TL;DR#
Increasing test-time compute shows promise for LLMs but remains underexplored in code generation. Existing parallel scaling improves solution coverage, while sequential refinement enhances individual samples. Validating code needs executing tests to ensure accuracy. Challenges arise in designing reward models due to the complexity of execution. But, code offers advantage, programmatic interpreters for precise outputs.
To solve this, the paper introduces S*, a hybrid test-time scaling framework for code generation. S substantially improves the coverage and selection accuracy of generated code.* S* extends parallel scaling with sequential scaling and leverages selection mechanism to generate distinguishing inputs for comparison. Grounded execution info helps identify the correct solution.
Key Takeaways#
Why does it matter?#
This paper introduces a novel test-time scaling framework that significantly improves code generation performance in LLMs. The findings demonstrate that S* can consistently improve model performance and generalization across diverse models and code generation benchmarks. This opens new research avenues for test-time scaling techniques in code generation.
Visual Insights#

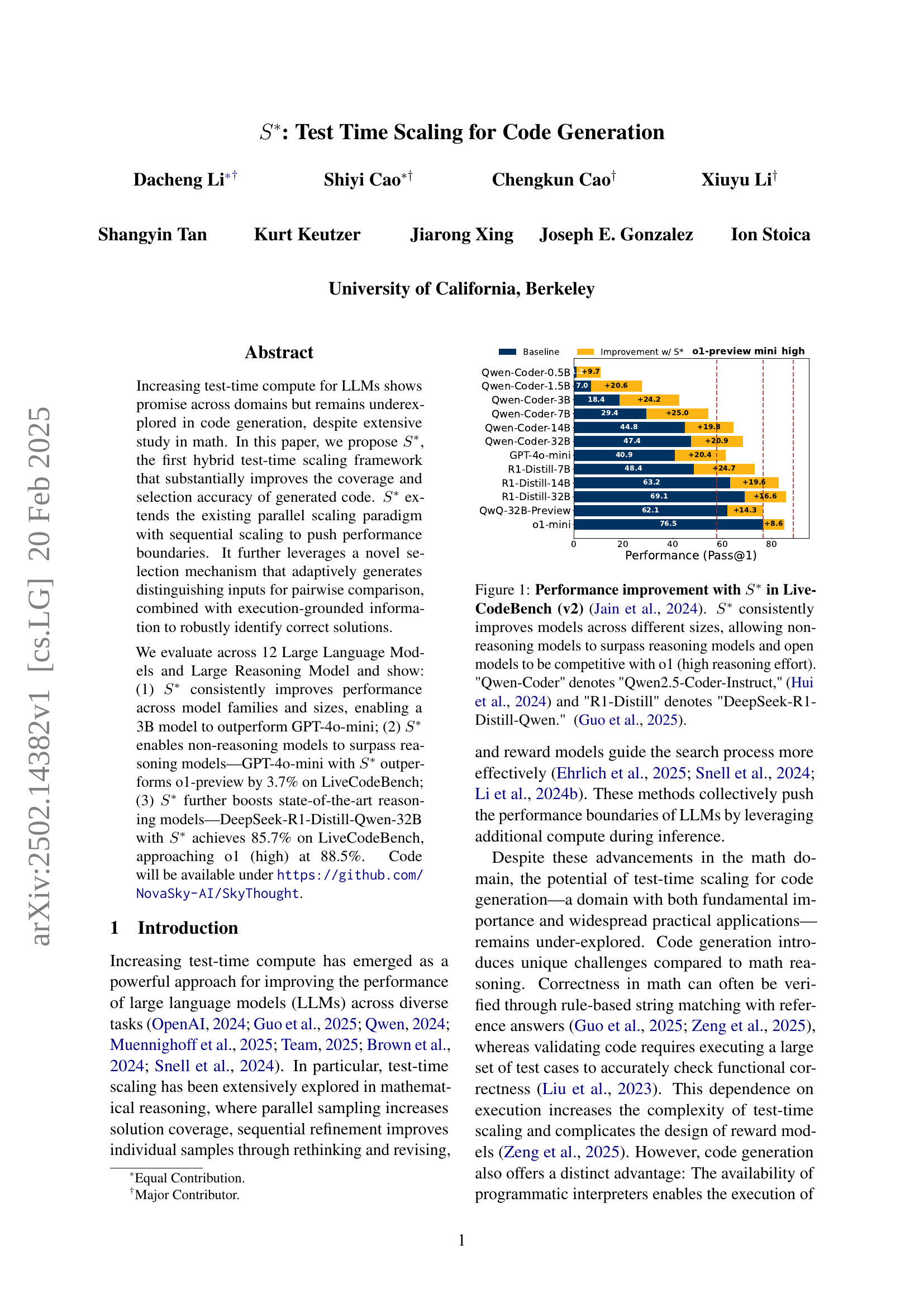
🔼 Figure 1 shows the performance improvement achieved by the proposed test-time scaling framework, S*, on various code generation models using LiveCodeBench (v2). The bar chart compares the Pass@1 (the percentage of problems solved by the top-ranked solution) for each model with and without S*. Results show that S* consistently boosts performance across different model sizes and types. Importantly, it enables non-reasoning models to outperform reasoning models and open-source models to reach a performance level comparable to the state-of-the-art closed model, o1 (which represents high reasoning effort). Model names are clarified with their full names in the caption (e.g., Qwen-Coder denotes Qwen2.5-Coder-Instruct).
read the caption
Figure 1: Performance improvement with S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT in LiveCodeBench (v2) (Jain et al., 2024). S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT consistently improves models across different sizes, allowing non-reasoning models to surpass reasoning models and open models to be competitive with o1 (high reasoning effort). 'Qwen-Coder' denotes 'Qwen2.5-Coder-Instruct,' (Hui et al., 2024) and 'R1-Distill' denotes 'DeepSeek-R1-Distill-Qwen.' (Guo et al., 2025).
| Method | Qwen2.5-Coder-Instruct | 4o-mini | R1-Distill | QwQ | o1-mini | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5B | 1.5B | 3B | 7B | 14B | 32B | 7B | 14B | 32B | ||||
| Zero-Shot | 1.2 | 7.0 | 18.4 | 29.4 | 44.8 | 47.4 | 40.9 | 48.4 | 63.2 | 69.1 | 62.1 | 76.5 |
| Majority Vote | 2.5 | 11.0 | 25.2 | 40.5 | 50.8 | 55.9 | 46.6 | 58.7 | 68.1 | 75.8 | 67.3 | 81.6 |
| Self-Debugging | 2.4 | 9.4 | 27.8 | 39.9 | 51.5 | 59.5 | 51.7 | 58.4 | 66.2 | 70.1 | 59.3 | 79.9 |
| S* | 10.9 | 27.6 | 42.7 | 54.4 | 64.6 | 70.1 | 61.3 | 73.2 | 82.8 | 85.7 | 76.3 | 85.3 |
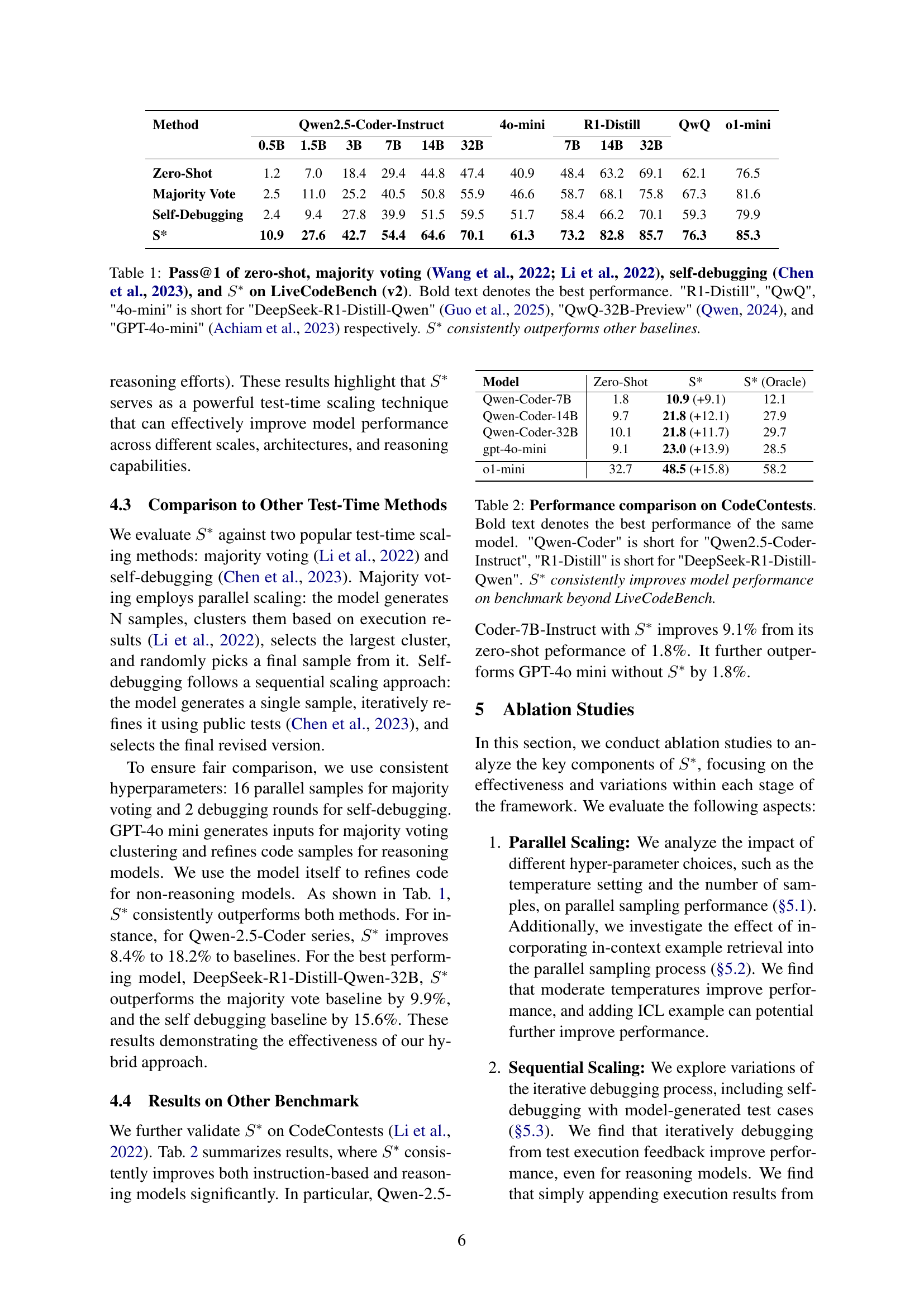
🔼 Table 1 presents a comparison of the Pass@1 metric (the percentage of problems solved correctly on the first attempt) across several methods for code generation using LiveCodeBench (version 2). The methods compared are: zero-shot (no test-time scaling), majority voting (a parallel scaling technique), self-debugging (a sequential scaling technique), and S* (the proposed hybrid approach). The table shows results for various large language models (LLMs), categorized by size and whether they are instruction-based or reasoning-based models. The models include Qwen-Coder (various sizes), GPT-40 mini, R1-Distill (various sizes), QwQ-32B-Preview, and O1-mini. Bold font indicates the best-performing method for each model. Abbreviations are provided for clarity. Overall, the table demonstrates S*’s superior performance compared to all the baseline techniques.
read the caption
Table 1: Pass@1 of zero-shot, majority voting (Wang et al., 2022; Li et al., 2022), self-debugging (Chen et al., 2023), and S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT on LiveCodeBench (v2). Bold text denotes the best performance. 'R1-Distill', 'QwQ', '4o-mini' is short for 'DeepSeek-R1-Distill-Qwen' (Guo et al., 2025), 'QwQ-32B-Preview' (Qwen, 2024), and 'GPT-4o-mini' (Achiam et al., 2023) respectively. S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT consistently outperforms other baselines.
In-depth insights#
Hybrid Scaling#
The concept of hybrid scaling in the context of large language models (LLMs) represents a pivotal advancement. It strategically combines parallel and sequential scaling approaches. This enables exploration of a broader solution space and more effective refinement of individual solutions. Parallel scaling enhances coverage through simultaneous generation of multiple candidate solutions. Sequential scaling improves solution quality through iterative refinement and revision. Hybrid scaling’s core value proposition lies in its ability to overcome the limitations inherent in either parallel or sequential scaling. Integrating these approaches allows for a more comprehensive and robust search strategy, leading to significant performance gains in complex tasks such as code generation and mathematical reasoning. The framework leverages adaptive mechanisms that respond to the intermediate results from both strategies to further improve efficiency. The adaptive mechanisms may utilize techniques, such as pruning less promising parallel branches based on the outcomes from preliminary sequential refinement or dynamic allocation of more resources to parallel search in areas identified as more challenging by the sequential exploration.
Adaptive Select#
Adaptive selection is a crucial aspect of intelligent systems, enabling them to dynamically adjust their behavior based on real-time feedback. This process is key to enhance decision-making, especially in scenarios with high variability. A robust method should consider a variety of selection techniques. A proper method should involve selecting the best samples by prompting an LLM to generate inputs that differentiate between paired samples. After generating test inputs, the framework must leverage execution results to inform the LLM to determine the optimal choice. In summary, adaptive selection not only boosts the efficiency of resource allocation but also ensures the system remains responsive.
Iterative Debug#
Iterative debugging signifies a cyclic refinement where code is tested, and outputs guide revisions. In LLMs, this involves feeding execution results back into the model for sequential correction. The method leverages feedback for incremental improvements, pushing solutions towards correctness. It refines parallel sampling by integrating sequential refinement, with each iteration aiming to fix errors identified in the preceding step, enhancing code quality and reducing failures. Effective iterative debugging involves carefully chosen public tests that give clear signals for correction. Balancing the debugging rounds is critical, preventing over-correction and ensuring diverse solution exploration. Efficient revision strategies prevent model hallucination. Iterative debugging may use the last round of output as a code sample instead of all. All of these iterative debugging methods are crucial for improving LLM code.
Code v. Math Scaling#
While both code generation and mathematical reasoning benefit from test-time scaling of LLMs, they present unique challenges. Math correctness can be rule-based verified but validating code needs execution, increasing complexity in reward model design. Code however offers the advantage of interpreters, enabling precise output and error messages for better grounding during generation and selection. Hybrid approaches combining parallel and sequential scaling are effective, as seen in the exploration of iterative debugging leveraging test execution feedback. Adaptive input synthesis further enables to select an appropriate and distinguishing test in order to better evaluate generated code.
Beyond Benchmarks#
Moving beyond standard benchmarks is crucial for advancing code generation. Current evaluations often focus on superficial metrics, failing to capture real-world usability. Future research should prioritize evaluations that assess code maintainability, scalability, and security vulnerabilities. It’s vital to consider how well generated code integrates into existing projects and adapts to evolving requirements, pushing beyond simplistic pass/fail rates on benchmark tests. User studies and qualitative analysis are key to understanding the practical value of these models.
More visual insights#
More on figures

🔼 Figure 2 illustrates the two-stage S* framework for code generation. Stage 1 (Generation) enhances parallel code generation by iteratively debugging each generated sample using public test cases. The outputs and errors from test execution guide subsequent rounds of code generation, refining the samples. Stage 2 (Selection) uses an LLM to generate distinguishing test inputs for pairs of generated code samples. The execution results of these test inputs on each sample are fed back to the LLM, allowing it to select the best performing code sample.
read the caption
Figure 2: Overview of S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT. Stage 1: Generation—S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT enhances parallel samples through iterative debugging. Each sample is tested using public test cases executed via an interpreter, with outputs and/or error messages used to guide the next round of sample generation. Stage 2: Selection—S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT selects the best sample by prompting an LLM to generate inputs that differentiate between paired samples, then leveraging actual execution results to inform the LLM to determine the optimal choice.
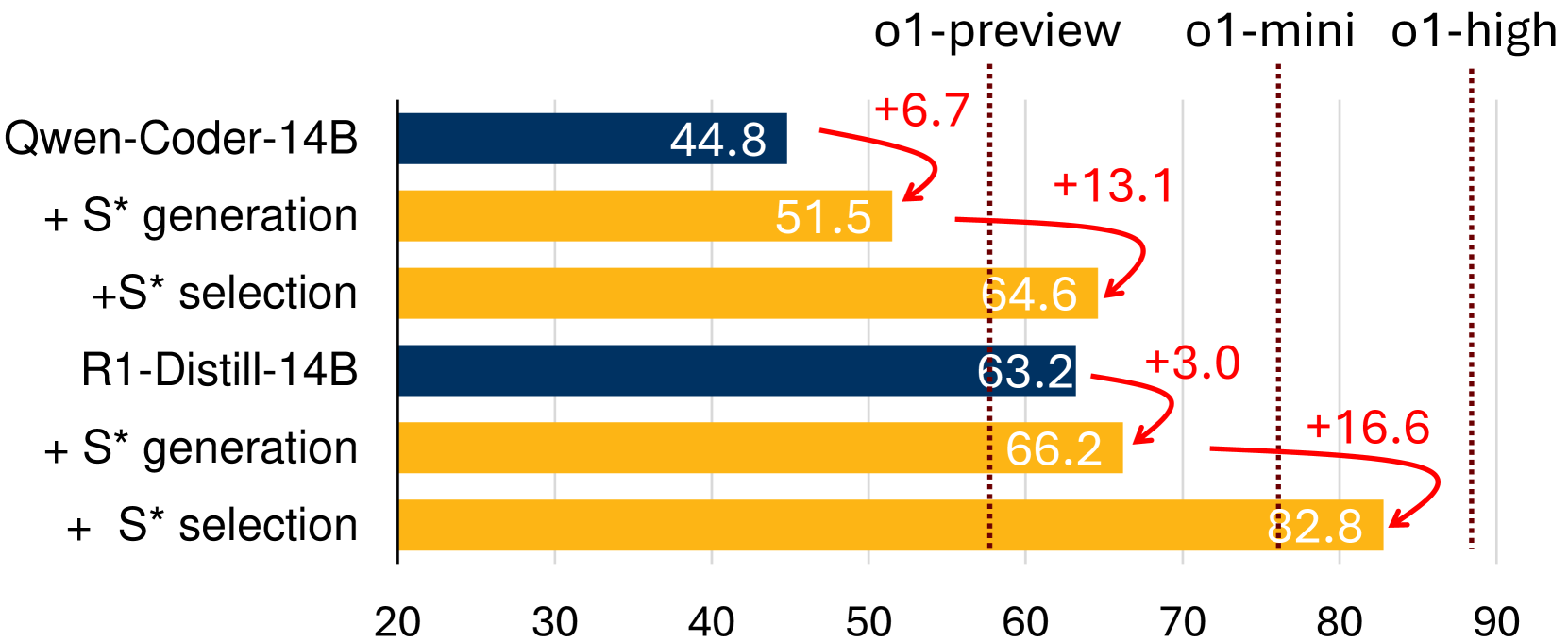
🔼 This figure displays the performance improvements achieved by the proposed test-time scaling framework, S*. It shows that incorporating S* enhances the performance of both instruction-based models (Qwen2.5-Coder-14B) and reasoning-based models (R1-Distill-14B), enabling them to surpass the performance of baseline models (o1-preview and o1-mini) without the test-time scaling method. The ablation study demonstrates that S* significantly improves the coverage and selection accuracy of generated code.
read the caption
Figure 3: Ablation of S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT performance benefits: Qwen2.5-Coder-14B-Instruct (denoted as Qwen-Coder-14B) (Hui et al., 2024) with S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT can surpass o1-preview without S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT. DeepSeek-R1-Distill-Qwen-14B (denoted as R1-Distill-14B) (Guo et al., 2025) with S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT outperforms o1-mini without S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT.

🔼 This figure shows the effects of two key hyperparameters on the performance of the S* model: temperature and the number of samples. The left panel illustrates the relationship between temperature and Pass@N (the percentage of problems solved by the best sample). It demonstrates that a moderate temperature (0.7) optimizes the balance between generating diverse code samples and ensuring high-quality code, resulting in the best performance. Higher temperatures (0.95) fail to significantly improve performance and may even reduce code quality. The right panel shows how performance scales with the number of parallel samples. It exhibits a clear log-linear relationship, indicating that increasing the number of samples leads to steadily improved performance.
read the caption
Figure 4: The effect of hyper-parameters. Left: The impact of temperature. A moderate temperature (0.7) balances diversity and quality, leading to higher Pass@N. In contrast, a higher temperature (0.95) does not further improve Pass@N, potentially degrading code quality. Right: The effect of increasing the number of samples. Performance improves log-linearly.

🔼 This figure displays the impact of in-context examples on the performance of three different language models (GPT-4o mini, Qwen-2.5-Coder-7B-Instruct, and Qwen-2.5-Coder-32B-Instruct) with varying numbers of parallel samples (N). It shows how the addition of in-context examples affects the Pass@N (the percentage of problems solved correctly by at least one of N samples) across different numbers of parallel samples. This allows for an analysis of the interaction between parallel sampling and in-context learning, demonstrating how different models respond to varying numbers of samples and whether the inclusion of in-context examples enhances the effect of increasing the sample size.
read the caption
Figure 5: Performance with in-context examples across different numbers of parallel samples (N𝑁Nitalic_N), for GPT-4o mini, Qwen2.5-Coder-7B-Instruct, and Qwen2.5-Coder-32B-Instruct.

🔼 Figure 6 illustrates a comparison of three different iterative debugging strategies used in the S* framework. These strategies are: using only public test cases; using public test cases plus model-generated test cases; and using only the last round of code sample as context when debugging. The results show the performance for each of these methods across multiple rounds of debugging, using 8 parallel samples, a temperature of 0.7, and up to 4 debugging rounds. The figure visually displays how the performance changes as more iterations of debugging are performed for each method.
read the caption
Figure 6: Comparison of three iterative debugging approaches: Public Tests, + Generated Tests and Last Round Context. Results are obtained with N=8𝑁8N=8italic_N = 8, temperature=0.7temperature0.7\text{temperature}=0.7temperature = 0.7 and up to four rounds of debugging.

🔼 This prompt guides the LLM to iteratively refine its code generation by providing the previous round’s reasoning, generated code, and test feedback. The LLM is instructed to reason about why the previous code failed and to correct it. The prompt ensures that the LLM only focuses on code generation, preventing non-code content in the code field.
read the caption
Figure 7: The prompt for iterative debugging.

🔼 This figure displays the prompt template used to instruct a large language model (LLM) to generate comprehensive test cases for a given coding problem. The prompt guides the LLM to create diverse test cases, including edge cases, complex scenarios, and cases designed to maximize the chance of detecting bugs. The expected output is structured as a JSON array where each element contains an input and its corresponding expected output. This structured output aids in efficient evaluation and automated verification of code solutions.
read the caption
Figure 8: The prompt for generating test cases.

🔼 This figure shows the prompt template used for the code generation stage in the S* framework. The prompt instructs the LLM to generate only the body of a Python function based on a given problem description, without including any extra text or comments. It’s designed to elicit concise and functional code from the model. The template is structured to facilitate interaction with the model and manage responses in a clear, consistent format for processing and evaluation.
read the caption
Figure 9: The prompt for code generation.
More on tables
| Model | Zero-Shot | S* | S* (Oracle) |
|---|---|---|---|
| Qwen-Coder-7B | 1.8 | 10.9 (+9.1) | 12.1 |
| Qwen-Coder-14B | 9.7 | 21.8 (+12.1) | 27.9 |
| Qwen-Coder-32B | 10.1 | 21.8 (+11.7) | 29.7 |
| gpt-4o-mini | 9.1 | 23.0 (+13.9) | 28.5 |
| o1-mini | 32.7 | 48.5 (+15.8) | 58.2 |
🔼 Table 2 presents a comparison of model performance on the CodeContests benchmark, focusing on the impact of the proposed S* method. It shows the Pass@1 scores (the percentage of problems solved by the top-ranked solution) for several models, including both instruction-based models (Qwen-Coder, short for Qwen2.5-Coder-Instruct) and reasoning-based models (R1-Distill, short for DeepSeek-R1-Distill-Qwen). The table compares the zero-shot performance of these models to their performance when augmented with S*, illustrating the improvement achieved by the S* method. Results are presented for different model sizes, highlighting the consistent performance gains provided by S* across models of varying capabilities.
read the caption
Table 2: Performance comparison on CodeContests. Bold text denotes the best performance of the same model. 'Qwen-Coder' is short for 'Qwen2.5-Coder-Instruct', 'R1-Distill' is short for 'DeepSeek-R1-Distill-Qwen'. S∗superscript𝑆S^{*}italic_S start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT consistently improves model performance on benchmark beyond LiveCodeBench.
| Model | Public | Generated | LLM | Adaptive Input |
|---|---|---|---|---|
| Only | Tests | Judge | Synthesis (Ours) | |
| Qwen-Coder-7B | 42.3 | 42.3 | 42.3 | 44.5 |
| Qwen-Coder-32B | 54.6 | 57.8 | 55.5 | 58.3 |
| GPT-4o mini | 54.1 | 55.2 | 56.3 | 57.3 |
| QwQ-32B-Preview | 64.3 | 65.9 | 68.6 | 69.7 |
| Avg. | 53.8 | 53.1 | 55.6 | 57.5 |
🔼 This table presents a comparison of different code selection methods used in the test-time scaling framework, S*. The performance metric is Pass@1 (the percentage of problems solved by selecting the best sample out of N generated samples) on the LiveCodeBench (v4) dataset. Four selection methods are compared: using only public tests; using public tests plus additional model-generated tests; using a Large Language Model (LLM) to judge between sample code; and using the adaptive input synthesis method proposed by the authors (S*). The table shows the Pass@1 scores for each method across four different models. Results are obtained using 8 parallel samples and a temperature of 0.7. The adaptive input synthesis method is shown to consistently outperform the other methods.
read the caption
Table 3: Pass@1 Performance comparison between different selection methods on LiveCodeBench(v4). Bold text denotes the best performance of the same model. 'Qwen-Coder', 'R1-Distill' is short for 'Qwen2.5-Coder-Instruct' and 'DeepSeek-R1-Distill-Qwen'. Results are obtained with N=8 and temperature=0.7. Our Adaptive Input Synthesis method achieves better accuracy over other methods.
Full paper#