TL;DR#
AI agents hold promise for accelerating scientific discovery, yet lack standardized frameworks. Current LLM agent frameworks lack open-ended research tasks and don’t enable research on different training algorithms, hindering objective progress measurement. This paper introduces Meta MLGYM and MLGYM-Bench. The framework enables research on RL algorithms for training such agents, also integrating diverse AI tasks for development/evaluation.
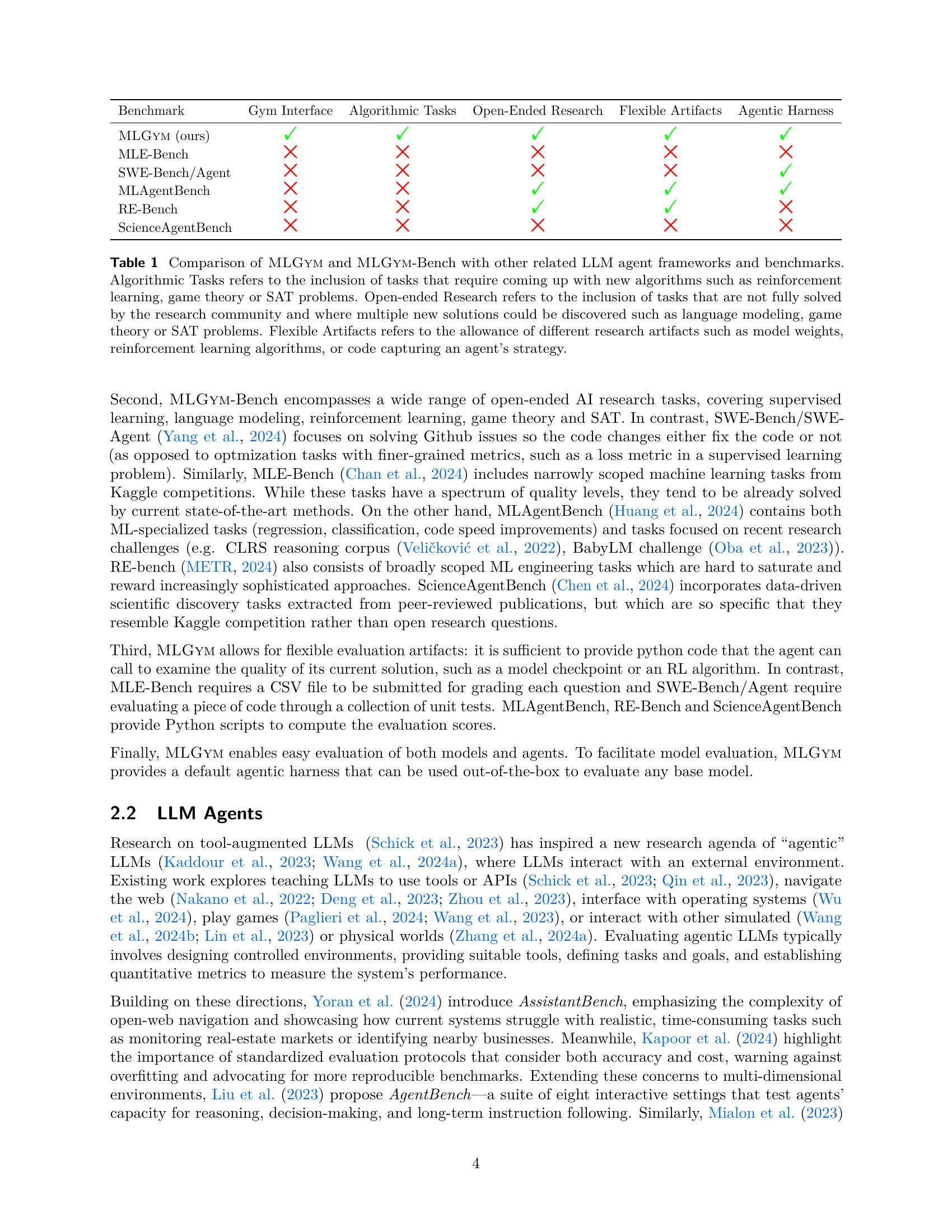
MLGYM-Bench consists of 13 open-ended AI research tasks from diverse domains. Evaluations on benchmarks assess LLMs like Claude-3.5-Sonnet, Llama-3.1-405B, and GPT-4o, finding they improve on baselines but don’t generate novel hypotheses or algorithms. The open-source framework facilitates research in advancing LLM agent capabilities. This will allow the research community to iterate new tasks and models.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces a new Gym environment, called MLGYM and benchmark, MLGYM-Bench, for AI research agents, advancing the field by providing standardized tools for development and evaluation. This enables easier integration, training with RL, and facilitates reproducible research, potentially accelerating advancements in agent capabilities.
Visual Insights#
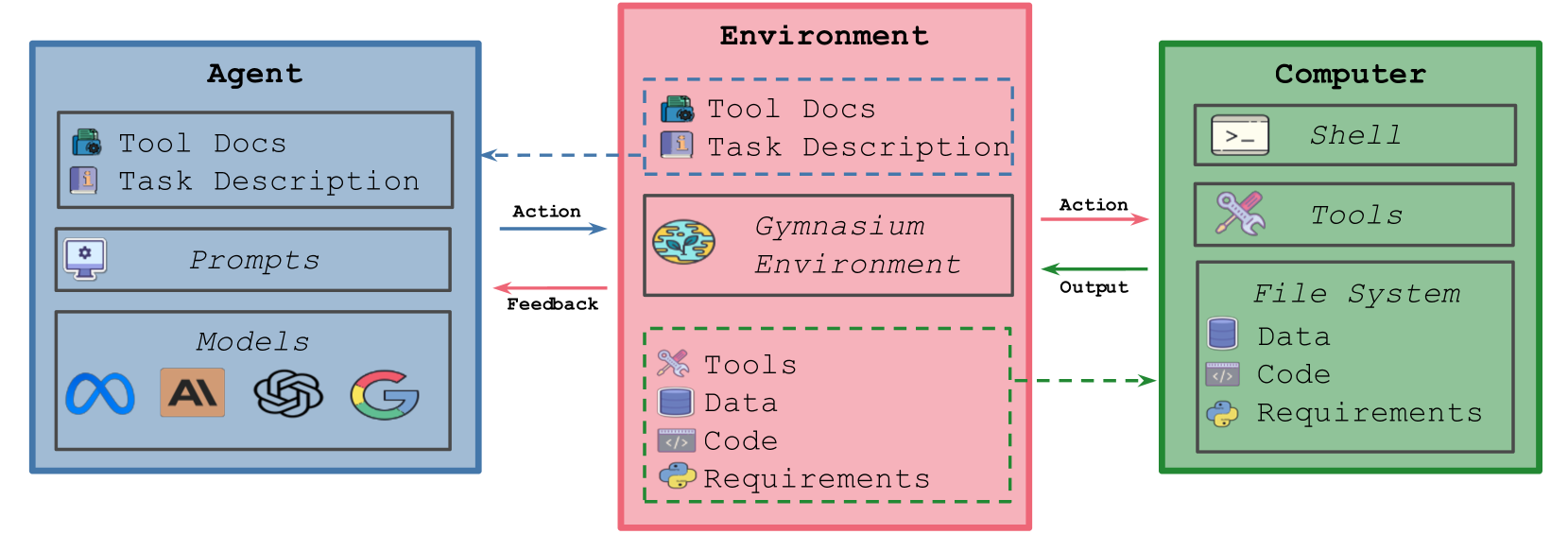
🔼 The figure shows a schematic diagram of the MLGYM framework. The framework integrates various components for developing and evaluating large language model (LLM) agents on diverse AI research tasks. It highlights the interaction between an agent (the LLM), an environment (which includes tools and data access), and a computer system. The agent receives a task description and interacts with the environment to perform actions, such as generating hypotheses, running experiments, and interpreting results. Feedback from these actions is used to guide the agent’s further iterations and improvements. The unified nature of MLGYM allows for streamlined evaluation of multiple LLM agents across different AI research domains.
read the caption
Figure 1: Diagram of \mlgym, a unified framework designed to integrate diverse and open-ended AI research tasks into a single platform for developing and evaluating LLM agents on these tasks.
In-depth insights#
MLGYM Framework#
The MLGYM framework is presented as a unified environment for evaluating and developing AI agents. It emphasizes ease of integration for new tasks and models. The Gym interface enables the application of reinforcement learning. MLGYM offers core components: Agents, Environments, Datasets, and Tasks, to improve flexibility and accessibility. The agents’ interactions are controlled through shell commands, making it simple and reproducible to interact with the platform.
AI Research Gym#
The concept of an “AI Research Gym” as envisioned in this paper represents a pivotal advancement. It’s a dedicated environment and benchmark designed for evaluating and developing AI agents specifically for AI research tasks. The goal is to accelerate scientific discovery. This “Gym” enables researchers to train agents using reinforcement learning (RL) and other algorithms in a safe, and reproducible setting. By formalizing research tasks into a Gym environment, this approach offers the potential to standardize evaluation, promote algorithmic improvements, and encourage open collaboration within the AI research community. Moreover, this also paves the way to create novel hypothesis and improve algorithmic capabilities of LLM agents.
Frontier LLM study#
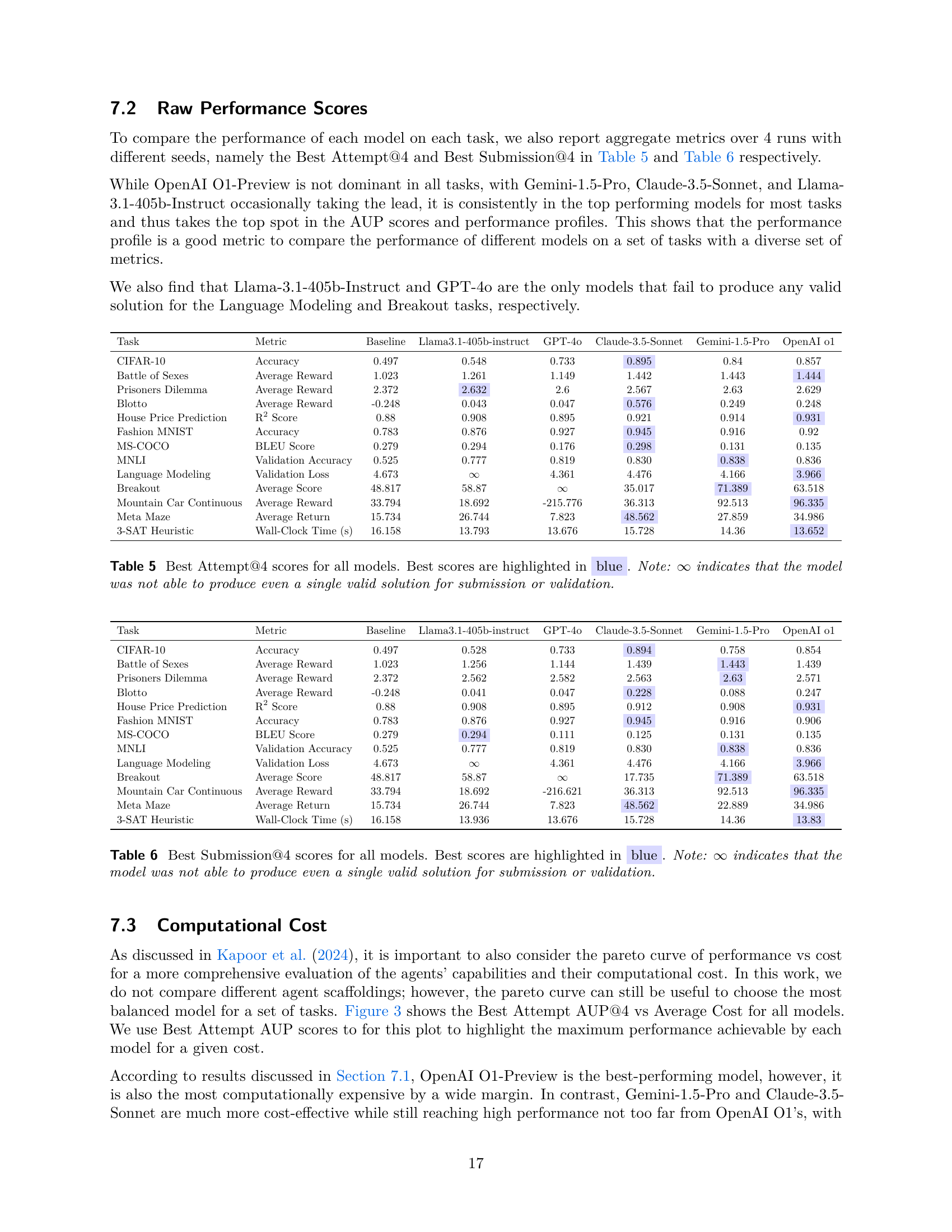
This paper introduces MLGYM and MLGYM-Bench, designed for evaluating LLM agents on AI research tasks. The framework facilitates research on RL algorithms for training agents, offering 13 diverse AI tasks. The research evaluated frontier LLMs like Claude-3.5-Sonnet and GPT-4o, showcasing the framework’s ability to integrate, evaluate, and generate synthetic data. The LLMs improved on baselines, particularly in hyperparameter tuning. However, they struggled with generating novel ideas or substantial improvements. The study also open-sources the framework and benchmark to advance AI research capabilities.
Bench Capabilities#
The paper introduces MLGYM and MLGYM-Bench as a framework and benchmark for AI research agents, emphasizing real-world AI research skills. MLGYM-Bench has 13 diverse tasks from domains like computer vision and game theory. It assesses agents’ ability to generate hypotheses, create data, implement methods, and analyze results, surpassing existing benchmarks by including open-ended research tasks. Frontier LLMs are evaluated, and a new metric, adapted from optimization literature, is used to fairly compare agents. MLGYM aims to facilitate future AI research by advancing AI research capabilities.
Limited novelty#
The paper acknowledges that the scientific novelty of AI agents remains a challenge. While agents can effectively execute tasks and demonstrate skills, their ability to produce truly original scientific breakthroughs is still limited. The benchmark focuses on baseline improvement which underscores the need for further research into enabling agents to generate novel hypotheses, design innovative experiments, and formulate groundbreaking theories. Overcoming this limitation is crucial for AI to become a driving force in scientific discovery.
More visual insights#
More on figures

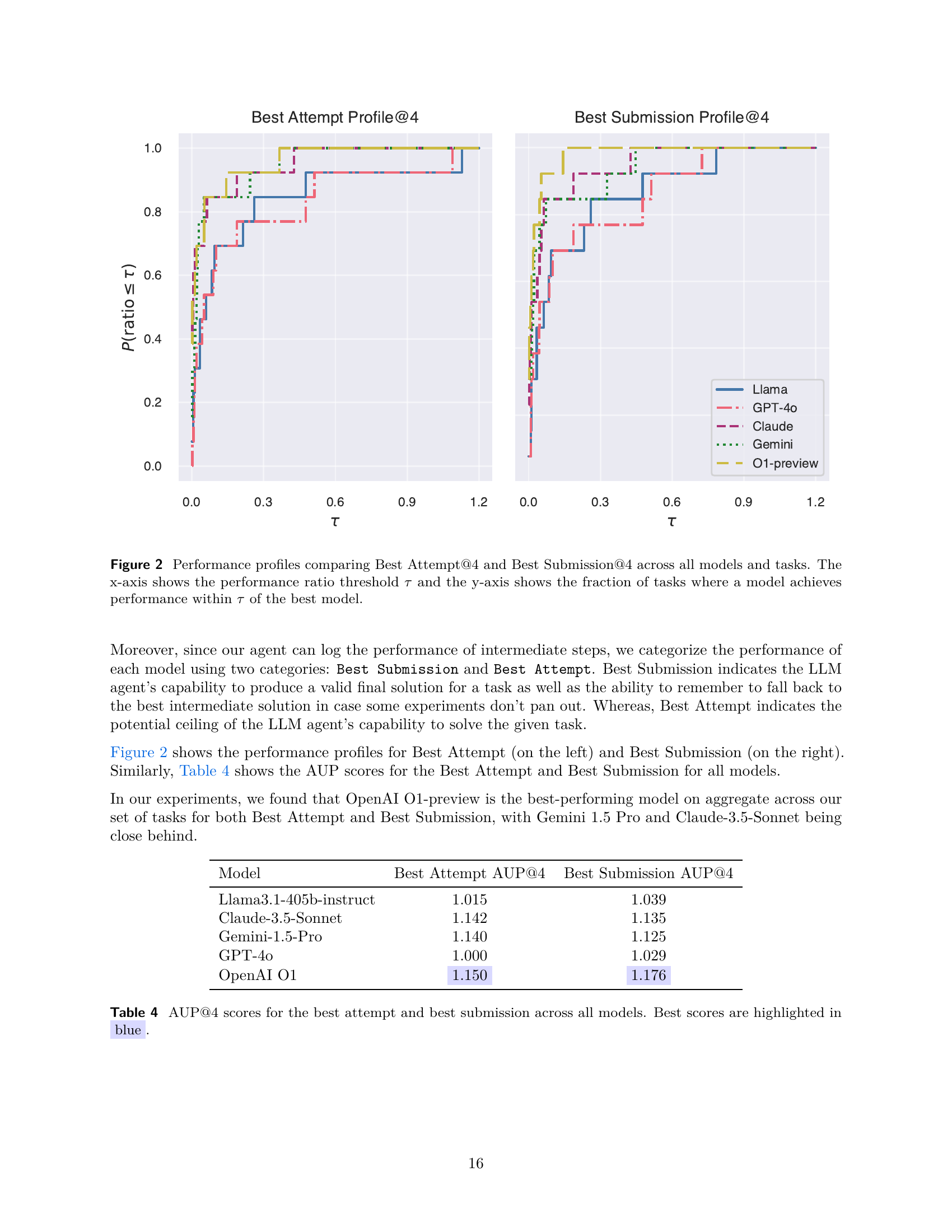
🔼 Figure 2 presents performance profiles that compare the models’ performance across all tasks within the MLGYM-Bench benchmark. Two performance profiles are shown: one for ‘Best Attempt’ (the best performance achieved at any point during the four runs), and one for ‘Best Submission’ (the best final performance achieved at the end of the four runs). The x-axis represents the performance ratio threshold (τ). This threshold indicates how much worse a model’s performance can be compared to the best-performing model on a task and still be counted. The y-axis shows the fraction of tasks for which a given model’s performance is within τ of the best model’s performance. In simpler terms, the plots illustrate the probability that a model’s performance is within a certain range of the optimal performance across the entire set of tasks.
read the caption
Figure 2: Performance profiles comparing Best Attempt@4 and Best Submission@4 across all models and tasks. The x-axis shows the performance ratio threshold τ𝜏\tauitalic_τ and the y-axis shows the fraction of tasks where a model achieves performance within τ𝜏\tauitalic_τ of the best model.

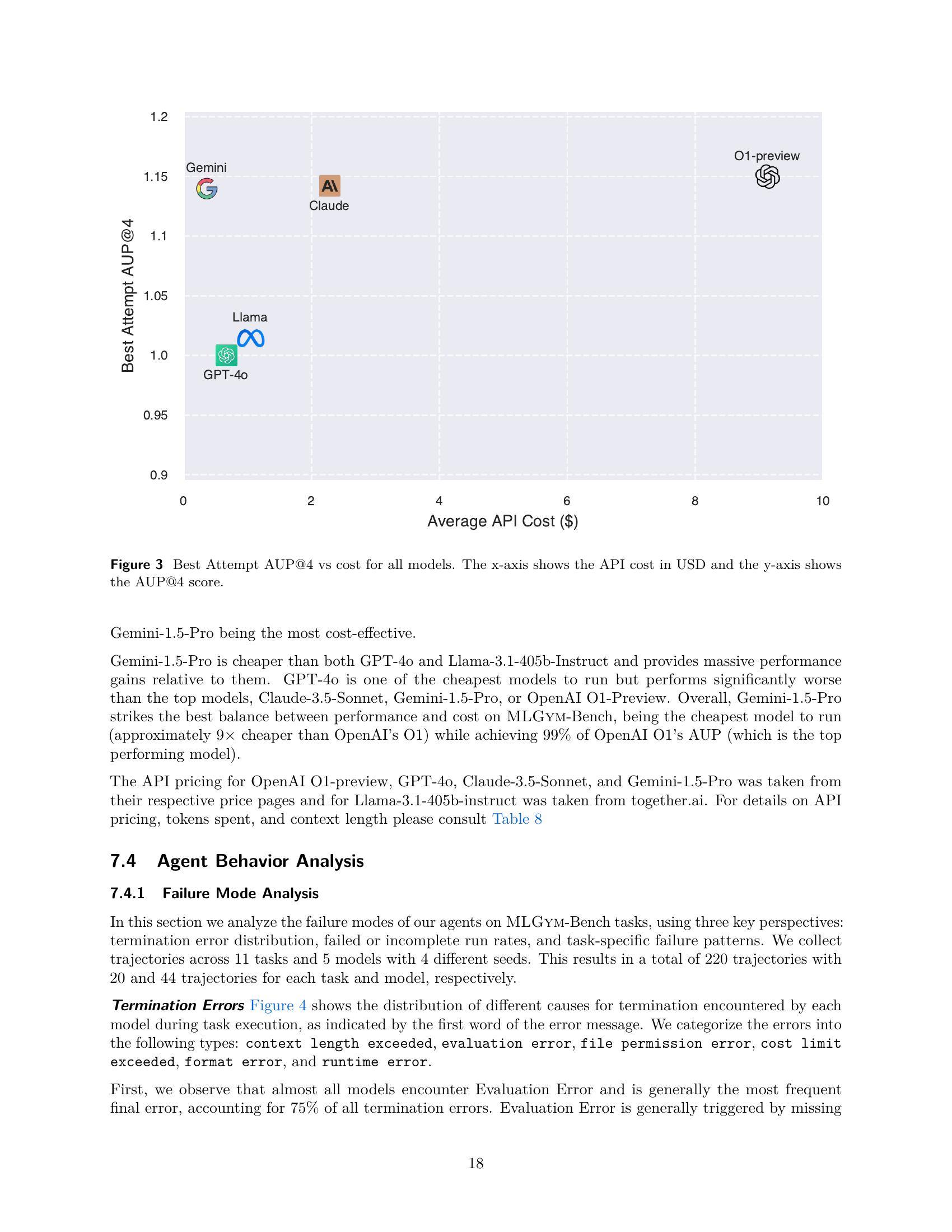
🔼 This figure compares the cost-effectiveness of different large language models (LLMs) in terms of their performance on a benchmark of AI research tasks. The x-axis represents the total cost of using each LLM’s API, while the y-axis shows the Area Under the Performance Profile (AUP) score, a measure that summarizes the model’s performance across all tasks. A higher AUP score indicates better performance. The plot allows for a visual assessment of which models provide the best balance between performance and cost. Models appearing higher on the y-axis and lower on the x-axis would be considered more cost-effective.
read the caption
Figure 3: Best Attempt AUP@4 vs cost for all models. The x-axis shows the API cost in USD and the y-axis shows the AUP@4 score.

🔼 This bar chart visualizes the frequency of different error types encountered by various large language models (LLMs) during the execution of machine learning research tasks. Each bar represents an LLM, and the height of the bar corresponds to the total number of times the model terminated due to errors. The chart provides a breakdown of error types, such as context length exceeded, evaluation errors, file permission errors, cost limit exceeded, and others. This allows for a comparison of the robustness and reliability of different LLMs in handling various issues that might arise during complex AI research tasks.
read the caption
Figure 4: Termination Error Distribution by model. The size of the bars corresponds to the number of times each model triggered an exit status.

🔼 This figure presents a bar chart visualizing the number of failed and incomplete runs achieved by different language models during the execution of AI research tasks. A run is classified as failed if it terminates with an error and doesn’t produce any valid results. It’s marked as incomplete if it finishes with an error but yields at least one valid intermediate result. The chart provides a comparison of model reliability and robustness across various tasks, highlighting the frequency of failures and incomplete runs for each model.
read the caption
Figure 5: Number of Failed and Incomplete runs per model. The criteria for marking a run as incomplete or failed is described in Section 7.4.1

🔼 This figure visualizes the frequency of different actions performed by the AI agents across all their attempts in solving various tasks. The actions are categorized according to their functionalities (e.g., editing, viewing, validating code; running Python scripts; executing bash commands) as described in Sections 3.5 and 7.4.2 of the paper. It offers insights into the AI agents’ workflow strategies when tackling complex tasks. For example, the proportion of ‘Edit’ and ‘View’ actions relative to ‘Python’ actions may reflect the balance between code refinement and experiment execution during the problem-solving process. The relative scarcity of ‘Search’ actions could highlight areas for improvement in the agents’ information gathering strategies.
read the caption
Figure 6: Action distribution across all runs. We group the actions into categories following the grouping defined in Section 3.5 and Section 7.4.2.

🔼 Figure 7 is a bar chart that visualizes the frequency of different types of actions taken by five large language models (LLMs) while performing AI research tasks within the MLGYM framework. The actions are categorized into groups defined in Sections 3.5 and 7.4.2 of the paper. These categories include actions related to editing, viewing, validating, submitting, searching, using Python scripts, and executing bash commands. The chart allows for a comparison of the action patterns of the five LLMs, providing insights into their approaches to solving AI research tasks.
read the caption
Figure 7: Action distribution for each model. We group the actions into categories following the grouping defined in Section 3.5 and Section 7.4.2.

🔼 This figure visualizes the frequency of different action types taken by AI agents at each step during the task-solving process. Actions are categorized according to their function (e.g., editing files, running code, searching, validating, or submitting results). The chart shows how the relative importance of each action category changes over the course of the process, reflecting the agents’ strategy and problem-solving behavior.
read the caption
Figure 8: Action distribution for each step. We group the actions into categories following the grouping defined in Section 3.5 and Section 7.4.2.

🔼 This figure visualizes the number of failed and incomplete runs for each task in the MLGYM-Bench benchmark. A ‘failed’ run is defined as a run that terminates with an error and does not produce a valid intermediate submission (at least one score on the test set is not obtained). An ‘incomplete’ run is defined as a run that terminates with an error but does produce at least one valid intermediate submission. The chart allows for a visual comparison of the relative reliability of different tasks within the benchmark, highlighting those that present the most challenges to the AI agent, as well as those more easily solved. This helps to understand the relative difficulty of the tasks within the MLGYM-Bench suite.
read the caption
Figure 9: Number of Failed and Incomplete runs per task. The criteria for marking a run as incomplete or failed is described in Section 7.4.1

🔼 Figure 10 displays a breakdown of the actions performed by AI agents across various tasks in the MLGYM benchmark. The actions are categorized into groups (Edit, View, Validate, Submit, Search, Python, Bash), defined earlier in the paper. The chart visually represents the frequency of each action type for each task, offering insights into the AI agent’s workflow and strategies.
read the caption
Figure 10: Action Distribution for each task. We group the actions into categories following the grouping defined in Section 3.5 and Section 7.4.2.
Full paper#