TL;DR#
Large Language Models (LLMs) show impressive capabilities, but short-context models often struggle with longer contexts due to alignment issues. Human annotation is impractical for extended contexts, and balancing short- and long-context performance is difficult. Current methods fall short because they either lack sufficient long-context data or fail to preserve short-context abilities.
To solve these issues, LongPO enables LLMs to self-evolve by transferring short-context skills to longer contexts. It uses self-generated preference data from short-to-long contexts and a short-to-long KL constraint to maintain short-context performance. Applied to Mistral-7B-Instruct-v0.2, LongPO retains short-context performance and outperforms other methods. The models achieve results comparable to superior LLMs like GPT-4-128K on long-context benchmarks.
Key Takeaways#
Why does it matter?#
LongPO offers an efficient way to enhance LLMs for long contexts by transferring short-context capabilities, reducing reliance on expensive manual annotation. This approach opens new research directions for adapting LLMs to diverse context lengths and improving alignment strategies.
Visual Insights#

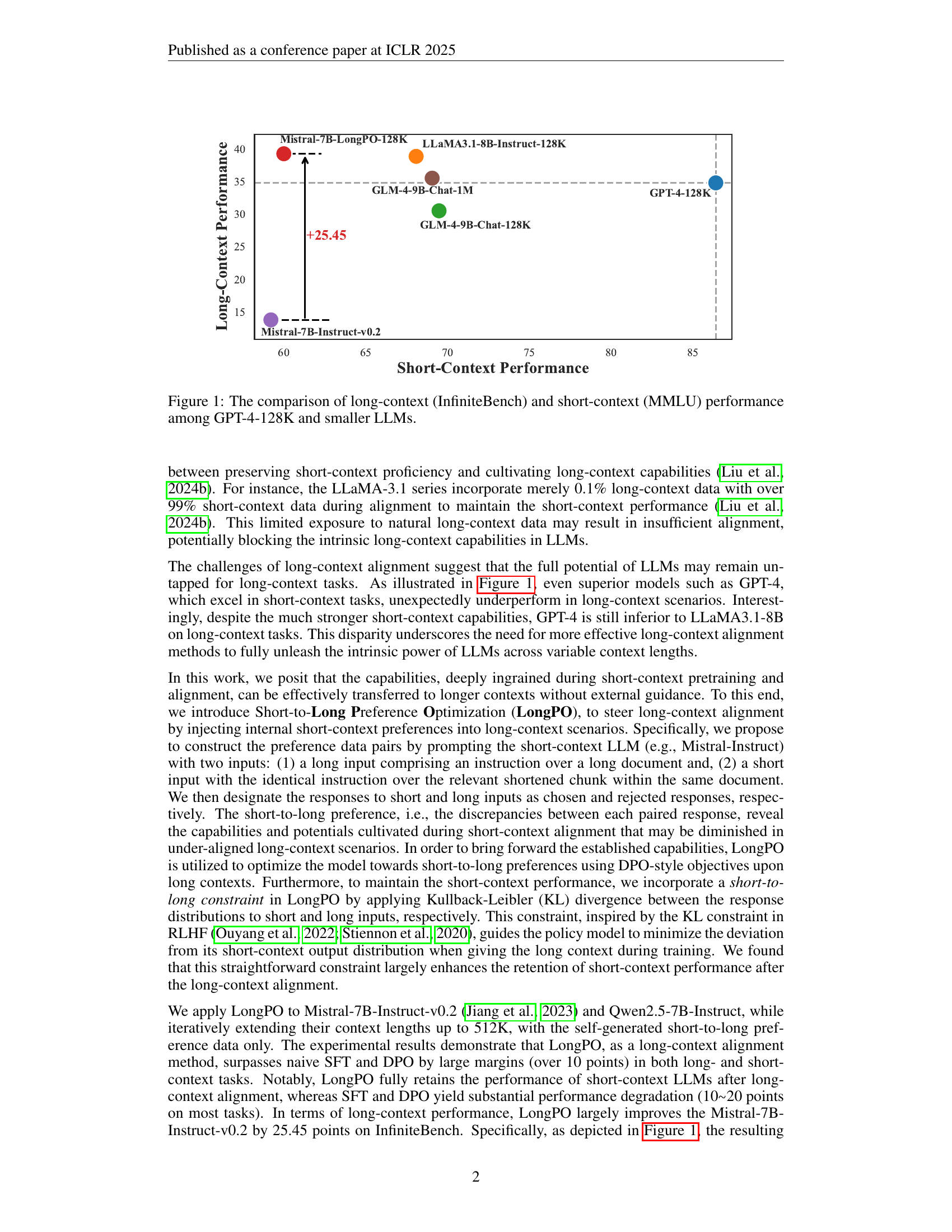
🔼 This figure compares the performance of several large language models (LLMs) on both long-context and short-context tasks. The long-context performance is measured using the InfiniteBench benchmark, while the short-context performance is measured using the MMLU benchmark. The models compared include GPT-4-128K (a high-performing model), and several smaller LLMs. The figure visually demonstrates the performance gap between short and long-context tasks, showing that even high-performing, short-context models can underperform on long-context benchmarks. It highlights a key challenge addressed in the paper: the difficulty of aligning LLMs to perform well in both short and long-context scenarios.
read the caption
Figure 1: The comparison of long-context (InfiniteBench) and short-context (MMLU) performance among GPT-4-128K and smaller LLMs.
| Model | Train/Claimed | Bench | RULER | LongBench- | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Length | En.Sum | En.QA | En.MC | AVG. | NIAH | VT | QA | AVG. | Chat (EN) | ||||
| GPT-4-128K | 128K | 14.73 | 22.44 | 67.25 | 34.81 | 95.4 | 99.9 | 70.3 | 88.53 | 8.40 | |||
| Qwen2-72B | 128K | 24.32♭ | 7.03♭ | 72.05♭ | 34.47♭ | 88.6 | 95.7 | 66.7 | 83.67 | 7.72♭ | |||
| LLaMA 3.1-70B | 128K | 33.55♭ | 36.08♭ | 69.00♭ | 46.21♭ | 96.1 | 93.2 | 67.8 | 85.7 | 6.67♭ | |||
| LLaMA 3.1-8B | 128K | 28.06♭ | 30.47♭ | 58.08♭ | 38.87♭ | 97.93 | 91.4 | 64.7 | 84.68 | 6.22♭ | |||
| GLM-4-9B | 128K | 14.84♭ | 9.51♭ | 67.25♭ | 30.53♭ | 96.51♭ | 97.3♭ | 64.8♭0 | 86.20♭ | 5.67♭ | |||
| GLM-4-9B-1M | 1M | 28.3 | 9.7 | 68.6 | 35.53 | 98.2 | 99.4 | 69.4 | 89.0 | 5.03♭ | |||
| LWM-7B-1M | 1M | 4.33♭ | 0.0♭ | 3.06♭ | 2.46♭ | 87.20 | 57.5 | 56.4 | 67.03 | 1.25♭ | |||
| YaRN-Mistral-7B | 128K | 9.09 | 9.55 | 27.95 | 15.53 | 63.4 | 36.1 | 25.9 | 41.8 | - | |||
| \hdashlineMistral-7B | 32K | 22.13 | 4.93 | 14.41 | 13.82 | 72.60 | 74.40 | 52.2 | 66.4 | 4.10 | |||
| - SFT | 128K | 23.44 | 13.45 | 53.21 | 30.03 | 88.73 | 79.64 | 51.08 | 73.15 | 4.25 | |||
| - DPO | 128K | 15.21 | 10.34 | 48.14 | 25.56 | 74.25 | 72.36 | 50.24 | 65.62 | 4.08 | |||
| - LongPO (iter1) | 128K | 27.05 | 23.51 | 67.25 | 39.27 | 96.88 | 96.49 | 64.81 | 86.06 | 5.42 | |||
| - LongPO (iter2) | 256K | 28.16 | 24.43 | 66.35 | 39.65 | 96.80 | 97.0 | 64.87 | 86.22 | 5.48 | |||
| - LongPO (iter3) | 512K | 29.10 | 27.85 | 66.67 | 41.21 | 97.28 | 97.48 | 64.92 | 86.56 | 5.80 | |||
| \hdashlineQwen2.5-7B | 128K | 22.89 | 6.08 | 52.4 | 27.12 | 82.1 | 80.09 | 54.30 | 72.16 | 5.80 | |||
| - LongPO (iter1) | 128K | 32.06 | 17.32 | 72.05 | 40.48 | 95.81 | 89.71 | 59.4 | 81.64 | 5.75 | |||
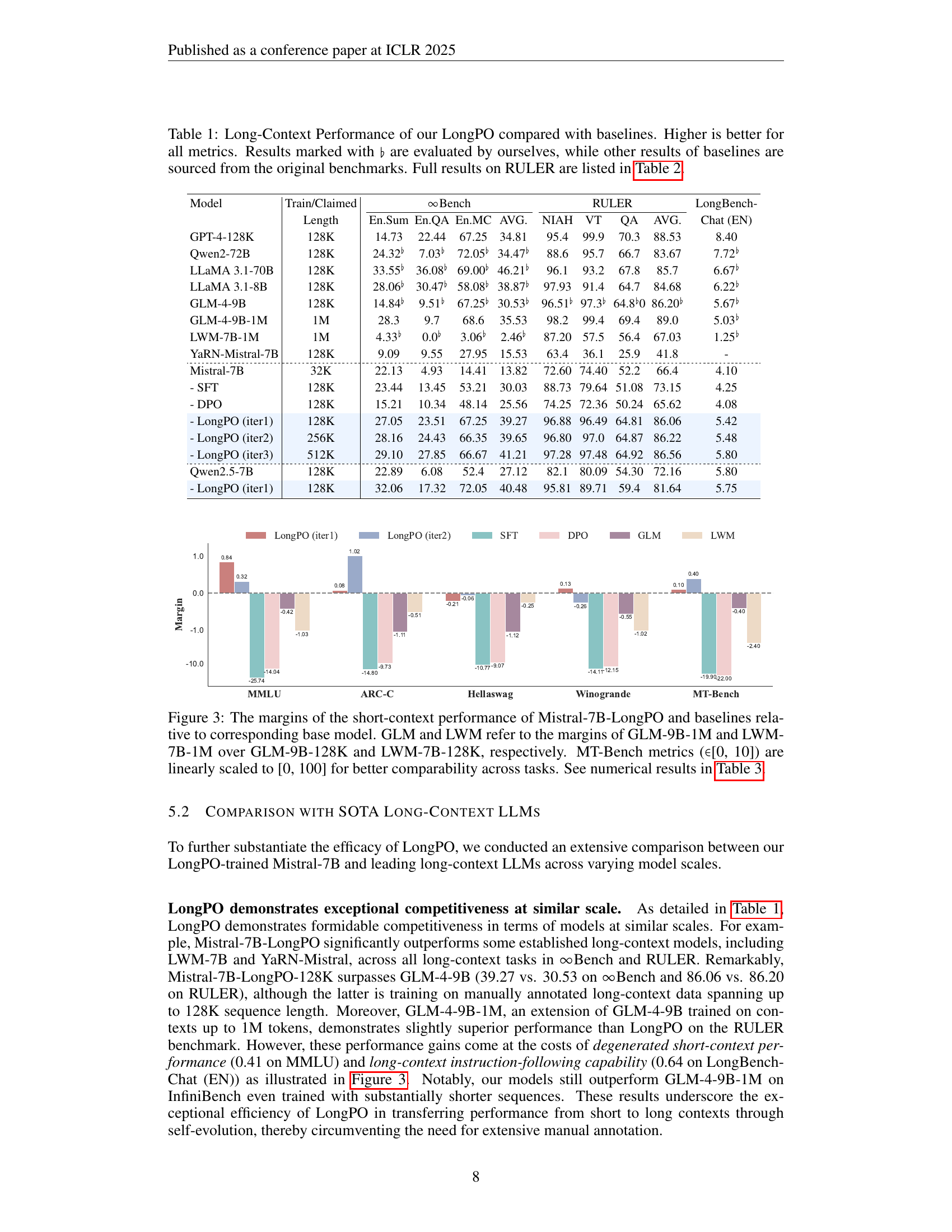
🔼 Table 1 presents a comparison of the long-context performance of the proposed LongPO method against various baselines. The models are evaluated across multiple metrics on several benchmark datasets, focusing on long-context tasks. Higher scores indicate better performance. Some results were obtained by the authors, indicated by the symbol ‘♭’, while others are sourced directly from the original benchmark papers. For a comprehensive breakdown of the RULER benchmark results, refer to Table 2.
read the caption
Table 1: Long-Context Performance of our LongPO compared with baselines. Higher is better for all metrics. Results marked with ♭♭\flat♭ are evaluated by ourselves, while other results of baselines are sourced from the original benchmarks. Full results on RULER are listed in Table 2.
In-depth insights#
LongPO: Overview#
While “LongPO: Overview” isn’t explicitly a heading, we can infer its core concept from the paper. LongPO likely introduces a novel alignment method targeting long-context LLMs. It aims to equip models with the ability to effectively transfer short-context capabilities to these longer scenarios. The core problem being tackled is the difficulty in aligning LLMs for long contexts due to the scarcity of annotated data and the challenges in balancing short and long-context performance. LongPO’s key innovation probably revolves around a clever way to circumvent the need for extensive manual annotation, potentially through a self-evolution or self-supervised approach, allowing the LLM to learn from its own generated data or existing short-context knowledge, and maintaining shorter context performance throughout this evolution.
Short-to-Long Align#
The concept of ‘Short-to-Long Alignment,’ addresses a core challenge in scaling LLMs to handle extended contexts. The summary discusses transferring capabilities learned from short-context data to long-context scenarios. This focuses on maintaining performance and alignment across varying input lengths. The idea revolves around mitigating performance degradation observed in long-context tasks when models are primarily trained on short sequences. It tackles the imbalance between short- and long-context performance, aiming to retain proficiency while extending contextual understanding. Strategies involve fine-tuning and alignment techniques to ensure the model effectively utilizes information from long contexts without losing its ability to process short ones. This highlights the necessity of specialized training and optimization methods tailored for long-context data, as simply concatenating short-context data proves insufficient. A key goal is to optimize the trade-off between short and long sequence processing to enable LLMs with extended context windows.
KL Context Control#
KL context control is a strategy to manage the model’s behavior within a specific context. This is achieved using Kullback-Leibler (KL) divergence. By minimizing the KL divergence, the model is encouraged to stay close to a prior distribution and avoid generating outputs that deviate too much. This method can prevent undesirable behaviors like hallucination or nonsensical output within particular contexts. However, there is a trade-off between control and flexibility: too much constraint may stifle the model and compromise its ability to generate creative solutions. Effective KL context control requires carefully tuning the parameters to strike a balance between adhering to the desired constraints and allowing for sufficient exploration of the solution space. The primary goal of KL context control is to improve the reliability and quality of model-generated content within a context.
512K Self-Evolving#
The concept of ‘512K Self-Evolving’ suggests a language model’s capacity to expand its context window to 512K tokens through self-improvement. It implies a process where the model, starting with a smaller context, iteratively trains itself on data it generates, allowing it to handle longer sequences. Key aspects of such a system involve the method for creating training data, the architecture enabling longer contexts, and strategies to maintain performance on shorter contexts. Self-generation could involve tasks like summarizing long documents or answering questions that require understanding across a larger context, enabling iterative model improvement. The goal is to develop a model that can effectively leverage information within a 512K token window while avoiding performance decline on shorter context tasks.
No Ext. Annotat.#
The paper emphasizes the importance of circumventing the need for external annotations, especially in the context of long-context LLMs. The scarcity and impracticality of human annotation for extended contexts pose significant challenges. LongPO addresses these challenges by leveraging self-generated data and internal model knowledge. The approach enables the transfer of capabilities from short-context alignment to long-context scenarios, effectively eliminating reliance on external supervision. This self-evolution property is a key contribution, offering a more efficient and scalable approach to long-context alignment. The focus on intrinsic model capabilities opens new avenues for adapting LLMs to diverse context lengths without the prohibitive costs of extensive manual annotation.
More visual insights#
More on figures

🔼 This figure illustrates the process of creating short-to-long preference data pairs. It begins with a long document. A short chunk of text is extracted from that document. An instruction is generated based on this short chunk. Then the model generates a response based on this short chunk (chosen response) and the entire long document (rejected response). These two responses paired with the same instruction form a data pair showing preference for one over the other. This process is repeated many times to build up a dataset.
read the caption
Figure 2: The procedure of generating short-to-long preference data from step 1 to 7.

🔼 This figure compares the short-context performance of Mistral-7B-LongPO and several baseline models relative to their corresponding base models. It shows the improvement or degradation in short-context performance after long-context alignment. The baselines include models trained with supervised fine-tuning (SFT) and direct preference optimization (DPO). For reference, the improvements for GLM-9B-1M and LWM-7B-1M over their 128K counterparts (GLM-9B-128K and LWM-7B-128K) are also displayed. The MT-Bench metric, which originally ranges from 0 to 10, is linearly scaled to 0 to 100 for easier comparison across different tasks. Detailed numerical results can be found in Table 3.
read the caption
Figure 3: The margins of the short-context performance of Mistral-7B-LongPO and baselines relative to corresponding base model. GLM and LWM refer to the margins of GLM-9B-1M and LWM-7B-1M over GLM-9B-128K and LWM-7B-128K, respectively. MT-Bench metrics (∈\in∈[0, 10]) are linearly scaled to [0, 100] for better comparability across tasks. See numerical results in Table 3.

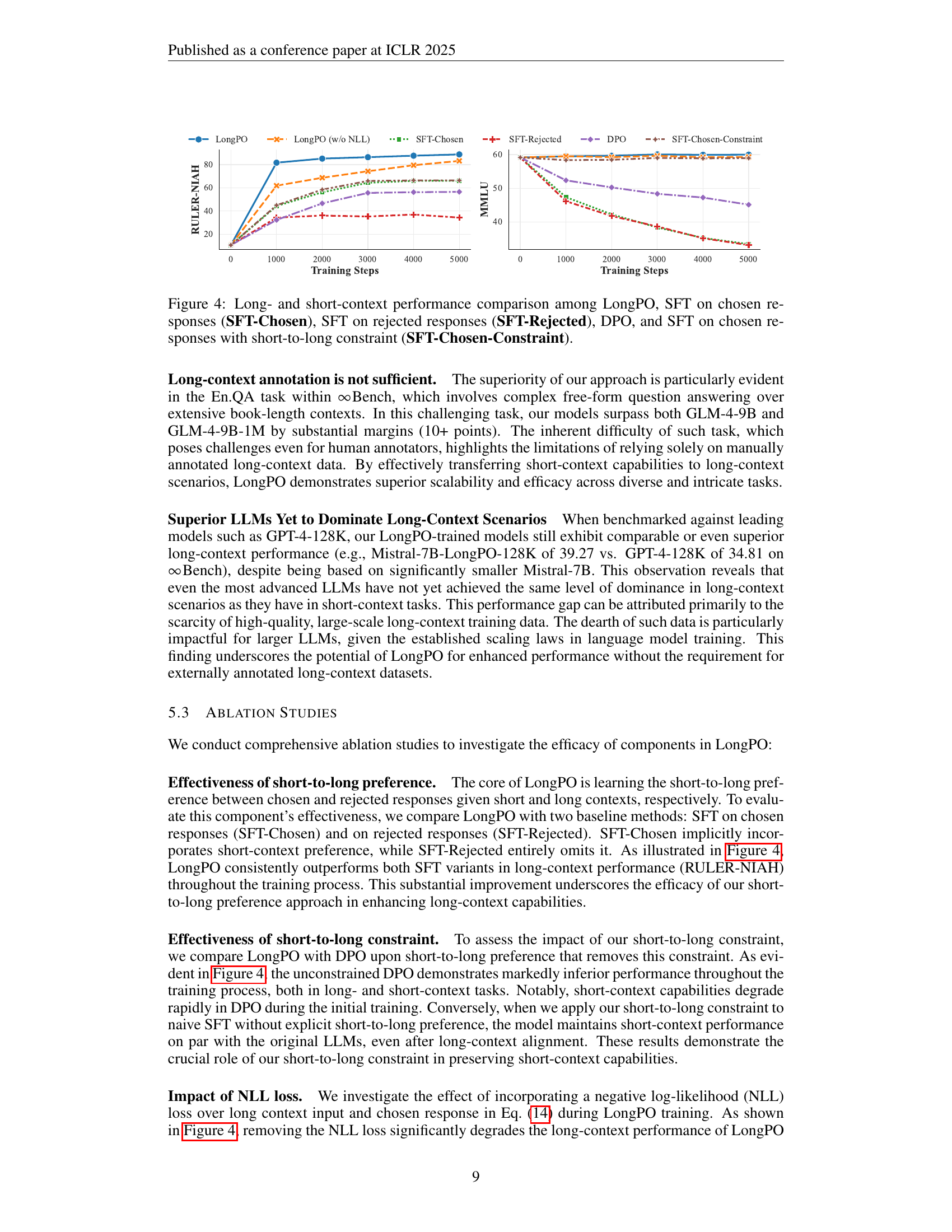
🔼 This figure compares the performance of LongPO with several baseline methods across both long- and short-context tasks. The baselines include: Supervised Fine-Tuning (SFT) using only the chosen responses, SFT using only the rejected responses, Direct Preference Optimization (DPO), and SFT with an added short-to-long constraint. The plots show the training progress over a number of steps, tracking performance on the RULER-NIAH (long-context) and MMLU (short-context) benchmarks. The figure illustrates LongPO’s ability to maintain strong performance on short-context tasks while simultaneously improving long-context performance, a key advantage over the baseline methods.
read the caption
Figure 4: Long- and short-context performance comparison among LongPO, SFT on chosen responses (SFT-Chosen), SFT on rejected responses (SFT-Rejected), DPO, and SFT on chosen responses with short-to-long constraint (SFT-Chosen-Constraint).

🔼 This figure shows the prompt used to instruct a large language model (LLM) to generate a pool of instructions for creating short-to-long preference data. The prompt guides the LLM to produce diverse, comprehensive questions that test a reader’s comprehension, analytical abilities, and the capacity to interconnect key themes across a document. These questions are designed to facilitate the creation of high-quality preference pairs by ensuring that each short-to-long comparison is meaningful and covers a broad range of the document’s content.
read the caption
Figure 5: The prompt for generating instruction pool.

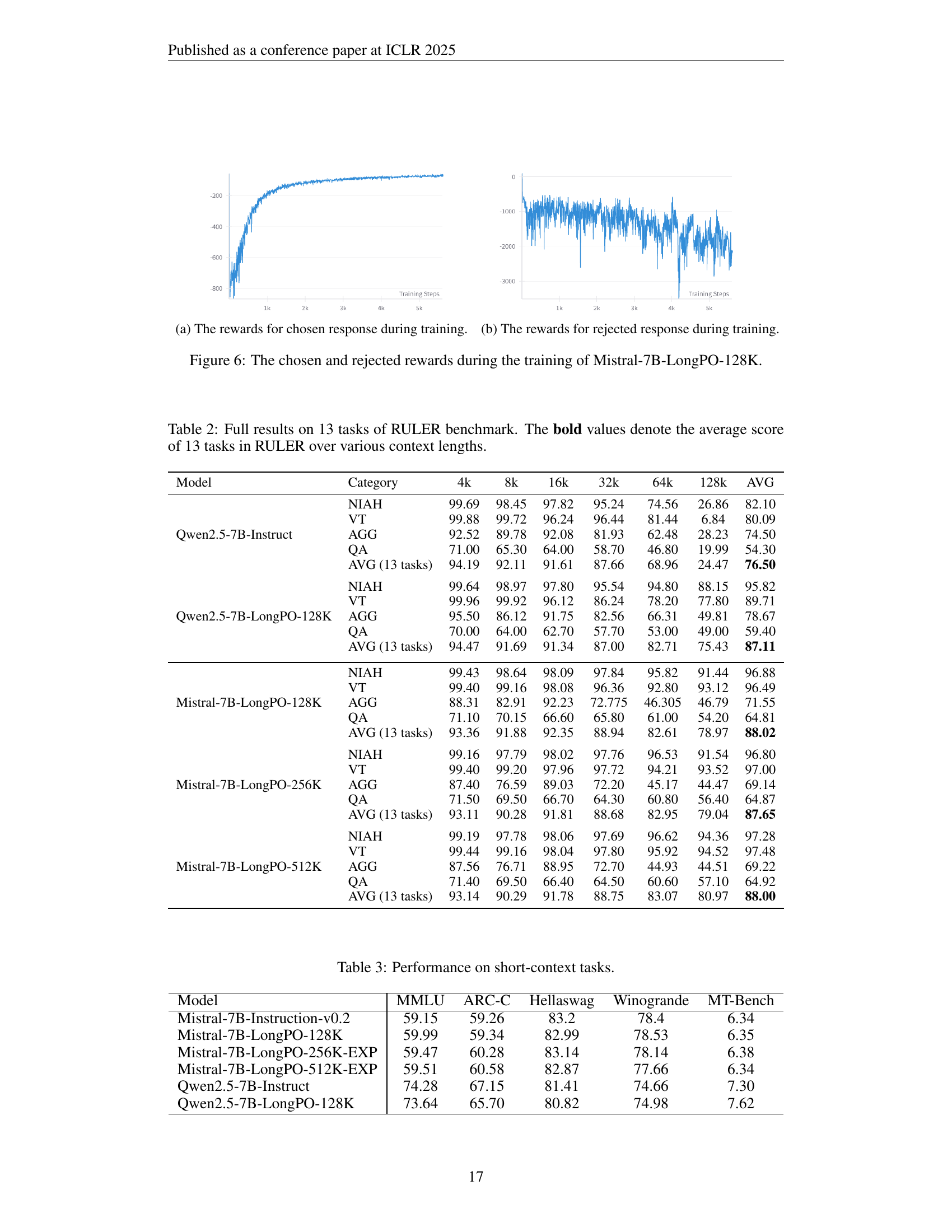
🔼 This figure shows the reward trend for chosen responses during the training process of Mistral-7B-LongPO-128K. The reward, reflecting the model’s performance on selecting preferred responses, initially fluctuates before increasing steadily. This suggests the model effectively learns from the short-to-long preferences, improving its long-context capabilities over time.
read the caption
(a) The rewards for chosen response during training.

🔼 This figure shows the reward values for rejected responses during the training process of the Mistral-7B-LongPO-128K model. The rewards reflect the model’s preference for the chosen response over the rejected response as training progresses. Negative reward values indicate that the model prefers the chosen response. Observing the trend in the rewards for rejected responses can help assess the model’s alignment with the intended preferences and reveal if the model is learning to generate better long-context responses over the course of training.
read the caption
(b) The rewards for rejected response during training.
More on tables
| Model | Category | 4k | 8k | 16k | 32k | 64k | 128k | AVG |
| Qwen2.5-7B-Instruct | NIAH | 99.69 | 98.45 | 97.82 | 95.24 | 74.56 | 26.86 | 82.10 |
| VT | 99.88 | 99.72 | 96.24 | 96.44 | 81.44 | 6.84 | 80.09 | |
| AGG | 92.52 | 89.78 | 92.08 | 81.93 | 62.48 | 28.23 | 74.50 | |
| QA | 71.00 | 65.30 | 64.00 | 58.70 | 46.80 | 19.99 | 54.30 | |
| AVG (13 tasks) | 94.19 | 92.11 | 91.61 | 87.66 | 68.96 | 24.47 | 76.50 | |
| Qwen2.5-7B-LongPO-128K | NIAH | 99.64 | 98.97 | 97.80 | 95.54 | 94.80 | 88.15 | 95.82 |
| VT | 99.96 | 99.92 | 96.12 | 86.24 | 78.20 | 77.80 | 89.71 | |
| AGG | 95.50 | 86.12 | 91.75 | 82.56 | 66.31 | 49.81 | 78.67 | |
| QA | 70.00 | 64.00 | 62.70 | 57.70 | 53.00 | 49.00 | 59.40 | |
| AVG (13 tasks) | 94.47 | 91.69 | 91.34 | 87.00 | 82.71 | 75.43 | 87.11 | |
| Mistral-7B-LongPO-128K | NIAH | 99.43 | 98.64 | 98.09 | 97.84 | 95.82 | 91.44 | 96.88 |
| VT | 99.40 | 99.16 | 98.08 | 96.36 | 92.80 | 93.12 | 96.49 | |
| AGG | 88.31 | 82.91 | 92.23 | 72.775 | 46.305 | 46.79 | 71.55 | |
| QA | 71.10 | 70.15 | 66.60 | 65.80 | 61.00 | 54.20 | 64.81 | |
| AVG (13 tasks) | 93.36 | 91.88 | 92.35 | 88.94 | 82.61 | 78.97 | 88.02 | |
| Mistral-7B-LongPO-256K | NIAH | 99.16 | 97.79 | 98.02 | 97.76 | 96.53 | 91.54 | 96.80 |
| VT | 99.40 | 99.20 | 97.96 | 97.72 | 94.21 | 93.52 | 97.00 | |
| AGG | 87.40 | 76.59 | 89.03 | 72.20 | 45.17 | 44.47 | 69.14 | |
| QA | 71.50 | 69.50 | 66.70 | 64.30 | 60.80 | 56.40 | 64.87 | |
| AVG (13 tasks) | 93.11 | 90.28 | 91.81 | 88.68 | 82.95 | 79.04 | 87.65 | |
| Mistral-7B-LongPO-512K | NIAH | 99.19 | 97.78 | 98.06 | 97.69 | 96.62 | 94.36 | 97.28 |
| VT | 99.44 | 99.16 | 98.04 | 97.80 | 95.92 | 94.52 | 97.48 | |
| AGG | 87.56 | 76.71 | 88.95 | 72.70 | 44.93 | 44.51 | 69.22 | |
| QA | 71.40 | 69.50 | 66.40 | 64.50 | 60.60 | 57.10 | 64.92 | |
| AVG (13 tasks) | 93.14 | 90.29 | 91.78 | 88.75 | 83.07 | 80.97 | 88.00 |
🔼 This table presents a comprehensive evaluation of different language models on the RULER benchmark, a challenging test focusing on various long-context reasoning tasks. It breaks down the performance of each model across 13 sub-tasks within RULER, categorized by context length (4K, 8K, 16K, 32K, 64K, and 128K tokens). The average performance across all 13 tasks is highlighted in bold for each model and context length, providing a concise summary of the overall capabilities of each model in handling long-context information.
read the caption
Table 2: Full results on 13 tasks of RULER benchmark. The bold values denote the average score of 13 tasks in RULER over various context lengths.
| Model | MMLU | ARC-C | Hellaswag | Winogrande | MT-Bench |
|---|---|---|---|---|---|
| Mistral-7B-Instruction-v0.2 | 59.15 | 59.26 | 83.2 | 78.4 | 6.34 |
| Mistral-7B-LongPO-128K | 59.99 | 59.34 | 82.99 | 78.53 | 6.35 |
| Mistral-7B-LongPO-256K-EXP | 59.47 | 60.28 | 83.14 | 78.14 | 6.38 |
| Mistral-7B-LongPO-512K-EXP | 59.51 | 60.58 | 82.87 | 77.66 | 6.34 |
| Qwen2.5-7B-Instruct | 74.28 | 67.15 | 81.41 | 74.66 | 7.30 |
| Qwen2.5-7B-LongPO-128K | 73.64 | 65.70 | 80.82 | 74.98 | 7.62 |
🔼 This table presents the performance of various models on short-context tasks. It compares the base Mistral-7B-Instruct-v0.2 model against models enhanced with LongPO (at various context lengths) and other baselines (Qwen2.5-7B-Instruct). The performance is measured across several standard benchmarks: MMLU (Mass Multitask Language Understanding), ARC-C (AI2 Reasoning Challenge), HellaSwag (a commonsense reasoning task), Winogrande (a word sense disambiguation task), and MT-Bench (Machine Translation Benchmark). The scores provide a comparative analysis of how these model variations perform in short-context settings and the effect of LongPO.
read the caption
Table 3: Performance on short-context tasks.
Full paper#