TL;DR#
Current automated methods for evaluating large language models (LLMs), particularly those using LLMs as judges, suffer from limitations in their ability to provide comprehensive and nuanced evaluations. These methods often rely on simpler approaches like majority voting or criteria expansion, which fail to capture the full depth of response quality. This leads to unreliable and inefficient evaluation outcomes, hindering progress in LLM development and deployment.
To address this problem, the researchers propose a novel crowd-based comparative evaluation (CCE) method. CCE introduces additional crowd responses to compare with the candidate responses, allowing the LLM-as-a-judge to uncover deeper details and produce more comprehensive evaluations. Experimental results demonstrate that CCE significantly enhances evaluation accuracy, generates higher-quality chain-of-thought (CoT) judgments, and improves the efficiency of supervised fine-tuning (SFT) through a technique called crowd rejection sampling. The findings highlight the effectiveness and practicality of CCE for improving automated LLM evaluation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of current automated evaluation methods for large language models (LLMs). By introducing a novel crowd-based comparative evaluation, it improves the reliability and efficiency of LLM evaluation, paving the way for better LLM development and deployment. This work directly addresses a significant challenge in the field and opens up new avenues of research for improving the evaluation and training of LLMs.
Visual Insights#

🔼 The figure illustrates the Crowd-based Comparative Evaluation (CCE) method. Candidate responses (A and B) are evaluated not in isolation, but in comparison to additional crowd responses (C, D, etc.). The judgments derived from comparing the candidate responses against the crowd responses provide richer contextual information. This information is then fed back into the LLM-as-a-Judge to produce a more comprehensive and detailed chain-of-thought (CoT) judgment for the original candidate responses. Essentially, the crowd responses act as anchors, exposing deeper details and nuances within the candidate responses that the LLM may have otherwise missed.
read the caption
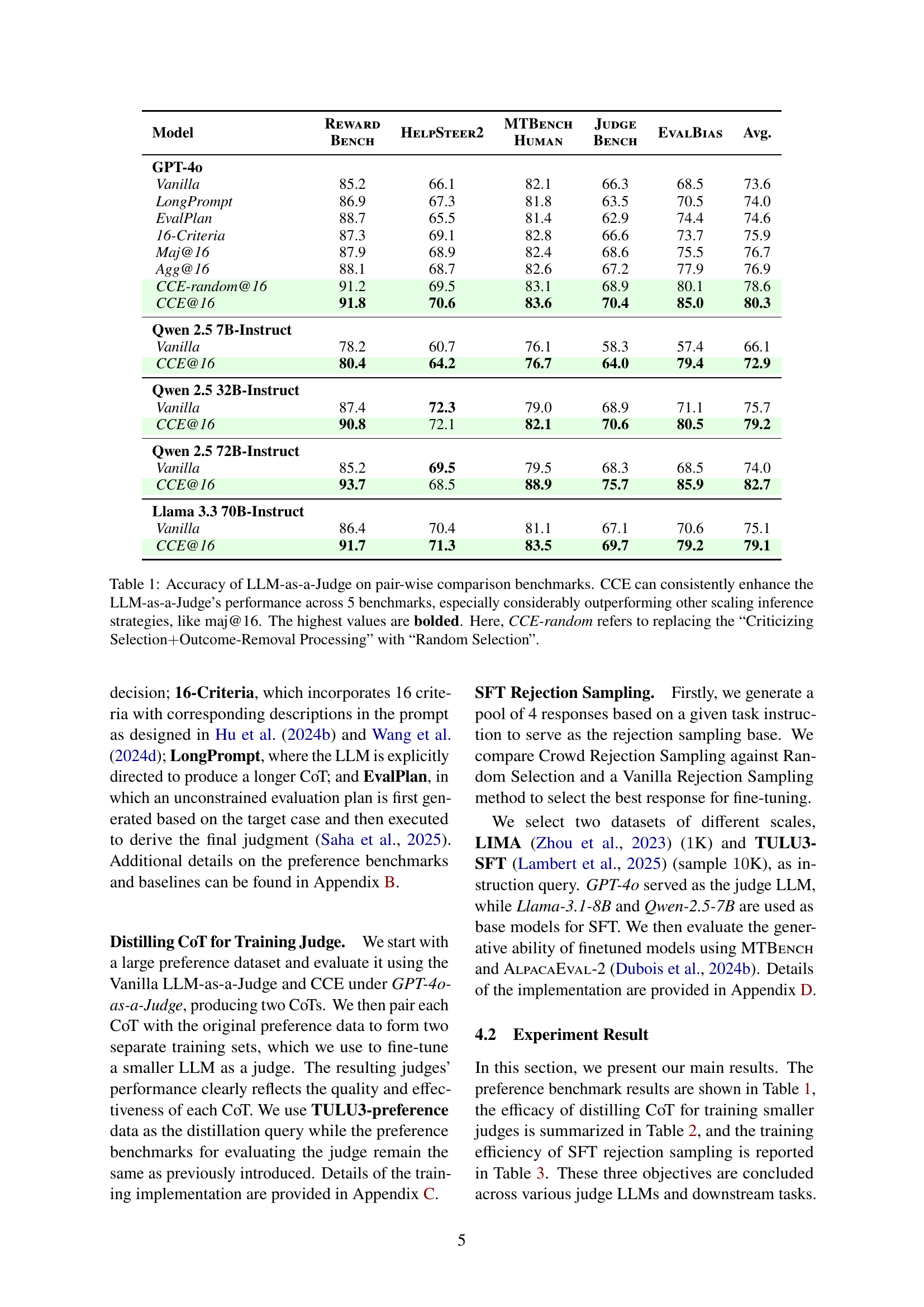
Figure 1: An overview of our method. By evaluating the candidate responses A/B alongside the crowd responses, the resulting crowd judgment can be used as context to enrich the evaluation of A/B responses, leading to a more comprehensive CoT judgment.
| Model | Reward Bench | HelpSteer2 | MTBench Human | Judge Bench | EvalBias | Avg. |
| GPT-4o | ||||||
| Vanilla | 85.2 | 66.1 | 82.1 | 66.3 | 68.5 | 73.6 |
| LongPrompt | 86.9 | 67.3 | 81.8 | 63.5 | 70.5 | 74.0 |
| EvalPlan | 88.7 | 65.5 | 81.4 | 62.9 | 74.4 | 74.6 |
| 16-Criteria | 87.3 | 69.1 | 82.8 | 66.6 | 73.7 | 75.9 |
| Maj@16 | 87.9 | 68.9 | 82.4 | 68.6 | 75.5 | 76.7 |
| Agg@16 | 88.1 | 68.7 | 82.6 | 67.2 | 77.9 | 76.9 |
| CCE-random@16 | 91.2 | 69.5 | 83.1 | 68.9 | 80.1 | 78.6 |
| CCE@16 | 91.8 | 70.6 | 83.6 | 70.4 | 85.0 | 80.3 |
| Qwen 2.5 7B-Instruct | ||||||
| Vanilla | 78.2 | 60.7 | 76.1 | 58.3 | 57.4 | 66.1 |
| CCE@16 | 80.4 | 64.2 | 76.7 | 64.0 | 79.4 | 72.9 |
| Qwen 2.5 32B-Instruct | ||||||
| Vanilla | 87.4 | 72.3 | 79.0 | 68.9 | 71.1 | 75.7 |
| CCE@16 | 90.8 | 72.1 | 82.1 | 70.6 | 80.5 | 79.2 |
| Qwen 2.5 72B-Instruct | ||||||
| Vanilla | 85.2 | 69.5 | 79.5 | 68.3 | 68.5 | 74.0 |
| CCE@16 | 93.7 | 68.5 | 88.9 | 75.7 | 85.9 | 82.7 |
| Llama 3.3 70B-Instruct | ||||||
| Vanilla | 86.4 | 70.4 | 81.1 | 67.1 | 70.6 | 75.1 |
| CCE@16 | 91.7 | 71.3 | 83.5 | 69.7 | 79.2 | 79.1 |
🔼 This table presents the accuracy results of different LLM-as-a-Judge methods across five benchmark datasets. The methods compared include the proposed Crowd-based Comparative Evaluation (CCE), majority voting (Maj@16), aggregation of multiple judgements (Agg@16), and several baseline methods (Vanilla, Long Prompt, EvalPlan, 16-Criteria). The results show the accuracy of each method in determining which of two candidate responses is superior. CCE demonstrates consistent improvement over baseline methods, particularly outperforming the scaling strategies such as Maj@16. The impact of using random selection instead of the CCE’s more sophisticated selection process is also shown by comparing CCE with CCE-random. Results are shown separately for different LLMs (GPT-4, Qwen 2.5-7B, Qwen 2.5-32B, Qwen 2.5-72B, and Llama 3.3-70B).
read the caption
Table 1: Accuracy of LLM-as-a-Judge on pair-wise comparison benchmarks. CCE can consistently enhance the LLM-as-a-Judge’s performance across 5 benchmarks, especially considerably outperforming other scaling inference strategies, like maj@16. The highest values are bolded. Here, CCE-random refers to replacing the “Criticizing Selection+++Outcome-Removal Processing” with “Random Selection”.
In-depth insights#
Crowd-based Eval#
Crowd-based evaluation methods for large language models (LLMs) offer a compelling alternative to traditional human evaluation, addressing limitations in scalability and cost. These methods leverage the wisdom of the crowd by aggregating multiple judgments from different sources. A key advantage is the potential to uncover nuanced details and perspectives that might be missed by a single evaluator. However, careful consideration must be given to the design and implementation of the crowd-based system. Bias mitigation strategies are crucial to prevent inaccuracies in the aggregated judgments. This includes careful selection of annotators or generating diverse synthetic responses, as well as employing techniques to identify and remove biased responses. Furthermore, the process of aggregating and interpreting crowd judgments requires thoughtful analysis. Sophisticated aggregation techniques may be needed to effectively handle diverse and potentially conflicting judgments, ultimately leading to a more robust and reliable assessment of LLM performance.
CoT Enhancement#
The concept of ‘CoT Enhancement’ in the context of LLMs as judges centers on improving the quality and comprehensiveness of chain-of-thought reasoning. The paper argues that current methods, such as majority voting and criteria expansion, are insufficient. Crowd-based Comparative Evaluation (CCE) is proposed as a solution, leveraging additional crowd responses to expose deeper details within candidate responses, thereby guiding the LLM judge to produce more detailed and accurate CoT judgments. This approach is motivated by how humans compare items, using additional context for enhanced comparison. The effectiveness of CCE is demonstrated through improved accuracy and the generation of higher-quality CoTs suitable for tasks like judge distillation and SFT rejection sampling. The analysis suggests that CCE’s success stems from its ability to encourage more comprehensive CoT reasoning by providing richer contextual information, ultimately leading to more reliable automated evaluations. Criticizing Selection, a key component of CCE, focuses on selecting judgments that offer deeper insights by highlighting weaknesses rather than strengths. Further, the study explores the positive impact of scaling inference and its effectiveness on reducing bias, improving overall evaluation accuracy.
Judge Distillation#
Judge distillation, in the context of LLM-as-a-judge evaluations, focuses on transferring the knowledge of a large, powerful language model (the “teacher” judge) to a smaller, more efficient model (the “student” judge). This is crucial because using large LLMs for every evaluation is computationally expensive. The process involves training the student judge on the chain-of-thought (CoT) reasoning provided by the teacher judge, effectively distilling the complex evaluation logic into a more compact form. High-quality CoTs are essential for successful distillation, as they provide rich and nuanced reasoning which the student model can learn from. The effectiveness of judge distillation is often measured by comparing the performance of the distilled model against the original teacher model on various benchmarks, looking at factors such as accuracy and efficiency. The paper likely explores different methods for generating high-quality CoTs to improve distillation, such as techniques which encourage more comprehensive comparisons between responses, potentially leading to better student judge performance and reduced computational cost. The resulting distilled judge model aims to maintain the evaluation quality of the larger model while offering improved efficiency and scalability. Further analysis might examine the impact of various factors on the distillation process, such as the size and architecture of the student model, the size of the training dataset, and the specific techniques used to generate the CoTs.
SFT Rejection#
Supervised fine-tuning (SFT) is a crucial process in developing effective large language models (LLMs). However, the cost and time associated with SFT can be substantial, and not all training data is equally valuable. SFT rejection sampling offers a solution to this problem by selectively choosing high-quality data points for inclusion in the SFT process. This selective approach improves training efficiency and model performance by avoiding the inclusion of less informative or noisy examples. The paper explores the integration of the crowd-based comparative evaluation (CCE) method with SFT rejection sampling. CCE is shown to produce higher-quality judgments, enabling a more effective selection of training data. The process improves the quality of the final SFT model and improves efficiency by reducing the amount of data that needs to be processed. Crowd rejection sampling, a novel approach, is introduced. This approach leverages the richness of information extracted through CCE’s comprehensive analysis to enhance the filtering process. Experimental results demonstrate a noticeable performance improvement in models trained using crowd rejection sampling, surpassing traditional methods in both effectiveness and efficiency.
CCE Limitations#
The Crowd-based Comparative Evaluation (CCE) method, while showing promise in enhancing LLM-as-a-Judge evaluations, presents several limitations. Firstly, the reliance on a progressive self-iteration paradigm is absent from the study. While the method inherently allows for iterative refinement, a structured approach to such iteration is not explored, limiting the potential for even greater accuracy and robustness. Secondly, the methodology heavily depends on the quality of crowd judgments generated by LLMs. The selection of these judgments is not comprehensively investigated, raising concerns about potential biases inherent in the selected crowd responses and their influence on the overall evaluation. A more thorough exploration of different LLM choices and their impact on crowd judgment quality is crucial for improving reliability. Finally, while the study shows promising results in scaling inference, the inherent computational cost of generating and processing numerous crowd judgments remains a practical consideration. The scalability of CCE in real-world applications may be limited by this resource-intensive nature. Further research should focus on improving efficiency and exploring more cost-effective strategies for generating and selecting high-quality crowd responses to fully unlock the potential of CCE.
More visual insights#
More on figures

🔼 This figure illustrates the Crowd-based Comparative Evaluation (CCE) process. For a given task (x) and two candidate responses (yA and yB), the system first generates additional responses (crowd responses, yi) using an LLM. These crowd responses are then compared with the original candidate responses to create initial judgments (J). These judgments are refined (J^) through selection and processing steps that prioritize informative comparisons. Finally, the refined judgments are used as context for the LLM to produce a more comprehensive evaluation of the original candidates (yA, yB).
read the caption
Figure 2: Pipeline of our proposed crowd-based comparative evaluation. For a given instance (x,yA,yB)𝑥superscript𝑦𝐴superscript𝑦𝐵(x,y^{A},y^{B})( italic_x , italic_y start_POSTSUPERSCRIPT italic_A end_POSTSUPERSCRIPT , italic_y start_POSTSUPERSCRIPT italic_B end_POSTSUPERSCRIPT ), we first use the LLM to generate crowd responses {yi|i∈{C,D,E,…}}conditional-setsuperscript𝑦𝑖𝑖𝐶𝐷𝐸…\left\{y^{i}|i\in\{C,D,E,...\}\right\}{ italic_y start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT | italic_i ∈ { italic_C , italic_D , italic_E , … } } based on x𝑥xitalic_x. These responses are then compared with yAsuperscript𝑦𝐴y^{A}italic_y start_POSTSUPERSCRIPT italic_A end_POSTSUPERSCRIPT and yBsuperscript𝑦𝐵y^{B}italic_y start_POSTSUPERSCRIPT italic_B end_POSTSUPERSCRIPT to produce initial crowd judgments 𝒥𝒥\mathcal{J}caligraphic_J, which are subsequently refined into 𝒥^^𝒥\hat{\mathcal{J}}over^ start_ARG caligraphic_J end_ARG after selection and processing. Finally, 𝒥^^𝒥\hat{\mathcal{J}}over^ start_ARG caligraphic_J end_ARG are used as contextual input to evaluate the instance (x,yA,yB)𝑥superscript𝑦𝐴superscript𝑦𝐵(x,y^{A},y^{B})( italic_x , italic_y start_POSTSUPERSCRIPT italic_A end_POSTSUPERSCRIPT , italic_y start_POSTSUPERSCRIPT italic_B end_POSTSUPERSCRIPT ).

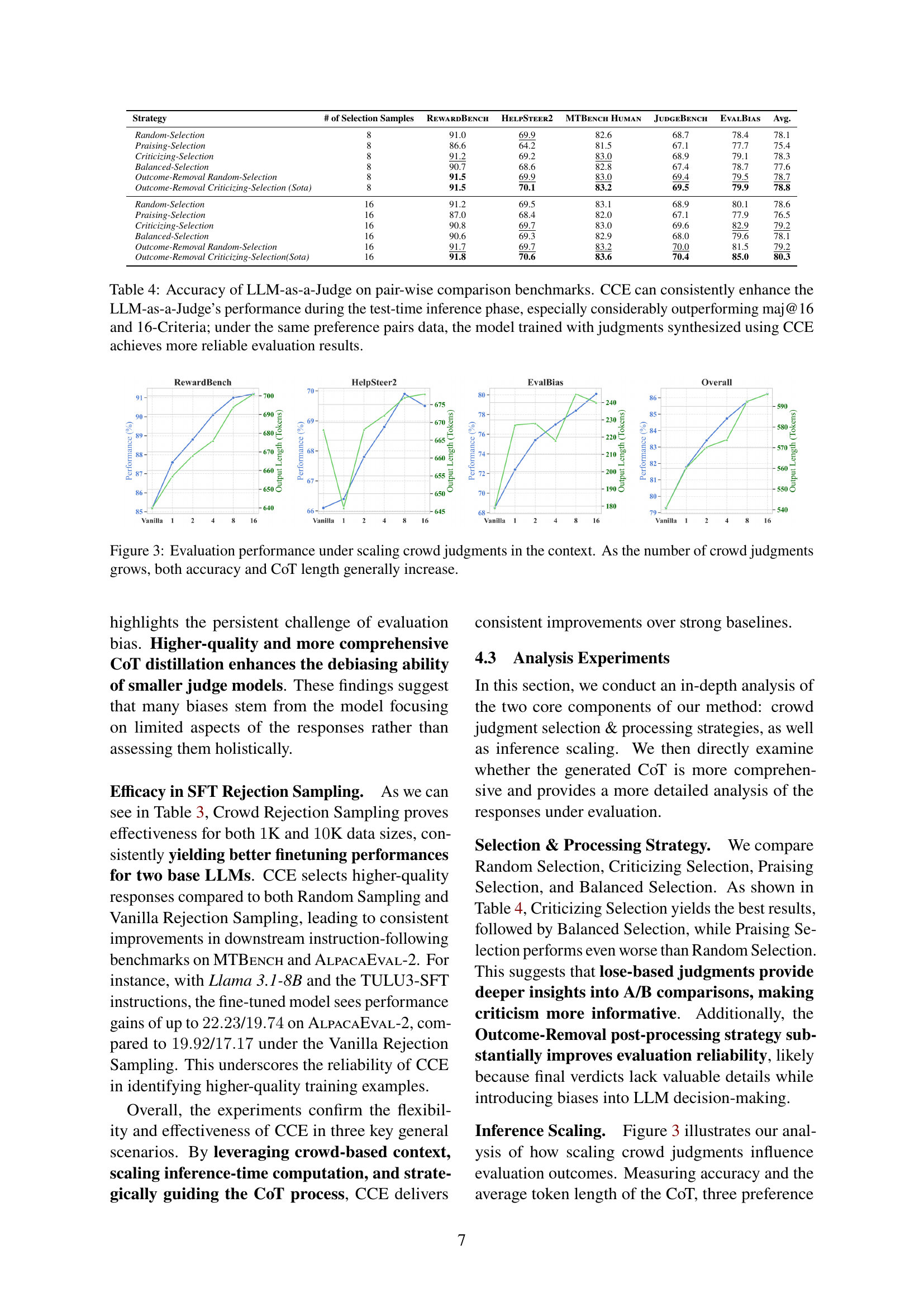
🔼 This figure displays the impact of increasing the number of crowd judgments on the performance of the proposed Crowd-based Comparative Evaluation (CCE) method. The x-axis represents the number of crowd judgments included, while the y-axis shows two key metrics: accuracy of the LLM-as-a-judge and the length of the chain-of-thought (CoT) reasoning produced by the LLM. The graphs illustrate that as more crowd judgments are considered (increasing context), both the accuracy of the evaluation and the detail level of the CoT reasoning generally improve.
read the caption
Figure 3: Evaluation performance under scaling crowd judgments in the context. As the number of crowd judgments grows, both accuracy and CoT length generally increase.

🔼 Figure 4 presents a comparison of Chain-of-Thought (CoT) reasoning quality between the proposed Crowd-based Comparative Evaluation (CCE) method and the standard approach (Vanilla). It uses two key metrics: the average number of key points identified in the CoT and the coverage rate. The key points metric reflects how many distinct aspects or details the model considered when forming its judgment. The coverage rate indicates the proportion of relevant information in the input response that the model’s CoT addressed. Across all five benchmarks used for evaluation, CCE consistently outperformed the vanilla method in both of these metrics, demonstrating that CCE generates more comprehensive and in-depth CoTs.
read the caption
Figure 4: CoT Comparison. CCE’s CoT consistently yields a higher average number of key points and a higher coverage rate across all benchmarks.

🔼 This figure displays the prompt used in the Crowd-based Comparative Evaluation (CCE) method. The prompt instructs the LLM to act as an impartial judge, evaluating two AI-generated responses. It emphasizes holistic assessment, considering various criteria like helpfulness, relevance, accuracy, and completeness. The prompt also instructs the LLM to implicitly consider characteristics of other responses (crowd responses) as a background context, further refining its judgment. Crucially, the prompt explicitly forbids the LLM from referencing these background responses directly in its final verdict. The prompt concludes by specifying the format for the final verdict: ‘[[A]]’ or ‘[[B]]’, indicating which assistant performed better.
read the caption
Figure 5: Prompt of Our Method.

🔼 This figure displays the prompt used in the vanilla LLM-as-a-Judge method. Unlike the more complex prompt used in the Crowd Comparative Evaluation method (CCE), the vanilla prompt is simpler and focuses on the basic comparison of the two responses based on general criteria such as helpfulness, relevance, accuracy, depth, creativity, and level of detail. It instructs the LLM to choose the response that better answers the user’s question, emphasizing objectivity and avoiding bias based on factors such as length, style, order of presentation, or AI assistant names.
read the caption
Figure 6: Prompt of Vanilla LLM-as-a-Judge.

🔼 This figure displays the prompt used for the 16-criteria LLM-as-a-Judge evaluation method. The prompt instructs the LLM to act as an impartial judge, evaluating two AI-generated responses based on sixteen specified criteria, which are listed explicitly in the prompt, encompassing aspects such as helpfulness, relevance, accuracy, depth, creativity, detail level, overall quality, readability, coherence, fluency, grammaticality, simplicity, adequacy, faithfulness, non-hallucination and complexity. The LLM is directed to compare the responses, provide a short explanation, and render a final verdict indicating which response is superior, using a pre-defined format.
read the caption
Figure 7: Prompt of 16-Criteria LLM-as-a-Judge.

🔼 This figure shows the prompt used for the LongPrompt LLM-as-a-Judge baseline. The prompt instructs the LLM to act as an impartial judge, comparing two AI-generated responses to a given question. It emphasizes a detailed explanation of the comparison, aiming for a comprehensive evaluation of aspects like helpfulness, accuracy, depth, and creativity. The LLM is explicitly instructed to provide a long explanation. The final verdict must follow the format ‘[[A]]’ or ‘[[B]]’, indicating the better response.
read the caption
Figure 8: Prompt of LongPrompt LLM-as-a-Judge.
More on tables
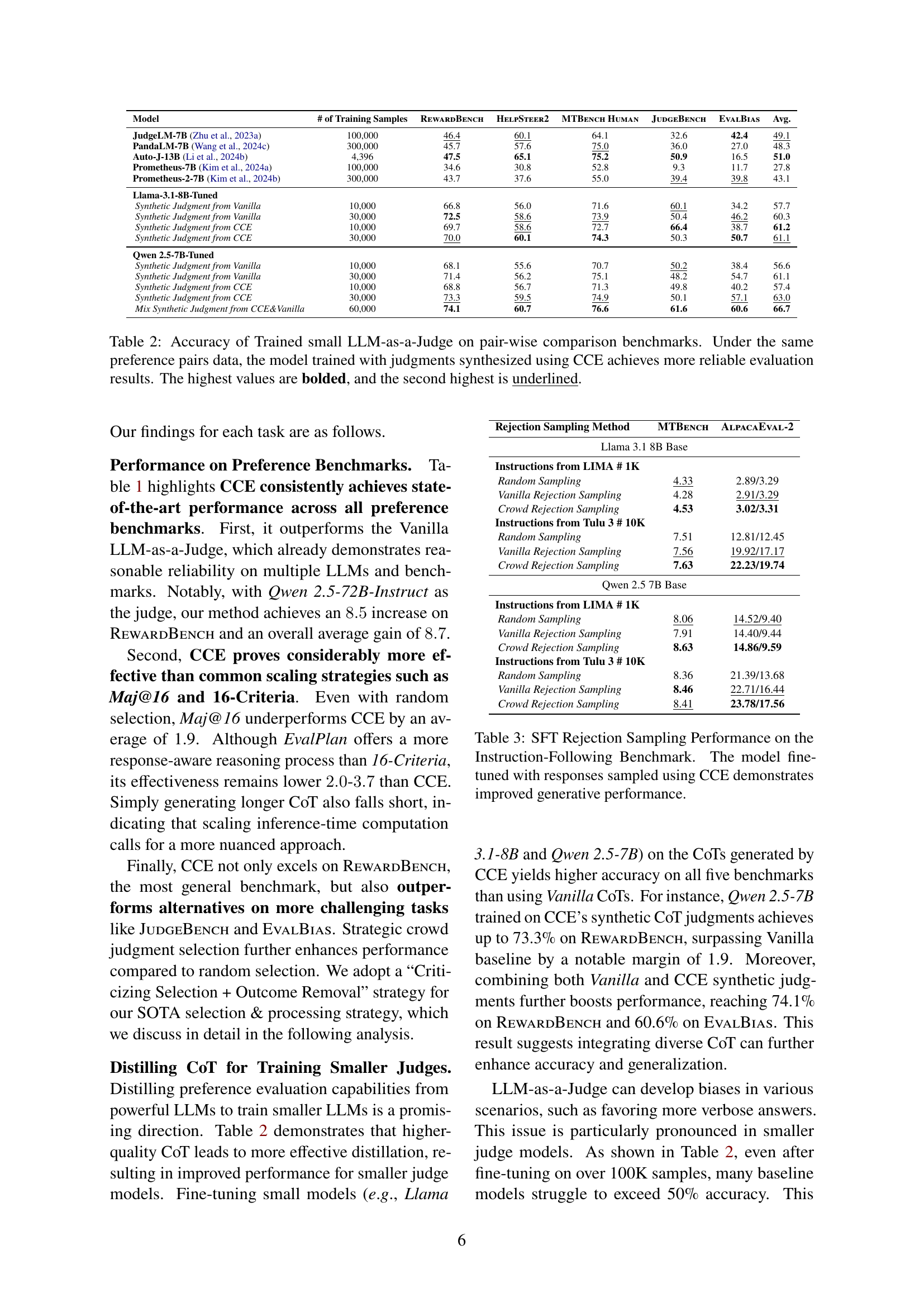
| Model | # of Training Samples | RewardBench | HelpSteer2 | MTBench Human | JudgeBench | EvalBias | Avg. |
| JudgeLM-7B (Zhu et al., 2023a) | 100,000 | 46.4 | 60.1 | 64.1 | 32.6 | 42.4 | 49.1 |
| PandaLM-7B (Wang et al., 2024c) | 300,000 | 45.7 | 57.6 | 75.0 | 36.0 | 27.0 | 48.3 |
| Auto-J-13B (Li et al., 2024b) | 4,396 | 47.5 | 65.1 | 75.2 | 50.9 | 16.5 | 51.0 |
| Prometheus-7B (Kim et al., 2024a) | 100,000 | 34.6 | 30.8 | 52.8 | 9.3 | 11.7 | 27.8 |
| Prometheus-2-7B (Kim et al., 2024b) | 300,000 | 43.7 | 37.6 | 55.0 | 39.4 | 39.8 | 43.1 |
| Llama-3.1-8B-Tuned | |||||||
| Synthetic Judgment from Vanilla | 10,000 | 66.8 | 56.0 | 71.6 | 60.1 | 34.2 | 57.7 |
| Synthetic Judgment from Vanilla | 30,000 | 72.5 | 58.6 | 73.9 | 50.4 | 46.2 | 60.3 |
| Synthetic Judgment from CCE | 10,000 | 69.7 | 58.6 | 72.7 | 66.4 | 38.7 | 61.2 |
| Synthetic Judgment from CCE | 30,000 | 70.0 | 60.1 | 74.3 | 50.3 | 50.7 | 61.1 |
| Qwen 2.5-7B-Tuned | |||||||
| Synthetic Judgment from Vanilla | 10,000 | 68.1 | 55.6 | 70.7 | 50.2 | 38.4 | 56.6 |
| Synthetic Judgment from Vanilla | 30,000 | 71.4 | 56.2 | 75.1 | 48.2 | 54.7 | 61.1 |
| Synthetic Judgment from CCE | 10,000 | 68.8 | 56.7 | 71.3 | 49.8 | 40.2 | 57.4 |
| Synthetic Judgment from CCE | 30,000 | 73.3 | 59.5 | 74.9 | 50.1 | 57.1 | 63.0 |
| Mix Synthetic Judgment from CCE&Vanilla | 60,000 | 74.1 | 60.7 | 76.6 | 61.6 | 60.6 | 66.7 |
🔼 This table presents the accuracy results of smaller LLMs trained as judges using Chain-of-Thought (CoT) judgments generated by two different methods: Vanilla and Crowd-based Comparative Evaluation (CCE). The accuracy is measured across five pairwise comparison benchmarks (REWARDBENCH, HELPSTEER2, MTBENCH HUMAN, JUDGEBENCH, EVALBIAS). The table shows that using CCE to generate CoT judgments leads to significantly better performance of the trained judge models compared to using Vanilla. The highest accuracy scores for each benchmark are highlighted in bold, and the second-highest scores are underlined, demonstrating the consistent superior performance of the CCE approach.
read the caption
Table 2: Accuracy of Trained small LLM-as-a-Judge on pair-wise comparison benchmarks. Under the same preference pairs data, the model trained with judgments synthesized using CCE achieves more reliable evaluation results. The highest values are bolded, and the second highest is underlined.
| Rejection Sampling Method | MTBench | AlpacaEval-2 |
| Llama 3.1 8B Base | ||
| Instructions from LIMA # 1K | ||
| Random Sampling | 4.33 | 2.89/3.29 |
| Vanilla Rejection Sampling | 4.28 | 2.91/3.29 |
| Crowd Rejection Sampling | 4.53 | 3.02/3.31 |
| Instructions from Tulu 3 # 10K | ||
| Random Sampling | 7.51 | 12.81/12.45 |
| Vanilla Rejection Sampling | 7.56 | 19.92/17.17 |
| Crowd Rejection Sampling | 7.63 | 22.23/19.74 |
| Qwen 2.5 7B Base | ||
| Instructions from LIMA # 1K | ||
| Random Sampling | 8.06 | 14.52/9.40 |
| Vanilla Rejection Sampling | 7.91 | 14.40/9.44 |
| Crowd Rejection Sampling | 8.63 | 14.86/9.59 |
| Instructions from Tulu 3 # 10K | ||
| Random Sampling | 8.36 | 21.39/13.68 |
| Vanilla Rejection Sampling | 8.46 | 22.71/16.44 |
| Crowd Rejection Sampling | 8.41 | 23.78/17.56 |
🔼 This table presents the results of an experiment evaluating the effectiveness of different response sampling methods for supervised fine-tuning (SFT) within the context of instruction-following tasks. Three methods were compared: random sampling, vanilla rejection sampling (using a standard LLM-as-a-Judge), and crowd-based rejection sampling (using the proposed CCE method). The table shows the performance of models fine-tuned using each sampling method, measured on two instruction-following benchmarks (MTBENCH and ALPACAEVAL-2) with different numbers of training instructions (LIMA with 1K instructions, and TULU3-SFT with 10K instructions). The performance is assessed using two metrics, and the results demonstrate the improved generative capabilities of models trained with responses selected using the proposed CCE method.
read the caption
Table 3: SFT Rejection Sampling Performance on the Instruction-Following Benchmark. The model fine-tuned with responses sampled using CCE demonstrates improved generative performance.
| Strategy | # of Selection Samples | RewardBench | HelpSteer2 | MTBench Human | JudgeBench | EvalBias | Avg. |
| Random-Selection | 8 | 91.0 | 69.9 | 82.6 | 68.7 | 78.4 | 78.1 |
| Praising-Selection | 8 | 86.6 | 64.2 | 81.5 | 67.1 | 77.7 | 75.4 |
| Criticizing-Selection | 8 | 91.2 | 69.2 | 83.0 | 68.9 | 79.1 | 78.3 |
| Balanced-Selection | 8 | 90.7 | 68.6 | 82.8 | 67.4 | 78.7 | 77.6 |
| Outcome-Removal Random-Selection | 8 | 91.5 | 69.9 | 83.0 | 69.4 | 79.5 | 78.7 |
| Outcome-Removal Criticizing-Selection (Sota) | 8 | 91.5 | 70.1 | 83.2 | 69.5 | 79.9 | 78.8 |
| Random-Selection | 16 | 91.2 | 69.5 | 83.1 | 68.9 | 80.1 | 78.6 |
| Praising-Selection | 16 | 87.0 | 68.4 | 82.0 | 67.1 | 77.9 | 76.5 |
| Criticizing-Selection | 16 | 90.8 | 69.7 | 83.0 | 69.6 | 82.9 | 79.2 |
| Balanced-Selection | 16 | 90.6 | 69.3 | 82.9 | 68.0 | 79.6 | 78.1 |
| Outcome-Removal Random-Selection | 16 | 91.7 | 69.7 | 83.2 | 70.0 | 81.5 | 79.2 |
| Outcome-Removal Criticizing-Selection(Sota) | 16 | 91.8 | 70.6 | 83.6 | 70.4 | 85.0 | 80.3 |
🔼 This table presents the results of evaluating the performance of LLM-as-a-Judge models on several pairwise comparison benchmarks. It compares the accuracy of different methods, including the proposed Crowd-based Comparative Evaluation (CCE), majority voting (Maj@16), and criteria expansion (16-Criteria). The results show that CCE consistently improves the accuracy of LLM-as-a-Judge across various benchmarks, significantly outperforming both Maj@16 and 16-Criteria. Furthermore, it highlights that models trained using judgments generated by CCE achieve higher reliability in evaluation.
read the caption
Table 4: Accuracy of LLM-as-a-Judge on pair-wise comparison benchmarks. CCE can consistently enhance the LLM-as-a-Judge’s performance during the test-time inference phase, especially considerably outperforming maj@16 and 16-Criteria; under the same preference pairs data, the model trained with judgments synthesized using CCE achieves more reliable evaluation results.
| Instruction: Classify this tweet from the categories of positive, negative, or neutral. Tweet: I’m so thankful for all the wonderful people in my life |
| Response A |
| The sentiment of this social media comment is positive. The use of the word "grateful" implies appreciation and thankfulness, while "amazing experiences" suggest that these experiences have been very fulfilling or enjoyable. |
| Response B |
| Positive |
| Vanilla LLM-as-a-Judge: |
| Assistant A’s . . . . . . It highlights specific words and phrases in the tweet, such as “thankful” and “wonderful people,” to justify the positive sentiment classification. This explanation adds depth and clarity to the response, making it more helpful and informative. Assistant B, . . . . . . the response less informative and helpful . . . . . . . . . - Final Verdict: [[A]] |
| CCE: |
| AC Judgment: However, Assistant A makes a mistake by referencing words not present in the tweet, such as "grateful" and "amazing experiences," . . . . . . Assistant C also classifies the tweet as positive and provides a detailed explanation . . . . . . . . . Assistant A . . . . . , but it inaccurately references words not present in the tweet, such as "grateful" and "amazing experiences." This detracts from the accuracy of the response and could potentially confuse the user. . . . . . . Assistant B is concise and correctly classifies the tweet as positive. However, it lacks any explanation or reasoning, which limits its helpfulness and depth. . . . . . . In comparing the two, Given the importance of accuracy and explanation in sentiment analysis, . . . . . . - Final Verdict: [[B]] |
🔼 Table 5 presents a case study comparing the evaluation results of a standard LLM-as-a-Judge approach and the proposed Crowd-based Comparative Evaluation (CCE) method. The example shows two model responses to a sentiment analysis task. The table highlights how CCE, by incorporating additional crowd responses and judgments, leads to a more nuanced and accurate evaluation compared to the standard LLM-as-a-Judge approach, which may be susceptible to noise or bias in individual judgments. Colors are used to distinguish between unreliable and helpful aspects of each evaluation. Limongreen highlights elements of evaluation considered useful or well-reasoned, while orange denotes unreliable or noisy aspects.
read the caption
Table 5: A pairwise comparison case evaluated by different methods. Preference refers to right result and Preference refers to wrong result. We emphasize the noisy evaluation elements in orange, while highlighting the useful elements of the evaluation in limongreen.
| Benchmarks | Size | Focus |
| RewardBench | It covers multiple scenarios, including Chat, Chat-Hard, Safety, and Reasoning. | |
| HelpSteeer2 | It provides multiple fine-grained dimensions for evaluation, like Helpfulness, Coherence, Correctness, Complexity, Verbosity. | |
| MTBench Human | It provides multi-turn conversation for evaluation, and we filter the samples whose outcome is “Tie”. | |
| JudgeBench | It focuses on challenging response pairs spanning knowledge, reasoning, math, and coding | |
| EvalBias | It tests the robustness of judges on various scenarios containing evaluation biases. |
🔼 This table details the five preference benchmarks used to evaluate the LLM-as-a-Judge models. For each benchmark, it provides the number of instances (size) and a brief description of its focus, highlighting the types of scenarios or aspects it evaluates. These benchmarks encompass diverse evaluation scenarios, including chat, reasoning, and bias detection, to provide a comprehensive assessment of LLM-as-a-Judge performance.
read the caption
Table 6: The brief description of Preference Benchmarks for testing.
Full paper#