TL;DR#
Current text-to-song models often use complex multistage processes, which make training and use harder. Also, there is a lack of opensource dataset to do research in this field. The paper aims to solve these issues by improving pipeline simplicity and data availablity.
The paper introduces a single-stage, autoregressive transformer model that converts text and optional vocal references into songs. SongGen offers control over musical elements and voice cloning. The model supports mixed and dual-track output modes. Through token pattern explorations, the model improves output quality. The project includes a dataset, preprocessing pipeline, model weights, and code.
Key Takeaways#
Why does it matter?#
This work is important because it introduces a novel, open-source, single-stage approach to text-to-song generation, overcoming limitations of multi-stage methods. By releasing model weights, code, data, and a preprocessing pipeline, it establishes a strong baseline for future research, fostering innovation in AI music creation.
Visual Insights#
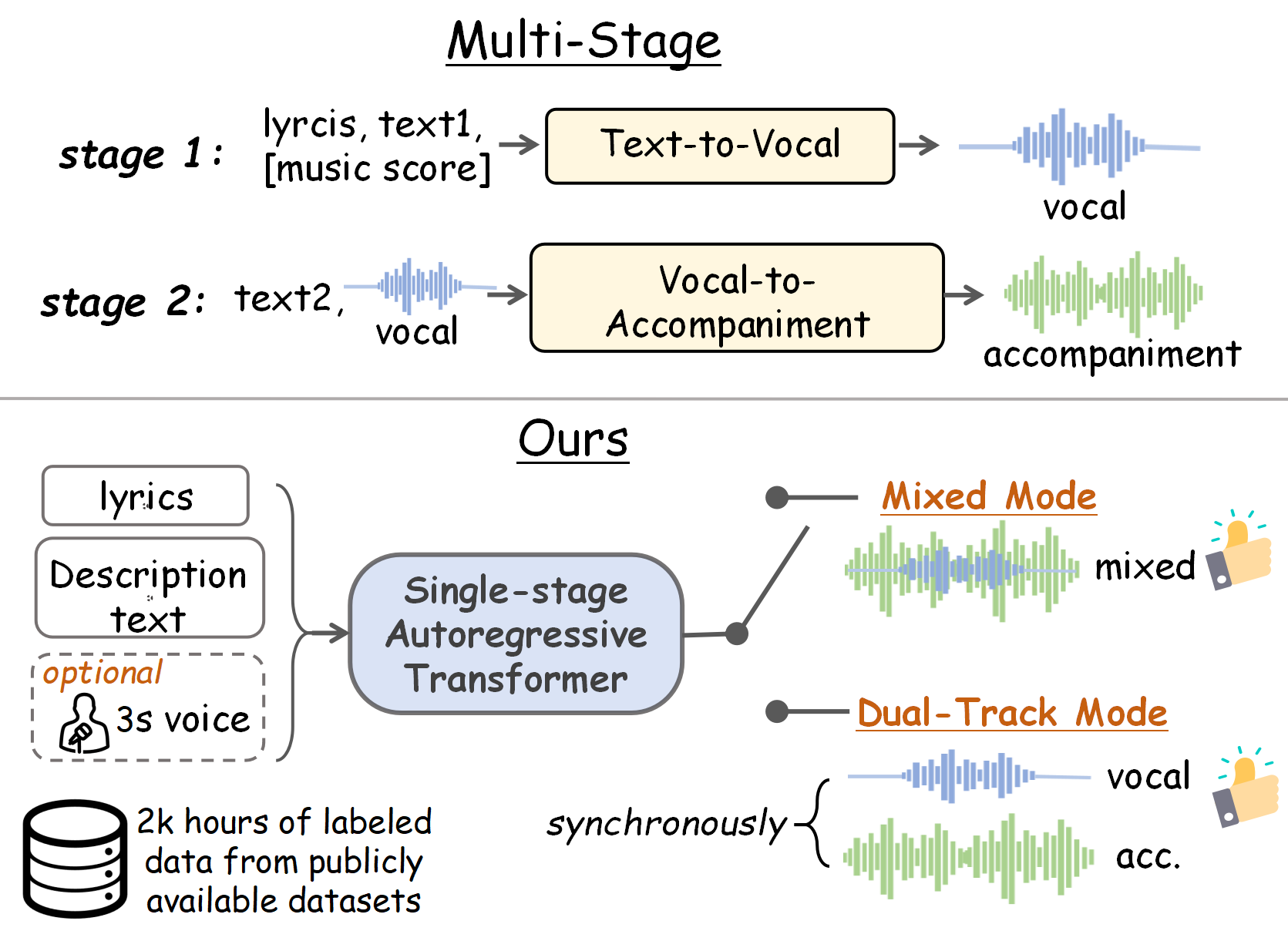
🔼 Figure 1 illustrates the difference between traditional multi-stage text-to-song generation methods and the proposed SongGen approach. Traditional methods involve separate stages for generating music scores, vocals, and accompaniment, leading to complex and inflexible pipelines. In contrast, SongGen uses a single-stage auto-regressive transformer to directly generate both mixed-mode (vocals and accompaniment combined) and dual-track mode (vocals and accompaniment separated) song outputs, simplifying the generation process and enhancing controllability.
read the caption
Figure 1: Traditional methods often rely on multi-stage processes, making pipelines inflexible and complex. SongGen simplifies this with a single-stage auto-regressive transformer that supports both mixed mode and dual-track mode song generation.
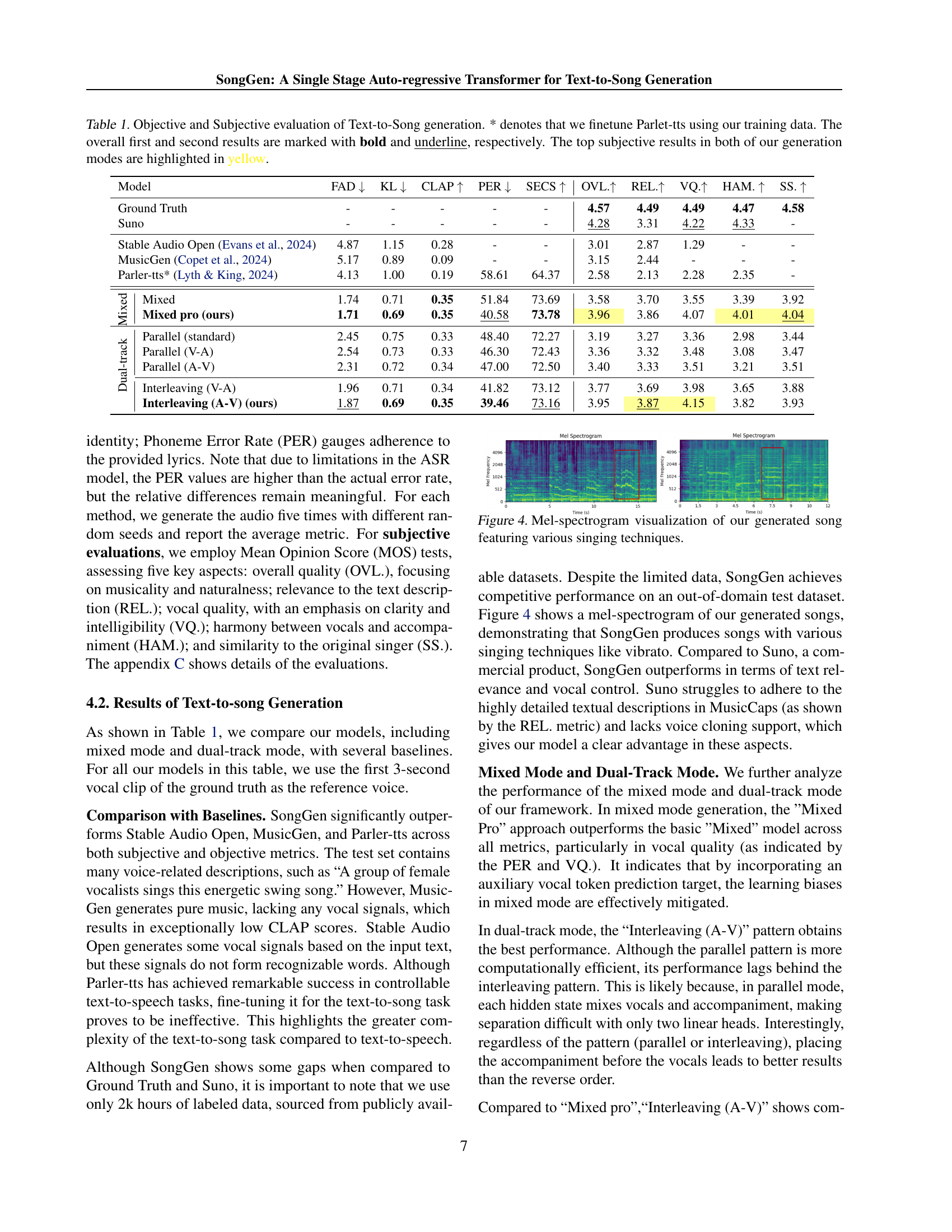
| Model | FAD | KL | CLAP | PER | SECS | OVL. | REL. | VQ. | HAM. | SS. | |
| Ground Truth | - | - | - | - | - | 4.57 | 4.49 | 4.49 | 4.47 | 4.58 | |
| Suno | - | - | - | - | - | 4.28 | 3.31 | 4.22 | 4.33 | - | |
| Stable Audio Open (Evans et al., 2024) | 4.87 | 1.15 | 0.28 | - | - | 3.01 | 2.87 | 1.29 | - | - | |
| MusicGen (Copet et al., 2024) | 5.17 | 0.89 | 0.09 | - | - | 3.15 | 2.44 | - | - | - | |
| Parler-tts* (Lyth & King, 2024) | 4.13 | 1.00 | 0.19 | 58.61 | 64.37 | 2.58 | 2.13 | 2.28 | 2.35 | - | |
| Mixed | Mixed | 1.74 | 0.71 | 0.35 | 51.84 | 73.69 | 3.58 | 3.70 | 3.55 | 3.39 | 3.92 |
| Mixed pro (ours) | 1.71 | 0.69 | 0.35 | 40.58 | 73.78 | 3.96 | 3.86 | 4.07 | 4.01 | 4.04 | |
| Dual-track | Parallel (standard) | 2.45 | 0.75 | 0.33 | 48.40 | 72.27 | 3.19 | 3.27 | 3.36 | 2.98 | 3.44 |
| Parallel (V-A) | 2.54 | 0.73 | 0.33 | 46.30 | 72.43 | 3.36 | 3.32 | 3.48 | 3.08 | 3.47 | |
| Parallel (A-V) | 2.31 | 0.72 | 0.34 | 47.00 | 72.50 | 3.40 | 3.33 | 3.51 | 3.21 | 3.51 | |
| Interleaving (V-A) | 1.96 | 0.71 | 0.34 | 41.82 | 73.12 | 3.77 | 3.69 | 3.98 | 3.65 | 3.88 | |
| Interleaving (A-V) (ours) | 1.87 | 0.69 | 0.35 | 39.46 | 73.16 | 3.95 | 3.87 | 4.15 | 3.82 | 3.93 | |
🔼 Table 1 presents a comprehensive evaluation of SongGen’s text-to-song generation capabilities, comparing its performance against various baselines using both objective and subjective metrics. Objective metrics include FAD (Frechet Audio Distance), KL (Kullback-Leibler Divergence), CLAP (CLAP Score), PER (Phoneme Error Rate), and VQ (Vocal Quality), assessing aspects like audio fidelity, lyric accuracy, and vocal clarity. Subjective metrics involve MOS (Mean Opinion Score) ratings across five key aspects: overall quality, relevance to the text description, vocal quality, vocal-accompaniment harmony, and speaker similarity. The results show SongGen outperforming the baselines, demonstrating its ability to generate high-quality, text-relevant songs with clear vocals and effective vocal-accompaniment harmony, despite being trained on a relatively smaller dataset compared to some commercial products. The table highlights the best-performing models and variants within SongGen’s mixed and dual-track modes, indicating the effectiveness of different design choices. The asterisk (*) indicates that Parler-tts was fine-tuned using the author’s training data.
read the caption
Table 1: Objective and Subjective evaluation of Text-to-Song generation. * denotes that we finetune Parlet-tts using our training data. The overall first and second results are marked with bold and underline, respectively. The top subjective results in both of our generation modes are highlighted in yellow.
In-depth insights#
Single-stage ASR#
While the paper doesn’t explicitly have a “Single-stage ASR” heading, we can interpret this in the context of the presented SongGen model as contrasting with multi-stage approaches. In the landscape of text-to-song generation, a single-stage ASR (Auto-regressive) model offers significant advantages in terms of simplifying the training and inference pipeline. Traditional systems often decompose the task into multiple stages (e.g., text-to-vocal followed by vocal-to-accompaniment), leading to increased complexity and potential error propagation. A single-stage approach, like SongGen, aims to directly map text input to song output, potentially enabling more unified control over musical attributes and a streamlined end-to-end learning process. The key is effectively capturing the complex relationships between lyrics, instrumentation, and vocal performance within a single model architecture. The main challenge of the single-stage is how to balance generating high-quality vocals and clear lyrics since the model may prioritize easily predictable accompaniment. The authors mentioned introducing auxiliary vocal token to solve the problem.
Token Patterns#
Analyzing token patterns is crucial in sequence generation tasks. Different patterns can significantly impact the model’s ability to capture complex relationships within the data. Mixed token approaches might simplify the generation process but could lead to challenges in disentangling different data modalities, such as vocals and accompaniment in music. Conversely, dual-track or interleaved patterns, while potentially more complex to implement, could offer better control and separation, enabling more nuanced and expressive results. Careful consideration of the order and structure within these patterns is essential. For example, placing certain tokens before others might provide necessary context or influence the generation process in specific ways. Experimentation is key to determining optimal arrangements. Token patterns directly shape the model’s ability to extract meaningful data representations, ultimately impacting the coherence, quality, and style of the generated outputs.
Data Pipeline#
A robust data pipeline appears crucial for the success of this endeavor, given the inherent challenges in text-to-song generation. Data scarcity is a major hurdle. Therefore, I expect the authors will need to invest significant effort in creating an automated system for data collection, cleaning, and pre-processing. The pipeline probably incorporates steps like audio segmentation, to isolate vocals from instrumentals, and lyric alignment, to synchronize lyrics with the audio. Given the unreliability of automated speech recognition (ASR) systems on sung vocals, I anticipate a multi-ASR system with discrepancy analysis to produce more accurate transcriptions. Finally, I presume the pipeline will include robust data augmentation techniques to expand the dataset size and improve the model’s generalization capabilities, especially considering the inherent limitations of current datasets.
Vocal clarity#
Vocal clarity is crucial in text-to-song generation, yet challenging due to overlaps with accompaniment, leading models to prioritize the latter. This paper introduces an auxiliary vocal token prediction target to enhance vocal learning, significantly improving vocal clarity in mixed-token outputs. Techniques to maintain alignment of vocals and accompaniment are also examined. Results from these methods highlight the importance of explicit focus on vocal features to produce natural-sounding, intelligible vocals within a cohesive song structure. The proposed approach helps the model overcome biases towards the more stable and predictable accompaniment, ultimately achieving a more balanced and perceptually pleasing final output. The results showcase the effectiveness of targeted strategies in addressing specific challenges in music generation.
Cross-attention#
Cross-attention mechanisms are pivotal for integrating diverse modalities in a unified model like SongGen. They enable the model to selectively focus on relevant information from different input sources, such as lyrics, descriptive text, and reference voice clips, when generating music. By learning to attend to specific parts of the lyrics or text descriptions during vocal and accompaniment synthesis, SongGen can create more coherent and contextually relevant songs. This selective attention allows for fine-grained control over musical attributes, ensuring that the generated audio aligns with the intended style, mood, and instrumentation. Effectively implemented cross-attention can significantly improve the quality and controllability of text-to-song generation by dynamically adapting the generation process based on the input conditions. The success hinges on appropriate projection layers to transform the embeddings and effective techniques to focus on relevant inter-modal relationships.
More visual insights#
More on figures
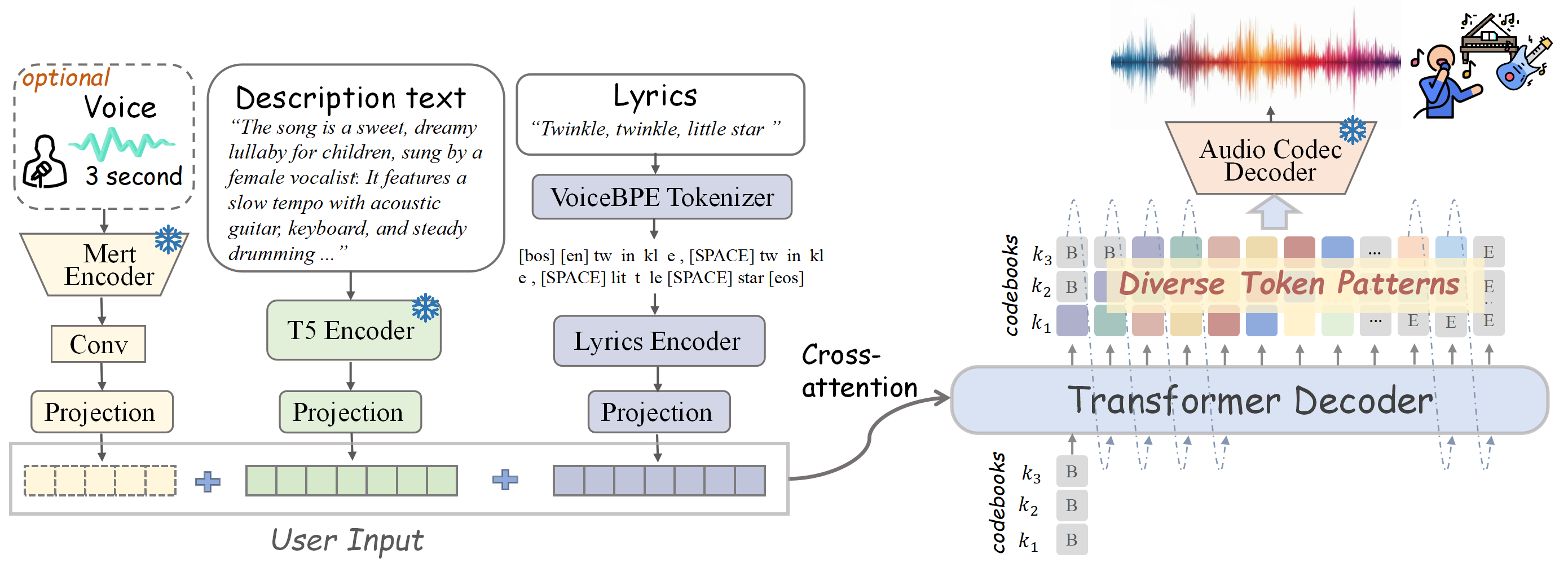
🔼 SongGen uses an auto-regressive transformer decoder to generate audio tokens. These tokens incorporate user input (lyrics, description text, and optional reference audio) via cross-attention. The decoder outputs a sequence of these tokens, which are then processed by a neural audio codec to synthesize the final song. Different token patterns are used to control the generation process for flexibility.
read the caption
Figure 2: Overview of SongGen: An auto-regressive transformer decoder generates audio tokens with diverse patterns, incorporating user-defined controls via cross-attention. The final song is synthesized from these tokens through the audio codec decoder.

🔼 Figure 3 illustrates various token patterns used in SongGen for different generation modes. It focuses on how the model handles vocals and accompaniment. The ‘codebook-delay’ pattern from MusicGen is used in all modes. Panel (a) shows the ‘Mixed Pro’ approach, where mixed audio tokens are directly decoded with an auxiliary vocal token prediction target added to improve vocal quality. Panels (b) and (c) display dual-track mode strategies. Panel (b), the ‘Parallel’ method, concatenates vocal and accompaniment tokens along the codebook dimension with variations in the ordering of the tracks. Panel (c), ‘Interleaving’, interleaves vocal and accompaniment tokens in time, also showing variations in track ordering. This figure visually explains the different strategies SongGen uses to generate either a mixed audio track or separate vocal and accompaniment tracks.
read the caption
Figure 3: Illustration of token patterns for different generation modes. The codebook-delay pattern (from MusicGen) is applied to every audio token. (a) Mixed Pro: Directly decoding mixed tokens, with an auxiliary vocal token prediction target to enhance vocal learning. Dual-track mode: (b) Parallel: Vocal and accompaniment tokens are concatenated along the codebook dimension, with three track order variants. (c) Interleaving: Tokens from both tracks are interleaved along the temporal dimension, with two track order variants.
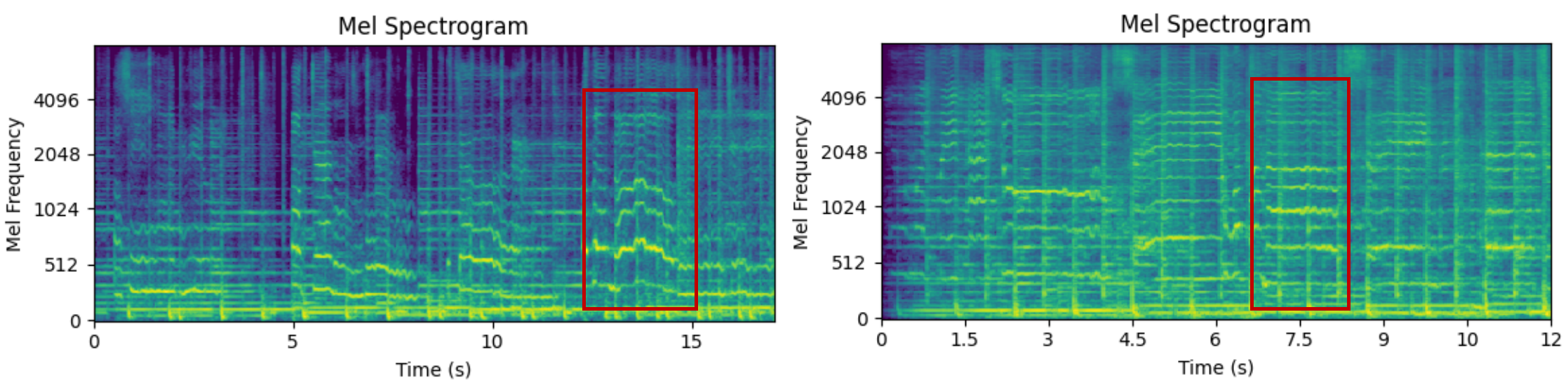
🔼 Figure 4 presents mel-spectrograms of a song generated by the SongGen model. The spectrograms visually demonstrate the model’s ability to generate songs incorporating a variety of expressive vocal techniques, showcasing the model’s capabilities beyond simple audio generation.
read the caption
Figure 4: Mel-spectrogram visualization of our generated song featuring various singing techniques.
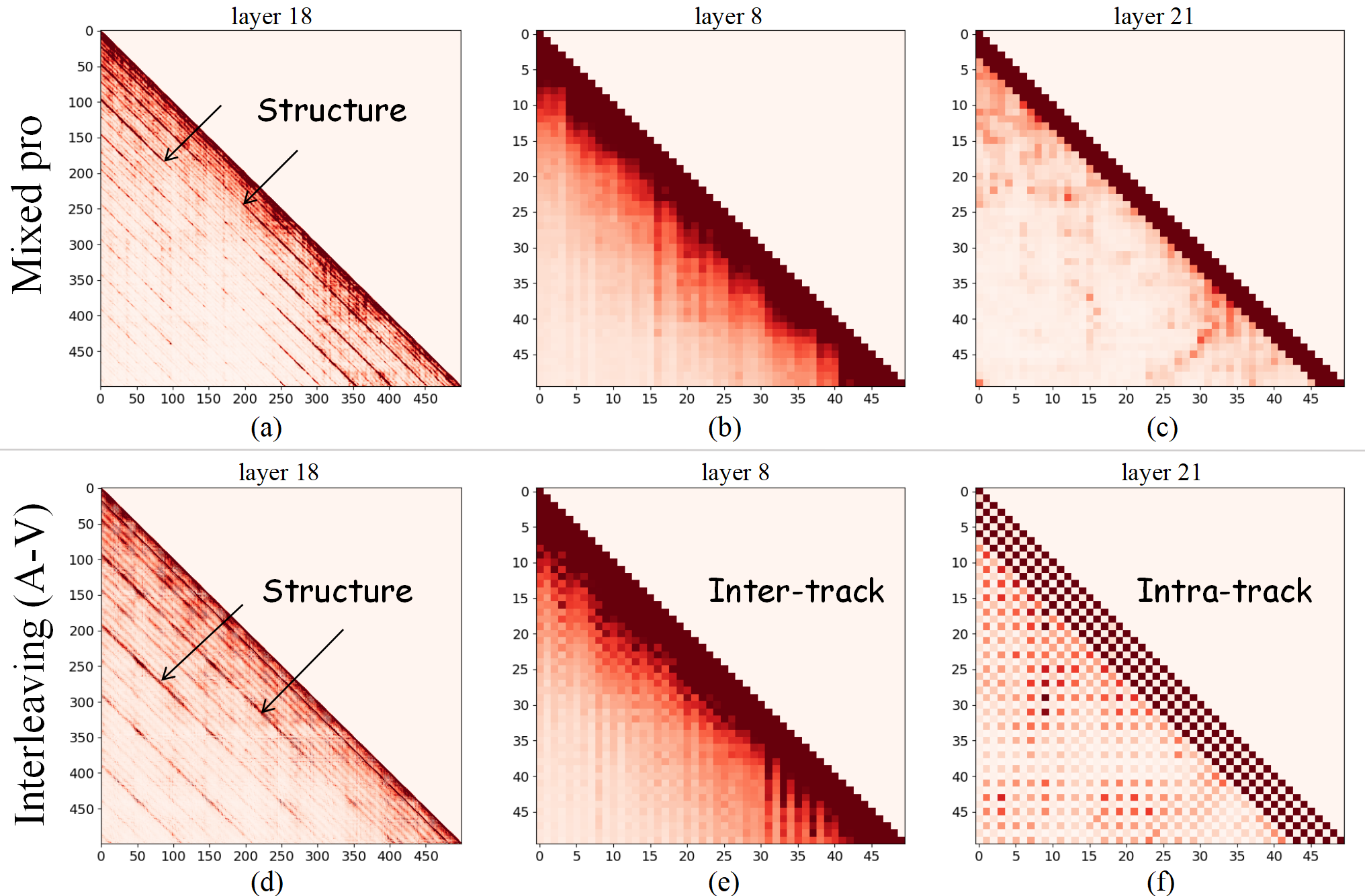
🔼 Figure 5 visualizes the attention weights within the transformer decoder of the SongGen model for both mixed and dual-track modes. Subfigures (a) and (b) display the self-attention patterns in layers 18 and 8 respectively for the ‘mixed pro’ generation mode, showcasing a diagonal pattern indicating the model’s ability to capture repetitive structures common in music. (c) shows layer 21 for the same mode, presenting a checkerboard pattern suggesting different focus on intra- and inter-track relations. (d), (e), and (f) show the same self-attention visualizations but for the ‘Interleaving (A-V)’ dual-track mode, revealing a similar diagonal pattern in higher layers and a distinct checkerboard pattern in lower layers. This difference highlights how different layers in the model focus on capturing various relationships between vocal and accompaniment tracks in different modes.
read the caption
Figure 5: Visualization of decoder attention.
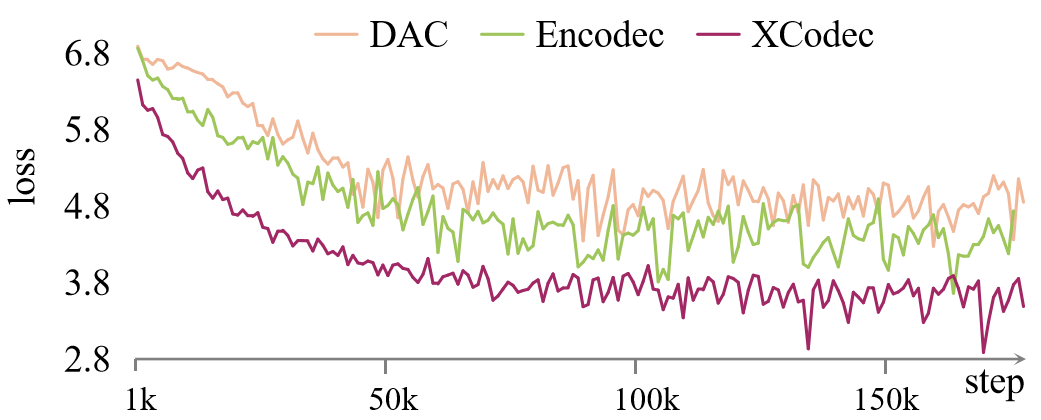
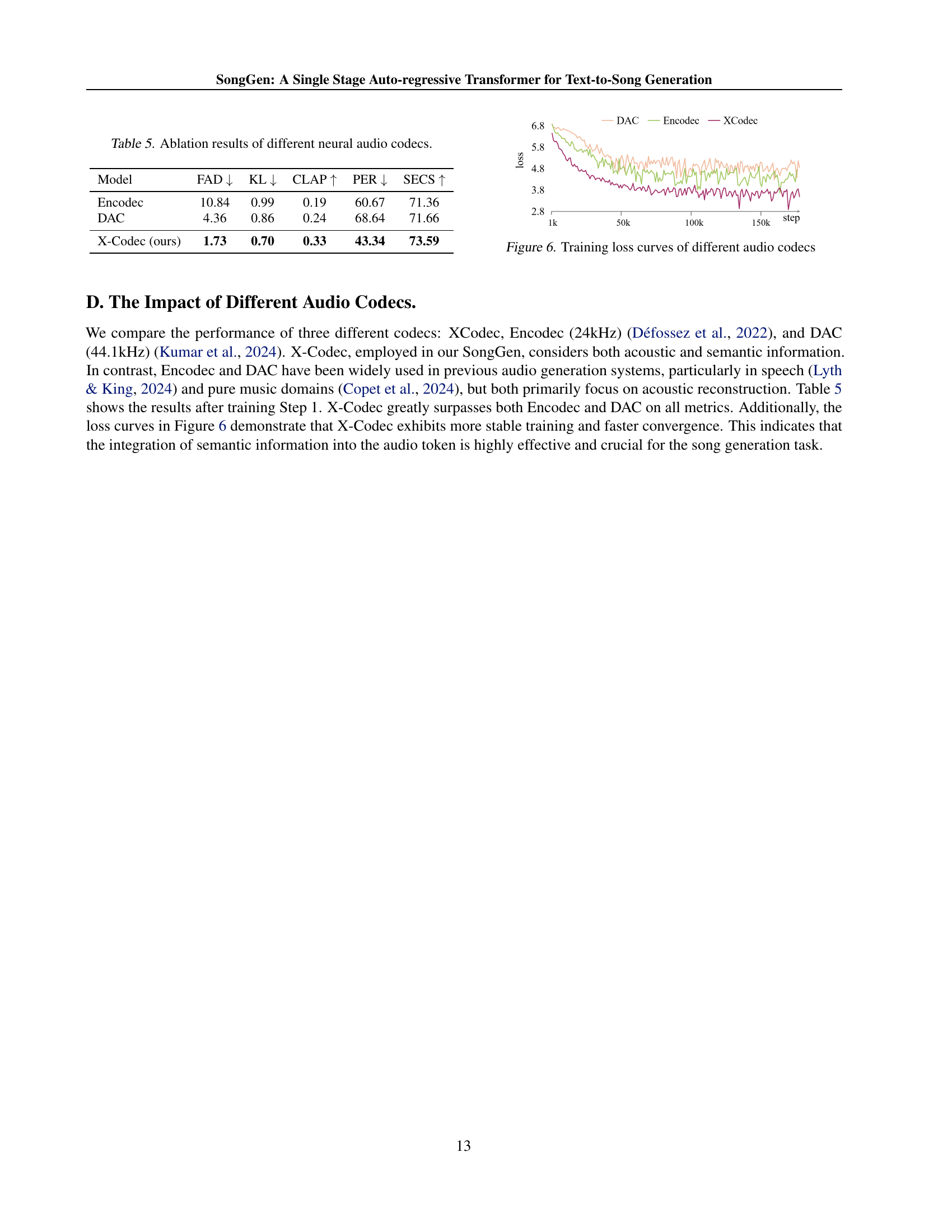
🔼 This figure shows the training loss curves for three different audio codecs: X-Codec, Encodec, and DAC. The X-axis represents the training step, and the Y-axis represents the loss. The plot visually compares the convergence speed and final loss values achieved by each codec during the training process of the SongGen model. This helps to illustrate the impact of the choice of audio codec on model performance.
read the caption
Figure 6: Training loss curves of different audio codecs
More on tables
| Model | FAD | OVL. | REL. | VQ. | HAM. |
| mixed pro | 1.96 | 3.72 | 3.48 | 3.88 | 3.87 |
| inter.(A-V) | 2.21 | 3.70 | 3.47 | 3.91 | 3.83 |
🔼 This table presents the performance of SongGen’s text-to-song generation model when the reference voice input is removed. It compares two modes: ‘mixed pro’ and ‘interleaving (A-V)’, evaluating their performance across multiple metrics including FAD (Frechet Audio Distance), OVL (Overall Quality), REL (Relevance), VQ (Vocal Quality), HAM (Harmony), and SS (Speaker Similarity). The results showcase SongGen’s ability to generate songs even without a voice reference, although with some performance reduction.
read the caption
Table 2: Text-to-Song results without voice input.
| Model | FAD | KL | CLAP | PER | SECS |
| w/o HQFT | 2.01 | 0.72 | 0.32 | 43.68 | 72.83 |
| w/o CL | 2.35 | 0.73 | 0.33 | 55.71 | 72.81 |
| ours | 1.71 | 0.69 | 0.35 | 40.58 | 73.78 |
🔼 This table presents ablation study results focusing on the impact of different training schemes on the SongGen model’s performance. It compares the model’s performance under three training schemes: (1) without high-quality fine-tuning (HQFT), (2) without curriculum learning (CL), and (3) with both HQFT and CL (the proposed method). The evaluation metrics include Frechet Audio Distance (FAD), Kullback-Leibler Divergence (KL), CLAP score, Phoneme Error Rate (PER), and Speaker Embedding Cosine Similarity (SECS) to comprehensively assess the quality of generated songs.
read the caption
Table 3: Ablation results on training scheme. HQFT is short for High-Quality Finetuning and CL stands for curriculum learning.
| Tokenizer | w/ Lyrics Encoder | prepend / cross | FAD | PER | SECS |
| VoiceBPE | ✗ | prepend | 3.41 | 62.38 | 69.09 |
| VoiceBPE | ✓ | prepend | 3.56 | 56.21 | 70.70 |
| VoiceBPE | ✗ | cross | 1.95 | 61.81 | 72.59 |
| T5 | ✓ | cross | 1.88 | 55.27 | 73.67 |
| VoiceBPE | ✓ | cross | 1.73 | 43.34 | 73.59 |
🔼 This table presents the ablation study results of different lyric integration methods used in the SongGen model. It compares the performance using various tokenizers (VoiceBPE, T5), lyric encoder inclusion (with or without), and integration approaches (prepending lyrics or cross-attention). The results are evaluated using FAD, PER, and SECS metrics to determine the impact of each method on the generated song quality.
read the caption
Table 4: Ablation results on different lyric integration methods.
| Model | FAD | KL | CLAP | PER | SECS |
| Encodec | 10.84 | 0.99 | 0.19 | 60.67 | 71.36 |
| DAC | 4.36 | 0.86 | 0.24 | 68.64 | 71.66 |
| X-Codec (ours) | 1.73 | 0.70 | 0.33 | 43.34 | 73.59 |
🔼 This table presents the ablation study results comparing three different neural audio codecs: X-Codec, Encodec, and DAC. The comparison focuses on the impact of the codec choice on several key metrics including Frechet Audio Distance (FAD), Kullback-Leibler Divergence (KL), CLAP Score, Phoneme Error Rate (PER), and Speaker Embedding Cosine Similarity (SECS). The results demonstrate X-Codec’s superior performance across all metrics, highlighting the importance of incorporating both acoustic and semantic information into the audio token for the song generation task.
read the caption
Table 5: Ablation results of different neural audio codecs.
Full paper#