TL;DR#
Large language models (LLMs) excel at generating long texts, but processing extensive contexts strains GPU memory, particularly the key-value (KV) cache. Current solutions like quantization or layer-wise offloading have limitations in reducing memory usage or are not suitable for consumer-level hardware. This creates a significant hurdle for widespread LLM deployment, especially on devices with limited memory resources.
To overcome these memory limitations, the researchers introduce HEADINFER, a novel framework that offloads the KV cache to the CPU in a head-wise manner. This means only a portion of the KV cache is kept in the GPU memory at any given time, improving memory efficiency. HEADINFER incorporates several key optimizations like adaptive head grouping, asynchronous data transfer, and chunked pre-filling to maintain high computational efficiency while significantly reducing memory usage. The experiments show that HEADINFER drastically reduces memory usage while enabling significantly longer context lengths, even on a single consumer-grade GPU. This innovative approach democratizes access to powerful LLMs by making them accessible on more affordable and readily available hardware.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and memory-efficient inference. It addresses the critical challenge of high memory consumption in LLMs, particularly when handling long contexts. The proposed HEADINFER method offers a practical solution for deploying LLMs on consumer-grade hardware, opening up new avenues of research in efficient LLM inference and expanding accessibility to advanced AI. This has significant implications for the wider adoption of LLMs across various domains and contributes to the advancement of memory-efficient AI systems.
Visual Insights#
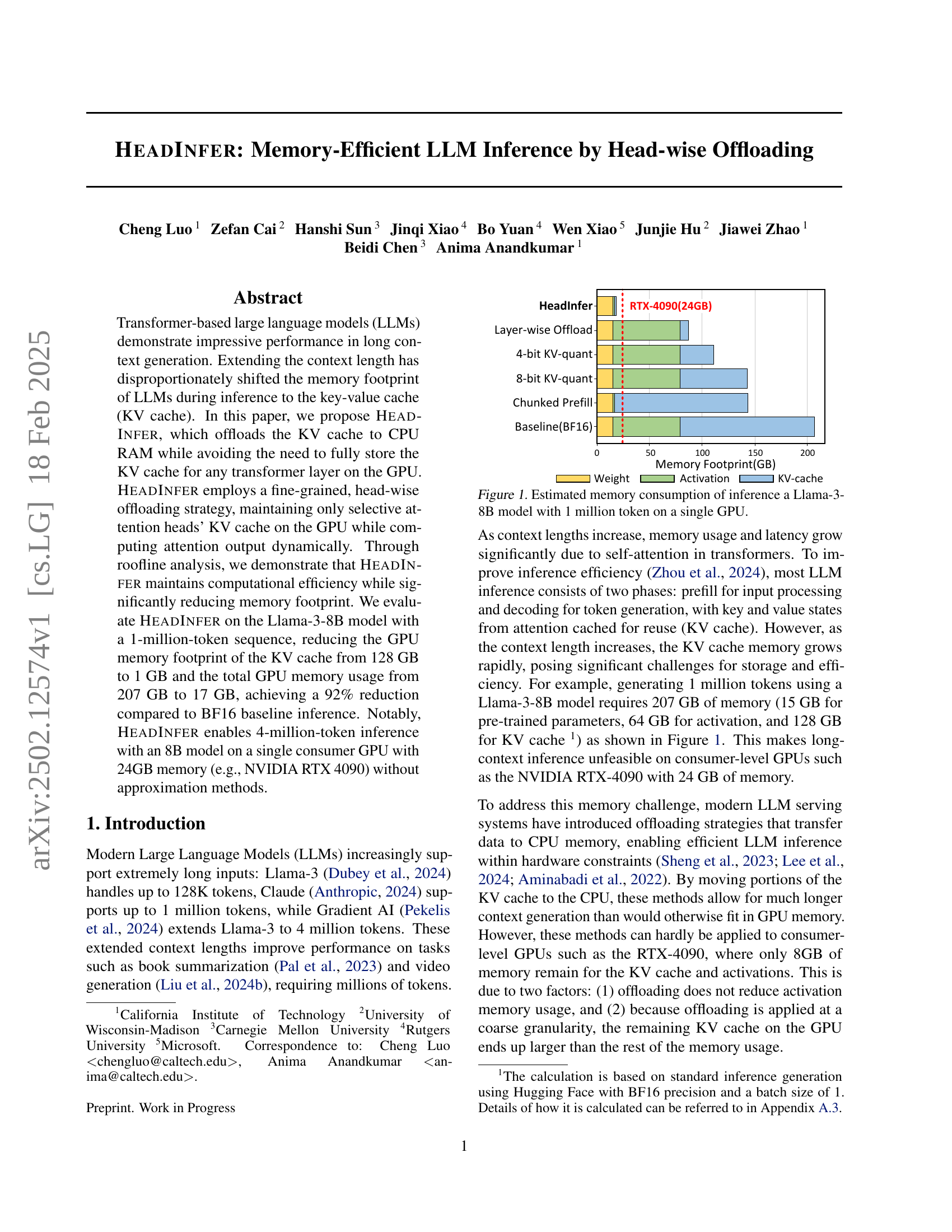
🔼 The bar chart visualizes the memory usage breakdown for inferencing a Llama-3-8B model with a 1 million token input sequence on a single GPU. It compares the memory consumption of the key-value cache (KV cache), activations, and model weights. The chart highlights the disproportionately large memory footprint of the KV cache compared to the other components, emphasizing the memory challenge posed by long context inference.
read the caption
Figure 1: Estimated memory consumption of inference a Llama-3-8B model with 1 million token on a single GPU.
| LongBench V2 | Overall | Easy | Hard | Short | Medium | Long |
|---|---|---|---|---|---|---|
| Standard 25K | 28.4 | 30.2 | 27.3 | 33.9 | 25.1 | 25.9 |
| Chunked Prefill 30K | 28.2 | 27.1 | 28.9 | 32.8 | 25.6 | 25.9 |
| Layer-wise offload 45K | 29.0 | 29.2 | 28.9 | 36.1 | 24.2 | 26.9 |
| HeadInfer 1024K | 30.2 | 31.2 | 29.6 | 33.9 | 27.0 | 30.6 |
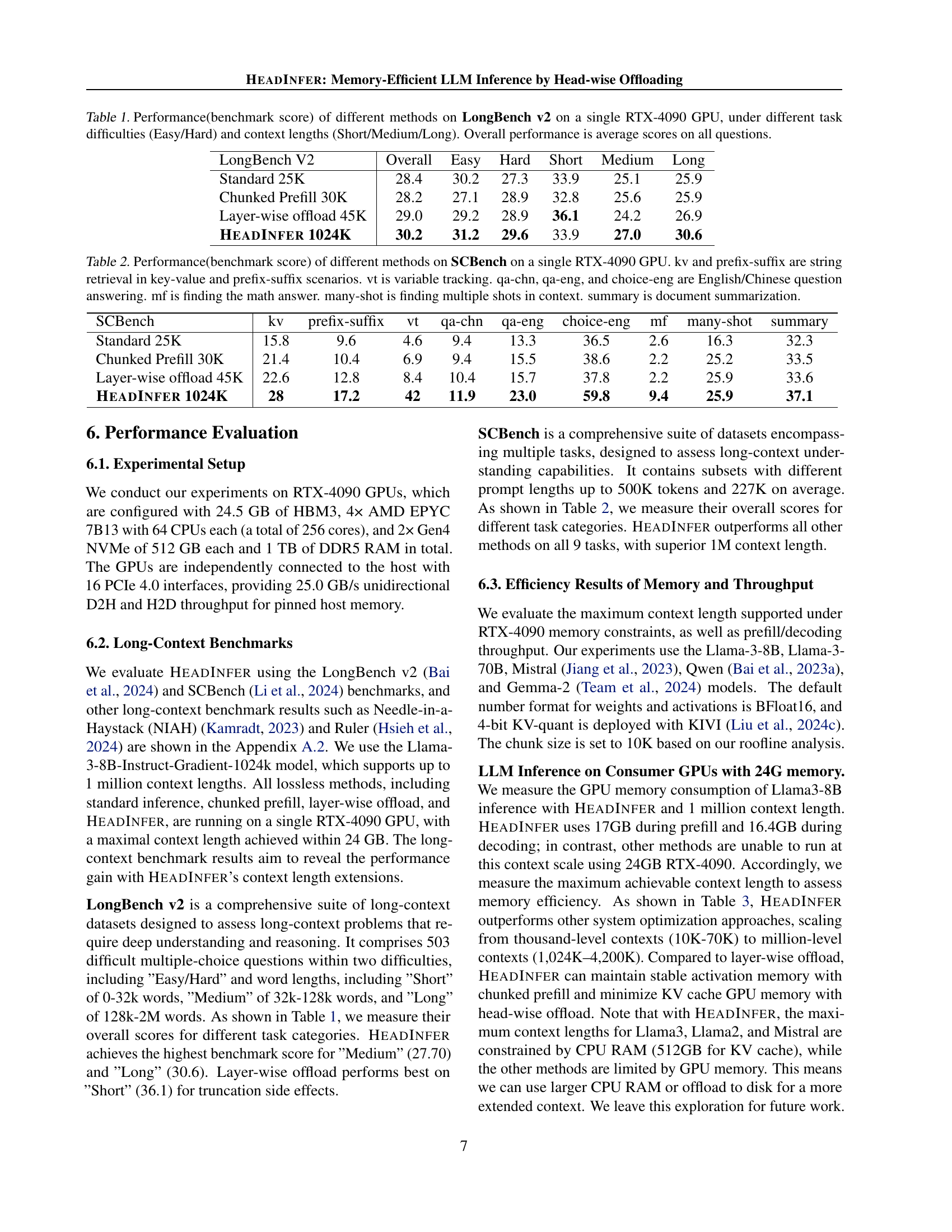
🔼 This table presents the performance comparison of four different methods on the LongBench v2 benchmark, using a single RTX 4090 GPU. The benchmark evaluates performance on various question-answering tasks with different difficulty levels (Easy and Hard) and various context lengths (Short, Medium, and Long). The four methods compared are Standard inference, Chunked Prefill, Layer-wise offload, and HEADINFER. The ‘Overall’ column shows the average score across all questions, while the individual columns for Short, Medium, and Long show the average score for questions with those respective context lengths. The table highlights the impact of different context lengths and offloading techniques on the performance of long-context question answering tasks.
read the caption
Table 1: Performance(benchmark score) of different methods on LongBench v2 on a single RTX-4090 GPU, under different task difficulties (Easy/Hard) and context lengths (Short/Medium/Long). Overall performance is average scores on all questions.
In-depth insights#
Head-wise Offload#
The core concept of “Head-wise Offload” in the HeadINFER model is a fine-grained memory management strategy for large language models (LLMs) during inference. Unlike layer-wise offloading, which moves entire layers’ key-value caches to CPU memory, Head-wise Offload operates at the level of individual attention heads. This granular approach allows the system to selectively maintain only the most crucial heads’ information in the GPU’s high-bandwidth memory (HBM), dynamically offloading less important heads to the CPU RAM. This significantly reduces GPU memory footprint, enabling the processing of extremely long input sequences that would otherwise be infeasible due to memory limitations. The strategy’s effectiveness is augmented by techniques like adaptive head grouping, which dynamically adjusts the number of heads kept in GPU memory based on context length, maintaining computational efficiency. Asynchronous data transfer further enhances performance by overlapping offloading operations with GPU computations, preventing stalls. Overall, this head-wise approach demonstrates a significant improvement in memory efficiency and scalability for LLM inference, particularly on consumer-grade GPUs with limited memory capacity.
Memory Efficiency#
The research paper explores memory efficiency in large language model (LLM) inference, focusing on reducing the memory footprint of the key-value (KV) cache. A key contribution is the introduction of HEADINFER, a novel framework that offloads the KV cache to the CPU in a fine-grained, head-wise manner. This approach maintains computational efficiency while significantly reducing GPU memory usage, enabling inference with significantly longer contexts. HEADINFER achieves this by selectively offloading attention heads’ KV caches to the CPU, maintaining only critical heads on the GPU at any given time. The paper validates its approach through extensive experimentation and analysis, including roofline analysis to demonstrate computational efficiency and benchmark results showing substantial memory reduction and improved context length handling on consumer-grade GPUs. The results highlight the significant potential of HEADINFER to democratize access to advanced LLMs by making long-context inference feasible on hardware with limited resources. The authors introduce further optimizations such as adaptive head grouping, chunked prefill, and asynchronous data transfer to enhance efficiency. Overall, the paper makes a substantial contribution to the field by presenting a practical and efficient solution to the memory constraints in LLM inference. The head-wise approach provides a more granular control over memory usage compared to previous layer-wise offloading techniques, offering increased flexibility and improved performance.
Roofline Analysis#
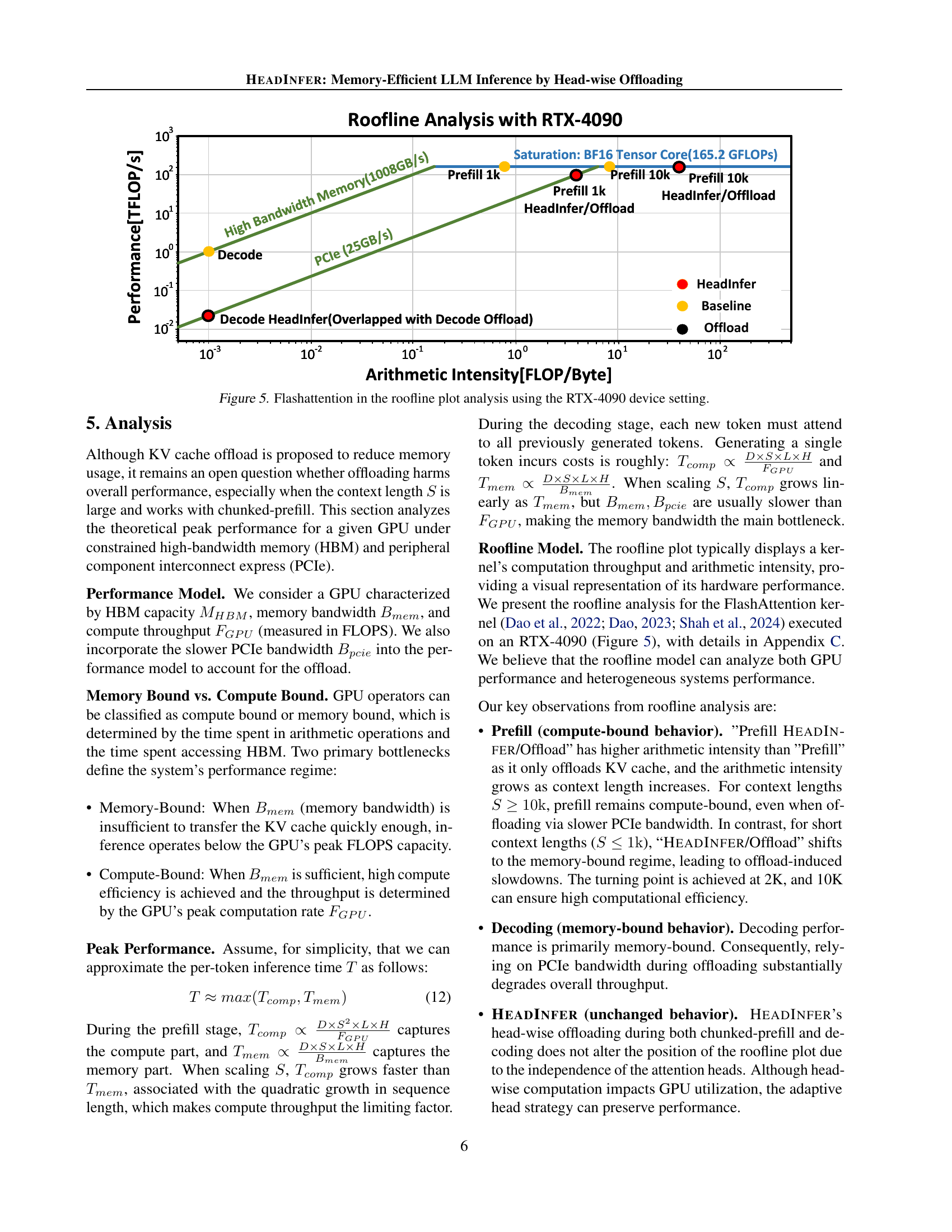
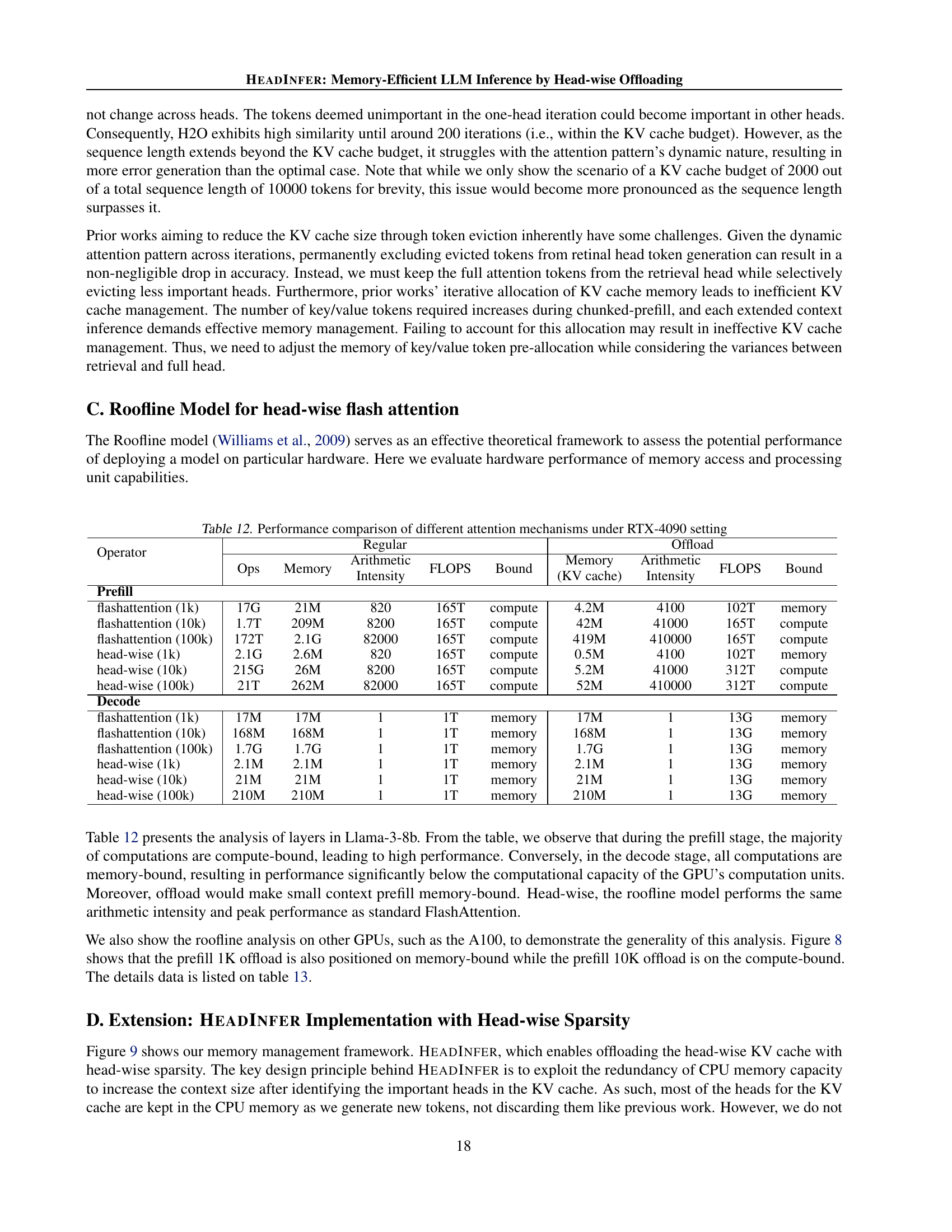
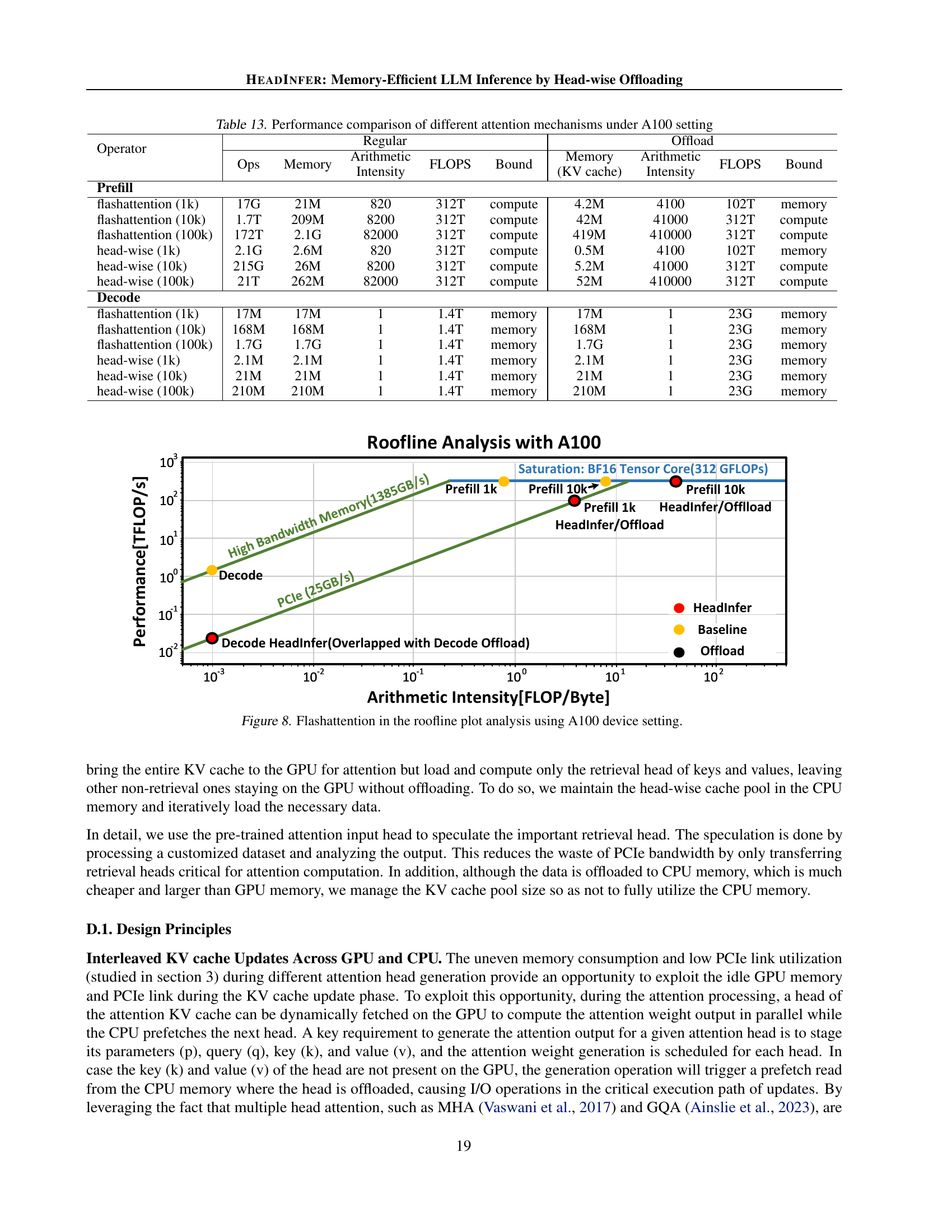
Roofline analysis is a powerful technique for evaluating the performance of computational kernels, especially on GPUs. In the context of large language model (LLM) inference, this analysis is particularly insightful because it helps to understand the interplay between computation and memory bandwidth. The roofline plot visually represents the peak performance achievable by a GPU, limited by either its computational capabilities or its memory bandwidth. The analysis is crucial because LLMs can quickly become memory-bound as context length grows, particularly concerning the key-value (KV) cache. Therefore, the plot helps researchers assess whether an optimization is compute-bound (limited by arithmetic intensity) or memory-bound (limited by memory bandwidth). By analyzing the position of the kernel on the roofline plot, researchers can identify performance bottlenecks and determine whether optimization efforts should focus on computational enhancements or memory access improvements. HEADINFER’s roofline analysis clearly demonstrates its efficiency, maintaining compute efficiency even with reduced memory usage. This is a critical finding because it shows that HEADINFER’s head-wise offloading strategy does not sacrifice computational performance for memory efficiency. The analysis provides strong evidence for HEADINFER’s effectiveness and offers valuable insights into the design and optimization of memory-efficient LLMs.
Long-Context LLM#
Long-context LLMs demonstrate significant advancements in natural language processing by enabling the handling of substantially longer input sequences. This capability is crucial for various applications requiring the processing of extensive textual data, such as book summarization and complex question answering. However, increased context length presents substantial challenges, primarily concerning memory consumption. The quadratic growth of memory requirements with context length poses a significant hurdle to inference, limiting the practicality of these models on resource-constrained hardware. Efficient memory management strategies are thus essential, including techniques like KV cache optimization, quantization, and offloading to alleviate these limitations. This research area actively explores innovative approaches to strike a balance between maximizing context length and maintaining computational efficiency, aiming for practical deployment on consumer-grade hardware while preserving accuracy.
Ablation Study#
An ablation study systematically removes components of a model to determine their individual contributions. In the context of the research paper, an ablation study on HEADINFER would likely involve removing or modifying key aspects of its design to evaluate their impact. This could include disabling head-wise offloading, removing the asynchronous data transfer optimization, or altering the adaptive head grouping strategy. By comparing the performance of the modified models against the full HEADINFER model, researchers could quantify the impact of each component and determine which aspects are essential for achieving memory efficiency and high performance. The results would highlight the trade-offs between different design choices and potentially identify areas for further optimization or simplification. For example, removing asynchronous data transfers might reveal a performance penalty, indicating its importance. Removing adaptive head grouping might show less flexibility in handling varied context lengths, revealing its value in robust memory management. Ultimately, a well-executed ablation study provides a crucial understanding of the model’s inner workings, justifying design choices and paving the way for future improvements. It provides concrete evidence supporting claims made about the significance of each part of the HEADINFER architecture.
More visual insights#
More on figures

🔼 This figure illustrates different strategies for managing the key-value (KV) cache in large language model (LLM) inference. The KV cache stores intermediate activations crucial for efficient attention computation. The figure shows three scenarios: (1) No offloading: the entire KV cache resides in GPU memory, which is inefficient for long sequences; (2) Layer-wise offloading: KV cache for each layer is treated as a single unit, and a portion may be offloaded to CPU RAM, reducing GPU memory footprint, but the granularity is quite coarse; (3) HeadInfer: the KV cache is managed at a much finer granularity - per attention head. Only the necessary heads’ KV cache remain in GPU memory, with others offloaded to CPU RAM, offering a significant reduction in GPU memory use compared to Layer-wise offloading. This head-wise adaptive strategy optimizes memory usage dynamically during inference.
read the caption
Figure 2: Demonstrations of KV cache policies in inference. Full KV cache contains two main dimensions: layer and head. Layer-wise offloads KV cache in the layer’s dimension, with a cache budget of all heads per layer. HeadInfer further reduces GPU memory by adaptively reallocating cache budgets in the head’s dimension, with a cache budget of one head.

🔼 Figure 3 illustrates the different granularities of various LLMs inference methods. Each cube visually represents the entire attention process, broken down into three dimensions: sequence length (S), number of layers (L), and number of attention heads (H). Standard inference loads the entire computation onto the GPU, resulting in high memory consumption. Chunked pre-filling optimizes memory usage by processing only a portion of the sequence at a time. Layer-wise offloading reduces memory footprint by moving some layers from GPU memory to CPU memory. Finally, HeadInfer employs a head-wise approach, significantly reducing memory needs by keeping only a small subset of attention heads in GPU memory and offloading the rest to the CPU, offering the finest granularity.
read the caption
Figure 3: Granularity of different methods. Each cube represents the entire attention process along three dimensions: Sequence (S), Layers (L), and Heads (H). Standard inference puts everything on the GPU. Chunked-prefill fetches only a part of the sequence dimension of all tokens on the GPU at a time. Layer-wise offloading fetches a subset of layers on the GPU, offloading the rest. HeadInfer introduces an even finer approach that maintains only selected heads within a layer.

🔼 This figure illustrates the memory management strategy of HEADINFER. Unlike traditional methods where the entire key-value (KV) cache resides on the GPU, HEADINFER partitions the KV cache into individual heads. Only a single head’s KV cache is held on the GPU at any given time, with the remaining heads stored in CPU RAM. The ping-pong memory mechanism is used to efficiently transfer data between the GPU and CPU, ensuring that computation on the GPU is not stalled by data movement. This approach drastically reduces the GPU memory footprint, enabling inference with significantly longer context lengths.
read the caption
Figure 4: HeadInfer snapshot. All parameters are stored on the GPU. Head-wise partitioned KV cache is moved across GPU and CPU with the ping-pong memory.

🔼 This roofline plot visualizes the performance of FlashAttention on an NVIDIA RTX 4090 GPU, contrasting different inference methods with varying context lengths. The plot shows the arithmetic intensity (FLOPs/Byte) on the x-axis, representing the computational efficiency, and the performance in TFLOPs/s on the y-axis. Separate lines represent baseline, offloading, and HEADINFER methods for both prefill (input processing) and decoding (output generation) phases. The plot helps to understand how these methods perform under different levels of computational intensity and whether they are compute-bound or memory-bound. The plot illustrates HEADINFER’s performance relative to other methods under varying context lengths.
read the caption
Figure 5: Flashattention in the roofline plot analysis using the RTX-4090 device setting.

🔼 The figure displays the results of the Needle-in-a-Haystack benchmark, which assesses a model’s ability to accurately identify and retrieve information from a long context. It shows that HeadInfer achieves the same accuracy as standard inference methods, demonstrating its effectiveness in long-context tasks without sacrificing accuracy. The graph likely shows accuracy or other relevant metric across various context lengths, highlighting HeadInfer’s performance consistency across different context sizes.
read the caption
Figure 6: HeadInfer provides equal accuracy as standard inference on the Needle-in-a-Haystack benchmark

🔼 Figure 7 demonstrates the limitations of token eviction methods in handling less relevant information within long contexts. A 10,000-token document from the LongBench benchmark is used, with an added sentence unrelated to the main theme. Existing methods like H2O, which discards less relevant tokens, produce erroneous outputs. Similarly, StreamingLLM, which discards tokens based on the query but retains question tokens, results in hallucinations. In contrast, HeadInfer correctly retrieves the target information, even with a 75% reduction in KV cache size, highlighting its robustness and efficiency.
read the caption
Figure 7: Token eviction methods cannot work when querying the less relevant information to the main theme. Here, we use a 10K document from LongBench (Bai et al., 2023b) and add one sentence that is not relevant to the main theme. In this case, H2O discards tokens less relevant to the main theme, leading to error generation. StreamingLLM discards tokens based on the query but remaining question tokens, making it Hallucinations. HeadInfer can successfully output the exact information from the lengthy input, even when we compress 75% of the KV cache

🔼 This roofline plot visualizes the performance of FlashAttention on an NVIDIA A100 GPU, comparing the performance of standard inference, offloading, and HEADINFER methods at different arithmetic intensity levels. It shows the peak performance achievable by the GPU’s memory bandwidth and computational capabilities, revealing whether the kernel is compute-bound or memory-bound under various conditions. This helps in understanding how different inference strategies affect performance by comparing their arithmetic intensity and peak throughput against the GPU’s theoretical limits.
read the caption
Figure 8: Flashattention in the roofline plot analysis using A100 device setting.

🔼 This figure compares different KV cache management strategies for LLM inference. The upper part uses symbolic cubes to visualize the different granularities of the approaches. Standard inference keeps all keys and values in GPU memory. Chunked prefill loads only a portion of the sequence into GPU memory at a time. Layer-wise offloading loads a subset of layers into memory at once, while head-wise offloading loads only a small number of attention heads into memory at once. The lower part illustrates the HeadInfer architecture, showing the interplay between CPU and GPU and the adaptive head-wise offloading strategy.
read the caption
Figure 9: Demonstrations of KV cache policies in inference from the head-wise view. Upper plots illustrate symbolic plots of an attention map deploying different policies in LLM generation. Lower: the overview of HeadInfer.

🔼 This figure illustrates the workflow of HeadInfer, a memory-efficient inference framework, during the generation of a model with (n+1) layers and (j+1) attention heads. It showcases the interplay between the GPU and CPU in managing the KV cache, highlighting the asynchronous data transfer and prefetching mechanisms. The GPU processes one head at a time while concurrently prefetching the next head’s data from CPU memory, enabling overlapping computations and data transfers. The CPU manages the offloaded KV cache for the remaining heads. Asynchronous data transfers between the GPU and CPU are facilitated using PCIe, minimizing transfer delays. The diagram visualizes the movement of data between the GPU and CPU memories during prefill and decoding stages, emphasizing the optimized utilization of both GPU and CPU resources for efficient long-context LLM inference.
read the caption
Figure 10: Workflow of HeadInfer generating a model with (n+1) layers and (j+1) attention heads.
More on tables
| SCBench | kv | prefix-suffix | vt | qa-chn | qa-eng | choice-eng | mf | many-shot | summary |
|---|---|---|---|---|---|---|---|---|---|
| Standard 25K | 15.8 | 9.6 | 4.6 | 9.4 | 13.3 | 36.5 | 2.6 | 16.3 | 32.3 |
| Chunked Prefill 30K | 21.4 | 10.4 | 6.9 | 9.4 | 15.5 | 38.6 | 2.2 | 25.2 | 33.5 |
| Layer-wise offload 45K | 22.6 | 12.8 | 8.4 | 10.4 | 15.7 | 37.8 | 2.2 | 25.9 | 33.6 |
| HeadInfer 1024K | 28 | 17.2 | 42 | 11.9 | 23.0 | 59.8 | 9.4 | 25.9 | 37.1 |
🔼 This table presents a comprehensive comparison of different LLMs’ performance on the SCBench benchmark, utilizing a single NVIDIA RTX 4090 GPU. The benchmark encompasses a range of tasks, including string retrieval (key-value and prefix-suffix), variable tracking (vt), question answering (English and Chinese, multiple-choice), math problem solving (mf), multi-shot reasoning (many-shot), and document summarization (summary). Each row represents a different method for performing inference and their resulting performance score on each of these SCBench sub-tasks. The table allows for comparison of various approaches in terms of their ability to handle long-context tasks and their overall performance.
read the caption
Table 2: Performance(benchmark score) of different methods on SCBench on a single RTX-4090 GPU. kv and prefix-suffix are string retrieval in key-value and prefix-suffix scenarios. vt is variable tracking. qa-chn, qa-eng, and choice-eng are English/Chinese question answering. mf is finding the math answer. many-shot is finding multiple shots in context. summary is document summarization.
| Context Length | Llama-3-8B | Llama-2-7B | Mistral-7B | Qwen2-7B | Gemma-2-9b |
|---|---|---|---|---|---|
| Standard | 25K | 10K | 30K | 35K | 10K |
| Chunked Prefill | 30K | 20K | 40K | 70K | 10K |
| 4-bit KV-quant | 45K | 30K | 40K | 50K | 20K |
| Layer-wise offload | 45K | 60K | 45K | 50K | 35K |
| HeadInfer | 4096K | 1024K | 4096K | 4200K | 1300K |
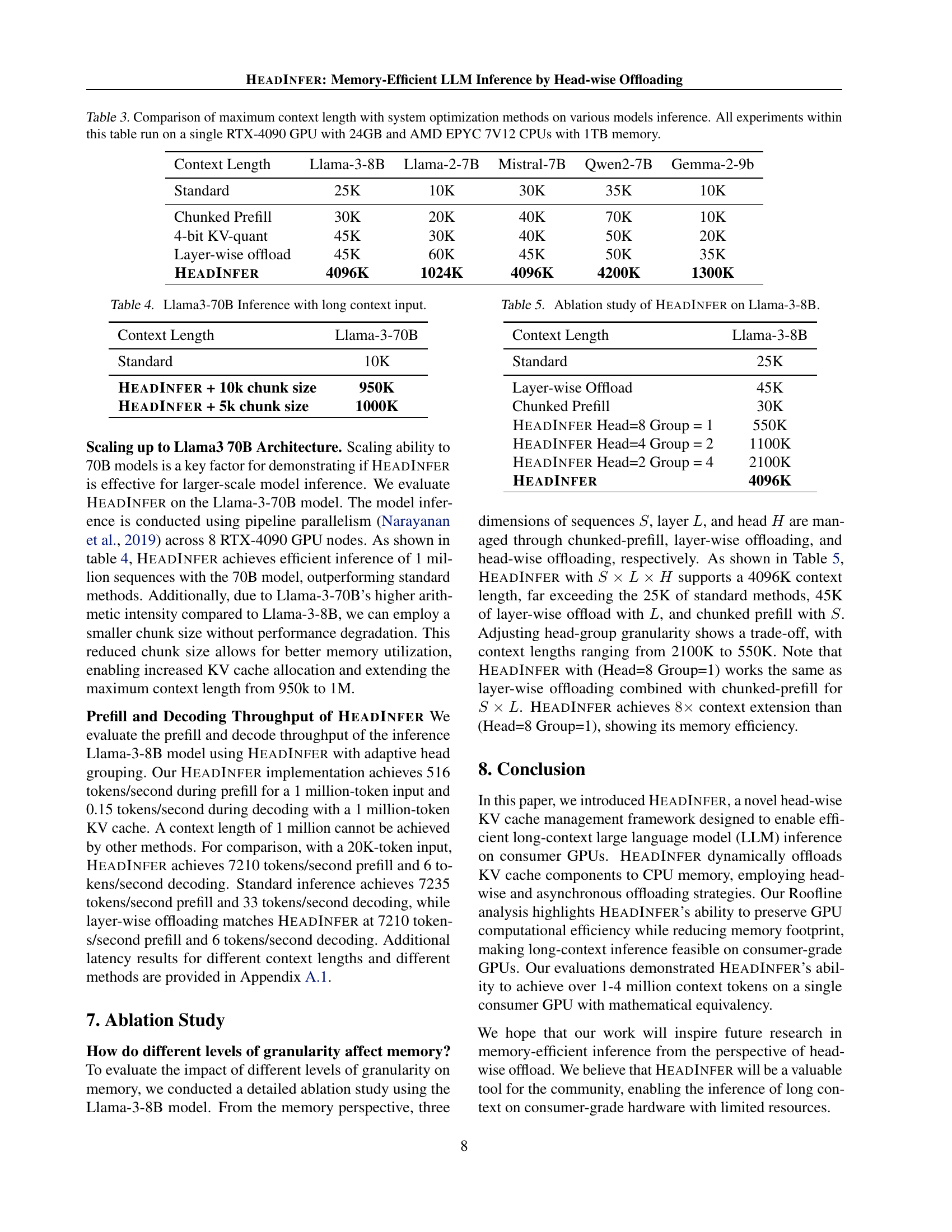
🔼 Table 3 compares the maximum context length achievable by different inference optimization methods across various large language models (LLMs). The experiments were conducted using a single NVIDIA RTX 4090 GPU with 24GB of memory, along with AMD EPYC 7V12 CPUs and 1TB of RAM. The table presents the context length limits for standard inference, Chunked Prefill, 4-bit KV quantization, Layer-wise offloading, and HEADINFER methods. This comparison demonstrates the impact of each optimization strategy on extending context length for different LLMs.
read the caption
Table 3: Comparison of maximum context length with system optimization methods on various models inference. All experiments within this table run on a single RTX-4090 GPU with 24GB and AMD EPYC 7V12 CPUs with 1TB memory.
| Context Length | Llama-3-70B |
|---|---|
| Standard | 10K |
| HeadInfer + 10k chunk size | 950K |
| HeadInfer + 5k chunk size | 1000K |
🔼 This table presents the results of inference experiments conducted on the Llama3-70B model using HEADINFER. It demonstrates HEADINFER’s ability to handle long input sequences, specifically comparing the maximum context length achieved under standard inference and HEADINFER with different chunk sizes. The results highlight HEADINFER’s efficiency in processing significantly longer contexts.
read the caption
Table 4: Llama3-70B Inference with long context input.
| Context Length | Llama-3-8B |
|---|---|
| Standard | 25K |
| Layer-wise Offload | 45K |
| Chunked Prefill | 30K |
| HeadInfer Head=8 Group = 1 | 550K |
| HeadInfer Head=4 Group = 2 | 1100K |
| HeadInfer Head=2 Group = 4 | 2100K |
| HeadInfer | 4096K |
🔼 This table presents the results of an ablation study conducted to evaluate the impact of different granularity levels (sequence, layer, and head) on the memory efficiency of the HEADINFER model. It uses the Llama-3-8B model and compares the maximum context length achieved by different approaches: Standard inference, Layer-wise offload, Chunked Prefill, and HEADINFER with varying head group sizes.
read the caption
Table 5: Ablation study of HeadInfer on Llama-3-8B.
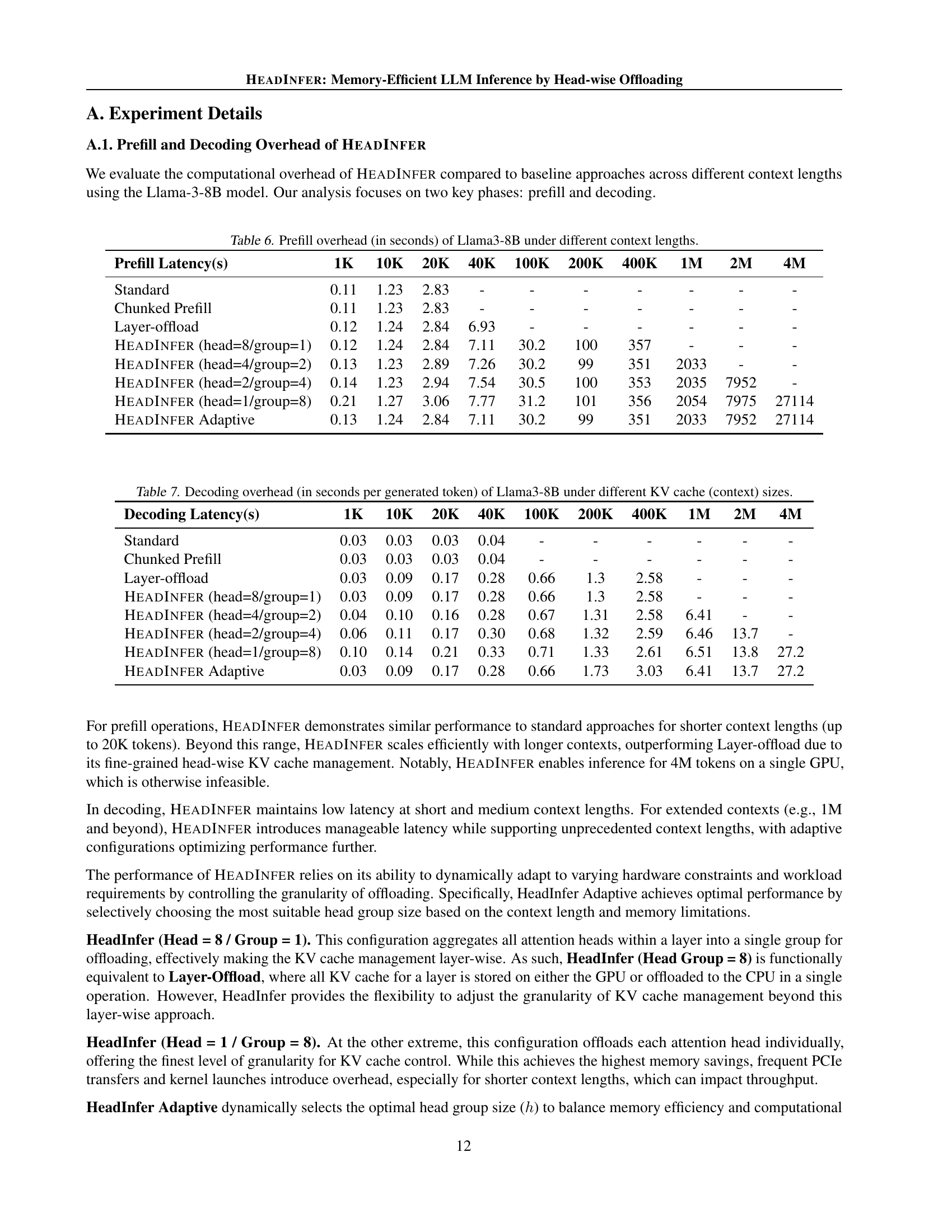
| Prefill Latency(s) | 1K | 10K | 20K | 40K | 100K | 200K | 400K | 1M | 2M | 4M |
|---|---|---|---|---|---|---|---|---|---|---|
| Standard | 0.11 | 1.23 | 2.83 | - | - | - | - | - | - | - |
| Chunked Prefill | 0.11 | 1.23 | 2.83 | - | - | - | - | - | - | - |
| Layer-offload | 0.12 | 1.24 | 2.84 | 6.93 | - | - | - | - | - | - |
| HeadInfer (head=8/group=1) | 0.12 | 1.24 | 2.84 | 7.11 | 30.2 | 100 | 357 | - | - | - |
| HeadInfer (head=4/group=2) | 0.13 | 1.23 | 2.89 | 7.26 | 30.2 | 99 | 351 | 2033 | - | - |
| HeadInfer (head=2/group=4) | 0.14 | 1.23 | 2.94 | 7.54 | 30.5 | 100 | 353 | 2035 | 7952 | - |
| HeadInfer (head=1/group=8) | 0.21 | 1.27 | 3.06 | 7.77 | 31.2 | 101 | 356 | 2054 | 7975 | 27114 |
| HeadInfer Adaptive | 0.13 | 1.24 | 2.84 | 7.11 | 30.2 | 99 | 351 | 2033 | 7952 | 27114 |
🔼 This table presents the time (in seconds) taken for the prefill stage of Llama-3-8B model inference under different context lengths. The prefill stage processes the input prompt and builds the key-value cache. The table compares the standard inference method against several optimization techniques, showing how prefill times change with longer sequences and different optimization strategies (chunked prefill and different HEADINFER configurations). The goal is to demonstrate the efficiency gains and scalability of HEADINFER for long-context inputs.
read the caption
Table 6: Prefill overhead (in seconds) of Llama3-8B under different context lengths.
| Decoding Latency(s) | 1K | 10K | 20K | 40K | 100K | 200K | 400K | 1M | 2M | 4M |
|---|---|---|---|---|---|---|---|---|---|---|
| Standard | 0.03 | 0.03 | 0.03 | 0.04 | - | - | - | - | - | - |
| Chunked Prefill | 0.03 | 0.03 | 0.03 | 0.04 | - | - | - | - | - | - |
| Layer-offload | 0.03 | 0.09 | 0.17 | 0.28 | 0.66 | 1.3 | 2.58 | - | - | - |
| HeadInfer (head=8/group=1) | 0.03 | 0.09 | 0.17 | 0.28 | 0.66 | 1.3 | 2.58 | - | - | - |
| HeadInfer (head=4/group=2) | 0.04 | 0.10 | 0.16 | 0.28 | 0.67 | 1.31 | 2.58 | 6.41 | - | - |
| HeadInfer (head=2/group=4) | 0.06 | 0.11 | 0.17 | 0.30 | 0.68 | 1.32 | 2.59 | 6.46 | 13.7 | - |
| HeadInfer (head=1/group=8) | 0.10 | 0.14 | 0.21 | 0.33 | 0.71 | 1.33 | 2.61 | 6.51 | 13.8 | 27.2 |
| HeadInfer Adaptive | 0.03 | 0.09 | 0.17 | 0.28 | 0.66 | 1.73 | 3.03 | 6.41 | 13.7 | 27.2 |
🔼 This table presents the decoding time (in seconds) needed to generate each new token for the Llama-3-8B language model. The decoding time is measured under various context sizes (1K, 10K, 20K, 40K, 100K, 200K, 400K, 1M, 2M, and 4M tokens). The table compares different inference methods, illustrating how decoding time changes as the context length increases and when different strategies (Standard, Chunked Prefill, Layer-offload, and various HEADINFER configurations) are used.
read the caption
Table 7: Decoding overhead (in seconds per generated token) of Llama3-8B under different KV cache (context) sizes.
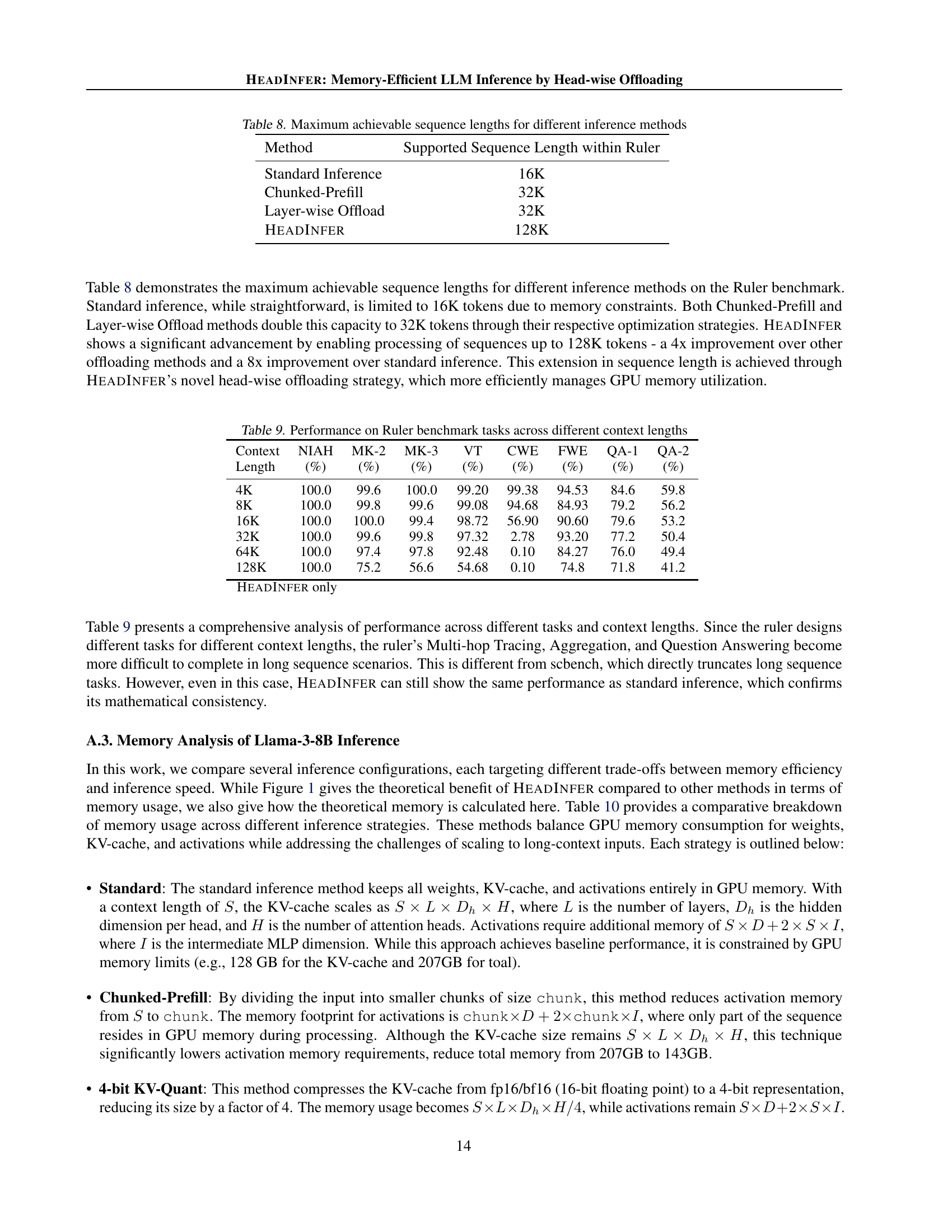
| Method | Supported Sequence Length within Ruler |
|---|---|
| Standard Inference | 16K |
| Chunked-Prefill | 32K |
| Layer-wise Offload | 32K |
| HeadInfer | 128K |
🔼 This table compares the maximum context lengths supported by different inference methods on the Ruler benchmark dataset. It shows how various optimization strategies impact the model’s ability to handle longer sequences. The methods compared include standard inference, chunked prefill, layer-wise offloading, and HEADINFER. The results highlight the significant improvement in maximum context length achieved by HEADINFER, demonstrating its effectiveness in managing GPU memory resources.
read the caption
Table 8: Maximum achievable sequence lengths for different inference methods
| Context | NIAH | MK-2 | MK-3 | VT | CWE | FWE | QA-1 | QA-2 |
|---|---|---|---|---|---|---|---|---|
| Length | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) |
| 4K | 100.0 | 99.6 | 100.0 | 99.20 | 99.38 | 94.53 | 84.6 | 59.8 |
| 8K | 100.0 | 99.8 | 99.6 | 99.08 | 94.68 | 84.93 | 79.2 | 56.2 |
| 16K | 100.0 | 100.0 | 99.4 | 98.72 | 56.90 | 90.60 | 79.6 | 53.2 |
| 32K | 100.0 | 99.6 | 99.8 | 97.32 | 2.78 | 93.20 | 77.2 | 50.4 |
| 64K | 100.0 | 97.4 | 97.8 | 92.48 | 0.10 | 84.27 | 76.0 | 49.4 |
| 128K | 100.0 | 75.2 | 56.6 | 54.68 | 0.10 | 74.8 | 71.8 | 41.2 |
| HeadInfer only | ||||||||
🔼 This table presents the performance of the HEADINFER model on the Ruler benchmark across various context lengths. The Ruler benchmark is a comprehensive suite of tasks designed to evaluate a model’s ability to accurately identify and retrieve information from long contexts. This table shows the performance for different context lengths (4K, 8K, 16K, 32K, 64K, 128K tokens) across multiple tasks within the benchmark, specifically focusing on the following categories: Needle-in-a-Haystack (various subtasks), Multi-hop Tracing, Aggregation (Common Words Extraction and Frequent Words Extraction), and Question Answering. The performance is represented as a percentage, indicating the accuracy of the model on each task at each context length.
read the caption
Table 9: Performance on Ruler benchmark tasks across different context lengths
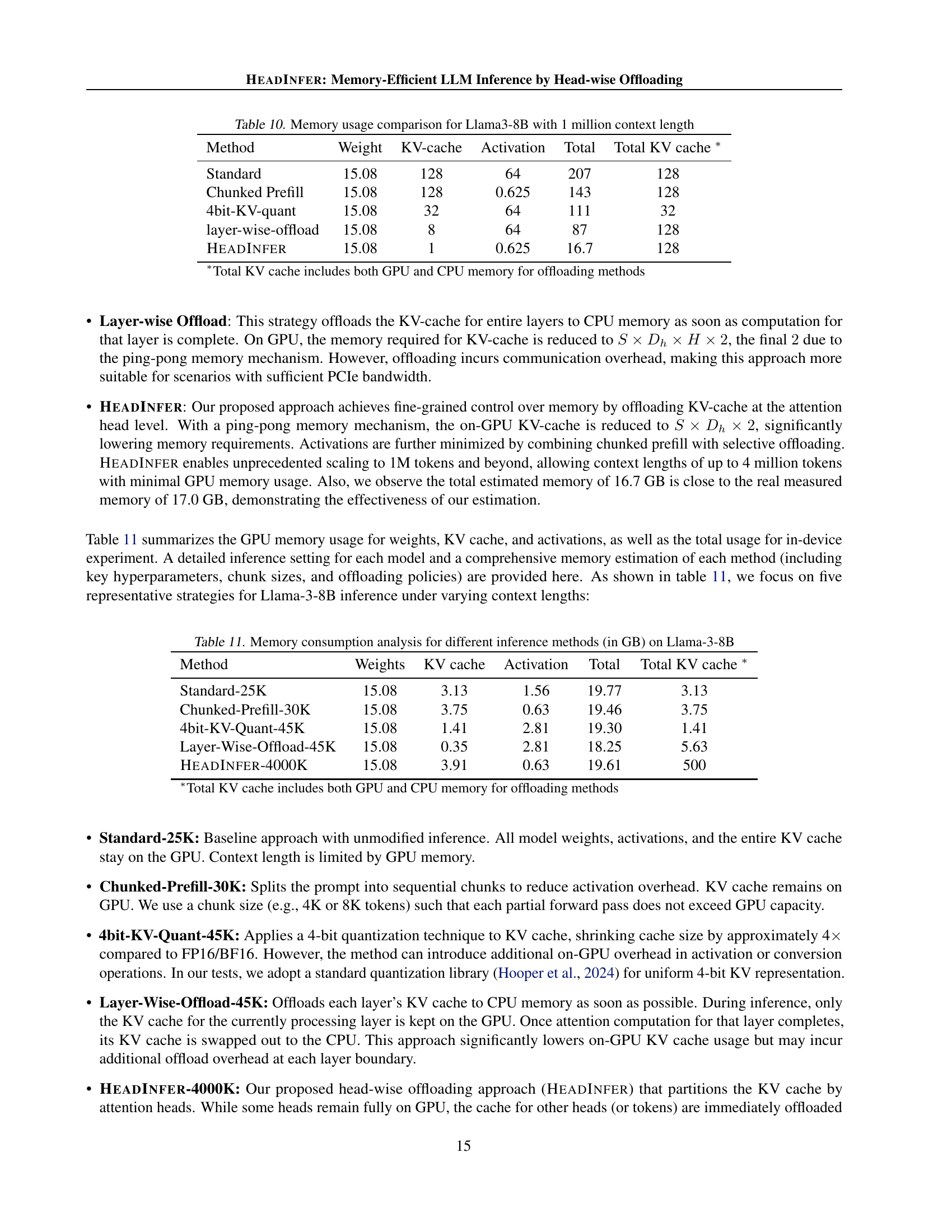
| Method | Weight | KV-cache | Activation | Total | Total KV cache ∗ |
|---|---|---|---|---|---|
| Standard | 15.08 | 128 | 64 | 207 | 128 |
| Chunked Prefill | 15.08 | 128 | 0.625 | 143 | 128 |
| 4bit-KV-quant | 15.08 | 32 | 64 | 111 | 32 |
| layer-wise-offload | 15.08 | 8 | 64 | 87 | 128 |
| HeadInfer | 15.08 | 1 | 0.625 | 16.7 | 128 |
| ∗Total KV cache includes both GPU and CPU memory for offloading methods | |||||
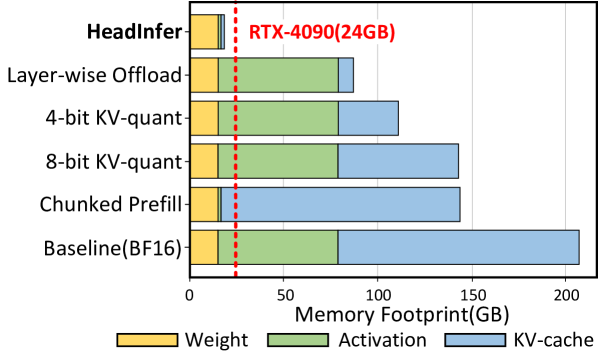
🔼 This table compares the GPU memory usage of different inference methods for the Llama-3-8B large language model when processing a 1 million token context. It breaks down the memory usage into the key components: Weights (model parameters), KV-cache (key-value cache used for attention), and Activations (intermediate activations during computation). It shows how different optimization techniques like chunked pre-filling, 4-bit quantization, and layer-wise offloading affect the memory footprint. The key highlight is the substantial reduction in memory usage achieved by HEADINFER, which uses a head-wise offloading strategy.
read the caption
Table 10: Memory usage comparison for Llama3-8B with 1 million context length
| Method | Weights | KV cache | Activation | Total | Total KV cache ∗ |
|---|---|---|---|---|---|
| Standard-25K | 15.08 | 3.13 | 1.56 | 19.77 | 3.13 |
| Chunked-Prefill-30K | 15.08 | 3.75 | 0.63 | 19.46 | 3.75 |
| 4bit-KV-Quant-45K | 15.08 | 1.41 | 2.81 | 19.30 | 1.41 |
| Layer-Wise-Offload-45K | 15.08 | 0.35 | 2.81 | 18.25 | 5.63 |
| HeadInfer-4000K | 15.08 | 3.91 | 0.63 | 19.61 | 500 |
| ∗Total KV cache includes both GPU and CPU memory for offloading methods | |||||
🔼 This table presents a detailed breakdown of GPU memory usage (in GB) for different Llama-3-8B inference methods, including standard inference, chunked prefill, 4-bit KV quantization, layer-wise offloading, and HEADINFER. For each method, it shows the memory consumption for weights, KV cache, and activations, along with the total memory used and the total KV cache size. The total KV cache size includes both GPU and CPU memory, if applicable. This comparison highlights the memory efficiency gains achieved by each optimization technique in handling long-context inference.
read the caption
Table 11: Memory consumption analysis for different inference methods (in GB) on Llama-3-8B
| Operator | Regular | Offload | ||||||||||||
| Ops | Memory |
| FLOPS | Bound |
|
| FLOPS | Bound | ||||||
| Prefill | ||||||||||||||
| flashattention (1k) | 17G | 21M | 820 | 165T | compute | 4.2M | 4100 | 102T | memory | |||||
| flashattention (10k) | 1.7T | 209M | 8200 | 165T | compute | 42M | 41000 | 165T | compute | |||||
| flashattention (100k) | 172T | 2.1G | 82000 | 165T | compute | 419M | 410000 | 165T | compute | |||||
| head-wise (1k) | 2.1G | 2.6M | 820 | 165T | compute | 0.5M | 4100 | 102T | memory | |||||
| head-wise (10k) | 215G | 26M | 8200 | 165T | compute | 5.2M | 41000 | 312T | compute | |||||
| head-wise (100k) | 21T | 262M | 82000 | 165T | compute | 52M | 410000 | 312T | compute | |||||
| Decode | ||||||||||||||
| flashattention (1k) | 17M | 17M | 1 | 1T | memory | 17M | 1 | 13G | memory | |||||
| flashattention (10k) | 168M | 168M | 1 | 1T | memory | 168M | 1 | 13G | memory | |||||
| flashattention (100k) | 1.7G | 1.7G | 1 | 1T | memory | 1.7G | 1 | 13G | memory | |||||
| head-wise (1k) | 2.1M | 2.1M | 1 | 1T | memory | 2.1M | 1 | 13G | memory | |||||
| head-wise (10k) | 21M | 21M | 1 | 1T | memory | 21M | 1 | 13G | memory | |||||
| head-wise (100k) | 210M | 210M | 1 | 1T | memory | 210M | 1 | 13G | memory | |||||
🔼 This table presents a performance comparison of different attention mechanisms implemented on an NVIDIA RTX 4090 GPU. It compares the performance of standard FlashAttention against a head-wise offloading approach for prefill and decoding stages at varying sequence lengths (1K, 10K, and 100K tokens). Metrics include operations (Ops), memory usage, arithmetic intensity, FLOPS, whether the operation was compute-bound or memory-bound, and the KV cache size. This analysis helps determine the effectiveness of head-wise offloading in terms of computational efficiency and memory footprint.
read the caption
Table 12: Performance comparison of different attention mechanisms under RTX-4090 setting
| Arithmetic |
| Intensity |
🔼 This table presents a performance comparison of different attention mechanisms on an NVIDIA A100 GPU. It shows the number of operations (Ops), memory usage (Memory), arithmetic intensity, theoretical peak FLOPS (GFLOPS), whether the computation is compute-bound or memory-bound, and KV cache size for both prefill and decoding phases of the attention mechanism. The comparison is made across different context lengths (1K, 10K, and 100K tokens) for different attention mechanisms: Flashattention and HEADINFER’s head-wise offloading strategy.
read the caption
Table 13: Performance comparison of different attention mechanisms under A100 setting
| Memory |
| (KV cache) |
🔼 This table presents a comparison of the performance of the HEADINFER model with and without 50% sparsity in terms of prefill and decoding latency. The experiment involves processing a 1 million-token context (1M). The results show the effect of incorporating sparsity into the HEADINFER model on performance.
read the caption
Table 14: Prefill 1M, Decoding with 1M KV cache performance comparison
Full paper#