TL;DR#
Large AI models excel in reasoning but demand high resources and raise privacy issues. Small Language Models (SLMs) offer a solution, balancing performance and efficiency with lower costs. A key challenge is enhancing SLM reasoning while keeping them small, crucial for accessibility and privacy. Existing models often require cloud deployment raising privacy concerns. Thus, there is a need for practical AI systems capable of performing reasoning tasks, while reducing barriers to AI system adoption and addressing user privacy requirements through model size reduction.
This paper introduces InfiR, a novel training pipeline enhancing reasoning in small models for edge deployment. InfiR includes a pre- and post-training pipeline, achieving state-of-the-art results at the 1B parameter scale. The InfiR-VL-1.6B model excels in Android scenarios, improving accuracy. The project aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github.com/Reallm-Labs/InfiR.
Key Takeaways#
Why does it matter?#
InfiR offers efficient, smaller AI models with strong reasoning, enhancing accessibility and addressing privacy, a key advancement for edge deployment and broader AI adoption.
Visual Insights#

🔼 This figure illustrates the data preprocessing pipeline used to create high-quality training data for small language models. The pipeline consists of five stages: 1) Heuristic Filtering removes low-quality data using various methods. 2) Reasoning-Oriented Text Recall focuses on selecting data relevant to reasoning tasks. 3) Deduplication removes redundant data. 4) Quality Assessment employs various techniques to ensure the quality of the selected data. 5) Decontamination removes potentially biased or contaminated information. The caption notes that comparative experiments using LLaMA3.2-1B with datasets processed using different cleaning methods validate the importance of high data quality.
read the caption
Figure 1: The pipeline of pretrain data drocesses: heuristic filtering, reasoning-oriented text recall, deduplication, quality assessment and decontamination. Comparative experiments on LLaMA3.2-1B with differently cleaned datasets validate the significance of data quality.
| Type Source | Datasets |
|---|---|
| Web Pages | Common crawl, FineWeb-Edu, DCLM |
| Math | InfiMM-WebMath-40B, OpenWebMath, MathCode-Pile, Proof-pile-2, finemath |
| Code | the-Stack-v2, Starcoder |
| General Knowledge | arXiv, StackExchange, peS2o |
| Encyclopedia | Wikipedia |
| Open-Source Instruction | FLAN, Infinity Instruct |
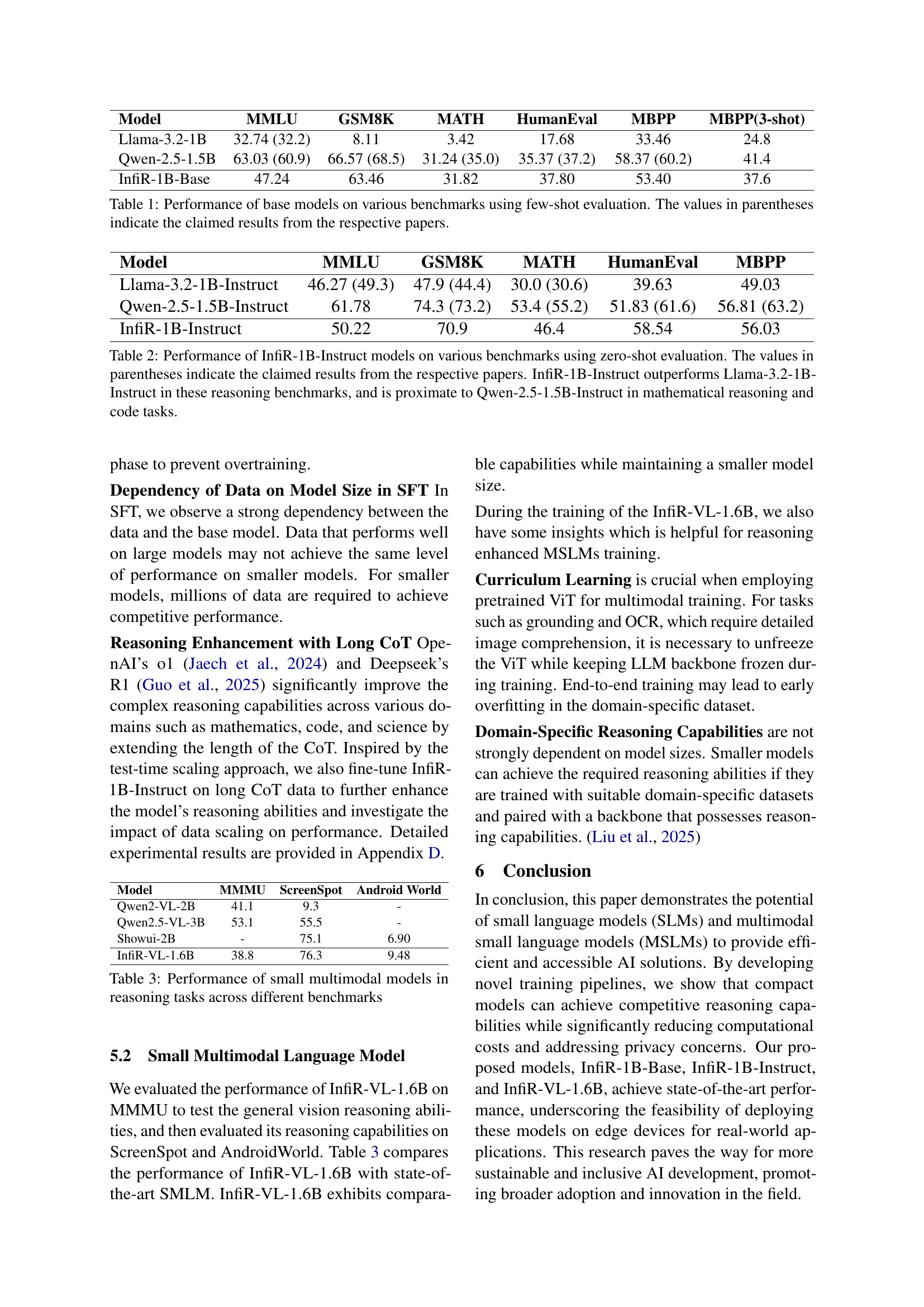
🔼 This table compares the performance of several different base language models on a variety of established benchmarks. The models are evaluated using a few-shot evaluation approach. The table shows each model’s scores on various benchmarks, such as MMLU for general reasoning, GSM8K for math word problems, MATH for advanced math problems, HumanEval for code generation, and MBPP for Python programming tasks. Scores reported in parentheses represent the performance values claimed by the original authors of the respective papers. This allows for a comparison between the results reported here and the performance reported by the original research teams.
read the caption
Table 1: Performance of base models on various benchmarks using few-shot evaluation. The values in parentheses indicate the claimed results from the respective papers.
In-depth insights#
InfiR: Edge Reasoning#
InfiR: Edge Reasoning suggests a focus on enabling AI reasoning capabilities directly on edge devices. This implies optimizing small language models (SLMs) for efficient computation and deployment in resource-constrained environments. Key challenges include balancing model size and reasoning performance, addressing privacy concerns by processing data locally, and developing specialized training pipelines and architectures tailored for edge deployment. The research likely explores techniques for model compression, knowledge distillation, and efficient inference to achieve state-of-the-art reasoning on edge devices while minimizing latency and power consumption. Furthermore, it may consider incorporating multimodal inputs to enhance the reasoning process in real-world applications.
SLM Training Pipeline#
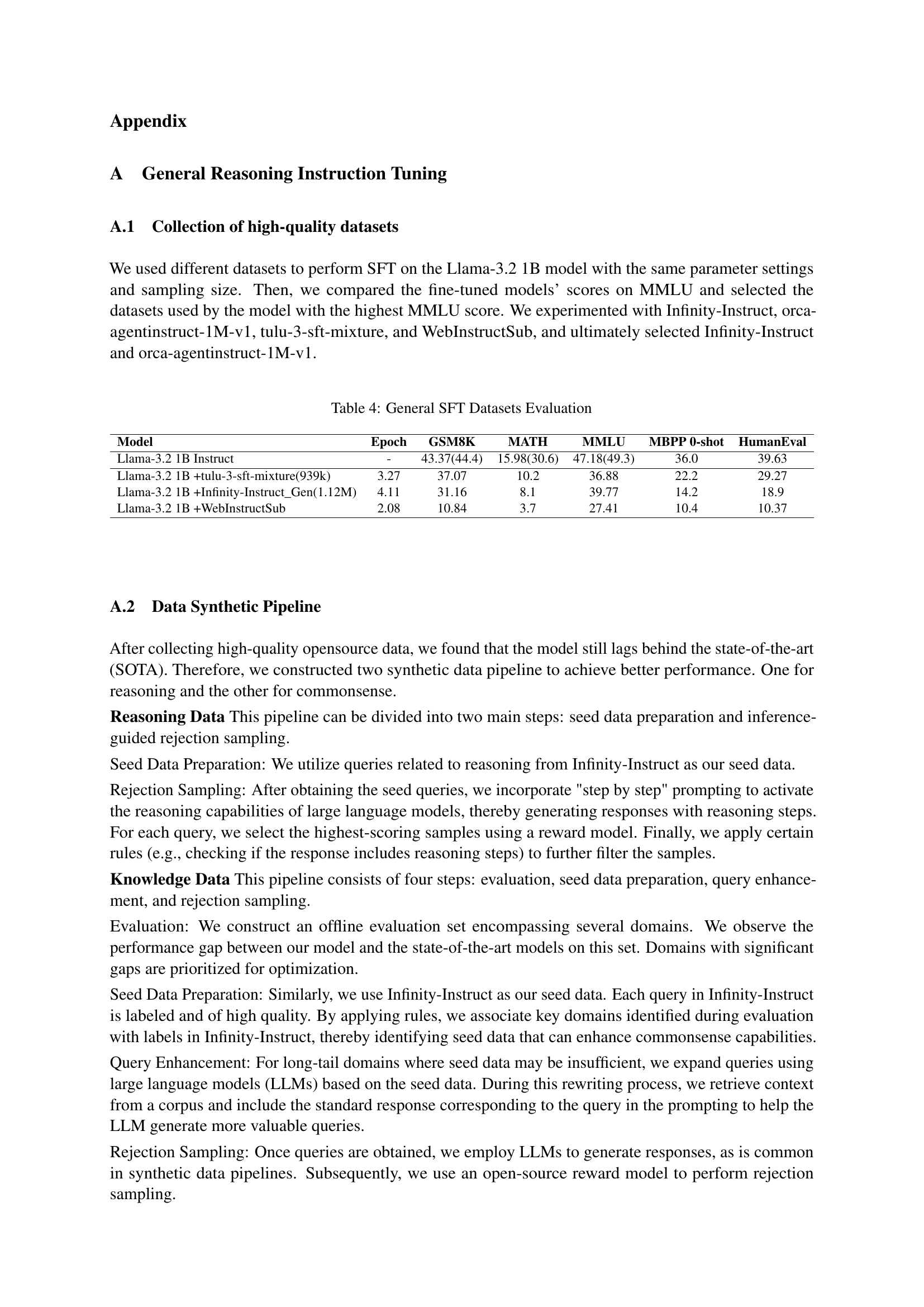
I don’t see an explicit “SLM Training Pipeline” section. However, inferring from the content, a hypothetical SLM training pipeline would likely involve several key stages. Pre-training focuses on imbuing the model with broad knowledge using a large corpus of text and code, with a heavy emphasis on high-quality data and aggressive noise filtering via heuristic and model-based methods. The architecture is based on Llama-3.2 1B with a focus on 900 billion tokens. Data annealing refines the model, emphasizing reasoning capabilities with a smaller, carefully curated dataset. Subsequently, supervised fine-tuning (SFT) would further hone the model’s instruction-following and reasoning abilities via datasets involving instruction, reasoning and code relation. A diverse, high-quality SFT dataset ensures robustness. A visual projector helps align visual features. Rejection sampling is also used to improve the quality of responses. The aim is to allow smaller models to perform tasks efficiently.
Data Annealing#
Data annealing, as I envision it, is a clever method for refining a pre-trained model. It involves further training with a dataset emphasizing high-quality reasoning and data that bridges the gap between pre-training and the later fine-tuning stages. It’s about improving reasoning abilities. Annealing dataset construction requires careful selection of examples, blending original data with open source and synthetic datasets. This focuses on keeping source code while dropping the web data. Proper setting on data ratios is very important.
MultiModal Finetuning#
Multimodal fine-tuning is a critical stage for adapting pre-trained models to specific downstream tasks, particularly when dealing with data from diverse sources. This process involves adjusting the model’s parameters to effectively integrate and process information from various modalities such as images, text, and audio. Effective strategies typically involve carefully curated datasets, tailored loss functions, and specialized architectures designed to handle the complexities of cross-modal interactions. Transfer learning techniques are often employed, leveraging knowledge gained from large-scale pre-training to accelerate convergence and improve generalization on target tasks. Data augmentation and regularization methods play a vital role in preventing overfitting and ensuring robust performance across different scenarios.
Long CoT Impact#
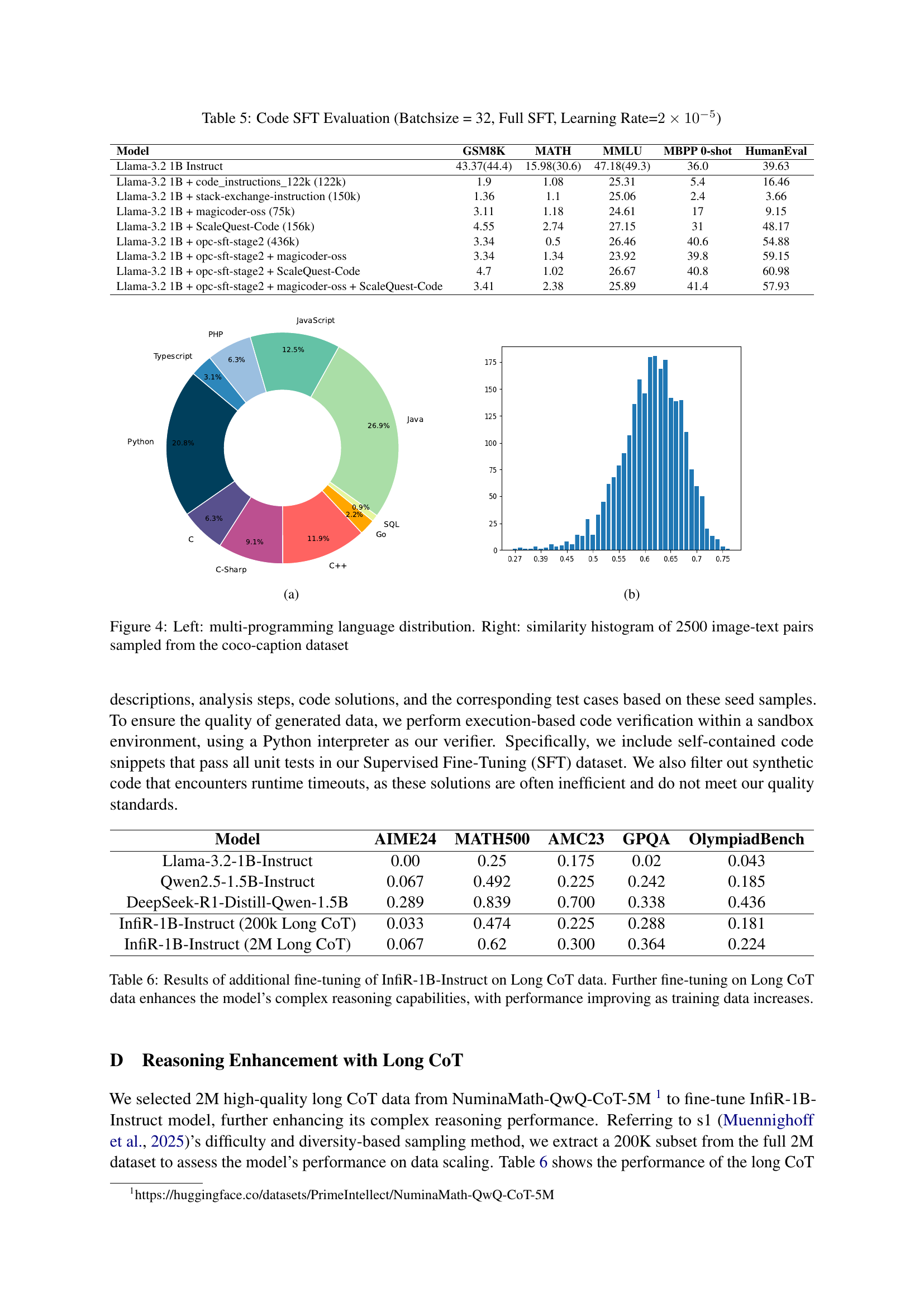
The impact of long Chain-of-Thought (CoT) data on small language models is a fascinating area. Extending the CoT during training may significantly improve complex reasoning, but it has drawbacks. Longer CoTs demand increased computational resources during both training and inference. Small models may struggle to effectively learn from extremely long CoTs due to limited capacity, potentially leading to overfitting. The quality of long CoT data is paramount; noisy or irrelevant steps can hinder learning. Careful data curation and filtering are essential. The optimal CoT length may vary depending on the task and model size. There’s a need for adaptive techniques that dynamically adjust CoT length during inference to balance accuracy and efficiency.
More visual insights#
More on figures
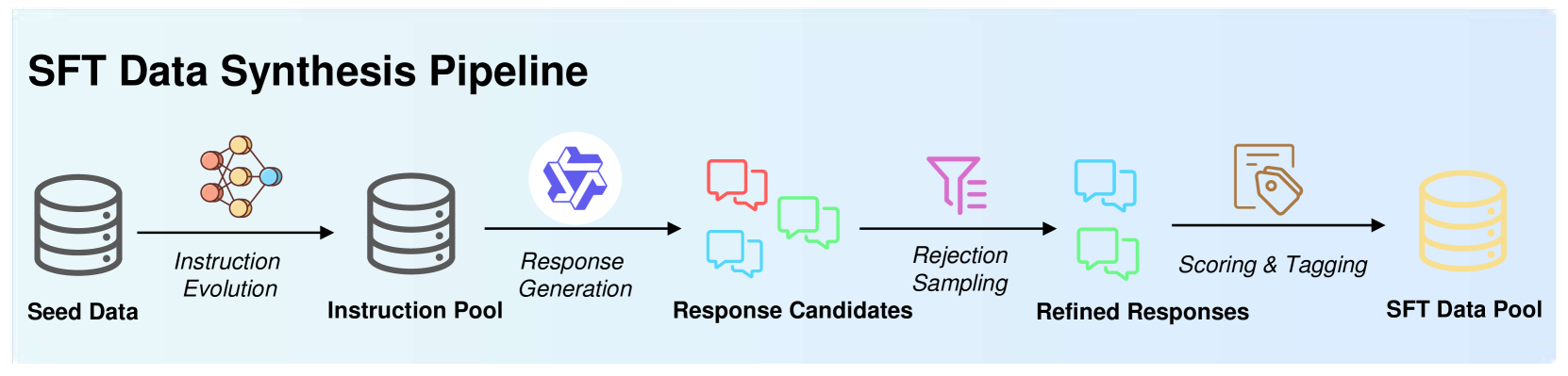
🔼 This figure illustrates the process of creating a high-quality dataset for supervised fine-tuning. It starts with a set of high-quality seed data which is then expanded by generating variations of the instructions (instruction evolution). A large language model (Qwen-2.5-32B-Instruct) generates multiple response candidates for each instruction. To ensure high quality, a rejection sampling method is used, leveraging a reward model and a sandbox environment to filter out low-quality responses. The final curated data is scored for quality and difficulty, and then labeled with domain-specific tags before being used in the fine-tuning phase.
read the caption
Figure 2: Supervised fine-tuning data synthesis pipeline. The pipeline initiates with a set of high-quality seed data, which is augmented through instruction evolution. Response candidates are generated using the Qwen-2.5-32B-Instruct model, followed by rejection sampling with a reward model and sandbox environment. Finally, we score the curated data for quality and difficulty, and assign domain labels.

🔼 Figure 3 illustrates the training process for Multimodal Small Language Models (MSLMs). It begins with a pre-training stage focusing on fundamental visual-language alignment through tasks like captioning and question answering. This is followed by a text rendering stage which generates data by converting various text formats (documents, code, etc.) into visual representations to enhance the model’s understanding of the relationship between visual and textual information. Next, instruction tuning further refines the model’s capabilities. This stage includes instruction-tuning using multiple datasets which cover diverse domains (mathematics, operator system tasks, etc.) across various modalities (single image, multiple images, text). This progressive training approach culminates in an MSLM with enhanced reasoning abilities in both mathematical and operating system contexts.
read the caption
Figure 3: Illustration of the MSLM training pipeline and the MSLM training details, showcasing the progression from captioning and QA tasks to text rendering, followed by instruction-tuning, culminating in enhanced mathematical and operating system reasoning abilities.

🔼 This figure shows the distribution of programming languages used in the dataset. Python is the most prevalent language, followed by Java, JavaScript, and C++, indicating a focus on popular and widely used languages in software development. The other languages are used to a lesser extent but still contribute to the diversity of the dataset. This diversity ensures the model is exposed to a broad range of coding styles and paradigms.
read the caption
(a)

🔼 The figure shows a histogram of the similarity scores for 2500 image-text pairs sampled from the COCO-caption dataset. The x-axis represents the similarity score, and the y-axis represents the frequency. The distribution is heavily concentrated around a similarity score of 0.7, indicating that most image-text pairs have relatively high similarity. There is a tail towards lower similarity scores, which may represent image-text pairs with lower semantic alignment. This distribution is important because it informs a decision about a similarity threshold used for filtering low-quality pairs from the dataset during the data cleaning phase, impacting the overall quality of the multimodal model training.
read the caption
(b)
Full paper#