TL;DR#
Existing embedding model benchmarks often overlook the unique challenges of the financial domain. Models trained on general-purpose datasets may not effectively capture the nuances of financial language, which often involves specialized terminology, complex numerical relationships, and temporal sensitivity. This paper highlights the need for domain-specific evaluation and addresses the limitation by presenting a benchmark specialized for the financial domain.
To tackle these issues, the researchers introduce FinMTEB, a finance-specific benchmark encompassing diverse datasets and tasks. They also develop a domain-adapted model, Fin-E5. Their evaluation reveals that domain-adapted models consistently outperform general-purpose ones. Surprisingly, a basic Bag-of-Words (BoW) model outperforms sophisticated dense embeddings in specific tasks, indicating limitations of current techniques in handling financial text semantics. FinMTEB establishes a robust evaluation framework for financial NLP, offering valuable insights for developing effective financial embedding models.
Key Takeaways#
Why does it matter?#
This paper is crucial for financial NLP researchers because it introduces FinMTEB, the first comprehensive benchmark for evaluating embedding models in finance. It addresses the lack of domain-specific evaluation in the field and provides a standard for comparing models effectively. The development of Fin-E5, a domain-adapted model, and the surprising performance of BoW demonstrate limitations in current models and suggest new avenues for model development.
Visual Insights#

🔼 This word cloud shows the most frequent terms present in the training data used to develop the Fin-E5 model. The size of each word reflects its frequency, illustrating the prevalence of various financial concepts within the training dataset. This visualization helps to highlight the domain-specific vocabulary learned by Fin-E5, illustrating its focus on finance-related terms and concepts.
read the caption
Figure 1: Word cloud visualization of Fin-E5’s training data, contain common financial terms.
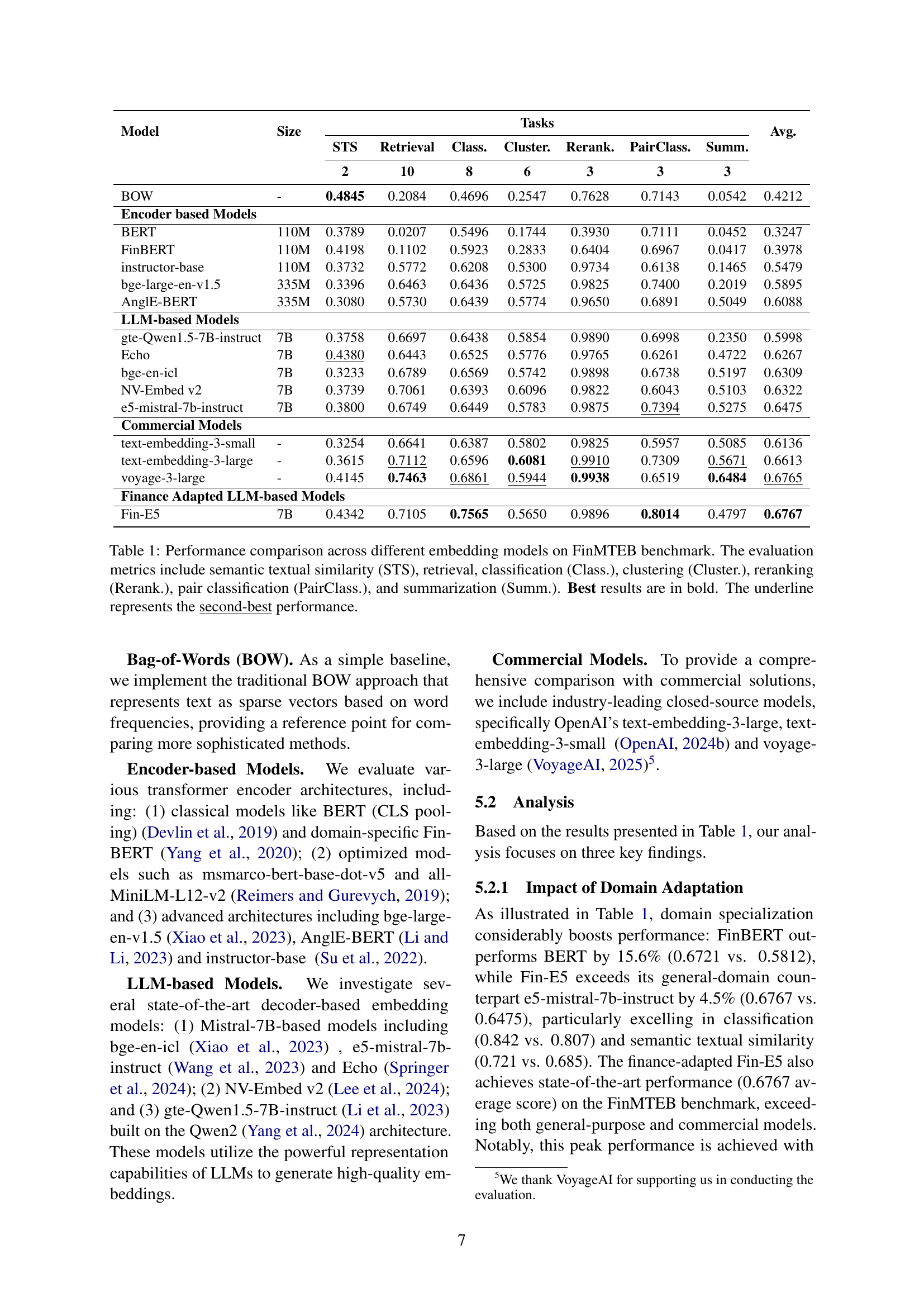
| Model | Size | Tasks | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|
| STS | Retrieval | Class. | Cluster. | Rerank. | PairClass. | Summ. | |||
| 2 | 10 | 8 | 6 | 3 | 3 | 3 | |||
| BOW | - | 0.4845 | 0.2084 | 0.4696 | 0.2547 | 0.7628 | 0.7143 | 0.0542 | 0.4212 |
| Encoder based Models | |||||||||
| BERT | 110M | 0.3789 | 0.0207 | 0.5496 | 0.1744 | 0.3930 | 0.7111 | 0.0452 | 0.3247 |
| FinBERT | 110M | 0.4198 | 0.1102 | 0.5923 | 0.2833 | 0.6404 | 0.6967 | 0.0417 | 0.3978 |
| instructor-base | 110M | 0.3732 | 0.5772 | 0.6208 | 0.5300 | 0.9734 | 0.6138 | 0.1465 | 0.5479 |
| bge-large-en-v1.5 | 335M | 0.3396 | 0.6463 | 0.6436 | 0.5725 | 0.9825 | 0.7400 | 0.2019 | 0.5895 |
| AnglE-BERT | 335M | 0.3080 | 0.5730 | 0.6439 | 0.5774 | 0.9650 | 0.6891 | 0.5049 | 0.6088 |
| LLM-based Models | |||||||||
| gte-Qwen1.5-7B-instruct | 7B | 0.3758 | 0.6697 | 0.6438 | 0.5854 | 0.9890 | 0.6998 | 0.2350 | 0.5998 |
| Echo | 7B | 0.4380 | 0.6443 | 0.6525 | 0.5776 | 0.9765 | 0.6261 | 0.4722 | 0.6267 |
| bge-en-icl | 7B | 0.3233 | 0.6789 | 0.6569 | 0.5742 | 0.9898 | 0.6738 | 0.5197 | 0.6309 |
| NV-Embed v2 | 7B | 0.3739 | 0.7061 | 0.6393 | 0.6096 | 0.9822 | 0.6043 | 0.5103 | 0.6322 |
| e5-mistral-7b-instruct | 7B | 0.3800 | 0.6749 | 0.6449 | 0.5783 | 0.9875 | 0.7394 | 0.5275 | 0.6475 |
| Commercial Models | |||||||||
| text-embedding-3-small | - | 0.3254 | 0.6641 | 0.6387 | 0.5802 | 0.9825 | 0.5957 | 0.5085 | 0.6136 |
| text-embedding-3-large | - | 0.3615 | 0.7112 | 0.6596 | 0.6081 | 0.9910 | 0.7309 | 0.5671 | 0.6613 |
| voyage-3-large | - | 0.4145 | 0.7463 | 0.6861 | 0.5944 | 0.9938 | 0.6519 | 0.6484 | 0.6765 |
| Finance Adapted LLM-based Models | |||||||||
| Fin-E5 | 7B | 0.4342 | 0.7105 | 0.7565 | 0.5650 | 0.9896 | 0.8014 | 0.4797 | 0.6767 |
🔼 Table 1 presents a performance comparison of various embedding models on the Finance Massive Text Embedding Benchmark (FinMTEB). It evaluates these models across seven distinct tasks: Semantic Textual Similarity (STS), Retrieval, Classification, Clustering, Reranking, Pair Classification, and Summarization. The table displays the performance of each model on each task, allowing for a comparison of their relative strengths and weaknesses. The best performing model for each task is highlighted in bold, and the second-best is underlined. Model sizes (in parameters) are also included to provide context for performance differences.
read the caption
Table 1: Performance comparison across different embedding models on FinMTEB benchmark. The evaluation metrics include semantic textual similarity (STS), retrieval, classification (Class.), clustering (Cluster.), reranking (Rerank.), pair classification (PairClass.), and summarization (Summ.). Best results are in bold. The underline represents the second-best performance.
In-depth insights#
FinMTEB Benchmark#
The FinMTEB Benchmark represents a substantial contribution to the field of financial natural language processing (NLP). Its core strength lies in its comprehensive nature, covering diverse financial text types in both English and Chinese across seven distinct tasks. This breadth ensures a more robust evaluation of embedding models, moving beyond the limitations of general-purpose benchmarks which often fail to capture the nuances of financial language. FinMTEB’s focus on domain-specific datasets, including annual reports, news articles, and regulatory filings, is particularly valuable. The inclusion of both Chinese and English datasets significantly expands the scope of applicability and allows for cross-lingual comparisons. Furthermore, the development and release of the Fin-E5 model, a finance-adapted embedding model, provides a valuable resource for researchers and practitioners. The findings regarding the surprising performance of simple Bag-of-Words models in certain tasks highlight the current limitations of sophisticated dense embeddings in the financial domain and suggest avenues for future research. Overall, FinMTEB offers a more realistic and challenging evaluation framework that will significantly advance the field of financial NLP.
Fin-E5 Model#
The research paper introduces Fin-E5, a finance-adapted text embedding model, designed to overcome limitations of general-purpose embedding models in financial applications. Fin-E5’s development directly addresses the need for improved handling of domain-specific terminology, temporal sensitivities, and complex numerical relationships prevalent in financial text. The model’s creation is notable for its use of a persona-based data synthesis method, generating a diverse range of financial tasks and incorporating different perspectives. This approach enhances the model’s ability to capture nuanced financial semantics and adapt to various financial contexts. The paper emphasizes the importance of domain adaptation through the use of Fin-E5, highlighting its consistent outperformance over general-purpose counterparts across multiple financial tasks. The results demonstrate that Fin-E5 achieves state-of-the-art performance on the Finance Massive Text Embedding Benchmark (FinMTEB), a comprehensive benchmark specifically designed for evaluating financial embedding models. Overall, Fin-E5 represents a significant advance in finance-specific natural language processing, offering valuable insights for researchers and practitioners working within the financial domain.
Domain Adaptation#
The concept of domain adaptation is central to the research paper, addressing the challenges of applying general-purpose embedding models to the specialized financial domain. The authors highlight the limited correlation between performance on general benchmarks and financial domain-specific tasks, emphasizing the necessity of adapting models to the unique characteristics of financial text. This adaptation is crucial due to factors like domain-specific terminology, temporal sensitivity, and complex numerical relationships. The paper explores domain adaptation strategies, specifically focusing on the development of a finance-adapted model (Fin-E5) using a persona-based data augmentation technique, and demonstrates the effectiveness of these techniques. Their findings strongly support that domain-adapted models significantly outperform their general-purpose counterparts, underscoring the importance of considering domain-specific needs when developing embedding models for financial natural language processing (NLP) applications.
BOW Outperforms#
The unexpected finding that a Bag-of-Words (BoW) model outperforms sophisticated dense embedding models in specific financial semantic textual similarity (STS) tasks is a significant result. This challenges the prevailing assumption that complex, dense embeddings are always superior; instead, it suggests that the current dense embedding techniques struggle to capture the nuances of financial language effectively. The reasons might include: over-reliance on contextual information which fails to identify core semantic similarities obscured by boilerplate language and financial jargon prevalent in financial documents; inability to effectively handle numerical and temporal relationships key to financial understanding; and/or limitations in the training data itself which may not sufficiently represent the intricate semantic space inherent in financial language. This finding underscores the need for further research into embedding model design and training methods to address these weaknesses, including investigations into how to incorporate better financial domain expertise and potentially explore alternative embedding techniques beyond the dense vector representation paradigm.
Future Directions#
Future research should focus on addressing the limitations of current embedding models in capturing nuanced financial semantics, particularly within the context of complex numerical data and temporal dependencies. Developing more robust and comprehensive evaluation frameworks for specialized financial domains is crucial, moving beyond single-task benchmarks to encompass diverse financial applications. This includes exploring new architectural designs that effectively handle the specific linguistic features and semantic complexities of financial text, including boilerplate language and domain-specific terminology. Investigating the potential of multimodal approaches that integrate textual and numerical data sources holds significant promise. Further research should also explore cross-lingual financial embedding models, expanding the scope beyond English and Chinese to support broader financial data analysis. Finally, exploring novel domain adaptation techniques specific to financial text is vital to optimize embedding model performance.
More visual insights#
More on figures

🔼 This figure provides a visual overview of the tasks and datasets included in the FinMTEB benchmark. It’s organized into seven categories representing different natural language processing tasks: Clustering, Reranking, Retrieval, Pair Classification, Classification, Summarization, and Semantic Textual Similarity (STS). Each task category lists the specific datasets used within FinMTEB for that task, showing the breadth of financial text data types covered by the benchmark (e.g., financial news, annual reports, etc.). The figure highlights the diversity of tasks and datasets designed to comprehensively evaluate the performance of embedding models in the financial domain. More detailed information on each dataset is available in Appendix A.
read the caption
Figure 2: An overview of tasks and datasets used in FinMTEB. All the dataset descriptions and examples are provided in the Appendix A.

🔼 This figure presents a breakdown of the data used to train the Fin-E5 model. The left pie chart visualizes the distribution of different personas (e.g., financial analyst, investor, trader) represented in the training data, illustrating the diversity of user perspectives. The right pie chart shows the distribution of various financial tasks (e.g., market analysis, risk assessment, financial planning) covered by the dataset. Both charts offer insights into the comprehensiveness and balance of the training data, demonstrating its ability to capture the nuances of financial language across various roles and tasks.
read the caption
Figure 3: Distribution analysis of 5000 randomly sampled training data showing the breakdown of Tasks and Person Types. Left: Persona distribution. Right: Task distribution.

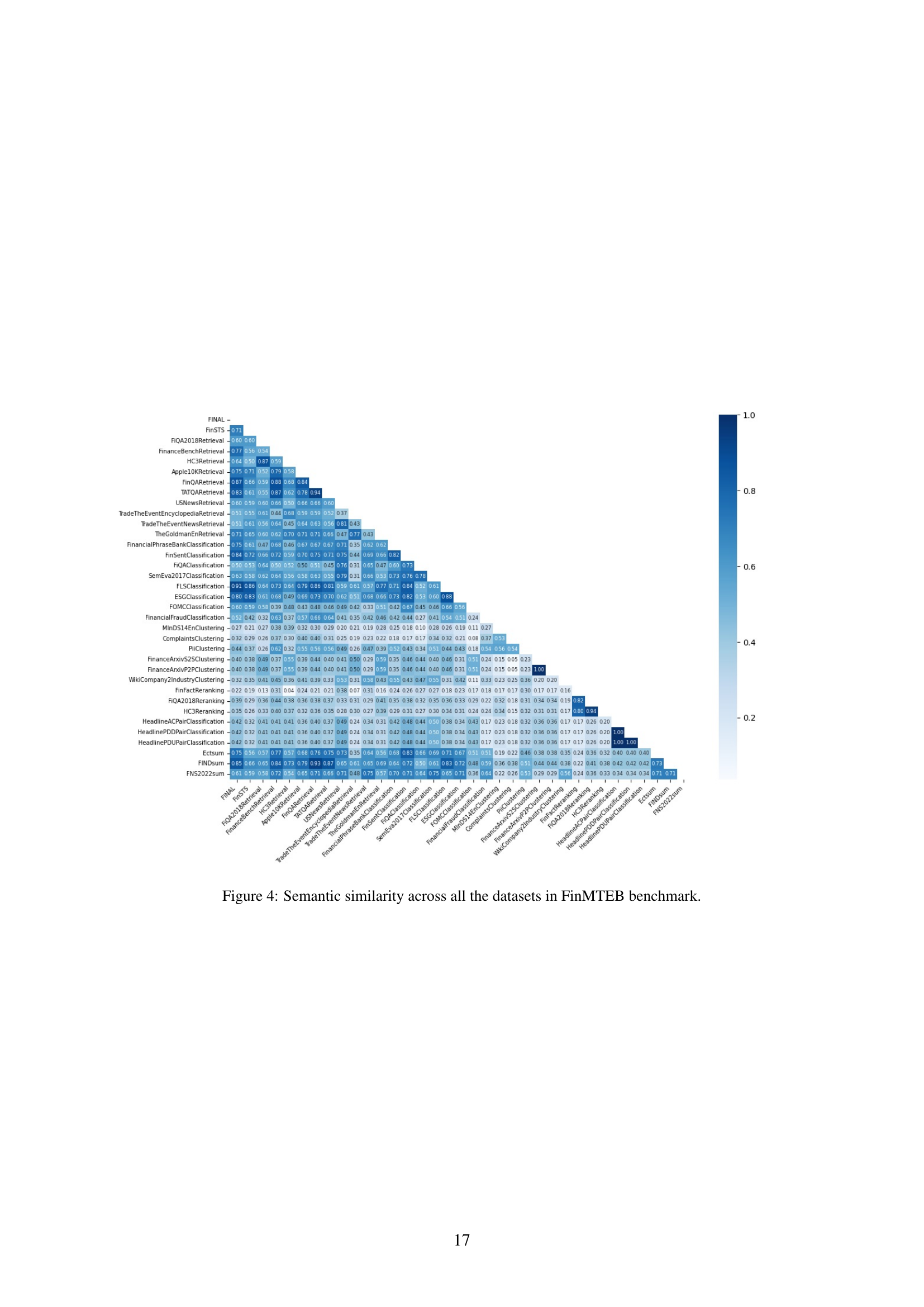
🔼 This heatmap visualizes the pairwise semantic similarity between the 64 datasets within the FinMTEB benchmark. Each cell represents the cosine similarity between the average embeddings of two datasets, calculated using the all-MiniLM-L6-v2 model. Darker blues indicate higher similarity, revealing relationships between datasets with similar semantic content. The figure highlights the semantic diversity of the FinMTEB datasets, showing that many have low similarity scores, demonstrating the benchmark’s comprehensive coverage of distinct financial text types.
read the caption
Figure 4: Semantic similarity across all the datasets in FinMTEB benchmark.
More on tables
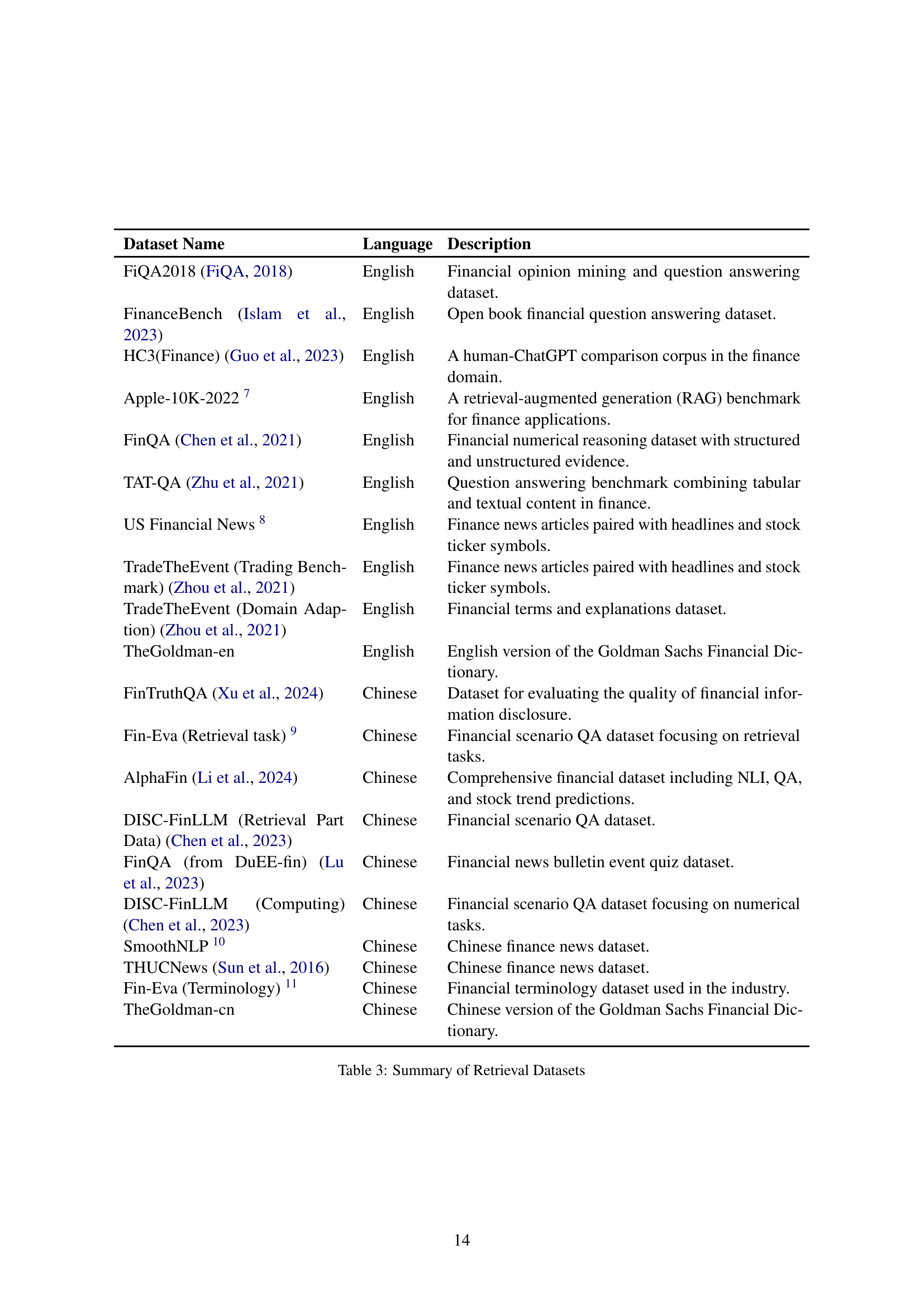
| Dataset Name | Language | Description |
|---|---|---|
| FINAL (Ju et al., 2023) | English | A dataset designed for discovering financial signals in narrative financial reports. |
| FinSTS (Liu et al., 2024a) | English | A dataset focused on detecting subtle semantic shifts in financial narratives. |
| AFQMC 666https://tianchi.aliyun.com/dataset/106411 | Chinese | A Chinese dataset for customer service question matching in the financial domain. |
| BQ-Corpus (Chen et al., 2018) | Chinese | A large-scale Chinese corpus for sentence semantic equivalence identification (SSEI) in the banking domain. |
🔼 This table lists the datasets used for the Semantic Textual Similarity (STS) task in the FinMTEB benchmark. It shows the dataset name, language (English or Chinese), and a brief description of each dataset’s content and purpose within the financial domain.
read the caption
Table 2: Summary of STS Datasets
| Dataset Name | Language | Description |
|---|---|---|
| FiQA2018 (FiQA, 2018) | English | Financial opinion mining and question answering dataset. |
| FinanceBench (Islam et al., 2023) | English | Open book financial question answering dataset. |
| HC3(Finance) (Guo et al., 2023) | English | A human-ChatGPT comparison corpus in the finance domain. |
| Apple-10K-2022 777https://lighthouz.ai/blog/rag-benchmark-finance-apple-10K-2022/ | English | A retrieval-augmented generation (RAG) benchmark for finance applications. |
| FinQA (Chen et al., 2021) | English | Financial numerical reasoning dataset with structured and unstructured evidence. |
| TAT-QA (Zhu et al., 2021) | English | Question answering benchmark combining tabular and textual content in finance. |
| US Financial News 888https://www.kaggle.com/datasets/jeet2016/us-financial-news-articles | English | Finance news articles paired with headlines and stock ticker symbols. |
| TradeTheEvent (Trading Benchmark) (Zhou et al., 2021) | English | Finance news articles paired with headlines and stock ticker symbols. |
| TradeTheEvent (Domain Adaption) (Zhou et al., 2021) | English | Financial terms and explanations dataset. |
| TheGoldman-en | English | English version of the Goldman Sachs Financial Dictionary. |
| FinTruthQA (Xu et al., 2024) | Chinese | Dataset for evaluating the quality of financial information disclosure. |
| Fin-Eva (Retrieval task) 999https://github.com/alipay/financial_evaluation_dataset/tree/main | Chinese | Financial scenario QA dataset focusing on retrieval tasks. |
| AlphaFin (Li et al., 2024) | Chinese | Comprehensive financial dataset including NLI, QA, and stock trend predictions. |
| DISC-FinLLM (Retrieval Part Data) (Chen et al., 2023) | Chinese | Financial scenario QA dataset. |
| FinQA (from DuEE-fin) (Lu et al., 2023) | Chinese | Financial news bulletin event quiz dataset. |
| DISC-FinLLM (Computing) (Chen et al., 2023) | Chinese | Financial scenario QA dataset focusing on numerical tasks. |
| SmoothNLP 101010https://github.com/smoothnlp/SmoothNLP | Chinese | Chinese finance news dataset. |
| THUCNews (Sun et al., 2016) | Chinese | Chinese finance news dataset. |
| Fin-Eva (Terminology) 111111https://github.com/alipay/financial_evaluation_dataset/tree/main | Chinese | Financial terminology dataset used in the industry. |
| TheGoldman-cn | Chinese | Chinese version of the Goldman Sachs Financial Dictionary. |
🔼 This table lists 20 datasets used in the paper’s benchmark for the retrieval task. Each dataset is described with its name, language (English or Chinese), and a concise description of its content and purpose. For example, some datasets contain financial news articles, others focus on question answering about financial topics, and yet others include information from SEC filings.
read the caption
Table 3: Summary of Retrieval Datasets
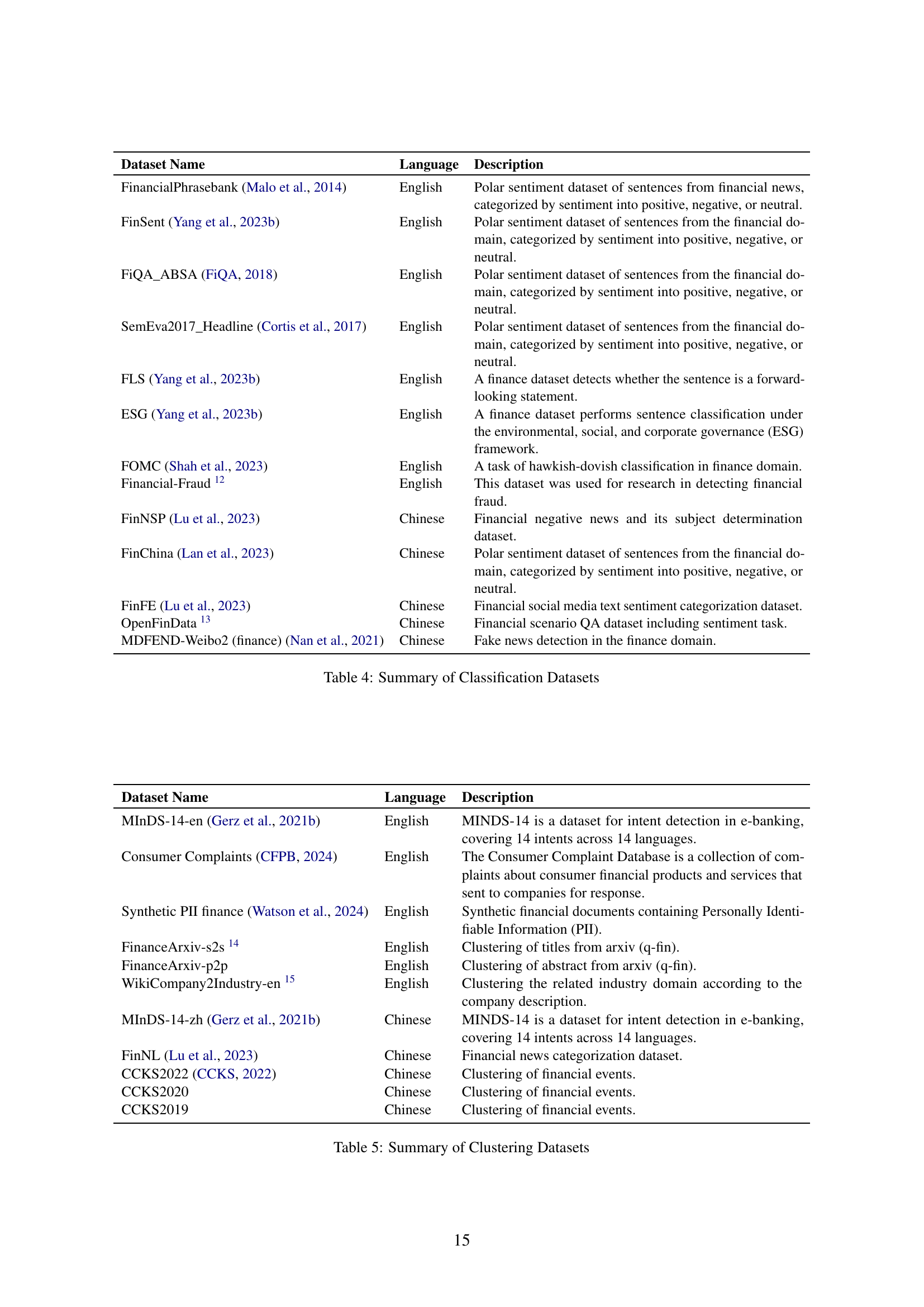
| Dataset Name | Language | Description |
|---|---|---|
| FinancialPhrasebank (Malo et al., 2014) | English | Polar sentiment dataset of sentences from financial news, categorized by sentiment into positive, negative, or neutral. |
| FinSent (Yang et al., 2023b) | English | Polar sentiment dataset of sentences from the financial domain, categorized by sentiment into positive, negative, or neutral. |
| FiQA_ABSA (FiQA, 2018) | English | Polar sentiment dataset of sentences from the financial domain, categorized by sentiment into positive, negative, or neutral. |
| SemEva2017_Headline (Cortis et al., 2017) | English | Polar sentiment dataset of sentences from the financial domain, categorized by sentiment into positive, negative, or neutral. |
| FLS (Yang et al., 2023b) | English | A finance dataset detects whether the sentence is a forward-looking statement. |
| ESG (Yang et al., 2023b) | English | A finance dataset performs sentence classification under the environmental, social, and corporate governance (ESG) framework. |
| FOMC (Shah et al., 2023) | English | A task of hawkish-dovish classification in finance domain. |
| Financial-Fraud 121212https://github.com/amitkedia007/Financial-Fraud-Detection-Using-LLMs/tree/main | English | This dataset was used for research in detecting financial fraud. |
| FinNSP (Lu et al., 2023) | Chinese | Financial negative news and its subject determination dataset. |
| FinChina (Lan et al., 2023) | Chinese | Polar sentiment dataset of sentences from the financial domain, categorized by sentiment into positive, negative, or neutral. |
| FinFE (Lu et al., 2023) | Chinese | Financial social media text sentiment categorization dataset. |
| OpenFinData 131313https://github.com/open-compass/OpenFinData?tab=readme-ov-file | Chinese | Financial scenario QA dataset including sentiment task. |
| MDFEND-Weibo2 (finance) (Nan et al., 2021) | Chinese | Fake news detection in the finance domain. |
🔼 This table lists 16 classification datasets used in the FinMTEB benchmark. Each dataset is described with its language (English or Chinese), and a detailed description of its contents and intended use in financial natural language processing. The descriptions highlight the type of financial text included (e.g., news, social media, regulatory filings), the task the dataset supports (e.g., sentiment analysis, fraud detection, financial news categorization), and key characteristics such as the number of sentences and whether the data is labeled with positive, negative, or neutral sentiments.
read the caption
Table 4: Summary of Classification Datasets
| Dataset Name | Language | Description |
|---|---|---|
| MInDS-14-en (Gerz et al., 2021b) | English | MINDS-14 is a dataset for intent detection in e-banking, covering 14 intents across 14 languages. |
| Consumer Complaints (CFPB, 2024) | English | The Consumer Complaint Database is a collection of complaints about consumer financial products and services that sent to companies for response. |
| Synthetic PII finance (Watson et al., 2024) | English | Synthetic financial documents containing Personally Identifiable Information (PII). |
| FinanceArxiv-s2s 141414Collect from the Arixv | English | Clustering of titles from arxiv (q-fin). |
| FinanceArxiv-p2p | English | Clustering of abstract from arxiv (q-fin). |
| WikiCompany2Industry-en 151515Collect from the Wikipedia | English | Clustering the related industry domain according to the company description. |
| MInDS-14-zh (Gerz et al., 2021b) | Chinese | MINDS-14 is a dataset for intent detection in e-banking, covering 14 intents across 14 languages. |
| FinNL (Lu et al., 2023) | Chinese | Financial news categorization dataset. |
| CCKS2022 (CCKS, 2022) | Chinese | Clustering of financial events. |
| CCKS2020 | Chinese | Clustering of financial events. |
| CCKS2019 | Chinese | Clustering of financial events. |
🔼 This table lists the datasets used in the FinMTEB benchmark for the clustering task. Each dataset is described with its language (English or Chinese) and a brief explanation of its content and purpose, providing context to understand the nature of the financial data included in each dataset and its relevance to clustering tasks. This aids in interpreting the results obtained by using these datasets in the FinMTEB benchmark. The datasets show diversity in terms of their sources and the type of financial data represented.
read the caption
Table 5: Summary of Clustering Datasets
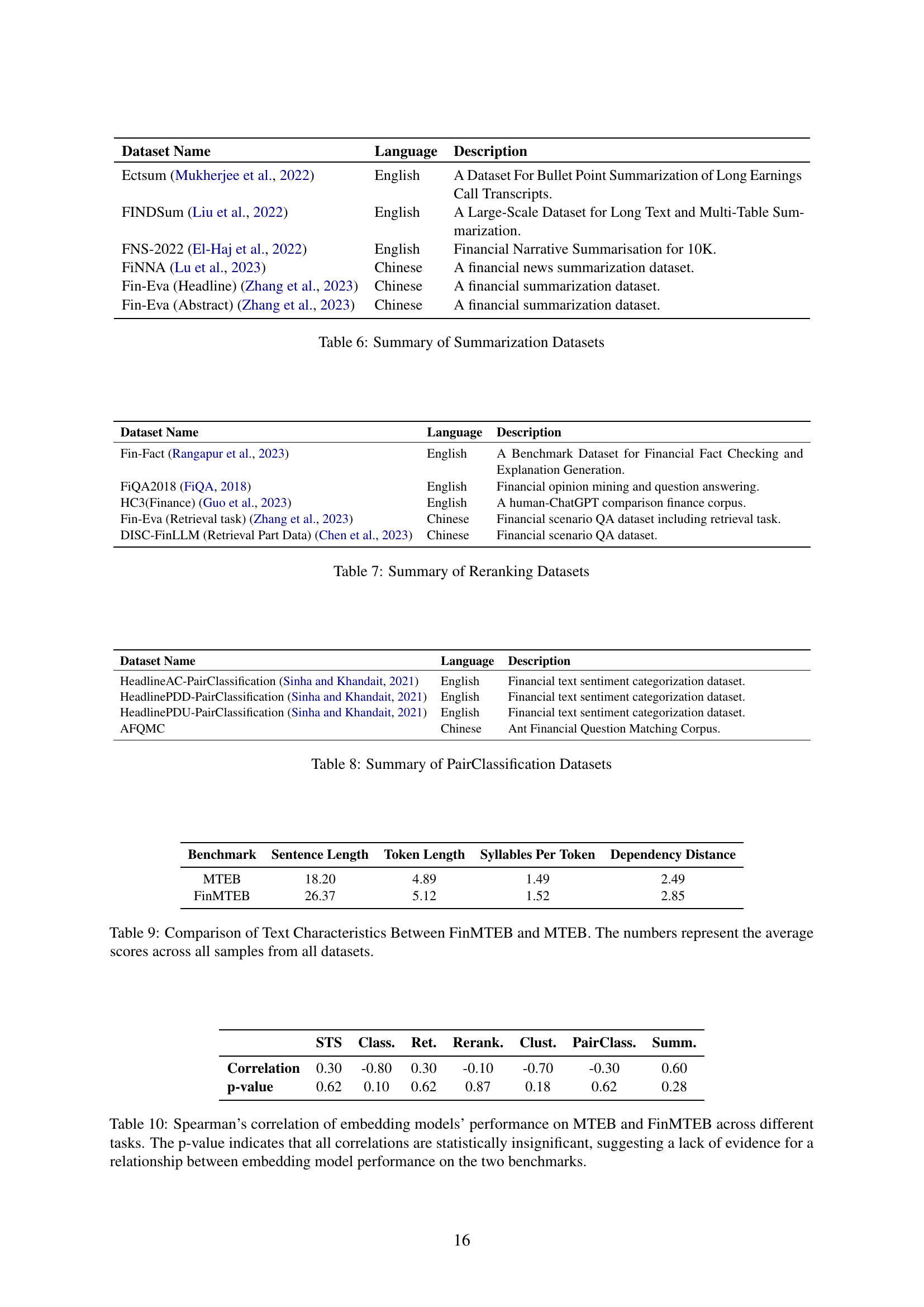
| Dataset Name | Language | Description |
|---|---|---|
| Ectsum (Mukherjee et al., 2022) | English | A Dataset For Bullet Point Summarization of Long Earnings Call Transcripts. |
| FINDSum (Liu et al., 2022) | English | A Large-Scale Dataset for Long Text and Multi-Table Summarization. |
| FNS-2022 (El-Haj et al., 2022) | English | Financial Narrative Summarisation for 10K. |
| FiNNA (Lu et al., 2023) | Chinese | A financial news summarization dataset. |
| Fin-Eva (Headline) (Zhang et al., 2023) | Chinese | A financial summarization dataset. |
| Fin-Eva (Abstract) (Zhang et al., 2023) | Chinese | A financial summarization dataset. |
🔼 This table lists summarization datasets used in the FinMTEB benchmark. It provides details for each dataset, including the dataset name, language (English or Chinese), and a description of the dataset’s content and purpose within the context of financial text summarization.
read the caption
Table 6: Summary of Summarization Datasets
| Dataset Name | Language | Description |
|---|---|---|
| Fin-Fact (Rangapur et al., 2023) | English | A Benchmark Dataset for Financial Fact Checking and Explanation Generation. |
| FiQA2018 (FiQA, 2018) | English | Financial opinion mining and question answering. |
| HC3(Finance) (Guo et al., 2023) | English | A human-ChatGPT comparison finance corpus. |
| Fin-Eva (Retrieval task) (Zhang et al., 2023) | Chinese | Financial scenario QA dataset including retrieval task. |
| DISC-FinLLM (Retrieval Part Data) (Chen et al., 2023) | Chinese | Financial scenario QA dataset. |
🔼 This table lists the datasets used for the reranking task in the FinMTEB benchmark. For each dataset, it provides the language (English or Chinese) and a description of its content and purpose. The descriptions highlight the specific focus of each dataset, such as financial fact-checking, question answering, or retrieval of relevant information in financial contexts.
read the caption
Table 7: Summary of Reranking Datasets
| Dataset Name | Language | Description |
|---|---|---|
| HeadlineAC-PairClassification (Sinha and Khandait, 2021) | English | Financial text sentiment categorization dataset. |
| HeadlinePDD-PairClassification (Sinha and Khandait, 2021) | English | Financial text sentiment categorization dataset. |
| HeadlinePDU-PairClassification (Sinha and Khandait, 2021) | English | Financial text sentiment categorization dataset. |
| AFQMC | Chinese | Ant Financial Question Matching Corpus. |
🔼 This table lists the datasets used for the pair classification task in the FinMTEB benchmark. For each dataset, it provides the language (English or Chinese) and a brief description of its content and purpose within the context of financial text analysis. The descriptions highlight the type of data and the specific aspect of financial text pairs being classified.
read the caption
Table 8: Summary of PairClassification Datasets
| STS | Class. | Ret. | Rerank. | Clust. | PairClass. | Summ. | |
|---|---|---|---|---|---|---|---|
| Correlation | 0.30 | -0.80 | 0.30 | -0.10 | -0.70 | -0.30 | 0.60 |
| p-value | 0.62 | 0.10 | 0.62 | 0.87 | 0.18 | 0.62 | 0.28 |
🔼 This table compares several linguistic features of the FinMTEB and MTEB datasets, which are used for evaluating text embedding models. The features compared are average sentence length, average token length, average number of syllables per token, and average dependency distance. The data reveals differences in the complexity of text between the financial domain (FinMTEB) and a general domain (MTEB), with FinMTEB showing longer and more complex sentences.
read the caption
Table 9: Comparison of Text Characteristics Between FinMTEB and MTEB. The numbers represent the average scores across all samples from all datasets.
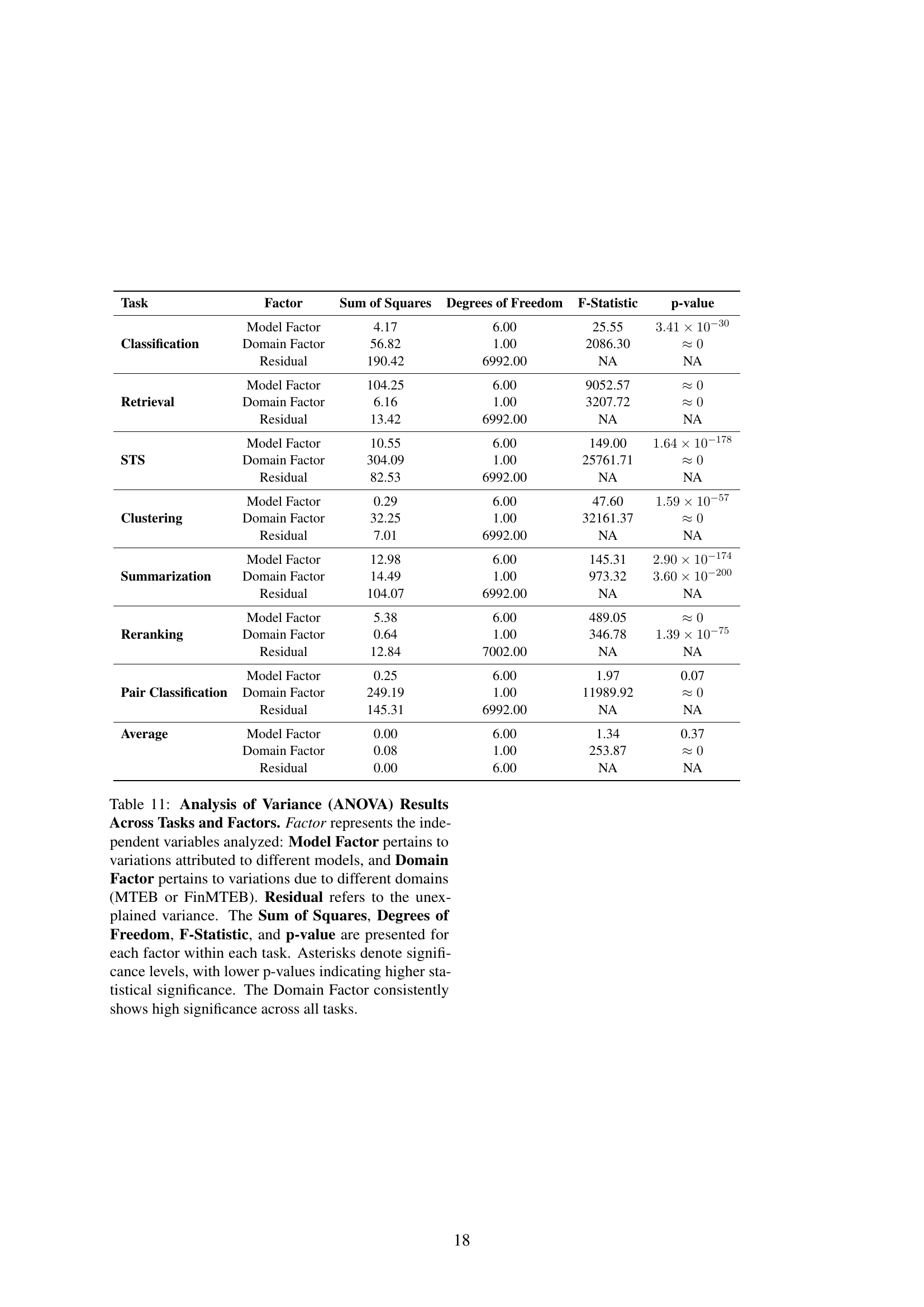
| Task | Factor | Sum of Squares | Degrees of Freedom | F-Statistic | p-value |
|---|---|---|---|---|---|
| Classification | Model Factor | 4.17 | 6.00 | 25.55 | |
| Domain Factor | 56.82 | 1.00 | 2086.30 | ||
| Residual | 190.42 | 6992.00 | NA | NA | |
| Retrieval | Model Factor | 104.25 | 6.00 | 9052.57 | |
| Domain Factor | 6.16 | 1.00 | 3207.72 | ||
| Residual | 13.42 | 6992.00 | NA | NA | |
| STS | Model Factor | 10.55 | 6.00 | 149.00 | |
| Domain Factor | 304.09 | 1.00 | 25761.71 | ||
| Residual | 82.53 | 6992.00 | NA | NA | |
| Clustering | Model Factor | 0.29 | 6.00 | 47.60 | |
| Domain Factor | 32.25 | 1.00 | 32161.37 | ||
| Residual | 7.01 | 6992.00 | NA | NA | |
| Summarization | Model Factor | 12.98 | 6.00 | 145.31 | |
| Domain Factor | 14.49 | 1.00 | 973.32 | ||
| Residual | 104.07 | 6992.00 | NA | NA | |
| Reranking | Model Factor | 5.38 | 6.00 | 489.05 | |
| Domain Factor | 0.64 | 1.00 | 346.78 | ||
| Residual | 12.84 | 7002.00 | NA | NA | |
| Pair Classification | Model Factor | 0.25 | 6.00 | 1.97 | 0.07 |
| Domain Factor | 249.19 | 1.00 | 11989.92 | ||
| Residual | 145.31 | 6992.00 | NA | NA | |
| Average | Model Factor | 0.00 | 6.00 | 1.34 | 0.37 |
| Domain Factor | 0.08 | 1.00 | 253.87 | ||
| Residual | 0.00 | 6.00 | NA | NA |
🔼 This table presents the Spearman’s rank correlation coefficients between the performance rankings of various embedding models on two benchmark datasets: the Massive Text Embedding Benchmark (MTEB) and the Finance Massive Text Embedding Benchmark (FinMTEB). The analysis considers seven different NLP tasks. The p-values associated with each correlation indicate whether the observed correlation is statistically significant. In this case, all p-values are above the standard significance threshold, suggesting that there is no statistically significant relationship between a model’s performance on MTEB and its performance on FinMTEB. This implies that performance on a general-purpose benchmark (MTEB) does not reliably predict performance on a domain-specific benchmark (FinMTEB), highlighting the importance of domain-specific evaluation.
read the caption
Table 10: Spearman’s correlation of embedding models’ performance on MTEB and FinMTEB across different tasks. The p-value indicates that all correlations are statistically insignificant, suggesting a lack of evidence for a relationship between embedding model performance on the two benchmarks.
Full paper#