TL;DR#
Large language models (LLMs) have excelled in reasoning, prompting efforts to distill their capabilities into smaller models. However, this paper reveals the Small Model Learnability Gap: small models struggle with complex reasoning traces or distillation from larger models, performing better with shorter, simpler reasoning. This is because they find it hard to internalize the logic due to their limited ability.
To address this, the paper introduces Mix Distillation, a strategy that balances reasoning complexity by combining long and short reasoning or blending responses from larger and smaller models. Experiments demonstrate that Mix Distillation significantly enhances small model reasoning compared to training on either data type alone, adapting reasoning for effective capability transfer.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it highlights the limitations of directly applying large model distillation to smaller models and introduces a novel approach (Mix Distillation) to overcome these limitations. This work paves the way for more effective knowledge transfer strategies and opens new avenues for research on adapting reasoning complexity for smaller models.
Visual Insights#

🔼 This figure illustrates the Small Model Learnability Gap. It shows that smaller language models (with 3 billion parameters or less) don’t consistently improve their performance when trained using long chain-of-thought (CoT) reasoning examples or by distilling knowledge from much larger models. Instead, these smaller models perform better when trained on shorter, simpler CoT examples or when knowledge is distilled from similarly sized models. This is because their learning capacity is better suited to shorter, less complex reasoning steps. The gap highlights the difficulty of transferring complex reasoning abilities from large to small models directly.
read the caption
Figure 1: Small student models (≤\leq≤3B parameters) do not consistently benefit from long CoT reasoning or distillation from large teacher models. Instead, they perform better when fine-tuned on shorter CoT reasoning or distilled from smaller teachers, which better matches their intrinsic learning capacity. We term this phenomenon the Small Model Learnability Gap.
| Student Model | Better? | |||
| Qwen2.5-0.5B | 14.8 | 19.5 | -4.7 | Short |
| Qwen2.5-1.5B | 27.0 | 34.2 | -7.1 | Short |
| Qwen2.5-3B | 40.3 | 43.4 | -3.1 | Short |
| Qwen2.5-7B | 48.9 | 47.2 | 1.7 | Long |
| Qwen2.5-14B | 59.2 | 54.3 | 4.9 | Long |
| Qwen2.5-32B | 73.0 | 59.3 | 13.7 | Long |
| Llama-3.2-1B | 15.8 | 19.5 | -3.7 | Short |
| Llama-3.2-3B | 32.5 | 33.1 | -0.6 | Short |
| Llama-3.1-8B | 35.2 | 31.5 | 3.7 | Long |
| Llama-3.3-70B | 58.2 | 54.3 | 3.8 | Long |
🔼 This table compares the average performance of smaller language models (student models) after fine-tuning on datasets with long chain-of-thought (CoT) reasoning and short CoT reasoning. Long CoT refers to detailed reasoning steps, while short CoT uses more concise explanations. The results show the performance difference (PLong - PShort) for each model. The purpose is to demonstrate the phenomenon of the Small Model Learnability Gap, where smaller models don’t consistently benefit from long, complex CoT reasoning and might perform better with shorter, simpler reasoning traces.
read the caption
Table 1: Comparison of the average performance between fine-tuning with long CoT (PLongsubscript𝑃𝐿𝑜𝑛𝑔P_{Long}italic_P start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT) and short CoT (PShortsubscript𝑃𝑆ℎ𝑜𝑟𝑡P_{Short}italic_P start_POSTSUBSCRIPT italic_S italic_h italic_o italic_r italic_t end_POSTSUBSCRIPT). We find that small student models may struggle to learn from long CoT data.
In-depth insights#
Learnability Gap#
The ‘Learnability Gap,’ as introduced in the paper, underscores a crucial limitation in directly transferring reasoning capabilities from large models to smaller ones. Smaller models often struggle to effectively learn from the complex reasoning traces (e.g., long CoT) generated by larger models, leading to suboptimal performance. Instead, they tend to benefit more from simpler, shorter reasoning chains that better align with their intrinsic learning capacity. This gap suggests that direct distillation, a common strategy, may not always be the most effective approach for imbuing smaller models with sophisticated reasoning skills. The underlying causes of this gap are multifaceted. Limited domain knowledge of smaller models, coupled with a tendency to be overwhelmed by complex reasoning steps contribute to their inability to effectively leverage information from longer CoT or larger teacher CoT data. The paper addresses this gap by proposing ‘Mix Distillation’, a strategy that blends various forms of reasoning traces (short and long CoT, reasoning from larger and smaller models) to balance complexity and facilitate effective knowledge transfer. Mix distillation yields better results.
Mix Distillation#
Mix Distillation is introduced to bridge the observed learnability gap in small models. The approach blends easier-to-learn data with more challenging data. Mix Distillation leverages the strengths of both. The insight is small models perform better on data matching their inherent distribution. They struggle with data exhibiting greater distribution shifts. The mixed long CoT and large teacher CoT data’s token distribution may become closer to small models’ inherent distribution, enabling them to learn more effectively from challenging datasets. Two versions are proposed: Mix-Long combines long and short CoT data. Mix-Large combines large teacher CoT with small teacher CoT. The experiment results show, this method helps to solve the observed learnability gap.
CoT Complexity#
Chain-of-Thought (CoT) complexity is a critical factor in determining the effectiveness of large language models (LLMs), especially when transferring reasoning capabilities to smaller models. It encapsulates several dimensions, including the length of reasoning chains, the depth of intermediate steps, and the intrinsic difficulty of each step. Longer CoT traces don’t always guarantee better outcomes, particularly for smaller models with limited capacity. This suggests a learnability gap where intricate reasoning processes become overwhelming, hindering effective knowledge transfer. Adapting CoT complexity is therefore crucial, balancing detail with conciseness to align with the student model’s intrinsic learning capacity. Strategies like Mix Distillation, which blends long and short CoT examples, can bridge this gap by exposing models to varied levels of reasoning complexity, enhancing overall performance. It is important to optimize the CoT complexity of the teacher model for the distillation process.
Speaking Styles#
The section on speaking styles reveals a fascinating aspect of language model behavior post-fine-tuning. By analyzing token distribution shifts, the research pinpoints that long CoT and large teacher CoT primarily influence a student model’s expressive and stylistic elements. This goes beyond mere factual knowledge transfer; models adapt their communication style, adopting patterns from the training data. The identification of tokens like “wait,” “But,” and “Let” as being significantly impacted highlights the nuances of this stylistic adaptation. These words are not directly related to mathematical reasoning itself, yet their alteration suggests a deeper integration of the teacher model’s communication nuances. The research emphasizes how fine-tuning with different CoT lengths not only affects the accuracy of the solutions but also subtly reshapes the way a model expresses itself. This offers further insights into the nature of knowledge distillation, where a model learns to mimic the tone and presentation of the teacher model. It would be interesting to study whether these changes are superficial or lead to a more robust understanding of the task and improved generalization in different contexts. Ultimately, this observation underscores the importance of carefully selecting training data to avoid unintended stylistic biases.
Domain Matters#
The influence of domain expertise on model performance is paramount; a model’s grasp of domain-specific nuances critically shapes its problem-solving capabilities. Models trained on a diverse range of tasks may show proficiency across different areas but often lack the depth of understanding seen in models specifically honed for a single domain. This domain-specific understanding often enables more accurate and efficient reasoning. The disparity in performance arises from the concentrated exposure to domain-relevant data, which enables a model to learn intricate patterns, relationships, and subtleties that would otherwise be diluted in a more generalized training scheme. Adaptation to specific domains is crucial for achieving state-of-the-art performance in complex reasoning tasks. The ability to effectively leverage pre-existing knowledge and adapt it to new situations is a hallmark of intelligent systems.
More visual insights#
More on figures

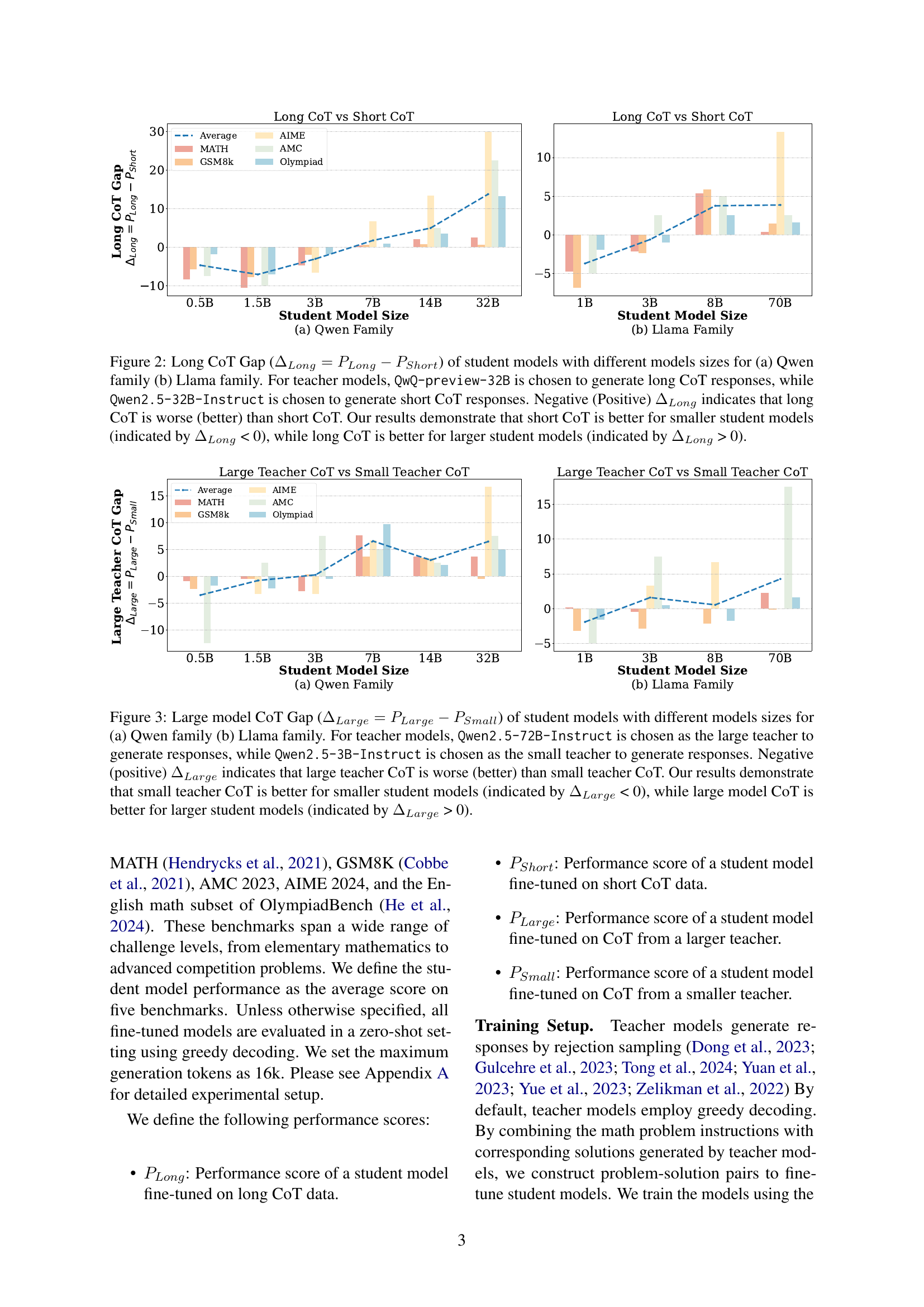
🔼 This figure illustrates the performance difference between using long chain-of-thought (CoT) reasoning and short CoT reasoning for training small language models. The x-axis represents the size of the student model (in billions of parameters), and the y-axis represents the difference in performance (Long CoT Gap) calculated as the performance with long CoT minus the performance with short CoT. A positive Long CoT Gap indicates that long CoT improves performance, while a negative gap means short CoT is better. The results show that smaller models (less than 3B parameters) perform better with short CoT, whereas larger models benefit more from long CoT training. The figure includes separate graphs for the Qwen family and Llama family of language models, highlighting that this trend holds consistently across different model architectures.
read the caption
Figure 2: Long CoT Gap (ΔLong=PLong−PShortsubscriptΔ𝐿𝑜𝑛𝑔subscript𝑃𝐿𝑜𝑛𝑔subscript𝑃𝑆ℎ𝑜𝑟𝑡\Delta_{Long}=P_{Long}-P_{Short}roman_Δ start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT = italic_P start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT - italic_P start_POSTSUBSCRIPT italic_S italic_h italic_o italic_r italic_t end_POSTSUBSCRIPT) of student models with different models sizes for (a) Qwen family (b) Llama family. For teacher models, QwQ-preview-32B is chosen to generate long CoT responses, while Qwen2.5-32B-Instruct is chosen to generate short CoT responses. Negative (Positive) ΔLongsubscriptΔ𝐿𝑜𝑛𝑔\Delta_{Long}roman_Δ start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT indicates that long CoT is worse (better) than short CoT. Our results demonstrate that short CoT is better for smaller student models (indicated by ΔLongsubscriptΔ𝐿𝑜𝑛𝑔\Delta_{Long}roman_Δ start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT < 0), while long CoT is better for larger student models (indicated by ΔLongsubscriptΔ𝐿𝑜𝑛𝑔\Delta_{Long}roman_Δ start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT > 0).

🔼 This figure displays the performance difference between using large teacher-generated chain-of-thought (CoT) reasoning and small teacher-generated CoT reasoning to fine-tune student models of varying sizes. The x-axis represents the size of the student model (in billions of parameters), and the y-axis shows the difference in performance (Large Teacher CoT performance - Small Teacher CoT performance). Positive values indicate that the large teacher CoT is better, while negative values mean the small teacher CoT performs better. The results are shown separately for Qwen and Llama families of language models. The key finding is that smaller student models benefit from using CoT from smaller teachers, while larger models benefit more from using CoT from larger teachers.
read the caption
Figure 3: Large model CoT Gap (ΔLarge=PLarge−PSmallsubscriptΔ𝐿𝑎𝑟𝑔𝑒subscript𝑃𝐿𝑎𝑟𝑔𝑒subscript𝑃𝑆𝑚𝑎𝑙𝑙\Delta_{Large}=P_{Large}-P_{Small}roman_Δ start_POSTSUBSCRIPT italic_L italic_a italic_r italic_g italic_e end_POSTSUBSCRIPT = italic_P start_POSTSUBSCRIPT italic_L italic_a italic_r italic_g italic_e end_POSTSUBSCRIPT - italic_P start_POSTSUBSCRIPT italic_S italic_m italic_a italic_l italic_l end_POSTSUBSCRIPT) of student models with different models sizes for (a) Qwen family (b) Llama family. For teacher models, Qwen2.5-72B-Instruct is chosen as the large teacher to generate responses, while Qwen2.5-3B-Instruct is chosen as the small teacher to generate responses. Negative (positive) ΔLargesubscriptΔ𝐿𝑎𝑟𝑔𝑒\Delta_{Large}roman_Δ start_POSTSUBSCRIPT italic_L italic_a italic_r italic_g italic_e end_POSTSUBSCRIPT indicates that large teacher CoT is worse (better) than small teacher CoT. Our results demonstrate that small teacher CoT is better for smaller student models (indicated by ΔLargesubscriptΔ𝐿𝑎𝑟𝑔𝑒\Delta_{Large}roman_Δ start_POSTSUBSCRIPT italic_L italic_a italic_r italic_g italic_e end_POSTSUBSCRIPT < 0), while large model CoT is better for larger student models (indicated by ΔLargesubscriptΔ𝐿𝑎𝑟𝑔𝑒\Delta_{Large}roman_Δ start_POSTSUBSCRIPT italic_L italic_a italic_r italic_g italic_e end_POSTSUBSCRIPT > 0).
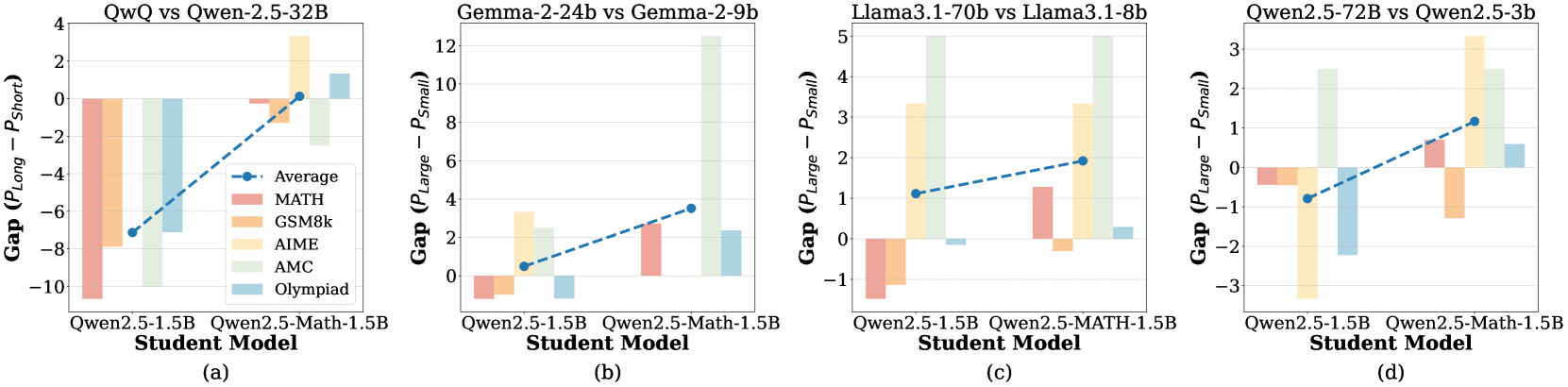
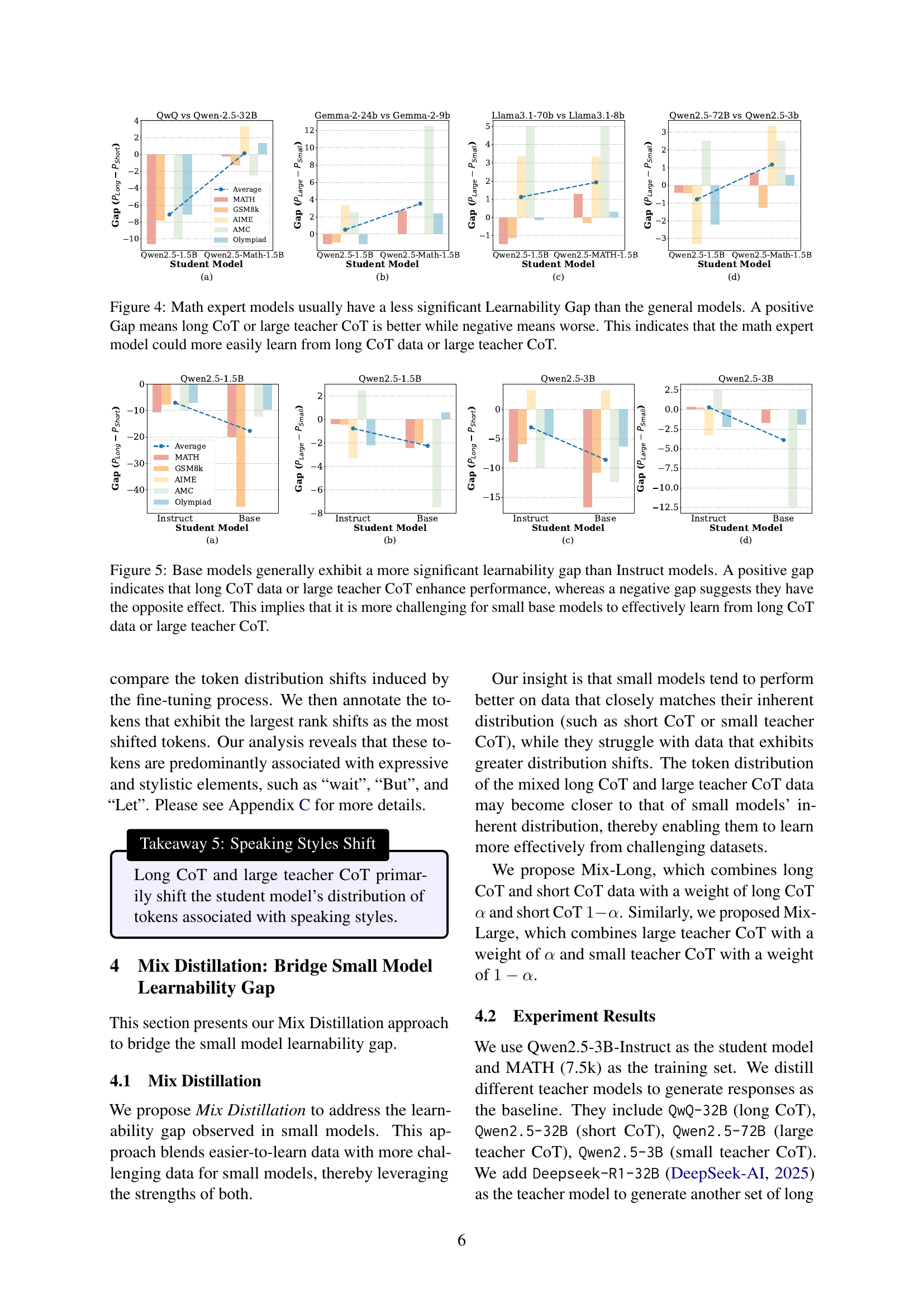
🔼 This figure compares the performance of general-purpose and math-specialized language models (LLMs) when trained using different methods: long chain-of-thought (CoT) reasoning, short CoT reasoning, large teacher CoT, and small teacher CoT. A positive gap indicates that the longer/larger methods led to better performance than shorter/smaller methods. The results show that math-specialized models exhibit a smaller learnability gap; they are less sensitive to the complexity of the training data, demonstrating a stronger ability to learn from complex, large teacher CoT data.
read the caption
Figure 4: Math expert models usually have a less significant Learnability Gap than the general models. A positive Gap means long CoT or large teacher CoT is better while negative means worse. This indicates that the math expert model could more easily learn from long CoT data or large teacher CoT.

🔼 This figure compares the performance of base and instruct models of varying sizes when trained using different types of chain-of-thought (CoT) reasoning data: long CoT, short CoT, large teacher CoT, and small teacher CoT. The x-axis represents the model size, while the y-axis shows the difference in performance between using complex (long CoT or large teacher CoT) vs simpler (short CoT or small teacher CoT) reasoning data. A positive value on the y-axis indicates that the model performs better with complex reasoning data, while a negative value shows the opposite. The results reveal that smaller base models struggle to effectively utilize the complex reasoning data provided by longer chains of thought or larger teacher models, exhibiting a greater performance difference compared to instruct models. This highlights a significant ’learnability gap’ between base and instruct models.
read the caption
Figure 5: Base models generally exhibit a more significant learnability gap than Instruct models. A positive gap indicates that long CoT data or large teacher CoT enhance performance, whereas a negative gap suggests they have the opposite effect. This implies that it is more challenging for small base models to effectively learn from long CoT data or large teacher CoT.

🔼 This figure illustrates the impact of varying the ratio of long Chain-of-Thought (CoT) examples or large teacher model responses when training a smaller language model using Mix Distillation. The x-axis represents the weighting of long CoT data (or large teacher data) in the training data, ranging from 0 to 1. The y-axis shows the average performance of the Qwen2.5-3B-Instruct model across several benchmarks. The graph reveals an optimal mix ratio where a weighting of 0.2 for long CoT or large teacher data results in peak performance. This suggests a balance needs to be struck between the complexity of long CoT examples and the capacity of smaller models.
read the caption
Figure 6: The average performance varies with the mix weight of long CoT or large teacher CoT data. Qwen2.5-3B-Instruct is chosen as the student model. At a weight of 0.2, mix distillation achieves the highest average performance.

🔼 Figure 7 presents a comparative analysis of model performance across three different training methodologies: long chain-of-thought (CoT), short CoT, and Mix-Long (a blend of both). The figure showcases how models trained solely on long CoT reasoning may produce overly complex and ultimately incorrect responses due to an inability to identify a concise solution path. In contrast, models trained exclusively on short CoT sequences provide short, yet often inaccurate results due to a lack of detailed reasoning. The Mix-Long approach effectively combines the strengths of long and short CoT training paradigms, allowing the model to benefit from both the comprehensive reasoning steps provided by long CoT examples and the efficiency and conciseness of short CoT. The result is a balanced approach that produces accurate and efficient answers, as demonstrated by the example shown in Figure 7.
read the caption
Figure 7: Case Study of Mix-Long. Models fine-tuned on long CoT tended to overthink, while those trained on short CoT produced incorrect answers. In contrast, Mix-Long, incorporating branching elements (e.g., “Alternatively”), achieved a balanced reasoning process and arrived at the correct answer.

🔼 This figure illustrates the methodology for identifying the tokens that have undergone the most significant rank shifts during the fine-tuning process of a language model. The process begins by decoding tokens generated by the fine-tuned model, prior to fine-tuning. Then, the rank shift for each of these tokens is computed within the student model. Tokens with the largest rank shifts are highlighted as the most shifted tokens. The analysis reveals that these tokens are predominantly associated with expressive and stylistic elements in the generated text, specifically words like ‘But’ and ‘Let’.
read the caption
Figure 8: The process of calculating most shifted tokens. We decode each token generated by the fine-tuned LLM in the student model before fine-tuning. Then we calculate the rank shift in the student model for each token generated by the fine-tuned model. We annotate the tokens that exhibit the largest rank shifts as the most shifted tokens. We found that these tokens are predominantly associated with expressive and stylistic elements, such as “But” and “Let”.
More on tables
| Student Model | Better? | |||
| Qwen2.5-0.5B | 16.9 | 20.4 | -3.5 | Weak |
| Qwen2.5-1.5B | 32.2 | 33.0 | -0.8 | Weak |
| Qwen2.5-3B | 39.7 | 39.4 | 0.3 | Strong |
| Qwen2.5-7B | 48.9 | 42.3 | 6.6 | Strong |
| Qwen2.5-14B | 52.9 | 49.9 | 3.0 | Strong |
| Qwen2.5-32B | 59.5 | 53.0 | 6.5 | Strong |
| Llama-3.2-1B | 16.5 | 18.5 | -1.9 | Weak |
| Llama-3.2-3B | 32.8 | 31.2 | 1.6 | Strong |
| Llama-3.2-8B | 25.6 | 25.1 | 0.5 | Strong |
| Llama-3.2-70B | 57.6 | 53.3 | 4.3 | Strong |
🔼 This table compares the performance of small language models (student models) fine-tuned using chain-of-thought (CoT) reasoning examples generated by two different teacher models: a larger, more powerful model and a smaller, less powerful model. The goal is to assess whether smaller student models benefit more from learning from a similar-sized teacher or a much larger teacher. The table shows the average performance scores across several benchmarks for various sized student models. It highlights the ‘Small Model Learnability Gap’, indicating that smaller models may struggle to learn from more complex reasoning traces generated by larger models, performing better when trained with simpler, shorter CoT examples.
read the caption
Table 2: Comparison of average performance between fine-tuning with large teacher CoT (PLongsubscript𝑃𝐿𝑜𝑛𝑔P_{Long}italic_P start_POSTSUBSCRIPT italic_L italic_o italic_n italic_g end_POSTSUBSCRIPT) and small teacher CoT (PSmallsubscript𝑃𝑆𝑚𝑎𝑙𝑙P_{Small}italic_P start_POSTSUBSCRIPT italic_S italic_m italic_a italic_l italic_l end_POSTSUBSCRIPT). We find that small student models may struggle to learn from large teacher CoT data.
| Takeaway 2: Large Teacher CoT Gap |
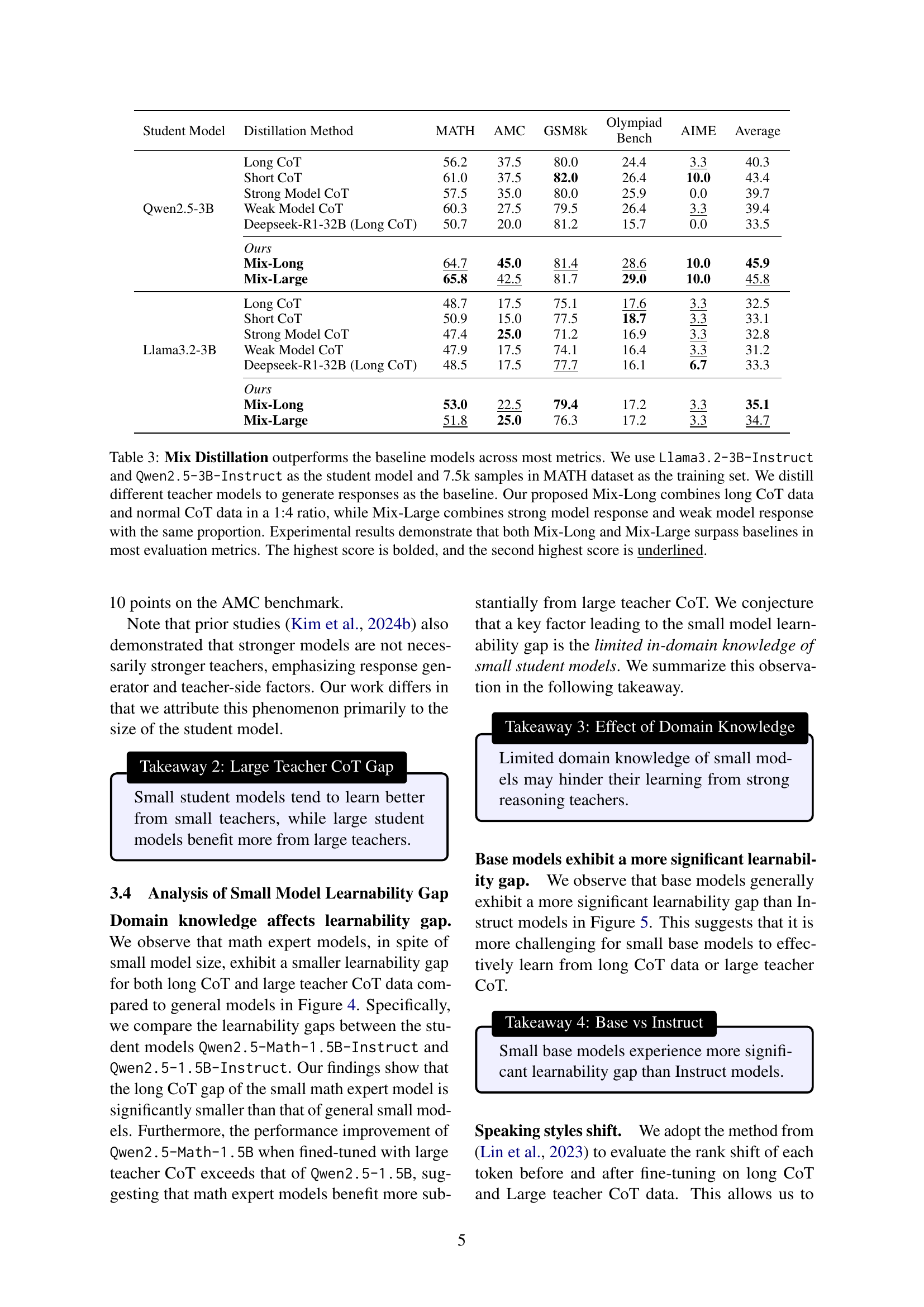
🔼 This table presents a comparison of different model training methods on math reasoning tasks using two small language models (LLMs), Llama3.2-3B-Instruct and Qwen2.5-3B-Instruct, trained on 7.5k samples from the MATH dataset. The baseline methods involve distillation from various teacher models generating different types of chain-of-thought (CoT) responses. The table shows the performance of these baselines on several math benchmarks. The new proposed method, Mix Distillation, involves two variations: Mix-Long (combining long and short CoT data in a 1:4 ratio) and Mix-Large (combining strong and weak model responses equally). The results demonstrate that Mix Distillation consistently outperforms all baseline methods, achieving the highest scores across most evaluation metrics. The table highlights the performance improvements on each benchmark by bolding the best score and underlining the second-best score for each method.
read the caption
Table 3: Mix Distillation outperforms the baseline models across most metrics. We use Llama3.2-3B-Instruct and Qwen2.5-3B-Instruct as the student model and 7.5k samples in MATH dataset as the training set. We distill different teacher models to generate responses as the baseline. Our proposed Mix-Long combines long CoT data and normal CoT data in a 1:4 ratio, while Mix-Large combines strong model response and weak model response with the same proportion. Experimental results demonstrate that both Mix-Long and Mix-Large surpass baselines in most evaluation metrics. The highest score is bolded, and the second highest score is underlined.
| Student Model | Distillation Method | MATH | AMC | GSM8k | Olympiad Bench | AIME | Average |
| Qwen2.5-3B | Long CoT | 56.2 | 37.5 | 80.0 | 24.4 | 3.3 | 40.3 |
| Short CoT | 61.0 | 37.5 | 82.0 | 26.4 | 10.0 | 43.4 | |
| Strong Model CoT | 57.5 | 35.0 | 80.0 | 25.9 | 0.0 | 39.7 | |
| Weak Model CoT | 60.3 | 27.5 | 79.5 | 26.4 | 3.3 | 39.4 | |
| Deepseek-R1-32B (Long CoT) | 50.7 | 20.0 | 81.2 | 15.7 | 0.0 | 33.5 | |
| Ours | |||||||
| Mix-Long | 64.7 | 45.0 | 81.4 | 28.6 | 10.0 | 45.9 | |
| Mix-Large | 65.8 | 42.5 | 81.7 | 29.0 | 10.0 | 45.8 | |
| Llama3.2-3B | Long CoT | 48.7 | 17.5 | 75.1 | 17.6 | 3.3 | 32.5 |
| Short CoT | 50.9 | 15.0 | 77.5 | 18.7 | 3.3 | 33.1 | |
| Strong Model CoT | 47.4 | 25.0 | 71.2 | 16.9 | 3.3 | 32.8 | |
| Weak Model CoT | 47.9 | 17.5 | 74.1 | 16.4 | 3.3 | 31.2 | |
| Deepseek-R1-32B (Long CoT) | 48.5 | 17.5 | 77.7 | 16.1 | 6.7 | 33.3 | |
| Ours | |||||||
| Mix-Long | 53.0 | 22.5 | 79.4 | 17.2 | 3.3 | 35.1 | |
| Mix-Large | 51.8 | 25.0 | 76.3 | 17.2 | 3.3 | 34.7 |
🔼 This table lists the large language models (LLMs) used in the experiments as teacher models and the smaller models used as student models. For each category (long vs short chain-of-thought, large vs small teacher), it specifies the particular LLMs used to generate the different types of training data. It also provides a complete list of student models used in the fine-tuning experiments, categorizing them by their model family (Qwen and Llama). This detailed breakdown is essential for understanding the experimental setup and comparing the performance across various model sizes and training approaches.
read the caption
Table 4: Overview of Teacher and Student Models
| Takeaway 3: Effect of Domain Knowledge |
🔼 This table details the hyperparameters used for fine-tuning language models with the full parameter approach. It includes the learning rate, number of epochs, number of devices used for training, batch size per device, optimizer, learning rate scheduler, and the maximum sequence length.
read the caption
Table 5: This table shows the hyper-parameters for full parameter fine-tuning.
| Takeaway 5: Speaking Styles Shift |
🔼 This table details the hyperparameters used for fine-tuning language models using the LoRA (Low-Rank Adaptation) technique. It lists specific values for parameters such as learning rate, the number of training epochs, and the maximum sequence length processed during training. These settings are crucial for optimizing the LoRA fine-tuning process and achieving the best performance.
read the caption
Table 6: This table shows the hyper-parameters for LoRA fine-tuning.
| Takeaway 6: Mix Distillation Bridges Gap |
🔼 This table presents the performance of various sized language models (LLMs) from the Llama and Qwen families, focusing on their ability to solve mathematical reasoning problems. The models were fine-tuned using two different types of Chain-of-Thought (CoT) reasoning data: long CoT and short CoT. Long CoT data consists of detailed, multi-step reasoning processes, while short CoT uses concise, shorter reasoning steps. The models’ performance is evaluated across five benchmark datasets: MATH, GSM8K, AIME, AMC, and OlympiadBench. The results show a trend where smaller models perform better with short CoT data, while larger models benefit more from long CoT data, highlighting a relationship between model size and the optimal complexity of reasoning data for effective fine-tuning.
read the caption
Table 7: This table summarizes the performance of models in Llama and Qwen families fine-tuned with long CoT and short CoT data. They are evaluated on MATH, GSM8K, AIME, AMC, and OlympiadBench. QwQ-32B-Preview is chosen to generate long CoT and awhile Qwen-2.5-32B-Instruct is chosen to generate short CoT. We observe that small student models tend to benefit more from short CoT, while large student models gain greater advantages from long CoT.
| Category | Models |
| Teacher Models | |
| Long CoT vs | QwQ-32B-Preview vs |
| ShortCoT | Qwen2.5-32B-Instruct |
| Large Teacher vs | |
| Small Teacher | |
| Qwen Family | Qwen2.5-72B-Instruct vs |
| Qwen2.5-3B-Instruct | |
| Llama Family | Llama3.1-70B-Instruct vs |
| Llama3.1-8B-Instruct | |
| Gemma Family | Gemma2-27B-it vs |
| Gemma2-9B-it | |
| Student Models | |
| Qwen Family | Qwen2.5-0.5B-Instruct, |
| Qwen2.5-1.5B-Instruct, | |
| Qwen2.5-3B-Instruct, | |
| Qwen2.5-7B-Instruct, | |
| Qwen2.5-14B-Instruct, | |
| Qwen2.5-32B-Instruct | |
| Llama Family | Llama3.2-1B-Instruct, |
| Llama3.2-3B-Instruct, | |
| Llama3.1-8B-Instruct, | |
| Llama3.3-70B-Instruct | |
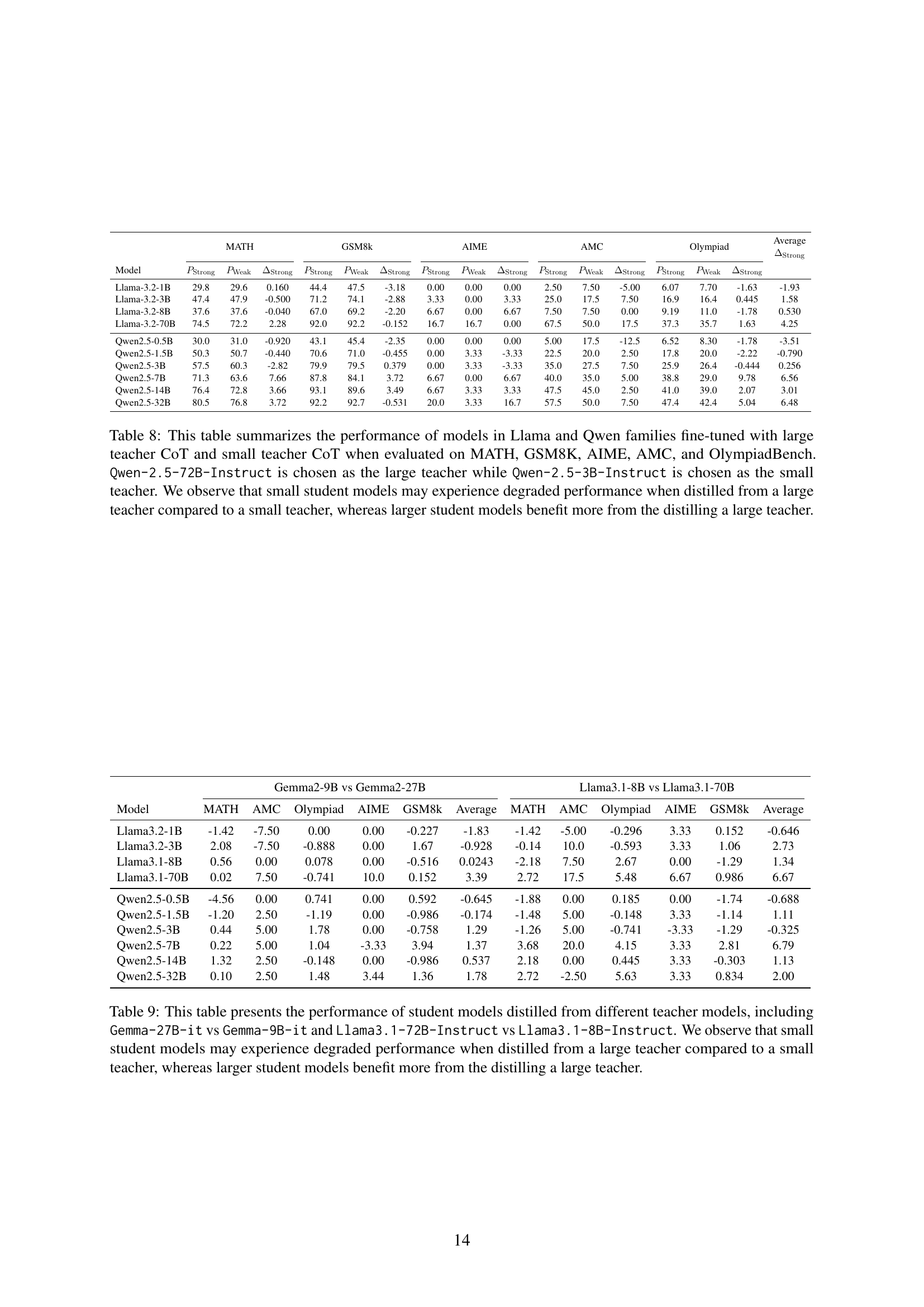
🔼 This table presents the performance of various sized language models (student models) from the Llama and Qwen families, after fine-tuning using chain-of-thought (CoT) data from different teacher models. Specifically, it compares the performance when using CoT from a much larger teacher model (Qwen-2.5-72B-Instruct) versus a smaller, more comparable teacher model (Qwen-2.5-3B-Instruct). The evaluation is performed across five benchmark datasets: MATH, GSM8K, AIME, AMC, and OlympiadBench. The results show a trend: smaller student models often perform worse after training with CoT from the significantly larger teacher model than when trained with CoT from the smaller teacher model. Larger student models, however, tend to benefit from training with CoT data from the larger teacher model.
read the caption
Table 8: This table summarizes the performance of models in Llama and Qwen families fine-tuned with large teacher CoT and small teacher CoT when evaluated on MATH, GSM8K, AIME, AMC, and OlympiadBench. Qwen-2.5-72B-Instruct is chosen as the large teacher while Qwen-2.5-3B-Instruct is chosen as the small teacher. We observe that small student models may experience degraded performance when distilled from a large teacher compared to a small teacher, whereas larger student models benefit more from the distilling a large teacher.
| Hyper-parameter | Value |
| Learning Rate | |
| Number of Epochs | |
| Number of Devices | |
| Per-device Batch Size | |
| Optimizer | Adamw |
| Learning Rate Scheduler | cosine |
| Max Sequence Length |
🔼 This table presents the results of an experiment comparing the performance of smaller language models (student models) trained using knowledge distillation from different teacher models. The experiment included pairs of teacher models where one was significantly larger than the other (e.g., Gemma-27B-it vs. Gemma-9B-it and Llama3.1-70B-Instruct vs. Llama3.1-8B-Instruct). The performance of the student models is assessed across various metrics on standard benchmarks. The key finding is that smaller student models perform worse when distilled from much larger teachers, while larger student models benefit from distilling knowledge from larger teachers.
read the caption
Table 9: This table presents the performance of student models distilled from different teacher models, including Gemma-27B-it vs Gemma-9B-it and Llama3.1-72B-Instruct vs Llama3.1-8B-Instruct. We observe that small student models may experience degraded performance when distilled from a large teacher compared to a small teacher, whereas larger student models benefit more from the distilling a large teacher.
Full paper#