TL;DR#
Existing MLLM-based GUI agents often struggle with the complexities of PC environments, which feature denser interactive elements, varied text layouts, and intricate workflows compared to smartphones. Current methods lack fine-grained perception and struggle with interdependent subtasks across multiple applications, hindering their ability to perform real-world instructions effectively. This paper addresses the challenge in GUI agents.
This paper proposes a hierarchical agent framework called PC-Agent to tackle complex tasks on PCs. PC-Agent includes an Active Perception Module (APM) for refined perception and a hierarchical multi-agent collaboration architecture that decomposes decision-making into instruction-subtask-action levels. Additionally, it introduces a reflection-based dynamic decision-making mechanism for error detection and adjustment. A new benchmark, PC-Eval, is introduced. The PC-Agent achieves a 32% improvement in task success rate.
Key Takeaways#
Why does it matter?#
This work introduces PC-Agent, a hierarchical multi-agent framework, and PC-Eval benchmark which is important for the GUI agent research community. It demonstrates a significant advancement in automating complex tasks on PCs, offering a robust solution and benchmark for future research and development.
Visual Insights#
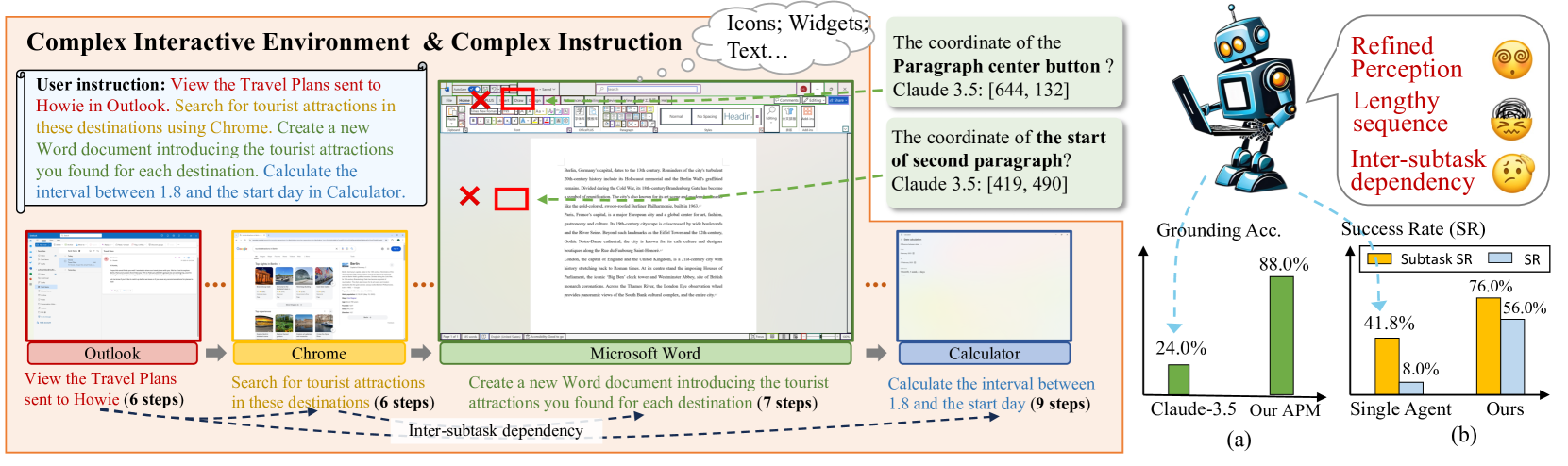
🔼 Figure 1 illustrates the challenges posed by the PC environment for automated task completion, contrasting it with simpler smartphone interfaces. The figure highlights two key aspects: (1) The PC GUI presents a significantly more complex visual landscape, characterized by a high density and variety of interactive elements (icons, widgets, text layouts) compared to the relatively simpler arrangement on smartphones. This density and diversity pose a substantial challenge for accurate screen perception and understanding by AI agents. (2) Tasks on PCs typically involve considerably more complex sequences of operations spanning multiple applications. These sequences are not only longer but also exhibit strong interdependencies between individual subtasks, meaning the successful completion of one step is often crucial to the success of subsequent steps. This high degree of complexity makes automated task completion significantly more challenging than for similar tasks on smartphones.
read the caption
Figure 1: Illustration of the complexity of the PC scenario: (1) Complex interactive environment with dense and diverse elements. (2) Long and complex task sequences containing intra- and inter-software workflows.
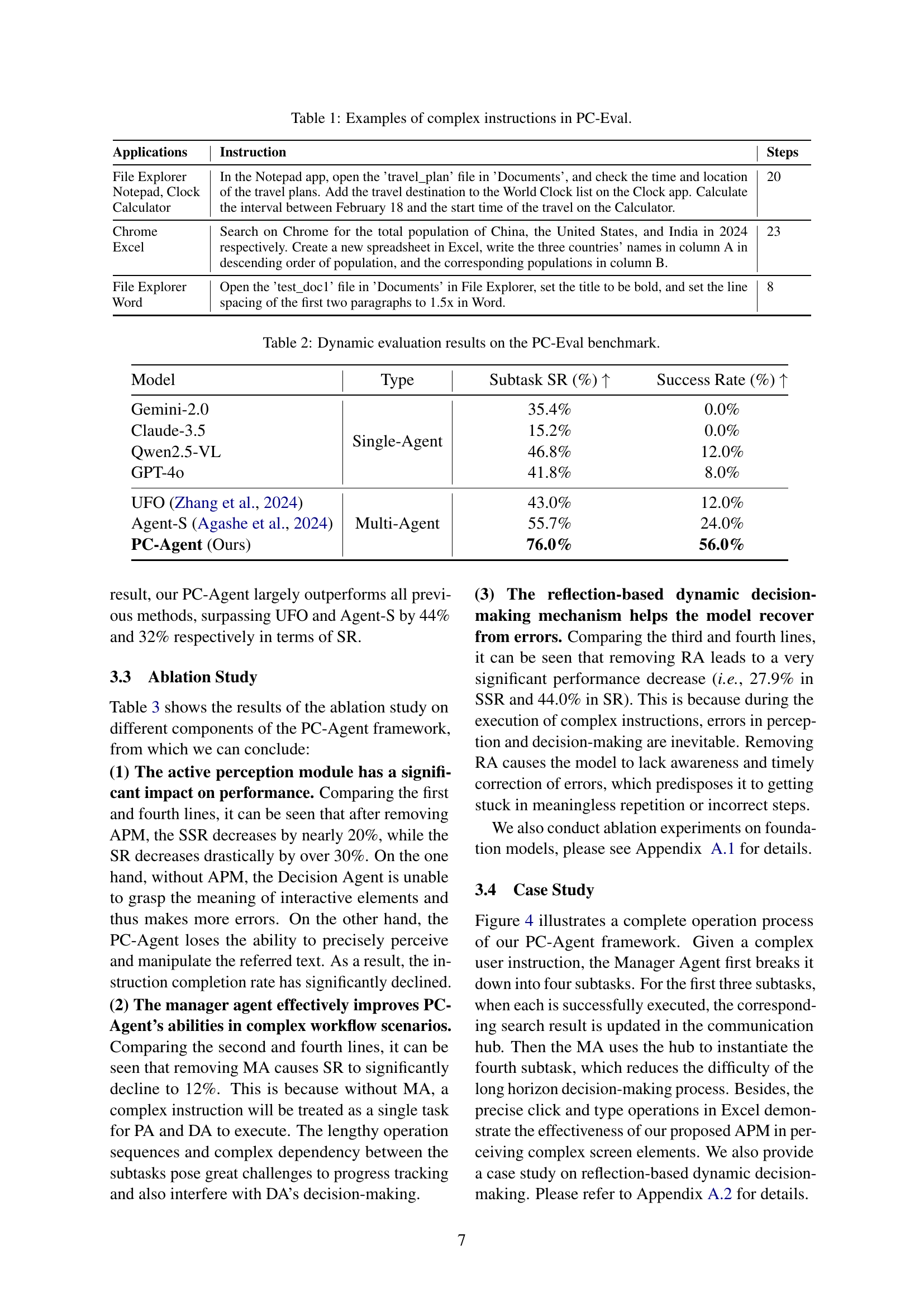
| Applications | Instruction | Steps |
| File Explorer Notepad, Clock Calculator | In the Notepad app, open the ’travel_plan’ file in ’Documents’, and check the time and location of the travel plans. Add the travel destination to the World Clock list on the Clock app. Calculate the interval between February 18 and the start time of the travel on the Calculator. | 20 |
| Chrome Excel | Search on Chrome for the total population of China, the United States, and India in 2024 respectively. Create a new spreadsheet in Excel, write the three countries’ names in column A in descending order of population, and the corresponding populations in column B. | 23 |
| File Explorer Word | Open the ’test_doc1’ file in ’Documents’ in File Explorer, set the title to be bold, and set the line spacing of the first two paragraphs to 1.5x in Word. | 8 |
🔼 This table presents three examples of complex instructions from the PC-Eval benchmark dataset. Each example details the applications involved (File Explorer, Notepad, Clock, Calculator, Chrome, Excel, File Explorer, Word), the specific instruction given to the agent, and the total number of steps required to complete the task. These examples showcase the complexity and length of real-world workflows on a PC, highlighting the challenges faced by AI agents in completing such tasks.
read the caption
Table 1: Examples of complex instructions in PC-Eval.
In-depth insights#
PC-Agent Design#
The PC-Agent design centers around a hierarchical, collaborative architecture to tackle the complexities of PC automation. It addresses the limitations of existing MLLM-based agents in handling intricate GUI environments and multi-step workflows. A key component is the Active Perception Module (APM), enhancing the agent’s ability to perceive and ground elements and text accurately. The design employs a hierarchical multi-agent collaboration approach, dividing decision-making into Instruction, Subtask, and Action levels. This involves a Manager Agent (MA) for instruction decomposition, a Progress Agent (PA) for subtask progress tracking, and a Decision Agent (DA) for step-by-step action. Reflection-based dynamic decision-making is incorporated with a Reflection Agent to detect errors and provide feedback, enabling adjustments. **This comprehensive approach enables the agent to overcome existing limitations.
Active Perception#
Active perception is crucial for intelligent agents operating in complex environments like PCs. It involves more than passive observation; it entails actively gathering information relevant to the task at hand. An active perception module should enable the agent to intelligently select which parts of the screen to focus on, based on the current goal. This might involve prioritizing interactive elements like buttons and input fields, or strategically sampling text to extract key information. The module should dynamically adjust its focus as the task progresses, responding to changes in the environment and the agent’s own understanding of the situation. By actively seeking out information, the agent can overcome the limitations of static screenshots and make more informed decisions. This approach is important as it allows the agent to actively query the environment for information it needs, instead of relying solely on pre-existing data, enabling greater adaptability and robustness.
Hierarchical MAs#
Hierarchical Multi-Agent Systems (HMAS) represent a sophisticated approach to task decomposition and coordination, particularly relevant in complex environments. This involves structuring multiple agents in a hierarchical manner, typically reflecting the organizational structure of the problem itself. The key advantage lies in improved scalability and efficiency, as higher-level agents manage overall goals and delegate subtasks to lower-level agents. Decision-making is distributed, reducing the cognitive load on individual agents and facilitating parallel execution. This hierarchical approach enhances robustness, as local failures are less likely to disrupt the entire system. Communication overhead can be optimized by limiting interactions to within and between adjacent levels of the hierarchy. However, designing an effective HMAS requires careful consideration of the hierarchical structure, task allocation strategies, and communication protocols, which can be challenging. Proper management ensures that the system maintains coherence.
Dynamic Reflection#
Dynamic Reflection in AI agents, particularly in PC automation, is crucial for enhancing reliability and accuracy. It involves the agent’s ability to observe the outcomes of its actions and adjust its strategy based on the observed results. This contrasts with static, pre-programmed routines. A core element is the Reflection Agent (RA), which parallels the Decision Agent (DA). The RA observes state changes before and after DA’s actions to assess goal alignment. This process informs three types of judgments: non-conforming changes, lack of effective response, or successful execution. Incorrect or ineffective outcomes trigger feedback to the DA and PA, prompting error correction or alternative actions, thereby avoiding repetitive mistakes. The RA’s insights refine decision-making and improve overall task completion accuracy.
PC-Eval Details#
PC-Eval, as detailed in this research, is a custom-built benchmark designed to evaluate the performance of GUI agents, specifically in PC environments, addressing limitations of existing datasets. It includes 25 complex instructions spanning eight popular PC applications, emphasizing intricate workflows, refined operations, and extended decision-making. A key aspect is its focus on real-world productivity scenarios with interdependent subtasks, going beyond basic actions. Evaluation relies on success rate (SR), measuring completed instructions, and subtask success rate (SSR) for a thorough agent capability assessment. The benchmark’s design aims to challenge current models with tasks reflecting realistic PC usage, offering a valuable resource for advancing GUI agent research and development. The benchmark fills a crucial gap by presenting difficult PC automation challenges, focusing on long workflows and complex scenarios.
More visual insights#
More on figures

🔼 The figure illustrates the hierarchical structure of PC-Agent, a multi-agent system designed for complex task automation on PCs. It shows how the system decomposes the decision-making process into three levels: instruction, subtask, and action. The orange lines represent the top-down decomposition of a user’s instruction into manageable subtasks, while the purple lines depict the bottom-up feedback mechanism provided by the Reflection Agent, which monitors the execution and provides error correction and adjustment. The figure highlights the collaboration between the Manager Agent, Progress Agent, and Decision Agent at each level to ensure smooth task completion.
read the caption
Figure 2: Overview of the proposed PC-Agent, which decomposes the decision-making process into three levels. The orange lines denote the top-down decision-making decomposition, and the purple lines represent the bottom-up reflection process.

🔼 This figure illustrates the PC-Agent’s Active Perception Module (APM), a key component for handling complex interactive environments on a PC. The APM uses two main approaches for perception: For interactive GUI elements (buttons, menus, etc.), it leverages the accessibility tree (A11y tree) to extract precise bounding boxes and functional descriptions. This allows the agent to accurately locate and interact with these elements. For text-based elements, the APM employs a two-step process. First, an intention understanding agent processes the user’s request to identify the target text. Second, an OCR (Optical Character Recognition) tool is used to precisely locate and extract the identified text from the screen. This dual approach enables accurate text selection and editing operations.
read the caption
Figure 3: Illustration of the active perception module. For interactive elements, the A11y tree is adopted to obtain the bounding boxes and functional information. For text, an intention understanding agent and an OCR tool are utilized to perform precise selecting or editing.

🔼 This figure demonstrates the PC-Agent’s workflow for a complex task involving multiple applications. The user instruction is to find stock prices for Nvidia, Apple, and Microsoft, then create an Excel sheet with this data. The diagram shows the agent breaking this task into subtasks: searching for each stock price on Chrome, and then populating the Excel sheet. The communication hub facilitates passing data between subtasks. The visualization highlights the agent’s ability to handle multi-step, multi-application tasks and demonstrate the process of data exchange between subtasks using a communication hub.
read the caption
Figure 4: A case of searching for information multiple times and build an Excel sheet accordingly.

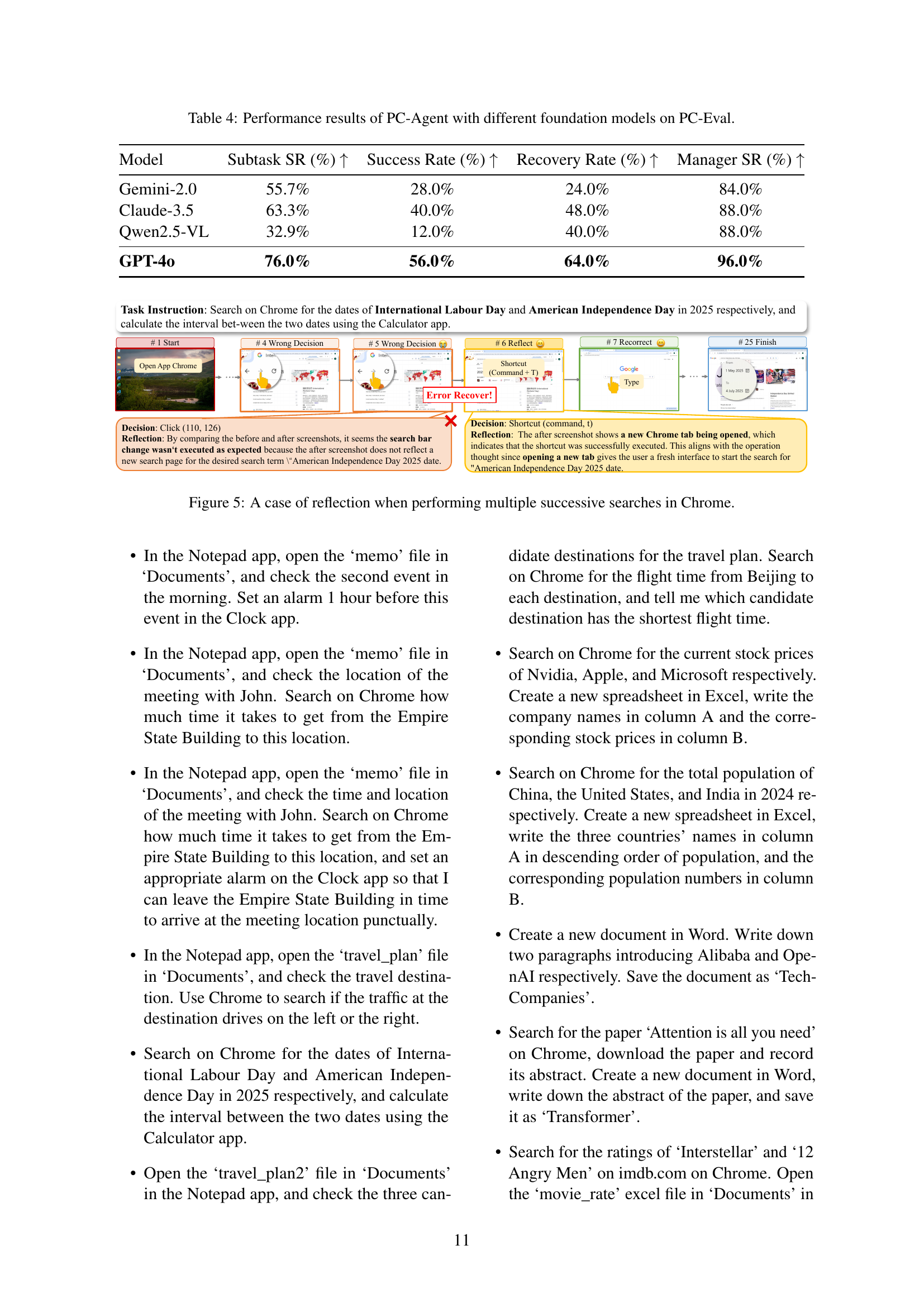
🔼 This figure illustrates the PC-Agent’s reflection mechanism in action. During a multi-step process involving successive searches on Chrome, an error occurs. The Reflection Agent (RA) detects this error by comparing screenshots before and after the action. This feedback is then used to adjust the subsequent actions. The figure visually demonstrates how the system corrects itself by opening a new tab using a shortcut, effectively handling and recovering from an incorrect action that did not produce the expected result.
read the caption
Figure 5: A case of reflection when performing multiple successive searches in Chrome.

🔼 This figure showcases the PC-Agent’s ability to perform precise text manipulations within a Word document. It demonstrates the effectiveness of the Active Perception Module (APM) in identifying and targeting specific text elements for operations such as centering the title and underlining the last paragraph. The detailed steps involved highlight the agent’s capability to handle complex GUI interactions and carry out precise operations that require fine-grained control.
read the caption
Figure 6: A case of refined text editing operations in the Word application.

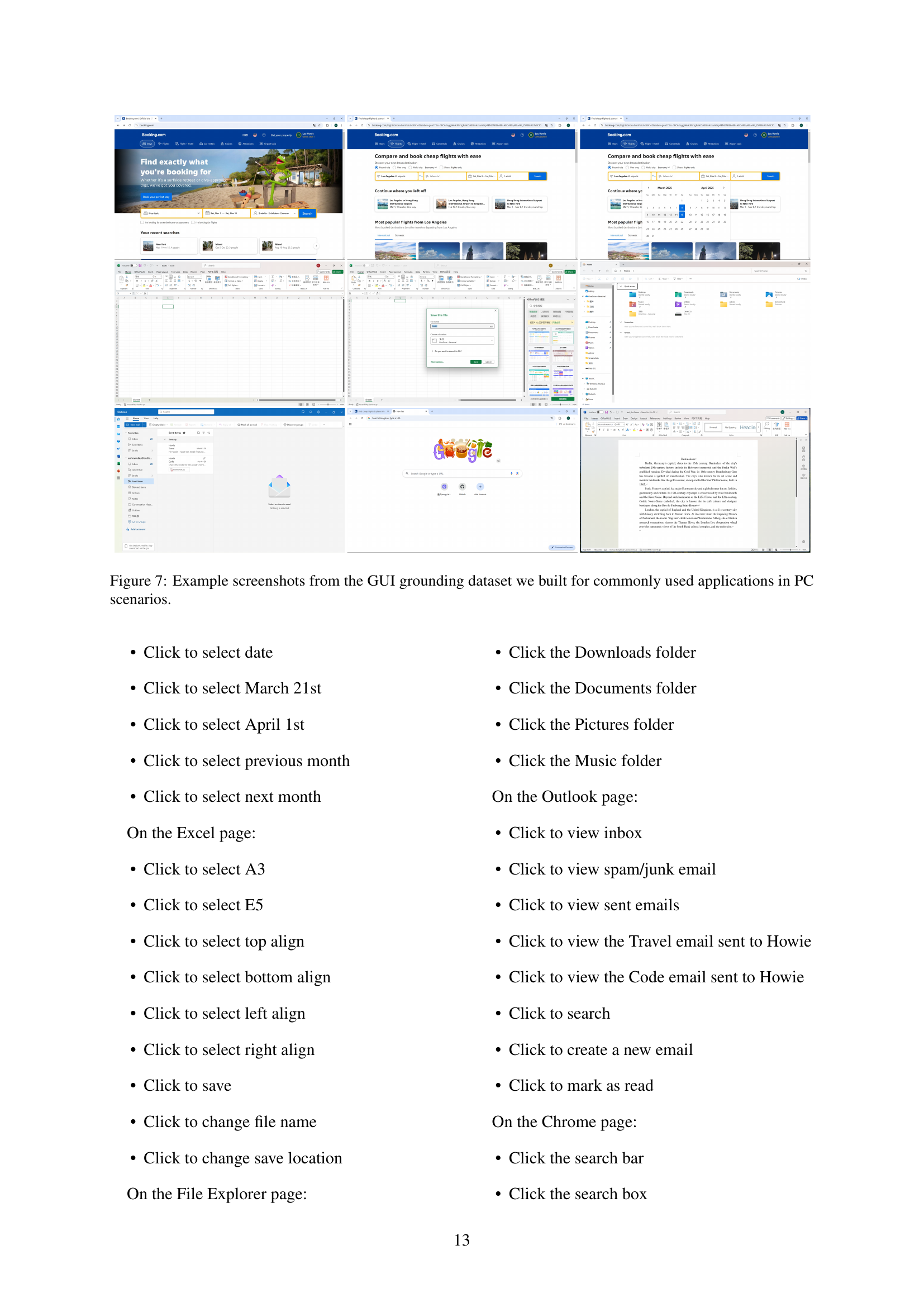
🔼 This figure displays example screenshots from a GUI grounding dataset. The dataset was created by the authors and contains screenshots of common PC applications (such as File Explorer, Chrome, Outlook, Excel, and Word) showcasing various interactive elements. The purpose is to illustrate the complexity and diversity of the graphical user interfaces (GUIs) in a typical PC environment, emphasizing the challenges in building robust and accurate GUI agents. The screenshots show different actions and highlighted elements in these applications that are part of the grounding task.
read the caption
Figure 7: Example screenshots from the GUI grounding dataset we built for commonly used applications in PC scenarios.
More on tables
| Model | Type | Subtask SR (%) | Success Rate (%) |
| Gemini-2.0 | Single-Agent | 35.4% | 0.0% |
| Claude-3.5 | 15.2% | 0.0% | |
| Qwen2.5-VL | 46.8% | 12.0% | |
| GPT-4o | 41.8% | 8.0% | |
| UFO Zhang et al. (2024) | Multi-Agent | 43.0% | 12.0% |
| Agent-S Agashe et al. (2024) | 55.7% | 24.0% | |
| PC-Agent (Ours) | 76.0% | 56.0% |
🔼 This table presents a dynamic evaluation of different methods on the PC-Eval benchmark. It compares the subtask success rate (SSR) and overall success rate (SR) achieved by various single-agent and multi-agent approaches on a set of 25 complex instructions designed for PC environments. The results highlight the relative performance of different methods in handling complex, multi-step tasks involving interactions across multiple applications.
read the caption
Table 2: Dynamic evaluation results on the PC-Eval benchmark.
| Ablation study | Subtask Success Rate | Success Rate | ||
| APM | Manager Agent | Reflection Agent | ||
| ✓ | ✓ | 58.2% | 20.0% | |
| ✓ | ✓ | 50.6% | 12.0% | |
| ✓ | ✓ | 48.1% | 12.0% | |
| ✓ | ✓ | ✓ | 76.0% | 56.0% |
🔼 This table presents the results of an ablation study assessing the impact of three key components of the PC-Agent framework: the Active Perception Module (APM), the Manager Agent, and the Reflection Agent. Each row shows the performance (Subtask Success Rate and overall Success Rate) when one or more of these components are removed from the system, illustrating their individual contributions to the overall success of the system.
read the caption
Table 3: The results of the ablation study on the APM module, Manager agent and Reflection Agent.
| Model | Subtask SR (%) | Success Rate (%) | Recovery Rate (%) | Manager SR (%) |
| Gemini-2.0 | 55.7% | 28.0% | 24.0% | 84.0% |
| Claude-3.5 | 63.3% | 40.0% | 48.0% | 88.0% |
| Qwen2.5-VL | 32.9% | 12.0% | 40.0% | 88.0% |
| GPT-4o | 76.0% | 56.0% | 64.0% | 96.0% |
🔼 This table presents a comparative analysis of the PC-Agent’s performance using different large language models (LLMs) as its foundation. It shows the subtask success rate (SSR), overall success rate, recovery rate (percentage of tasks where errors were detected and corrected), and manager agent success rate (how well the agent decomposed tasks). The results highlight the impact of the chosen LLM on the PC-Agent’s ability to complete complex tasks on a PC.
read the caption
Table 4: Performance results of PC-Agent with different foundation models on PC-Eval.
Full paper#