TL;DR#
Linear sequence modeling methods offer efficiency, but compressing input into a single memory state hinders performance, especially in recall-intensive tasks. Inspired by the brain’s memory mechanisms, this paper introduces a new architecture to overcome these limitations. By leveraging biological insights, the paper addresses the challenge of balancing explicit token representations and extreme compression.
The paper presents Mixture-of-Memories (MoM), which employs multiple independent memory states with a routing network, directing input tokens to specific states. This enhances memory capacity and reduces interference. MoM retains linear complexity during training and constant complexity during inference. Experiments show MoM outperforms current models on downstream tasks, even matching Transformer performance.
Key Takeaways#
Why does it matter?#
This paper is important as it introduces a novel architecture that addresses the limitations of existing linear sequence models. By overcoming challenges related to limited memory capacity and memory interference, this research paves the way for more efficient and effective handling of long-range dependencies in various NLP tasks, opening new avenues for exploration.
Visual Insights#

🔼 The Mixture-of-Memories (MoM) model uses multiple independent memory states to process input tokens. A router network directs each token to the top K most relevant memory states, where it updates the memory state. Non-selected memories remain unchanged to prevent interference. A shared memory is continuously active and accessible to all tokens. The diagram shows this memory routing and updating process, illustrating a basic update mechanism. More complex mechanisms, such as gating, would follow a similar approach.
read the caption
Figure 1: Framework of MoM. Each input token selectively activates and updates K𝐾Kitalic_K memory states, leaving non-activated memory states unchanged to avoid interference from current input. Additionally, we introduce a continuously activated shared memory. This figure presents the basic memory update mechanism; other mechanisms involving gating or more complex updates follow a similar approach.
| Method | Memory Update Rule |
|---|---|
| LA | |
| Lightning | |
| RetNet | |
| HGRN2 | |
| GLA | |
| Mamba2 | |
| DeltaNet | |
| G-DeltaNet | |
| TTT | |
| Titan |
🔼 This table lists various memory update rules used in different linear sequence models, showing how they can be interpreted within a recurrent model framework. Each rule describes how the current memory state (Mt) is updated based on the previous state (Mt-1), key (kt), and value (vt) vectors. The parameters αt and βt are data-dependent scalars (between 0 and 1), at is a data-dependent vector, and γ is a data-independent constant. This clarifies the relationship between seemingly different linear models and their underlying memory update mechanisms.
read the caption
Table 1: Memory Update Rules. We demonstrate that several current linear sequence models can be viewed as recurrent models in terms of memory updates, where αt,βt∈(0,1)subscript𝛼𝑡subscript𝛽𝑡01\alpha_{t},\beta_{t}\in(0,1)italic_α start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_β start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∈ ( 0 , 1 ) are data-dependent scaler, 𝒂tsubscript𝒂𝑡\bm{a}_{t}bold_italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is data-dependent vector, and γ𝛾\gammaitalic_γ is a data-independent constant.
In-depth insights#
MoM: Interference#
The Mixture-of-Memories (MoM) architecture tackles the challenge of memory interference in sequence modeling. Traditional linear models compress the entire input into a single memory state, leading to information loss during recall-intensive tasks. Inspired by neuroscience, MoM utilizes multiple independent memory states, with a router network directing input tokens to specific memories. This greatly expands the overall memory capacity while minimizing interference. Tokens that introduce new or orthogonal information are directed to separate memory states, preserving diverse information without overwriting existing content. By isolating memory updates, MoM concurrently manages distinct types of information, improving performance on tasks that require extensive contextual understanding. The MoM model effectively narrows the performance gap with Transformer models.
Linear w/MoM#
The concept of “Linear w/MoM” seems to be a novel approach to combine the efficiency of linear sequence models with the enhanced memory capabilities of the Mixture-of-Memories (MoM) architecture. Traditional linear models often struggle with recall-intensive tasks due to their limited capacity to retain long-range dependencies. “Linear w/MoM” likely addresses this by leveraging multiple independent memory states, allowing the model to capture and retain diverse aspects of the input sequence without the interference that plagues single-memory linear models. The integration of a routing mechanism is also critical, directing input tokens to the most relevant memory states. This selective activation ensures that each memory specializes in encoding specific types of information. By mixing the memories through weighed summation, the model is better able to retrieve info.
Exp.: LongBench#
While “Exp.: LongBench” isn’t explicitly present, it’s reasonable to infer its purpose: evaluating performance on tasks requiring long-range dependency handling. The ‘LongBench’ benchmark (Bai et al., 2024) measures a model’s ability to process extended contexts, crucial for tasks like summarization and code completion. Models with limited memory often struggle, making ‘LongBench’ a critical test. The paper likely presents results showing the model’s performance across various LongBench categories (summarization, few-shot, code), highlighting its capacity to capture and utilize information over long input sequences. It demonstrates whether proposed architecture can effectively overcome the limitations of existing methods and maintain performance with increasing sequence length.
Memory Routing#
The research paper introduces a novel approach to sequence modeling called Mixture-of-Memories (MoM), drawing inspiration from neuroscience to address the limitations of existing linear sequence models. The core idea is to utilize multiple independent memory states, akin to how the brain handles multi-item memory, to mitigate memory interference. A key component for achieving this is a router network which directs input tokens to specific memory states, ensuring that relevant information is stored and retrieved effectively. The router acts as an information bottleneck, guiding each token to the most appropriate memory. This approach allows MoM to increase memory capacity and maintain diverse information without overwriting. This memory routing mechanism helps MoM perform well on recall-intensive tasks.
Neuro-Inspired#
The paper’s title, “MoM: Linear Sequence Modeling with Mixture-of-Memories,” immediately suggests a neuro-inspired approach. The mention of “memories” directly connects to cognitive functions of the brain. The abstract explicitly states inspiration from neuroscience, particularly the brain’s ability to maintain long-term memory while reducing “memory interference.” The Mixture-of-Memories architecture mirrors how the brain segregates and processes information. This is evident in the hippocampus, where theta-gamma oscillations manage multi-item memory. Each token gets routed to specific memory states, mimicking specialized neural circuits. The design to mitigate memory interference reflects an understanding of how the brain avoids overwriting or corrupting stored information. The approach mirrors how the brain handles complexity and information overload. This is by dividing tasks among specialized areas or circuits, ensuring that each piece of information is handled efficiently without causing interference with other processes. The explicit reference to theta-gamma oscillations indicates a sophisticated understanding of neural coding and memory consolidation. The MoM architecture is designed to emulate the brain’s efficient memory management system.
More visual insights#
More on figures

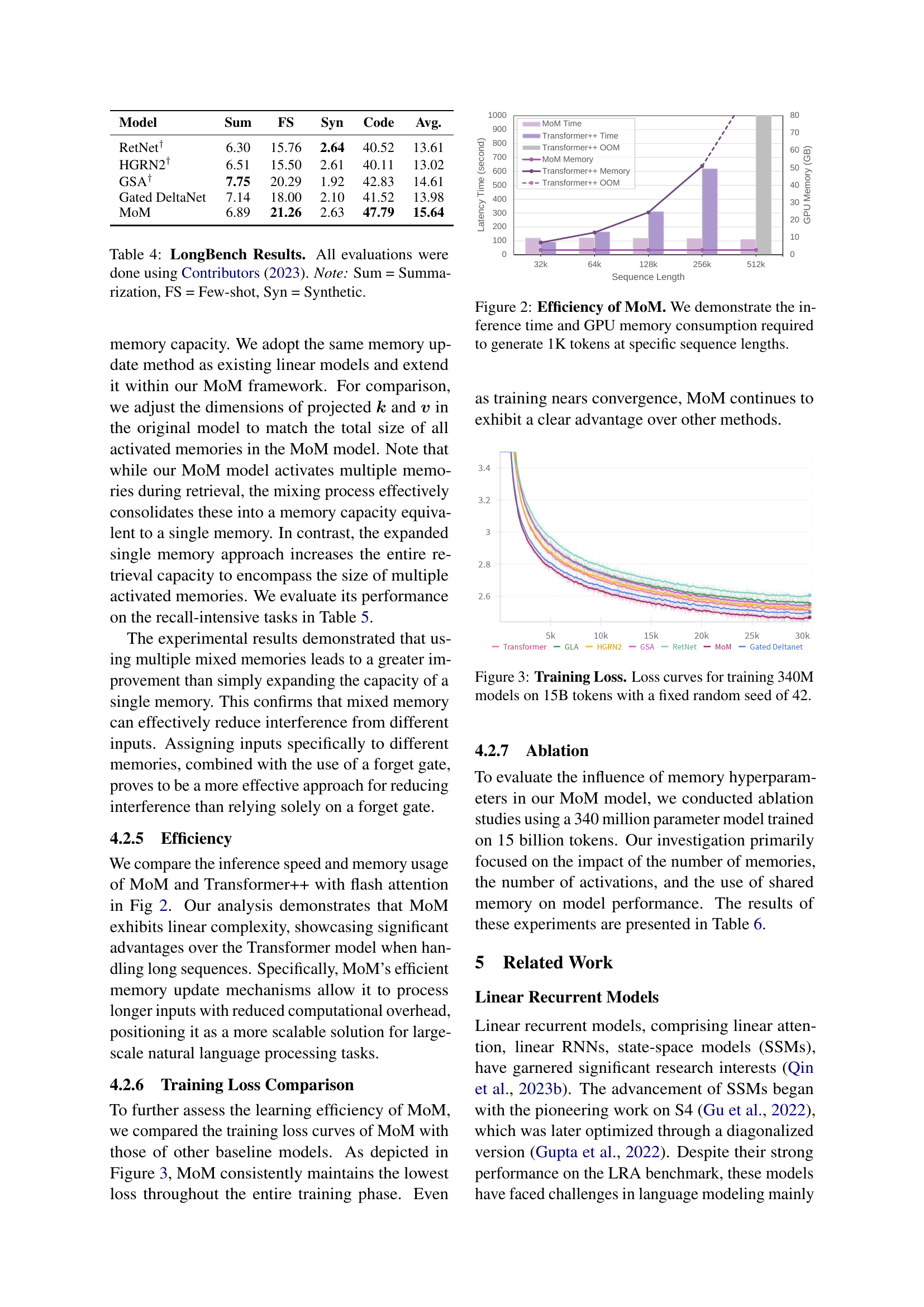
🔼 This figure compares the inference time and GPU memory usage of MoM and Transformer++ with flash attention when generating 1K tokens at various sequence lengths. It visually demonstrates the linear time and space complexity of MoM compared to the quadratic complexity of Transformer++, highlighting MoM’s efficiency advantage, especially for longer sequences.
read the caption
Figure 2: Efficiency of MoM. We demonstrate the inference time and GPU memory consumption required to generate 1K tokens at specific sequence lengths.

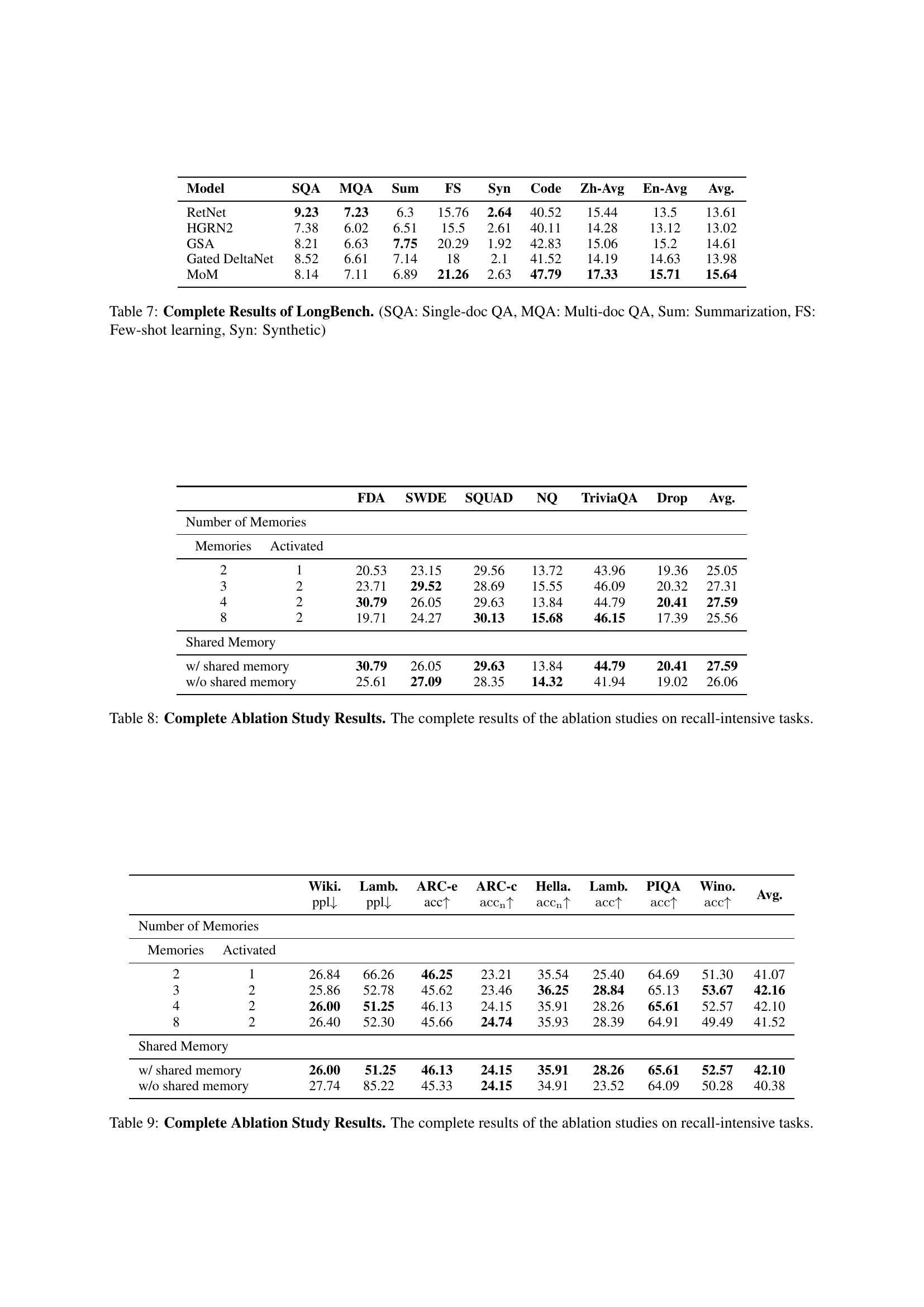
🔼 This figure displays the training loss curves for 340 million parameter models trained on 15 billion tokens. A fixed random seed of 42 was used to ensure reproducibility. The graph allows for a comparison of training loss across different models, showing the rate at which each model’s loss decreases over the course of training.
read the caption
Figure 3: Training Loss. Loss curves for training 340M models on 15B tokens with a fixed random seed of 42.
More on tables
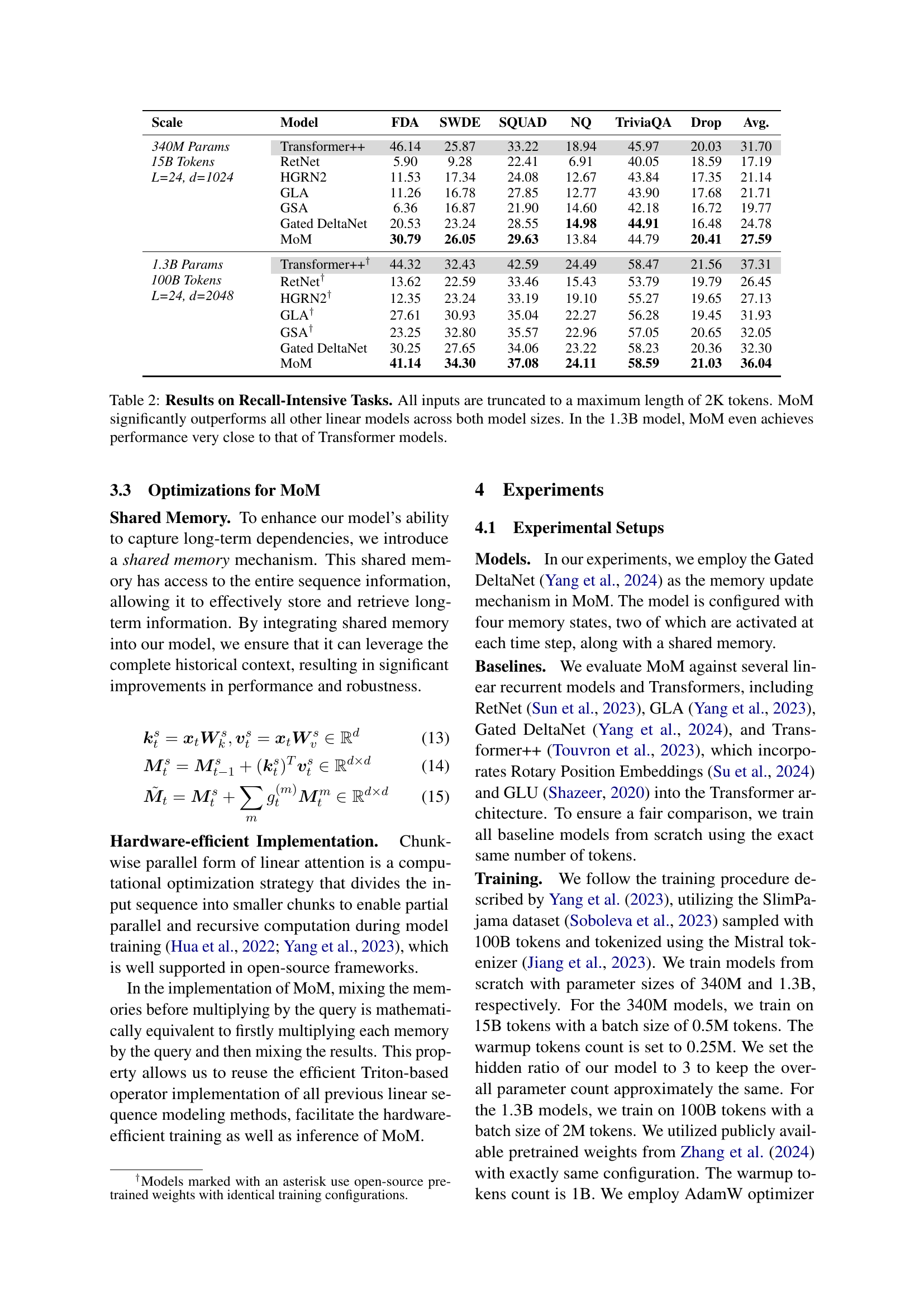
| Scale | Model | FDA | SWDE | SQUAD | NQ | TriviaQA | Drop | Avg. |
|---|---|---|---|---|---|---|---|---|
| 340M Params 15B Tokens L=24, d=1024 | Transformer++ | 46.14 | 25.87 | 33.22 | 18.94 | 45.97 | 20.03 | 31.70 |
| RetNet | 5.90 | 9.28 | 22.41 | 6.91 | 40.05 | 18.59 | 17.19 | |
| HGRN2 | 11.53 | 17.34 | 24.08 | 12.67 | 43.84 | 17.35 | 21.14 | |
| GLA | 11.26 | 16.78 | 27.85 | 12.77 | 43.90 | 17.68 | 21.71 | |
| GSA | 6.36 | 16.87 | 21.90 | 14.60 | 42.18 | 16.72 | 19.77 | |
| Gated DeltaNet | 20.53 | 23.24 | 28.55 | 14.98 | 44.91 | 16.48 | 24.78 | |
| MoM | 30.79 | 26.05 | 29.63 | 13.84 | 44.79 | 20.41 | 27.59 | |
| 1.3B Params 100B Tokens L=24, d=2048 | Transformer++† | 44.32 | 32.43 | 42.59 | 24.49 | 58.47 | 21.56 | 37.31 |
| RetNet† | 13.62 | 22.59 | 33.46 | 15.43 | 53.79 | 19.79 | 26.45 | |
| HGRN2† | 12.35 | 23.24 | 33.19 | 19.10 | 55.27 | 19.65 | 27.13 | |
| GLA† | 27.61 | 30.93 | 35.04 | 22.27 | 56.28 | 19.45 | 31.93 | |
| GSA† | 23.25 | 32.80 | 35.57 | 22.96 | 57.05 | 20.65 | 32.05 | |
| Gated DeltaNet | 30.25 | 27.65 | 34.06 | 23.22 | 58.23 | 20.36 | 32.30 | |
| MoM | 41.14 | 34.30 | 37.08 | 24.11 | 58.59 | 21.03 | 36.04 |
🔼 This table presents the results of several linear sequence models and Transformer models on six recall-intensive tasks. The input sequences were truncated to a maximum length of 2000 tokens for all models. The key finding is that the Mixture-of-Memories (MoM) model significantly outperforms all other linear models in terms of accuracy, achieving performance close to that of Transformer models, especially with the larger 1.3B parameter model.
read the caption
Table 2: Results on Recall-Intensive Tasks. All inputs are truncated to a maximum length of 2K tokens. MoM significantly outperforms all other linear models across both model sizes. In the 1.3B model, MoM even achieves performance very close to that of Transformer models.
| Scale | Model |
|
|
|
|
|
|
|
| Avg. | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 340M Params 15B Tokens L=24, d=1024 | Transformer++ | 26.88 | 76.46 | 44.91 | 25.94 | 34.95 | 26.90 | 64.31 | 51.07 | 41.35 | ||||||||||||||||
| RetNet | 31.07 | 87.11 | 44.49 | 23.04 | 33.86 | 23.93 | 63.49 | 52.33 | 40.19 | |||||||||||||||||
| HGRN2 | 27.90 | 77.40 | 45.24 | 23.63 | 35.61 | 24.74 | 65.45 | 54.06 | 41.46 | |||||||||||||||||
| GLA | 28.78 | 79.95 | 44.53 | 22.27 | 34.84 | 24.94 | 63.93 | 51.38 | 40.32 | |||||||||||||||||
| GSA | 28.17 | 82.50 | 45.50 | 24.23 | 35.00 | 24.02 | 64.85 | 50.43 | 40.67 | |||||||||||||||||
| Gated DeltaNet | 26.47 | 58.59 | 46.04 | 23.55 | 35.18 | 27.01 | 66.05 | 50.83 | 41.44 | |||||||||||||||||
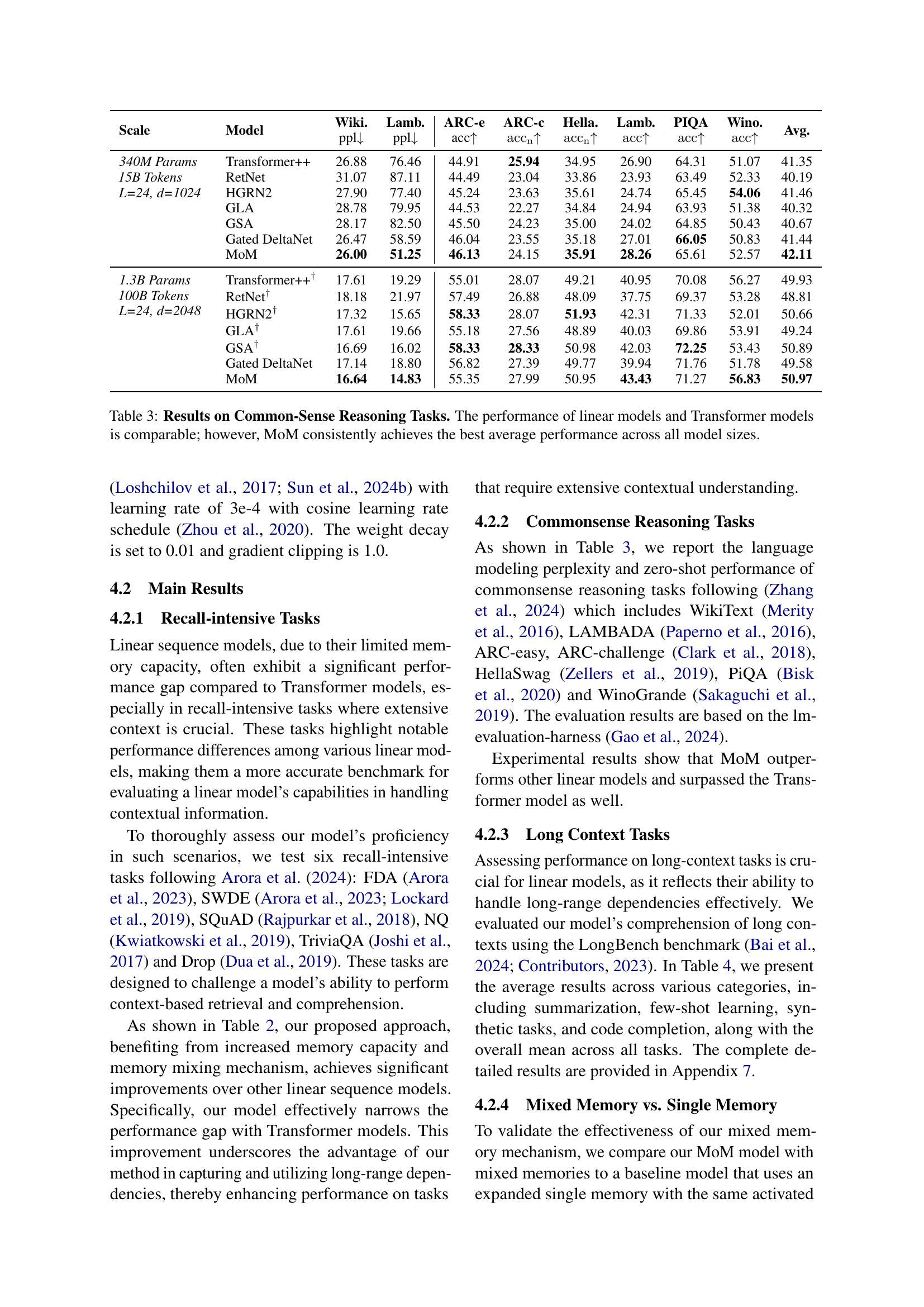
| MoM | 26.00 | 51.25 | 46.13 | 24.15 | 35.91 | 28.26 | 65.61 | 52.57 | 42.11 | |||||||||||||||||
| 1.3B Params 100B Tokens L=24, d=2048 | Transformer++† | 17.61 | 19.29 | 55.01 | 28.07 | 49.21 | 40.95 | 70.08 | 56.27 | 49.93 | ||||||||||||||||
| RetNet† | 18.18 | 21.97 | 57.49 | 26.88 | 48.09 | 37.75 | 69.37 | 53.28 | 48.81 | |||||||||||||||||
| HGRN2† | 17.32 | 15.65 | 58.33 | 28.07 | 51.93 | 42.31 | 71.33 | 52.01 | 50.66 | |||||||||||||||||
| GLA† | 17.61 | 19.66 | 55.18 | 27.56 | 48.89 | 40.03 | 69.86 | 53.91 | 49.24 | |||||||||||||||||
| GSA† | 16.69 | 16.02 | 58.33 | 28.33 | 50.98 | 42.03 | 72.25 | 53.43 | 50.89 | |||||||||||||||||
| Gated DeltaNet | 17.14 | 18.80 | 56.82 | 27.39 | 49.77 | 39.94 | 71.76 | 51.78 | 49.58 | |||||||||||||||||
| MoM | 16.64 | 14.83 | 55.35 | 27.99 | 50.95 | 43.43 | 71.27 | 56.83 | 50.97 |
🔼 This table presents the results of common-sense reasoning tasks using various linear models and transformer models. It compares the performance of these models across different sizes (340M and 1.3B parameters) and demonstrates that while linear models and Transformers show comparable performance, the Mixture-of-Memories (MoM) model consistently achieves the highest average accuracy across all model sizes. The metrics used include perplexity (ppl) and accuracy (acc) on various tasks like WikiText, LAMBADA, ARC (easy and challenge), HellaSwag, PiQA, and WinoGrande.
read the caption
Table 3: Results on Common-Sense Reasoning Tasks. The performance of linear models and Transformer models is comparable; however, MoM consistently achieves the best average performance across all model sizes.
| Wiki. |
| ppl |
🔼 This table presents the results of the LongBench benchmark, which evaluates large language models on various long-context tasks. The benchmark includes summarization, few-shot learning, and synthetic tasks. The results are organized by model and task, showing the performance (presumably metrics such as accuracy or F1 score) for each. The ‘Sum’, ‘FS’, and ‘Syn’ columns likely represent summarization, few-shot, and synthetic task categories, respectively. The evaluation was performed using the Contributors (2023) framework.
read the caption
Table 4: LongBench Results. All evaluations were done using Contributors (2023). Note: Sum = Summarization, FS = Few-shot, Syn = Synthetic.
| Lamb. |
| ppl |
🔼 This table compares the performance of MoM models with multiple independent memory segments against models with a single, expanded memory. Both types of models use different memory update mechanisms. The results show that using separate memory segments (MoM) leads to significantly better performance on recall-intensive tasks than simply increasing the capacity of a single memory. This highlights the effectiveness of MoM’s approach in mitigating memory interference and improving long-term memory.
read the caption
Table 5: Comparison Between Mixed Memory and Single Memory. We constructed MoM models using different memory update mechanisms. Separate memory segments yielded better performance compared to simply increasing the memory capacity of a single memory.
| ARC-e |
| acc |
🔼 This table presents the results of ablation studies conducted to analyze the impact of the number of memories and the inclusion of a shared memory on the model’s performance. The average scores across six recall-intensive tasks (FDA, SWDE, SQUAD, NQ, TriviaQA, Drop) are shown for different configurations, allowing for a comparison of the effects of varying the number of memories and the presence/absence of the shared memory component.
read the caption
Table 6: Ablation Study. We performed ablation studies on the number of memories and the use of shared memory. The table presents the average results across all recall-intensive tasks.
| ARC-c |
🔼 This table presents a comprehensive evaluation of various models on the LongBench benchmark, which assesses performance across diverse long-context tasks. The results are broken down into several categories: Single-document Question Answering (SQA), Multi-document Question Answering (MQA), Summarization, Few-shot learning, and Synthetic tasks. This provides a detailed view of each model’s strengths and weaknesses in handling different types of long-context problems.
read the caption
Table 7: Complete Results of LongBench. (SQA: Single-doc QA, MQA: Multi-doc QA, Sum: Summarization, FS: Few-shot learning, Syn: Synthetic)
| Hella. |
🔼 This table presents a comprehensive analysis of the ablation studies conducted on recall-intensive tasks. It shows the impact of varying the number of memories and the number of activated memories, as well as the effect of including a shared memory, on model performance across six different datasets (FDA, SWDE, SQUAD, NQ, TriviaQA, Drop). The results provide detailed insights into the contribution of these architectural components to the model’s overall performance on recall-heavy tasks.
read the caption
Table 8: Complete Ablation Study Results. The complete results of the ablation studies on recall-intensive tasks.
| Lamb. |
🔼 This table presents a comprehensive analysis of the impact of different hyperparameters on the performance of the MoM model. Specifically, it examines the effects of varying the number of memories, the number of activated memories, and the inclusion of shared memory on several recall-intensive tasks. The results help to understand the optimal configuration of the MoM model for achieving superior performance.
read the caption
Table 9: Complete Ablation Study Results. The complete results of the ablation studies on recall-intensive tasks.
Full paper#