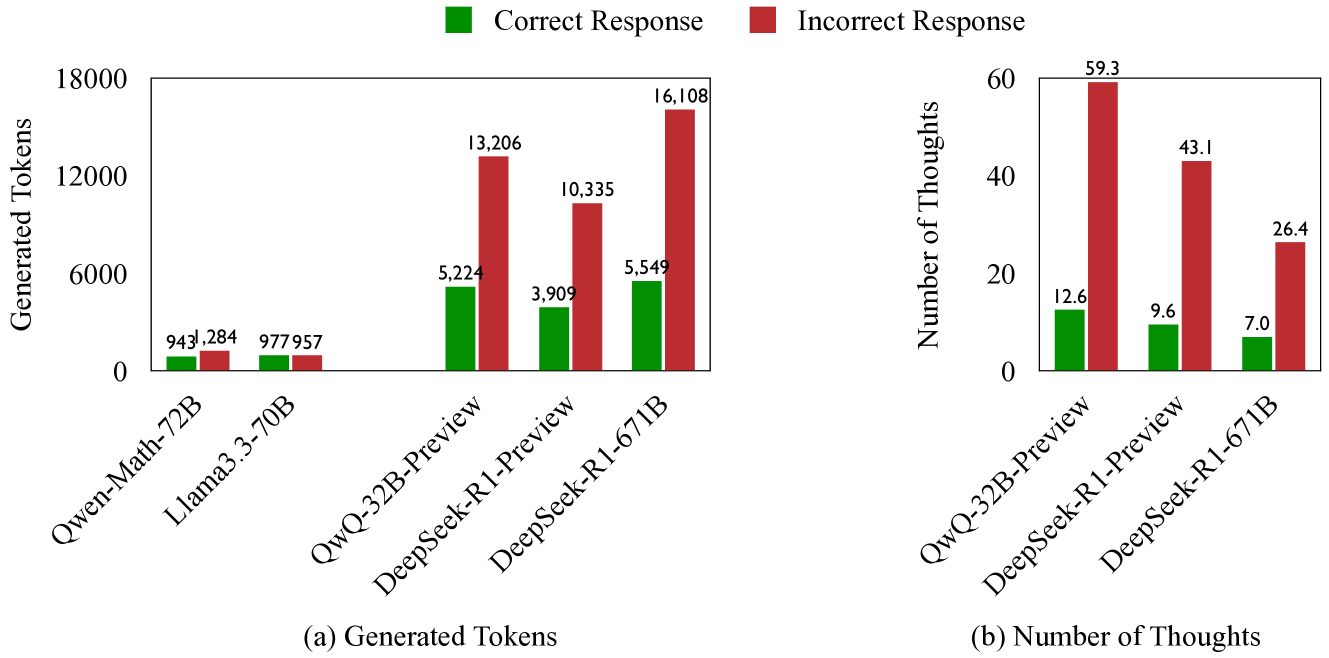
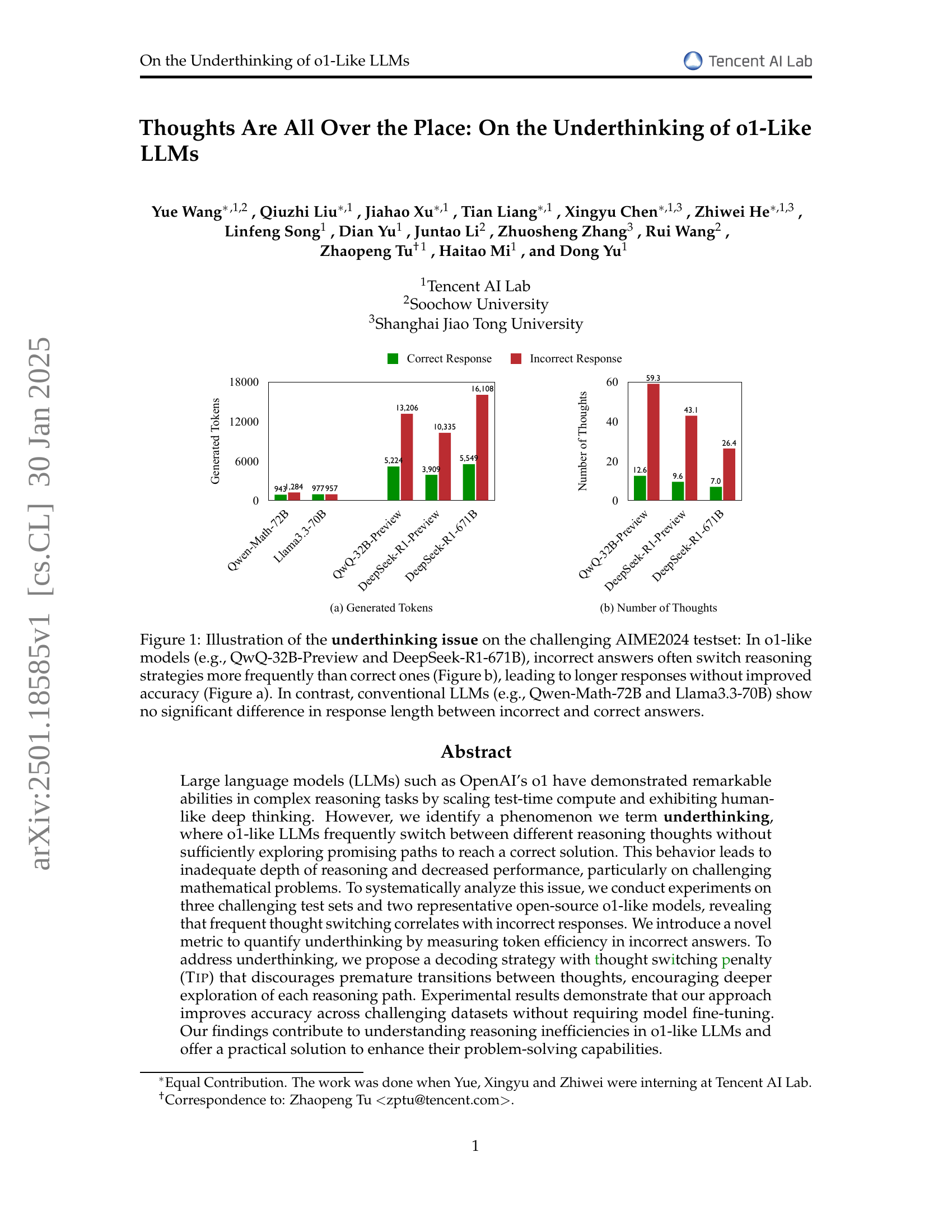
🔼 Figure 1 illustrates the underthinking phenomenon observed in o1-like large language models (LLMs) when solving challenging mathematical problems from the AIME2024 dataset. The figure uses two subfigures to compare the behavior of o1-like models (QwQ-32B-Preview and DeepSeek-R1-671B) with conventional LLMs (Qwen-Math-72B and Llama3.3-70B). Subfigure (a) shows that o1-like models generate significantly more tokens (words) for incorrect answers compared to correct answers, indicating inefficiency. Subfigure (b) reveals that incorrect answers from o1-like models exhibit much more frequent switching between different reasoning strategies than correct answers. This frequent switching, despite generating longer responses, doesn’t improve accuracy. In contrast, conventional LLMs show no significant difference in response length between correct and incorrect answers.
read the caption
Figure 1: Illustration of the underthinking issue on the challenging AIME2024 testset: In o1-like models (e.g., QwQ-32B-Preview and DeepSeek-R1-671B), incorrect answers often switch reasoning strategies more frequently than correct ones (Figure b), leading to longer responses without improved accuracy (Figure a). In contrast, conventional LLMs (e.g., Qwen-Math-72B and Llama3.3-70B) show no significant difference in response length between incorrect and correct answers.
| Models | Accuracy | UT Score |
| MATH500-Hard (Level 5) | ||
| QwQ-32B-Preview | 84.3 | 58.2 |
| DeepSeek-R1-Preview | 83.6 | 61.5 |
| DeepSeek-R1-671B | 92.5 | 65.4 |
| GPQA Diamond | ||
| QwQ-32B-Preview | 59.6 | 48.3 |
| DeepSeek-R1-671B | 73.2 | 58.8 |
| AIME24 | ||
| QwQ-32B-Preview | 46.7 | 65.0 |
| DeepSeek-R1-Preview | 46.7 | 75.7 |
| DeepSeek-R1-671B | 73.3 | 37.0 |
🔼 This table presents the underthinking scores and accuracies of three different language models (QwQ-32B-Preview, DeepSeek-R1-Preview, and DeepSeek-R1-671B) across three challenging datasets: MATH500-Hard (level 5), GPQA Diamond, and AIME24. The underthinking score (UT Score) measures the inefficiency of the model’s token usage in generating incorrect responses, while accuracy represents the percentage of correct answers generated. The table aims to demonstrate the variability of underthinking across different models and datasets, highlighting the challenge of creating consistently effective reasoning models.
read the caption
Table 1: Underthinking scores on challenging testsets.
In-depth insights#
Underthinking in LLMs#
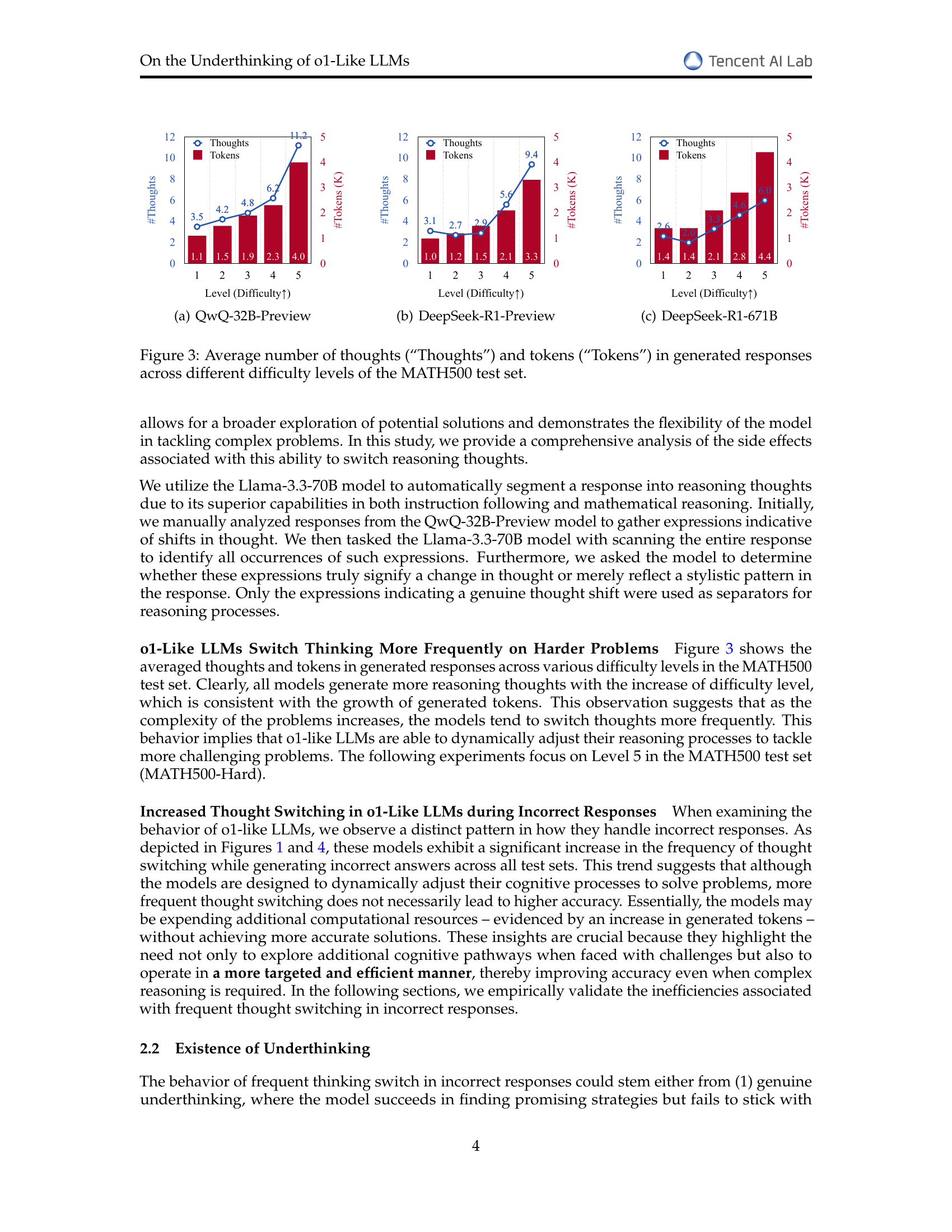
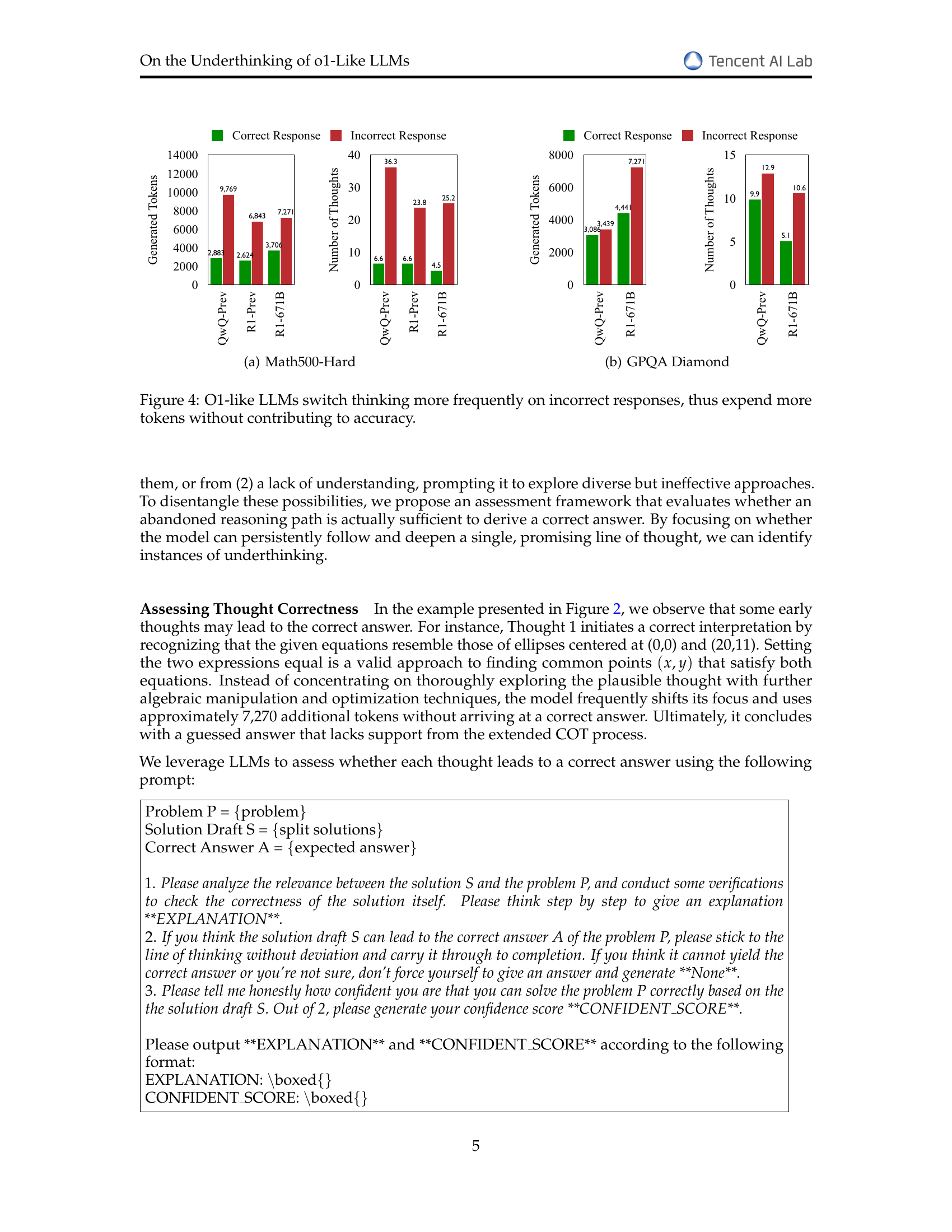
The concept of ‘Underthinking in LLMs’ highlights a crucial limitation in large language models: premature abandonment of promising reasoning paths. Unlike human-like deep thinking, where complex problems are tackled by exploring various avenues, underthinking manifests as a frequent switching between thoughts without sufficient exploration, leading to inadequate reasoning depth and suboptimal results, especially on challenging mathematical tasks. This phenomenon is particularly concerning because it suggests that even when models initiate a correct reasoning strategy, they often fail to persist, ultimately hindering their ability to arrive at accurate solutions. The implications are significant; simply scaling computational resources or model size may not effectively resolve underthinking. Instead, future research must focus on novel decoding strategies or architectural changes that encourage deeper exploration of individual reasoning paths and discourage premature transitions between alternative approaches.
TIP Decoding Strategy#
The TIP (Thought Switching Penalty) decoding strategy is a novel approach to mitigate the problem of underthinking in large language models (LLMs). Underthinking, as defined in the paper, is the tendency of LLMs to prematurely abandon promising reasoning paths, leading to inaccurate conclusions. TIP directly addresses this by introducing a penalty that discourages frequent transitions between different reasoning thoughts. This penalty is applied during the generation process by modifying the logit scores of tokens associated with thought switching. The core idea is to incentivize the model to delve deeper into each thought before considering alternatives, thus promoting more thorough and accurate reasoning. The effectiveness of TIP is demonstrated through experiments, showing improved accuracy on challenging mathematical problem-solving tasks without the need for model fine-tuning. A key advantage is its lightweight nature, meaning it can easily be incorporated into existing LLMs without requiring significant changes to the model architecture. This method represents a significant step towards developing more efficient and accurate reasoning capabilities in LLMs, focusing on resolving underthinking rather than solely on increasing model scale or compute.
UT Score Metric#
The paper introduces a novel metric, the UT score, to quantify the phenomenon of ‘underthinking’ in large language models (LLMs). Underthinking, as defined in the paper, refers to the tendency of LLMs to prematurely abandon promising reasoning paths, leading to less efficient problem-solving. The UT score directly addresses this by measuring token efficiency within incorrect responses. It calculates the proportion of tokens in an incorrect response that contribute to a correct thought before the model switches to another reasoning path. A lower UT score indicates higher token efficiency, suggesting the model effectively used its resources, even if the final answer was wrong. Conversely, a high UT score reveals significant inefficiency, indicating wasted computational effort due to excessive, unproductive thought switching. This metric provides a valuable complement to traditional accuracy metrics, offering a more comprehensive assessment of LLM reasoning capabilities, particularly in identifying and analyzing cases where models abandon correct solution paths prematurely.
Reasoning Efficiency#
Reasoning efficiency in large language models (LLMs) is a crucial aspect determining their overall performance, especially on complex tasks. The ability of LLMs to reach correct solutions efficiently depends on various factors, including the model’s architecture, training data, and decoding strategies. Inefficient reasoning manifests in two primary ways: underthinking and overthinking. Underthinking occurs when the model prematurely abandons promising reasoning paths, leading to inaccurate conclusions. Overthinking, on the other hand, involves excessive exploration of irrelevant or redundant paths, wasting computational resources without improving accuracy. Effective reasoning strategies are needed to balance exploration and exploitation, ensuring that promising paths are pursued thoroughly while avoiding excessive detours. Metrics that quantify reasoning efficiency are essential for evaluating and improving LLMs, providing insights into the model’s ability to effectively allocate computational resources and achieve accurate results. Further research should focus on developing techniques to enhance reasoning efficiency in LLMs, potentially through improved training methods, more effective decoding algorithms, or architectures designed to explicitly manage the tradeoff between exploration and exploitation.
Future Work#
Future research directions stemming from this paper on underthinking in large language models (LLMs) could fruitfully explore adaptive mechanisms that allow LLMs to self-regulate the frequency of thought switching, dynamically adjusting their approach based on problem complexity and progress. Investigating how different penalty schemes beyond the thought switching penalty (TIP) can improve reasoning efficiency would also be valuable. For example, incorporating penalties related to token usage or exploring reward-based methods to guide deeper reasoning are promising avenues. Furthermore, extending the TIP approach to other LLMs and a broader range of tasks is crucial for validating its generalizability and effectiveness. A deeper investigation into the interplay between underthinking and other reasoning inefficiencies, such as overthinking, would provide a holistic understanding of LLMs’ limitations. Finally, a focus on developing more robust and nuanced evaluation metrics that better capture the subtleties of reasoning is essential to accurately assess progress in addressing underthinking and related challenges. Developing benchmark datasets with varied levels of complexity is important to evaluate the effectiveness of different mitigation techniques.
More visual insights#
More on figures

🔼 Figure 2 presents a detailed illustration of the underthinking phenomenon observed in the QwQ-32B-Preview large language model (LLM). It showcases a solution attempt to a mathematical problem that involves 25 distinct reasoning thoughts. The model switches between these thoughts frequently, indicating insufficient exploration of individual pathways before jumping to another. This behavior contrasts with the ideal approach of thoroughly investigating each thought to ensure its potential for leading to a solution. An example of overthinking (excessive exploration of less promising paths) is included for comparison, emphasizing the difference between underthinking (premature abandonment of possibly correct reasoning paths) and overthinking (too much exploration of incorrect paths). This example visually highlights the core concept of underthinking that is explored in the paper.
read the caption
Figure 2: An example of underthinking issue for QwQ-32B-Preview model’s output response that consists of 25 reasoning thoughts within a single solution. We also list an example of overthinking issue outputs for comparison.

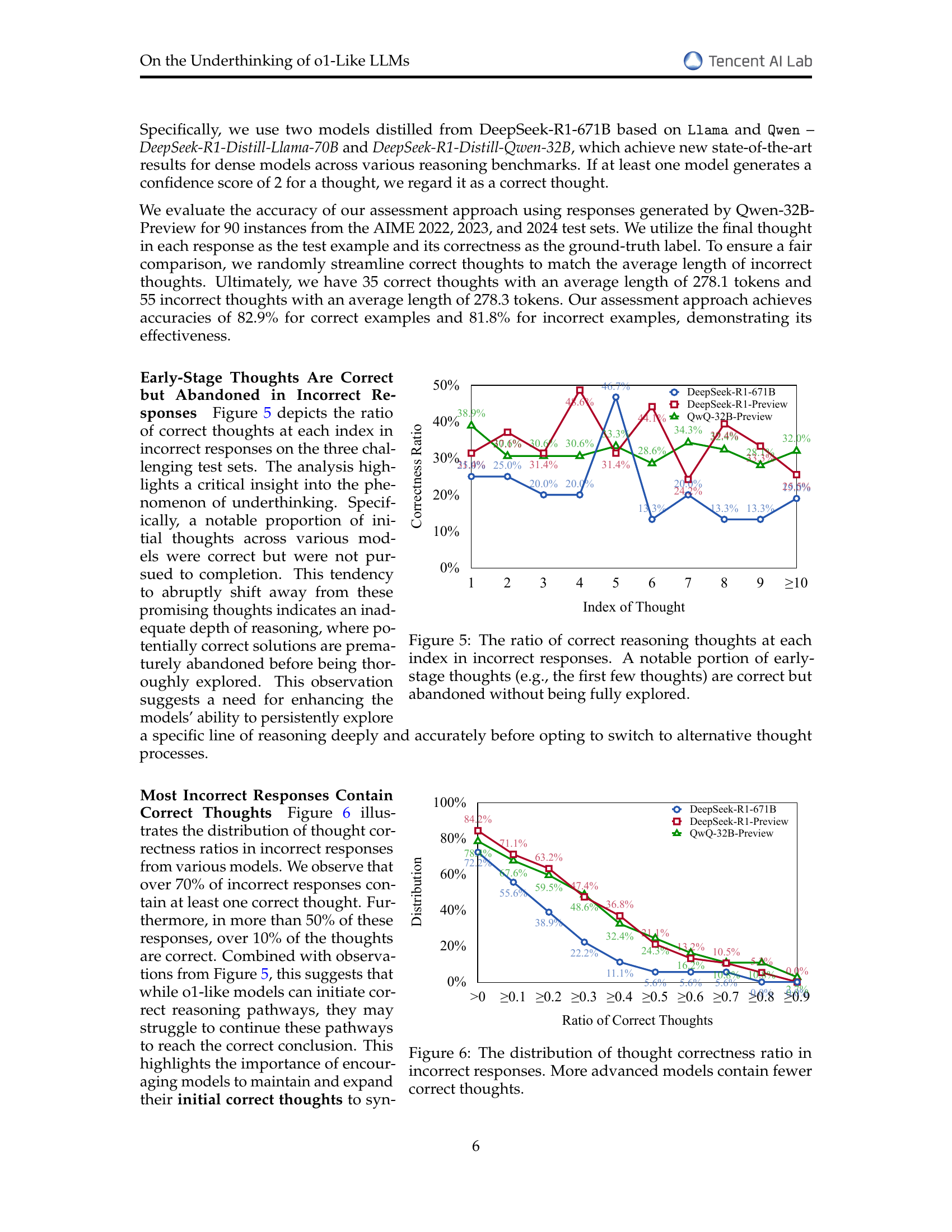
🔼 This figure displays the percentage of correct reasoning thoughts at different positions within incorrect responses generated by three different large language models (QwQ-32B-Preview, DeepSeek-R1-Preview, and DeepSeek-R1-671B) across three challenging datasets. The x-axis represents the position (index) of a thought within the response, starting from the first thought generated. The y-axis shows the percentage of responses where the thought at that position was deemed correct. The key finding is that a significant proportion of early thoughts (especially the first few) are often correct but are subsequently abandoned and not fully explored by the model. This suggests that the models tend to prematurely abandon potentially fruitful lines of reasoning, leading to inaccurate results.
read the caption
Figure 5: The ratio of correct reasoning thoughts at each index in incorrect responses. A notable portion of early-stage thoughts (e.g., the first few thoughts) are correct but abandoned without being fully explored.

🔼 This figure shows the distribution of the ratio of correct thoughts within incorrect responses generated by different language models. The x-axis represents the ratio of correct thoughts within an incorrect response (ranging from 0 to 1, indicating the proportion of thoughts that are actually correct). The y-axis represents the percentage of incorrect responses that fall into each ratio bin. The figure reveals that while most incorrect responses from all models contain at least some correct thoughts, more advanced models tend to have a lower proportion of correct thoughts in their incorrect responses. This suggests that, while they can initiate correct reasoning pathways, more advanced models struggle more to maintain these pathways and arrive at a correct answer, possibly due to premature abandonment of promising lines of reasoning.
read the caption
Figure 6: The distribution of thought correctness ratio in incorrect responses. More advanced models contain fewer correct thoughts.
More on tables
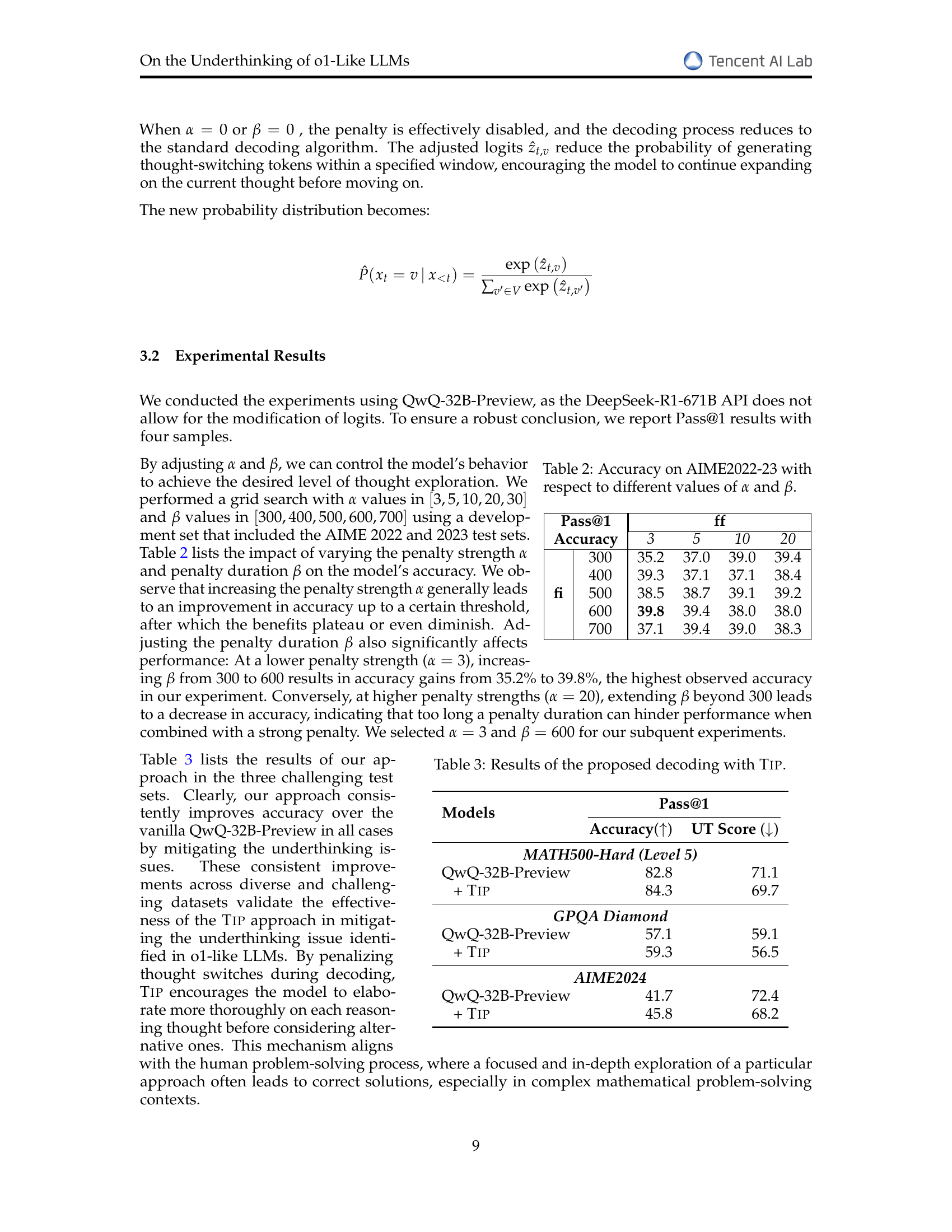
| Pass@1 | |||||
|---|---|---|---|---|---|
| Accuracy | 3 | 5 | 10 | 20 | |
| 300 | 35.2 | 37.0 | 39.0 | 39.4 | |
| 400 | 39.3 | 37.1 | 37.1 | 38.4 | |
| 500 | 38.5 | 38.7 | 39.1 | 39.2 | |
| 600 | 39.8 | 39.4 | 38.0 | 38.0 | |
| 700 | 37.1 | 39.4 | 39.0 | 38.3 | |
🔼 This table presents the accuracy results of the QwQ-32B-Preview model on the AIME2022 and AIME2023 datasets, showing the impact of varying the thought switching penalty’s strength (α) and duration (β). Different combinations of α and β values were tested, and the corresponding Pass@1 accuracy is reported for each combination. This allows for an analysis of how the penalty parameters influence the model’s performance, helping to determine optimal settings for mitigating underthinking.
read the caption
Table 2: Accuracy on AIME2022-23 with respect to different values of α𝛼\alphaitalic_α and β𝛽\betaitalic_β.
| Models | Pass@1 | |
|---|---|---|
| Accuracy() | UT Score () | |
| MATH500-Hard (Level 5) | ||
| QwQ-32B-Preview | 82.8 | 71.1 |
| + Tip | 84.3 | 69.7 |
| GPQA Diamond | ||
| QwQ-32B-Preview | 57.1 | 59.1 |
| + Tip | 59.3 | 56.5 |
| AIME2024 | ||
| QwQ-32B-Preview | 41.7 | 72.4 |
| + Tip | 45.8 | 68.2 |
🔼 This table presents the results of the proposed thought switching penalty (TIP) decoding strategy on three challenging datasets: MATH500-Hard, GPQA Diamond, and AIME2024. It compares the accuracy and underthinking (UT) score of the QwQ-32B-Preview model with and without the TIP method applied. The results show the impact of TIP on improving model accuracy while simultaneously reducing the underthinking score, indicating enhanced reasoning efficiency. The table provides a quantitative comparison of the model’s performance across different datasets with and without the proposed TIP improvement.
read the caption
Table 3: Results of the proposed decoding with Tip.
Full paper#