TL;DR#
Training large language models (LLMs) is computationally expensive, especially Low-Rank Adaption (LoRA) due to the memory footprint dominated by the original model parameters. This paper addresses the challenge of high memory requirements in LLM fine-tuning. Many neurons in over-parameterized LLMs have low training utility but are essential for inference.
To mitigate these issues, the paper introduces LORAM, a memory-efficient LoRA training scheme. LORAM trains on a pruned model and obtains pruned low-rank matrices which are then utilized with the original model for inference. It presents minimal-cost continual pre-training to aligns knowledge discrepancy between the pruned and original models. Experiments shows LORAM reduces parameter storage cost by 15.81× while achieving performance gains over original and LoRA-trained models.
Key Takeaways#
Why does it matter?#
This paper introduces LORAM, a novel approach to training large language models using limited resources. It demonstrates a significant reduction in memory footprint while maintaining high performance. Thus, researchers can push the boundaries of LLM customization even with hardware limitations and may further explores knowledge alignment techniques.
Visual Insights#

🔼 The figure illustrates the core concept of LORAM (Low-Rank Adaptation Memory). Unlike traditional LoRA which uses the same model for training and inference, LORAM employs a pruned (smaller) model for training and the original (larger) model for inference. During training, only a subset of the model’s parameters (yellow blocks) are updated using low-rank matrices, significantly reducing memory usage. These updated parameters, along with the knowledge from continual pre-training (offline), are then used to recover the full low-rank matrices which are applied to the original model during inference. This allows LORAM to achieve memory efficiency during training while maintaining performance during inference.
read the caption
Figure 1: Idea of LoRAM
| Method | OpenHermes | OpenOrca | Parameter Redu. Ratio | ||
| MathQA | GSM8K | MathQA | GSM8K | ||
| 13B w/o FT | 32.60 | 24.26 | 32.93 | 23.35 | 1.00 |
| 7B LoRA | 29.61 | 22.82 | 30.95 | 13.87 | 1.93 |
| 13B LoRAM-Rand | 33.77 | 27.22 | 32.83 | 25.93 | 2.17 |
| 13B LoRAM-Stru | 33.80 | 24.64 | 33.07 | 24.49 | 2.17 |
| 13B LoRAM-Semi | 31.76 | 36.92 | 33.07 | 27.29 | ▲ 1.95 |
| 13B LoRAM-Unst | 30.12 | 31.92 | 32.70 | 26.61 | ▲ 2.16 |
| 70B w/o FT | 39.53 | 52.01 | 39.53 | 52.01 | 1.00 |
| 13B LoRA | 32.03 | 36.69 | 33.63 | 25.70 | 5.30 |
| 70B QLoRAM-Rand | 39.66 | 57.62 | 39.40 | 55.72 | 12.84 |
| 70B QLoRAM-Stru | 39.77 | 57.16 | 39.73 | 54.44 | 12.84 |
🔼 This table presents the accuracy results for two mathematical reasoning tasks: MathQA (1-shot) and GSM8K (8-shot) using the LLaMA-2 model. It compares the performance of different fine-tuning methods: the original LLaMA-2 model without fine-tuning, a LoRA-trained smaller LLaMA-2 model, and several variants of the proposed LORAM method using different pruning strategies (random, structured, semi-structured, unstructured). The parameter reduction ratios are indicated, showing the memory savings achieved by each method. It’s important to note that the theoretical parameter reduction for non-structured pruning is shown, but these parameters are filled with zeros during training, therefore not reducing memory footprint.
read the caption
Table 1: Accuracy (%) of the MathQA (1-shot) & GSM8K (8-shots) in the mathematical domain under LLaMA-2. ▲ indicates the theoretical parameters reduction of non-structured pruning. However, these parameters are filled with zeros in actual training, so the memory footprint is not reduced.
In-depth insights#
Prune, then Train#
Prune, then Train is an intriguing paradigm. The intuition is that it’s computationally cheaper to train a smaller network. Pruning before training could reduce the parameter space, accelerating convergence and potentially improving generalization by preventing overfitting. This could lead to efficient resource usage. However, the initial pruning step is vital. Random pruning might remove essential connections, hindering learning. Smart pruning strategies based on magnitude or gradient can preserve critical pathways. The core challenge lies in balancing model size reduction with the preservation of essential information. A trade-off exists between computational efficiency and the model’s representation capacity. It would be beneficial to understand the optimal pruning ratio with associated pre-training steps.
Align then Fine-tune#
Align then Fine-tune is a prevalent strategy in transfer learning, particularly for large models, where an initial alignment phase prepares the model for subsequent task-specific fine-tuning. The alignment phase often involves techniques like contrastive learning or domain adaptation to bring the model’s representations closer to the target domain or task distribution. This pre-alignment can significantly improve the efficiency and effectiveness of fine-tuning, as the model starts from a better initialization point. By first aligning the model, we ensure that the fine-tuning process focuses on learning task-specific nuances rather than overcoming large distributional shifts, leading to faster convergence and better generalization. This approach is useful when there is a significant distribution difference between source data and target task’s data.
Memory Efficient LoRA#
Memory-efficient LoRA training addresses the significant memory footprint of large language models (LLMs) during fine-tuning. It likely involves techniques to reduce memory usage by quantizing the weights. A possible mitigation strategy involves training on a smaller, pruned model and then transferring the learned knowledge or parameters to the full-sized model for inference, which can improve memory efficiency. An alignment strategy can reduce inconsistencies by pre-training the pruned model to be similar to the original one.
Pruning strategies#
Pruning strategies in large language models offer a pathway to reduce computational costs and model size, enabling efficient deployment. Methods range from unstructured pruning, which removes individual weights, to structured pruning, which eliminates entire neurons or layers. Unstructured pruning offers finer granularity, but can result in irregular memory access patterns, hindering speedup. Structured pruning maintains model architecture, facilitating hardware acceleration. The effectiveness of pruning hinges on identifying redundant parameters while preserving vital knowledge. Techniques such as magnitude-based pruning and gradient-based pruning are employed. Combining pruning with techniques like quantization can lead to further compression gains.
Domain Specificity#
The study demonstrates that LoRAM excels in domain-specific settings, retaining high accuracy with substantial parameter reduction, showcasing robustness and efficiency. These results emphasize LoRAM’s versatility beyond general instruction fine-tuning, implying its potential for customized applications where specialized knowledge is crucial. The ability to maintain accuracy with fewer parameters suggests that LoRAM can effectively distill and transfer relevant information for particular domains.
More visual insights#
More on figures

🔼 This figure compares the LoRA and LoRAM training and inference processes. LoRA uses the same original model for both training and inference, while LoRAM uses a pruned model for training and recovers the weights to use the original model for inference. The figure highlights the key stages: (a) LoRA training, updating low-rank matrices with original weights frozen; (b) LoRAM training, updating low-rank matrices on the pruned model; (c) LoRA inference, using the updated low-rank matrices with original weights; (d) LoRAM inference, using recovered low-rank matrices to integrate with original weights; (e) offline processing on the full-rank matrix; and (f) online generation of the low-rank matrix.
read the caption
Figure 2: Comparison of LoRAM and LoRA: Training (subfigures a and b) and Inference (c and d). Key stages include the offline process of the frozen full-rank matrix 𝐖0∗superscriptsubscript𝐖0\mathbf{W}_{0}^{*}bold_W start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT (subfigure e) and the online generation of the learnable low-rank matrix 𝐖Δ∗superscriptsubscript𝐖Δ\mathbf{W}_{\Delta}^{*}bold_W start_POSTSUBSCRIPT roman_Δ end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT (f) during LoRAM training (b) and inference (d).

🔼 This figure displays the test perplexity results for fine-tuning two different sizes of LLAMA language models (13B and 70B parameters) using the OpenHermes dataset. The perplexity is tracked over various training iterations for different training methods, including standard LoRA and several variations of the proposed LORAM method incorporating different pruning strategies (random, structured, semi-structured, and unstructured). This allows comparison of the training convergence speeds and the resulting test perplexity for these different training approaches, demonstrating the effectiveness of LORAM in improving efficiency without significant loss of performance.
read the caption
Figure 3: The test perplexity of training LLaMA-2-13B & LLaMA-2-70B on OpenHermes.

🔼 This figure displays the test perplexity results for training two large language models, LLaMA-2-13B and LLaMA-2-70B, on the OpenOrca dataset. The graphs show the perplexity over training iterations for each model, comparing standard LORA fine-tuning with several variants of the proposed memory-efficient LORA training scheme (LORAM) using different pruning strategies: LORAM-RAND, LORAM-STRU, LORAM-SEMI, and LORAM-UNST. The figure also includes results for a smaller LLaMA model (7B) trained with LORA to provide a performance baseline for comparison. This comparison allows assessment of the tradeoffs between model size, memory efficiency, and performance.
read the caption
Figure 4: The test perplexity of training LLaMA-2-13B & LLaMA-2-70B on OpenOrca.

🔼 This figure displays the results of training the LLaMA-3.1-70B model on the OpenHermes dataset using different training methods. It shows the test perplexity during training (how well the model predicts the next word in a sequence, lower is better) on the Alpaca dataset (an out-of-domain dataset; that is, a dataset different than the one used for training). Additionally, the figure presents downstream task performance results across various tasks, showing the effectiveness of different training methods on various downstream applications after training.
read the caption
Figure 5: The test perplexity & downstream performance of training LLaMA-3.1-70B on OpenHermes.

🔼 This figure demonstrates the impact of the recovery and alignment steps in the LORAM model training process on LLaMA-2-13B. It compares the performance of four different pruning strategies (Rand, Stru, Semi, Unst) with and without the recovery and alignment steps. The plots show the test perplexity on the Alpaca dataset for each strategy and configuration. This illustrates that the recovery and alignment steps significantly improve performance, especially under aggressive pruning rates. The results highlight that simply pruning and then fine-tuning is not enough to achieve high performance; the recovery and alignment steps are crucial in bridging the gap between the pruned model used for training and the full original model used for inference.
read the caption
Figure 6: Necessity of Recovery & Alignment across different pruning strategies on LLaMA-2-13B.

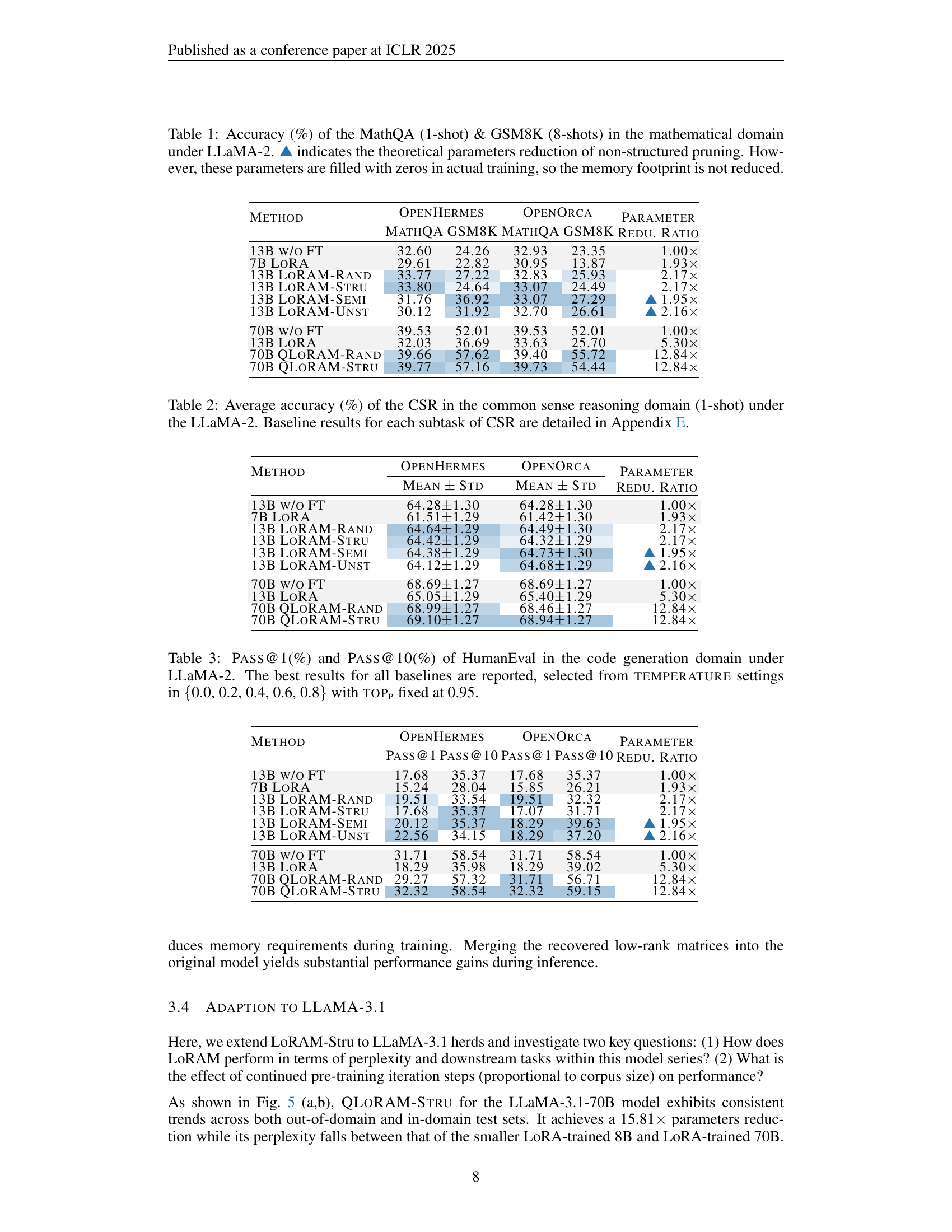
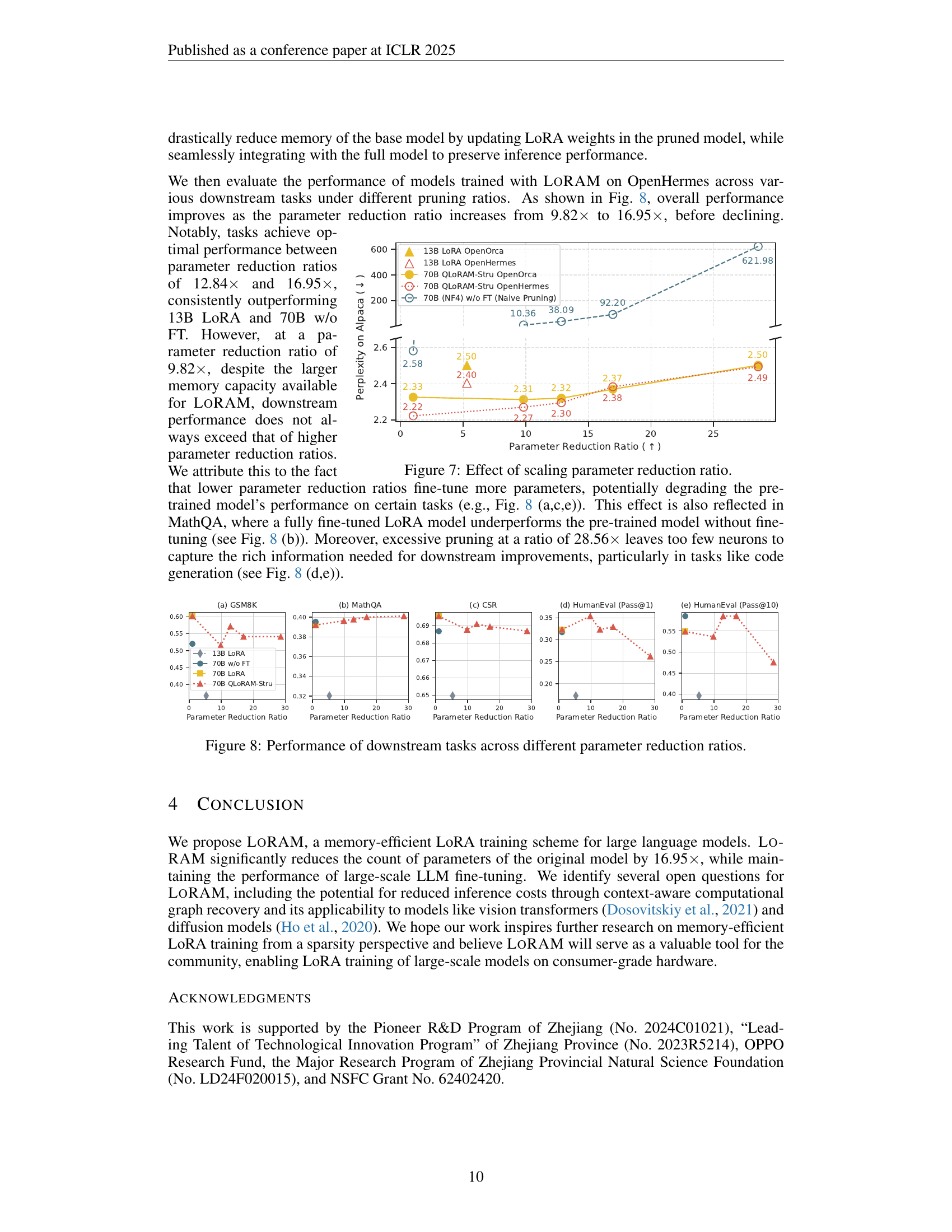
🔼 This figure demonstrates the impact of varying parameter reduction ratios on the performance of LoRA and QLORAM-STRU models. The x-axis represents the parameter reduction ratio, ranging from approximately 10x to nearly 30x. The y-axis shows the test perplexity on the Alpaca dataset. LoRA-trained and QLORAM-STRU-trained models show a trend of improved performance with increasing reduction ratios, but excessive pruning (larger reduction ratios) negatively impacts the model’s performance. A comparison with a naive pruning method demonstrates that LoRAM’s method leads to far more robust performance as the parameter reduction increases.
read the caption
Figure 7: Effect of scaling parameter reduction ratio.

🔼 This figure presents the performance of various downstream tasks (GSM8K, MathQA, CSR, HumanEval) for different parameter reduction ratios achieved by QLORAM-STRU on the LLaMA-2-70B model. It shows how the model’s performance on these tasks changes as the parameter reduction ratio increases from approximately 10x to nearly 30x. The graph illustrates a trade-off: increasing the reduction ratio initially improves performance, reaching an optimal point, before performance starts to decrease again at the most aggressive pruning ratios. This demonstrates the effectiveness of QLORAM-STRU in balancing memory efficiency and task performance up to a certain level of model compression, beyond which the level of pruning negatively affects performance.
read the caption
Figure 8: Performance of downstream tasks across different parameter reduction ratios.
More on tables
| Method | OpenHermes | OpenOrca | Parameter Redu. Ratio |
| Mean Std | Mean Std | ||
| 13B w/o FT | 64.281.30 | 64.281.30 | 1.00 |
| 7B LoRA | 61.511.29 | 61.421.30 | 1.93 |
| 13B LoRAM-Rand | 64.641.29 | 64.491.30 | 2.17 |
| 13B LoRAM-Stru | 64.421.29 | 64.321.29 | 2.17 |
| 13B LoRAM-Semi | 64.381.29 | 64.731.30 | ▲ 1.95 |
| 13B LoRAM-Unst | 64.121.29 | 64.681.29 | ▲ 2.16 |
| 70B w/o FT | 68.691.27 | 68.691.27 | 1.00 |
| 13B LoRA | 65.051.29 | 65.401.29 | 5.30 |
| 70B QLoRAM-Rand | 68.991.27 | 68.461.27 | 12.84 |
| 70B QLoRAM-Stru | 69.101.27 | 68.941.27 | 12.84 |
🔼 This table presents the average accuracy scores achieved by different LLaMA-2 models on six common sense reasoning tasks. The models compared include the original, untrained LLaMA-2-13B, a smaller LoRA-trained LLaMA-2-7B, and various versions of the memory-efficient LORAM model with different pruning techniques (random, structured, semi-structured, and unstructured). The results show the average accuracy across the six tasks, along with the parameter reduction ratio for each LORAM variant compared to the original LLaMA-2-13B model. Appendix E provides a detailed breakdown of the performance on each individual common sense reasoning sub-task.
read the caption
Table 2: Average accuracy (%) of the CSR in the common sense reasoning domain (1-shot) under the LLaMA-2. Baseline results for each subtask of CSR are detailed in Appendix E.
| Method | OpenHermes | OpenOrca | Parameter Redu. Ratio | ||
| Pass@1 | Pass@10 | Pass@1 | Pass@10 | ||
| 13B w/o FT | 17.68 | 35.37 | 17.68 | 35.37 | 1.00 |
| 7B LoRA | 15.24 | 28.04 | 15.85 | 26.21 | 1.93 |
| 13B LoRAM-Rand | 19.51 | 33.54 | 19.51 | 32.32 | 2.17 |
| 13B LoRAM-Stru | 17.68 | 35.37 | 17.07 | 31.71 | 2.17 |
| 13B LoRAM-Semi | 20.12 | 35.37 | 18.29 | 39.63 | ▲ 1.95 |
| 13B LoRAM-Unst | 22.56 | 34.15 | 18.29 | 37.20 | ▲ 2.16 |
| 70B w/o FT | 31.71 | 58.54 | 31.71 | 58.54 | 1.00 |
| 13B LoRA | 18.29 | 35.98 | 18.29 | 39.02 | 5.30 |
| 70B QLoRAM-Rand | 29.27 | 57.32 | 31.71 | 56.71 | 12.84 |
| 70B QLoRAM-Stru | 32.32 | 58.54 | 32.32 | 59.15 | 12.84 |
🔼 This table presents the performance of different LLaMA-2 models on the HumanEval code generation benchmark. The HumanEval benchmark evaluates the ability of a language model to generate correct code given a function signature, a docstring (description of the function), and unit tests. The models tested include the original untuned LLaMA-2 model, smaller LoRA-tuned models, and various LoRAM-tuned models which use different pruning techniques. The results reported are PASS@1 (the percentage of tasks for which the top-ranked generated solution is correct) and PASS@10 (the percentage of tasks for which at least one of the top-10 generated solutions is correct). The best results from a range of temperature settings (controlling randomness in the model’s output) are shown for each model.
read the caption
Table 3: Pass@1(%) and Pass@10(%) of HumanEval in the code generation domain under LLaMA-2. The best results for all baselines are reported, selected from temperature settings in {0.0, 0.2, 0.4, 0.6, 0.8} with toppsubscripttopp\textsc{top}_{\textsc{p}}top start_POSTSUBSCRIPT p end_POSTSUBSCRIPT fixed at 0.95.
| Method | #Orig. Params | Pruning Ratio | #Pruned Params | Reduction | HBM |
| LoRAM-Semi | 13015864320 | 0.50 | 6738415616 | 1.93 | 12.55 |
| LoRAM-Unst | 13015864320 | 0.55 | 6037628912 | 2.16 | 11.25 |
| LoRAM-Rand & Stru | 13015864320 | 0.65 | 6005662720 | 2.17 | 11.19 |
🔼 This table presents a comparison of four different pruning methods used in the LoRAM (Low-Rank Adaptation with Memory efficiency) training scheme. Specifically, it shows the impact of each pruning method on LLaMA-2-13B. The table lists the original number of parameters, the pruning ratio applied, the resulting number of pruned parameters, the parameter reduction ratio achieved (expressed as a multiple), and the amount of High Bandwidth Memory (HBM) required to store the pruned parameters. Note that the low-rank matrix overhead isn’t included in this HBM calculation.
read the caption
Table 4: LoRAM configures on LLaMA-2-13B. Comparison of different pruning methods in terms of parameter reduction ratio (Reduction) and HBM footprint (GB) of pruned parameters (HBM), ignoring low-rank matrix overhead.
| Method | #Orig. Params | Pruning Ratio | #Pruned Params | Reduction | HBM |
| LoRAM-Rand & Stru | 68976648192 | 0.65 | 28099436544 | 2.45 | 52.34 |
| LoRAM-Rand & Stru | 68976648192 | 0.75 | 21488738304 | 3.21 | 40.03 |
| LoRAM-Rand & Stru | 68976648192 | 0.85 | 16272924672 | 4.24 | 30.31 |
| LoRAM-Rand & Stru | 68976648192 | 0.95 | 9662226432 | 7.14 | 18.00 |
| LoRAM-Rand & Stru | 70553706496 | 0.85 | 17849982976 | 3.95 | 33.25 |
🔼 This table presents the configurations used for the LoRAM experiments on the LLaMA-2-70B and LLaMA-3.1-70B models. It shows how different pruning ratios affect the number of pruned parameters, the reduction ratio compared to the original number of parameters, and the amount of GPU High Bandwidth Memory (HBM) required for training. The table is crucial for understanding the impact of different pruning strategies on memory efficiency and the trade-off between memory savings and performance.
read the caption
Table 5: LoRAM configures on LLaMA-2-70B and LLaMA-3.1-70B with different pruning ratios.
| Method | #Orig. Params | Pruning Ratio | #Pruned Params | Reduction | HBM |
| QLoRAM-Rand & Stru | 68976648192 | 0.65 | 7024859136 | 9.82 | 13.08 |
| QLoRAM-Rand & Stru | 68976648192 | 0.75 | 5372184576 | 12.84 | 10.01 |
| QLoRAM-Rand & Stru | 68976648192 | 0.85 | 4068231168 | 16.95 | 7.58 |
| QLoRAM-Rand & Stru | 68976648192 | 0.95 | 2415556608 | 28.56 | 4.50 |
| QLoRAM-Rand & Stru | 70553706496 | 0.85 | 4462495744 | 15.81 | 8.31 |
🔼 This table shows different configurations for QLoRAM (Quantized LoRAM) on two large language models, LLaMA-2-70B and LLaMA-3.1-70B. It details the original number of parameters, the pruning ratio used, the number of parameters after pruning, the reduction ratio achieved (showing how much smaller the model became), and the amount of High Bandwidth Memory (HBM) used by the pruned parameters. The table highlights how QLoRAM, by combining LORAM with quantization, achieves very aggressive parameter compression, significantly reducing memory requirements during training.
read the caption
Table 6: QLoRAM configures on LLaMA-2-70B and LLaMA-3.1-70B with , demonstrating more aggressive parameter compression.
| LLaMA-3.1 | GSM8K | Parameter Reduction Ratio |
| 8B w/o Fine-Tuning | 55.27 | 8.79× |
| 8B LoRA (OpenHermes 400) | 55.80 | 8.79× |
| 70B w/o Fine-Tuning | 75.28 | 1.00× |
| 70B QLoRAM-Stru 400 (OpenHermes 400) | 80.36 | 15.81× |
| 70B QLoRAM-Stru 400 (GSM8K 100) | 77.18 | 15.81× |
| 70B QLoRAM-Stru 400 (GSM8K 200) | 79.15 | 15.81× |
| 70B LoRA (OpenHermes 400) | 80.74 | 1.00× |
🔼 This table presents the results of evaluating LoRAM’s performance on the GSM8K dataset, a benchmark specifically designed for mathematical reasoning. It shows the accuracy achieved by different model configurations, including the original untuned model (70B w/o Fine-Tuning), a smaller model fine-tuned with LoRA (8B LORA), and several LoRAM variants (70B QLORAM-Stru) with varying degrees of parameter reduction. The accuracy is shown as a percentage, and the parameter reduction ratio indicates how much smaller the LoRAM models are compared to the 70B parameter model. The results demonstrate LoRAM’s performance on a domain-specific task and how it compares to alternative fine-tuning methods, highlighting its effectiveness in scenarios with limited resources.
read the caption
Table 7: Evaluation of LoRAM on the GSM8K dataset for domain-specific fine-tuning. Results show accuracy (%) and parameter reduction ratios for different configurations.
| LLaMA-2 | #Model Params | Reduction Ratio | Memory | Latency | Throughput |
| 7B LoRA | 6.73B | 1.93 | 30,517 | 134.27 | 7.626 |
| 13B LoRA | 13.02B | 1.00 | 51,661 | 206.07 | 4.969 |
| 13B LoRAM-Stru | 6.01B | 2.17 | 29,799 | 147.86 | 6.925 |
🔼 This table compares the peak memory usage, latency, and throughput of different models during the online training phase. The models compared are LoRA-trained 7B parameter model and LoRAM-trained 13B parameter model. The training workload consists of 1024 samples with a batch size of 128, micro-batch size of 4, and a sequence length of 512. The results show that LoRAM achieves comparable performance to the smaller 7B parameter LoRA model in terms of memory, latency and throughput, despite using a larger model.
read the caption
Table 8: Comparison of peak memory (MiB), latency (s), and throughput (samples/s) during the online training phase for LoRAM and LoRA models. Results are based on a workload of 1024 samples (batch size 128, micro-batch size 4, sequence length 512).
Full paper#