TL;DR#
Current multimodal AI agents often struggle with generalizability across tasks and domains. Existing models are typically trained separately for different environments (e.g., 2D digital vs. 3D physical), hindering their ability to seamlessly handle diverse inputs and complete complex tasks. Furthermore, training data for such models can be limited in size and diversity. These factors limit the progress towards truly general-purpose AI agents capable of handling real-world scenarios effectively.
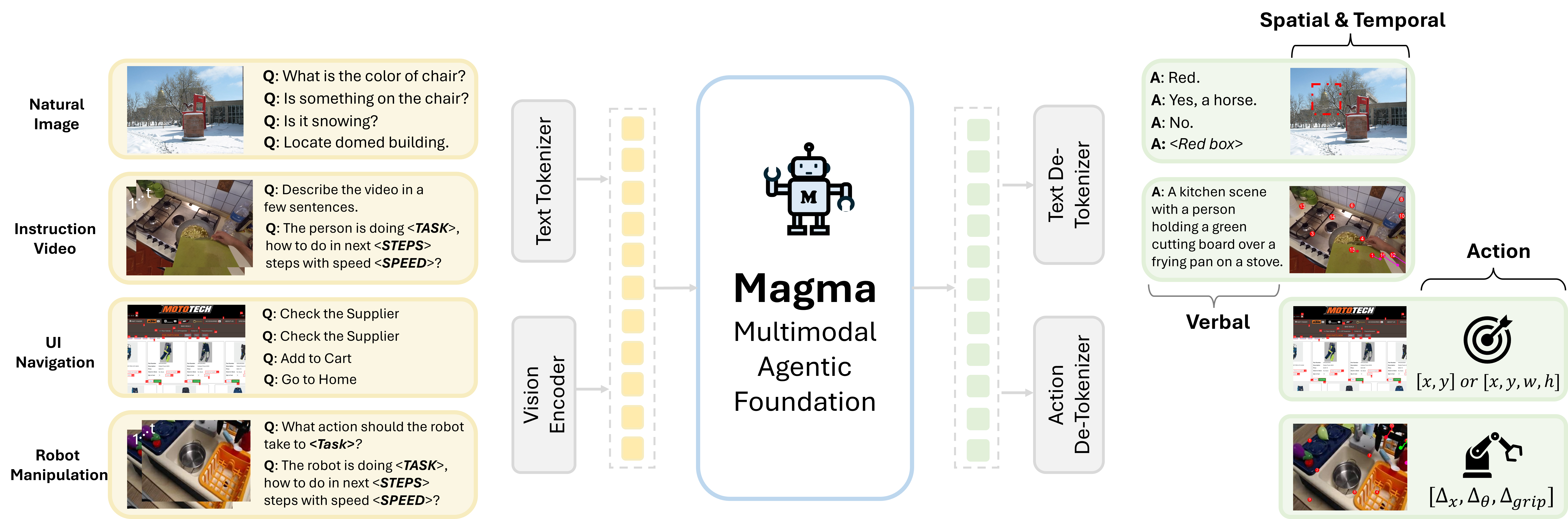
To address these limitations, the researchers present Magma, a foundation model that effectively combines multimodal understanding and action prediction. This is achieved by leveraging large amounts of diverse data (images, videos, robotics data) and using novel training techniques—Set-of-Mark (SoM) and Trace-of-Mark (ToM)—which bridge the gap between verbal and spatial intelligence. Magma demonstrates state-of-the-art performance on UI navigation and robotic manipulation tasks while showing favorable results in other areas as well. The model’s code and data are publicly available, fostering reproducibility and future research.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it introduces Magma, a groundbreaking foundation model for multimodal AI agents. Its ability to bridge verbal and spatial intelligence, achieving state-of-the-art results in diverse tasks (UI navigation, robotic manipulation), offers a significant advancement in the field. Researchers can utilize Magma’s open-source nature and novel training methods (SoM and ToM) to advance their own work on general-purpose AI agents and explore new research directions in multimodal AI.
Visual Insights#
🔼 This figure showcases Magma, a novel foundation model designed for multimodal AI agents. Magma uniquely integrates verbal and spatial intelligence, enabling it to understand and respond to various forms of input (visual and textual), plan actions, and execute those plans in real-world and digital environments. The diagrams illustrate Magma’s ability to accomplish diverse tasks, from interacting with user interfaces and manipulating objects to answering complex questions. This is achieved by leveraging knowledge effectively from freely available data encompassing visuals and language.
read the caption
Figure 1: We introduce Magma, the first foundation model that is capable of interpreting and grounding multimodal inputs within its environment. Given a described goal, Magma is able to formulate plans and execute actions to achieve it. By effectively transferring knowledge from freely available visual and language data, Magma bridges verbal and spatial intelligence to navigate complex tasks.
| Data Type | Set-of-Mark | Trace-of-Mark |
| UI Screenshots | ✓ | ✗ |
| Robotics Images | ✓ | ✓ |
| Instructional Videos | ✓ | ✓ |
🔼 This table shows how the Set-of-Mark (SoM) and Trace-of-Mark (ToM) labeling methods are applied to different data types used in the Magma model’s training. SoM labels actionable objects within images, while ToM labels object movements across video frames to model action planning. The table highlights that ToM is not used for UI data because it consists of discrete screenshots rather than continuous video sequences.
read the caption
Table 1: SoM and ToM applied to various data types. ToM is not applied to UI data as they are a sequence of discrete screenshots.
In-depth insights#
Multimodal AI Agents#
Multimodal AI agents represent a significant advancement in artificial intelligence, aiming to create systems capable of understanding and interacting with the world through multiple modalities like vision, language, and proprioception. The core challenge lies in seamlessly integrating these diverse data streams to enable intelligent action. This requires robust multimodal understanding capabilities to interpret complex scenarios accurately, followed by the ability to plan and execute appropriate actions within dynamic environments. Current research focuses on developing foundation models that can be efficiently transferred to a wide range of downstream tasks to improve generalizability and reduce the need for task-specific training. This involves training on vast amounts of heterogeneous data and designing effective surrogate tasks, such as action grounding and planning, to bridge the semantic gap between different modalities and facilitate the acquisition of spatial-temporal intelligence. A key area of exploration is the development of robust and reliable action prediction models, crucial for safe and effective interaction in real-world settings, as well as zero-shot generalization capabilities. The ultimate goal is the creation of truly autonomous and versatile AI agents that can perform complex tasks in both digital and physical worlds.
Magma’s Architecture#
Magma’s architecture is likely a complex, multi-modal system designed for robust performance across diverse tasks. It probably leverages a transformer-based backbone for processing both visual and textual inputs, possibly using separate encoders for each modality. The architecture likely incorporates mechanisms for multimodal fusion, combining the processed visual and linguistic information to create a unified representation. Furthermore, a planning module would be crucial for generating sequences of actions, possibly utilizing techniques like reinforcement learning or trajectory prediction. Action grounding, a key component, would map high-level goals or instructions to specific actions within the environment. The system’s effectiveness likely hinges on pre-training with massive, heterogeneous datasets, including image, video, and robotics data. The use of surrogate tasks, such as action grounding and action prediction, is probable during pre-training. This allows learning transferable skills, boosting generalization capabilities to unseen tasks. Finally, efficient mechanisms are needed for model outputs to be interpreted and translated into actions in different settings(digital or physical).
Action Grounding#
Action grounding, a crucial aspect of embodied AI, focuses on connecting high-level action descriptions with low-level, executable actions within a physical or digital environment. The challenge lies in bridging the semantic gap between human-understandable instructions and the precise motor commands needed for robots or digital agents. Effective action grounding requires robust perception to accurately identify actionable objects and their spatial relationships. Sophisticated planning algorithms are essential to translate abstract goals into sequences of feasible actions. Furthermore, handling uncertainty and errors in perception or execution is critical for reliable action grounding. Successful systems achieve this through a combination of large-scale multimodal training data, learned representations that encode object affordances and spatial context, and robust control policies capable of executing complex action sequences. Set-of-Mark (SoM) and Trace-of-Mark (ToM) are innovative methods for efficiently labeling data, improving model learning and achieving stronger grounding.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a thorough comparison of the proposed model’s performance against existing state-of-the-art methods. This would involve reporting quantitative metrics on various established benchmarks, clearly indicating the model’s strengths and weaknesses across different tasks. Key aspects to look for include the choice of benchmarks (relevance to the problem), the specific metrics used (accuracy, precision, recall, F1-score, etc., depending on the task type), and a detailed analysis of the results, highlighting significant improvements or shortcomings compared to baselines. Visualizations, such as tables and graphs, are essential for effective presentation. The discussion should not just present the numbers but provide insightful interpretations of the results, explaining any unexpected findings or limitations. Statistical significance testing should be employed to confirm the reliability of the observed differences. A comprehensive analysis might also delve into the computational cost and resource requirements of the model compared to others, providing a holistic evaluation beyond just raw performance.
Future of Magma#
The future of Magma, a foundational multimodal AI model, is promising and multifaceted. Continued development will likely focus on enhancing its scalability and efficiency, enabling it to handle even larger and more diverse datasets for improved performance across a wider range of tasks. Addressing the challenges of generalization and robustness will be crucial; making Magma more adaptable to unseen environments and inputs. Research into more sophisticated methods for action grounding and planning is key to unlocking the full potential of embodied AI agents. Furthermore, ethical considerations regarding bias and safety must be prioritized, ensuring responsible development and deployment. Finally, the model’s open-source nature encourages community collaboration, accelerating innovation and pushing the boundaries of multimodal AI.
More visual insights#
More on figures

🔼 This figure illustrates the core functionalities of a multimodal AI agent. The agent receives both a multimodal understanding input (combining visual and textual information) and a goal specification. Its core task is to predict the appropriate actions required to achieve the given goal, demonstrating both perception and action capabilities.
read the caption
Figure 2: A multimodal AI agent should be capable of mutimodal understanding and action-prediction towards a given goal.

🔼 Figure 3 illustrates the concept of Set-of-Mark (SoM), a method used for action grounding in various contexts. The image on the left shows SoM applied to a User Interface (UI) screenshot; actionable elements (like clickable buttons) are labeled with numerical marks overlaid onto the image. The middle image displays SoM applied to robot manipulation data; specific robot arm positions and actions are marked numerically. The image on the right shows SoM for human action video data; points corresponding to human hand motions during actions are labeled with numerical marks overlaid onto the video frames. All coordinates in the marks are normalized to the image height and width and then quantized into 256 bins for easier representation.
read the caption
Figure 3: Set-of-Mark supervisions for action grounding on UI screenshot (left), robot manipulation (middle) and human video (right). All coordinates are normalized by image size (height, width) and then quantized into 256 bins. Images better viewed by zooming in.

🔼 This figure illustrates the concept of Trace-of-Mark, a method used to enhance spatial-temporal intelligence in the Magma model. The left panel showcases Trace-of-Mark applied to robot manipulation, demonstrating how the model predicts the future trajectory of the robot’s end-effector by overlaying marks onto consecutive video frames. This shows the planned path of the robot arm as it moves a white object. The right panel shows Trace-of-Mark applied to human actions, illustrating how the model predicts the future hand movements involved in a task, here, gathering potato peels. In both cases, the marks show the trajectory over several frames. The same coordinate normalization and quantization scheme used for Set-of-Mark is consistently applied for the Trace-of-Mark.
read the caption
Figure 4: Trace-of-Mark supervisions for robot manipulation (left) and human action (right). Same coordinate normalization and quantization is used as SoM. Images show the future traces to predict.
🔼 This figure illustrates Algorithm 2, which addresses the challenge of camera motion in videos when generating Set-of-Mark (SoM) and Trace-of-Mark (ToM) annotations for action grounding and planning. Algorithm 2 first uses CoTracker to generate point traces, then filters for global motion using homography transformation, classifying traces into foreground and background. Finally, it clusters foreground and background traces separately and applies SoM to the first frame.
read the caption
Figure 5: An illustration of Alg. 2 to handle videos with camera motions for SoM/ToM generation.
🔼 Figure 6 provides a detailed breakdown of the datasets used for pretraining the Magma multimodal AI model. The figure visually represents the composition of the datasets using a pie chart, color-coding each data type. Instructional videos are shown in orange, robotics manipulation data in green, UI navigation data in pink, and multimodal understanding data in blue. The size of each slice in the pie chart corresponds to the number of image samples within each dataset. It’s important to note that for datasets containing videos (instructional videos and robotics manipulation data), only the images extracted from short video clips and robot trajectories are counted, not the complete videos themselves.
read the caption
Figure 6: Overview of Pretraining Data Sources. A diverse collection of datasets including instructional videos (orange), robotics manipulation (green), UI navigation (pink), and multimodal understanding (blue). Note that we count the size of each dataset by the number of image samples. For video and robotics data, we extract the images from the short clips and trajectories, respectively.
🔼 The figure illustrates the architecture of the Magma multimodal AI agent’s pretraining pipeline. Text data from various sources is tokenized. Images and videos, regardless of source domain (UI, robotics, instructional videos), are processed by a shared vision encoder, producing a common representation. These visual features, along with the text tokens, are fed into a large language model (LLM). The LLM then generates outputs representing verbal, spatial, and action information. This unified approach enables the model to bridge multimodal understanding and action prediction tasks, a key feature of the Magma model.
read the caption
Figure 7: Magma pretraining pipeline. For all training data, texts are tokenized into tokens, while images and videos from different domains are encoded by a shared vision encoder. The resulted discrete and continuous tokens are then fed into a LLM to generate the outputs in verbal, spatial and action types. Our proposed method reconcile the multimodal understanding and action prediction tasks.
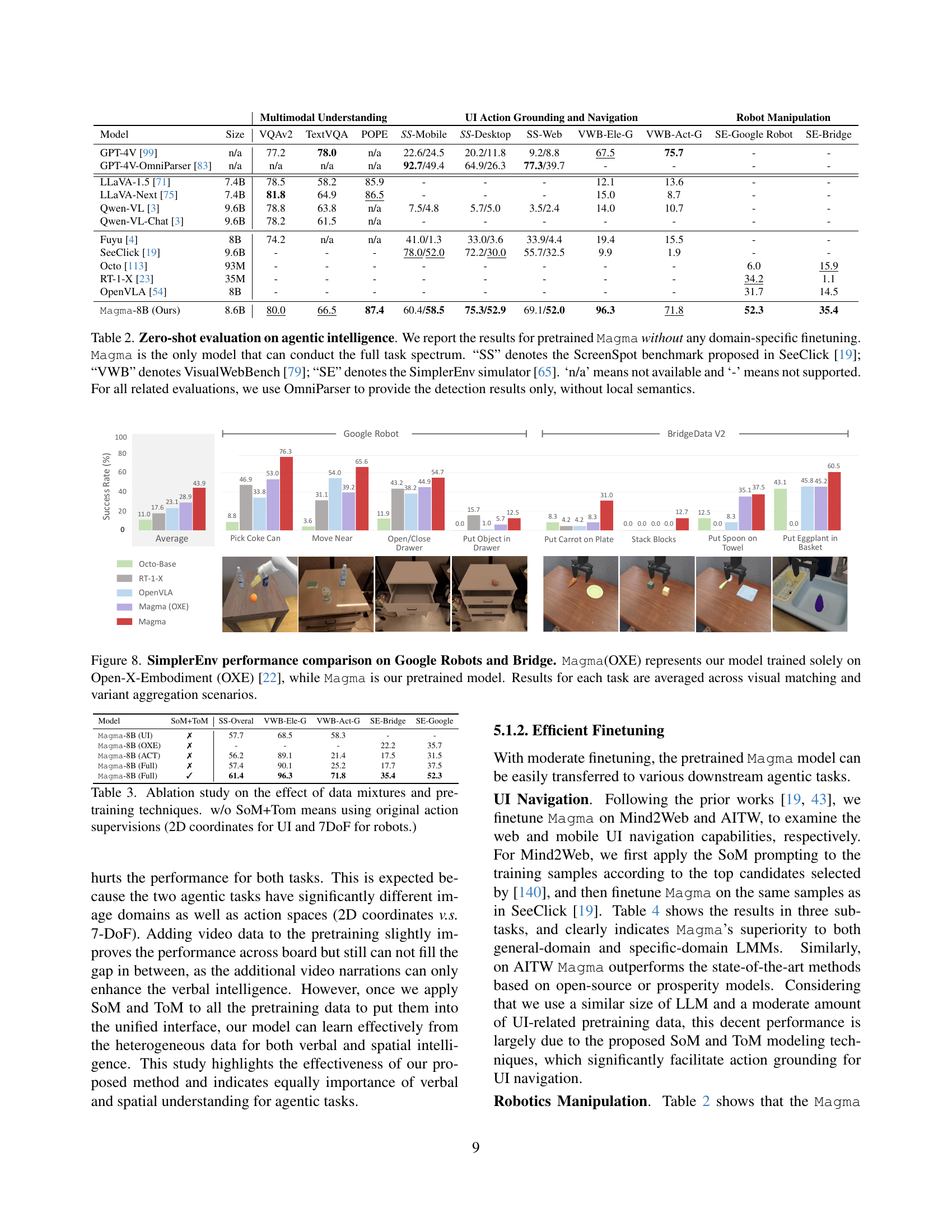
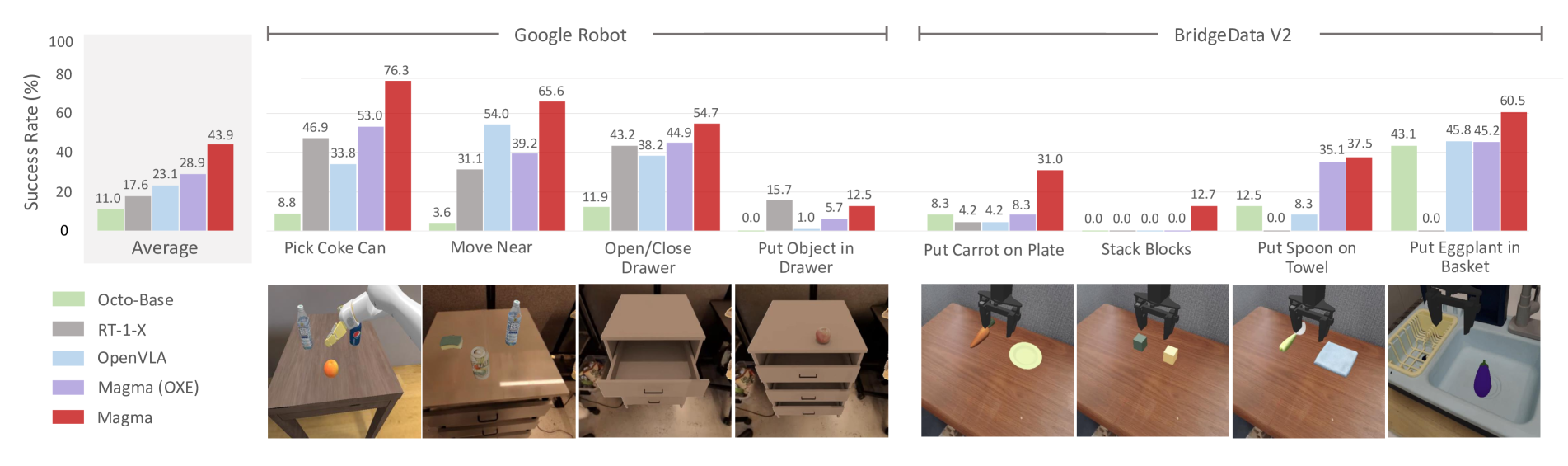
🔼 This figure compares the performance of two models, Magma and Magma(OXE), on the SimplerEnv benchmark for robot manipulation tasks using Google Robots and Bridge simulators. Magma(OXE) was trained solely on the Open-X-Embodiment dataset, while Magma is a pretrained model trained on a more diverse set of data. The results shown are the average success rates across various scenarios, including visual matching and variant aggregation tasks, showcasing the generalizability and robustness of the pretrained Magma model.
read the caption
Figure 8: SimplerEnv performance comparison on Google Robots and Bridge. Magma(OXE) represents our model trained solely on Open-X-Embodiment (OXE) [22], while Magma is our pretrained model. Results for each task are averaged across visual matching and variant aggregation scenarios.
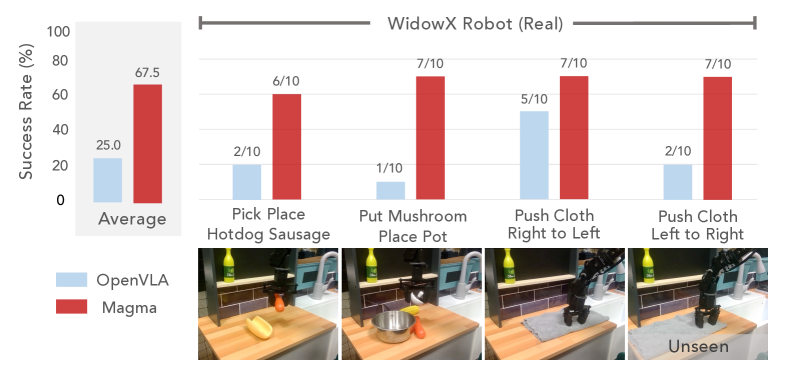
🔼 Figure 9 presents a comparative analysis of few-shot finetuning and generalization capabilities of the Magma model and other models on a WidowX real robot. The experiment involved four diverse everyday object manipulation tasks. The results highlight Magma’s superior performance in these tasks, particularly in challenging scenarios requiring precise spatial understanding and planning, where other models often fail.
read the caption
Figure 9: Few-shot finetuning and generalization performance on real robot. On a WidowX robot, we evaluate Magma on 4 tasks including diverse everyday object manipulation.

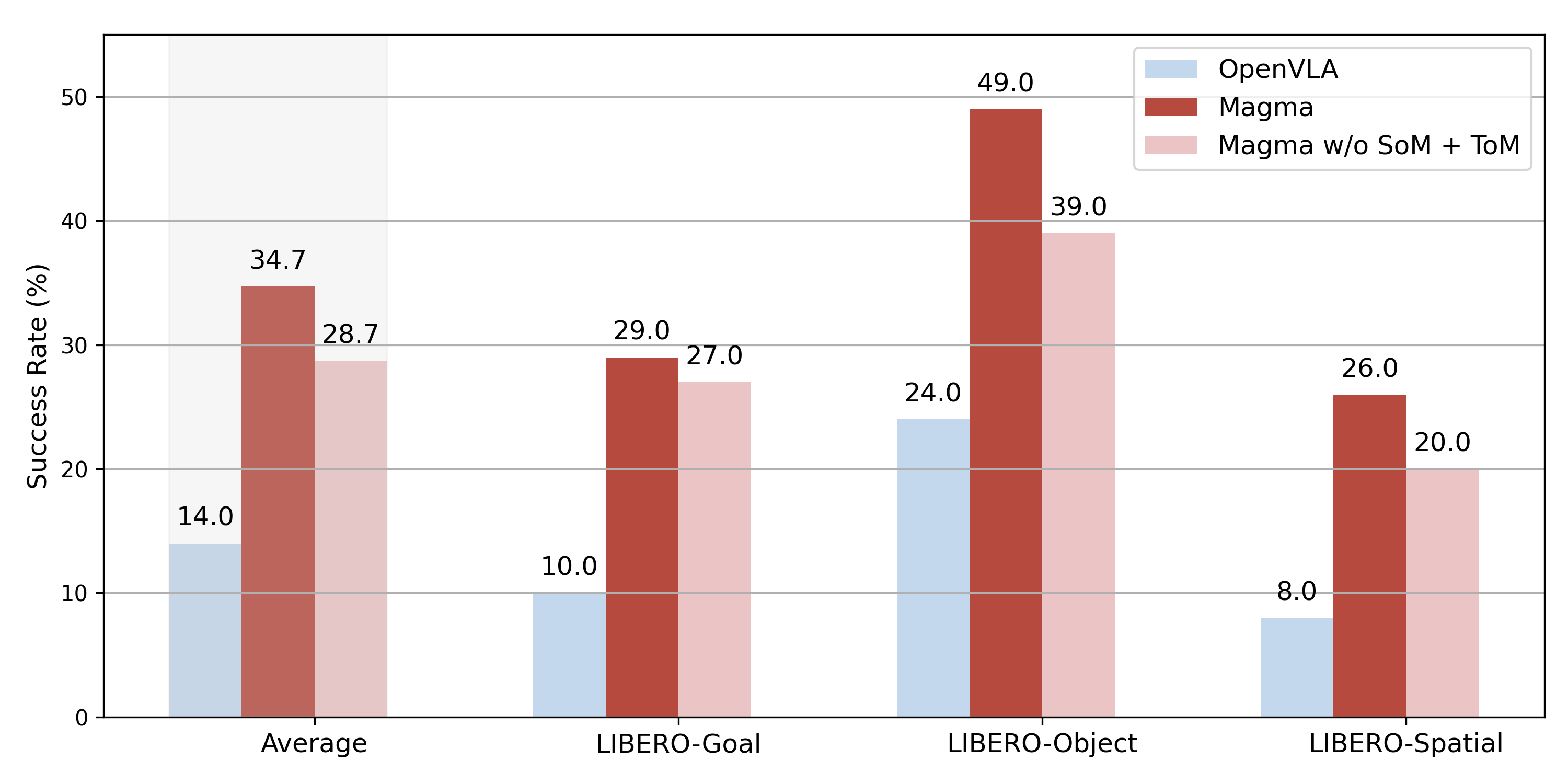
🔼 The figure visualizes the outcomes of a few-shot fine-tuning experiment conducted on the LIBERO simulation benchmark. The experiment involved using 10 trajectories per task for the fine-tuning process. The graph likely presents a comparison of the model’s performance (e.g., success rate) across different tasks within the LIBERO benchmark, possibly showcasing how well the model generalizes after a small amount of fine-tuning. Each bar might represent a specific task, and the height of the bar corresponds to the model’s performance on that task.
read the caption
Figure 10: Few-shot finetuning results on the LIBERO simulation benchmark, using 10 trajectories per task for fine-tuning.
🔼 Figure 11 presents a comparison of GPT-4 and Magma’s performance on spatial reasoning tasks. The figure shows example questions requiring complex spatial understanding, along with the answers produced by each model. It highlights Magma’s ability to perform relatively well on these challenging tasks, despite having been trained on significantly less data than GPT-4. This demonstrates Magma’s efficiency and effectiveness in spatial reasoning.
read the caption
Figure 11: Spatial evaluation predictions. Spatial reasoning questions are challenging even for GPT-4o but Magma can answer relatively well despite relying on much fewer pretraining data.

🔼 Figure 12 showcases examples of the Magma-PT-UI training dataset, demonstrating its versatility in handling various UI interaction tasks. (a) illustrates action grounding: given bounding box coordinates, the model generates a natural language description of the box’s content. (b) shows the reverse process: given a natural language description or the exact content, the model returns the corresponding bounding box coordinates. (c) demonstrates another aspect of action grounding, where the model identifies the point coordinates for a given text description. (d) and (e) present examples of widget captioning and UI summarization, respectively, showcasing the model’s ability to understand and process UI elements holistically.
read the caption
Figure 12: Training samples in our Magma-PT-UI. It covers a wide range of action grounding and UI understanding tasks including: (a) Given the bounding box or point coordinates as the query, assistant should return the natural language description or the content. (b) Given the natural language or the exact content as the query, assistant should return the value of the bounding box coordinates.. (c) Given the natural language as the query, assistant should return the value of the point coordinate. (d) Widget captioning. (e) UI summarization.
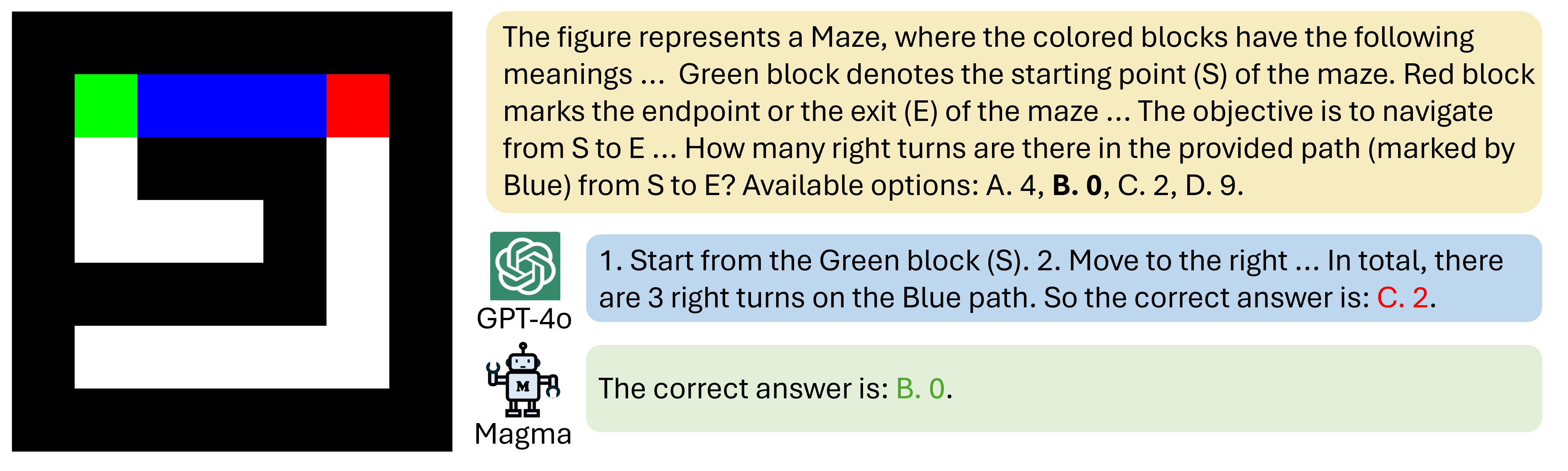
🔼 This figure presents bar charts visualizing the frequency distribution of action verbs used in the three types of datasets used for pretraining the Magma model: UI Navigation, Robotic Manipulation, and Instructional Videos. Each chart shows the top most frequent action verbs in that particular dataset, offering a glimpse into the semantic distinctions between the types of actions present in each dataset. The visualization provides insight into how the action vocabularies of each dataset differ, reflecting the varied nature of tasks and actions involved in each domain.
read the caption
Figure 13: Action distributions in three types of action-oriented pretraining datasets. (a) UI Navigation; (b) Robotic Manipulation; (c) Instructional Videos.

🔼 The image shows a WidowX 250 robot arm, equipped with a gripper, performing a series of kitchen-related manipulation tasks. This setup is used to evaluate the performance of the Magma model in real-world scenarios. The tasks involve precise movements and interactions, such as picking up and placing objects and performing soft manipulations (like adjusting the position of items). The figure highlights Magma’s capabilities in real-world object manipulation.
read the caption
Figure 14: Real robot setup. Magma is deployed on a WidowX 250 robot arm to perform a sequence of kitchen manipulation tasks including object pick-place and soft manipulation.

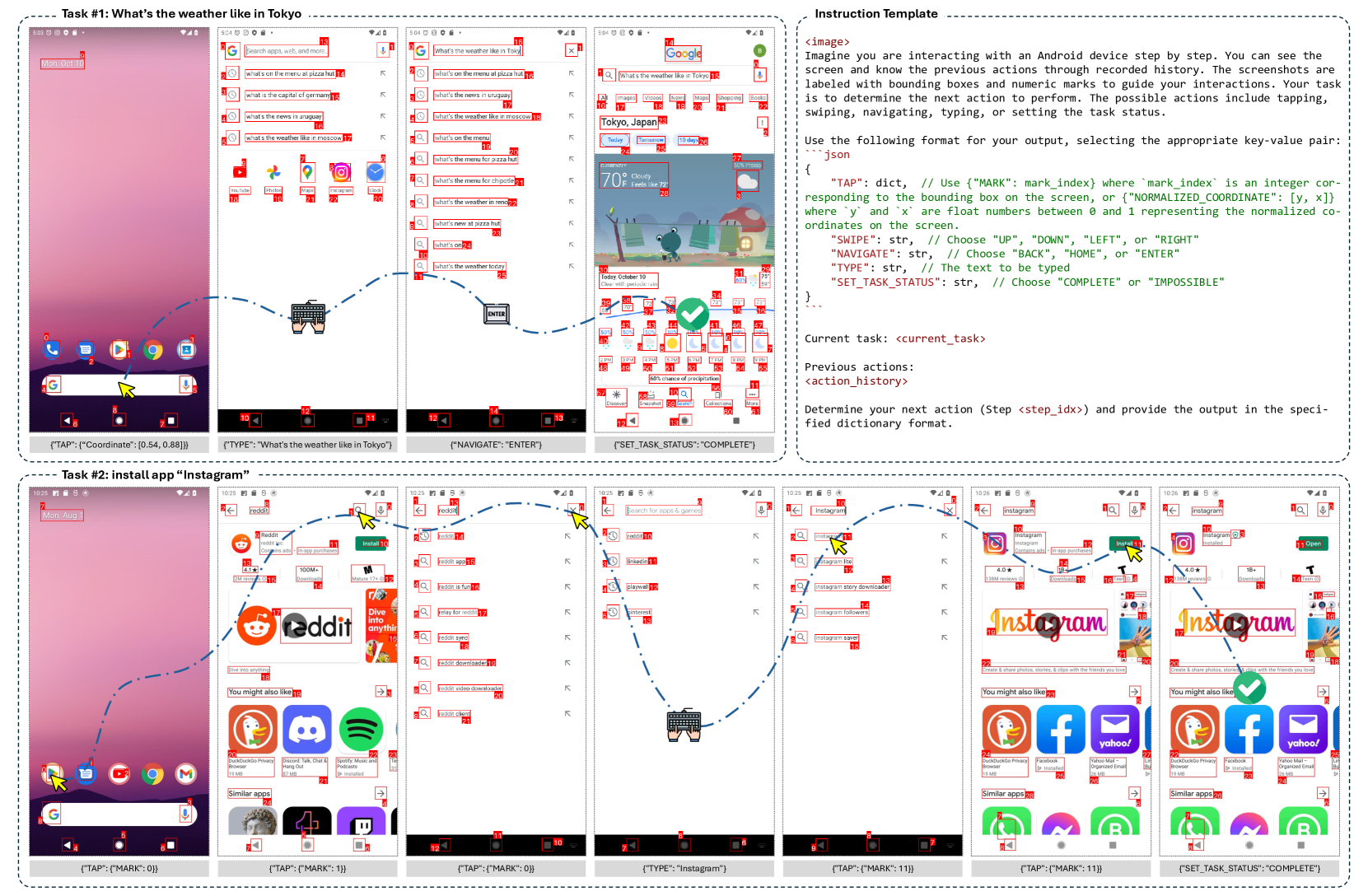
🔼 This figure showcases two examples of mobile UI navigation tasks performed by the Magma model. The first task is to find the weather in Tokyo, which involves a sequence of actions such as opening a weather app, entering a location, and reading the results. The second task is to install the Instagram app, involving actions like opening the app store, searching for the app, and initiating the installation process. The model’s actions are presented in a step-by-step fashion, illustrating how it processes new visual information and builds upon its history of actions to achieve the final goal. The images and text clearly demonstrate Magma’s ability to interpret user requests, generate a plan, and execute the plan by interacting with a mobile UI.
read the caption
Figure 15: Examples for mobile UI navigation sample. We prompt the model with two tasks: “What’s the weather like in Tokyo” and “Install app ‘Instagram’”. The model take actions sequentially given the new observation and history action information.

🔼 The figure shows a sequence of images depicting a robot’s failed attempt at placing a sausage into a hotdog bun. This is a result of using the OpenVLA model, which demonstrates limitations in executing complex manipulation tasks requiring precise spatial understanding and planning.
read the caption
a Robot policy rollout for task “Put the sausage to hotdog” for OpenVLA model. (Failure)

🔼 The figure shows a sequence of images depicting a robot’s failed attempt to perform the task of picking up a mushroom and placing it in a pot. The robot’s actions are clumsy and inefficient, ultimately failing to complete the task successfully. This illustrates the limitations of the OpenVLA model in handling this specific robotic manipulation task, which requires precise spatial reasoning and planning.
read the caption
b Robot policy rollout for task “Pick up the mushroom to the pot” for OpenVLA model. (Failure)
More on tables
Multimodal Understanding | UI Action Grounding and Navigation | Robot Manipulation | |||||||||
| Model | Size | VQAv2 | TextVQA | POPE | SS-Mobile | SS-Desktop | SS-Web | VWB-Ele-G | VWB-Act-G | SE-Google Robot | SE-Bridge |
| GPT-4V [99] | n/a | 77.2 | 78.0 | n/a | 22.6/24.5 | 20.2/11.8 | 9.2/8.8 | 67.5 | 75.7 | - | - |
| GPT-4V-OmniParser [83] | n/a | n/a | n/a | n/a | 92.7/49.4 | 64.9/26.3 | 77.3/39.7 | - | - | - | - |
| LLaVA-1.5 [71] | 7.4B | 78.5 | 58.2 | 85.9 | - | - | - | 12.1 | 13.6 | - | - |
| LLaVA-Next [75] | 7.4B | 81.8 | 64.9 | 86.5 | - | - | - | 15.0 | 8.7 | - | - |
| Qwen-VL [3] | 9.6B | 78.8 | 63.8 | n/a | 7.5/4.8 | 5.7/5.0 | 3.5/2.4 | 14.0 | 10.7 | - | - |
| Qwen-VL-Chat [3] | 9.6B | 78.2 | 61.5 | n/a | - | - | - | - | - | - | - |
| Fuyu [4] | 8B | 74.2 | n/a | n/a | 41.0/1.3 | 33.0/3.6 | 33.9/4.4 | 19.4 | 15.5 | - | - |
| SeeClick [19] | 9.6B | - | - | - | 78.0/52.0 | 72.2/30.0 | 55.7/32.5 | 9.9 | 1.9 | - | - |
| Octo [113] | 93M | - | - | - | - | - | - | - | - | 6.0 | 15.9 |
| RT-1-X [23] | 35M | - | - | - | - | - | - | - | - | 34.2 | 1.1 |
| OpenVLA [54] | 8B | - | - | - | - | - | - | - | - | 31.7 | 14.5 |
| Magma-8B (Ours) | 8.6B | 80.0 | 66.5 | 87.4 | 60.4/58.5 | 75.3/52.9 | 69.1/52.0 | 96.3 | 71.8 | 52.3 | 35.4 |
🔼 This table presents a zero-shot evaluation of the Magma model’s performance across various agentic intelligence tasks, without any task-specific fine-tuning. The results highlight Magma’s ability to handle a wide range of tasks encompassing multimodal understanding, UI action grounding and navigation, and robot manipulation. The table compares Magma’s performance against other state-of-the-art models on established benchmarks such as ScreenSpot, VisualWebBench, and SimplerEnv, revealing Magma’s superior performance and generalization capability across different domains. The evaluation utilized OmniParser for object detection, focusing solely on detection without incorporating local semantic information.
read the caption
Table 2: Zero-shot evaluation on agentic intelligence. We report the results for pretrained Magma without any domain-specific finetuning. Magma is the only model that can conduct the full task spectrum. “SS” denotes the ScreenSpot benchmark proposed in SeeClick [19]; “VWB” denotes VisualWebBench [79]; “SE” denotes the SimplerEnv simulator [65]. ‘n/a’ means not available and ‘-’ means not supported. For all related evaluations, we use OmniParser to provide the detection results only, without local semantics.
| Model | SoM+ToM | SS-Overal | VWB-Ele-G | VWB-Act-G | SE-Bridge | SE-Google |
| Magma-8B (UI) | ✗ | 57.7 | 68.5 | 58.3 | - | - |
| Magma-8B (OXE) | ✗ | - | - | - | 22.2 | 35.7 |
| Magma-8B (ACT) | ✗ | 56.2 | 89.1 | 21.4 | 17.5 | 31.5 |
| Magma-8B (Full) | ✗ | 57.4 | 90.1 | 25.2 | 17.7 | 37.5 |
| Magma-8B (Full) | ✓ | 61.4 | 96.3 | 71.8 | 35.4 | 52.3 |
🔼 This ablation study investigates the impact of data sources and training methods on the performance of the Magma model. It compares the model’s performance when trained with: 1) only UI data, 2) only robotics data, 3) both UI and robotics data (without using the proposed Set-of-Mark and Trace-of-Mark methods), 4) the full dataset (including the proposed training methods). The ‘w/o SoM+ToM’ condition indicates that the original action supervisions (2D coordinates for UI tasks and 7 degrees of freedom for robotics tasks) were used, instead of the novel methods introduced in the paper. The results highlight the importance of the proposed training techniques and data diversity for the model’s overall performance.
read the caption
Table 3: Ablation study on the effect of data mixtures and pretraining techniques. w/o SoM+Tom means using original action supervisions (2D coordinates for UI and 7DoF for robots.)
| Method | Backbone | Input Source | Cross-Website | Cross-Task | Cross-Domain | |||||||
| DoM Tree | Image | Ele. Acc | Op. F1 | Step SR | Ele. Acc | Op. F1 | Step SR | Ele. Acc | Op. F1 | Step SR | ||
| GPT-4-MindAct [27] | GPT-4 [98] | ✓ | 35.8 | 51.1 | 30.1 | 41.6 | 60.6 | 36.2 | 37.1 | 46.5 | 26.4 | |
| GPT-4V-OmniParser [83] | GPT-4V [99] | ✓ | ✓ | 41.0 | 84.8 | 36.5 | 42.4 | 87.6 | 39.4 | 45.5 | 85.7 | 42.0 |
| SeeAct [141] | GPT-4V [99] | ✓ | 13.9 | - | - | 20.3 | - | - | 23.7 | |||
| Gemini-Pro [36] | ✓ | ✓ | 21.5 | 67.7 | 19.6 | 21.5 | 67.7 | 19.6 | 20.7 | 64.3 | 18.0 | |
| GPT-4V [99] | ✓ | ✓ | 38.0 | 67.8 | 32.4 | 46.4 | 73.4 | 40.2 | 42.4 | 69.3 | 36.8 | |
| Fuyu-8B‡ | Fuyu-8B [4] | ✓ | 4.8 | 81.3 | 4.0 | 8.3 | 83.9 | 6.6 | 3.6 | 83.0 | 3.0 | |
| Fuyu-8B-GUI [17] | Fuyu-8B [4] | ✓ | 13.9 | 80.7 | 12.2 | 19.1 | 86.1 | 15.6 | 14.2 | 83.1 | 11.7 | |
| MiniCPM-V‡ | MiniCPM-V [128] | ✓ | 8.2 | 78.2 | 6.0 | 11.0 | 85.6 | 8.5 | 6.5 | 81.4 | 5.2 | |
| MiniCPM-V-GUI [17] | MiniCPM-V [128] | ✓ | 20.3 | 81.7 | 17.3 | 23.8 | 86.8 | 20.8 | 17.9 | 74.5 | 17.6 | |
| Qwen-VL♮ | Qwen-VL [3] | ✓ | 13.2 | 83.5 | 9.2 | 15.9 | 86.7 | 13.3 | 14.1 | 84.3 | 12.0 | |
| SeeClick [19] | Qwen-VL [3] | ✓ | 21.4 | 80.6 | 16.4 | 28.3 | 87.0 | 25.5 | 23.2 | 84.8 | 20.8 | |
| CogAgent† [43] | CogVLM [118] | ✓ | 27.3 | - | 23.4 | 30.2 | - | 26.9 | 33.1 | - | 28.5 | |
| Qwen2-UIX [78] | Qwen2 [124] | ✓ | 39.2 | - | 31.0 | 43.4 | - | 38.2 | 40.4 | - | 34.9 | |
| Magma-8B (Ours) | LLaMA3 [92] | ✓ | 57.2 | 76.9 | 45.4 | 54.8 | 79.7 | 43.4 | 55.7 | 80.6 | 47.3 | |
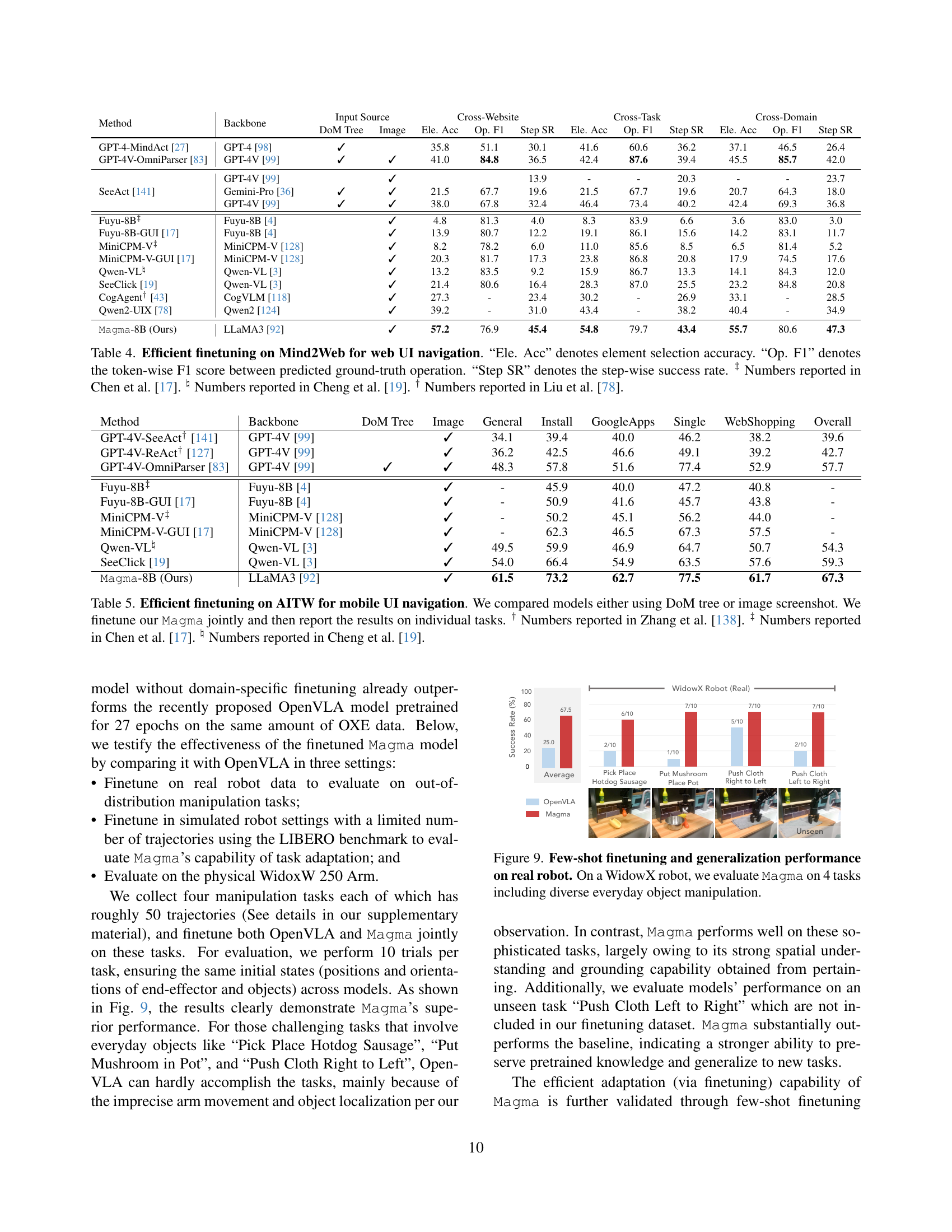
🔼 Table 4 presents the results of fine-tuning various models on the Mind2Web benchmark for web UI navigation. It compares the performance of different models across three key metrics: Element Selection Accuracy (Ele. Acc), which measures the accuracy of selecting the correct UI element; Operation F1 Score (Op. F1), which assesses the accuracy of predicting the correct operation (e.g., click, type); and Step-wise Success Rate (Step SR), representing the success rate at each step of the navigation task. The table includes a breakdown of results for different models, highlighting their strengths and weaknesses in each metric. Note that some numbers are taken from other studies as indicated by the symbols in the caption.
read the caption
Table 4: Efficient finetuning on Mind2Web for web UI navigation. “Ele. Acc” denotes element selection accuracy. “Op. F1” denotes the token-wise F1 score between predicted ground-truth operation. “Step SR” denotes the step-wise success rate. ‡ Numbers reported in Chen et al. [17]. ♮ Numbers reported in Cheng et al. [19]. † Numbers reported in Liu et al. [78].
| Method | Backbone | DoM Tree | Image | General | Install | GoogleApps | Single | WebShopping | Overall |
| GPT-4V-SeeAct† [141] | GPT-4V [99] | ✓ | 34.1 | 39.4 | 40.0 | 46.2 | 38.2 | 39.6 | |
| GPT-4V-ReAct† [127] | GPT-4V [99] | ✓ | 36.2 | 42.5 | 46.6 | 49.1 | 39.2 | 42.7 | |
| GPT-4V-OmniParser [83] | GPT-4V [99] | ✓ | ✓ | 48.3 | 57.8 | 51.6 | 77.4 | 52.9 | 57.7 |
| Fuyu-8B‡ | Fuyu-8B [4] | ✓ | - | 45.9 | 40.0 | 47.2 | 40.8 | - | |
| Fuyu-8B-GUI [17] | Fuyu-8B [4] | ✓ | - | 50.9 | 41.6 | 45.7 | 43.8 | - | |
| MiniCPM-V‡ | MiniCPM-V [128] | ✓ | - | 50.2 | 45.1 | 56.2 | 44.0 | - | |
| MiniCPM-V-GUI [17] | MiniCPM-V [128] | ✓ | - | 62.3 | 46.5 | 67.3 | 57.5 | - | |
| Qwen-VL♮ | Qwen-VL [3] | ✓ | 49.5 | 59.9 | 46.9 | 64.7 | 50.7 | 54.3 | |
| SeeClick [19] | Qwen-VL [3] | ✓ | 54.0 | 66.4 | 54.9 | 63.5 | 57.6 | 59.3 | |
| Magma-8B (Ours) | LLaMA3 [92] | ✓ | 61.5 | 73.2 | 62.7 | 77.5 | 61.7 | 67.3 |
🔼 Table 5 presents the results of fine-tuning various models on the AITW benchmark for mobile UI navigation. The models were either trained using the Document Object Model (DOM) tree or image screenshots. The table compares the performance of Magma against other models across multiple sub-tasks within the AITW benchmark (element selection accuracy, operation F1 score, and step-wise success rate). Results from other papers are included for comparison and marked with appropriate citations (Zhang et al. [138], Chen et al. [17], and Cheng et al. [19]). Magma’s performance is evaluated after joint finetuning across all subtasks.
read the caption
Table 5: Efficient finetuning on AITW for mobile UI navigation. We compared models either using DoM tree or image screenshot. We finetune our Magma jointly and then report the results on individual tasks. † Numbers reported in Zhang et al. [138]. ‡ Numbers reported in Chen et al. [17]. ♮ Numbers reported in Cheng et al. [19].
| VSR | BLINK-val | SpatialEval222We evaluate our model using the standard option matching before the official evaluation pipeline was released and will update in the next version. | |||
| Model | Spatial Map | Maze Nav. | Spatial Grid | ||
| GPT-4o | 74.8 | 60.0 | - | - | - |
| Gemini | - | 61.4 | - | - | - |
| LLaVA-1.5-7B | 57.1* | 37.1 | 28.4 | 28.8 | 41.6 |
| LLaVA-1.6-7B [75] | 52.2* | - | 28.0 | 34.8 | 32.2 |
| Qwen-VL-9.6B [3] | - | 40.3 | 28.7 | 31.8 | 25.7 |
| Magma-8B (Actw/o) | 62.8 | 30.1 | 36.9 | 44.8 | 37.5 |
| Magma-8B (Fullw/o) | 58.1 | 38.3 | 27.5 | 33.5 | 47.3 |
| Magma-8B (Full) | 65.1 | 41.0 | 43.4 | 36.5 | 64.5 |
🔼 This table presents a comparison of different models’ performance on spatial reasoning tasks. The models’ performance is measured across several benchmarks: Spatial Map, Maze Navigation, Spatial Grid, and VSR. Results are shown for models with and without the Set-of-Mark (SoM) and Trace-of-Mark (ToM) pre-training techniques. The asterisk (*) indicates results obtained by the authors of the paper directly evaluating pre-trained weights from other researchers. The ‘w/o’ superscript denotes results for models not trained with SoM and ToM.
read the caption
Table 6: Spatial reasoning evaluations. We use * to denote results that are obtained by us evaluating the provided model weights. Superscript ‘w/o’ means models pretrained without SoM/ToM.
| Model | VQAv2 | GQA | MME | POPE | TextVQA | ChartQA | DocVQA |
| LLaVA-1.5-7B [61] | 76.6 | 62.6 | 1510.8 | 85.9 | 46.1 | 18.2 | 28.1 |
| LLaVA-Next-7B [75] | 80.1 | 64.2 | 1519.3 | 86.4 | 64.9 | 54.8 | 74.4 |
| Magma-8B (SFT) | 79.5 | 61.5 | 1510.1 | 86.2 | 67.7 | 73.0 | 80.4 |
| Magma-8B (Actw/o) | 81.3 | 63.5 | 1559.5 | 86.1 | 69.8 | 71.0 | 84.1 |
| Magma-8B (Fullw/o) | 81.3 | 62.9 | 1576.0 | 86.3 | 69.6 | 71.7 | 83.8 |
| Magma-8B (Full) | 81.4 | 64.0 | 1588.7 | 86.3 | 70.2 | 76.2 | 84.8 |
🔼 This table presents the results of fine-tuning various large multimodal models on several image understanding tasks. The models were initially pre-trained, and then further fine-tuned. The table compares the performance of these models across different tasks, highlighting the superior performance achieved by the model when pre-trained with a full dataset incorporating both Set-of-Mark (SoM) and Trace-of-Mark (ToM) annotations. This demonstrates the effectiveness of the SoM and ToM methods in improving model performance on multimodal image understanding tasks.
read the caption
Table 7: Finetuned performance on multimodal image understanding tasks. Pretraining on full set with SoM and ToM (last row) attains the overall best performance compared with our own baselines and counterparts of the same model class.
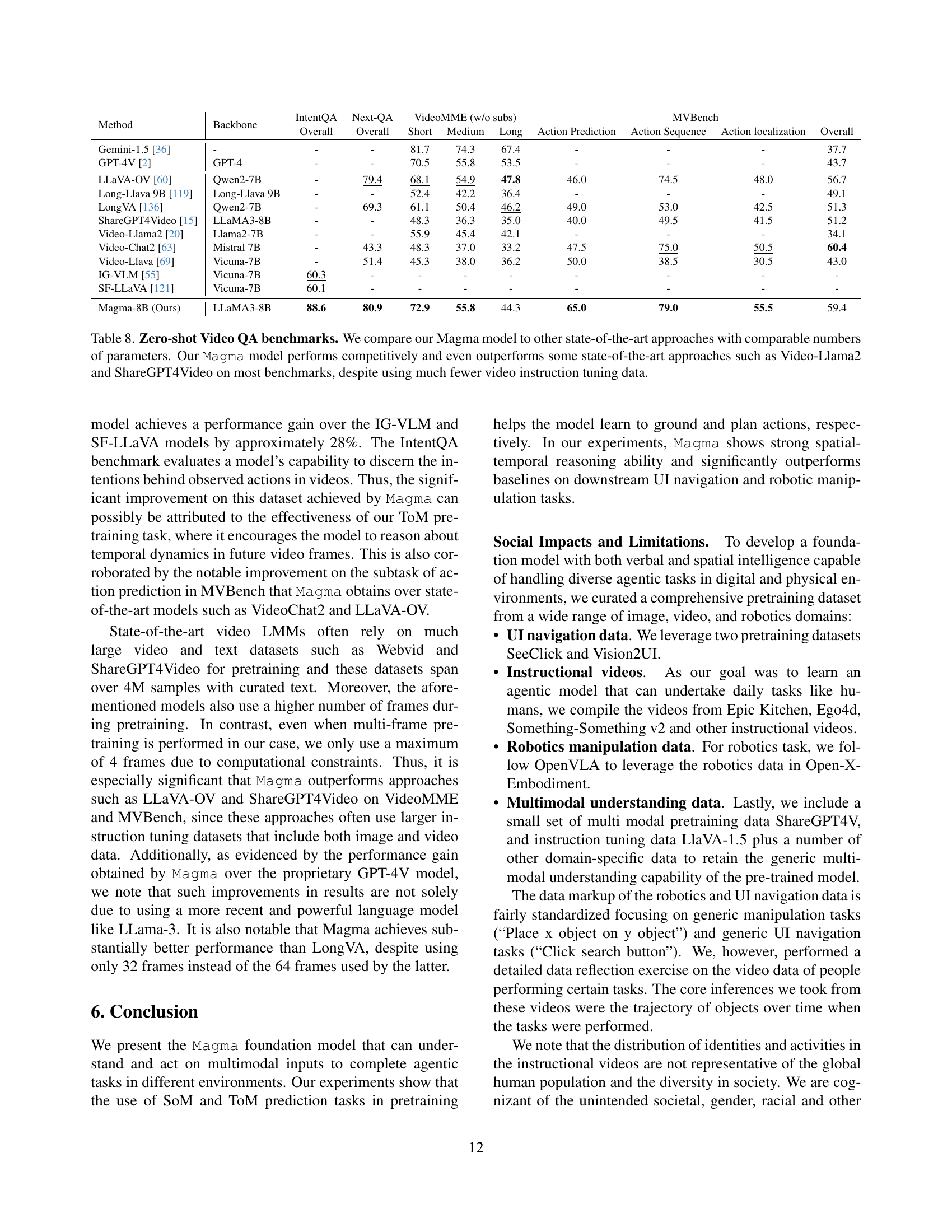
| Method | Backbone | IntentQA | Next-QA | VideoMME (w/o subs) | MVBench | |||||
| Overall | Overall | Short | Medium | Long | Action Prediction | Action Sequence | Action localization | Overall | ||
| Gemini-1.5 [36] | - | - | - | 81.7 | 74.3 | 67.4 | - | - | - | 37.7 |
| GPT-4V [2] | GPT-4 | - | - | 70.5 | 55.8 | 53.5 | - | - | - | 43.7 |
| LLaVA-OV [60] | Qwen2-7B | - | 79.4 | 68.1 | 54.9 | 47.8 | 46.0 | 74.5 | 48.0 | 56.7 |
| Long-Llava 9B [119] | Long-Llava 9B | - | - | 52.4 | 42.2 | 36.4 | - | - | - | 49.1 |
| LongVA [136] | Qwen2-7B | - | 69.3 | 61.1 | 50.4 | 46.2 | 49.0 | 53.0 | 42.5 | 51.3 |
| ShareGPT4Video [15] | LLaMA3-8B | - | - | 48.3 | 36.3 | 35.0 | 40.0 | 49.5 | 41.5 | 51.2 |
| Video-Llama2 [20] | Llama2-7B | - | - | 55.9 | 45.4 | 42.1 | - | - | - | 34.1 |
| Video-Chat2 [63] | Mistral 7B | - | 43.3 | 48.3 | 37.0 | 33.2 | 47.5 | 75.0 | 50.5 | 60.4 |
| Video-Llava [69] | Vicuna-7B | - | 51.4 | 45.3 | 38.0 | 36.2 | 50.0 | 38.5 | 30.5 | 43.0 |
| IG-VLM [55] | Vicuna-7B | 60.3 | - | - | - | - | - | - | - | - |
| SF-LLaVA [121] | Vicuna-7B | 60.1 | - | - | - | - | - | - | - | - |
| Magma-8B (Ours) | LLaMA3-8B | 88.6 | 80.9 | 72.9 | 55.8 | 44.3 | 65.0 | 79.0 | 55.5 | 59.4 |
🔼 Table 8 presents a comparison of the Magma model’s performance on several zero-shot video question answering (QA) benchmarks against other state-of-the-art models with similar parameter counts. The benchmarks evaluate various aspects of video understanding, including action prediction, action sequencing, and action localization. The results demonstrate that Magma performs competitively and, in some cases, surpasses top-performing models like Video-Llama2 and ShareGPT4Video. This is notable given that Magma was pre-trained on significantly less video instruction tuning data.
read the caption
Table 8: Zero-shot Video QA benchmarks. We compare our Magma model to other state-of-the-art approaches with comparable numbers of parameters. Our Magma model performs competitively and even outperforms some state-of-the-art approaches such as Video-Llama2 and ShareGPT4Video on most benchmarks, despite using much fewer video instruction tuning data.
| Setting | Pretraining | Finetuning | ||
| UI | Image/Video | Real Robot | ||
| batch size | 1024 | 32 | ||
| base learning rate | 1e-5 | 1e-5 | 1e-5 | 1e-5 |
| learning rate scheduler | Constant | Cosine | Cosine | Constant |
| training epochs | 3 | 3 | 1 | 20 |
| optimizer | adamw | adamw | adamw | adamw |
| Image Resolution | 512 | 768 | 768 | 256 |
| Number of Crops | 4 or 1 | 4 | 4 or 1 | 1 |
🔼 This table details the hyperparameters used for both the pretraining and finetuning stages of the Magma model. It shows the settings for various aspects of the training process, including batch size, learning rate, optimizer, learning rate scheduler, number of training epochs, and image resolution. The table also notes the hardware used for training, specifying that experiments used either 32 Nvidia H100 GPUs or 64 AMD MI300 GPUs.
read the caption
Table 9: Experimental settings pretraining and finetuning of Magma models. We maximally use either 32 Nvidia H100s or 64 AMD MI300 GPUs for all training jobs.
| Source | Task | Size |
| SeeClick-Web | text_2_point | 271K |
| text_2_bbox | 54K | |
| point_2_text | 54K | |
| bbox_2_text | 54K | |
| SeeClick-Mobile | text_2_point | 274K |
| text_2_bbox | 56K | |
| UI summarization | 48K | |
| widget captioning | 42K | |
| Visison2UI | input_2_point | 980K |
| input_2_bbox | 982K | |
| text_2_point | 794K | |
| text_2_bbox | 774K | |
| point_2_text | 199K | |
| bbox_2_text | 193K | |
| Magma-PT-UI (Ours) | Mixed | 2.8M |
🔼 This table presents a detailed breakdown of the UI-related data used in the Magma model’s pretraining phase. It lists the source of the data (SeeClick-Web, SeeClick-Mobile, Vision2UI), the specific task involved (e.g., text to point, text to bounding box, etc.), and the number of training samples available for each task and data source.
read the caption
Table 10: Statistics of UI related pretraining data.
| Dataset | Size | Domain |
| ShareGPT [106] | 40K | Text |
| ShareGPT4V [13] | 39K | General |
| LLaVA-Instruct [71] | 158K | General |
| LAION-GPT4V [58] | 11K | General |
| VQAv2 [39] | 83K | General VQA |
| GQA [45] | 72K | General VQA |
| OKVQA [105] | 9K | Knowledge VQA |
| OCRVQA [93] | 80K | OCR VQA |
| ChartQA [87] | 7K | Chart VQA |
| DVQA [46] | 16K | Chart VQA |
| DocVQA [89] | 10K | Document VQA |
| AI2D [51] | 2K | Infographic VQA |
| SynthDog-EN [53] | 20K | Document Understanding |
| A-OKVQA | 66K | Knowledge VQA |
| RefCOCO [133] | 48K | Grounding Desc. |
| VG [57] | 86K | Referring Exp. |
| InfographicsVQA [90] | 24k | Infographic VQA |
| ChartQA (Aug) [87] | 20k | Chart VQA |
| FigureQA [47] | 20k | Chart/Figure VQA |
| TQA [52] | 1.5k | Textbook VQA |
| ScienceQA [82] | 5k | Textbook VQA |
| Magma-SFT-Image (Ours) | 820k | Mixed |
🔼 This table details the composition of the 820k image instruction tuning dataset used to fine-tune the Magma model for multimodal image understanding tasks. The dataset is a compilation of various publicly available datasets, each focusing on different aspects of visual-language understanding, such as general VQA, OCR-VQA, Chart-VQA, and others. The sizes and domains of each dataset are listed for clarity and reproducibility.
read the caption
Table 11: A detailed breakdown of our 820k Magma image instruction tuning data used in our multimodal image understanding experiments shown in Table 5 in our main submission.
Full paper#