TL;DR#
Traditional reinforcement learning (RL) for algorithmic trading faces challenges in handling diverse market data and adapting to changing market conditions. Manually crafted features and complex feature engineering often lead to biases and information loss, hindering the robustness of real-time decisions. Large Language Models (LLMs), with their ability to process multimodal data, offer significant potential to overcome these limitations.
This paper introduces FLAG-TRADER, a novel framework that integrates LLMs with gradient-based RL for financial trading. FLAG-TRADER uses a partially fine-tuned LLM as the policy network, leveraging its pre-trained knowledge while adapting to the financial domain through parameter-efficient fine-tuning. This hybrid approach enhances LLM performance in trading and improves results on other financial tasks. Extensive experiments demonstrate that FLAG-TRADER consistently outperforms traditional methods across multiple metrics, highlighting the effectiveness of integrating LLMs with RL for financial decision-making.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates a novel approach to financial trading that combines the power of large language models (LLMs) with reinforcement learning (RL). This is a significant contribution because it addresses the limitations of traditional RL methods in financial markets and shows a novel solution by leveraging the strengths of LLMs in processing multimodal data and their ability to capture complex patterns. The findings have the potential to improve trading strategies, reduce reliance on manually crafted features, and open new avenues for research in both AI and finance.
Visual Insights#

🔼 This figure illustrates the FLAG-TRADER framework, which combines a large language model (LLM) with reinforcement learning for financial trading. The environment provides the current market state (st). This state, along with the trading task details and the allowed actions, is presented to the LLM as a prompt. The LLM then determines an action (at), which is executed in the trading environment. The environment provides feedback in the form of a reward (r(st, at)) and updates the system’s state to st+1. The LLM’s action likelihood is used in a policy gradient algorithm (like PPO) to iteratively improve trading decisions. Experience from trading (states, actions, rewards) is stored in a replay buffer to enhance the training process.
read the caption
Figure 1: A high-level overview of our LLM-based reinforcement learning setup for financial trading. The environment provides the current state stsubscript𝑠𝑡s_{t}italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. A prompt containing task details, the action space, and the current state is fed into the LLM, which outputs a trading action atsubscript𝑎𝑡a_{t}italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. The action is executed in the environment, yielding a reward r(st,at)𝑟subscript𝑠𝑡subscript𝑎𝑡r(s_{t},a_{t})italic_r ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) and next state st+1subscript𝑠𝑡1s_{t+1}italic_s start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT. The log-likelihood logπθ(at|lang(st))subscriptsubscript𝜋𝜃conditionalsubscript𝑎𝑡langsubscript𝑠𝑡\log_{\pi_{\theta}}(a_{t}|\texttt{lang}(s_{t}))roman_log start_POSTSUBSCRIPT italic_π start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT end_POSTSUBSCRIPT ( italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT | lang ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) ) is then leveraged by a policy gradient method (e.g., PPO), with experience tuples stored in a replay buffer for iterative updates.
| Model | MSFT | JNJ | UVV | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CR | SR | AV | MDD | CR | SR | AV | MDD | CR | SR | AV | MDD | |
| Buy & Hold | 15.340 | 1.039 | 24.980 | 9.428 | 13.895 | 1.343 | 17.500 | 9.847 | 36.583 | 2.112 | 29.299 | 15.406 |
| Financial Domain Models | ||||||||||||
| Palmyra-Fin-70B | 14.697 | 0.897 | 27.518 | 9.428 | 5.748 | 0.450 | 19.317 | 9.367 | 37.875 | 2.039 | 31.200 | 15.967 |
| Proprietary Models | ||||||||||||
| GPT-o1-preview | 17.184 | 0.962 | 30.000 | 9.428 | 13.561 | 1.086 | 20.864 | 9.847 | 41.508 | 2.147 | 32.479 | 9.633 |
| GPT-4 | 16.654 | 0.932 | 30.022 | 9.428 | 13.712 | 1.103 | 20.894 | 9.860 | 31.791 | 1.640 | 32.567 | 10.434 |
| GPT-4o | 12.461 | 0.924 | 22.653 | 6.647 | 9.099 | 0.875 | 17.471 | 7.169 | 8.043 | 0.496 | 27.241 | 14.889 |
| Open-Source Models | ||||||||||||
| Qwen2.5-72B-Instruct | 7.421 | 0.588 | 21.238 | 6.973 | 14.353 | 1.140 | 20.995 | 9.812 | 37.178 | 1.822 | 34.223 | 13.365 |
| Llama-3.1-70B-Instruct | 17.396 | 1.335 | 21.892 | 7.045 | 13.868 | 1.121 | 20.779 | 9.825 | 35.981 | 1.728 | 34.986 | 15.406 |
| DeepSeek-67B-Chat | 13.941 | 0.834 | 28.081 | 7.850 | 14.426 | 1.185 | 20.450 | 9.825 | 29.940 | 1.481 | 33.964 | 15.407 |
| Yi-1.5-34B-Chat | 22.093 | 1.253 | 29.613 | 9.428 | 14.004 | 1.180 | 19.938 | 9.847 | 20.889 | 1.020 | 34.417 | 14.936 |
| Qwen2.5-32B-Instruct | -0.557 | -0.041 | 22.893 | 8.946 | 2.905 | 0.292 | 16.725 | 7.169 | -1.623 | -0.097 | 27.973 | 17.986 |
| DeepSeek-V2-Lite (15.7B) | 11.904 | 0.694 | 28.796 | 16.094 | -7.482 | -0.670 | 18.773 | 17.806 | 33.560 | 1.703 | 33.099 | 12.984 |
| Yi-1.5-9B-Chat | 19.333 | 1.094 | 29.690 | 9.428 | 18.606 | 1.611 | 19.409 | 10.986 | 49.415 | 2.410 | 34.446 | 11.430 |
| Llama-3.1-8B-Instruct | 22.703 | 1.322 | 28.855 | 7.385 | 13.988 | 1.486 | 20.460 | 9.969 | 41.108 | 1.981 | 34.866 | 16.429 |
| Qwen-2.5-Instruct-7B | -10.305 | -0.724 | 23.937 | 23.371 | 21.852 | 0.980 | 37.425 | 9.573 | 11.752 | 0.853 | 22.988 | 15.451 |
| FLAG-TRADER | ||||||||||||
| SmolLM2-135M-Instruct | 20.106 | 1.373 | 24.932 | 9.428 | 33.724 | 3.344 | 17.174 | 9.320 | 46.799 | 1.463 | 67.758 | 35.039 |
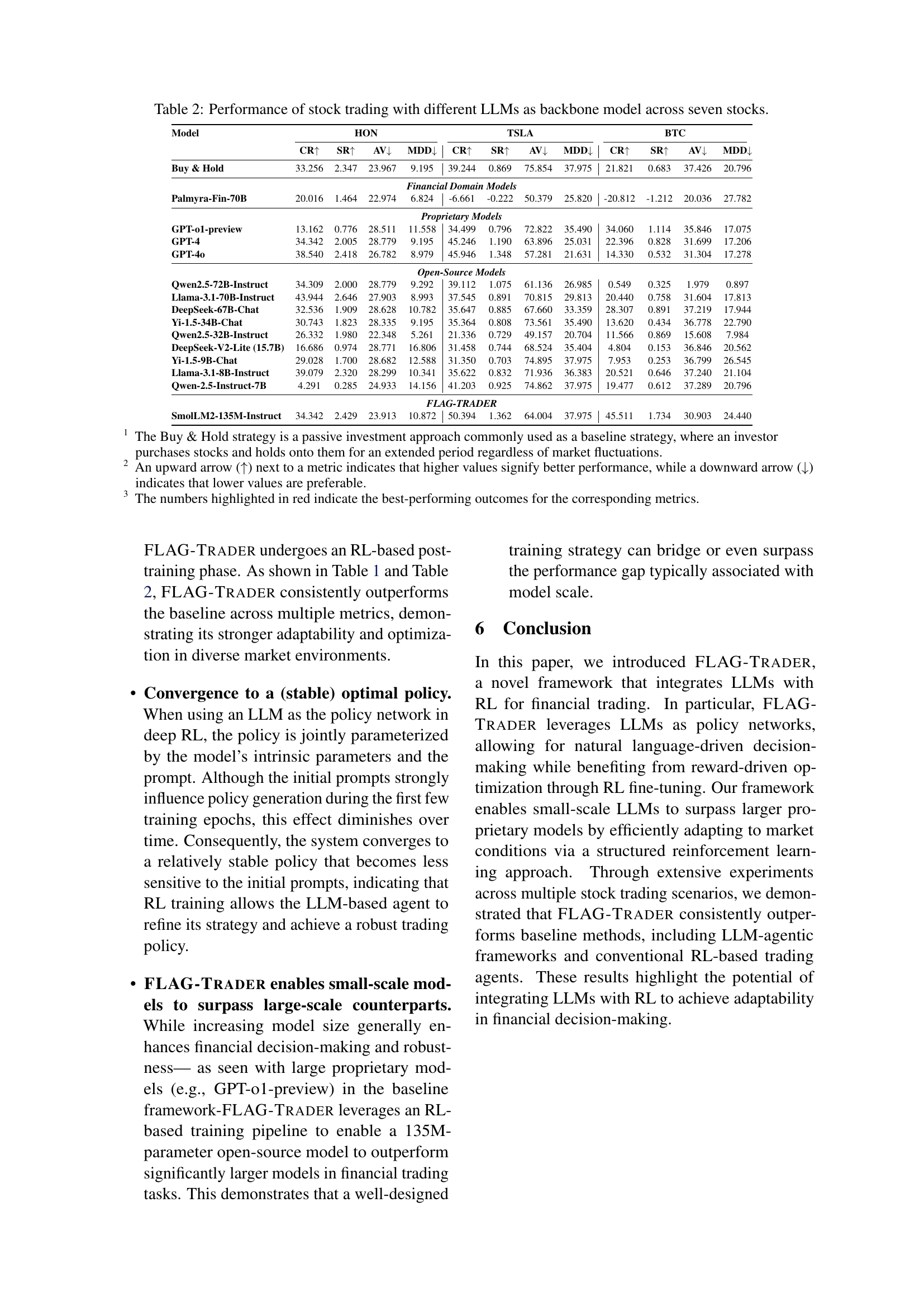
🔼 This table presents the performance comparison of various Large Language Models (LLMs) used as the backbone in a financial stock trading strategy. Seven different stocks (MSFT, JNJ, UVV, HON, TSLA, BTC, and a Buy & Hold strategy) are evaluated using four key metrics: Cumulative Return (CR), Sharpe Ratio (SR), Annualized Volatility (AV), and Maximum Drawdown (MDD). The results demonstrate the relative effectiveness of different LLMs in achieving profitable and stable trading performance across these diverse assets. The models are categorized into financial domain models, proprietary models, and open-source models to illustrate the performance differences between model types.
read the caption
Table 1: Performance of stock trading with different LLMs as backbone model across seven stocks.
In-depth insights#
LLM-RL Fusion#
LLM-RL fusion represents a significant advancement in AI, particularly within the context of complex sequential decision-making tasks like financial trading. The core idea is to leverage the strengths of both Large Language Models (LLMs) and Reinforcement Learning (RL): LLMs provide powerful multimodal reasoning and feature extraction capabilities from diverse data sources, while RL optimizes agent behavior through reward-driven learning. This synergy addresses key limitations of traditional RL approaches in finance, which often struggle with multimodal data integration and non-stationary market dynamics. By using an LLM as a policy network, the model benefits from pre-trained knowledge while fine-tuning to the specific financial domain. Parameter-efficient fine-tuning is crucial for efficiency and preventing catastrophic forgetting. The RL component, typically implemented using algorithms like PPO, guides the LLM to refine its decision-making process by directly optimizing for trading performance, maximizing cumulative returns, and mitigating risks. However, challenges remain. Computational costs can be high, especially with large LLMs, and careful consideration is needed for prompt design and handling non-stationary data. Future research should focus on improving efficiency, robustness, and incorporating explicit risk management into the optimization process. The fusion model shows immense promise, particularly in areas beyond finance, where complex sequential decisions must be made from diverse, often unstructured, input data.
Prompt Engineering#
Prompt engineering plays a crucial role in leveraging LLMs for financial trading, as highlighted in the research. Effective prompt design is vital for guiding the LLM to generate accurate and actionable trading decisions. The paper emphasizes the importance of structured prompts that encapsulate essential elements such as task descriptions, action spaces, and current market states. A well-crafted prompt ensures that the LLM receives comprehensive input, enabling informed and contextually relevant output. The research showcases how parameter-efficient fine-tuning, combined with meticulous prompt engineering, enhances LLM performance in financial trading tasks, surpassing even larger proprietary models. The emphasis on structured prompts and the careful selection of information to include/exclude within the prompts highlights the need for further investigation into this aspect of using LLMs in finance. This is crucial because the quality of the prompt directly influences the LLM’s reasoning capabilities and significantly impacts the final trading decisions. Future research might explore advanced prompt techniques, such as chain-of-thought prompting, to further improve the decision-making abilities of LLMs in this complex domain. Optimizing prompt design is therefore essential for maximizing the benefits of this technology in the financial sector.
Parameter Efficiency#
Parameter efficiency is crucial in large language model (LLM) adaptation for financial trading, as it addresses the computational cost challenges of fine-tuning massive models. FLAG-TRADER achieves this by employing a partial fine-tuning strategy, focusing on updating only a subset of the LLM’s parameters instead of the entire model. This approach retains the pre-trained knowledge while enabling domain adaptation to financial tasks. The parameter-efficient fine-tuning module jointly encodes temporal market data and textual information, improving model performance on various financial tasks. By carefully balancing domain adaptation and knowledge retention, FLAG-TRADER manages computational cost without sacrificing accuracy, making it suitable for real-time trading applications where computational efficiency is vital. The effectiveness of this approach is demonstrated by achieving superior trading results, surpassing even larger proprietary models.
Financial Trading RL#
Reinforcement learning (RL) has emerged as a powerful technique for algorithmic financial trading, offering the potential to optimize trading strategies in complex and dynamic market environments. Traditional RL approaches, however, often struggle with the multifaceted nature of financial data, encompassing time series, textual sentiment, and various other market signals. They also suffer from limitations in handling non-stationary data distributions and the need for manual feature engineering, which can introduce subjective bias. The integration of large language models (LLMs) presents a significant opportunity to overcome these challenges. LLMs excel at processing multimodal data and understanding contextual information, while RL provides the mechanism for adaptive decision-making based on rewards. A key area of focus is developing effective methods for combining the strengths of both, potentially through techniques like parameter-efficient fine-tuning of LLMs for the financial domain, thus balancing knowledge retention and adaptation. Further research should focus on addressing the computational cost of such hybrid models and improving their robustness to market volatility and non-stationarity, exploring techniques such as continual learning or risk-sensitive optimization. The integration of LLMs and RL in financial trading represents a promising frontier with the potential for significant advancements in automated trading strategies.
Future Directions#
Future research should prioritize reducing the computational cost of FLAG-TRADER, especially when dealing with large-scale market data. Addressing the non-stationarity of financial markets through continual learning or meta-learning is crucial for long-term generalization. Prompt engineering techniques need improvement to mitigate biases and enhance robustness. Finally, incorporating explicit risk management into the framework will significantly enhance its practicality and suitability for real-world financial applications. Exploring alternative state representations beyond structured text prompts could also improve efficiency and accuracy.
More visual insights#
More on figures

🔼 FLAG-TRADER uses an LLM as its core, splitting it into frozen base layers (retaining pre-trained knowledge) and trainable top layers (adapted for finance). Both a policy network (for choosing actions) and a value network (for estimating future value) use these trainable layers, but each has its own separate head which is updated during training using a policy gradient method. This architecture allows for efficient fine-tuning of the LLM for the financial trading task.
read the caption
Figure 2: The FLAG-Trader pipeline for financial trading, utilizing an LLM-based actor-critic architecture. The LLM consists of frozen base layers θfrozensubscript𝜃frozen\theta_{\texttt{frozen}}italic_θ start_POSTSUBSCRIPT frozen end_POSTSUBSCRIPT that retain pre-trained knowledge and trainable top layers θtrainsubscript𝜃train\theta_{\texttt{train}}italic_θ start_POSTSUBSCRIPT train end_POSTSUBSCRIPT for financial decision-making. Both the Policy_Net and Value_Net share these trainable layers while maintaining separate policy head θPsubscript𝜃𝑃\theta_{P}italic_θ start_POSTSUBSCRIPT italic_P end_POSTSUBSCRIPT and value head θVsubscript𝜃𝑉\theta_{V}italic_θ start_POSTSUBSCRIPT italic_V end_POSTSUBSCRIPT, which are updated by policy gradient method.

🔼 This figure shows the structure of the prompt used as input to the LLM in the FLAG-TRADER model. The prompt is designed to be comprehensive and unambiguous, providing all the necessary information for the model to make informed trading decisions. It includes four key parts: 1) a clear description of the trading task, stating the overall objective; 2) a definition of the permissible actions (buy, sell, or hold); 3) a detailed description of the current market state, including historical prices, account status, cash balance, asset position, and other relevant indicators; and 4) instructions on the expected format of the output (a JSON specifying the action to take). The example provided illustrates the prompt’s structure in the context of stock trading.
read the caption
Figure 3: The format of input prompt. It contains the task description, the legible action set, the current state description, and the output action format.
More on tables
| Model | HON | TSLA | BTC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CR | SR | AV | MDD | CR | SR | AV | MDD | CR | SR | AV | MDD | |
| Buy & Hold | 33.256 | 2.347 | 23.967 | 9.195 | 39.244 | 0.869 | 75.854 | 37.975 | 21.821 | 0.683 | 37.426 | 20.796 |
| Financial Domain Models | ||||||||||||
| Palmyra-Fin-70B | 20.016 | 1.464 | 22.974 | 6.824 | -6.661 | -0.222 | 50.379 | 25.820 | -20.812 | -1.212 | 20.036 | 27.782 |
| Proprietary Models | ||||||||||||
| GPT-o1-preview | 13.162 | 0.776 | 28.511 | 11.558 | 34.499 | 0.796 | 72.822 | 35.490 | 34.060 | 1.114 | 35.846 | 17.075 |
| GPT-4 | 34.342 | 2.005 | 28.779 | 9.195 | 45.246 | 1.190 | 63.896 | 25.031 | 22.396 | 0.828 | 31.699 | 17.206 |
| GPT-4o | 38.540 | 2.418 | 26.782 | 8.979 | 45.946 | 1.348 | 57.281 | 21.631 | 14.330 | 0.532 | 31.304 | 17.278 |
| Open-Source Models | ||||||||||||
| Qwen2.5-72B-Instruct | 34.309 | 2.000 | 28.779 | 9.292 | 39.112 | 1.075 | 61.136 | 26.985 | 0.549 | 0.325 | 1.979 | 0.897 |
| Llama-3.1-70B-Instruct | 43.944 | 2.646 | 27.903 | 8.993 | 37.545 | 0.891 | 70.815 | 29.813 | 20.440 | 0.758 | 31.604 | 17.813 |
| DeepSeek-67B-Chat | 32.536 | 1.909 | 28.628 | 10.782 | 35.647 | 0.885 | 67.660 | 33.359 | 28.307 | 0.891 | 37.219 | 17.944 |
| Yi-1.5-34B-Chat | 30.743 | 1.823 | 28.335 | 9.195 | 35.364 | 0.808 | 73.561 | 35.490 | 13.620 | 0.434 | 36.778 | 22.790 |
| Qwen2.5-32B-Instruct | 26.332 | 1.980 | 22.348 | 5.261 | 21.336 | 0.729 | 49.157 | 20.704 | 11.566 | 0.869 | 15.608 | 7.984 |
| DeepSeek-V2-Lite (15.7B) | 16.686 | 0.974 | 28.771 | 16.806 | 31.458 | 0.744 | 68.524 | 35.404 | 4.804 | 0.153 | 36.846 | 20.562 |
| Yi-1.5-9B-Chat | 29.028 | 1.700 | 28.682 | 12.588 | 31.350 | 0.703 | 74.895 | 37.975 | 7.953 | 0.253 | 36.799 | 26.545 |
| Llama-3.1-8B-Instruct | 39.079 | 2.320 | 28.299 | 10.341 | 35.622 | 0.832 | 71.936 | 36.383 | 20.521 | 0.646 | 37.240 | 21.104 |
| Qwen-2.5-Instruct-7B | 4.291 | 0.285 | 24.933 | 14.156 | 41.203 | 0.925 | 74.862 | 37.975 | 19.477 | 0.612 | 37.289 | 20.796 |
| FLAG-TRADER | ||||||||||||
| SmolLM2-135M-Instruct | 34.342 | 2.429 | 23.913 | 10.872 | 50.394 | 1.362 | 64.004 | 37.975 | 45.511 | 1.734 | 30.903 | 24.440 |
🔼 This table presents a comparison of the performance of various Large Language Models (LLMs) when used as the backbone model for stock trading. Seven different stocks (MSFT, JNJ, UVV, HON, TSLA, BTC) were used to assess the models’ performance across four key metrics: Cumulative Return (CR), Sharpe Ratio (SR), Annualized Volatility (AV), and Maximum Drawdown (MDD). The table allows readers to compare the effectiveness of different LLMs, both large and small, in a real-world financial trading task. The results demonstrate the relative strength of different models, showing how their capabilities vary across assets and risk metrics.
read the caption
Table 2: Performance of stock trading with different LLMs as backbone model across seven stocks.
| Parameter | Default Value | Description |
|---|---|---|
| total_timesteps | 13860 | Total number of timesteps |
| learning_rate | Learning rate of optimizer | |
| num_envs | 1 | Number of parallel environments |
| num_steps | 40 | Steps per policy rollout |
| anneal_lr | True | Enable learning rate annealing |
| gamma | 0.95 | Discount factor |
| gae_lambda | 0.98 | Lambda for Generalized Advantage Estimation |
| update_epochs | 1 | Number of update epochs per cycle |
| norm_adv | True | Advantages whitening |
| clip_coef | 0.2 | Surrogate clipping coefficient |
| clip_vloss | True | Clipped loss for value function |
| ent_coef | 0.05 | Coefficient of entropy term |
| vf_coef | 0.5 | Coefficient of value function |
| kl_coef | 0.05 | KL divergence with reference model |
| max_grad_norm | 0.5 | Maximum gradient clipping norm |
| target_kl | None | Target KL divergence threshold |
| dropout | 0.0 | Dropout rate |
| llm | "SmolLM2-135M-Instruct" | Model to fine-tune |
| train_dtype | "float16" | Training data type |
| gradient_accumulation_steps | 8 | Number of gradient accumulation steps |
| minibatch_size | 32 | Mini-batch size for fine-tuning |
| max_episode_steps | 65 | Maximum number of steps per episode |
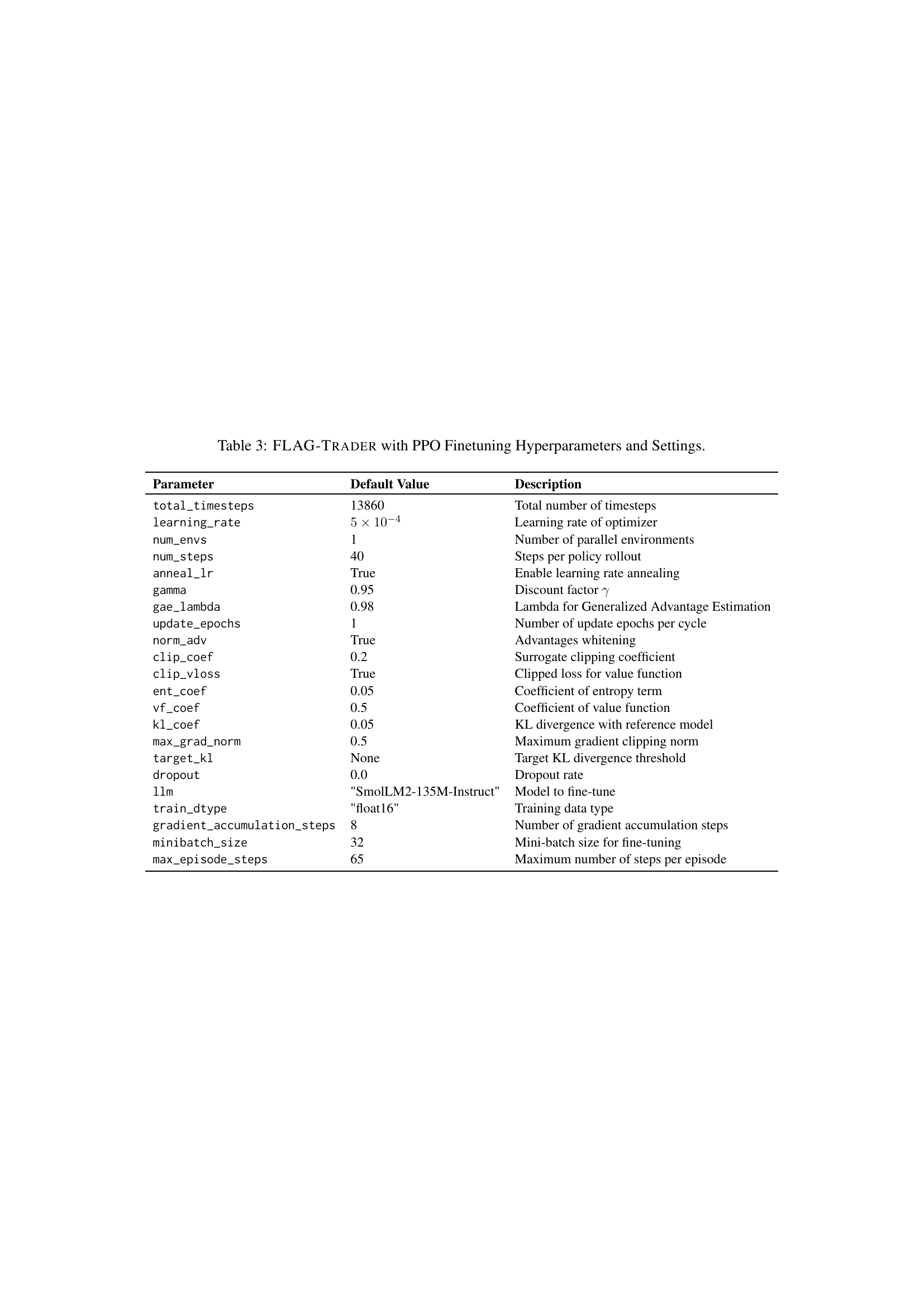
🔼 This table lists the hyperparameters and settings used for fine-tuning the FLAG-TRADER model with the Proximal Policy Optimization (PPO) algorithm. It includes parameters related to the training process, such as the total number of timesteps, learning rate, and steps per policy rollout. It also details parameters specific to PPO, including the discount factor, GAE lambda, and entropy coefficient. Additional settings are provided for gradient accumulation, mini-batch size, and data type.
read the caption
Table 3: FLAG-Trader with PPO Finetuning Hyperparameters and Settings.
Full paper#