TL;DR#
Large Language Models (LLMs) often struggle with complex reasoning during inference, particularly when existing test-time scaling methods accumulate excessive historical information, wasting resources and hindering effective reasoning. This paper introduces Atom of Thoughts (AOT), a novel approach that tackles this problem.
AOT addresses the issue by decomposing complex reasoning tasks into a series of smaller, independent sub-questions—‘atomic questions.’ These sub-questions, similar to transitions in a Markov process, depend primarily on their current state rather than accumulated history. This method is integrated seamlessly with existing scaling methods, enhancing their performance. Experiments across various benchmarks show that AOT significantly improves reasoning capabilities and computational efficiency, achieving state-of-the-art results in several cases.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of existing test-time scaling methods for LLMs: the excessive use of computational resources due to accumulated historical information. AOT offers a novel solution by decomposing complex reasoning tasks into smaller, independent sub-questions, leading to significant efficiency gains without sacrificing accuracy. This opens exciting avenues for research into more efficient and scalable LLM reasoning.
Visual Insights#

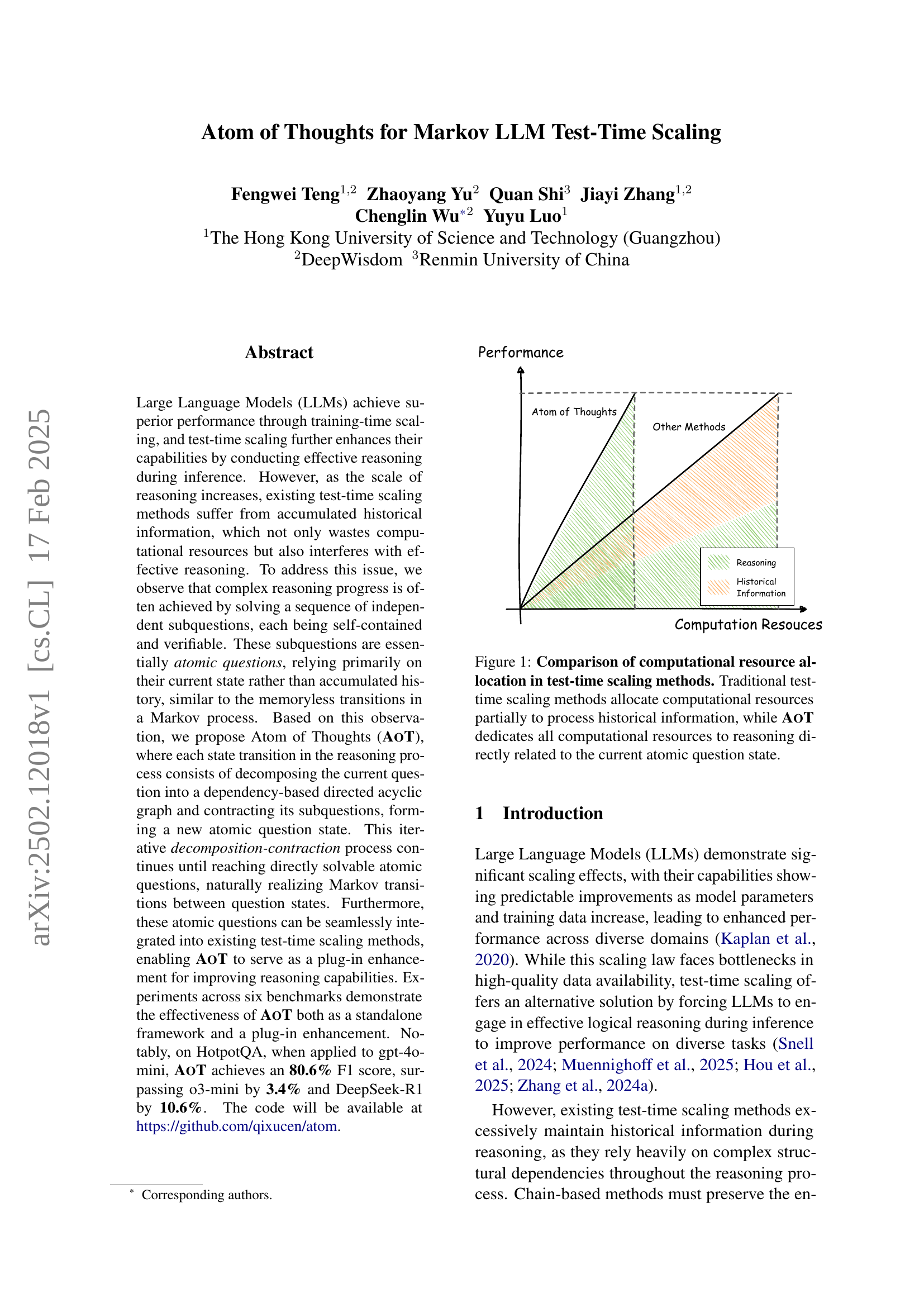
🔼 This figure compares how different test-time scaling methods utilize computational resources. Traditional methods dedicate some resources to processing past reasoning steps (historical information), which can be inefficient and potentially hinder accurate reasoning. In contrast, Atom of Thoughts (AoT) focuses all computational resources on the current reasoning step, treating each step as an independent ‘atomic’ question. This targeted approach aims for improved efficiency and better reasoning outcomes.
read the caption
Figure 1: Comparison of computational resource allocation in test-time scaling methods. Traditional test-time scaling methods allocate computational resources partially to process historical information, while AoT dedicates all computational resources to reasoning directly related to the current atomic question state.
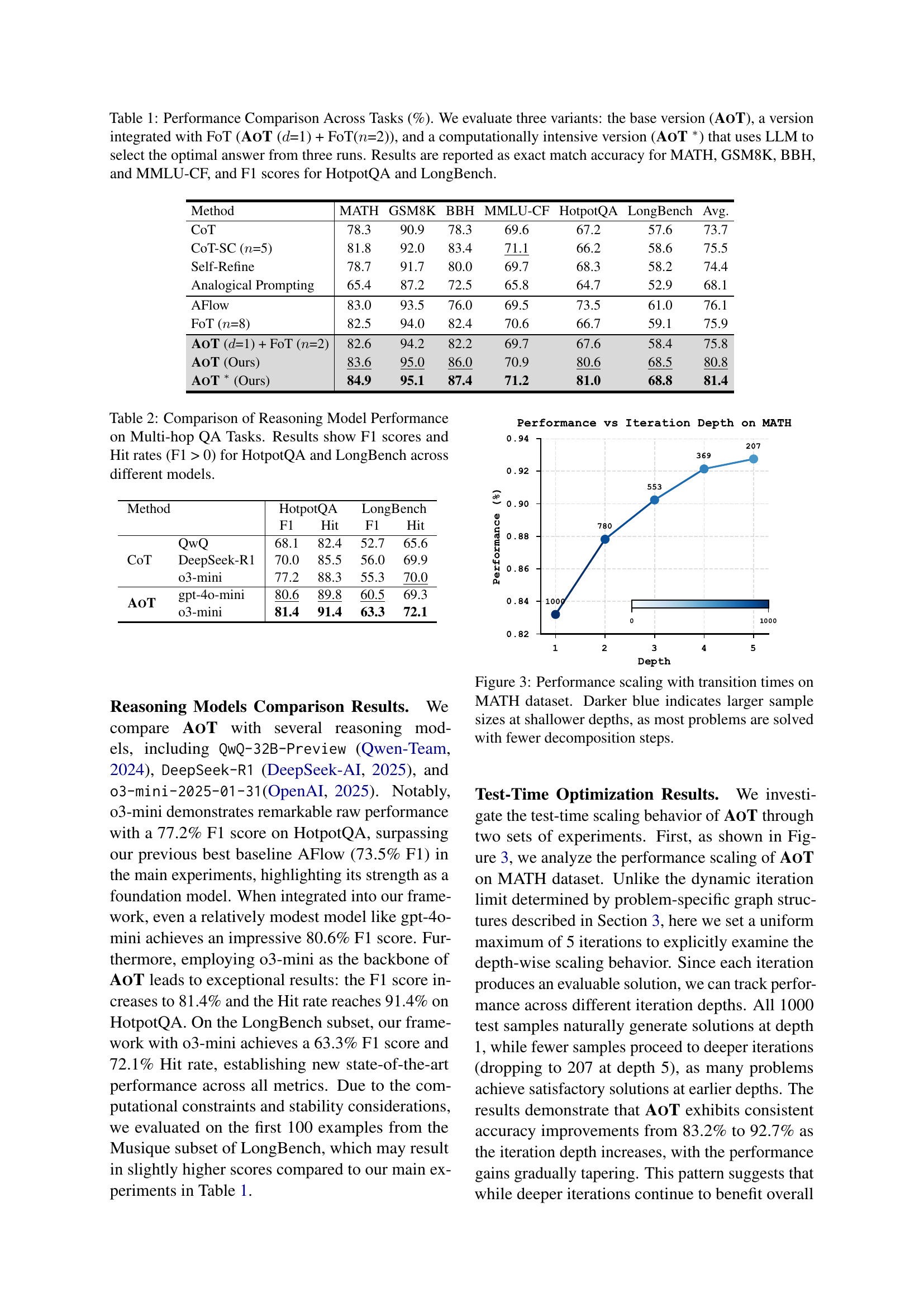
| Method | MATH | GSM8K | BBH | MMLU-CF | HotpotQA | LongBench | Avg. |
|---|---|---|---|---|---|---|---|
| CoT | 78.3 | 90.9 | 78.3 | 69.6 | 67.2 | 57.6 | 73.7 |
| CoT-SC (=5) | 81.8 | 92.0 | 83.4 | 71.1 | 66.2 | 58.6 | 75.5 |
| Self-Refine | 78.7 | 91.7 | 80.0 | 69.7 | 68.3 | 58.2 | 74.4 |
| Analogical Prompting | 65.4 | 87.2 | 72.5 | 65.8 | 64.7 | 52.9 | 68.1 |
| AFlow | 83.0 | 93.5 | 76.0 | 69.5 | 73.5 | 61.0 | 76.1 |
| FoT (=8) | 82.5 | 94.0 | 82.4 | 70.6 | 66.7 | 59.1 | 75.9 |
| AoT (=1) + FoT (=2) | 82.6 | 94.2 | 82.2 | 69.7 | 67.6 | 58.4 | 75.8 |
| AoT (Ours) | 83.6 | 95.0 | 86.0 | 70.9 | 80.6 | 68.5 | 80.8 |
| AoT ∗ (Ours) | 84.9 | 95.1 | 87.4 | 71.2 | 81.0 | 68.8 | 81.4 |
🔼 This table compares the performance of three versions of the Atom of Thoughts (AoT) model across six benchmark datasets. The three AoT versions are: the base version, a version integrated with the Forest of Thoughts (FoT) method, and a computationally intensive version that uses an LLM to select the best answer from three runs. The datasets cover various reasoning tasks: mathematical reasoning (MATH, GSM8K), logical reasoning (BBH), multiple-choice questions (MMLU-CF), and multi-hop reasoning (HotpotQA, LongBench). Performance is measured as exact match accuracy for MATH, GSM8K, BBH, and MMLU-CF, and F1 score for HotpotQA and LongBench.
read the caption
Table 1: Performance Comparison Across Tasks (%). We evaluate three variants: the base version (AoT), a version integrated with FoT (AoT (d𝑑ditalic_d=1) + FoT(n𝑛nitalic_n=2)), and a computationally intensive version (AoT ∗) that uses LLM to select the optimal answer from three runs. Results are reported as exact match accuracy for MATH, GSM8K, BBH, and MMLU-CF, and F1 scores for HotpotQA and LongBench.
In-depth insights#
Markov Test-Time#
A hypothetical ‘Markov Test-Time’ section in a research paper would likely explore the application of Markov models to enhance the efficiency and reasoning capabilities of large language models (LLMs) during inference. This approach would focus on modeling the LLM’s reasoning process as a sequence of states, where each state represents a particular stage of inference, and transitions between states follow Markovian properties (memorylessness). The key advantage would be the reduction of computational cost associated with traditional methods that maintain extensive reasoning histories. By focusing only on the current state, the Markov approach potentially reduces memory usage and speeds up processing. The core concept would involve decomposing complex reasoning tasks into simpler, independent subtasks. Each subtask would represent a state in the Markov chain, allowing for parallel processing and potentially minimizing the accumulation of irrelevant information. However, challenges might involve the design of effective state representations and the selection of appropriate transition probabilities to accurately reflect the LLM’s reasoning process. The evaluation would likely involve comparisons to existing methods across various benchmarks, demonstrating the trade-offs between computational efficiency and accuracy. Overall, a ‘Markov Test-Time’ approach promises significant improvements in LLM scaling, but careful design and thorough evaluation are crucial for its successful implementation.
Atomic Thoughts#
The concept of “Atomic Thoughts” introduces a novel approach to large language model (LLM) reasoning. It posits that complex reasoning tasks can be broken down into a sequence of independent, self-contained “atomic” sub-questions. This decomposition, akin to a Markov process, eliminates the need to retain and process extensive historical information, a significant advantage over traditional methods that struggle with computational cost and interference from accumulated data. By focusing on the current atomic question’s state, Atomic Thoughts improves reasoning efficiency and reduces resource waste. The framework’s flexibility allows for seamless integration with existing test-time scaling techniques, acting as a plug-in enhancement rather than a complete replacement. This modular design and Markov property are key strengths, enabling efficient scaling and enhanced performance across various reasoning benchmarks. The core innovation lies in managing the decomposition and contraction of sub-questions using dependency-based directed acyclic graphs (DAGs), ensuring that each step relies primarily on the immediately preceding state, thus realizing the Markov property. While promising, further research is needed to address limitations in the robustness of the DAG-based decomposition and the framework’s assumption of independent sub-questions.
DAG Decomposition#
The core idea behind “DAG Decomposition” is to break down complex reasoning problems into smaller, more manageable subproblems, represented as nodes in a Directed Acyclic Graph (DAG). This decomposition leverages the inherent structure of the problem to improve efficiency and reduce the computational burden associated with traditional methods that rely on maintaining extensive historical information. The DAG structure ensures that each subproblem depends only on previously solved ones, naturally leading to a more efficient, Markovian reasoning process. This decomposition step is crucial, as it forms the foundation for the subsequent contraction phase, enabling the iterative refinement and simplification of the original problem until a directly solvable state is reached. The careful construction of the DAG, ensuring acyclicity and representing dependencies accurately, is critical for the overall success and efficiency of the method. The effectiveness of this method hinges on the ability of an LLM to correctly decompose the problem into meaningful subproblems, which underscores the need for robust and accurate dependency identification techniques.
AOT Integration#
The concept of AOT integration centers on the seamless incorporation of Atom of Thoughts (AOT) into existing test-time scaling methods. AOT’s modular design allows it to function as both a standalone framework and a plug-in enhancement. This flexibility is crucial because it allows researchers to leverage AOT’s strengths (efficient decomposition and contraction of complex questions into atomic units) while simultaneously benefiting from the capabilities of established test-time scaling approaches like Chain-of-Thought or Tree of Thoughts. The integration process often involves using AOT’s output (the simplified atomic questions) as input for another method, thereby optimizing resource allocation and ensuring answer equivalence. This plug-and-play functionality is a significant advantage, facilitating broader adoption and enhancing the overall reasoning capabilities of LLMs. A successful AOT integration significantly reduces computational costs associated with processing historical information, enabling more efficient and effective large-language model reasoning.
Future of AOT#
The future of Atom of Thoughts (AOT) hinges on addressing its current limitations and exploring new avenues for improvement. Improving the robustness of the DAG decomposition is crucial, potentially through incorporating mechanisms for detecting and correcting faulty decompositions or utilizing more advanced graph representation techniques. Integrating AOT with other reasoning frameworks will be essential. Seamless integration with existing test-time scaling methods like Tree of Thoughts or Chain-of-Thought would offer a significant advantage. Extending AOT’s applicability beyond current benchmarks to diverse problem domains such as common sense reasoning, visual reasoning, or complex scientific reasoning requires further investigation. Finally, exploring the use of different LLM architectures alongside AOT presents an exciting area for future research. By incorporating more powerful LLMs, it may be possible to further enhance the reasoning abilities of the system and handle more complex tasks. Overall, the future of AOT looks promising, promising to enhance the efficiency and effectiveness of large language models in various reasoning tasks.
More visual insights#
More on figures
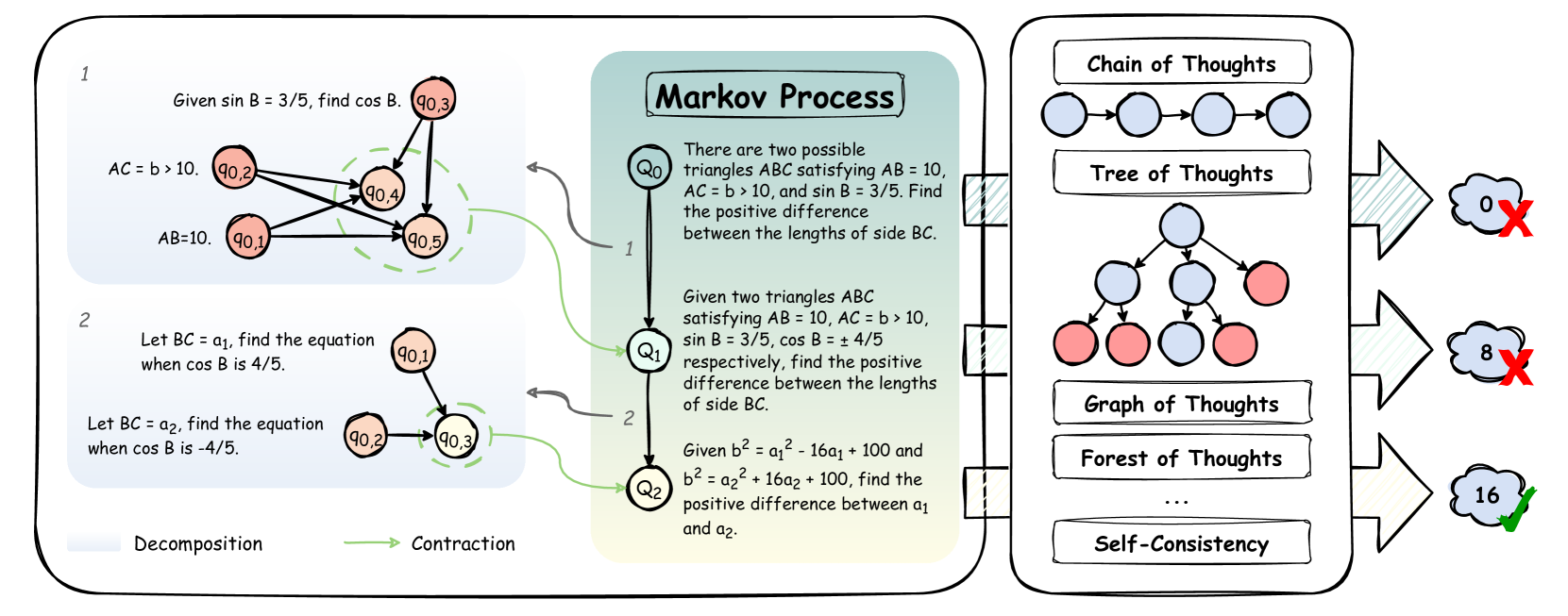
🔼 Figure 2 illustrates the Atom of Thoughts (AoT) framework. The left side shows how AoT uses a Markov process, where each state represents a simplified sub-problem (atomic question) derived from the previous state through a decomposition and contraction process. This process continues until the problem is broken down into easily solvable atomic questions. The right side shows that AoT can be integrated with existing test-time scaling methods (like Chain of Thoughts and Tree of Thoughts). Any intermediate state in AoT’s Markov process can be used as a starting point for other methods, allowing for flexible combination while ensuring the final answer remains consistent. AoT is designed to be used either as a stand-alone framework or as a pre-processing module to improve the reasoning capability of other methods.
read the caption
Figure 2: The overview of AoT. The left portion illustrates our Markov process where each state Qisubscript𝑄𝑖Q_{i}italic_Q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represents an atomic reasoning state derived through DAG decomposition and contraction from its predecessor. The right portion demonstrates AoT’s integration capability with existing test-time scaling methods (e.g., CoT, ToT). A key feature of this integration is that any intermediate state Qisubscript𝑄𝑖Q_{i}italic_Q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT from our Markov process can serve as an entry point (Q0subscript𝑄0Q_{0}italic_Q start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT) for other methods, enabling flexible composition while maintaining answer equivalence with the original question. This design allows AoT to function both as a standalone iterative framework and as a preprocessing module that can enhance existing approaches through structural optimization.

🔼 This figure illustrates how the performance of the Atom of Thoughts (AOT) model scales with the number of reasoning steps (depth) on the MATH dataset. The x-axis represents the depth of the reasoning process, and the y-axis shows the model’s accuracy. The color intensity (darker blue) corresponds to the number of data points at each depth; darker shades indicate a larger number of problems solved at that depth. The graph demonstrates that while performance continues to improve with more reasoning steps, a significant portion of problems can be solved efficiently with relatively few steps, highlighting the efficiency of AOT.
read the caption
Figure 3: Performance scaling with transition times on MATH dataset. Darker blue indicates larger sample sizes at shallower depths, as most problems are solved with fewer decomposition steps.

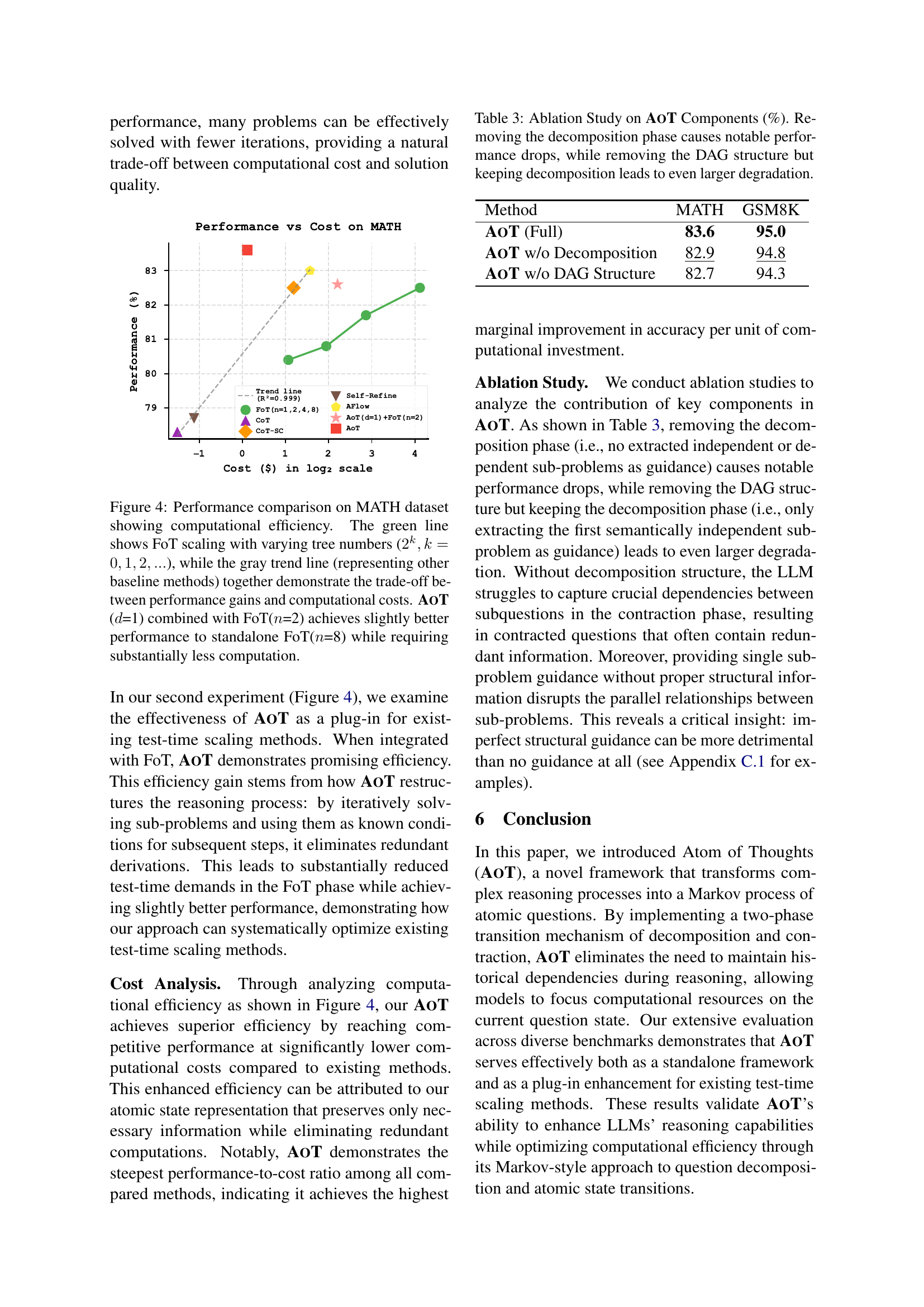
🔼 Figure 4 illustrates the computational efficiency of Atom of Thoughts (AOT) in comparison to other reasoning methods on the MATH dataset. The x-axis represents the computational cost (log scale), and the y-axis represents the accuracy. The green line shows the performance of the Forest of Thoughts (FoT) method with varying numbers of trees (2^k, where k = 0, 1, 2…). The gray trend line represents the performance of other baseline methods. The figure demonstrates that AOT, when combined with FoT, achieves slightly better accuracy than FoT alone while using significantly less computation.
read the caption
Figure 4: Performance comparison on MATH dataset showing computational efficiency. The green line shows FoT scaling with varying tree numbers (2k,k=0,1,2,…formulae-sequencesuperscript2𝑘𝑘012…2^{k},k=0,1,2,...2 start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT , italic_k = 0 , 1 , 2 , …), while the gray trend line (representing other baseline methods) together demonstrate the trade-off between performance gains and computational costs. AoT (d𝑑ditalic_d=1) combined with FoT(n𝑛nitalic_n=2) achieves slightly better performance to standalone FoT(n𝑛nitalic_n=8) while requiring substantially less computation.

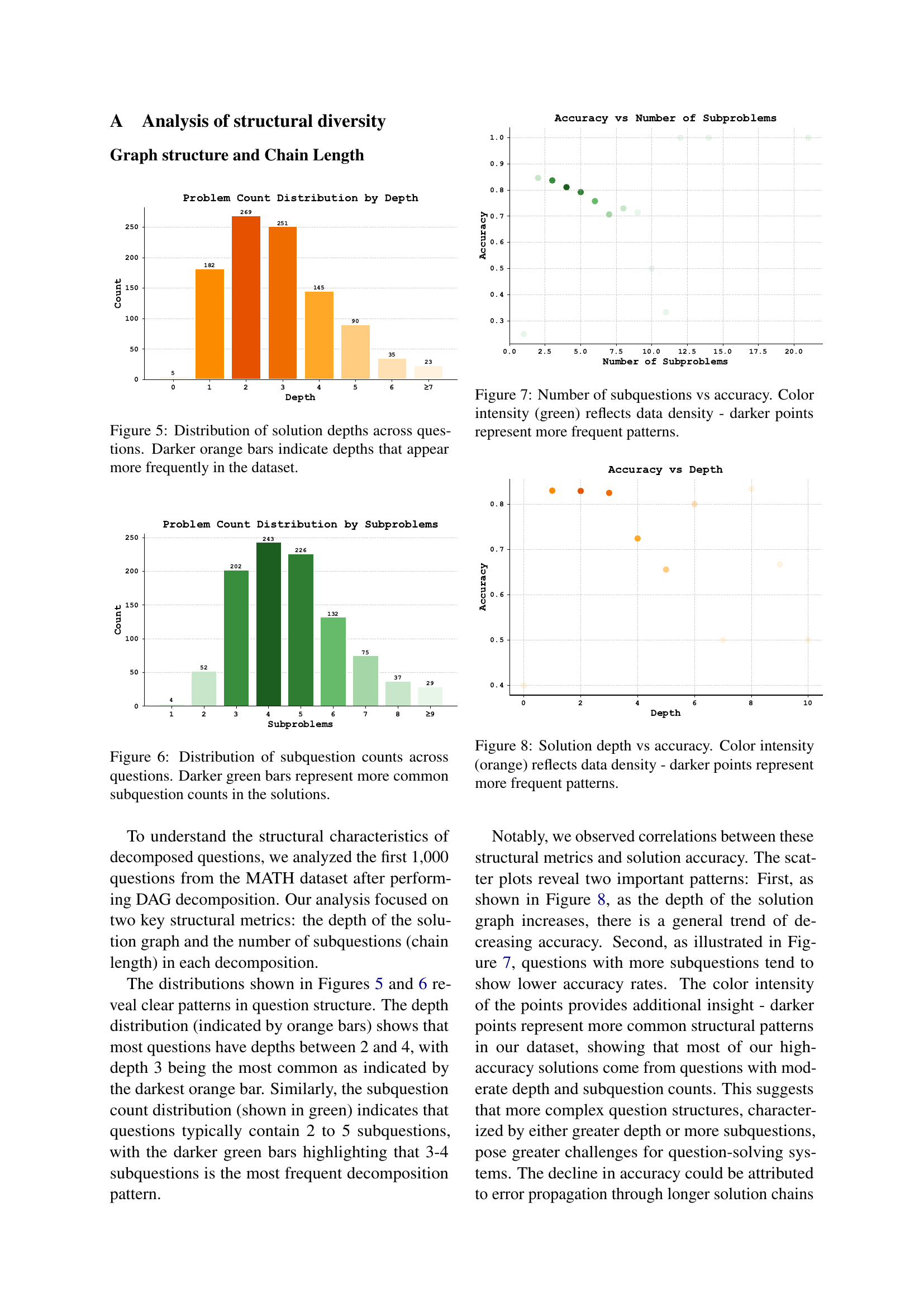
🔼 This figure displays a histogram showing the frequency distribution of solution depths across a set of questions. The x-axis represents the depth of the solution, and the y-axis represents the number of questions with that solution depth. Darker shades of orange indicate that a particular depth occurred more frequently in the dataset.
read the caption
Figure 5: Distribution of solution depths across questions. Darker orange bars indicate depths that appear more frequently in the dataset.

🔼 This bar chart visualizes the frequency distribution of the number of subquestions generated during the decomposition phase of the Atom of Thoughts (AOT) framework, for each question in the MATH dataset. The x-axis represents the count of subquestions, and the y-axis shows the number of questions resulting in that specific subquestion count. The darker the green color of a bar, the more frequently that particular subquestion count appears in the solutions.
read the caption
Figure 6: Distribution of subquestion counts across questions. Darker green bars represent more common subquestion counts in the solutions.

🔼 This figure illustrates the relationship between the number of subquestions generated during the decomposition phase of the Atom of Thoughts (AOT) framework and the accuracy of the final answers. The x-axis represents the number of subquestions, and the y-axis represents the accuracy. Each point represents a question from the dataset. The color intensity of the points indicates the frequency of occurrence of that particular combination of subquestion count and accuracy; darker points signify more frequent patterns in the data. This visualization helps in understanding how the complexity of question decomposition, as measured by the number of subquestions, affects the overall accuracy of the AOT framework.
read the caption
Figure 7: Number of subquestions vs accuracy. Color intensity (green) reflects data density - darker points represent more frequent patterns.

🔼 Figure 8 visualizes the correlation between the depth of the solution graph (number of reasoning steps) and the accuracy of the solution. The x-axis represents the solution depth, while the y-axis shows the accuracy. The color intensity of the data points indicates data density; darker points represent more frequently observed combinations of depth and accuracy. The figure reveals a trend of decreasing accuracy as the depth increases, suggesting that more complex reasoning processes (deeper graphs) are more prone to errors.
read the caption
Figure 8: Solution depth vs accuracy. Color intensity (orange) reflects data density - darker points represent more frequent patterns.
More on tables
| Method | HotpotQA | LongBench | |||
|---|---|---|---|---|---|
| F1 | Hit | F1 | Hit | ||
| CoT | QwQ | 68.1 | 82.4 | 52.7 | 65.6 |
| DeepSeek-R1 | 70.0 | 85.5 | 56.0 | 69.9 | |
| o3-mini | 77.2 | 88.3 | 55.3 | 70.0 | |
| AoT | gpt-4o-mini | 80.6 | 89.8 | 60.5 | 69.3 |
| o3-mini | 81.4 | 91.4 | 63.3 | 72.1 | |
🔼 This table compares the performance of different reasoning models on two multi-hop question answering datasets: HotpotQA and LongBench. For each model, it shows the F1 score (a measure of accuracy that considers both precision and recall) and the hit rate (the percentage of questions where the model produced at least one non-zero F1 score). The comparison helps to assess the effectiveness of various reasoning models on complex questions requiring multiple reasoning steps to find the answer.
read the caption
Table 2: Comparison of Reasoning Model Performance on Multi-hop QA Tasks. Results show F1 scores and Hit rates (F1 > 0) for HotpotQA and LongBench across different models.
| Method | MATH | GSM8K |
|---|---|---|
| AoT (Full) | 83.6 | 95.0 |
| AoT w/o Decomposition | 82.9 | 94.8 |
| AoT w/o DAG Structure | 82.7 | 94.3 |
🔼 This ablation study analyzes the impact of removing key components from the Atom of Thoughts (AoT) framework on its performance. The table shows that removing the decomposition phase significantly reduces performance, while removing the DAG structure while retaining the decomposition phase leads to an even greater decrease in performance. This demonstrates the importance of both the decomposition and DAG structure to the effectiveness of AoT.
read the caption
Table 3: Ablation Study on AoT Components (%). Removing the decomposition phase causes notable performance drops, while removing the DAG structure but keeping decomposition leads to even larger degradation.
Full paper#