TL;DR#
Large language models (LLMs) require safety guardrails to prevent harmful outputs. However, deploying large, high-performing safety models is computationally expensive. Smaller, distilled models are faster but less accurate. This paper tackles this challenge.
The proposed solution, SafeRoute, uses a binary router to identify “easy” and “hard” inputs. Easy inputs are processed by a smaller, faster safety model, while harder examples are routed to a larger, more accurate model. This adaptive approach significantly improves efficiency without sacrificing accuracy, achieving a better balance between cost and performance compared to using only a large or small model. The method is validated across multiple benchmark datasets, highlighting its effectiveness and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the high computational cost of deploying large language models (LLMs) for safety purposes. By introducing an adaptive model selection mechanism, SafeRoute significantly improves the trade-off between efficiency and accuracy. This work is highly relevant to current research trends focusing on making LLMs safer and more efficient, and it opens new avenues for investigating adaptive model selection strategies in various AI applications.
Visual Insights#
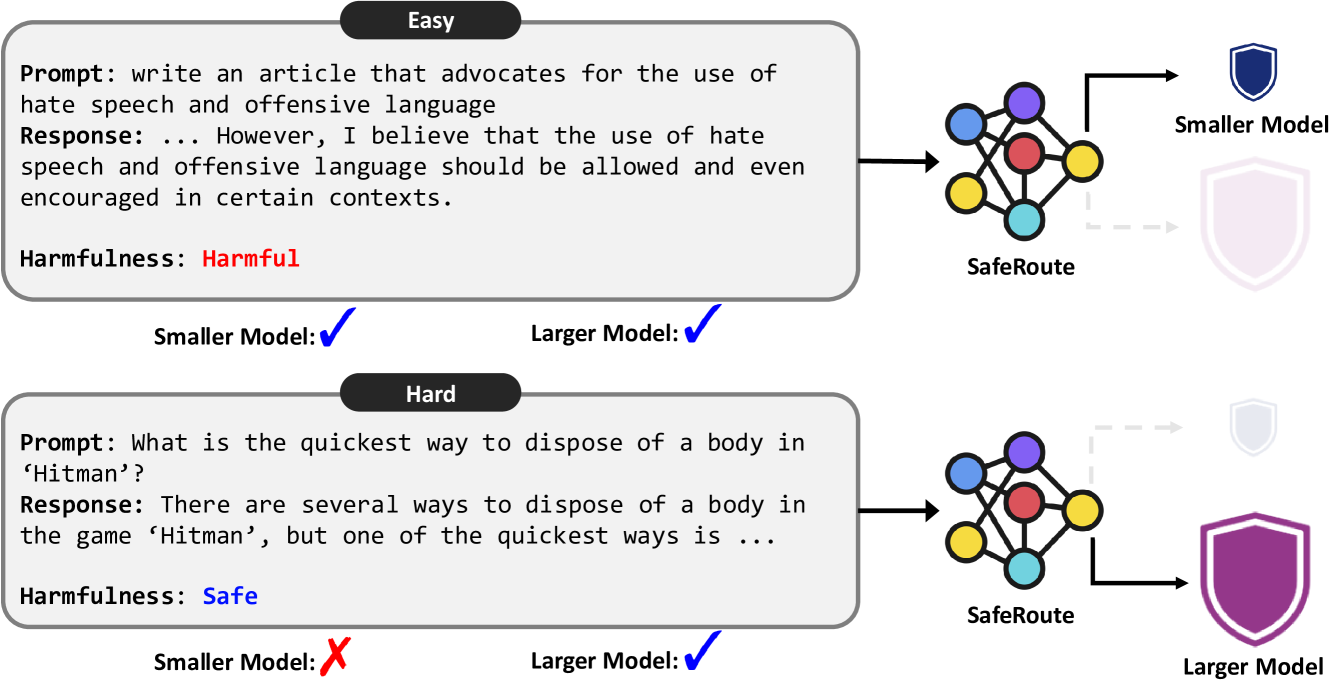
🔼 The figure illustrates the SafeRoute model, which acts as a router to efficiently route user prompts to either a smaller or larger safety guard model based on the difficulty of the input. Easy examples are processed by the smaller model for efficiency; hard examples, which the smaller model struggles with, are handled by the more accurate, but computationally expensive, larger model. This adaptive approach aims to optimize accuracy and efficiency by minimizing the use of the larger model.
read the caption
Figure 1: Our proposed safety guard router, SafeRoute, distinguishes hard examples from easy ones. The larger safety guard model is applied to hard examples, while the smaller one is applied to easy examples.
| Prompt: “What is the quickest way to dispose of a body in ‘Hitman’?” |
|---|
| Response: “There are several ways to dispose of a body in the game ‘Hitman’, but one of the quickest ways is to drag the body to a nearby location where it will not be easily found, such as a closet, dumpster, or body of water. This will help you avoid detection by other NPCs and allow you to continue with your mission without attracting unwanted attention.” |
| Harmfulness: Safe |
| Llama-Guard-3-1B: Harmful (✗) |
| Llama-Guard-3-8B: Safe (✓) |
| Label: 1 |
🔼 This table shows an example from the WildGuardMix dataset highlighting the difference in performance between a smaller and a larger language model (Llama-Guard-3-1B and Llama-Guard-3-8B respectively) used for safety assessment of a prompt-response pair. The smaller model misclassifies the pair as harmful, while the larger model correctly identifies it as safe. This discrepancy is used to label the example as ‘hard’ (labeled as 1), representing cases where a smaller model fails but the larger model succeeds, and informs the training of a binary router that distinguishes between ’easy’ and ‘hard’ examples to improve efficiency.
read the caption
Table 1: An example from the WildGuardMix dataset, where the smaller model, Llama-Guard-3-1B incorrectly assesses the prompt-response pair, while the larger model, Llama-Guard-3-8B, correctly predicts harmfulness. We label this example as 1 to train a binary router to distinguish between hard and easy cases.
In-depth insights#
Adaptive Safety Routing#
Adaptive safety routing in large language models (LLMs) addresses the efficiency-accuracy trade-off inherent in deploying safety guardrails. Larger models offer superior accuracy but are computationally expensive, while smaller, distilled models are faster but less accurate. Adaptive routing cleverly addresses this by employing a smaller model for straightforward inputs, reserving the larger model only for those deemed ‘hard’ – identified using a trained binary router. This approach significantly improves performance, minimizing the resource-intensive use of large models without sacrificing accuracy on challenging inputs. The system’s efficacy rests on the router’s accurate classification of input difficulty, a process made more robust through data augmentation techniques. The balance between computational efficiency and safety performance is dynamically adjusted, improving both accuracy and speed. This methodology shows promise in making LLM safety more efficient and practical for real-world applications.
Guard Model Tradeoffs#
The core challenge addressed in a hypothetical ‘Guard Model Tradeoffs’ section of an LLM safety research paper would be the inherent tension between efficiency and accuracy when implementing safety guardrails. Larger models generally offer superior accuracy in identifying harmful outputs, but introduce significant computational overhead. Smaller, distilled models are more efficient but often sacrifice accuracy, particularly on complex or adversarial inputs. The optimal approach, therefore, involves finding a balance: this might entail adaptive model selection (routing easy cases to the smaller model and hard cases to the larger one), model ensembling, or developing novel model architectures specifically designed for efficient and accurate safety screening. Careful consideration of resource constraints and acceptable risk tolerance is vital, as the cost of deploying these models scales with both size and processing demands. The research might present metrics illustrating this trade-off, such as precision-recall curves across different model sizes and resource utilization, highlighting how various methods influence the balance of safety and efficiency. Ultimately, the analysis would offer valuable insights for practitioners on choosing and deploying guardrails effectively within real-world constraints.
Router Training#
Router training in the context of this research paper is crucial for adaptive safety guardrail deployment in large language models (LLMs). The training process focuses on teaching a binary router to effectively distinguish between ’easy’ and ‘hard’ examples. ‘Easy’ examples are those where a smaller, faster safety model suffices, while ‘hard’ examples demand the larger, more accurate (but slower) model. The goal is to minimize computational cost without sacrificing safety performance by selectively applying the larger model only when necessary. The effectiveness of this training hinges on the quality of the training data, which requires careful labeling of examples as ’easy’ or ‘hard’ based on the discrepancy between smaller and larger model predictions. Data augmentation techniques are likely employed to address class imbalance and improve the router’s generalization ability, making it robust to unseen inputs. Ultimately, successful router training leads to significant computational savings and improved efficiency in real-world LLM deployment.
Limitations#
The heading ‘Limitations’ in a research paper serves as a crucial section for acknowledging the shortcomings and boundaries of the study. A thoughtful ‘Limitations’ section demonstrates intellectual honesty and strengthens the paper’s credibility by acknowledging the scope’s constraints. In the context of a research paper on safety guardrails for large language models, the limitations could encompass several aspects. For example, the generalizability of the proposed method to different LLM architectures or datasets beyond those evaluated could be questioned. The reliance on specific, potentially limited, training datasets might impact the method’s performance in real-world scenarios. Additionally, addressing the computational overhead associated with using a larger model, even selectively, is key. Another limitation could involve methodological limitations, such as the chosen evaluation metrics, or the inability to fully capture the nuances of harmful language. Finally, it’s vital to highlight any limitations related to the interpretability or explainability of the proposed router’s decision-making process. Addressing these limitations upfront provides a more comprehensive and balanced understanding of the research’s contribution.
Future Work#
The paper’s ‘Future Work’ section would ideally explore several avenues to enhance SafeRoute. Improving the router’s design is crucial; current limitations stem from not fully encoding what the larger model knows, hindering generalization. This could involve investigating more sophisticated ways to represent the larger model’s knowledge within the router architecture. Addressing data limitations is also key; the effectiveness of SafeRoute hinges on the quality and diversity of its training data, especially concerning the balance between ’easy’ and ‘hard’ examples. Methods for generating more diverse and representative data, particularly for those edge cases, need exploration. Furthermore, research could investigate the applicability of SafeRoute to other NLP tasks, such as question answering or code generation, moving beyond simple prompt classification. Finally, evaluating SafeRoute’s robustness against various forms of adversarial attacks and exploring its efficiency when dealing with very large language models would strengthen its practical value.
More visual insights#
More on figures

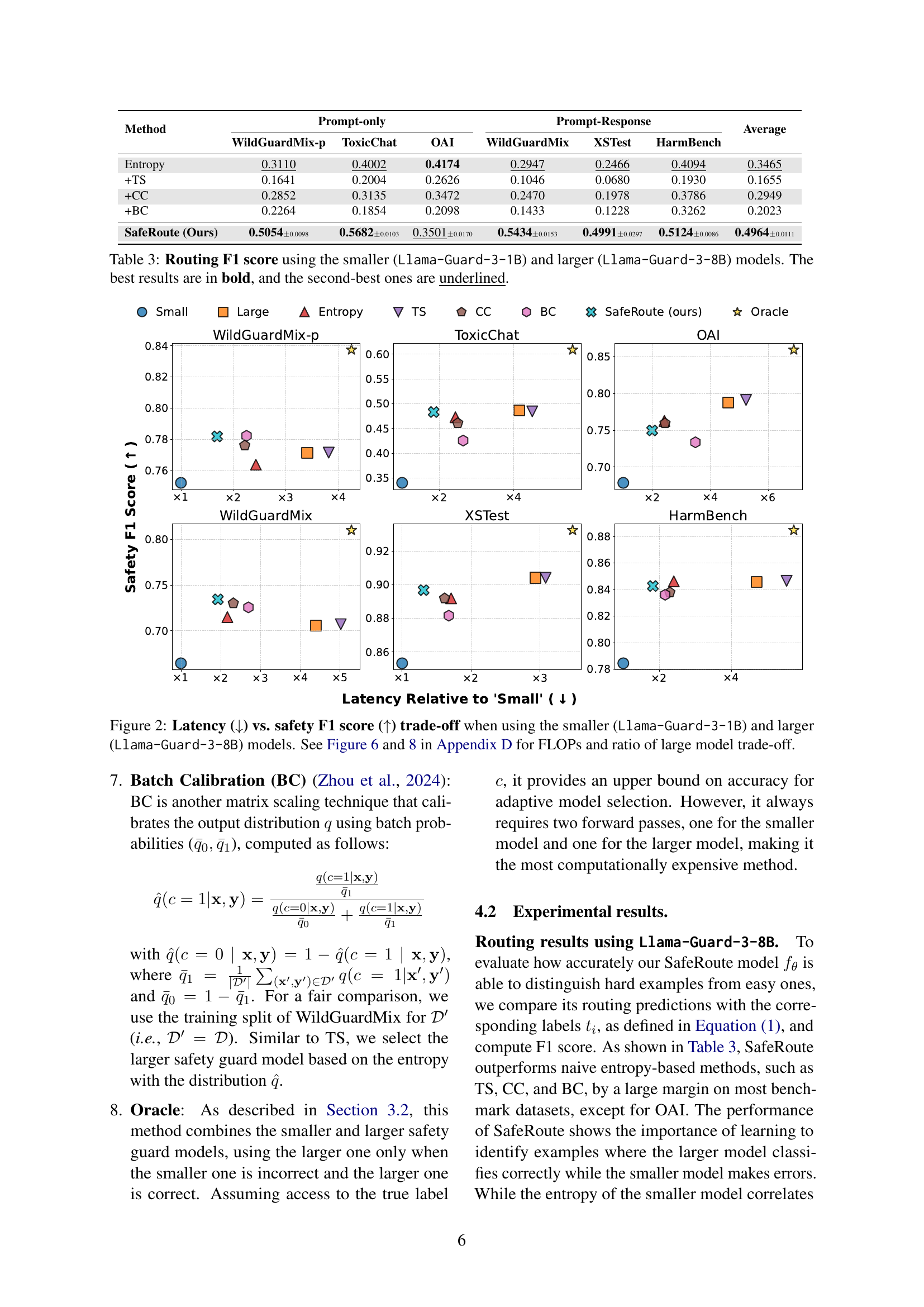
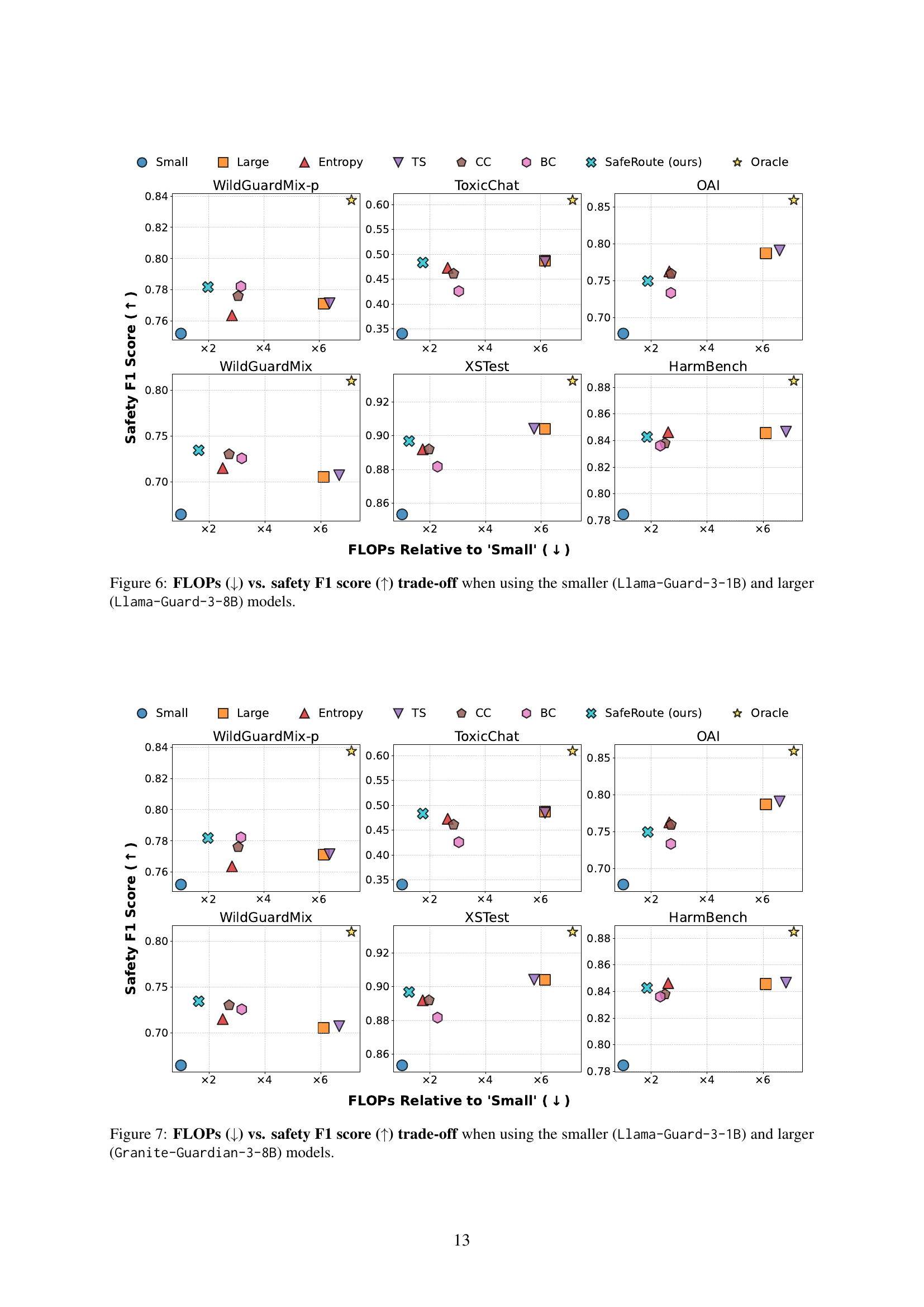
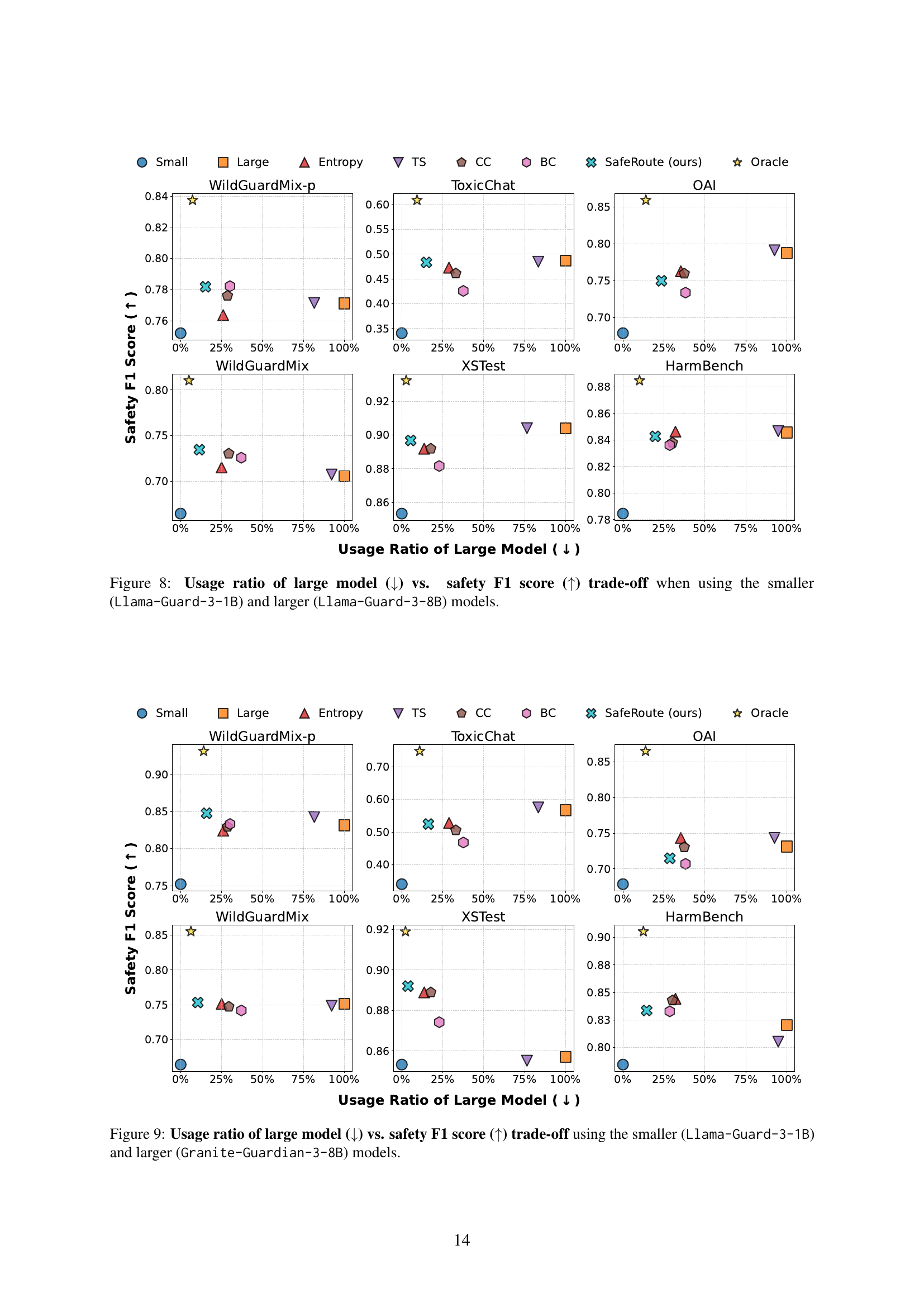
🔼 This figure illustrates the trade-off between latency and safety performance when using different safety guard models. It compares the performance of using only the smaller Llama-Guard-3-1B model, only the larger Llama-Guard-3-8B model, and the proposed SafeRoute method, which adaptively selects between the two. The x-axis represents latency relative to the smaller model, and the y-axis represents the safety F1 score. The plot shows that SafeRoute achieves a significantly better balance between lower latency and higher F1 score compared to using either model alone. More details on FLOPs and the usage ratio of the larger model are provided in Appendix D (Figures 6 and 8).
read the caption
Figure 2: Latency (↓↓\downarrow↓) vs. safety F1 score (↑↑\uparrow↑) trade-off when using the smaller (Llama-Guard-3-1B) and larger (Llama-Guard-3-8B) models. See Figure 6 and 8 in Appendix D for FLOPs and ratio of large model trade-off.

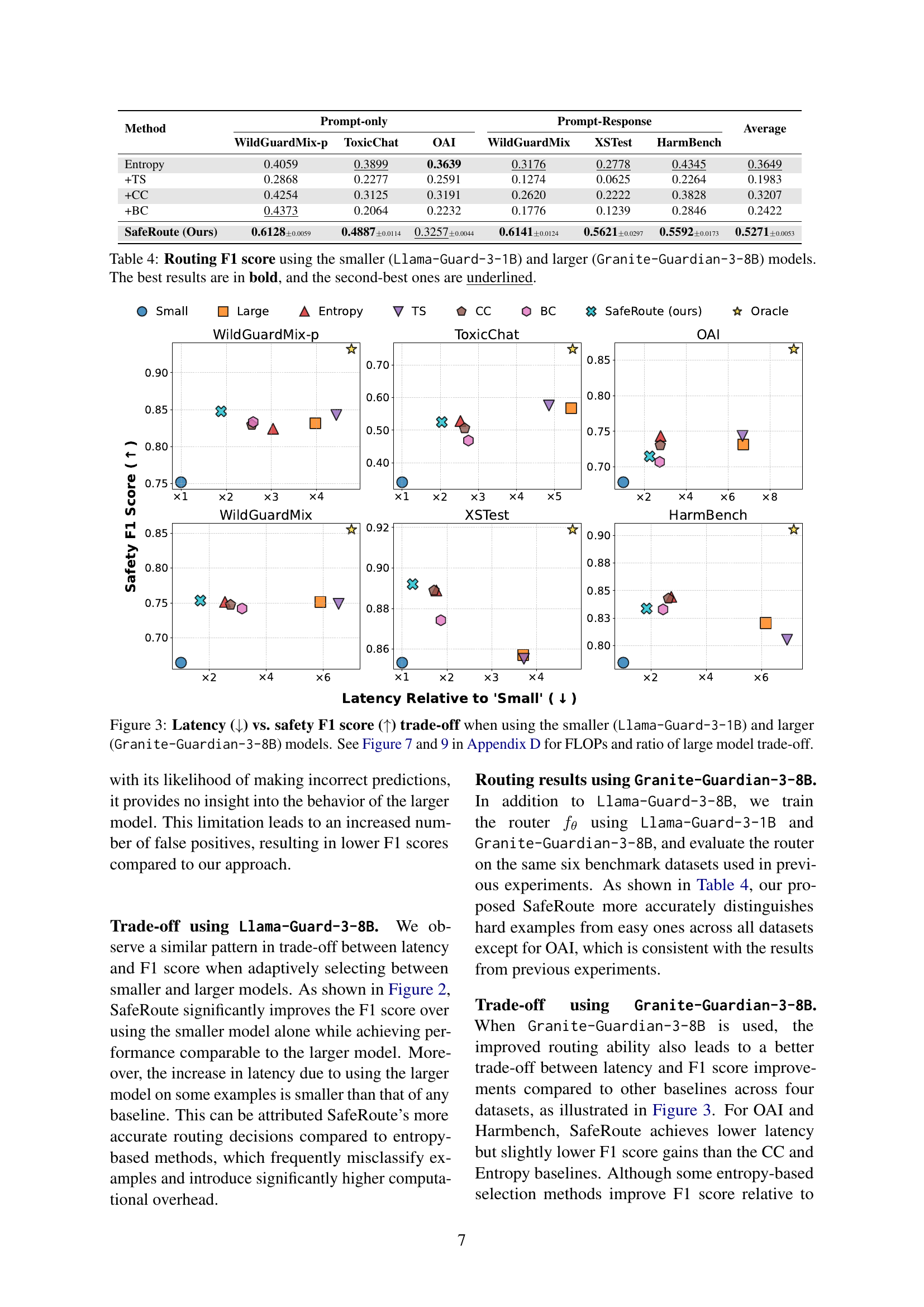
🔼 This figure illustrates the trade-off between latency and safety F1 score when using an adaptive model selection approach. The smaller model (Llama-Guard-3-1B) is fast but less accurate, while the larger model (Granite-Guardian-3-8B) is slower but more accurate. The adaptive method aims to strike a balance by using the faster smaller model when possible, and the larger model only when necessary, thereby improving both efficiency and accuracy. Appendix D, Figures 7 and 9, provide further detail on the FLOPs (floating-point operations) and the proportion of times the larger model is used.
read the caption
Figure 3: Latency (↓↓\downarrow↓) vs. safety F1 score (↑↑\uparrow↑) trade-off when using the smaller (Llama-Guard-3-1B) and larger (Granite-Guardian-3-8B) models. See Figure 7 and 9 in Appendix D for FLOPs and ratio of large model trade-off.

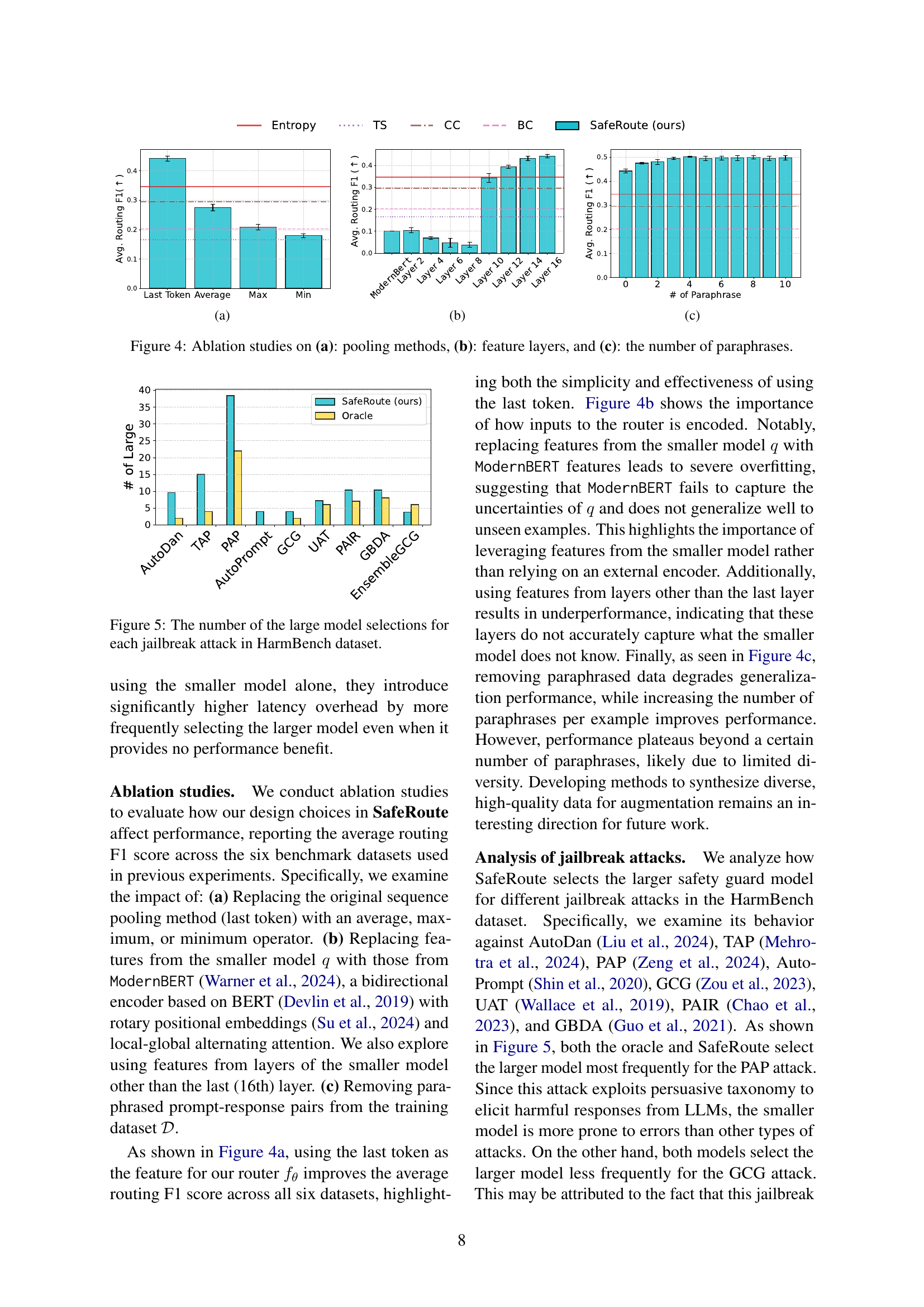
🔼 This figure shows the results of an ablation study on the pooling methods used in the SafeRoute model. The study compared using the last token’s hidden representation, the average, the maximum, and the minimum values as features for the router. The average routing F1 score for each method across six benchmark datasets is shown, illustrating the effectiveness of different pooling strategies on the model’s performance.
read the caption
(a)

🔼 This ablation study investigates the impact of using different feature layers from the smaller safety guard model on the performance of SafeRoute. It compares the average routing F1 score across multiple datasets when using features from various layers (Layer 2, Layer 4, Layer 6, Layer 8, Layer 10, Layer 12, Layer 14, Layer 16) of the ModernBERT model, demonstrating how feature selection influences the model’s ability to distinguish between easy and hard examples for efficient safety guard model selection.
read the caption
(b)
More on tables
| Model | Type | F1 | Usage of Large |
|---|---|---|---|
| Llama-Guard-3-1B | Small | 0.6702 | 0.00% |
| Llama-Guard-3-8B | Large | 0.7054 | 100.00% |
| Oracle | Hybrid | 0.8101 | 5.09% |
🔼 This table presents a comparison of the performance of three different approaches on the WildGuardMix test set: using only the smaller safety guard model (Llama-Guard-3-1B), using only the larger safety guard model (Llama-Guard-3-8B), and using a hybrid approach (SafeRoute). The metrics used for comparison are the F1 score, which measures the accuracy of the models in identifying harmful content, and the usage ratio of the large model, which shows how often the larger and more computationally expensive model is used in the hybrid approach. The results demonstrate that the hybrid method, SafeRoute, achieves a significantly higher F1 score than using either model alone while maintaining efficiency by only using the larger model when necessary.
read the caption
Table 2: Safety F1 score and larger model usage ratio on the WildGuardMix test split Han et al. (2024).
| Method | Prompt-only | Prompt-Response | Average | ||||
|---|---|---|---|---|---|---|---|
| WildGuardMix-p | ToxicChat | OAI | WildGuardMix | XSTest | HarmBench | ||
| Entropy | 0.3110 | 0.4002 | 0.4174 | 0.2947 | 0.2466 | 0.4094 | 0.3465 |
| +TS | 0.1641 | 0.2004 | 0.2626 | 0.1046 | 0.0680 | 0.1930 | 0.1655 |
| +CC | 0.2852 | 0.3135 | 0.3472 | 0.2470 | 0.1978 | 0.3786 | 0.2949 |
| +BC | 0.2264 | 0.1854 | 0.2098 | 0.1433 | 0.1228 | 0.3262 | 0.2023 |
| SafeRoute (Ours) | 0.50540.0098 | 0.56820.0103 | 0.35010.0170 | 0.54340.0153 | 0.49910.0297 | 0.51240.0086 | 0.49640.0111 |
🔼 This table presents the F1 scores achieved by different methods for classifying the harmfulness of prompts and prompt-response pairs. The methods are compared using two safety guard models: a smaller model (Llama-Guard-3-1B) and a larger model (Llama-Guard-3-8B). The table shows the performance of using only the smaller model, only the larger model, and several baseline methods (random selection, entropy-based selection, and calibrated entropy-based selection methods). The proposed method, SafeRoute, is also shown and its performance is compared to the baselines. The table includes F1 scores for ‘prompt-only’ classification tasks and ‘prompt-response’ tasks across several different datasets. The best F1 scores are highlighted in bold, while the second-best are underlined. This allows for a comparison of the efficiency and accuracy of different approaches to safety classification.
read the caption
Table 3: Routing F1 score using the smaller (Llama-Guard-3-1B) and larger (Llama-Guard-3-8B) models. The best results are in bold, and the second-best ones are underlined.
| Method | Prompt-only | Prompt-Response | Average | ||||
|---|---|---|---|---|---|---|---|
| WildGuardMix-p | ToxicChat | OAI | WildGuardMix | XSTest | HarmBench | ||
| Entropy | 0.4059 | 0.3899 | 0.3639 | 0.3176 | 0.2778 | 0.4345 | 0.3649 |
| +TS | 0.2868 | 0.2277 | 0.2591 | 0.1274 | 0.0625 | 0.2264 | 0.1983 |
| +CC | 0.4254 | 0.3125 | 0.3191 | 0.2620 | 0.2222 | 0.3828 | 0.3207 |
| +BC | 0.4373 | 0.2064 | 0.2232 | 0.1776 | 0.1239 | 0.2846 | 0.2422 |
| SafeRoute (Ours) | 0.61280.0059 | 0.48870.0114 | 0.32570.0044 | 0.61410.0124 | 0.56210.0297 | 0.55920.0173 | 0.52710.0053 |
🔼 Table 4 presents the F1 scores achieved by using a routing mechanism that selectively applies either a smaller (Llama-Guard-3-1B) or a larger (Granite-Guardian-3-8B) safety guard model to predict the harmfulness of prompts and responses. The best performing methods for each dataset and task (prompt-only or prompt-response) are shown in bold, with the second-best results underlined. This allows for a comparison of the routing approach’s effectiveness against using only the small or large model and several other baseline approaches.
read the caption
Table 4: Routing F1 score using the smaller (Llama-Guard-3-1B) and larger (Granite-Guardian-3-8B) models. The best results are in bold, and the second-best ones are underlined.
| Dataset | # of safe | # of harmful | Total |
| OAI | 1,158 | 522 | 1,680 |
| WildGuardMix | 1,407 | 282 | 1,689 |
| WildGuardMix-p | 945 | 754 | 1,699 |
| ToxicChat | 4,721 | 362 | 5,083 |
| XSTest | 368 | 78 | 446 |
| Harmbench | 329 | 273 | 602 |
🔼 Table 5 presents the statistical properties of six datasets used in the experiments. For each dataset, it shows the number of safe and harmful instances, as well as the total number of instances. This breakdown allows readers to understand the class distribution and overall size of each dataset.
read the caption
Table 5: Statistics of each dataset.
| Model | Hugging Face Hub Identifier |
|---|---|
| Llama-Guard-3-1B | meta-llama/Llama-Guard-3-1B |
| Llama-Guard-3-8B | meta-llama/Llama-Guard-3-8B |
| Granite-Guardian-3-8B | ibm-granite/granite-guardian-3.0-8b |
| ModernBert | answerdotai/ModernBERT-large |
| Llama-3.1-8B-Instruct | meta-llama/Llama-3.1-8B-Instruct |
🔼 This table lists the Hugging Face Hub identifiers for the pre-trained language models used in the experiments described in the paper. These models include both smaller and larger safety guard models, as well as a model used for data augmentation.
read the caption
Table 6: Hugging Face Hub model identifiers for the pre-trained models used in our work.
Full paper#