TL;DR#
Large Language Models (LLMs) often suffer from prompt brittleness; even slight variations significantly affect their performance after fine-tuning. This is because existing supervised fine-tuning (SFT) methods typically overfit to specific prompt formats, hindering generalization to unseen prompts. This issue is particularly problematic in real-world scenarios where diverse human-written prompts are common.
To tackle this, researchers propose Prompt-Agnostic Fine-Tuning (PAFT), a novel approach that dynamically adjusts prompts during training. PAFT uses a diverse set of synthetic prompts generated using multiple LLMs, randomly sampling from this set during training. This approach encourages the model to learn underlying task principles rather than overfitting specific prompt formulations. Experimental results show that PAFT achieves state-of-the-art performance and significantly enhanced robustness across diverse benchmarks, with faster inference times compared to baseline methods.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of current fine-tuning methods for large language models (LLMs): prompt brittleness. By introducing PAFT, researchers gain a novel technique to improve the robustness and generalization of LLMs, leading to more reliable and efficient real-world applications. Its focus on prompt-agnostic training opens new avenues for research in improving LLM adaptability and reducing the reliance on carefully crafted prompts.
Visual Insights#

🔼 The figure illustrates the impact of minor prompt variations on the accuracy of a large language model (LLM). Two examples of the same question, with slight differences in their prompts, showcase drastically different accuracy rates. One prompt yields 86.27% accuracy, while the other drops to 66.93%, highlighting the vulnerability of LLMs to even small prompt modifications if not robust.
read the caption
Figure 1: This figure shows how small changes in prompts can drastically affect the accuracy of a model. Two examples show the same user question, but the prompts differ by only one word, resulting in different answers. The first prompt achieves 86.27% accuracy across the entire dataset, while the second prompt drops significantly to 66.93%. This highlights how even small modifications can lead to large swings in performance if a model lacks prompt robustness.
| Methods | Hellaswag | PIQA | Winogrande | RACE-mid | RACE-high | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Mean | Std | Top | Mean | Std | Top | Mean | Std | Top | Mean | Std | Top | Mean | Std | Top | Mean | Std | Top |
| Base Model | 47.36 | 9.78 | 0% | 74.68 | 6.24 | 0% | 45.15 | 11.78 | 0% | 71.39 | 7.33 | 0% | 67.62 | 6.78 | 0% | 61.24 | 8.38 | 0% |
| user-specified prompt | 92.35 | 2.78 | 0% | 77.87 | 2.36 | 0% | 78.16 | 7.97 | 0% | 79.88 | 6.32 | 22% | 81.05 | 4.45 | 4% | 81.86 | 4.78 | 5% |
| TopAccuracy prompt | 91.27 | 2.79 | 86% | 75.96 | 3.89 | 0% | 66.77 | 3.94 | 0% | 84.81 | 4.06 | 59% | 82.45 | 3.26 | 14% | 80.25 | 3.63 | 32% |
| BATprompt | 90.30 | 1.79 | 78% | 83.41 | 1.74 | 16% | 69.01 | 4.45 | 0% | 83.92 | 5.38 | 65% | 81.33 | 4.21 | 12% | 81.56 | 3.51 | 34% |
| ZOPO prompt | 92.46 | 2.43 | 86% | 83.52 | 2.23 | 27% | 74.75 | 3.81 | 0% | 83.50 | 5.05 | 51% | 82.36 | 4.53 | 35% | 83.32 | 3.61 | 40% |
| PAFT | 93.83 | 0.70 | 100% | 89.33 | 0.63 | 100% | 82.09 | 0.81 | 100% | 87.26 | 2.23 | 94% | 85.17 | 1.71 | 73% | 87.57 | 1.57 | 94% |
| PAFT Improvement | +1.37 | -1.09 | 14% | +5.81 | -1.11 | 73% | +3.93 | -3.00 | 100% | +2.45 | -1.83 | 29% | +2.72 | -1.55 | 38% | +4.25 | -1.94 | 54% |
🔼 Table 1 compares the performance of various prompt-based fine-tuning methods on four datasets (Hellaswag, Winogrande, PIQA, RACE). The methods compared are a baseline (pre-trained model), fine-tuning with human-designed prompts, fine-tuning with the top-performing prompt from training, fine-tuning with a robust prompt from BATprompt, fine-tuning with an optimal prompt from ZOPO, and the proposed PAFT method. The table shows average accuracy, standard deviation, and the percentage of prompts exceeding specific accuracy thresholds (dataset-specific). PAFT outperforms other methods, showing both higher accuracy and lower variance. The final rows highlight PAFT’s improvement over the second-best method.
read the caption
Table 1: Performance comparison of different fine-tuning methods on the test prompt sets across various reasoning and reading comprehension tasks using the LLaMA3-8B Meta (2024) with LoRA rank 8. Results are reported as average accuracy, standard deviation, and percentage of test prompts exceeding a specific score threshold (90% for Hellaswag, 80% for Winogrande, and 85% for other datasets). The Base Model represents the pre-trained model without fine-tuning, user-specified prompt Wei et al. (2024) refers to fine-tuning with LoRA using human-designed prompts, TopAccuracy prompt refers to fine-tuning with LoRA using the prompt exhibiting the highest accuracy on the training set, BATprompt refers to fine-tuning with LoRA using the most robust prompt generated by BATprompt Shi et al. (2024), and ZOPO prompt refers to fine-tuning with LoRA using the optimal prompt selected by ZOPO Hu et al. (2024) from the training prompt set. PAFT (our proposed method) demonstrates superior performance, achieving the highest accuracy and lowest variance across all tasks. The last rows show the comparison of PAFT with the second-best performing method (underlined). The Top column indicates the percentage of test prompts with a correct rate of 90% for Hellaswag, 80% for Winogrande, and 85% for other datasets.
In-depth insights#
Prompt Robustness#
Prompt robustness in large language models (LLMs) is crucial for real-world applications. The ability of an LLM to consistently perform well despite variations in prompt phrasing is paramount. Supervised fine-tuning (SFT), while effective for improving performance on specific tasks, often leads to overfitting to the training prompts, resulting in significant performance degradation when presented with slightly different prompts. This fragility necessitates methods that enhance the generalizability of the models rather than overfitting to specific prompt patterns. Prompt-agnostic fine-tuning (PAFT) emerges as a promising technique to address this issue. By dynamically sampling from a diverse set of prompts during training, PAFT encourages the model to learn underlying task principles, rather than relying on specific wordings. The result is improved robustness and generalization, making LLMs more resilient and reliable in practical scenarios with varied user input.
PAFT Framework#
The PAFT (Prompt-Agnostic Fine-Tuning) framework offers a novel approach to enhance the robustness of Large Language Models (LLMs) by dynamically adjusting prompts during the fine-tuning process. Instead of relying on static, pre-defined prompts, PAFT employs a two-stage approach. First, it generates a diverse set of candidate prompts, leveraging the capabilities of multiple LLMs to ensure variety and quality. Second, during training, it randomly samples these prompts to create dynamic training inputs. This strategy encourages the model to learn underlying task principles rather than overfitting to specific prompt formulations, leading to significantly improved robustness and generalization. PAFT’s dynamic nature is key to its success, promoting adaptability to unseen prompts and mitigating the negative impact of minor prompt variations. The framework also demonstrably improves model performance and inference speed while maintaining training efficiency, making it a practical solution for improving LLM robustness in real-world applications.
Dynamic Tuning#
Dynamic tuning, as presented in the context of the research paper, is a crucial innovation in the field of prompt engineering for large language models (LLMs). The core idea revolves around dynamically adjusting prompts during the fine-tuning process, rather than relying on static, fixed prompts. This approach is designed to enhance the robustness of LLMs by encouraging them to learn underlying task principles instead of overfitting to specific prompt formulations. The method involves constructing a diverse set of meaningful synthetic prompts and then randomly sampling these prompts during training. This random selection forces the model to generalize across various prompt variations, thereby improving its adaptability and reducing its dependence on specific wording. A key advantage is improved prompt robustness, resulting in better generalization to unseen prompts and enhanced model performance. The approach also contributes to increased training efficiency and faster inference speeds.
Ablation Studies#
Ablation studies systematically remove components of a model or system to understand their individual contributions. In this context, an ablation study on prompt-agnostic fine-tuning (PAFT) would likely investigate the impact of each PAFT component. For instance, the study might evaluate the effect of removing the dynamic prompt sampling or the candidate prompt generation stage. Analyzing performance changes after each removal helps to quantify the importance of each module and validate the design choices. This process is essential for demonstrating that the improvements in robustness and generalization aren’t solely due to a single factor but rather a synergistic interaction between all parts. Results would showcase whether the core idea of PAFT remains effective even with simplified components, clarifying the necessity of each element for optimal results. It allows researchers to understand the relative importance of different elements in contributing to overall performance. The key here is whether PAFT’s benefits are truly holistic or driven by isolated aspects.
Future Work#
Future research directions for prompt-agnostic fine-tuning (PAFT) should prioritize improving the prompt selection strategy. Moving beyond random sampling to more sophisticated methods like curriculum learning or importance sampling could significantly enhance efficiency and robustness. Exploring incorporation of adversarial training is another promising area, though careful consideration is needed to address the inherent instability of adversarial training techniques. Further investigation into the generalizability of PAFT across different model architectures and sizes is crucial to establish its wider applicability. Finally, a deeper exploration into the interplay between prompt diversity, model capacity, and task complexity would reveal valuable insights into optimizing the PAFT framework and achieving greater performance gains.
More visual insights#
More on figures

🔼 The figure illustrates the core differences between traditional supervised fine-tuning (SFT) and the proposed Prompt-Agnostic Fine-Tuning (PAFT) method. SFT uses a fixed dataset with predefined prompts, leading to overfitting and reduced robustness to variations in prompt wording. In contrast, PAFT employs a dynamic prompt selection strategy during training. It leverages a commercial LLM to generate a diverse set of candidate prompts, which are then randomly sampled during training. This approach significantly improves the model’s robustness and generalizability to unseen prompts, making it more adaptable and scalable.
read the caption
Figure 2: An overview of PAFT: This figure compares Traditional Supervised Fine-tuning (SFT) and Prompt-Agnostic Fine-Tuning (PAFT), highlighting their main differences. SFT relies on a fixed dataset and predefined prompts, which limits its robustness and generalization to different prompts. In contrast, PAFT dynamically selects prompts during training, which improves robustness and generalization to a wide range of prompts. By leveraging a commercial LLM to generate candidate prompts, PAFT provides a more general and scalable solution.

🔼 This figure displays the results of preliminary experiments comparing the performance of a base language model and a model fine-tuned using supervised fine-tuning (SFT) across four datasets. Over 450 diverse prompts were used for evaluation. The results are visualized using probability distribution plots, showing the accuracy distribution for each model. While the SFT model generally performs better, the distributions reveal that even with SFT, the model’s accuracy on certain prompts remains low, and the overall variability in accuracy (as shown by high standard deviation) is significant. This indicates substantial sensitivity to prompt design and a need for improved model optimization techniques.
read the caption
Figure 3: This figure presents the results of preliminary experiments conducted on four datasets to evaluate the accuracy of the base model and the SFT model across over 450 diverse prompts. The probability distribution plots illustrate the distribution of accuracy for models. The results show that while the SFT model has an overall improvement in accuracy compared to the base model, the accuracy of some prompts is still relatively low, and the standard deviation of the SFT model is high, indicating that the accuracy varies greatly between different prompts, which highlights the impact of prompt design and the need for further optimization through model fine-tuning.

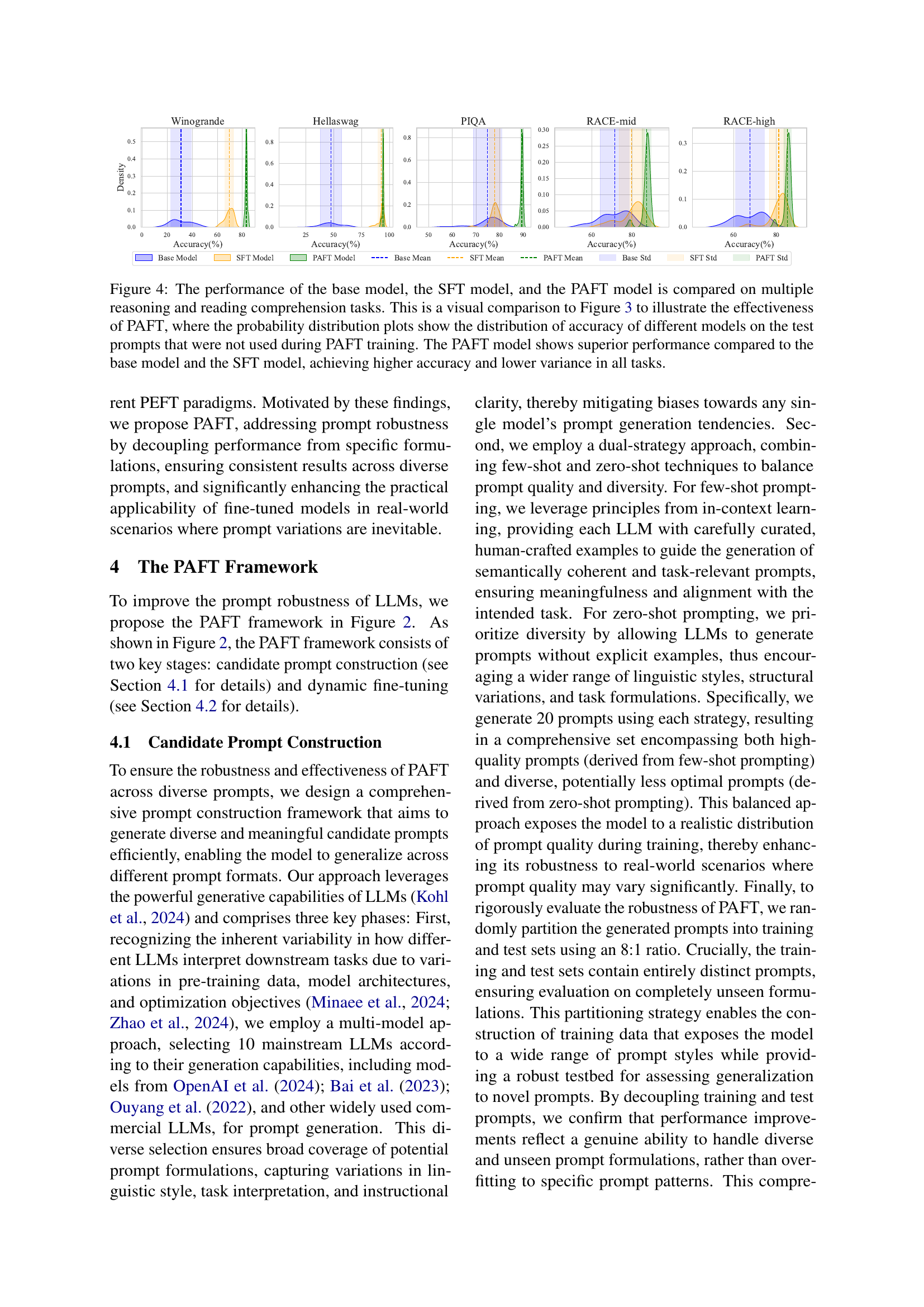
🔼 Figure 4 presents a visual comparison of three models’ performance across multiple reasoning and reading comprehension tasks. Unlike Figure 3 which used prompts seen during training, Figure 4 assesses performance on unseen test prompts. Probability distributions illustrate the accuracy range for each model. The key finding is that the PAFT model significantly outperforms both the base model and the SFT model, achieving higher average accuracy and lower variance (less variability) across all tasks.
read the caption
Figure 4: The performance of the base model, the SFT model, and the PAFT model is compared on multiple reasoning and reading comprehension tasks. This is a visual comparison to Figure 3 to illustrate the effectiveness of PAFT, where the probability distribution plots show the distribution of accuracy of different models on the test prompts that were not used during PAFT training. The PAFT model shows superior performance compared to the base model and the SFT model, achieving higher accuracy and lower variance in all tasks.

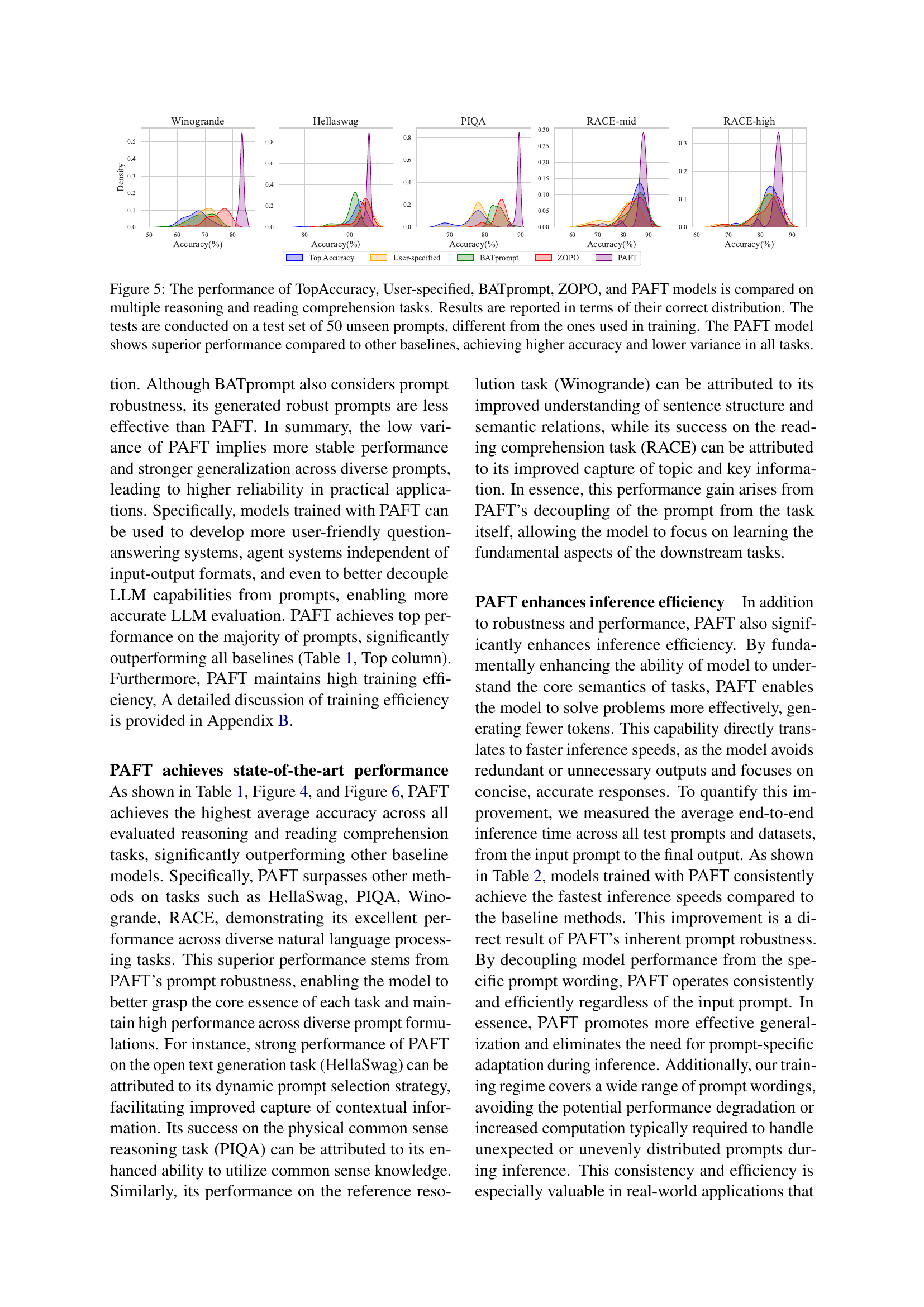
🔼 Figure 5 presents a comparative analysis of five different prompt-based fine-tuning methods across multiple reasoning and reading comprehension tasks. The models compared are: TopAccuracy (using the single best-performing prompt from training), User-specified (using human-designed prompts), BATprompt (a method generating robust prompts), ZOPO (an efficient prompt optimization technique), and PAFT (the proposed prompt-agnostic fine-tuning method). The evaluation employs 50 unseen test prompts, ensuring a robust assessment of generalization. Results are visualized as probability distributions showing the accuracy of each model across these unseen prompts. The figure highlights PAFT’s superior performance, demonstrating higher average accuracy and significantly lower variance (indicating improved robustness and generalization to diverse prompts) compared to all other baselines across all tasks.
read the caption
Figure 5: The performance of TopAccuracy, User-specified, BATprompt, ZOPO, and PAFT models is compared on multiple reasoning and reading comprehension tasks. Results are reported in terms of their correct distribution. The tests are conducted on a test set of 50 unseen prompts, different from the ones used in training. The PAFT model shows superior performance compared to other baselines, achieving higher accuracy and lower variance in all tasks.

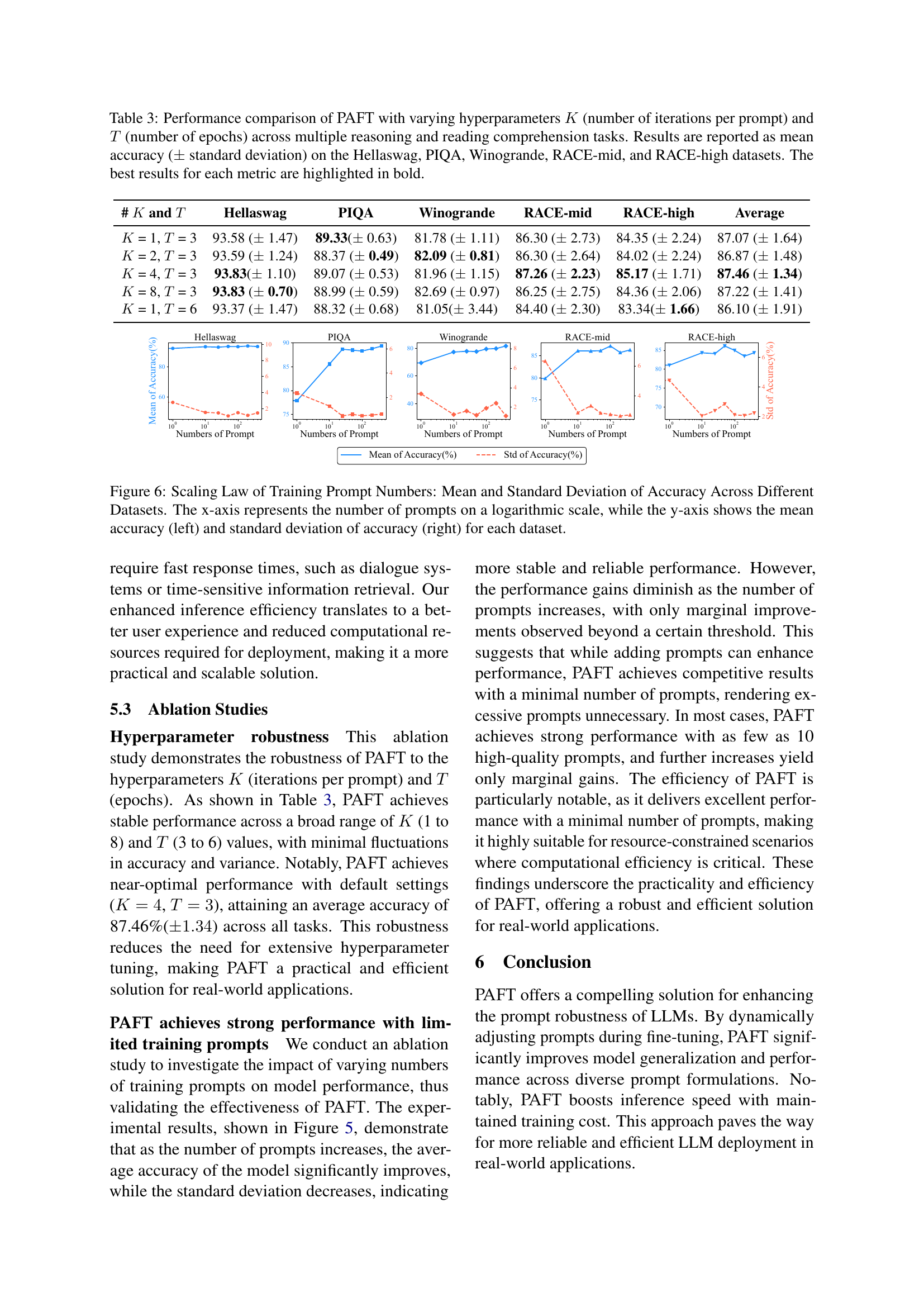
🔼 This figure illustrates the relationship between the number of training prompts and the model’s performance across multiple datasets. The x-axis uses a logarithmic scale to represent the number of training prompts used, while the y-axis displays both the average accuracy (left panel) and the standard deviation of accuracy (right panel) achieved on each dataset. The plot demonstrates that increasing the number of training prompts initially leads to a significant improvement in both the mean accuracy and a reduction in accuracy variance. However, beyond a certain point, the gains diminish, indicating diminishing returns. This suggests that while a diverse set of prompts is beneficial, an excessively large number of prompts doesn’t necessarily translate to substantial performance improvements.
read the caption
Figure 6: Scaling Law of Training Prompt Numbers: Mean and Standard Deviation of Accuracy Across Different Datasets. The x-axis represents the number of prompts on a logarithmic scale, while the y-axis shows the mean accuracy (left) and standard deviation of accuracy (right) for each dataset.
More on tables
| Inference time/h | Hellaswag | PIQA | Winogrande | RACE | Average |
|---|---|---|---|---|---|
| Base Model | 3.97 | 1.35 | 1.72 | 6.24 | 3.32 |
| user-specified prompt | 6.52 | 0.98 | 3.27 | 8.23 | 4.75 |
| TopAccuracy prompt | 5.75 | 1.13 | 2.76 | 7.56 | 4.30 |
| BATprompt | 4.57 | 1.57 | 3.14 | 7.98 | 4.32 |
| ZOPO prompt | 5.12 | 0.87 | 3.23 | 8.28 | 4.38 |
| PAFT | 1.19 | 0.39 | 0.45 | 2.08 | 1.02 |
| PAFT Improvement | 3.3 | 2.23 | 3.82 | 3.00 | 3.25 |
🔼 This table compares the inference time (in hours) required for different fine-tuning methods on various tasks. The baseline is a pre-trained model without any fine-tuning. Other rows show inference time for models fine-tuned using LoRA with different prompt selection strategies: user-specified prompts, prompts with the highest accuracy from the training set, the most robust prompt from BATprompt, the optimal prompt selected by ZOPO, and prompts selected dynamically by PAFT. The final row shows how many times faster PAFT is compared to each method.
read the caption
Table 2: Comparison of inference time (in hours) for different fine-tuning methods. The base model represents the pre-trained model without fine-tuning, while the other rows show the inference time of models fine-tuned with LoRA using different prompts. PAFT shows better inference efficiency than other methods. The last line shows the multiple of PAFT improvement.
| # and | Hellaswag | PIQA | Winogrande | RACE-mid | RACE-high | Average |
|---|---|---|---|---|---|---|
| = 1, = 3 | 93.58 ( 1.47) | 89.33( 0.63) | 81.78 ( 1.11) | 86.30 ( 2.73) | 84.35 ( 2.24) | 87.07 ( 1.64) |
| = 2, = 3 | 93.59 ( 1.24) | 88.37 ( 0.49) | 82.09 ( 0.81) | 86.30 ( 2.64) | 84.02 ( 2.24) | 86.87 ( 1.48) |
| = 4, = 3 | 93.83( 1.10) | 89.07 ( 0.53) | 81.96 ( 1.15) | 87.26 ( 2.23) | 85.17 ( 1.71) | 87.46 ( 1.34) |
| = 8, = 3 | 93.83 ( 0.70) | 88.99 ( 0.59) | 82.69 ( 0.97) | 86.25 ( 2.75) | 84.36 ( 2.06) | 87.22 ( 1.41) |
| = 1, = 6 | 93.37 ( 1.47) | 88.32 ( 0.68) | 81.05( 3.44) | 84.40 ( 2.30) | 83.34( 1.66) | 86.10 ( 1.91) |
🔼 This table presents a comprehensive analysis of PAFT’s performance under various hyperparameter settings. It investigates the impact of changing the number of iterations per prompt (K) and the number of training epochs (T) on the model’s accuracy across five different reasoning and reading comprehension datasets: Hellaswag, PIQA, Winogrande, RACE-mid, and RACE-high. The mean accuracy and standard deviation are reported for each dataset and hyperparameter combination, highlighting the optimal settings that yield the best results for each task.
read the caption
Table 3: Performance comparison of PAFT with varying hyperparameters K𝐾Kitalic_K (number of iterations per prompt) and T𝑇Titalic_T (number of epochs) across multiple reasoning and reading comprehension tasks. Results are reported as mean accuracy (±plus-or-minus\pm± standard deviation) on the Hellaswag, PIQA, Winogrande, RACE-mid, and RACE-high datasets. The best results for each metric are highlighted in bold.
| Number of samples | train dataset | validation dataset | test dataset |
|---|---|---|---|
| Hellaswag | 39900 | 10000 | 10000 |
| PIQA | 16000 | 2000 | 3000 |
| Winogrande | 40398 | 1267 | 1767 |
| RACE | 87866 | 4887 | 4934 |
🔼 This table presents the dataset sizes used in the experiments. For each dataset (Hellaswag, PIQA, Winogrande, RACE), it shows the number of samples used for training, validation, and testing.
read the caption
Table 4: Number of samples in the train, validation, and test datasets for various dateset.
| Methods | LoRA Target | Max Length | SFT Samples | LR | Training Prompts | Epoch |
|---|---|---|---|---|---|---|
| LoRA | q & v Proj | 1024 | 20000 | 0.0001 | 1 | 3 |
| PAFT | q & v Proj | 1024 | 20000 | 0.0001 | 400 | 3 |
🔼 Table 5 details the hyperparameters used in the experiments comparing different fine-tuning methods. It shows the settings for the LoRA target module, maximum sequence length, supervised fine-tuning sample size, learning rate, number of training prompts, and training epochs. Note that all other parameters were kept constant across the experiments.
read the caption
Table 5: Detailed experimental parameters. This table lists the specific parameters we used in the experiments for various methods. These parameters include the target module of LoRA (Lora Target), the maximum sequence length (Max Length), the number of samples for supervised fine-tuning (SFT Samples), the learning rate (LR), the number of training prompts (Training Prompts). Epoch(Epoch) represents the epoch of training. All other parameters not listed here remain consistent across all experiments.
| Training time/h | Hellaswag | PIQA | Winogrande | RACE | Average |
|---|---|---|---|---|---|
| LoRA + user-specified prompt | 3.01 | 2.35 | 3.27 | 3.95 | 3.15 |
| LoRA + TopAccuracy prompt | 3.00 | 2.29 | 2.98 | 3.93 | 3.05 |
| LoRA + BATprompt | 3.02 | 2.23 | 3 | 3.93 | 3.05 |
| LoRA + ZOPO prompt | 2.97 | 2.3 | 2.97 | 3.83 | 3.02 |
| PAFT | 2.98 | 2.32 | 3.38 | 3.81 | 3.12 |
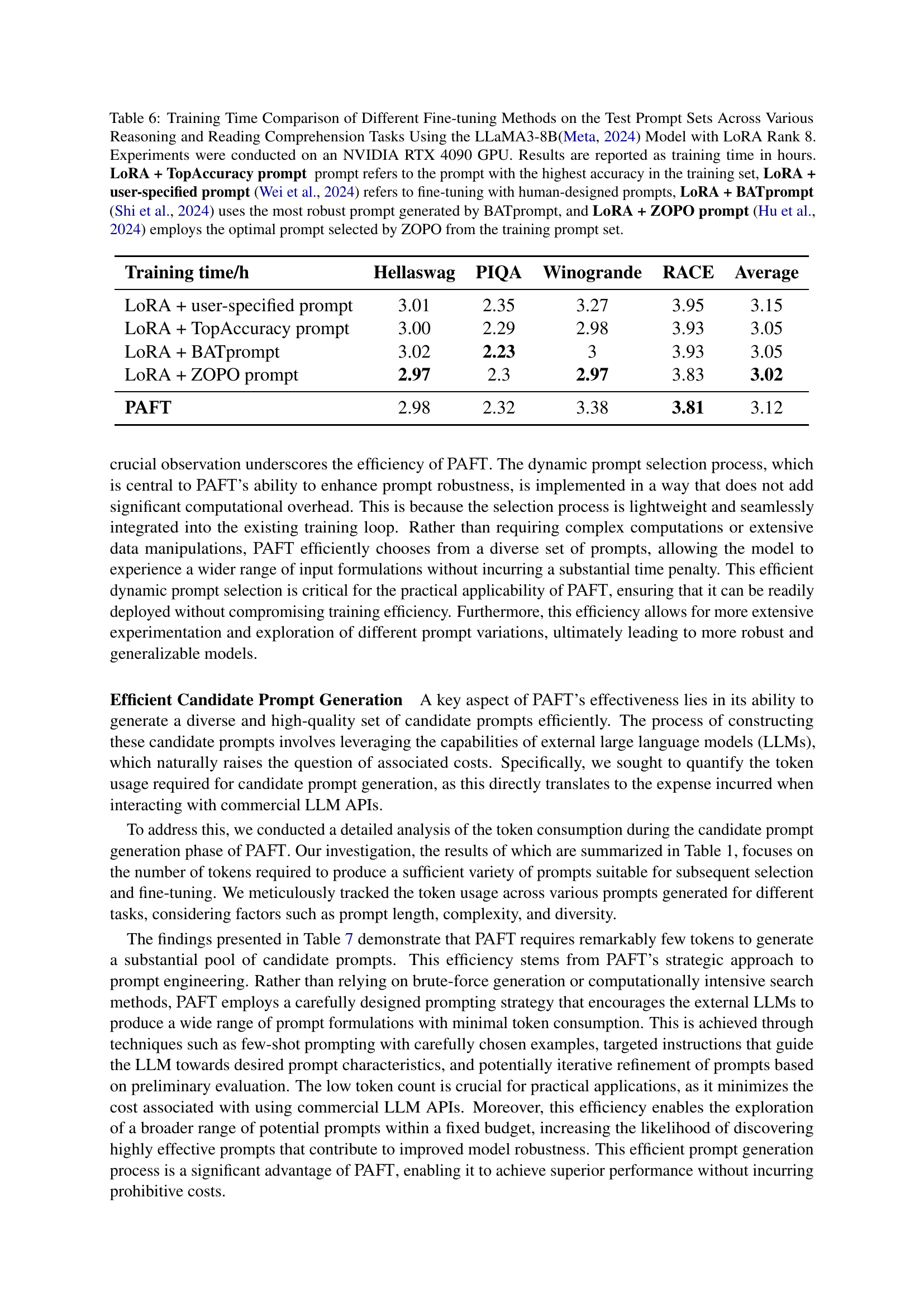
🔼 This table presents a comparison of training times for different fine-tuning methods on various reasoning and reading comprehension tasks using the LLaMA3-8B model with LoRA rank 8. The methods compared include: a baseline using only LoRA, LoRA with a user-specified prompt (as per Wei et al., 2024), LoRA with the prompt yielding the highest accuracy during training (TopAccuracy), LoRA with the most robust prompt (BATprompt from Shi et al., 2024), and LoRA with the optimal prompt chosen by ZOPO (Hu et al., 2024). Training times are reported in hours and were measured using an NVIDIA RTX 4090 GPU. The results show the training efficiency of each method across different datasets. This provides context for evaluating the efficiency of PAFT (Prompt-Agnostic Fine-Tuning) in terms of training time.
read the caption
Table 6: Training Time Comparison of Different Fine-tuning Methods on the Test Prompt Sets Across Various Reasoning and Reading Comprehension Tasks Using the LLaMA3-8BMeta (2024) Model with LoRA Rank 8. Experiments were conducted on an NVIDIA RTX 4090 GPU. Results are reported as training time in hours. LoRA + TopAccuracy prompt prompt refers to the prompt with the highest accuracy in the training set, LoRA + user-specified prompt Wei et al. (2024) refers to fine-tuning with human-designed prompts, LoRA + BATprompt Shi et al. (2024) uses the most robust prompt generated by BATprompt, and LoRA + ZOPO prompt Hu et al. (2024) employs the optimal prompt selected by ZOPO from the training prompt set.
| Tokens | Hellaswag | PIQA | Winogrande | RACE | Average |
|---|---|---|---|---|---|
| Total Tokens | 11.7k | 12.1k | 10.9k | 12.3k | 11.75k |
🔼 This table details the token usage for generating candidate prompts in the PAFT model. It shows the number of tokens required to generate approximately 400 candidate prompts for each of the four tasks (Hellaswag, PIQA, Winogrande, RACE). The average token usage across all tasks is 11,750 tokens. Importantly, the table highlights that the number of generated prompts is a variable and can be adjusted based on the scaling law (presented in Figure 5 of the paper) to manage costs associated with using external LLMs for prompt generation.
read the caption
Table 7: Token Usage for Candidate Prompt Generation. This table shows the number of tokens used to generate approximately 400 candidate prompts for each task. The average token usage is 11.75k. The number of generated prompts can be adjusted based on the scaling law observed in Figure 5 to control costs.
Full paper#