TL;DR#
This research addresses the underexplored area of how language models handle facts that change over time. It introduces the concept of Temporal Heads, which are specific attention heads within language models primarily responsible for processing temporal knowledge. Through circuit analysis, the study confirms the presence of these heads across multiple models. Disabling these heads impairs the model’s ability to recall time-specific information.
The paper demonstrates that Temporal Heads are activated by both numeric and textual temporal cues, indicating a deeper encoding of time beyond simple numerical representation. Moreover, the study shows that temporal knowledge can be edited by manipulating the values of these heads. The finding highlights Temporal Heads as key components for encoding and modifying time-sensitive knowledge.
Key Takeaways#
Why does it matter?#
This paper introduces Temporal Heads, a crucial component for LLMs to process time-specific information. This research opens new avenues for enhancing LLMs’ ability to reason about dynamically changing facts, improving their reliability in real-world applications. Findings inspires future works on better temporal aware LLMs.
Visual Insights#

🔼 Figure 1 illustrates the concept of ‘Temporal Heads’ within a neural network model. The figure shows how these specialized attention heads are responsible for processing time-specific information. It demonstrates that these Temporal Heads are present across various temporal knowledge circuits (TKCs) at different time points (Tk). When these Temporal Heads are deactivated (ablated), the model’s ability to correctly identify time-sensitive information is significantly impaired, leading to incorrect outputs, highlighting the importance of these heads for maintaining accurate temporal alignment.
read the caption
Figure 1: Temporal Heads exist within various TKCs at different times Tksubscript𝑇𝑘T_{k}italic_T start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT. Ablating them disrupts the model’s temporal alignment, yielding incorrect objects.
| Category | Knowledge | #Node | #Edge | CRS | |
| Temporal | |||||
| Sports | Nicolas Anelka | 29 | 37 | 74.14 | |
| David Beckham | 43 | 80 | 39.53 | ||
| Presidents | Argentina | 42 | 102 | 60.97 | |
| South Korea | 46 | 110 | 65.55 | ||
| CEO | Hewlett-Packard | 52 | 115 | 53.49 | |
| Chrysler | 51 | 97 | 57.10 | ||
| Defense | United States | 50 | 137 | 48.08 | |
| China | 19 | 19 | 37.62 | ||
| Avg | 42 | 87 | 54.56 | ||
| Time-Invariant | |||||
| CommonSense | Object Superclass | 43 | 56 | 44.47 | |
| Conditional CS | Fruit Inside Color | 76 | 131 | 53.08 | |
| Num in Obj | Geometric Shape | 52 | 118 | 76.09 | |
| Num in Sub | Roman Numerals | 43 | 135 | 95.70 | |
| Avg | 54 | 110 | 67.33 | ||
🔼 This table presents a statistical analysis of knowledge circuits within the Llama2 language model, categorized into temporal and time-invariant types. For temporal knowledge, data from three distinct years (1999, 2004, and 2009) are used to construct circuits, and the table shows the average number of nodes and edges in these circuits, along with their Circuit Reproduction Score (CRS). Time-invariant knowledge is analyzed using similar metrics. The CRS indicates how well a pruned circuit (a simplified subgraph representing a specific computation) reproduces the full model’s behavior. A higher CRS suggests better replication.
read the caption
Table 1: Statistics of temporal knowledge circuits for Llama2, both temporal and time-invariant knowledge. For temporal knowledge, each type of knowledge is reproduced with three selected years: 1999, 2004, and 2009. The numbers of nodes, edges and CRS is the average of each knowledge’s yearly circuits.
In-depth insights#
Temporal Heads#
The research paper introduces ‘Temporal Heads’ as specific attention heads within language models that primarily process temporal knowledge. Through circuit analysis, the paper confirms these heads exist across various models, though their locations vary. These heads are activated by both numeric and textual temporal cues, indicating a broader encoding of time. Disabling these heads degrades the model’s ability to recall time-specific facts, while maintaining general capabilities. Furthermore, adjusting their values enables editing of temporal knowledge. The identification of temporal heads provides valuable insights into how language models encode and utilize time-sensitive information, potentially inspiring future approaches for time-aware model alignment and precise temporal updates.
Circuit Analysis#
Circuit analysis, in the context of this paper, is presented as a crucial method for understanding how language models process and represent knowledge. The analysis treats a transformer network as a directed acyclic graph, where nodes represent components like attention heads and MLP layers, and edges signify the flow of activations. This approach is significant because it allows researchers to decompose the complex computations of a language model into more manageable and interpretable units. By identifying which nodes and edges are most critical for a specific task, such as recalling factual information, we can gain insights into the model’s internal mechanisms for knowledge storage and retrieval. Moreover, the techniques of ablating specific components (e.g., attention heads) and observing the resulting changes in the model’s output are central. This reveals the causal roles of different parts of the network and highlight the specific circuits responsible for various aspects of the model’s behavior.
EAP-IG Pruning#
EAP-IG Pruning seems like a critical step in dissecting the model’s knowledge representation. It helps to identify the most relevant connections for a given task and removes the less important ones. This is an integral process, as directly analyzing the raw model parameters would be extremely difficult. By ablating candidate edges (connections between nodes) and observing the impact on prediction accuracy, EAP-IG identifies the minimal subgraph responsible for eliciting specific knowledge, in this case, related to temporal facts. It is important to note that EAP-IG is extended to make it aware of the time component, making it able to generate circuits dependent of time. The process of ablation and measuring the effect of that is how the pruning is done, retaining only edges with scores exceeding a threshold, ultimately revealing key pathways for encoding and retrieving time-sensitive knowledge.
QA Unaffected#
The concept of “QA Unaffected” within the context of language model analysis refers to maintaining or even improving performance on general question-answering tasks when manipulating specific components responsible for temporal knowledge. The paper’s findings suggest that temporal heads, the identified attention heads crucial for processing time-specific information, can be ablated (removed) or edited without significantly hindering the model’s ability to answer general questions. This implies a degree of specialization and modularity within the model’s architecture, where temporal knowledge is handled by dedicated components while broader knowledge and reasoning capabilities remain intact. In essence, the manipulation does not negatively impact the circuits responsible for general knowledge as these circuits remain functional as they are untouched.
Editing TKC#
Editing Temporal Knowledge Circuits (TKCs) suggests a methodology to directly manipulate a language model’s understanding of time-specific facts. Instead of relying on prompting techniques or external knowledge retrieval, it proposes interventions within the model’s architecture to alter temporal knowledge. The approach potentially involves identifying specific components, likely attention heads, that are responsible for processing temporal information. By modifying the weights or activations of these components, the model’s output for a time-dependent query can be directly influenced. Such editing could involve selectively amplifying the correct temporal associations or suppressing incorrect ones. This level of control offers advantages in correcting errors or biases in the model’s knowledge base, allowing for more targeted interventions than retraining or fine-tuning. It would be crucial to maintain the model’s general capabilities while editing specific temporal facts to avoid unintended side effects on other knowledge domains or reasoning abilities.
More visual insights#
More on figures

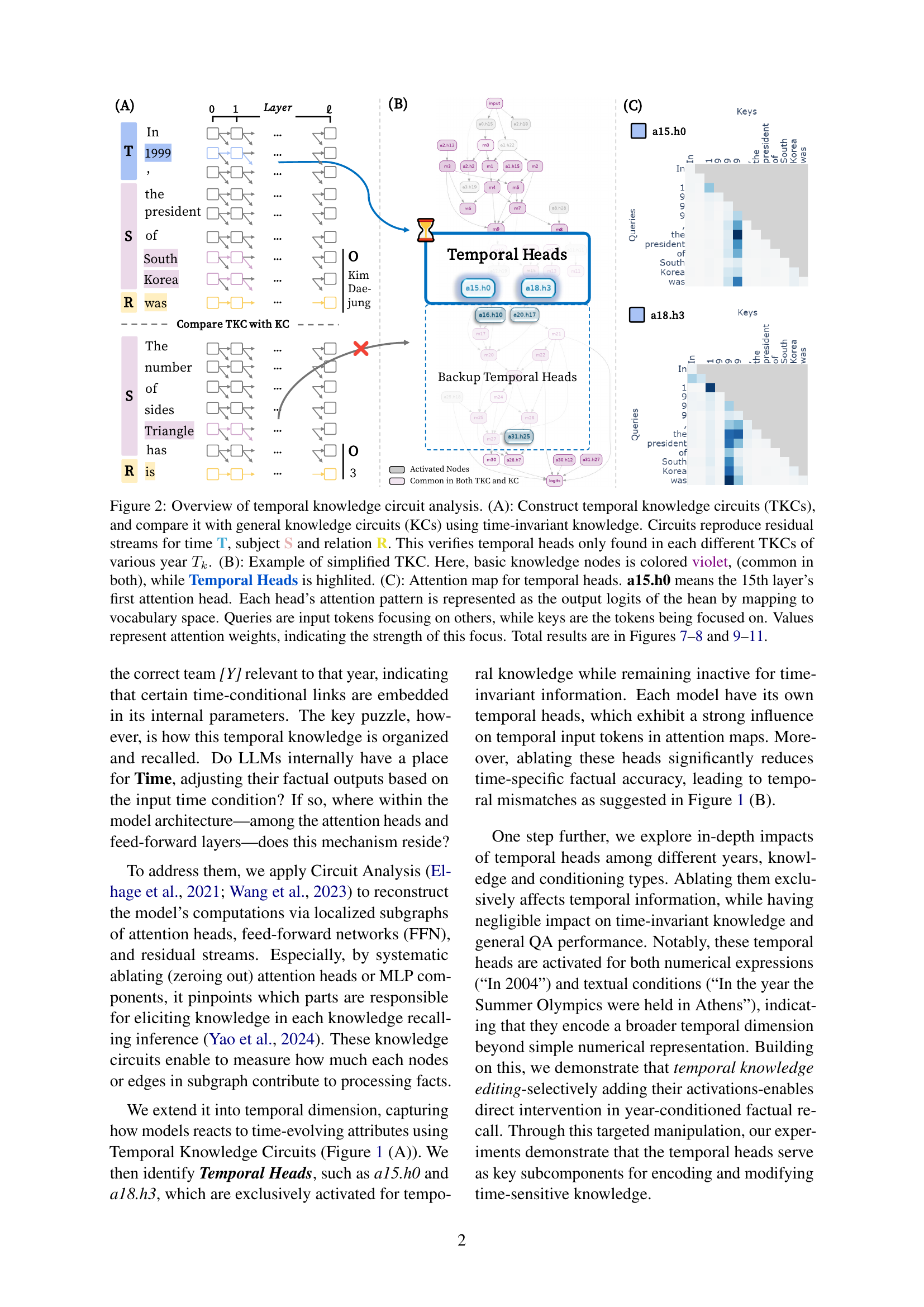
🔼 Figure 2 illustrates the process of temporal knowledge circuit analysis. Panel (A) shows the construction of Temporal Knowledge Circuits (TKCs) for time-specific knowledge and compares them to general Knowledge Circuits (KCs) built using time-invariant knowledge. The circuits trace the flow of information through the model’s layers, focusing on ’time’, ‘subject’, and ‘relation’ elements to identify which parts of the model process temporal information. Panel (B) provides a simplified example of a TKC, highlighting the ‘Temporal Heads’ within the overall circuit. Panel (C) displays the attention maps of these Temporal Heads, showing how their attention weights are distributed across input tokens. Darker colors represent stronger attention, indicating the importance of certain tokens for temporal understanding. The results of this analysis are further detailed in Figures 7-8 and 9-11.
read the caption
Figure 2: Overview of temporal knowledge circuit analysis. (A): Construct temporal knowledge circuits (TKCs), and compare it with general knowledge circuits (KCs) using time-invariant knowledge. Circuits reproduce residual streams for time T, subject S and relation R. This verifies temporal heads only found in each different TKCs of various year Tksubscript𝑇𝑘T_{k}italic_T start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT. (B): Example of simplified TKC. Here, basic knowledge nodes is colored violet, (common in both), while Temporal Heads is highlited. (C): Attention map for temporal heads. a15.h0 means the 15th layer’s first attention head. Each head’s attention pattern is represented as the output logits of the hean by mapping to vocabulary space. Queries are input tokens focusing on others, while keys are the tokens being focused on. Values represent attention weights, indicating the strength of this focus. Total results are in Figures 7–8 and 9–11.

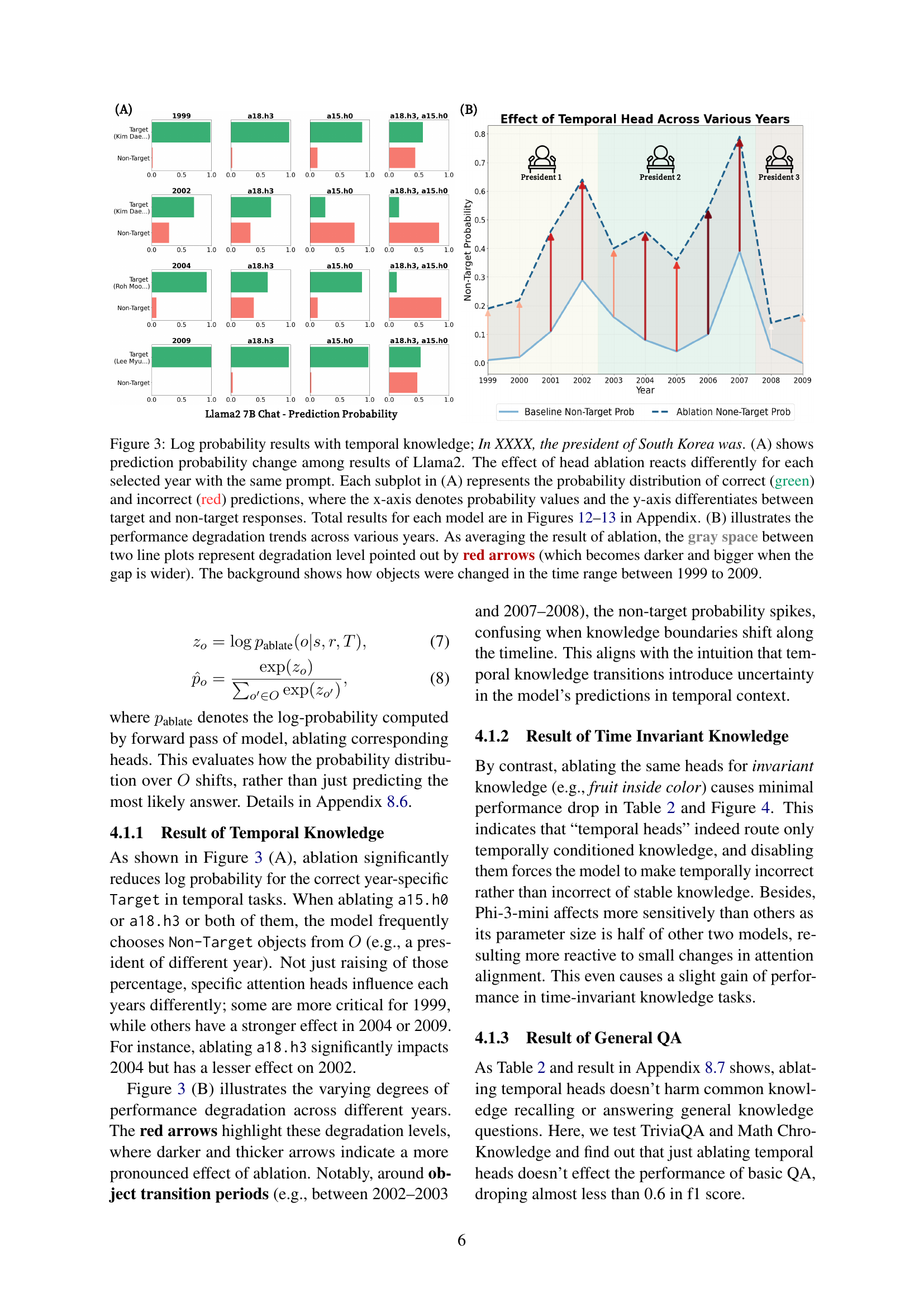
🔼 Figure 3 visualizes the impact of ablating temporal attention heads on the model’s ability to recall time-specific knowledge. Part (A) displays, for each year between 1999 and 2009, the probability distribution of correct (green) versus incorrect (red) predictions when specific heads are ablated. The x-axis shows probability, and the y-axis separates target (correct) from non-target (incorrect) predictions. Different years show varying degrees of sensitivity to ablation. Part (B) provides a summary, showing the average performance degradation across years. The shaded area between the two lines represents the magnitude of the performance drop, which is highlighted by red arrows that increase in size with greater performance loss. The background shows the changes in the president of South Korea over the 1999-2009 period.
read the caption
Figure 3: Log probability results with temporal knowledge; In XXXX, the president of South Korea was. (A) shows prediction probability change among results of Llama2. The effect of head ablation reacts differently for each selected year with the same prompt. Each subplot in (A) represents the probability distribution of correct (green) and incorrect (red) predictions, where the x-axis denotes probability values and the y-axis differentiates between target and non-target responses. Total results for each model are in Figures 12–13 in Appendix. (B) illustrates the performance degradation trends across various years. As averaging the result of ablation, the gray space between two line plots represent degradation level pointed out by red arrows (which becomes darker and bigger when the gap is wider). The background shows how objects were changed in the time range between 1999 to 2009.

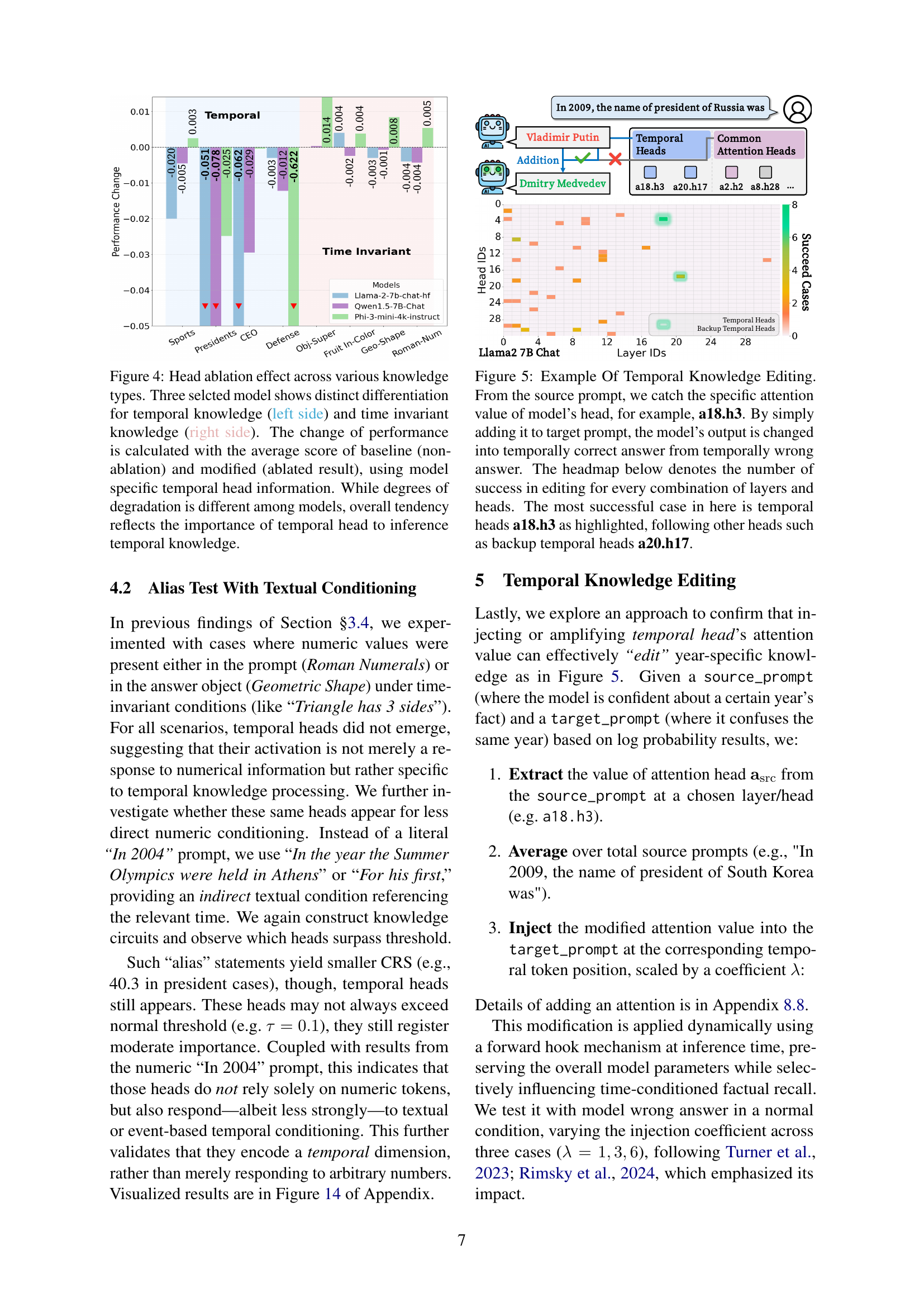
🔼 This figure displays the results of ablating temporal heads in three different large language models (LLMs) on various knowledge tasks. The left side shows the performance on tasks involving temporal knowledge (knowledge that changes over time), while the right side shows performance on time-invariant knowledge (knowledge that doesn’t change over time). Ablation refers to setting the weights of the temporal heads to zero, effectively removing their contribution to the model’s processing. The graph compares the baseline performance (before ablation) to the performance after ablating the temporal heads. Each bar represents the performance change (average score) for specific categories of temporal or time-invariant knowledge. The results illustrate that although the magnitude of performance degradation varies across models, the overall trend consistently indicates the crucial role of temporal heads in processing and reasoning about time-dependent information.
read the caption
Figure 4: Head ablation effect across various knowledge types. Three selcted model shows distinct differentiation for temporal knowledge (left side) and time invariant knowledge (right side). The change of performance is calculated with the average score of baseline (non-ablation) and modified (ablated result), using model specific temporal head information. While degrees of degradation is different among models, overall tendency reflects the importance of temporal head to inference temporal knowledge.
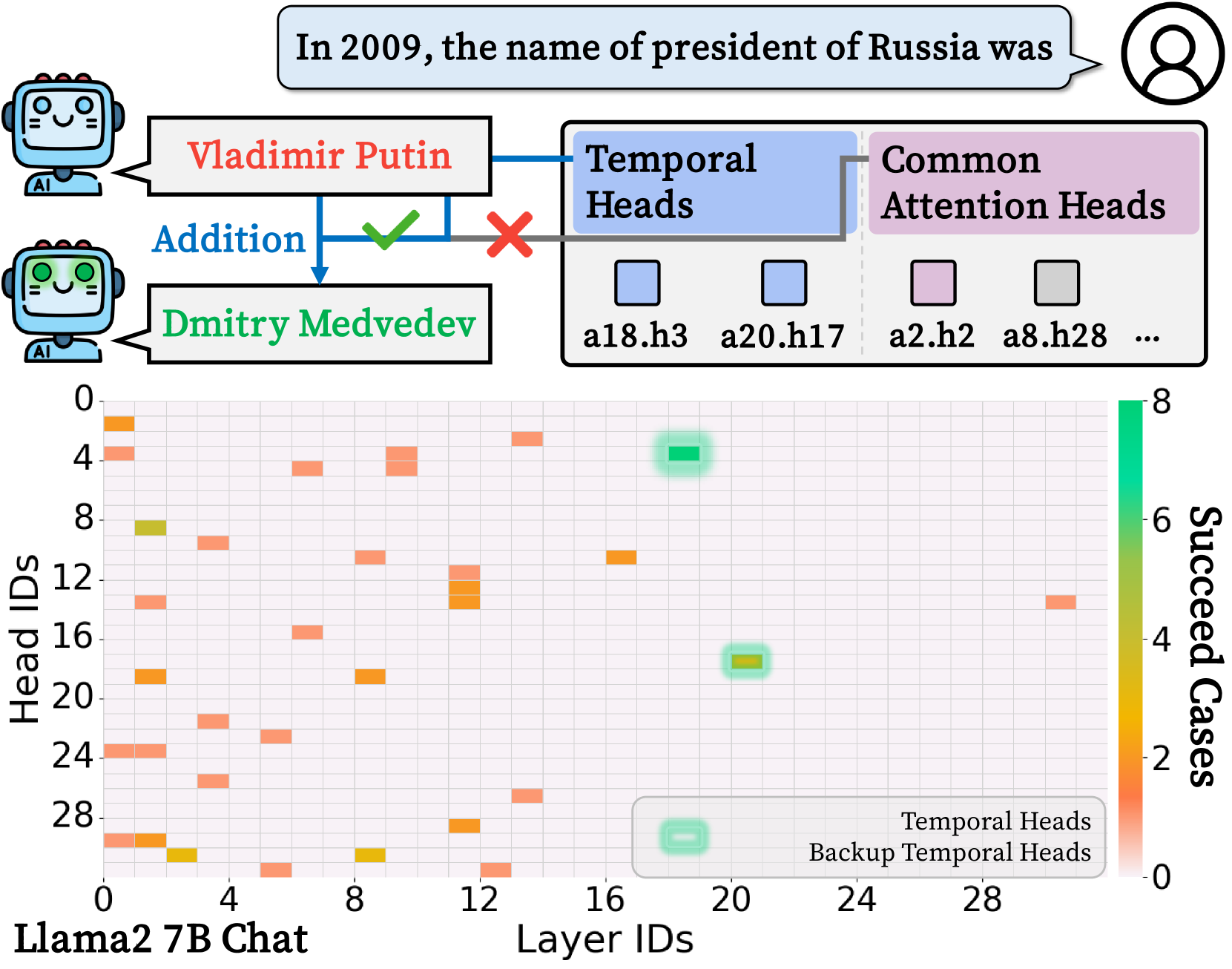
🔼 This figure demonstrates the concept of temporal knowledge editing. The researchers identified specific attention heads within a language model (LLM) that are primarily responsible for processing time-sensitive information. These heads are referred to as ‘Temporal Heads.’ By manipulating the activation values of these Temporal Heads (specifically head a18.h3 in this example), the researchers can change the model’s output for temporally-dependent facts, correcting inaccurate responses without retraining the entire model. The heatmap visually displays the success rate of this editing process across different layers and attention heads within the LLM, showing that a18.h3 and other heads like a20.h17 are the most effective for this task. This technique proves the existence of specialized components within LLMs for handling temporal knowledge.
read the caption
Figure 5: Example Of Temporal Knowledge Editing. From the source prompt, we catch the specific attention value of model’s head, for example, a18.h3. By simply adding it to target prompt, the model’s output is changed into temporally correct answer from temporally wrong answer. The headmap below denotes the number of success in editing for every combination of layers and heads. The most successful case in here is temporal heads a18.h3 as highlighted, following other heads such as backup temporal heads a20.h17.

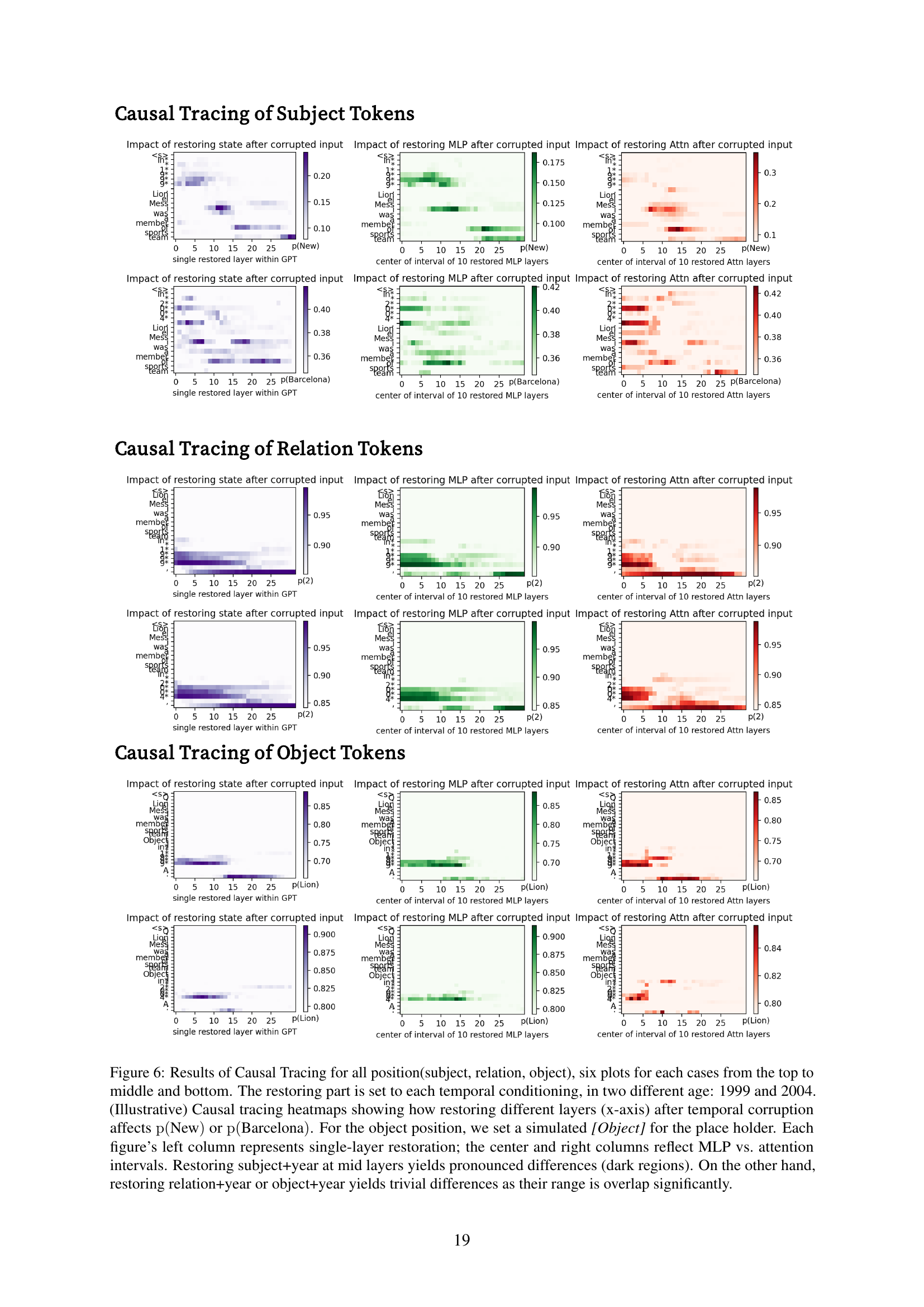
🔼 Figure 6 presents the results of causal tracing experiments, which aim to pinpoint which parts of a language model are responsible for accurate recall of time-specific information. The experiments focus on three different parts of a knowledge triplet: subject, relation, and object. Heatmaps visualize the impact of restoring different layers (or groups of layers) of the model after introducing temporal corruption (incorrect year information). Each row shows results for a particular layer type (single layers, MLP intervals, and attention intervals). The results indicate that restoring subject and year information in middle layers strongly affects prediction accuracy, producing noticeable differences in the heatmaps. In contrast, restoring relation or object information with the incorrect year results in minimal changes in accuracy, showing a much weaker connection to the temporal aspect.
read the caption
Figure 6: Results of Causal Tracing for all position(subject, relation, object), six plots for each cases from the top to middle and bottom. The restoring part is set to each temporal conditioning, in two different age: 1999 and 2004. (Illustrative) Causal tracing heatmaps showing how restoring different layers (x-axis) after temporal corruption affects p(New)pNew\mathrm{p}(\text{New})roman_p ( New ) or p(Barcelona)pBarcelona\mathrm{p}(\text{Barcelona})roman_p ( Barcelona ). For the object position, we set a simulated [Object] for the place holder. Each figure’s left column represents single-layer restoration; the center and right columns reflect MLP vs. attention intervals. Restoring subject+year at mid layers yields pronounced differences (dark regions). On the other hand, restoring relation+year or object+year yields trivial differences as their range is overlap significantly.

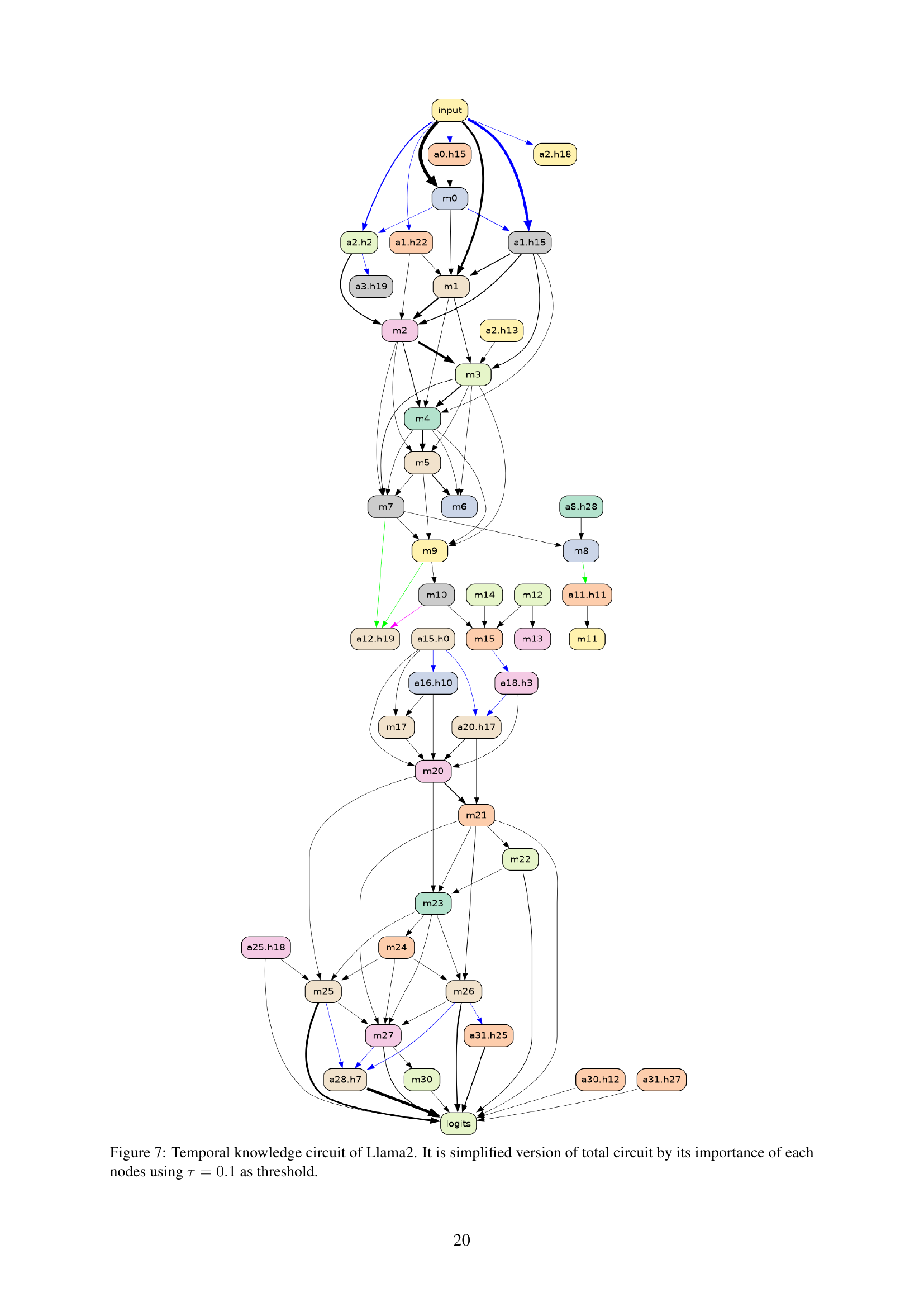
🔼 This figure shows a simplified version of the Llama2 model’s knowledge circuit, focusing specifically on the parts involved in retrieving temporal knowledge. The circuit is a directed acyclic graph (DAG) where nodes represent components of the model (attention heads, MLP modules, etc.) and edges show the flow of information. The simplification was achieved using circuit analysis with a threshold (τ = 0.1) to filter out less important nodes and edges, leaving only those that significantly contribute to retrieving temporal information. The color-coding of nodes likely indicates different functional components in the processing of time-related information.
read the caption
Figure 7: Temporal knowledge circuit of Llama2. It is simplified version of total circuit by its importance of each nodes using τ=0.1𝜏0.1\tau=0.1italic_τ = 0.1 as threshold.

🔼 This figure shows the temporal knowledge circuits for the Qwen-1.5 7B Chat and Phi-3 mini 4K Instruct models. These circuits illustrate the pathways within the models that are specifically activated when processing information that changes over time. The circuits are simplified versions of the complete models, retaining only the nodes and edges deemed most crucial for handling temporal information, as determined by a threshold of 0.1. This simplification makes it easier to visualize the key components involved in processing time-dependent knowledge. The circuits are generated using circuit analysis, which pinpoints which model components are responsible for processing specific knowledge tasks. Different colors and shapes represent different model components (such as attention heads, MLP layers, and input/output nodes). The detailed connections within each circuit reveal how information flows through the model when it processes time-sensitive data.
read the caption
Figure 8: Temporal knowledge circuit of Qwen 1.5 and Phi 3 mini. Those are simplified version of total circuit according to each nodes and edges’ importance of using same τ=0.1𝜏0.1\tau=0.1italic_τ = 0.1 as threshold.

🔼 This figure displays the attention maps for both Temporal Heads and Backup Temporal Heads in the Llama2-7b-chat-hf language model. The attention maps visualize how strongly each head attends to different input tokens. The left half shows the attention patterns of the primary Temporal Heads, while the right half displays the attention patterns of the Backup Temporal Heads. The color intensity in each cell indicates the strength of attention; brighter colors signify stronger attention. This visualization helps to understand how these specific heads process temporal information within the model architecture during inference.
read the caption
Figure 9: Total map of attention with Llama2-7b-chat-hf, for each temporal heads and backup temporal heads. The left side of border line is the attention map of Temporal Heads, and the other side is the result of Backup Temporal Heads.

🔼 This figure visualizes the attention weights of Qwen-1.5-7B-Chat’s attention heads, specifically focusing on those identified as ‘Temporal Heads’ and ‘Backup Temporal Heads’. The attention maps show which tokens the model focuses on when processing time-sensitive information. The left half displays the attention patterns for the primary ‘Temporal Heads’, highlighting their attention to temporal cues in the input text. The right half shows the attention patterns for the ‘Backup Temporal Heads’, which are activated when the primary ‘Temporal Heads’ are unavailable or insufficient. The differences between the two maps illustrate the model’s internal mechanisms for handling temporal information, showing the different roles of the primary and backup temporal heads.
read the caption
Figure 10: Total map of attention with Qwen1.5-7B-Chat, for each temporal heads and backup temporal heads. The left side of border line is the attention map of Temporal Heads, and the other side is the result of Backup Temporal Heads.

🔼 This figure visualizes the attention maps of both Temporal Heads and Backup Temporal Heads within the Phi-3-mini-4k-instruct language model. The attention mechanism is crucial for understanding how the model processes information; it shows which parts of the input the model focuses on when making predictions. The visualization is divided into two parts by a border line. The left side displays the attention patterns of the Temporal Heads, which are specifically responsible for processing time-related information. The right side shows the attention patterns of the Backup Temporal Heads, which act as a sort of backup or secondary mechanism that activates when the primary Temporal Heads are unable to fully process temporal information.
read the caption
Figure 11: Total map of attention with Phi-3-mini-4k-instruct, for each temporal heads and backup temporal heads. The left side of border line is the attention map of Temporal Heads, and the other side is the result of Backup Temporal Heads.

🔼 This figure visualizes the results of head ablation inference experiments conducted on the Llama2-7b-chat-hf language model. It shows the impact of ablating specific attention heads on the model’s ability to predict the correct answer for questions with temporal contexts. For each year (1999-2009), and for three different ablations (one head, the other head, and both heads ablated), the figure displays the log probabilities of both the correct answer (Target) and incorrect answers (Non-Target). The visualization helps to understand the relative importance of specific attention heads in processing temporal information and how their removal affects the model’s accuracy over time.
read the caption
Figure 12: Total results of Llama2-7b-chat-hf, head ablation inference with log probability.
More on tables
| THs | Settings | Temporal (%) | Invariant (%) | QA (F1) |
|---|---|---|---|---|
| Llama-2-7b-chat-hf | ||||
| a18.h3, a15.h0 | Baseline | 29.7 | 61.8 | 55.4 |
| Ablation | 25.6 | 61.7 | 54.9 | |
| Qwen1.5-7B-Chat | ||||
| a17.h15 | Baseline | 22.4 | 62.7 | 49.7 |
| Ablation | 19.8 | 62.6 | 49.5 | |
| Phi-3-mini-4k-instruct | ||||
| a10.h13 | Baseline | 35.4 | 59.8 | 46.8 |
| Ablation | 26.0 | 60.6 | 46.2 | |
🔼 This table presents a comparison of the performance of three different Large Language Models (LLMs) when specific attention heads, termed ‘Temporal Heads,’ are ablated. The Temporal Heads are hypothesized to be crucial for processing time-sensitive information. The table shows the performance of each LLM across three types of tasks: temporal knowledge questions (requiring time-specific information), time-invariant knowledge questions (not requiring time-specific information), and TriviaQA (a general question answering benchmark). For each task and LLM, performance is evaluated under two conditions: baseline (with Temporal Heads intact) and ablation (with Temporal Heads removed). Performance is measured as probability or F1 score, reflecting the accuracy of the LLM’s responses. The results reveal that removing Temporal Heads significantly impairs performance on temporal knowledge tasks (a 3-9% drop), while performance on time-invariant knowledge and TriviaQA tasks remains relatively stable or even slightly improves in some cases. This suggests that these heads play a specialized role in handling temporal information.
read the caption
Table 2: Temporal Heads (THs) across different LLMs. The scores besides each heads are evaluated in three cases (temporal knowledge, time-invariant knowledge, and TriviaQA) with two settings (baseline inference and ablation inference). Scores are checked with the average performance for each tasks, measured in probability (%) or f1 score. While performance in temporal knowledge drops significantly (3 to 9%), time-invariant and general QA remain relatively stable or even goes up.
| Category | Knowledge | #Node | #Edge | CRS | |
| Temporal | |||||
| Sports | Nicolas Anelka | 27 | 26 | 88.81 | |
| David Beckham | 42 | 59 | 26.50 | ||
| Presidents | Argentina | 38 | 64 | 43.99 | |
| South Korea | 51 | 104 | 53.18 | ||
| CEO | Hewlett-Packard | 31 | 34 | 40.36 | |
| Chrysler | 26 | 22 | 28.14 | ||
| Defense | United States | 8 | 5 | 25.60 | |
| China | 13 | 9 | 25.82 | ||
| Avg | 30 | 40 | 41.44 | ||
| Time-Invariant | |||||
| CommonSense | Object Superclass | 72 | 127 | 42.61 | |
| Conditional CS | Fruit Inside Color | 43 | 49 | 64.83 | |
| Num in Obj | Geometric Shape | 60 | 127 | 62.94 | |
| Num in Sub | Roman Numerals | 57 | 108 | 71.18 | |
| Avg | 58 | 103 | 60.39 | ||
🔼 This table presents a quantitative analysis of knowledge circuits within the Qwen 1.5 large language model (LLM). It breaks down the structure of these circuits, specifically focusing on those related to temporal (time-varying) and time-invariant (static) knowledge. For temporal knowledge, the analysis is conducted across three specific years (1999, 2004, and 2009), averaging the results for each knowledge type within each year. The key metrics provided are the number of nodes and edges in each circuit, and the Circuit Reproduction Score (CRS). The CRS value indicates how well a simplified circuit reproduces the behavior of the complete model, with a higher score indicating better reproduction. A threshold of τ=0.1 was used to simplify the circuits, which is consistent with the approach used for Llama2 analysis in the paper.
read the caption
Table 3: Statistics of temporal knowledge circuits for Qwen 1.5, both temporal and time-invariant knowledge. For temporal knowledge, each type of knowledge is reproduced with three selected years: 1999, 2004, and 2009. The numbers of nodes, edges and CRS is the average of each knowledge’s yearly circuits. We simplified total circuits with τ=0.1𝜏0.1\tau=0.1italic_τ = 0.1, same as Llama2.
| Category | Knowledge | #Node | #Edge | CRS | |
| Temporal | |||||
| Sports | Nicolas Anelka | 5 | 3 | 64.51 | |
| David Beckham | 22 | 22 | 42.24 | ||
| Presidents | Argentina | 53 | 127 | 91.19 | |
| South Korea | 55 | 142 | 81.47 | ||
| CEO | Hewlett-Packard | 12 | 9 | 35.55 | |
| Chrysler | 9 | 7 | 73.98 | ||
| Defense | United States* | 3 | 1 | 73.03 | |
| China* | 2 | 1 | 72.85 | ||
| Avg | 20 | 39 | 66.85 | ||
| Time-Invariant | |||||
| CommonSense | Object Superclass | 73 | 135 | 61.49 | |
| Conditional CS | Fruit Inside Color | 24 | 44 | 49.48 | |
| Num in Obj | Geometric Shape | 16 | 20 | 39.98 | |
| Num in Sub | Roman Numerals | 78 | 153 | 74.04 | |
| Avg | 48 | 88 | 56.25 | ||
🔼 This table presents a quantitative analysis of knowledge circuits within the Phi-3 mini language model. It compares the model’s performance in representing both temporal (time-varying) and time-invariant knowledge using a metric called the Circuit Reproduction Score (CRS). For temporal knowledge, the analysis is performed on data spanning three years: 1999, 2004, and 2009, with the CRS, number of nodes, and number of edges averaged across the three years. A notable observation is that the model’s performance (CRS) on temporal knowledge was higher than its performance on time-invariant knowledge. The table also indicates that the circuits for temporal knowledge were smaller (fewer nodes and edges) than those for time-invariant knowledge. The threshold for determining significant circuit components (τ) was set to 0.1, with an exception made for the ‘Defense’ category, where a lower threshold was used. This adjustment reflects the need for more strict criteria in evaluating knowledge circuits within this particular category.
read the caption
Table 4: Statistics of temporal knowledge circuits for Phi 3 mini, both temporal and time-invariant knowledge. For temporal knowledge, each type of knowledge is reproduced with three selected years: 1999, 2004, and 2009. The numbers of nodes, edges and CRS is the average of each knowledge’s yearly circuits. We simplified total circuits with τ=0.1𝜏0.1\tau=0.1italic_τ = 0.1, same as Llama2, except knowledge in Defense where at least 30% lower τ𝜏\tauitalic_τ is needed. Interestingly, Phi 3 mini shows better CRS of temporal knowledge than time-invariant ones, though their overall simplified nodes and edges are less than same cases of other models.
| Category | Time Range | # of Cases |
| Temporal Knowledge (Vrandečić and Krötzsch, 2014) | ||
| Sports | 1996-2020 | 81 |
| Presidents | 1999-2009 | 65 |
| CEO | 1999-2009 | 65 |
| Defense | 1999-2009 | 77 |
| Movies | 1999-2009 | 33 |
| GDP | 1999-2009 | 33 |
| Inflations | 1999-2009 | 33 |
| Time Invariant Knowledge (Hernandez et al., 2024) | ||
| Object Superclass | - | 36 |
| Fruit Inside Color | - | 76 |
| Geometric Shape | - | 28 |
| Roman Numerals | - | 31 |
🔼 This table presents a detailed breakdown of the datasets utilized for constructing and analyzing knowledge circuits within the study. It categorizes the data into ‘Temporal Knowledge’ and ‘Time-Invariant Knowledge’, providing the time range covered and the number of data points for each category. The temporal knowledge section further subdivides the data into specific types, such as sports, presidents, CEOs, defense budgets, movies, GDP, and inflation rates, with each type specifying a time range and the associated number of cases. The Time-Invariant Knowledge section covers categories such as object superclasses, fruit inside color, geometric shapes, and Roman numerals, also including the number of cases for each.
read the caption
Table 5: Statistics of dataset used for circuits.
| Dataset | Format | Test | Source |
|---|---|---|---|
| TriviaQA | MCQA | 11,313 | Joshi et al.,2017 |
| Math ChroKnowledge | MCQA | 2,585 | Wang,2022; Park et al.,2025 |
🔼 This table presents statistics for the datasets used in the general question answering (QA) portion of the study. It shows the dataset name, the format of the questions (Multiple Choice QA or MCQA), the number of test instances in each dataset, and the source or reference for each dataset.
read the caption
Table 6: Statistics of dataset used general QA.
| Settings | Temporal Knowledge (%) | Average | ||||||
| Sports | Presidents | CEO | Defense | Movies | GDP | Inflations | ||
| Llama-2-7b-chat-hf - a18,h3, a15.h0 | ||||||||
| Baseline | 41.9 | 80.7 | 27.5 | 13.5 | 23.1 | 10.4 | 10.8 | 29.7 |
| Ablation | 40.0 | 75.6 | 21.3 | 13.3 | 9.37 | 10.7 | 9.34 | 25.6 |
| Qwen1.5-7B-Chat - a17.h15 | ||||||||
| Baseline | 32.4 | 57.2 | 19.6 | 11.5 | 16.7 | 9.58 | 10.0 | 22.4 |
| Ablation | 32.0 | 49.4 | 16.6 | 10.3 | 10.8 | 9.50 | 10.3 | 19.8 |
| Phi-3-mini-4k-instruct - a10.h13 | ||||||||
| Baseline | 24.4 | 72.1 | 30.8 | 73.7 | 21.4 | 12.2 | 13.5 | 35.4 |
| Ablation | 24.8 | 69.6 | 30.7 | 11.5 | 21.6 | 11.7 | 11.8 | 26.0 |
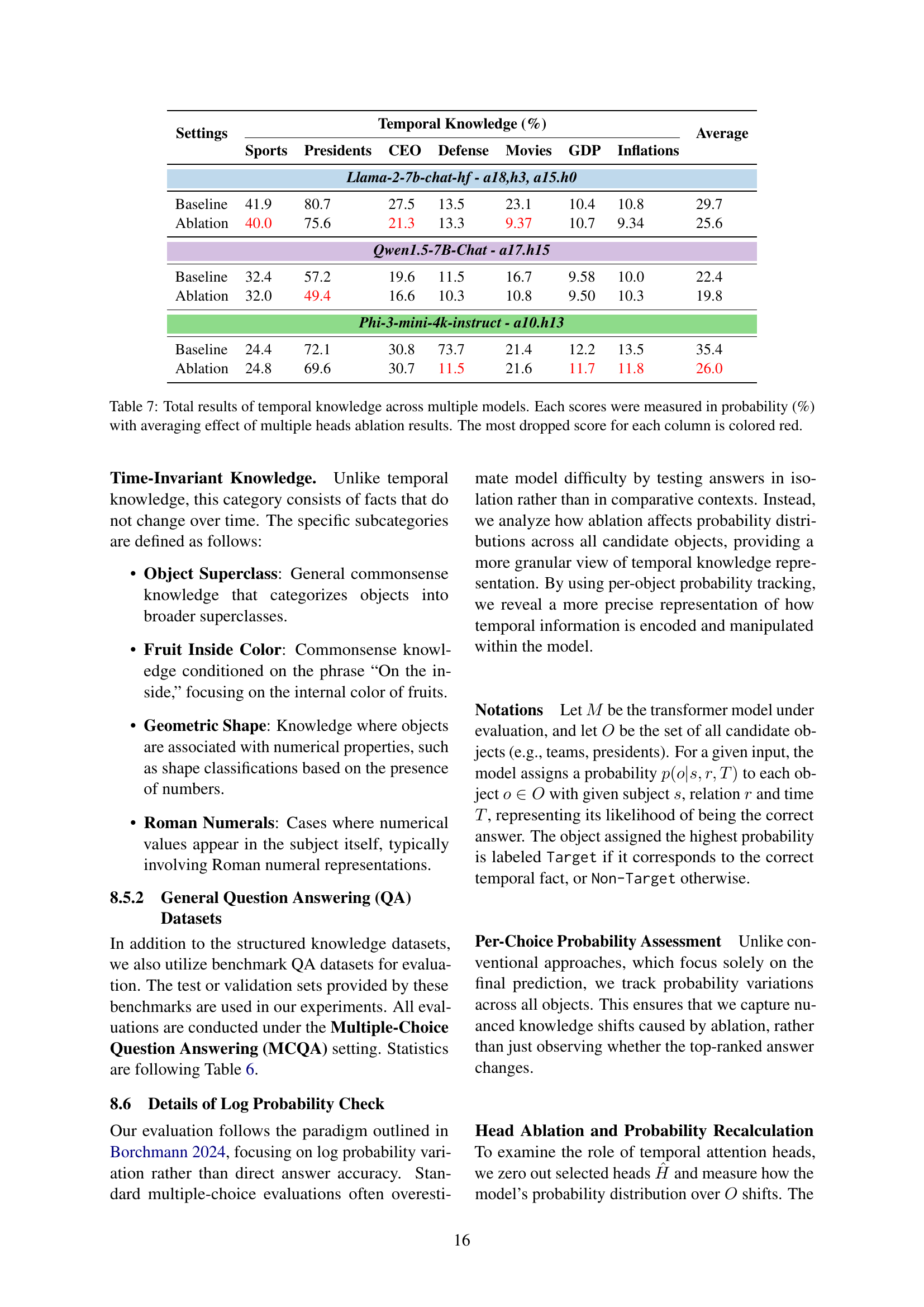
🔼 This table presents the performance of three different large language models (LLMs) on tasks involving temporal knowledge, specifically focusing on the accuracy of their responses to questions requiring time-specific information. The results show the average probability of correct answers across several categories of temporal knowledge (Sports, Presidents, CEO, Defense, Movies, GDP, and Inflation) after ablating (deactivating) specific attention heads within the LLMs. The baseline performance (without ablation) is compared to the performance after ablation, allowing for assessment of the importance of those attention heads in processing temporal information. The lowest probability (most significant performance drop) for each category after ablating the specified heads is highlighted in red.
read the caption
Table 7: Total results of temporal knowledge across multiple models. Each scores were measured in probability (%) with averaging effect of multiple heads ablation results. The most dropped score for each column is colored red.
| Settings | Time Invariant Knowledge (%) | General QA (F1 & %) | |||||
| Obj-Super | Fruit In-Color | Geo-Shape | Roman-Num | Average | TriviaQA | Math | |
| Llama-2-7b-chat-hf - a18,h3, a15.h0 | |||||||
| Baseline | 49.7 | 75.6 | 68.5 | 53.5 | 61.8 | 55.4 | 45.4 |
| Ablation | 50.2 | 75.6 | 68.1 | 53.0 | 61.7 | 54.9 | 45.3 |
| Qwen1.5-7B-Chat - a17.h15 | |||||||
| Baseline | 48.0 | 72.0 | 69.4 | 61.5 | 62.7 | 49.7 | 77.0 |
| Ablation | 47.8 | 72.0 | 69.3 | 61.1 | 62.6 | 49.5 | 77.0 |
| Phi-3-mini-4k-instruct - a10.h13 | |||||||
| Baseline | 21.8 | 76.0 | 68.3 | 73.2 | 59.8 | 46.8 | 80.8 |
| Ablation | 23.2 | 76.4 | 69.1 | 73.7 | 60.6 | 46.2 | 81.2 |
🔼 This table presents the performance of three different large language models (LLMs) on time-invariant knowledge tasks and general question answering (QA) after ablating their temporal attention heads. The results are shown as percentages for time-invariant knowledge tasks (Object Superclass, Fruit Inside Color, Geometric Shape, Roman Numerals) and F1 scores and percentages for TriviaQA (a general QA dataset with 11,313 instances). The scores represent the average performance after ablating multiple temporal heads, showcasing the models’ robustness in the absence of temporal information. Notably, in many cases the performance remains stable or even slightly improves, even without the temporal information provided by the temporal heads.
read the caption
Table 8: Total results of time invariant knowledge and general QA across multiple models. For TriviaQA, we test the unfiltered, no-context validation set (11.3k). Each scores were measured in probability (%) or f1 score with averaging effect of multiple heads ablation results. Most of cases, the scores remain stable or even goes up such as Object Superposition.
Full paper#