TL;DR#
Current methods for training robotic models often struggle due to the scarcity and high cost of labeled robotic data. Existing approaches either rely on limited robotic datasets or struggle to transfer knowledge effectively from other domains, like human video. This limits the development of robots capable of generalizing well to various tasks and environments.
This paper introduces ARM4R, a novel approach that leverages low-level 4D representations learned from readily available human video data. ARM4R uses 3D point tracking to create these representations, transferring knowledge efficiently to robotic control tasks. The model is trained in three stages: pre-training on human videos, fine-tuning on robotic data, and final fine-tuning for specific control tasks. Experimental results demonstrate the effectiveness of ARM4R, exceeding performance of existing methods in various simulations and real-world scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to pre-training robotic models using readily available human video data. This addresses the critical bottleneck of limited labeled robotic data, paving the way for more efficient and scalable development of generalizable robotic systems. The findings offer new avenues for research in transfer learning and representation learning for robotics, potentially impacting diverse applications.
Visual Insights#

🔼 This figure illustrates the architecture of ARM4R, an Auto-regressive Robotic Model. It shows a three-stage training process. First, low-level 4D representations (3D point tracks over time) are learned from massive unlabeled human video data. This pre-training step captures fundamental properties of the physical world without relying on expensive robotic data. Second, this knowledge is transferred and refined by fine-tuning on robotic videos, adapting the model to the specific characteristics of robotic environments. Finally, the model is fine-tuned for robotic control by using robot proprioceptive data (the robot’s own internal sensory information). The entire process allows for efficient transfer learning from abundant human video data to the more limited domain of robotic data, resulting in a better pre-trained robotic model that can generalize across different robots and environments.
read the caption
Figure 1: Overview of ARM4R. We introduce an Auto-regressive Robotic Model that leverages low-level 4D Representations (3D point tracks across time) learned from human videos to yield a better pre-trained robotic model.
| Method | Task | |||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||
| Image-BC (ViT) | 0 | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 0 | 0 | 2.67 | |||||||||||||||||||||||||
| C2FARM-BC | 20 | 20 | 68 | 12 | 72 | 0 | 16 | 24 | 8 | 18 | 24 | 4 | 23.83 | |||||||||||||||||||||||||
| ManiGaussian | 76 | 60 | 56 | - | 20 | 64 | 24 | 28 | - | - | 92 | 12 | 48.00 | |||||||||||||||||||||||||
| LLARVA | 60 | 80 | 56 | 44 | 56 | 84 | 100 | 28 | 8 | 12 | 52 | 0 | 48.33 | |||||||||||||||||||||||||
| PerAct | 80 | 84 | 80 | 44 | 48 | 56 | 72 | 60 | 24 | 12 | 68 | 36 | 55.33 | |||||||||||||||||||||||||
| ARM4R | 88.8 | 94.4 | 61.6 | 92.0 | 67.2 | 72.0 | 85.6 | 24.0 | 10.4 | 36.0 | 77.6 | 4.0 | 59.47 | |||||||||||||||||||||||||
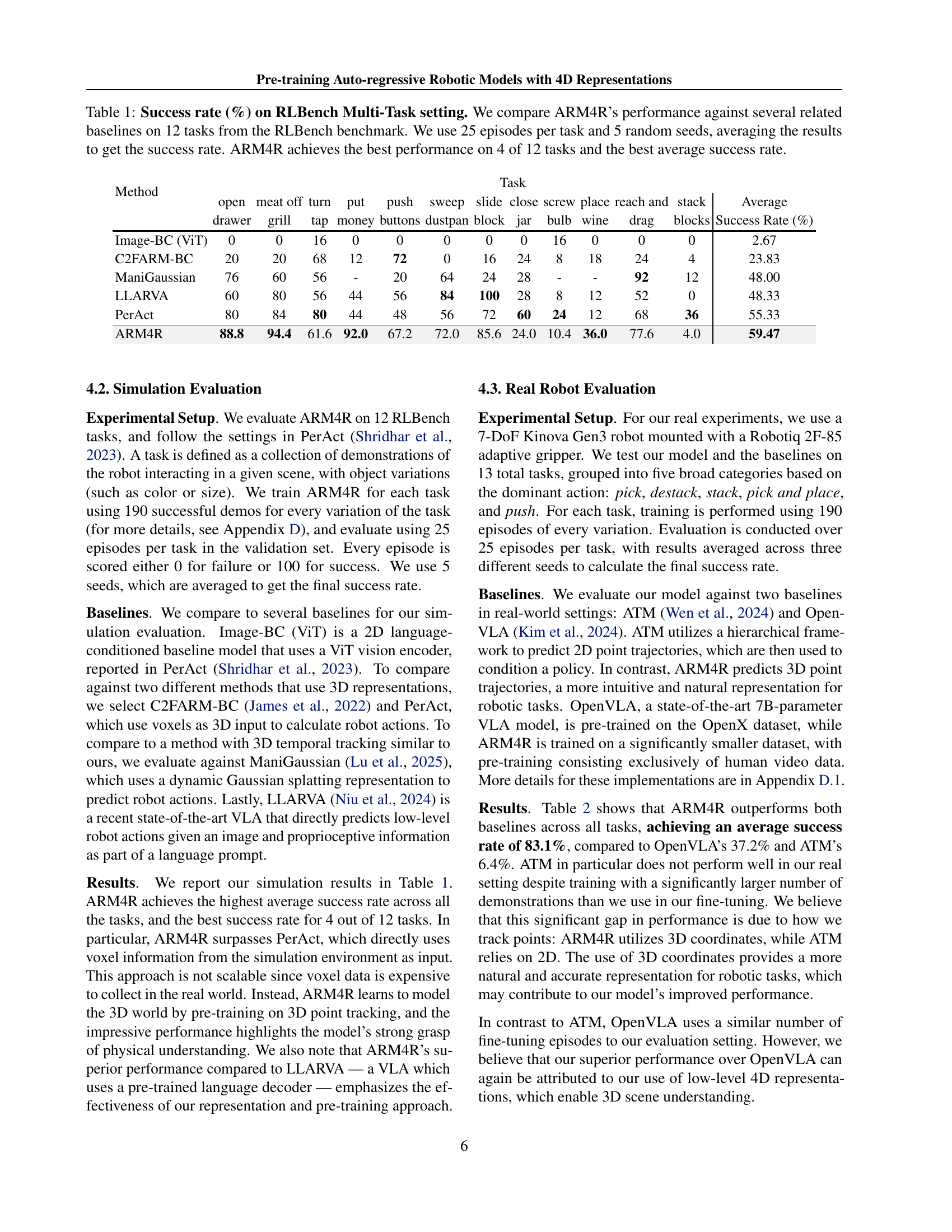
🔼 This table presents a comparison of the success rates achieved by different robotic models on 12 diverse tasks within the RLBench benchmark. Each model was evaluated using 25 episodes per task and 5 different random seeds, with the average success rate reported. The models compared include various baselines representing different approaches to robotic control, demonstrating the superior performance of ARM4R (the proposed model) in terms of overall average success rate and achieving the best performance on four out of the twelve tasks. This highlights ARM4R’s effectiveness and generalizability across a range of robotic manipulation challenges.
read the caption
Table 1: Success rate (%) on RLBench Multi-Task setting. We compare ARM4R’s performance against several related baselines on 12 tasks from the RLBench benchmark. We use 25 episodes per task and 5 random seeds, averaging the results to get the success rate. ARM4R achieves the best performance on 4 of 12 tasks and the best average success rate.
In-depth insights#
4D Rep. Pre-training#
The ‘4D Rep. Pre-training’ section in this robotics research paper explores a novel approach to pre-training robotic models using low-level 4D representations derived from human video data. This departs from existing methods that rely heavily on either costly robotic data or high-level vision-language models. The core idea is to leverage the abundance of readily available human videos, learning a representation that effectively captures the physical world through 3D point tracking across time (4D). This approach has several key advantages: it avoids the limitations of scarce robotic data, it allows for efficient transfer learning by exploiting inherent similarities between human and robot manipulation, and it focuses on low-level control rather than high-level reasoning typical of vision-language models. By pre-training on these low-level 4D representations, the model learns geometric structure and dynamics that generalize well to robotic tasks, leading to improved performance across diverse environments and robots. The use of human video data for pre-training allows for scalability and potentially significant cost reductions in data acquisition. This method shows promise for building more robust and adaptable robotic systems.
ARM4R Architecture#
The ARM4R architecture is designed for efficient transfer learning from human video data to robotic control. It leverages a causal transformer to process low-level 4D representations learned from human videos. This approach uses 3D point tracking across time and maintains shared geometric structure between points and robot states. Separate encoders process language, image, and point/state data, and these are combined for next-token prediction. The model’s auto-regressive nature enables efficient learning. Pre-training on human videos provides a foundation for understanding physical interactions. This is followed by fine-tuning on robot data, enabling adaptation to specific robotic environments. The use of low-level representations allows for better generalization than higher-level approaches found in Vision-Language-Action models.
Human Video Transfer#
The concept of ‘Human Video Transfer’ in robotics research is about leveraging the vast and readily available data of human actions in videos to train robotic models. This is a significant departure from traditional methods which relied heavily on expensive and time-consuming robotic data collection. The core idea is to find transferable representations from human actions that can effectively guide robotic control. The success of this approach hinges on the ability to identify low-level, physical interactions in human videos that are sufficiently similar to robotic tasks, thus enabling knowledge transfer without requiring direct robotic annotation. This involves carefully designing representations that effectively capture the geometric and dynamic aspects of movement; 4D representations (3D spatial coordinates plus time) have shown promise in this regard, effectively encoding the physical structure and temporal progression of actions. This technique presents opportunities to significantly reduce the data requirements for training complex robotic control policies, making robotic learning more accessible and scalable. However, challenges remain in handling differences between human and robotic embodiments, as well as in addressing the inherent variability of human actions in the videos. Future work could focus on refining the representation learning methods to ensure greater robustness and generalizability across diverse environments and robotic platforms.
Cross-robot Generalization#
Cross-robot generalization, the ability of a robotic model trained on one robot platform to effectively transfer its learned skills and knowledge to other robots with different morphologies and control systems, is a crucial yet challenging aspect of robotics research. Success in this area greatly reduces the need for extensive retraining across diverse robotic hardware, thus accelerating development cycles and promoting scalability. The paper’s emphasis on low-level 4D representations, derived from human video data and focused on geometric relationships, suggests a potential pathway to achieve better cross-robot generalization. This is because low-level representations capture fundamental physical interactions rather than task-specific details tied to particular robot designs. By abstracting from robot-specific characteristics, the model learns more generalizable skills that can be adapted to different hardware. However, the extent to which this approach addresses challenges such as discrepancies in sensor modalities, actuation dynamics, and control architectures remains a key question. Future work should focus on quantitatively evaluating the model’s performance across a wider range of robots and investigating techniques to further enhance the robustness and adaptability of these low-level learned skills in various robotic configurations.
Future Work: Invariance#
Future work focusing on invariance in robotic learning is crucial for building robust and generalizable models. A key challenge lies in disentangling object and camera motion from the learned 4D representations. Current approaches track points in camera coordinates, limiting their ability to generalize across different camera viewpoints and robot embodiments. Future work should explore methods to represent and track objects in a world-centered coordinate system, potentially using SLAM techniques to address the issue of camera motion. Incorporating multi-view information from multiple cameras could also improve robustness to occlusions and enhance 3D scene understanding. Furthermore, refining the pre-training objective to explicitly encourage invariance to camera parameters and scene variations would be beneficial. By addressing these challenges, researchers can significantly enhance the generalizability and real-world applicability of pre-trained robotic models. Investigating efficient methods for selectively tracking only relevant or moving points would increase computational efficiency and improve focus on critical task-related aspects. This focus would minimize the influence of background noise and other distracting visual elements that currently hinder learning and performance.
More visual insights#
More on figures

🔼 ARM4R training is divided into three stages. The first stage uses a large-scale egocentric human video dataset (Epic-Kitchens100) to pre-train the model to predict 3D point tracks over time, establishing a strong understanding of scene-wide 4D representations (3D points plus time). The second stage fine-tunes this pre-trained model on a smaller dataset (1-2K demonstrations) of robotic scenes. This adaptation step refines the point tracking to account for the differences in camera views and the robotic environment. Finally, the third stage fine-tunes the model to predict robot proprioceptive states instead of 3D points. This allows the model to transfer knowledge from human video data and use it effectively for low-level robotic control.
read the caption
Figure 2: ARM4R is trained in three stages. Top Grey Box: The first two stages focus on learning a scene-wide 4D representation by predicting 3D points across time, where Stage 1 pre-trains on a large egocentric human dataset (Epic-Kitchens100), and Stage 2 fine-tunes on a smaller dataset (1-2K demonstrations) of robotic scenes, adapting the point tracking to robotic scene and camera. Bottom Grey Box: Finally, the model is fine-tuned to predict robot proprioceptive states rather than 3D points to enable robotic control.

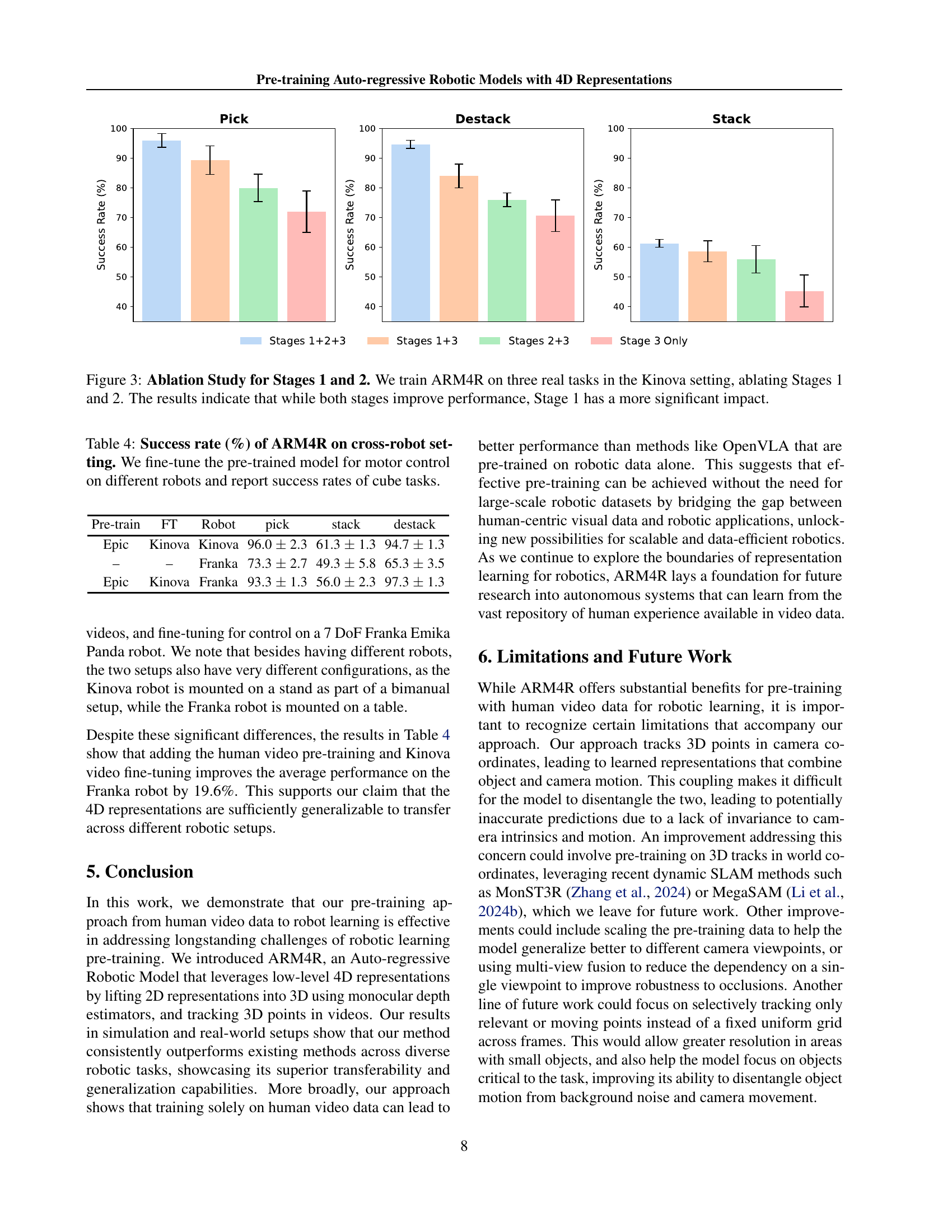
🔼 This ablation study investigates the individual contributions of the two pre-training stages (Stage 1: human video pre-training, Stage 2: robot video fine-tuning) in ARM4R’s performance on three real-world robotic tasks using a Kinova robot. By systematically removing one stage at a time, the experiment isolates the impact of each pre-training phase. The results demonstrate that while both stages contribute to improved performance, the human video pre-training (Stage 1) has a considerably more significant positive effect than the robot video fine-tuning (Stage 2). This suggests that learning from diverse human actions is more crucial for generalizing to new robotic tasks than fine-tuning on limited robot-specific data.
read the caption
Figure 3: Ablation Study for Stages 1 and 2. We train ARM4R on three real tasks in the Kinova setting, ablating Stages 1 and 2. The results indicate that while both stages improve performance, Stage 1 has a more significant impact.

🔼 This figure visualizes the performance of the ARM4R model on 3D point tracking tasks. It shows examples of the model’s predictions overlaid on frames from both in-domain (Epic-Kitchens) and out-of-domain (Ego4D) human videos. Each row displays a different video sequence, demonstrating how well the model can track 3D points across time even in videos it has not been trained on directly. The visual comparison highlights the model’s generalization capabilities.
read the caption
Figure 4: Visualization of ARM4R’s 3D Point Track results on randomly chosen Epic-Kitchens (in-domain) and Ego-4D (out-of-domain) human videos.

🔼 Figure 5 presents a qualitative assessment of ARM4R’s 3D point tracking capabilities. It showcases the model’s performance on both in-domain (Kinova robot) and out-of-domain (OpenX Embodiment) robot videos. The figure visually demonstrates the accuracy and robustness of the 3D point tracks generated by the model across diverse robotic scenarios and datasets, highlighting its ability to generalize beyond the specific data it was trained on.
read the caption
Figure 5: Visualization of ARM4R’s 3D Point Track results on randomly chosen Kinova (in-domain) and Open X-Embodiment (out-of-domain) robot videos.

🔼 The image shows the real-world experimental setup used for the Kinova robot. The robot arm is mounted on a base designed to mimic the height and orientation of a human shoulder, providing a more naturalistic setting for robotic manipulation tasks. Two Logitech BRIO 4K cameras are strategically positioned to capture the manipulation actions: one from an ego-centric view (as if from the robot’s perspective) and one from the side. This setup allows for comprehensive data collection, including visual information from multiple angles.
read the caption
Figure 6: The real-world experiment setup of Kinova robot.

🔼 This figure shows the experimental setup and tasks conducted using a Kinova Gen3 robot. It details the specific configurations for tasks such as picking up a cube, stacking cubes, destacking cubes, picking and placing toys or a basketball, and pushing buttons. Each task involves distinct actions, object placements, and movement patterns, showcasing the variety of robotic manipulation scenarios tested in the study. The image displays the robot’s arm performing each task in various stages and positions.
read the caption
Figure 7: Task building of real-world Kinova setup.

🔼 The image shows the real-world experimental setup for the Franka robot. A Franka Emika Panda robot arm is equipped with a Franka gripper and is positioned on a table. Two Logitech BRIO 4K cameras are set up on either side of the table to capture RGB images of the robot’s actions, providing multi-view visual data for the experiments. Autofocus is disabled on the cameras, and they capture images at a resolution of 640x480.
read the caption
Figure 8: The real-world experiment setup of Franka robot.
More on tables
| open |
| drawer |
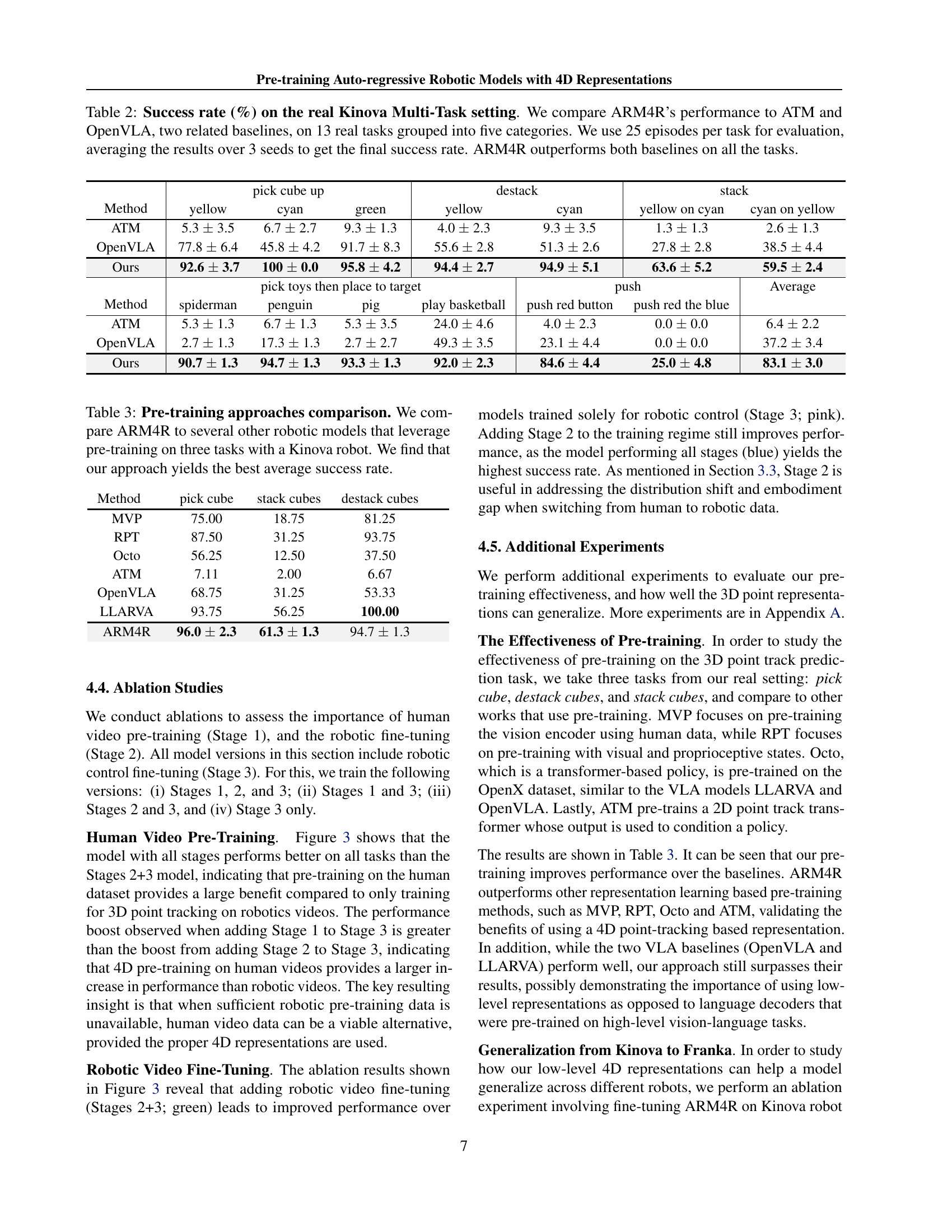
🔼 This table presents a comparison of the success rates achieved by three different robotic models: ARM4R, ATM, and OpenVLA, across thirteen real-world tasks using a Kinova Gen3 robot. The tasks are categorized into five groups for better analysis. Each model’s performance is evaluated over 25 episodes per task, with the results averaged across three random seeds to ensure robustness. ARM4R consistently outperforms both ATM and OpenVLA on all tasks.
read the caption
Table 2: Success rate (%) on the real Kinova Multi-Task setting. We compare ARM4R’s performance to ATM and OpenVLA, two related baselines, on 13 real tasks grouped into five categories. We use 25 episodes per task for evaluation, averaging the results over 3 seeds to get the final success rate. ARM4R outperforms both baselines on all the tasks.
| meat off |
| grill |
🔼 This table compares the performance of ARM4R against other robotic models that utilize pre-training. The comparison is done across three tasks using a Kinova robot. The results demonstrate that ARM4R achieves the highest average success rate among all the models considered.
read the caption
Table 3: Pre-training approaches comparison. We compare ARM4R to several other robotic models that leverage pre-training on three tasks with a Kinova robot. We find that our approach yields the best average success rate.
| turn |
| tap |
🔼 This table presents the success rates achieved by the ARM4R model on three cube-manipulation tasks (pick cube, stack cubes, destack cubes) when fine-tuned for motor control on different robot platforms. Specifically, it compares the performance of ARM4R pre-trained on human video data and then fine-tuned on a Kinova robot to the performance when that same pre-trained model is fine-tuned on a Franka Emika robot. It demonstrates the model’s ability to generalize across different robot hardware.
read the caption
Table 4: Success rate (%) of ARM4R on cross-robot setting. We fine-tune the pre-trained model for motor control on different robots and report success rates of cube tasks.
| put |
| money |
🔼 This table lists the hyperparameters used in the three training stages of the ARM4R model. It shows the learning rate, weight decay, batch size, and number of epochs used for each stage: pre-training on human videos (Stage 1), fine-tuning on robotic data (Stage 2), and fine-tuning for robotic control (Stage 3). The values indicate the specific settings used to optimize the model’s training for each phase.
read the caption
Table 5: Training Hyperparameters for the three stages.
Full paper#