TL;DR#
Multilingual language models struggle with extremely low-resource languages due to insufficient training data. Existing large language models also support few languages. This paper tackles this challenge by introducing a novel framework.
The proposed framework uses a weight-sharing mechanism between the encoder and decoder to efficiently adapt multilingual encoders to text generation in low-resource languages. The framework allows the model to reuse the encoder’s learned semantic space for faster and better learning. Experiments demonstrate that the model outperforms existing methods on various tasks for four Chinese minority languages.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of low-resource language modeling, a significant challenge in NLP. Its novel weight-sharing method offers a highly efficient solution, paving the way for improved NLP applications in under-resourced languages and opening new avenues for research in cross-lingual transfer learning. The results are significant and demonstrate the potential impact on numerous downstream tasks.
Visual Insights#

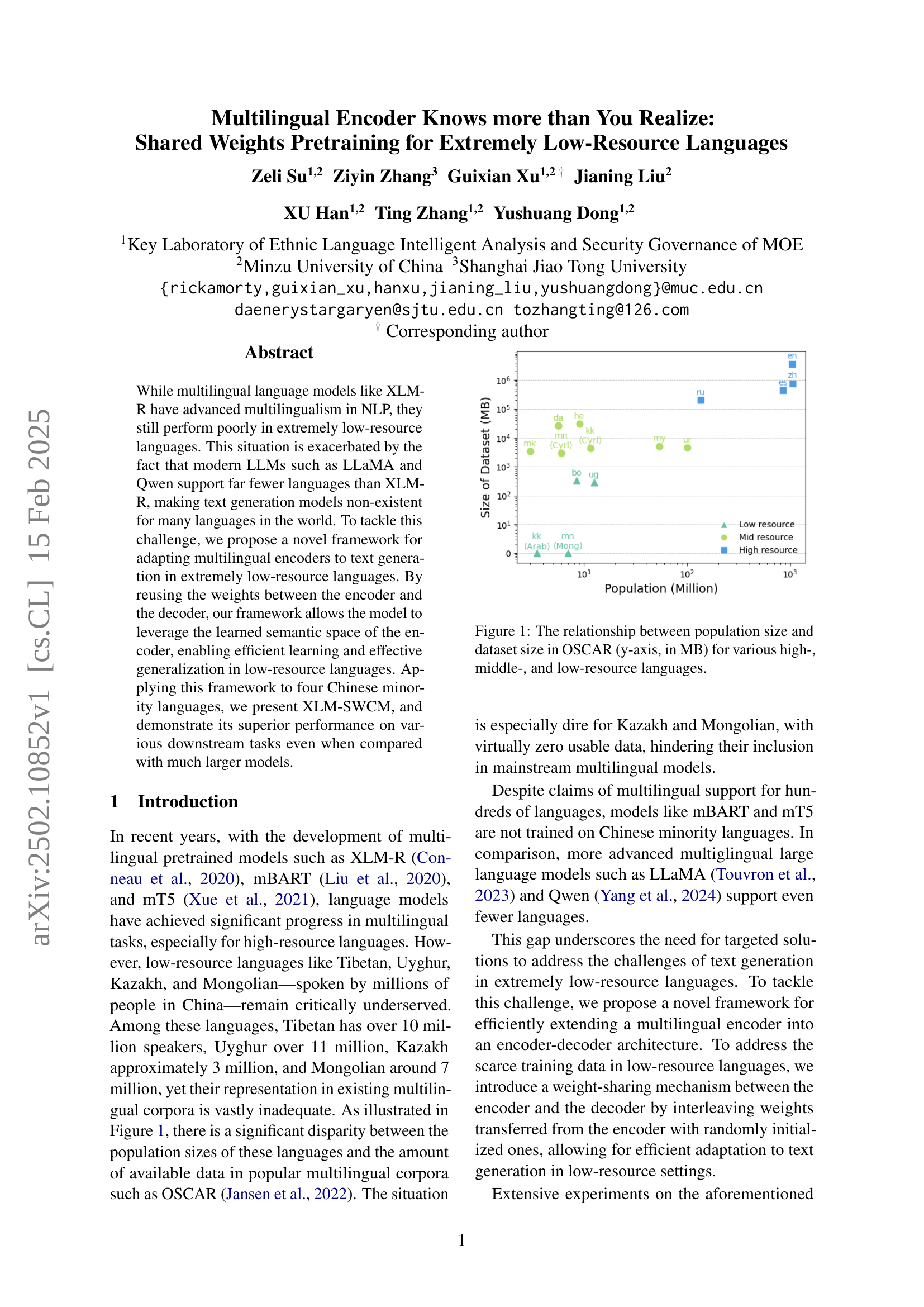
🔼 This figure visually represents the disparity in the amount of available data for various languages within the OSCAR corpus. The x-axis displays the population size of speakers for each language (in millions), while the y-axis shows the corresponding dataset size in megabytes (MB). Languages are categorized into high-resource, mid-resource, and low-resource groups, illustrating how the amount of available data often does not reflect the number of speakers. For instance, several languages with millions of speakers have limited or no data available in OSCAR, highlighting the data scarcity issue for low-resource languages.
read the caption
Figure 1: The relationship between population size and dataset size in OSCAR (y-axis, in MB) for various high-, middle-, and low-resource languages.
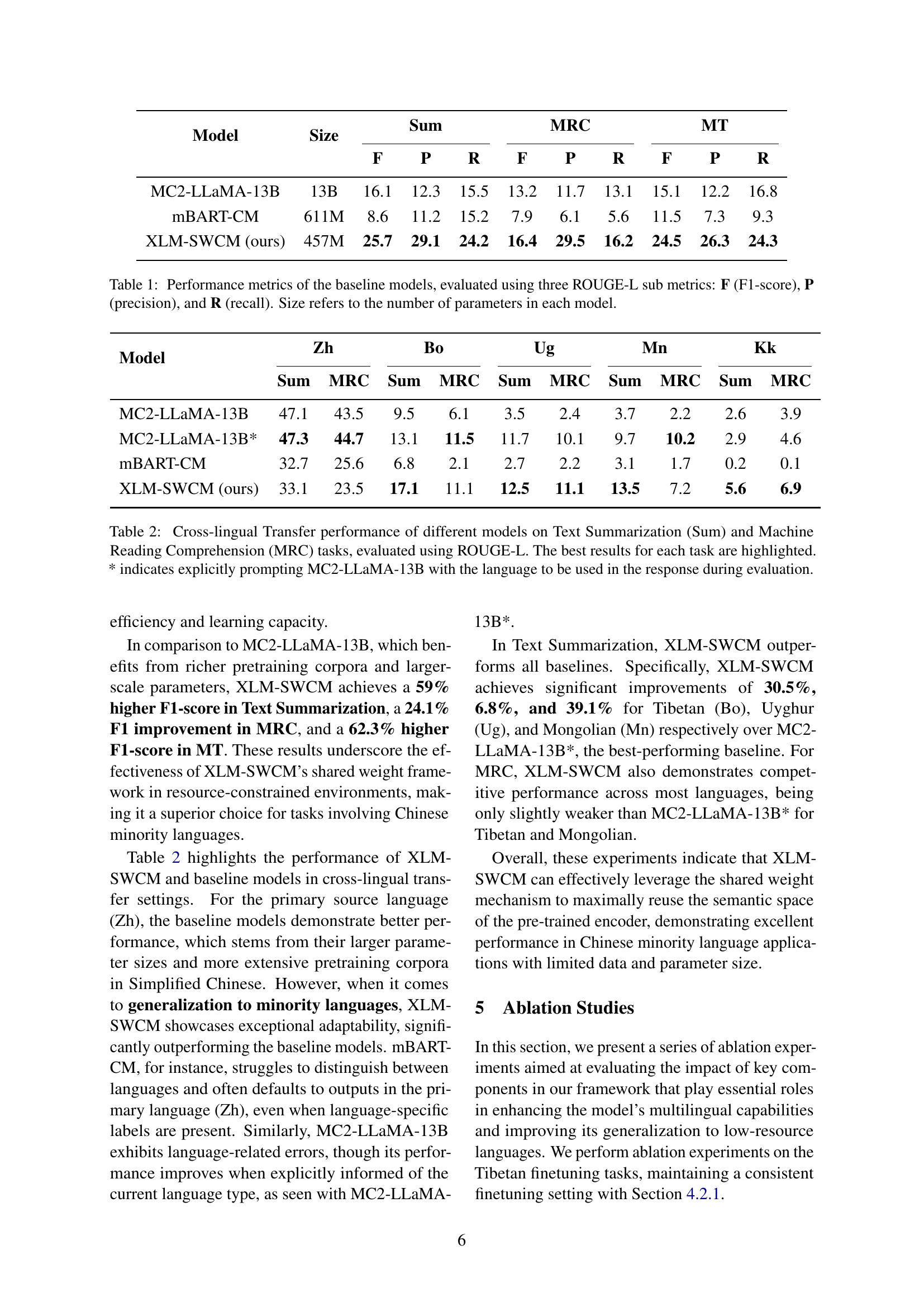
| Model | Size | Sum | MRC | MT | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F | P | R | F | P | R | F | P | R | ||
| MC2-LLaMA-13B | 13B | 16.1 | 12.3 | 15.5 | 13.2 | 11.7 | 13.1 | 15.1 | 12.2 | 16.8 |
| mBART-CM | 611M | 8.6 | 11.2 | 15.2 | 7.9 | 6.1 | 5.6 | 11.5 | 7.3 | 9.3 |
| XLM-SWCM (ours) | 457M | 25.7 | 29.1 | 24.2 | 16.4 | 29.5 | 16.2 | 24.5 | 26.3 | 24.3 |
🔼 This table presents a comparison of the performance of three different language models on three downstream tasks: text summarization, machine reading comprehension, and machine translation. The models compared are MC2-LLaMA-13B, mBART-CM, and the proposed XLM-SWCM. Performance is measured using the ROUGE-L metric, specifically its F1-score (F), precision (P), and recall (R). The table also indicates the number of parameters (size) for each model, allowing for an assessment of the trade-off between model size and performance.
read the caption
Table 1: Performance metrics of the baseline models, evaluated using three ROUGE-L sub metrics: F (F1-score), P (precision), and R (recall). Size refers to the number of parameters in each model.
In-depth insights#
Low-Resource NLP#
Low-resource NLP tackles the critical challenge of applying natural language processing techniques to languages with limited data. Data scarcity significantly hinders the performance of standard NLP models, which are typically trained on massive datasets. This necessitates innovative approaches like transfer learning, where knowledge gained from high-resource languages is transferred to low-resource ones. Cross-lingual techniques are crucial, leveraging similarities between languages to improve model generalization. Multilingual models pre-trained on diverse language corpora offer promising solutions, but adaptation and fine-tuning are essential to achieve optimal performance in specific low-resource contexts. Data augmentation strategies aim to artificially increase the size of low-resource datasets, enhancing model training. The field also explores novel architectures and learning paradigms specifically tailored to handle limited data effectively. Research in low-resource NLP is crucial for bridging the digital divide and ensuring equitable access to NLP technologies globally.
Shared Weight#
The concept of “Shared Weight” in multilingual model training offers a compelling approach to address low-resource language challenges. By tying the encoder and decoder weights, the model leverages the rich semantic understanding learned during the encoder’s pre-training phase, significantly accelerating the decoder’s adaptation to text generation tasks. This weight-sharing mechanism is particularly effective when data scarcity hinders independent training of decoder parameters. The strategic interleaving of pre-trained weights with randomly initialized ones balances knowledge transfer and the acquisition of generation-specific skills. This approach allows for more efficient learning and better generalization in low-resource scenarios, as evidenced by the superior performance shown in the paper. The success of this approach underscores the value of transfer learning techniques in mitigating data imbalances across languages. It highlights a cost-effective approach towards advancing multilingual NLP capabilities, particularly crucial for lesser-resourced languages where independent training is computationally expensive and data-intensive. The study demonstrates that this seemingly simple technique can yield impressive gains in cross-lingual transfer settings. Future research may explore optimizing weight-sharing strategies and further investigating the influence of architectural choices on model performance.
XLM-SWCM Model#
The XLM-SWCM model represents a novel approach to multilingual text generation, particularly focusing on extremely low-resource languages. Its core innovation lies in a weight-sharing mechanism between the encoder and decoder, leveraging a pre-trained multilingual encoder (like XLM-R) to efficiently initialize the decoder weights. This significantly reduces the need for extensive training data, crucial for low-resource scenarios. The model demonstrates superior performance on various downstream tasks (summarization, machine reading comprehension, machine translation) compared to larger models like MC2-LLaMA and standard baselines such as mBART, showcasing its effectiveness. This weight-sharing framework promotes faster convergence and improved generalization, highlighting its potential for addressing the challenges of text generation in under-resourced languages. However, the model’s performance might be sensitive to the insertion frequency of randomly initialized layers within the decoder, indicating a need for careful architecture design and potentially task-specific optimization.
Cross-lingual Transfer#
The concept of cross-lingual transfer in multilingual models is crucial for low-resource languages. Successful cross-lingual transfer allows a model trained on a high-resource language to generalize effectively to low-resource languages, even with limited training data in the target languages. This is particularly important for minority languages where large annotated datasets are scarce. The effectiveness of cross-lingual transfer hinges on the model’s ability to learn shared linguistic features and representations across languages. Weight-sharing mechanisms, as explored in the research paper, are a promising approach to facilitate efficient cross-lingual transfer by leveraging the knowledge learned in high-resource languages. Evaluation metrics should focus not only on overall performance but also on how well the model generalizes to various low-resource languages and the robustness to variations in data size. The study of cross-lingual transfer also helps to understand the inherent linguistic relationships between languages, revealing whether certain language families or typological features are easier to transfer than others. Further research should explore the effect of different model architectures, training strategies, and data augmentation techniques on cross-lingual transfer performance for even more effective multilingual models.
Future Work#
Future research should prioritize expanding the dataset to encompass a wider range of languages, particularly those with extremely low-resource availability. Addressing the data imbalance across different languages is crucial, requiring innovative data augmentation and collection strategies. Investigating alternative weight-sharing mechanisms and exploring different architectures beyond the transformer model could improve efficiency and performance. Further investigation into the optimal balance between normal and custom decoder layers, and the interaction with training data size is also needed to generalize the model’s applicability. Finally, thorough evaluation on a broader set of downstream tasks, encompassing diverse linguistic complexities, is essential to fully assess the XLM-SWCM framework’s robustness and practical implications.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of the proposed Shared Weights Framework for adapting multilingual encoders to text generation tasks, particularly focusing on low-resource languages. It shows how a pre-trained multilingual encoder (like XLM-R) is combined with a decoder. A key feature is the weight sharing between encoder and decoder layers, allowing the decoder to leverage the knowledge learned by the encoder during its initial training. This is designed to improve efficiency and effectiveness in low-resource language settings. The framework is shown to process a large multilingual corpus and a smaller Chinese minority language corpus before producing results on downstream tasks.
read the caption
Figure 2: An overview of the shared weight framework for efficiently adapting multilingual encoders to text generation in low-resource languages.

🔼 This figure illustrates how weights are initialized in the CustomDecoderLayer of the XLM-SWCM model. The CustomDecoderLayer is a modified transformer decoder layer that incorporates pre-trained weights from the encoder to improve efficiency. The diagram shows the flow of weight initialization from the encoder’s self-attention and feed-forward network blocks to the corresponding components in the decoder. Colored arrows visually represent this weight transfer. The weights are strategically transferred to leverage the encoder’s learned knowledge effectively, while the decoder retains its capacity to learn generation-specific features via its own randomly initialized layers.
read the caption
Figure 3: The weight initialization schemes for the CustomDecoderLayer. The colored arrows indicate the initialization of weights between the different components.

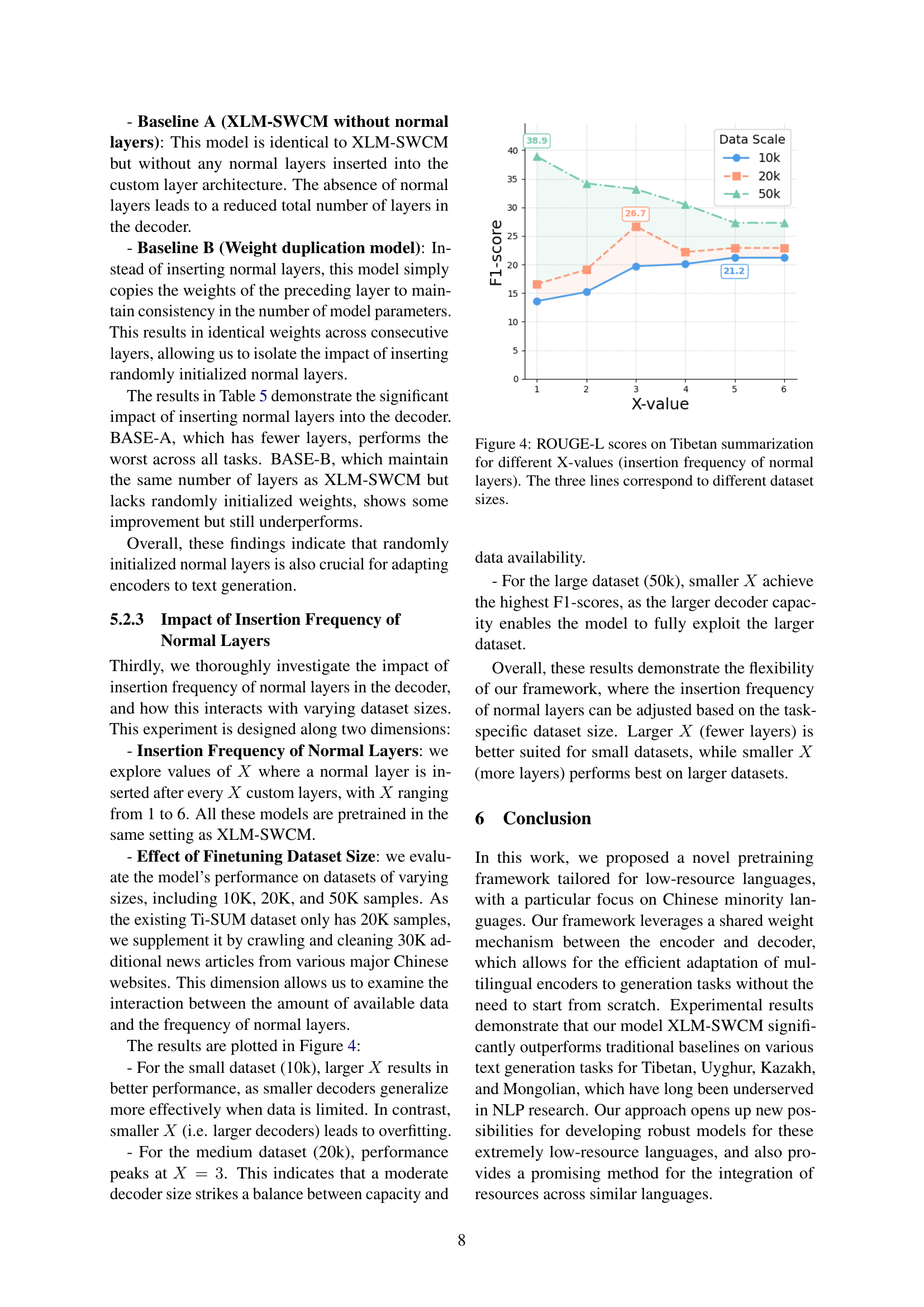
🔼 This figure shows the impact of varying the insertion frequency (X-value) of normal decoder layers on the ROUGE-L scores for Tibetan text summarization. The results are shown for three different training dataset sizes (10K, 20K, and 50K samples), illustrating how the optimal X-value changes with the amount of available training data. In essence, the figure explores the trade-off between model capacity (larger X values mean smaller decoders) and the risk of overfitting, demonstrating that the best X-value depends on data availability.
read the caption
Figure 4: ROUGE-L scores on Tibetan summarization for different X-values (insertion frequency of normal layers). The three lines correspond to different dataset sizes.
More on tables
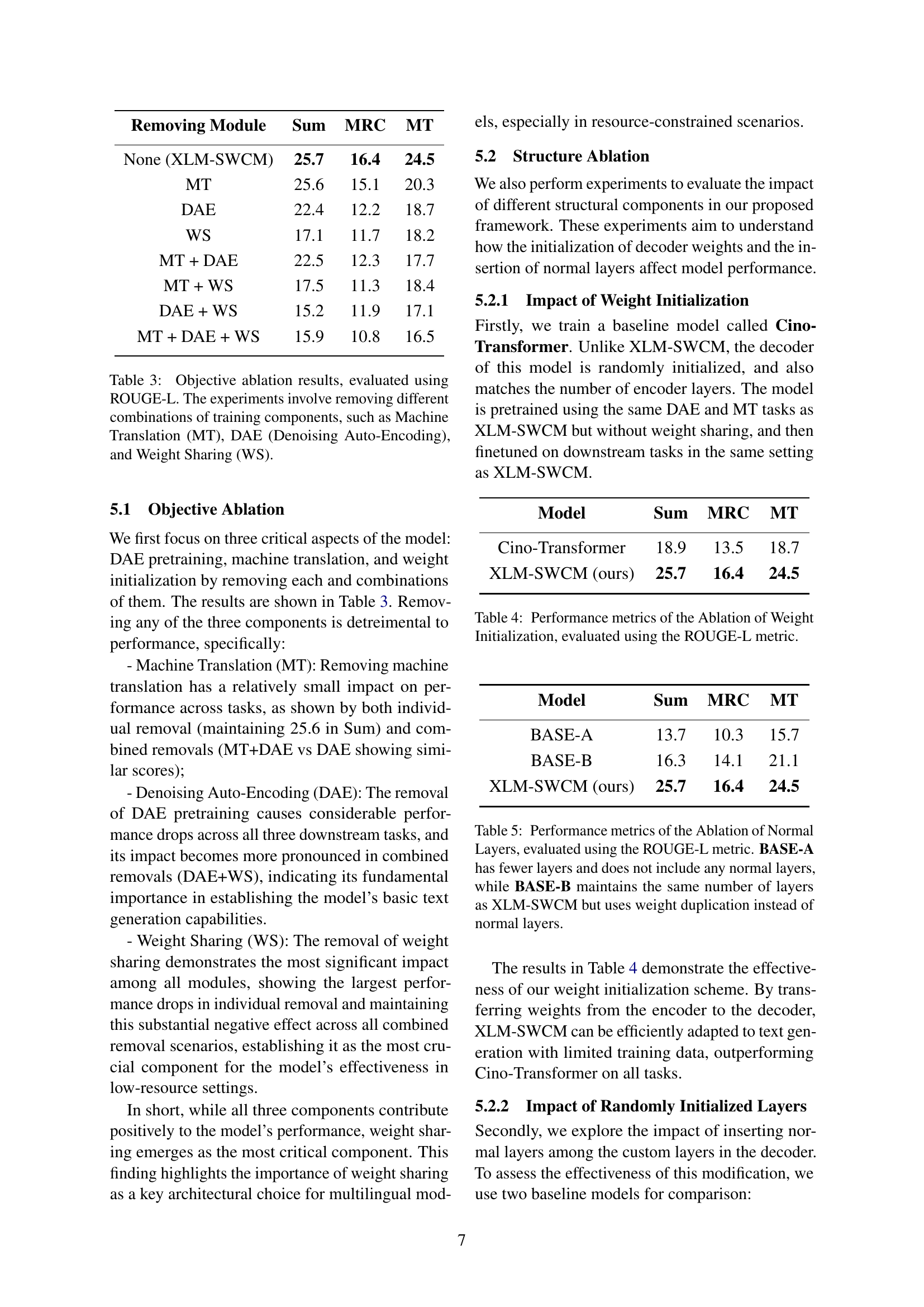
| Model | Zh | Bo | Ug | Mn | Kk | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sum | MRC | Sum | MRC | Sum | MRC | Sum | MRC | Sum | MRC | |
| MC2-LLaMA-13B | 47.1 | 43.5 | 9.5 | 6.1 | 3.5 | 2.4 | 3.7 | 2.2 | 2.6 | 3.9 |
| MC2-LLaMA-13B* | 47.3 | 44.7 | 13.1 | 11.5 | 11.7 | 10.1 | 9.7 | 10.2 | 2.9 | 4.6 |
| mBART-CM | 32.7 | 25.6 | 6.8 | 2.1 | 2.7 | 2.2 | 3.1 | 1.7 | 0.2 | 0.1 |
| XLM-SWCM (ours) | 33.1 | 23.5 | 17.1 | 11.1 | 12.5 | 11.1 | 13.5 | 7.2 | 5.6 | 6.9 |
🔼 This table presents the results of cross-lingual transfer experiments for text summarization and machine reading comprehension tasks. It compares the performance of three different models: XLM-SWCM (the proposed model), MC2-LLaMA-13B (a large language model), and mBART-CM (a baseline multilingual model). The performance is measured using ROUGE-L scores and is shown for four low-resource Chinese minority languages (Tibetan, Uyghur, Kazakh, and Mongolian) and one high-resource language (Chinese). A special note highlights that the MC2-LLaMA-13B results marked with an asterisk (*) were obtained by explicitly providing the target language to the model during evaluation. This highlights the impact of explicit language identification on performance for this model.
read the caption
Table 2: Cross-lingual Transfer performance of different models on Text Summarization (Sum) and Machine Reading Comprehension (MRC) tasks, evaluated using ROUGE-L. The best results for each task are highlighted. * indicates explicitly prompting MC2-LLaMA-13B with the language to be used in the response during evaluation.
| Removing Module | Sum | MRC | MT |
|---|---|---|---|
| None (XLM-SWCM) | 25.7 | 16.4 | 24.5 |
| MT | 25.6 | 15.1 | 20.3 |
| DAE | 22.4 | 12.2 | 18.7 |
| WS | 17.1 | 11.7 | 18.2 |
| MT + DAE | 22.5 | 12.3 | 17.7 |
| MT + WS | 17.5 | 11.3 | 18.4 |
| DAE + WS | 15.2 | 11.9 | 17.1 |
| MT + DAE + WS | 15.9 | 10.8 | 16.5 |
🔼 This table presents the ablation study results on the performance of the XLM-SWCM model when different training components are removed. The evaluation metric is ROUGE-L, a common metric for evaluating text summarization. The experiments systematically remove Machine Translation (MT), Denoising Auto-Encoding (DAE), and Weight Sharing (WS) components, both individually and in combination, to determine their individual and combined contributions to the model’s performance. The results show the impact of each component on text summarization, machine reading comprehension and machine translation tasks.
read the caption
Table 3: Objective ablation results, evaluated using ROUGE-L. The experiments involve removing different combinations of training components, such as Machine Translation (MT), DAE (Denoising Auto-Encoding), and Weight Sharing (WS).
| Model | Sum | MRC | MT |
|---|---|---|---|
| Cino-Transformer | 18.9 | 13.5 | 18.7 |
| XLM-SWCM (ours) | 25.7 | 16.4 | 24.5 |
🔼 This table presents the results of an ablation study on the impact of weight initialization in the XLM-SWCM model. It compares the performance of the full XLM-SWCM model (with weight sharing between encoder and decoder) to a baseline model (Cino-Transformer) where the decoder weights are randomly initialized. The performance is measured using ROUGE-L scores across three downstream tasks: Text Summarization, Machine Reading Comprehension (MRC), and Machine Translation (MT). The table shows that the weight sharing mechanism significantly improves the model’s performance on all three tasks.
read the caption
Table 4: Performance metrics of the Ablation of Weight Initialization, evaluated using the ROUGE-L metric.
| Model | Sum | MRC | MT |
|---|---|---|---|
| BASE-A | 13.7 | 10.3 | 15.7 |
| BASE-B | 16.3 | 14.1 | 21.1 |
| XLM-SWCM (ours) | 25.7 | 16.4 | 24.5 |
🔼 This table presents the results of an ablation study on the impact of normal layers within the decoder of the XLM-SWCM model. It compares the performance of three model variations on text summarization (Sum), machine reading comprehension (MRC), and machine translation (MT) tasks, all evaluated using the ROUGE-L metric. The variations include a baseline model (BASE-A) with fewer layers and no normal layers, a weight duplication model (BASE-B) with the same number of layers as XLM-SWCM but using weight duplication instead of normal layers, and the full XLM-SWCM model. The results show how the inclusion of normal layers and their specific implementation affects model performance on these downstream tasks.
read the caption
Table 5: Performance metrics of the Ablation of Normal Layers, evaluated using the ROUGE-L metric. BASE-A has fewer layers and does not include any normal layers, while BASE-B maintains the same number of layers as XLM-SWCM but uses weight duplication instead of normal layers.
| Language | Data Size | Number of Samples |
|---|---|---|
| Tibetan | 2.2 GB | 184,045 |
| Uyghur | 736 MB | 90,441 |
| Kazakh | 937 MB | 57,827 |
| Mongolian | 970 MB | 171,847 |
| Simplified Chinese | 2.1 GB | 836,075 |
🔼 Table 6 presents a detailed breakdown of the dataset used for pretraining the XLM-SWCM model and other baseline models. It includes the data size and the number of samples for each language in the dataset: Tibetan, Uyghur, Kazakh, Mongolian, and Simplified Chinese. This information is crucial for understanding the scale and composition of the training data used in the study.
read the caption
Table 6: Statistics of our pretraining dataset.
Full paper#